

Blind Watermarking for Hiding Color Images in Color Images with Super-Resolution Enhancement

Abstract
1. Introduction
2. Preliminaries
2.1. DCT-Based Watermarking
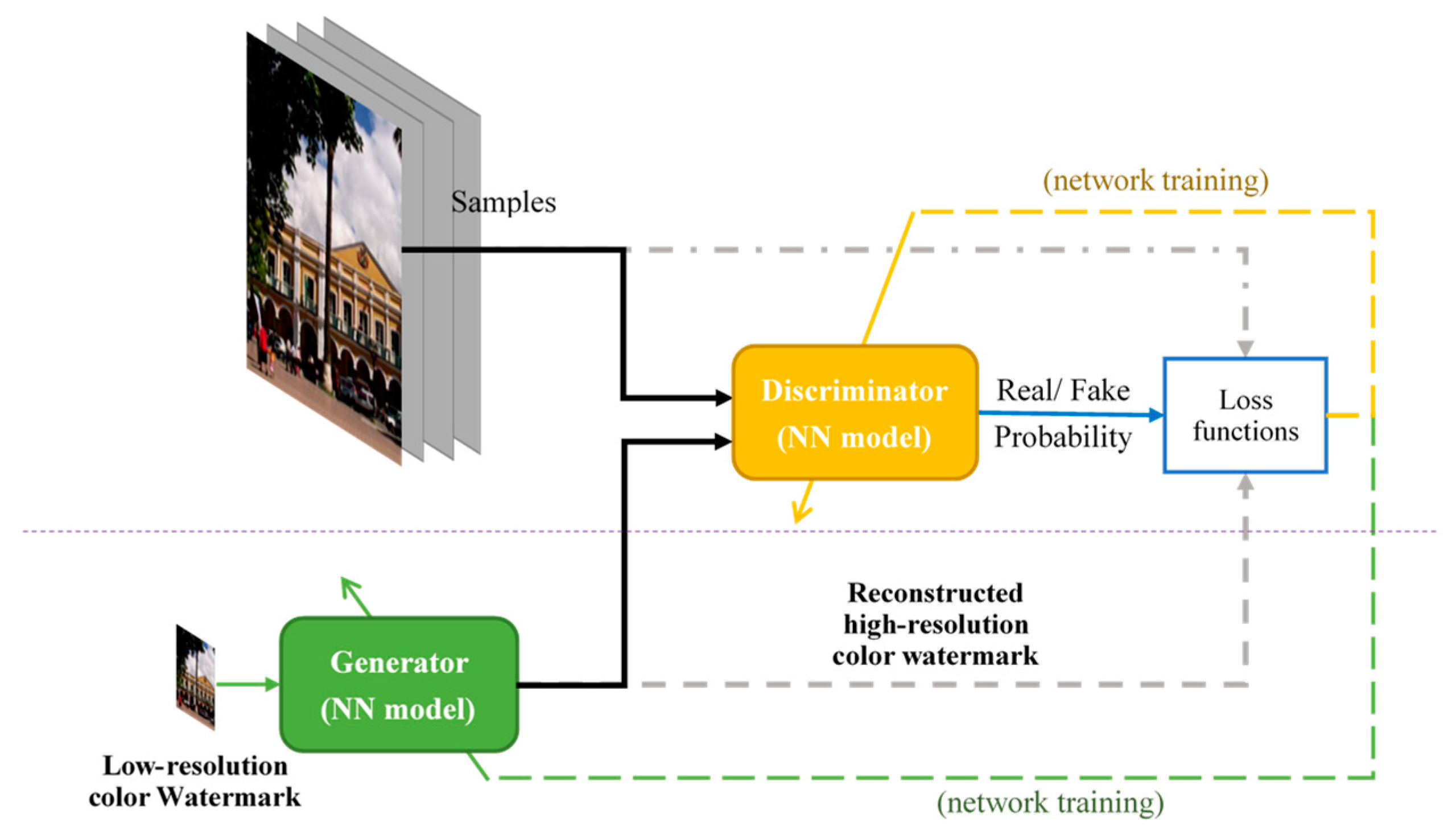
2.2. Super-Resolution Reconstruction
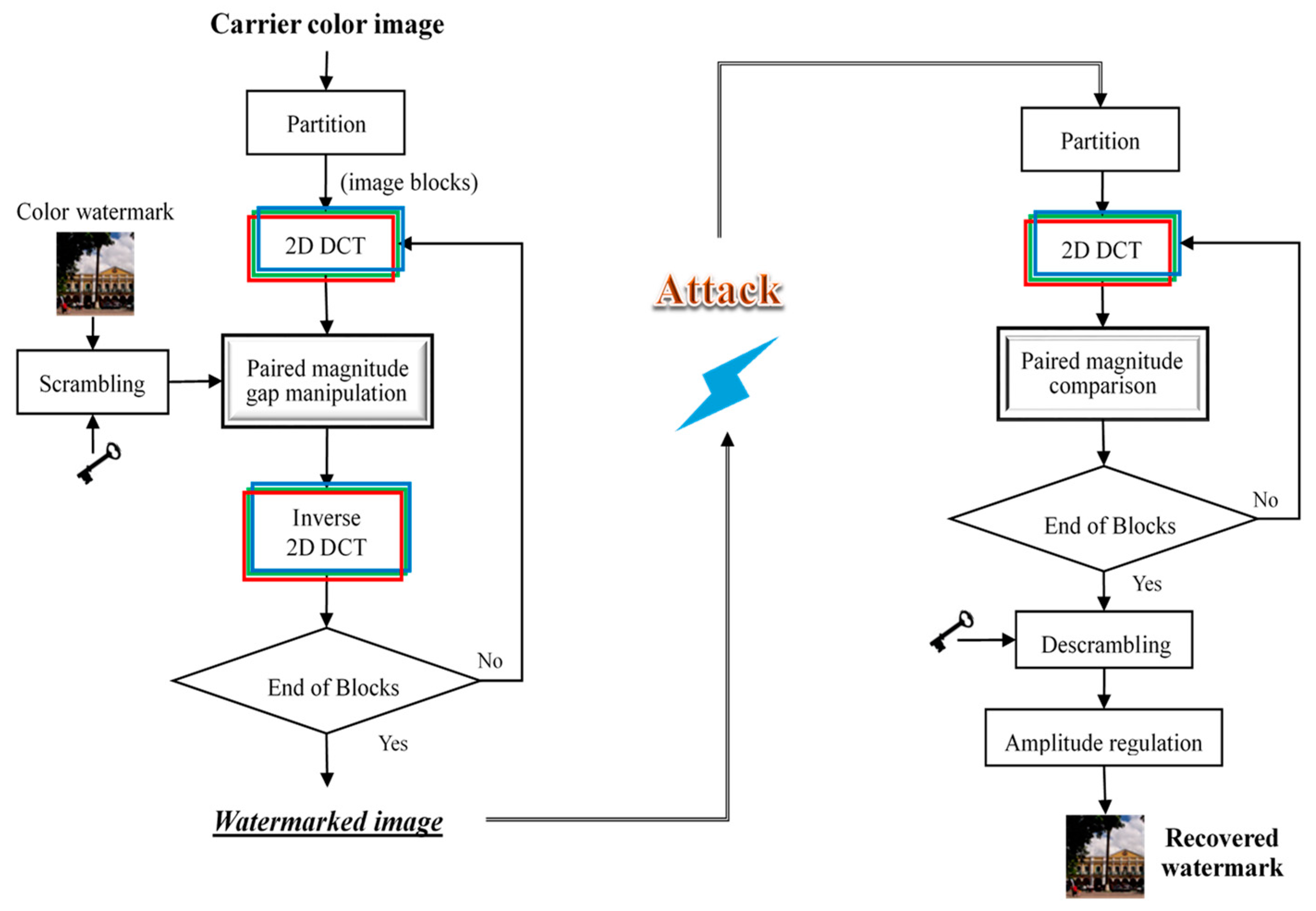
3. Proposed Watermarking Scheme
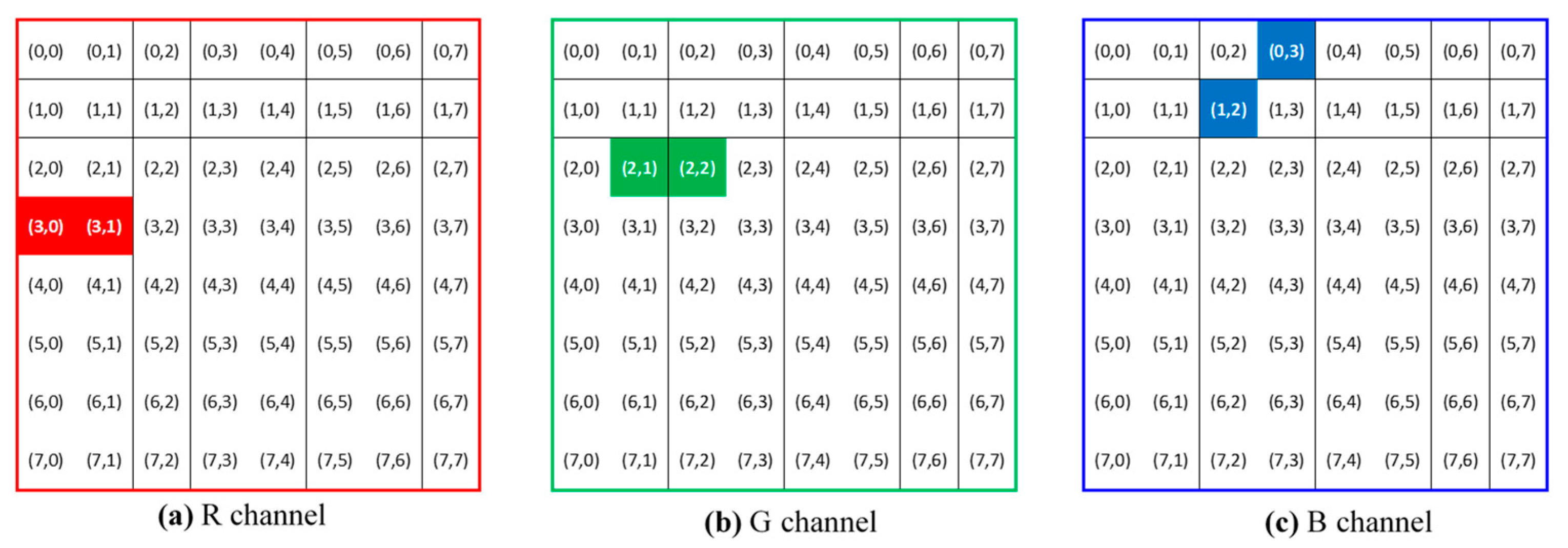
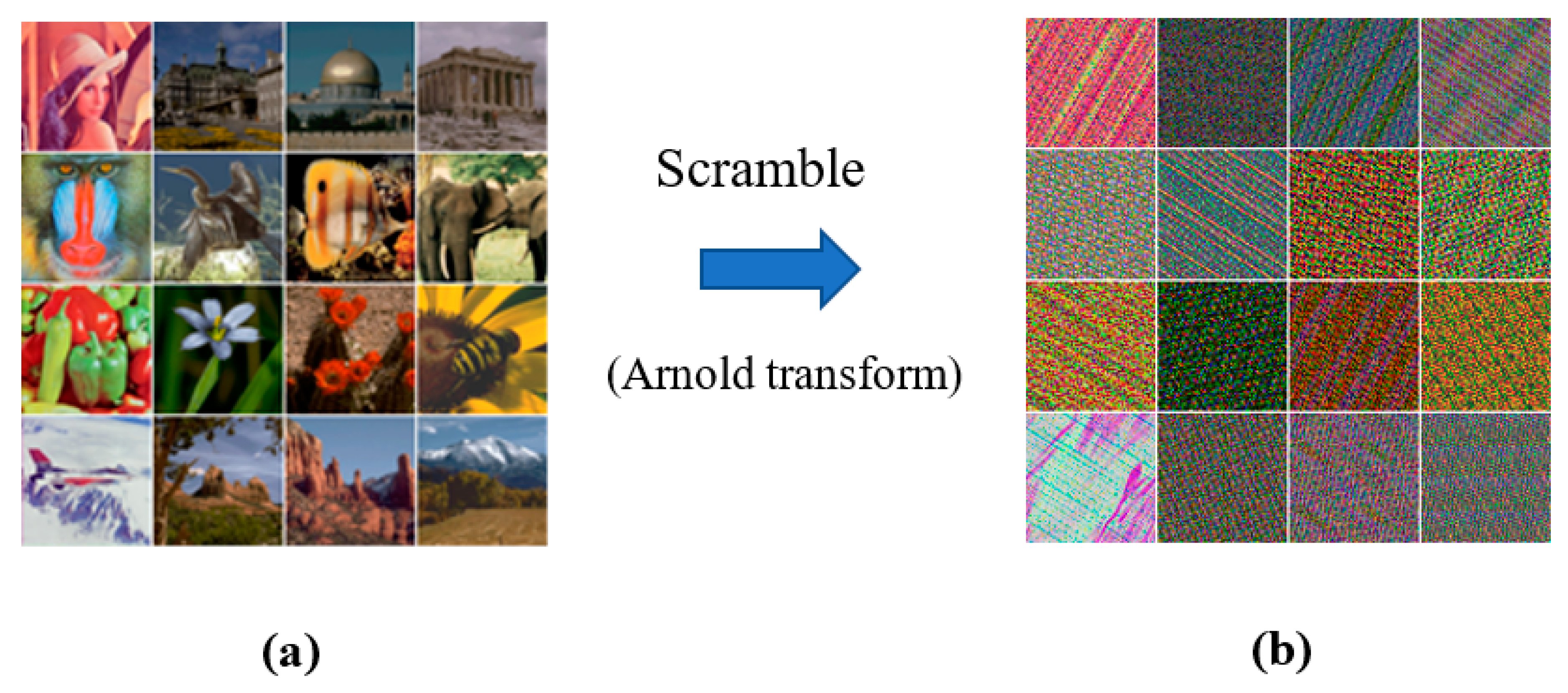
3.1. Watermark Embedding via the DCT-MGA Scheme
3.2. Watermark Extraction and Regulation
4. Performance Evaluation
4.1. Imperceptibility Test
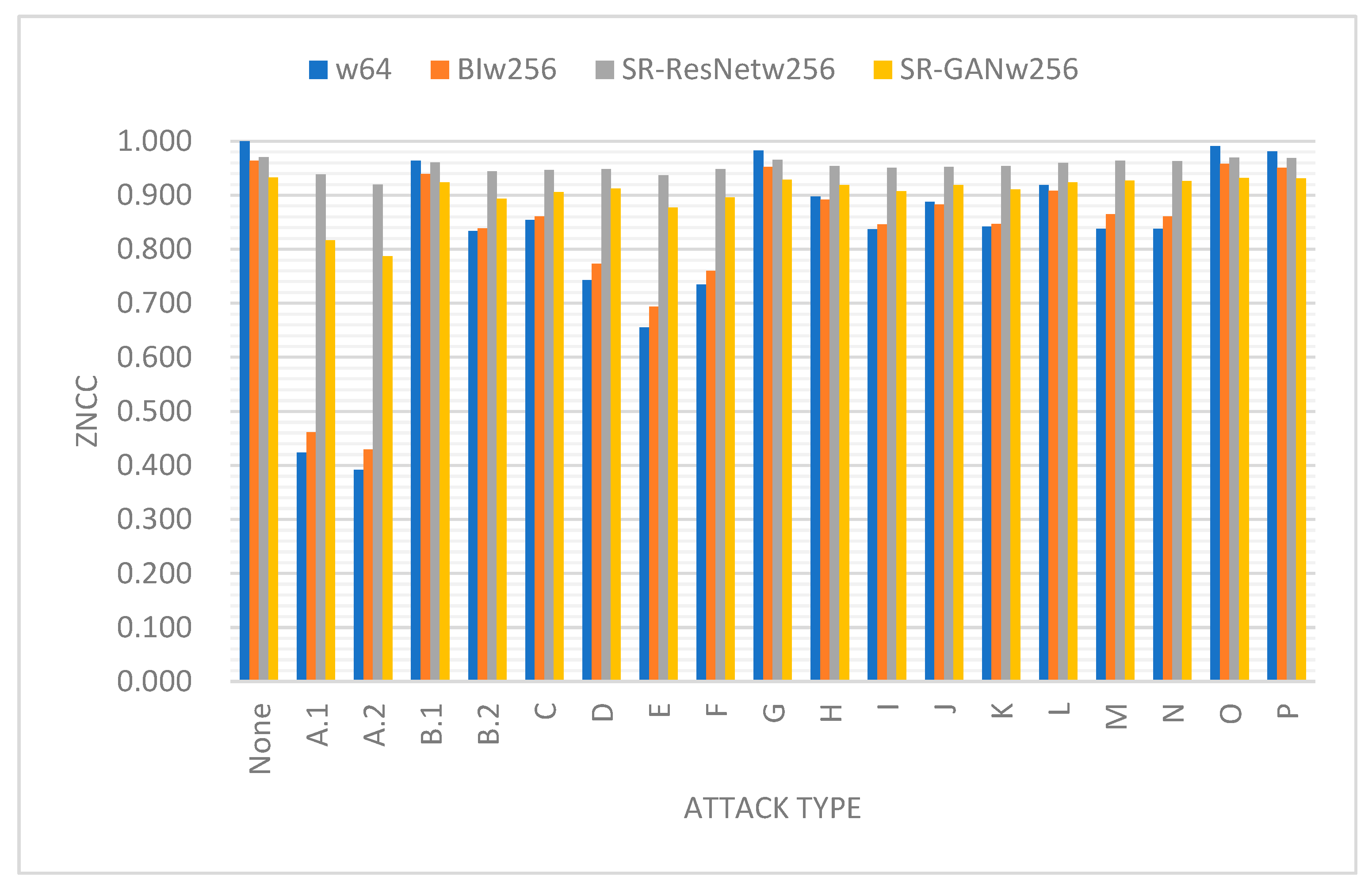
4.2. Robustness Test
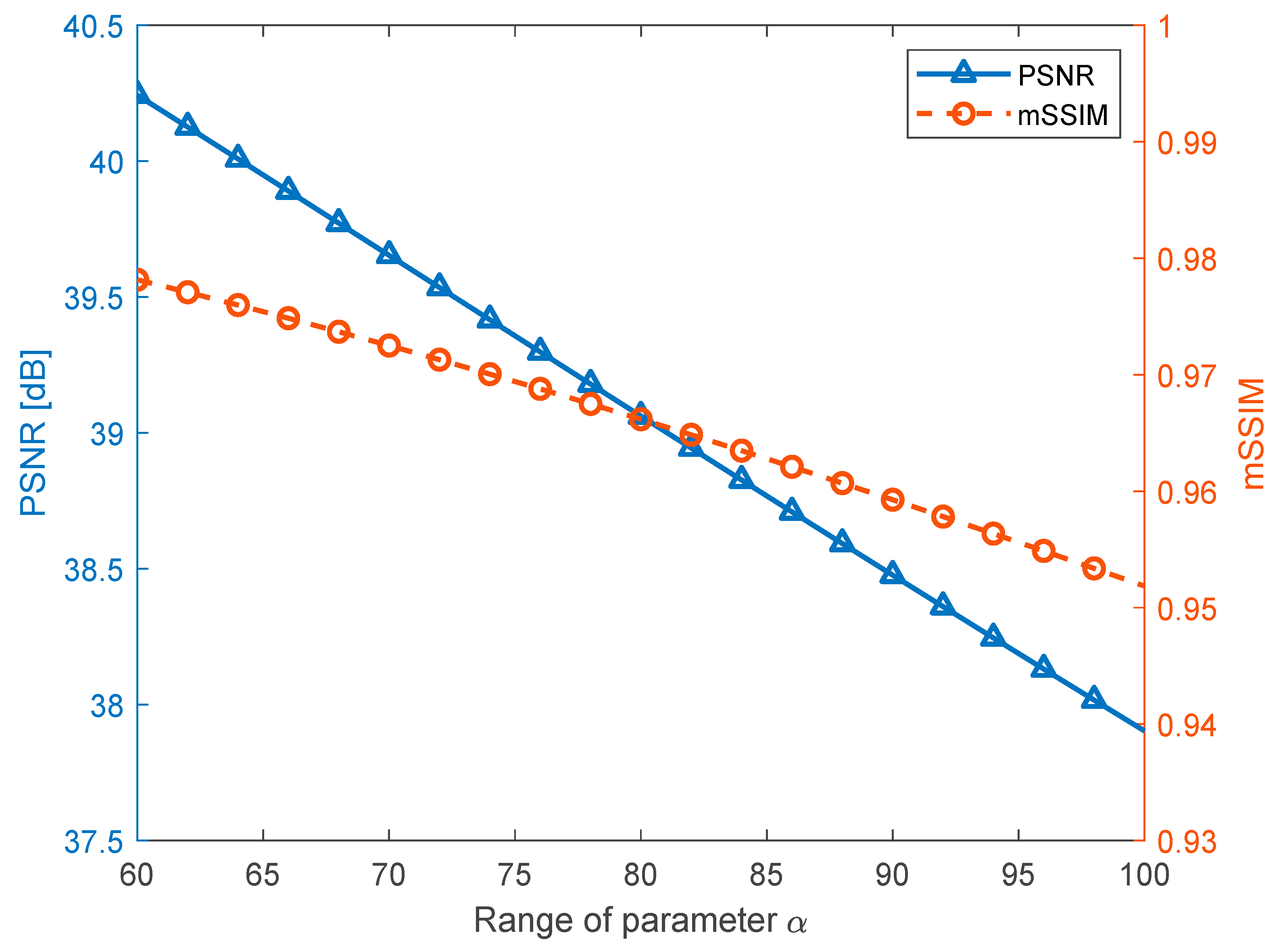
4.3. Watermark Enhancement
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, W.; Zhou, J.; Li, Y.; Cheung, M.; She, J. Robust High-Capacity Watermarking Over Online Social Network Shared Images. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1208–1221. [Google Scholar] [CrossRef]
- Lu, H.; Zhang, M.; Xu, X.; Li, Y.; Shen, H.T. Deep Fuzzy Hashing Network for Efficient Image Retrieval. IEEE Trans. Fuzzy Syst. 2021, 29, 166–176. [Google Scholar] [CrossRef]
- Rakhmawati, L.; Wirawan, W.; Suwadi, S. A recent survey of self-embedding fragile watermarking scheme for image authentication with recovery capability. EURASIP J. Image Video Process. 2019, 2019, 61. [Google Scholar] [CrossRef]
- Wang, F.-H.; Pan, J.-S.; Jain, L.C. Innovations in digital watermarking techniques. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; Volume 232. [Google Scholar]
