

Efficient Transformer-Based Compressed Video Modeling via Informative Patch Selection


Abstract
1. Introduction
2. Related Works
3. Methodology
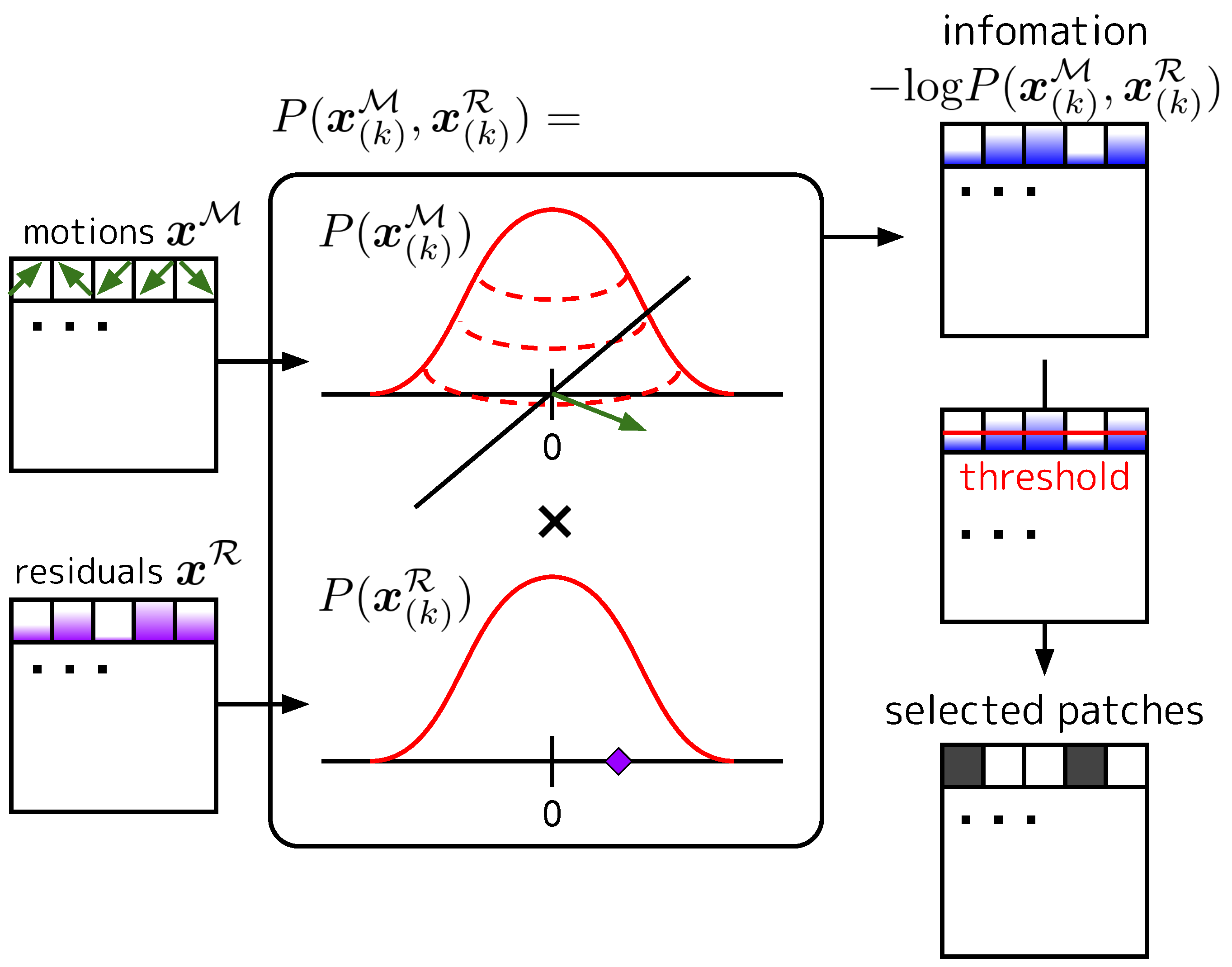
3.1. Preliminary: Motions and Residuals
3.2. Overview of Modeling
3.2.1. Original TimeSformer
3.2.2. TimeSformer with P-Frames as Motions and Residuals
3.2.3. TimeSformer with IPS
3.3. Impact of Reducing Input Patches on Inference Cost of TimeSformer
| Algorithm 1: PyTorch-like pseudocode of a Transformer block with axis attention (spatial) and IPS. Lists of numbers in parentheses in comments indicate the shapes of tensors. |
# Inputs: # T: number of time indexes # S: number of space indexes # D: number of channels # z_prev: embeddings of elements from the previous Transformer block (T*S+1, D) # mask: mask of elements. False if selected by IPS else True (T*S) # initialize embedding (z) for spatial axis attention z = z_prev z_cls = z[:1].unsqueeze(0).expand(T, -1, -1)# (T, 1 ,D) z_patch = z[1:].reshape(T, S, D)# (T, S ,D) z = concat(z_cls, z_patch), axis=1)# (T, S+1 ,D) # reshape mask and pad it for classification token mask = concat(zeros([T, 1], dtype=bool), mask.reshape(T, S), axis=1) # (T, S+1) # get selected (not masked) indices ind = where(not mask) # — element-wise calculation — # calculate query, key and value for only selected indices q, k, v = zeros([T, S+1, D]), zeros([T, S+1, D]), zeros([T, S+1, D]) q[ind], k[ind], v[ind] = fc_q(z[ind]), fc_k(z[ind]), fc_v(z[ind]) # — attention matrix calculation — # calculate attention matrix ”in parallel” along temporal-axis (axis=0) attn = (q @ k.transpose()) / scale# (T, S+1, S+1) mask = mask.unsqueeze(1).expand(-1, S+1, -1)# (T, S+1, S+1) attn = attn.masked_fill(mask=mask, value=float(’-inf’)) attn = softmax(attn, axis=1) z = attn @ v# (T, S+1 ,D) # — element-wise calculation — # postprocess z = fc(z) z_cls = mean(z[:, :1], axis=1)# averaging along temporal-axis z = concat(z_cls, z[:, 1:]) z += z_prev z = MLP(LayerNorm(z)) z_prev = z |
3.4. Informative Patch Selection (IPS)
