
STC-NLSTMNet: An Improved Human Activity Recognition Method Using Convolutional Neural Network with NLSTM from WiFi CSI

 , ,
, ,
Abstract
1. Introduction
- We propose a DL-based model (STC-NLSTMNet) which utilizes both features (spatial and temporal) simultaneously and automatically recognizes human activity with very high accuracy.
- In the STC-NLSTMNet model, DS-Conv extracts spatial features, FAM focuses on the most relevant spatial features, and NLSTM explores the hidden inherent temporal features. Thus, the representation capability of the STC-NLSTMNet model is improved to accurately recognize human activity.
- The proposed system is versatile and needs minimal preprocessing of the CSI data or feature engineering, which makes it easy to extend to other activity recognition datasets.
2. Related Work
2.1. Wearable-Based HAR
2.2. Non-Wearable-Based HAR
2.2.1. Vision-Based HAR
2.2.2. Radar-Based HAR
2.2.3. Ultrasonic Sensor-Based HAR
2.2.4. WiFi-Based HAR
3. Background of CSI
4. Dataset
4.1. Multi-Environment
4.2. StanWiFi Dataset
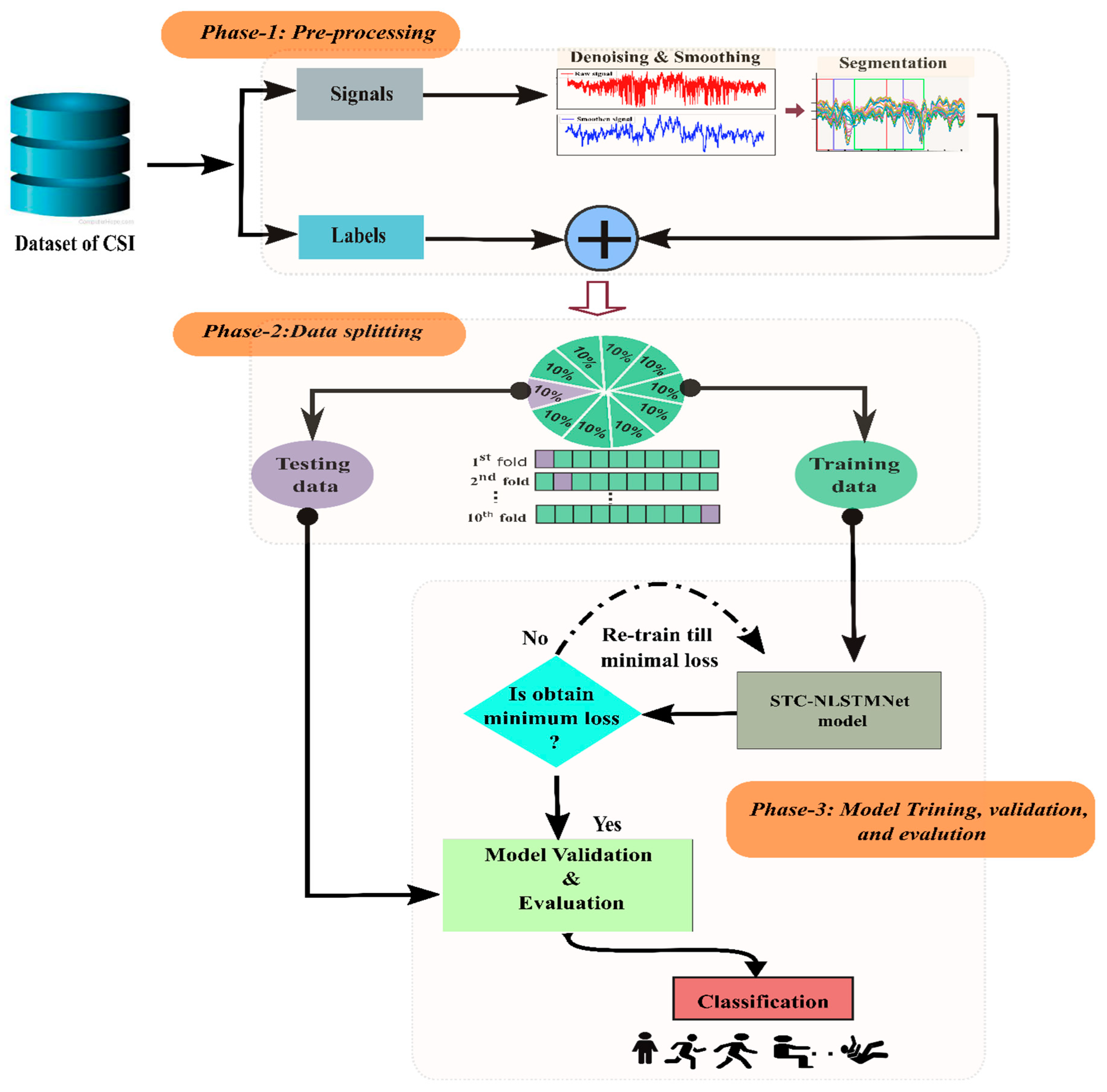
5. Proposed Methodology
5.1. Data Preprocessing
5.2. STC-NLSTMNet
5.2.1. Depthwise Separable Convolutional Block (DS-Conv)
5.2.2. Feature Attention Module (FAM)
5.2.3. Nested Long Short-Term Memory (NLSTM)
5.3. Training of STC-NLSTMNet Model
6. Results and Discussion
6.1. Experimental Results on StanWiFi Dataset
6.2. Experimental Result on Multi-Enviroment Dataset
6.3. Performance Comparison
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kalimuthu, S.; Perumal, T.; Yaakob, R.; Marlisah, E.; Babangida, L. Human Activity Recognition based on smart home environment and their applications, challenges. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 815–819. [Google Scholar] [CrossRef]
- Ahad, M.A. Activity recognition for health-care and related works. In Proceedings of the 2018 ACM International Joint Conference and International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018. [Google Scholar]
- Bocus, M.J.; Li, W.; Vishwakarma, S.; Kou, R.; Tang, C.; Woodbridge, K.; Craddock, I.; McConville, R.; Santos-Rodriguez, R.; Chetty, K.; et al. OPERAnet, a multimodal activity recognition dataset acquired from radio frequency and vision-based sensors. Sci. Data 2022, 9, 474. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. 2011, 43, 16. [Google Scholar] [CrossRef]
- Uddin, M.H.; Ara, J.M.; Rahman, M.H.; Yang, S.H. A Study of Real-Time Physical Activity Recognition from Motion Sensors via Smartphone Using Deep Neural Network. In Proceedings of the 2021 5th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 17–19 December 2021. [Google Scholar]
- Li, X.; He, Y.; Jing, X. A survey of deep learning-based human activity recognition in radar. Remote Sens. 2019, 11, 1068. [Google Scholar] [CrossRef]
- Shafiqul, I.M.; Jannat, M.K.; Kim, J.W.; Lee, S.W.; Yang, S.H. HHI-AttentionNet: An Enhanced Human-Human Interaction Recognition Method Based on a Lightweight Deep Learning Model with Attention Network from CSI. Sensors 2022, 22, 6018. [Google Scholar] [CrossRef] [PubMed]