- Pan, J.-S.; Huang, H.-C.; Jain, L.C. Intelligent watermarking techniques. In Series on Innovative Intelligence; World Scientific: River Edge, NJ, USA, 2004; Volume 7. [Google Scholar]
- Singh, O.P.; Singh, A.K.; Srivastava, G.; Kumar, N. Image watermarking using soft computing techniques: A comprehensive survey. Multimed. Tools Appl. 2020, 80, 30367–30398. [Google Scholar] [CrossRef]
- Urvoy, M.; Goudia, D.; Autrusseau, F. Perceptual DFT Watermarking With Improved Detection and Robustness to Geometrical Distortions. IEEE Trans Inf. Forensics Secur. 2014, 9, 1108–1119. [Google Scholar] [CrossRef]
- Hsu, L.-Y.; Hu, H.-T. Blind watermarking for color images using EMMQ based on QDFT. Expert Syst. Appl. 2020, 149, 113225. [Google Scholar] [CrossRef]
- Zhang, X.; Su, Q.; Yuan, Z.; Liu, D. An efficient blind color image watermarking algorithm in spatial domain combining discrete Fourier transform. Optik 2020, 219, 165272. [Google Scholar] [CrossRef]
- Hu, H.-T.; Hsu, L.-Y. Collective blind image watermarking in DWT-DCT domain with adaptive embedding strength governed by quality metrics. Multimed. Tools Appl. 2017, 76, 6575–6594. [Google Scholar] [CrossRef]
- Huynh-The, T.; Banos, O.; Lee, S.; Yoon, Y.; Le-Tien, T. Improving digital image watermarking by means of optimal channel selection. Expert Syst. Appl. 2016, 62, 177–189. [Google Scholar] [CrossRef]
- Barni, M.; Bartolini, F.; Piva, A. Improved wavelet-based watermarking through pixel-wise masking. IEEE Trans Image Process. 2001, 10, 783–791. [Google Scholar] [CrossRef]