3.4.1. P-Frame Accumulation
4. Experiments
4.1. Setups
4.1.1. Datasets and Evaluation
- HMDB-51 [50] contains 3570 videos for training and 1530 videos for validation; they are labeled according to 51 action classes. The average duration of the videos is approximately 3.1 s.
- Something-Something V2 (SSv2) [51] includes 168.9k videos for training and 24.7k videos for validation; they are labeled according to 174 classes. The average duration of the videos is approximately 3.8 s.
4.1.2. Model and IPS Implementation
4.1.3. Preprocess and Training
4.1.4. Baselines of Patch Selection
- Uniform space (uni space): The spatial indices of patches were sampled uniformly at equal intervals, and the patches with those spatial indices were excluded from the input in all the frames.
- Uniform time (uni time): The time indices of patches were sampled uniformly at equal intervals, and all patches in those time indices were excluded from the input.
- Uniform (uni): The spatiotemporal indices of the patches were randomly selected according to a uniform distribution and excluded from the input. Compared to uni space, the range of spatial indices that can be covered tended to be larger, because different spatial indices were allowed to be selected at different time indices. Similarly, compared to uni time, the range of time indices that could be covered tended to be larger.
- Frame subtraction (sub): Patches were selected if the average absolute subtraction from the previous frame was greater than or equal to a threshold value.