- Kabir, M.H.; Rahman, M.H.; Shin, W. CSI-IANet: An Inception Attention Network for Human-Human Interaction Recognition Based on CSI Signal. IEEE Access 2021, 9, 166624–166638. [Google Scholar] [CrossRef]
- Su, J.; Liao, Z.; Sheng, Z.; Liu, A.X.; Singh, D.; Lee, H.N. Human activity recognition using self-powered sensors based on multilayer bi-directional long short-term memory networks. IEEE Sens. J. 2022. Early Access. [Google Scholar] [CrossRef]
- Li, H.; He, X.; Chen, X.; Fang, Y.; Fang, Q. Wi-motion: A robust human activity recognition using WiFi signals. IEEE Access 2019, 7, 153287–153299. [Google Scholar] [CrossRef]
- Youssef, M.; Mah, M.; Agrawala, A. Challenges: Device-free passive localization for wireless environments. In Proceedings of the 13th Annual ACM international Conference on Mobile Computing and Networking, New Orleans, LA, USA, 25–29 October 2007; pp. 222–229. [Google Scholar]
- Hoang, M.T.; Yuen, B.; Dong, X.; Lu, T.; Westendorp, R.; Reddy, K. Recurrent neural networks for accurate RSSI indoor localization. IEEE Internet Things J. 2019, 6, 10639–10651. [Google Scholar] [CrossRef]
- Mohamed, S.E. Why the Accuracy of the Received Signal Strengths as a Positioning Technique was not accurate? Int. J. Wirel. Mob. Netw. 2011, 3, 69–82. [Google Scholar] [CrossRef]
- Wang, G.; Zou, Y.; Zhou, Z.; Wu, K.; Ni, L.M. We can hear you with Wi-Fi! IEEE Trans. Mob. Comput. 2016, 15, 2907–2920. [Google Scholar] [CrossRef]
- Ren, Y.; Wang, Z.; Wang, Y.; Tan, S.; Chen, Y.; Yang, J. 3D Human Pose Estimation Using WiFi Signals. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, Coimbra, Portugal, 15–17 November 2021; pp. 363–364. [Google Scholar]
- Guo, Z.; Xiao, F.; Sheng, B.; Fei, H.; Yu, S. WiReader: Adaptive air handwriting recognition based on commercial WiFi signal. IEEE Internet Things J. 2020, 7, 10483–10494. [Google Scholar] [CrossRef]
- Han, C.; Wu, K.; Wang, Y.; Ni, L.M. WiFall: Device-free fall detection by wireless networks. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 271–279. [Google Scholar] [CrossRef]
- Fard Moshiri, P.; Shahbazian, R.; Nabati, M.; Ghorashi, S.A. A CSI-Based Human Activity Recognition Using Deep Learning. Sensors 2021, 21, 7225. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI based passive human activity recognition using attention-based BLSTM. IEEE Trans. Mob. Comput. 2018, 18, 2714–2724. [Google Scholar] [CrossRef]
- Cui, W.; Li, B.; Zhang, L.; Chen, Z. Device-free single-user activity recognition using diversified deep ensemble learning. Appl. Soft Comput. 2021, 102, 107066. [Google Scholar] [CrossRef]
- Khalifa, S.; Lan, G.; Hassan, M.; Seneviratne, A.; Das, S.K. HARKE: Human Activity Recognition from Kinetic Energy Harvesting Data in Wearable Devices. IEEE Trans. Mob. Comput. 2018, 17, 1353–1368. [Google Scholar] [CrossRef]