- Wang, J.; Du, Z. A method of processing color image watermarking based on the Haar wavelet. J. Vis. Commun. Image Represent. 2019, 64, 102627. [Google Scholar] [CrossRef]
- Hsu, L.-Y.; Hu, H.-T. Robust blind image watermarking using crisscross inter-block prediction in the DCT domain. J. Vis. Commun. Image Represent. 2017, 46 (Suppl. C), 33–47. [Google Scholar] [CrossRef]
- Singh, S.P.; Bhatnagar, G. A new robust watermarking system in integer DCT domain. J. Vis. Commun. Image Represent. 2018, 53, 86–101. [Google Scholar] [CrossRef]
- Moosazadeh, M.; Ekbatanifard, G. A new DCT-based robust image watermarking method using teaching-learning-Based optimization. J. Inf. Secur. Appl. 2019, 47, 28–38. [Google Scholar] [CrossRef]
- Patra, J.C.; Phua, J.E.; Bornand, C. A novel DCT domain CRT-based watermarking scheme for image authentication surviving JPEG compression. Digit. Signal Process. 2010, 20, 1597–1611. [Google Scholar] [CrossRef]
- Hu, H.-T.; Hsu, L.-Y.; Lee, T.-T. All-round improvement in DCT-based blind image watermarking with visual enhancement via denoising autoencoder. Comput. Electr. Eng. 2022, 100, 107845. [Google Scholar] [CrossRef]
- Ali, M.; Ahn, C.W.; Pant, M.; Siarry, P. An image watermarking scheme in wavelet domain with optimized compensation of singular value decomposition via artificial bee colony. Inf. Sci. 2015, 301, 44–60. [Google Scholar] [CrossRef]
- Chang, C.-C.; Tsai, P.; Lin, C.-C. SVD-based digital image watermarking scheme. Pattern Recognit. Lett. 2005, 26, 1577–1586. [Google Scholar] [CrossRef]