4.2. Effectiveness of IPS for Each Attention Type
4.3. Ablation Study
4.3.1. Input Modalities
4.3.2. P-Frame Accumulation
4.3.3. Residuals
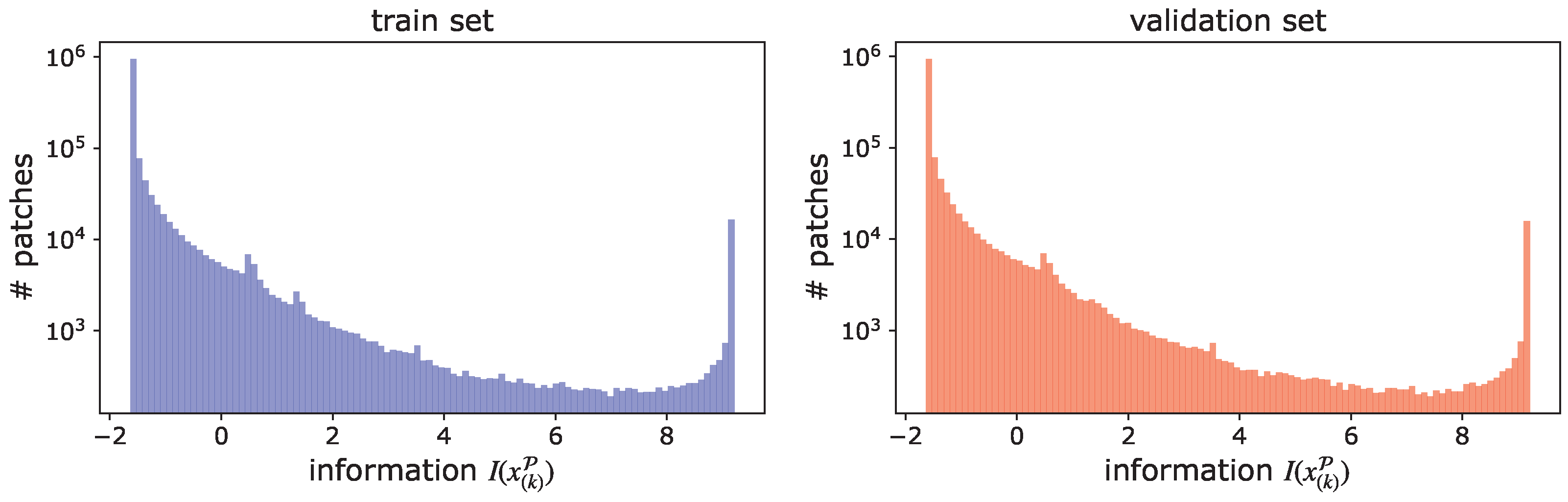
4.3.4. Distribution Fitting
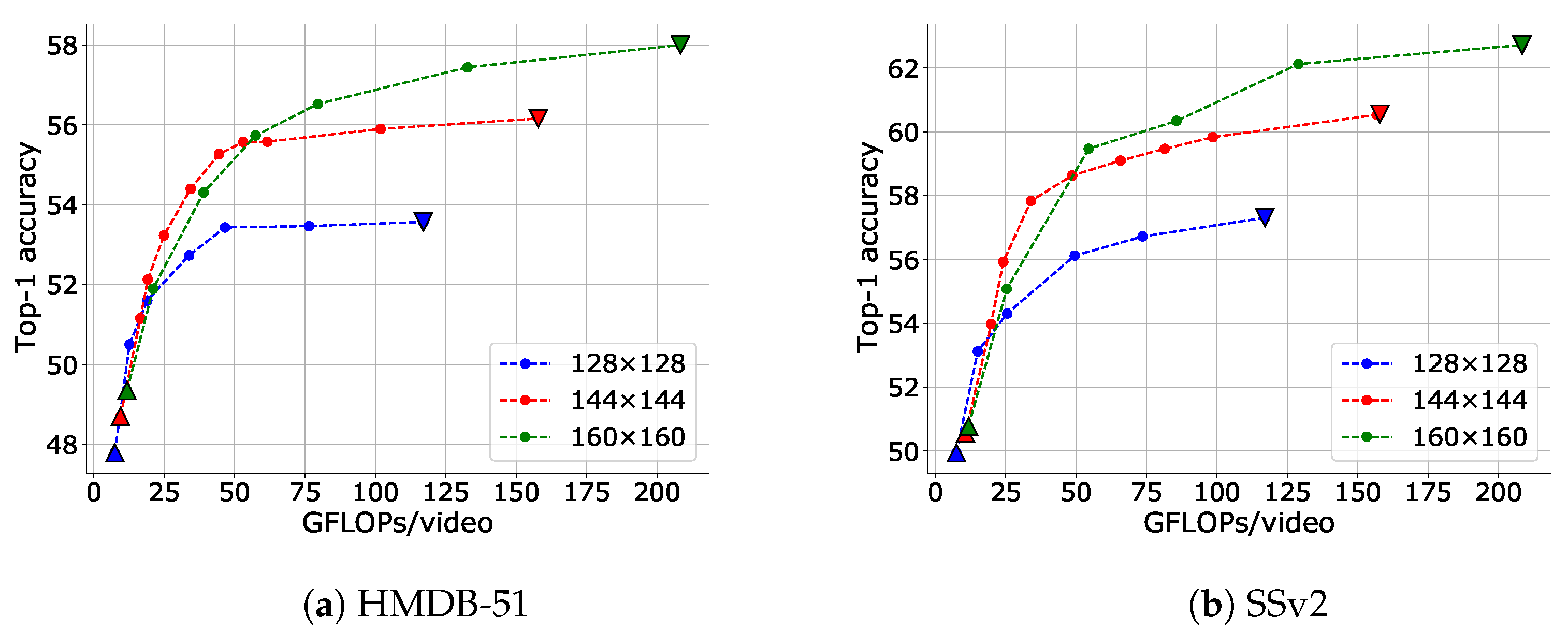
4.4. Comparison with Baselines
4.5. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| IPS | Informative Patch Selection |
| I-frame | Intra-coded frame |
| P-frame | Predicted frame |
| GFLOPs | Giga FLoating-Operation-Points |
| GPU | Graphics Processing Unit |
| CPU | Central Processing Unit |
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Zhang, Y.; Li, X.; Liu, C.; Shuai, B.; Zhu, Y.; Brattoli, B.; Chen, H.; Marsic, I.; Tighe, J. VidTr: Video transformer without convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Chen, J.; Ho, C.M. MM-ViT: Multi-modal video transformer for compressed video action recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Chen, R.J.; Chen, C.; Li, Y.; Chen, T.Y.; Trister, A.D.; Krishnan, R.G.; Mahmood, F. Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ukwuoma, C.C.; Qin, Z.; Heyat, M.B.B.; Akhtar, F.; Smahi, A.; Jackson, J.K.; Furqan Qadri, S.; Muaad, A.Y.; Monday, H.N.; Nneji, G.U. Automated Lung-Related Pneumonia and COVID-19 Detection Based on Novel Feature Extraction Framework and Vision Transformer Approaches Using Chest X-ray Images. Bioengineering 2022, 9, 709. [Google Scholar] [CrossRef] [PubMed]