- Zubair, M.; Song, K.; Yoon, C. Human activity recognition using wearable accelerometer sensors. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Republic of Korea, 26–28 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable computing: Accelerometers’ data classification of body postures and movements. In Brazilian Symposium on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 52–61. [Google Scholar]
- Badawi, A.A.; Al-Kabbany, A.; Shaban, H. Multimodal human activity recognition from wearable inertial sensors using machine learning. In Proceedings of the 2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES), Sarawak, Malaysia, 3–6 December 2018; pp. 402–407. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Ji, X.; Cheng, J.; Feng, W.; Tao, D. Skeleton embedded motion body partition for human action recognition using depth sequences. Signal Process. 2018, 143, 56–68. [Google Scholar] [CrossRef]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar] [CrossRef]
- Karayaneva, Y.; Sharifzadeh, S.; Li, W.; Jing, Y.; Tan, B. Unsupervised Doppler Radar Based Activity Recognition for e-Healthcare. IEEE Access 2021, 9, 62984–63001. [Google Scholar] [CrossRef]
- Kim, W.Y.; Seo, D.H. Radar-Based Human Activity Recognition Combining Range–Time–Doppler Maps and Range-Distributed-Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1002311. [Google Scholar] [CrossRef]
- Franceschini, S.; Ambrosanio, M.; Vitale, S.; Baselice, F.; Gifuni, A.; Grassini, G.; Pascazio, V. Hand gesture recognition via radar sensors and convolutional neural networks. In Proceedings of the 2020 IEEE Radar Conference, Florence, Italy, 21–25 September 2020. [Google Scholar]
- Ghosh, A.; Sanyal, A.; Chakraborty, A.; Sharma, P.K.; Saha, M.; Nandi, S.; Saha, S. On automatizing recognition of multiple human activities using ultrasonic sensor grid. In Proceedings of the 2017 9th International Conference on Communication Systems and Networks (COMSNETS), Bengaluru, India, 4–8 January 2017. [Google Scholar]
- Hori, T.; Nishida, Y. Ultrasonic sensors for the elderly and caregivers in a nursing home. In Proceedings of the ICEIS, Miami, FL, USA, 25–28 May 2005; pp. 110–115. [Google Scholar]
- Xiong, J.; Li, F.; Liu, J. Fusion of different height pyroelectric infrared sensors for person identification. IEEE Sens. J. 2016, 16, 436–446. [Google Scholar] [CrossRef]
- Sigg, S.; Blanke, U.; Tröster, G. The telepathic phone: Frictionless activity recognition from WiFi-RSSI. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communications (PerCom), Budapest, Hungary, 24–28 March 2014; pp. 148–155. [Google Scholar] [CrossRef]
- Gu, Y.; Ren, F.; Li, J. PAWS: Passive Human Activity Recognition Based on WiFi Ambient Signals. IEEE Internet Things J. 2016, 3, 796–805. [Google Scholar] [CrossRef]
- Gu, Y.; Quan, L.; Ren, F. WiFi-assisted human activity recognition. In Proceedings of the 2014 IEEE Asia Pacific Conference on Wireless and Mobile, Bali, Indonesia, 28–30 August 2014; pp. 60–65. [Google Scholar] [CrossRef]