- Hsu, C.-S.; Tu, S.-F. Enhancing the robustness of image watermarking against cropping attacks with dual watermarks. Multimed. Tools Appl. 2020, 79, 11297–11323. [Google Scholar] [CrossRef]
- Koley, S. Visual attention model based dual watermarking for simultaneous image copyright protection and authentication. Multimed. Tools Appl. 2021, 80, 6755–6783. [Google Scholar] [CrossRef]
- Hsu, L.-Y.; Hu, H.-T.; Chou, H.-H. A high-capacity QRD-based blind color image watermarking algorithm incorporated with AI technologies. Expert Syst. Appl. 2022, 199, 117134. [Google Scholar] [CrossRef]
- Liu, D.; Su, Q.; Yuan, Z.; Zhang, X. A color watermarking scheme in frequency domain based on quaternary coding. Vis. Comput. 2021, 37, 2355–2368. [Google Scholar] [CrossRef]
- Hu, H.-T.; Hsu, L.-Y. Exploring DWT–SVD–DCT feature parameters for robust multiple watermarking against JPEG and JPEG2000 compression. Comput. Electr. Eng. 2015, 41, 52–63. [Google Scholar] [CrossRef]
- Abadi, R.Y.; Moallem, P. Robust and optimum color image watermarking method based on a combination of DWT and DCT. Optik 2022, 261, 169146. [Google Scholar] [CrossRef]
- Su, Q.; Wang, H.; Liu, D.; Yuan, Z.; Zhang, X. A combined domain watermarking algorithm of color image. Multimed. Tools Appl. 2020, 79, 30023–30043. [Google Scholar] [CrossRef]
- Islam, M.; Roy, A.; Laskar, R.H. SVM-based robust image watermarking technique in LWT domain using different sub-bands. Neural Comput. Appl. 2020, 32, 1379–1403. [Google Scholar] [CrossRef]
