
VERD: Emergence of Product-Based Video E-Commerce Retrieval Dataset from User’s Perspective


Abstract
:1. Introduction
2. Related Work
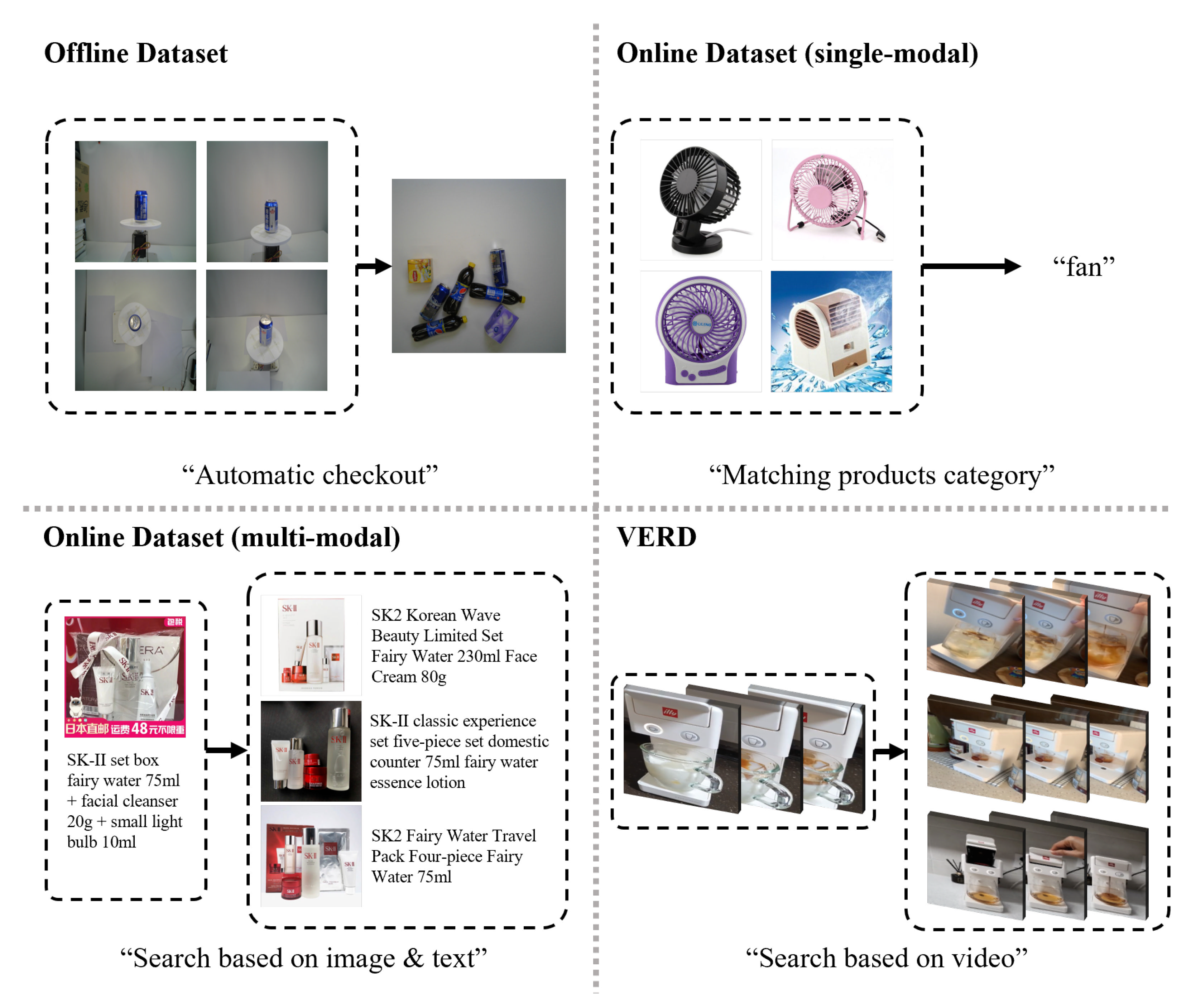
2.1. Datasets
2.1.1. Offline Dataset
2.1.2. Online Dataset
2.2. Methods
2.2.1. Image-Based Retrieval
2.2.2. Video-Based Retrieval
2.2.3. Multimodal-Based Retrieval
3. Proposed Dataset
3.1. Video Collection
3.2. Annotation Process
3.3. Hierarchical Category Labeling
3.4. Dataset Statistics
3.5. Dataset Characteristics
4. Experiments
4.1. Setup
4.2. Benchmark
4.3. Analysis
4.3.1. Feature Comparison
4.3.2. Modality Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Merler, M.; Galleguillos, C.; Belongie, S. Recognizing groceries in situ using in vitro training data. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Jund, P.; Abdo, N.; Eitel, A.; Burgard, W. The freiburg groceries dataset. arXiv 2016, arXiv:1611.05799. [Google Scholar]
- Klasson, M.; Zhang, C.; Kjellström, H. A hierarchical grocery store image dataset with visual and semantic labels. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 491–500. [Google Scholar]
- Georgiadis, K.; Kordopatis-Zilos, G.; Kalaganis, F.; Migkotzidis, P.; Chatzilari, E.; Panakidou, V.; Pantouvakis, K.; Tortopidis, S.; Papadopoulos, S.; Nikolopoulos, S.; et al. Products-6K: A Large-Scale Groceries Product Recognition Dataset. In Proceedings of the The 14th PErvasive Technologies Related to Assistive Environments Conference, Virtual Event, 29 June–2 July 2021; pp. 1–7. [Google Scholar]
- Wei, X.S.; Cui, Q.; Yang, L.; Wang, P.; Liu, L.; Yang, J. RPC: A Large-Scale and Fine-Grained Retail Product Checkout Dataset. arXiv 2022, arXiv:1901.07249. [Google Scholar] [CrossRef]
- Oh Song, H.; Xiang, Y.; Jegelka, S.; Savarese, S. Deep metric learning via lifted structured feature embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 27–30 June 2016; pp. 4004–4012. [Google Scholar]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 27–30 June 2016; pp. 1096–1104. [Google Scholar]
- Ge, Y.; Zhang, R.; Wang, X.; Tang, X.; Luo, P. Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CA, USA, 16–20 June 2019; pp. 5337–5345. [Google Scholar]
- Bai, Y.; Chen, Y.; Yu, W.; Wang, L.; Zhang, W. Products-10k: A large-scale product recognition dataset. arXiv 2020, arXiv:2008.10545. [Google Scholar]
- Corbiere, C.; Ben-Younes, H.; Rame, A.; Ollion, C. Leveraging Weakly Annotated Data for Fashion Image Retrieval and Label Prediction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, D.; Liu, F.; Du, X.; Gao, R.; Xu, F. MEP-3M: A Large-scale Multi-modal E-Commerce Products Dataset. In Proceedings of the IJCAI 2021 Workshop on Long-Tailed Distribution Learning, Virtual Event, 21 August 2021. [Google Scholar]