- Sigg, S.; Shi, S.; Buesching, F.; Ji, Y.; Wolf, L. Leveraging RF-channel fluctuation for activity recognition: Active and passive systems, continuous and RSSI-based signal features. In Proceedings of the International Conference on Advances in Mobile Computing & Multimedia, Vienna, Austria, 2–4 December 2013; p. 43. [Google Scholar]
- Wang, F.; Panev, S.; Dai, Z.; Han, J.; Huang, D. Can WiFi estimate person pose? arXiv 2019, arXiv:1904.00277. [Google Scholar]
- Yang, J. A framework for human activity recognition based on WiFi CSI signal enhancement. Int. J. Antennas Propag. 2021, 2021, 6654752. [Google Scholar] [CrossRef]
- Damodaran, N.; Schäfer, J. Device free human activity recognition using WiFi channel state information. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Leicester, UK, 19–23 August 2019; pp. 1069–1074. [Google Scholar]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A survey on behavior recognition using WiFi channel state information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]
- Yadav, S.K.; Sai, S.; Gundewar, A.; Rathore, H.; Tiwari, K.; Pandey, H.M.; Mathur, M. CSITime: Privacy-preserving human activity recognition using WiFi channel state information. Neural Netw. 2022, 146, 11–21. [Google Scholar] [CrossRef]
- Wang, W.; Liu, A.X.; Shahzad, M.; Ling, K.; Lu, S. Device-Free Human Activity Recognition Using Commercial WiFi Devices. IEEE J. Sel. Areas Commun. 2017, 35, 1118–1131. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, Y.; Wang, Y.; Xu, K. WiAct: A passive WiFi-based human activity recognition system. IEEE Sens. J. 2019, 20, 296–305. [Google Scholar] [CrossRef]
- Muaaz, M.; Chelli, A.; Pätzold, M. Wi-Fi-based human activity recognition using convolutional neural network. In Innovative and Intelligent Technology-Based Services for Smart Environments–Smart Sensing and Artificial Intelligence; CRC Press: Boca Raton, FL, USA, 2021; pp. 61–67. [Google Scholar]
- Zhang, J.; Wu, F.; Wei, B.; Zhang, Q.; Huang, H.; Shah, S.W.; Cheng, J. Data augmentation and dense-LSTM for human activity recognition using WiFi signal. IEEE Internet Things J. 2020, 8, 4628–4641. [Google Scholar] [CrossRef]
- Shang, S.; Luo, Q.; Zhao, J.; Xue, R.; Sun, W.; Bao, N. LSTM-CNN network for human activity recognition using WiFi CSI data. J. Phys. Conf. Ser. 2021, 1883, 012139. [Google Scholar] [CrossRef]
- Khan, P.; Reddy, B.S.; Pandey, A.; Kumar, S.; Youssef, M. Differential channel-state-information-based human activity recognition in IoT networks. IEEE Internet Things J. 2020, 7, 11290–11302. [Google Scholar] [CrossRef]
- Alsaify, B.A.; Almazari, M.M.; Alazrai, R.; Alouneh, S.; Daoud, M.I. A CSI-Based Multi-Environment Human Activity Recognition Framework. Appl. Sci. 2022, 12, 930. [Google Scholar] [CrossRef]
- Baha, A.A.; Almazari, M.M.; Alazrai, R.; Daoud, M.I. A dataset for Wi-Fi-based human activity recognition in line-of-sight and non-line-of-sight indoor environments. Data Brief 2020, 33, 106534. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Moniz, J.R.A.; David, K. Nested LSTMs. In Proceedings of the Asian Conference on Machine Learning, PMLR, Seoul, Republic of Korea, 15–17 November 2017. [Google Scholar]