- Maloo, S.; Kumar, M.; Lakshmi, N. A modified whale optimization algorithm based digital image watermarking approach. Sens. Imaging 2020, 21, 26. [Google Scholar] [CrossRef]
- Liu, D.; Su, Q.; Yuan, Z.; Zhang, X. A fusion-domain color image watermarking based on Haar transform and image correction. Expert Syst. Appl. 2021, 170, 114540. [Google Scholar] [CrossRef]
- Yuan, Z.; Su, Q.; Liu, D.; Zhang, X.; Yao, T. Fast and robust image watermarking method in the spatial domain. IET Image Process. 2020, 14, 3829–3838. [Google Scholar] [CrossRef]
- Chen, S.; Su, Q.; Wang, H.; Wang, G. A high-efficiency blind watermarking algorithm for double color image using Walsh Hadamard transform. Vis. Comput. 2022, 38, 2189–2205. [Google Scholar] [CrossRef]
- Rao, K.R.; Yip, P. Discrete Cosine Transform: Algorithms, Advantages, Applications; Academic Press Professional, Inc.: Cambridge, MA, USA, 1990. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; Shi, W. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Arnold, V.I.; Avez, A. Ergodic problems of classical mechanics. In The Mathematical Physics Monograph Series; Benjamin: New York, NY, USA, 1968. [Google Scholar]
- USC-SIPI. University of Southern California—Signal and Image Processing Institute. Image Database. 1997. Available online: http://sipi.usc.edu/database (accessed on 22 December 2022).
- CVG-UGR Image Database. Computer Vision Group, University of Granada. Available online: https://ccia.ugr.es/cvg/dbimagenes/ (accessed on 22 December 2022).