- Zhan, X.; Wu, Y.; Dong, X.; Wei, Y.; Lu, M.; Zhang, Y.; Xu, H.; Liang, X. Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-Modal Pretraining. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2021; pp. 11782–11791. [Google Scholar]
- Dong, X.; Zhan, X.; Wu, Y.; Wei, Y.; Kampffmeyer, M.C.; Wei, X.; Lu, M.; Wang, Y.; Liang, X. M5Product: Self-Harmonized Contrastive Learning for E-Commercial Multi-Modal Pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 21252–21262. [Google Scholar]
- Kordopatis-Zilos, G.; Papadopoulos, S.; Patras, I.; Kompatsiaris, Y. Near-duplicate video retrieval with deep metric learning. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 347–356. [Google Scholar]
- Kordopatis-Zilos, G.; Papadopoulos, S.; Patras, I.; Kompatsiaris, I. Visil: Fine-grained spatio-temporal video similarity learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6351–6360. [Google Scholar]
- Shao, J.; Wen, X.; Zhao, B.; Xue, X. Temporal context aggregation for video retrieval with contrastive learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3268–3278. [Google Scholar]
- George, M.; Floerkemeier, C. Recognizing products: A per-exemplar multi-label image classification approach. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 440–455. [Google Scholar]
- Li, C.; Du, D.; Zhang, L.; Luo, T.; Wu, Y.; Tian, Q.; Wen, L.; Lyu, S. Data priming network for automatic check-out. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2152–2160. [Google Scholar]
- Shankar, D.; Narumanchi, S.; Ananya, H.; Kompalli, P.; Chaudhury, K. Deep learning based large scale visual recommendation and search for e-commerce. arXiv 2017, arXiv:1703.02344. [Google Scholar]
- Yang, F.; Kale, A.; Bubnov, Y.; Stein, L.; Wang, Q.; Kiapour, H.; Piramuthu, R. Visual search at ebay. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, USA, 13–17 August 2017; pp. 2101–2110. [Google Scholar]
- Hu, H.; Wang, Y.; Yang, L.; Komlev, P.; Huang, L.; Chen, X.; Huang, J.; Wu, Y.; Merchant, M.; Sacheti, A. Web-scale responsive visual search at bing. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 359–367. [Google Scholar]
- Tan, H.K.; Ngo, C.W.; Hong, R.; Chua, T.S. Scalable detection of partial near-duplicate videos by visual-temporal consistency. In Proceedings of the 17th ACM international conference on Multimedia, Columbia, BC, Canada, 19–24 October 2009; pp. 145–154. [Google Scholar]