- Islam, M.; Shafiqul, K.T.; Sung-Hyun, Y. Epileptic-Net: An Improved Epileptic Seizure Detection System Using Dense Convolutional Block with Attention Network from EEG. Sensors 2022, 22, 728. [Google Scholar] [CrossRef] [PubMed]
- Salehinejad, H.; Valaee, S. LiteHAR: Lightweight Human Activity Recognition from WIFI Signals with Random Convolution Kernels. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Alsaify, B.A.; Almazari, M.M.; Alazrai, R.; Daoud, M.I. Exploiting Wi-Fi Signals for Human Activity Recognition. In Proceedings of the 2021 12th International Conference on Information and Communication Systems (ICICS), Valencia, Spain, 24–26 May 2021; pp. 245–250. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity Label | Activity Name | Details | Number of Samples |
|---|---|---|---|
| A1 | No movement | Standing still or sitting still or laying down | 7513 |
| A2 | Falling | Falling from a sitting position or standing position | 2405 |
| A3 | Walking | Walking to the transmitter or to the receiver | 2408 |
| A4 | Sitting/Standing | Sitting on a chair or standing from a chair | 1612 |
| A5 | Turning | Turning to the receiver or to the transmitter | 2412 |
| A6 | Pick up | Picking up a pen from the ground | 1421 |
| Activity Name | Number of Samples | Activity Name | Number of Samples |
|---|---|---|---|
| Walk | 4707 | Sit down | 1394 |
| Fall | 1510 | Lay down | 2175 |
| Stand up | 1057 | Run | 3889 |
| Section | Layer Type | Output Shape | Parameters |
|---|---|---|---|
| Spatial-temporal feature extraction | Conv 2D | 256 × 45 × 32 | 320 |
| BN and ReLU | 256 × 45 × 32 | 128 | |
| DS-Conv block | 128 × 23 × 64 | 2816 | |
| FAM | 128 × 23 × 64 | 49 | |
| DS-Conv block | 64 × 12 × 128 | 9728 | |
| FAM | 64 × 12 × 128 | 49 | |
| DS-Conv block | 32 × 6 × 512 | 69,888 | |
| GAP | 1 × 512 | 0 | |
| NLSTM (50) | 512 × 50 | 30,600 | |
| TDFC (20) | 512 × 20 | 1020 | |
| Recognition | GAP | 1 × 20 | 0 |
| FC(20) | 1 × 20 | 420 | |
| Softmax | 1 × 6 | 126 |
| Scenario’s | Metrics | Fold | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | 10th | |||
| StanWiFi | Accuracy | 99.86 | 99.86 | 99.93 | 99.89 | 99.83 | 99.86 | 100 | 99.89 | 99.90 | 99.80 | 99.88 |
| Precision | 99.66 | 99.81 | 99.9 | 99.85 | 99.79 | 98.99 | 99.82 | 99.79 | 99.85 | 99.73 | 99.72 | |
| Recall | 99.79 | 99.76 | 99.86 | 99.81 | 99.8 | 99.25 | 99.75 | 99.81 | 99.79 | 99.68 | 99.73 | |
| F1-score | 99.72 | 99.78 | 99.88 | 99.83 | 99.79 | 99.12 | 99.78 | 99.80 | 99.82 | 99.71 | 99.72 | |
| Scenario’s | Metrics | Fold | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | 10th | |||
| E1 | Accuracy | 98.49 | 98.32 | 97.93 | 98.21 | 97.93 | 98.17 | 97.99 | 98.35 | 97.96 | 98.67 | 98.20 |
| Precision | 98.35 | 98.29 | 97.79 | 98.05 | 97.86 | 98.13 | 97.87 | 98.31 | 97.74 | 98.62 | 98.10 | |
| Recall | 98.39 | 98.25 | 97.84 | 98.09 | 97.85 | 98.03 | 97.86 | 98.28 | 97.71 | 98.58 | 98.08 | |
| F1-score | 98.37 | 98.27 | 97.82 | 98.07 | 97.86 | 98.08 | 97.87 | 98.30 | 97.73 | 98.60 | 98.09 | |