- Grubinger, M.; Clough, P.D.; Müller, H.; Deselaers, T. The IAPR TC-12 Benchmark: A New Evaluation Resource for Visual Information Systems. In Proceedings of the International Conference on Language Resources and Evaluation, Genoa, Italy, 24–26 May 2006. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 658–666. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR [dB] | mSSIM |
|---|---|---|
| DCT-MGA | 38.48 [1.50] | 0.959 [0.021] |
| QRMM22 | 37.98 [0.67] | 0.953 [0.013] |
| WHT21 | 34.78 [2.10] | 0.958 [0.004] |
| Haar21 | 36.86 [0.32] | 0.931 [0.028] |
| Schur21 | 36.30 [0.17] | 0.940 [0.023] |
| DCT20 | 32.09 [2.18] | 0.944 [0.008] |
| DWT20 | 36.13 [0.24] | 0.925 [0.026] |
| DFT20 | 32.61 [2.29] | 0.956 [0.009] |
| Item | Type | Description |
|---|---|---|
| A | JPEG compression | Apply the JPEG compression to the test image with the quality factor (QF) chosen from {80, 40}. |
| B | JPEG2000 compression | Apply the JPEG2000 compression to the test image with the compression ratio (CR) chosen from {4,8}. |
| C | Gaussian noise corruption | Corrupt the test image using Gaussian noise with the variance set as 0.001 of the full scale. |
| D | Salt-and-pepper noise corruption | Corrupt the test image using the salt-and-pepper noise with 1% intensity. |
| E | Speckle noise corruption | Add the multiplicative noise with a variance of 0.01 to the test image |
| F | Median filtering | Apply a median filter with a 3 × 3 mask to the test image. |
| G | Lowpass filtering | Apply a Gaussian filter with a 3 × 3 mask to the test image. |
| H | Unsharp filtering | Apply an unsharp filter with a 3 × 3 mask to the test image. |