- Chou, C.L.; Chen, H.T.; Lee, S.Y. Pattern-based near-duplicate video retrieval and localization on web-scale videos. IEEE Trans. Multimed. 2015, 17, 382–395. [Google Scholar] [CrossRef]
- Kordopatis-Zilos, G.; Papadopoulos, S.; Patras, I.; Kompatsiaris, Y. Near-duplicate video retrieval by aggregating intermediate cnn layers. In Proceedings of the International Conference on Multimedia Modeling, Reykjavik, Iceland, 4–6 January 2017; pp. 251–263. [Google Scholar]
- Shin, W.; Park, J.; Woo, T.; Cho, Y.; Oh, K.; Song, H. e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3484–3494. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Category | Fold | Mean | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| DML [14] | Product | 0.081 | 0.080 | 0.087 | 0.077 | 0.083 | 0.082 |
| Fashion | 0.090 | 0.077 | 0.097 | 0.093 | 0.092 | 0.090 | |
| ViSiL [15] | Product | 0.309 | 0.310 | 0.311 | 0.311 | 0.309 | 0.310 |
| Fashion | 0.159 | 0.159 | 0.158 | 0.159 | 0.161 | 0.159 | |
| TCA [16] | Product | 0.290 | 0.292 | 0.293 | 0.293 | 0.294 | 0.292 |
| Fashion | 0.175 | 0.182 | 0.183 | 0.184 | 0.184 | 0.181 | |
| Descriptor | Category | Fold | Mean | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| Frame-level | Product | 0.290 | 0.292 | 0.293 | 0.293 | 0.294 | 0.292 |
| Fashion | 0.175 | 0.182 | 0.183 | 0.184 | 0.184 | 0.181 | |
| Video-level | Product | 0.288 | 0.290 | 0.290 | 0.290 | 0.292 | 0.290 |
| Fashion | 0.173 | 0.181 | 0.182 | 0.184 | 0.183 | 0.181 | |
| Method | Category | Fold | Mean | ||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||
| Image-based | Product | 0.191 | 0.192 | 0.192 | 0.192 | 0.192 | 0.192 |
| Fashion | 0.100 | 0.100 | 0.099 | 0.100 | 0.100 | 0.100 | |
| Video-based | Product | 0.291 | 0.291 | 0.292 | 0.293 | 0.291 | 0.292 |
| Fashion | 0.158 | 0.158 | 0.157 | 0.158 | 0.159 | 0.158 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, G.; Jo, W.; Choi, Y. VERD: Emergence of Product-Based Video E-Commerce Retrieval Dataset from User’s Perspective. Sensors 2023, 23, 513. https://doi.org/10.3390/s23010513
Lee G, Jo W, Choi Y. VERD: Emergence of Product-Based Video E-Commerce Retrieval Dataset from User’s Perspective. Sensors. 2023; 23(1):513. https://doi.org/10.3390/s23010513
Chicago/Turabian StyleLee, Gwangjin, Won Jo, and Yukyung Choi. 2023. "VERD: Emergence of Product-Based Video E-Commerce Retrieval Dataset from User’s Perspective" Sensors 23, no. 1: 513. https://doi.org/10.3390/s23010513
APA StyleLee, G., Jo, W., & Choi, Y. (2023). VERD: Emergence of Product-Based Video E-Commerce Retrieval Dataset from User’s Perspective. Sensors, 23(1), 513. https://doi.org/10.3390/s23010513