| E2 | Accuracy | 96.47 | 96.86 | 96.82 | 95.91 | 96.86 | 96.04 | 97.04 | 97.04 | 96.91 | 96.56 | 96.65 |
| Precision | 96.44 | 96.71 | 96.76 | 95.82 | 96.79 | 95.93 | 97.00 | 96.94 | 96.69 | 96.36 | 96.54 | |
| Recall | 96.41 | 96.73 | 96.72 | 95.87 | 96.36 | 95.78 | 95.95 | 97.01 | 96.85 | 96.46 | 96.41 | |
| F1-score | 96.43 | 96.72 | 96.74 | 95.85 | 96.57 | 95.85 | 96.47 | 96.97 | 96.77 | 96.41 | 96.48 | |
| Scenario’s | Metrics | Fold | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | 10th | |||
| E3 | Accuracy | 94.68 | 94.28 | 94.00 | 94.73 | 93.83 | 95.00 | 94.28 | 95.63 | 95.29 | 95.12 | 94.68 |
| Precision | 94.53 | 94.19 | 93.92 | 94.65 | 93.79 | 94.89 | 94.13 | 95.45 | 95.13 | 95.02 | 94.57 | |
| Recall | 94.54 | 94.21 | 93.88 | 94.55 | 93.75 | 94.76 | 94.11 | 95.45 | 95.23 | 95.01 | 94.55 | |
| F1-score | 94.53 | 94.2 | 93.9 | 94.60 | 93.77 | 94.82 | 94.12 | 95.45 | 95.18 | 95.02 | 94.56 | |
| Dataset | Study | Environment | Method and Year | Metrics (%) | |||
|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | ||||
| StanWiFi | Yousefi et al. [41] | LOS | LSTM (2017) | 90.5 | --- | --- | --- |
| Chen et al. [19] | ABLSTM (2018) | 97.3 | --- | --- | --- | ||
| Santosh et al. [42] | CSITime (2022) | 98.00 | 99.16 | 98.87 | 99.01 | ||
| Shahrokh et al. [54] | LiteHAR (2022) | 93.00 | --- | --- | --- | ||
| proposed | STC-NLSTMNet | 99.88 | 99.72 | 99.73 | 99.872 | ||
| Multi-environment | Alsaify et al. [49] | LOS (E1) | SVM (2022) | 91.27 | --- | --- | --- |
| Alsaify et al. [55] | SVM (2021) | 94.03 | --- | --- | --- | ||
| proposed | STC-NLSTMNet | 98.20 | 98.10 | 98.08 | 98.09 | ||
| Alsaify et al. [49] | LOS (E2) | SVM (2022) | 86.53 | --- | --- | --- | |
| Alsaify et al. [55] | SVM (2021) | 89.07 | --- | --- | --- | ||
| proposed | STC-NLSTMNet | 96.65 | 96.54 | 96.41 | 96.48 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.S.; Jannat, M.K.A.; Hossain, M.N.; Kim, W.-S.; Lee, S.-W.; Yang, S.-H. STC-NLSTMNet: An Improved Human Activity Recognition Method Using Convolutional Neural Network with NLSTM from WiFi CSI. Sensors 2023, 23, 356. https://doi.org/10.3390/s23010356
Islam MS, Jannat MKA, Hossain MN, Kim W-S, Lee S-W, Yang S-H. STC-NLSTMNet: An Improved Human Activity Recognition Method Using Convolutional Neural Network with NLSTM from WiFi CSI. Sensors. 2023; 23(1):356. https://doi.org/10.3390/s23010356
Chicago/Turabian StyleIslam, Md Shafiqul, Mir Kanon Ara Jannat, Mohammad Nahid Hossain, Woo-Su Kim, Soo-Wook Lee, and Sung-Hyun Yang. 2023. "STC-NLSTMNet: An Improved Human Activity Recognition Method Using Convolutional Neural Network with NLSTM from WiFi CSI" Sensors 23, no. 1: 356. https://doi.org/10.3390/s23010356
APA StyleIslam, M. S., Jannat, M. K. A., Hossain, M. N., Kim, W.-S., Lee, S.-W., & Yang, S.-H. (2023). STC-NLSTMNet: An Improved Human Activity Recognition Method Using Convolutional Neural Network with NLSTM from WiFi CSI. Sensors, 23(1), 356. https://doi.org/10.3390/s23010356