| I | Wiener filtering | Apply a Wiener filter with a 3 × 3mask to the test image. |
| J | Histogram equalization | Enhance the contrast of the test image using histogram equalization. |
| K | Rescaling restoration | Shrink the test image from 512 × 512 to 256 × 256 pixels. |
| L | Rotation restoration | Rotate the test image counterclockwise by 45°. |
| M | Cropping (I) | Crop 25% of the test image on the upper-left corner. |
| N | Cropping (II) | Crop 25% of the test image on the left side. |
| O | Brightening | Add 20 to each pixel value of the test image. |
| P | Darkening | Subtract 20 from each pixel value of the test image. |
| Method | DCT-MGA | QRMM22 | WHT22 | Haar21 | Schur21 | DCT20 | DWT20 | DFT20 | |
|---|---|---|---|---|---|---|---|---|---|
| Attack | |||||||||
| None | 1.000 | 1.000 | 0.962 | 0.958 | 0.933 | 1.000 | 1.000 | 1.000 | |
| A.1/QF = 80 | 0.334 | 0.131 | 0.192 | 0.119 | 0.216 | 0.190 | 0.301 | 0.117 | |
| A.2/QF = 40 | 0.315 | 0.039 | 0.049 | 0.019 | 0.074 | 0.083 | 0.143 | 0.061 | |
| B.1/CR = 4 | 0.931 | 0.823 | 0.798 | 0.659 | 0.753 | 0.632 | 0.919 | 0.370 | |
| B.2/CR = 8 | 0.749 | 0.418 | 0.413 | 0.304 | 0.438 | 0.330 | 0.648 | 0.207 | |
| C | 0.794 | 0.205 | 0.479 | 0.021 | 0.335 | 0.415 | 0.535 | 0.307 | |
| D | 0.669 | 0.980 | 0.891 | 0.920 | 0.757 | 0.920 | 0.914 | 0.901 | |
| E | 0.701 | 0.266 | 0.473 | 0.136 | 0.307 | 0.445 | 0.415 | 0.328 | |
| F | 0.646 | 0.097 | 0.015 | 0.065 | 0.349 | 0.341 | 0.460 | 0.276 | |
| G | 0.977 | 0.724 | 0.754 | 0.660 | 0.769 | 0.653 | 0.927 | 0.422 | |
| H | 0.869 | −0.035 | 0.839 | −0.018 | −0.007 | 0.754 | −0.081 | 0.649 | |
| I | 0.793 | 0.133 | 0.086 | 0.213 | 0.392 | 0.335 | 0.528 | 0.219 | |
| J | 0.845 | 0.560 | 0.911 | −0.031 | 0.004 | 0.867 | −0.006 | 0.576 | |
| K | 0.792 | 0.248 | 0.110 | 0.359 | 0.559 | 0.396 | 0.651 | 0.255 | |
| L | 0.901 | 0.564 | 0.569 | 0.458 | 0.607 | 0.507 | 0.776 | 0.322 | |
| M | 0.800 | 0.760 | 0.762 | 0.760 | 0.732 | 0.785 | 0.785 | 0.785 | |
| N | 0.798 | 0.760 | 0.758 | 0.755 | 0.740 | 0.786 | 0.786 | 0.786 | |
| O | 0.990 | 0.988 | 0.953 | 0.304 | 0.044 | 0.988 | 0.985 | 0.986 | |
| P | 0.913 | 0.897 | 0.917 | 0.262 | 0.053 | 0.913 | 0.896 | 0.898 | |
 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, H.-T.; Hsu, L.-Y.; Wu, S.-T. Blind Watermarking for Hiding Color Images in Color Images with Super-Resolution Enhancement. Sensors 2023, 23, 370. https://doi.org/10.3390/s23010370
Hu H-T, Hsu L-Y, Wu S-T. Blind Watermarking for Hiding Color Images in Color Images with Super-Resolution Enhancement. Sensors. 2023; 23(1):370. https://doi.org/10.3390/s23010370
Chicago/Turabian StyleHu, Hwai-Tsu, Ling-Yuan Hsu, and Shyi-Tsong Wu. 2023. "Blind Watermarking for Hiding Color Images in Color Images with Super-Resolution Enhancement" Sensors 23, no. 1: 370. https://doi.org/10.3390/s23010370
APA StyleHu, H.-T., Hsu, L.-Y., & Wu, S.-T. (2023). Blind Watermarking for Hiding Color Images in Color Images with Super-Resolution Enhancement. Sensors, 23(1), 370. https://doi.org/10.3390/s23010370