- Hütten, N.; Meyes, R.; Meisen, T. Vision Transformer in Industrial Visual Inspection. Appl. Sci. 2022, 12, 11981. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, F.; Liu, X.; Li, L.; Qian, X. TCSPANet: Two-Staged Contrastive Learning and Sub-Patch Attention Based Network for PolSAR Image Classification. Remote Sens. 2022, 14, 2451. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal relational reasoning in videos. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, J.; Gan, C.; Wang, K.; Han, S. TSM: Temporal shift module for efficient and scalable video understanding on edge devices. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2760–2774. [Google Scholar] [CrossRef] [PubMed]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Xie, Q.; Luong, M.-T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Van Der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. YouTube-8M: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Srinivasan, K.; Raman, K.; Chen, J.; Bendersky, M.; Najork, M. WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning. arXiv 2021, arXiv:2103.01913. [Google Scholar]
- Changpinyo, S.; Sharma, P.; Ding, N.; Soricut, R. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar]
- Sikora, T. The MPEG-4 video standard verification model. IEEE Trans. Circuits. Syst. Video Technol. 1997, 7, 19–31. [Google Scholar] [CrossRef]
- Wu, Z.; Xiong, C.; Jiang, Y.G.; Davis, L.S. LiteEval: A coarse-to-fine framework for resource efficient video recognition. arXiv 2019, arXiv:1912.01601. [Google Scholar]
- Wu, W.; He, D.; Tan, X.; Chen, S.; Wen, S. Multi-agent reinforcement learning based frame sampling for effective untrimmed video recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wu, Z.; Li, H.; Xiong, C.; Jiang, Y.G.; Davis, L.S. A dynamic frame selection framework for fast video recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1699–1711. [Google Scholar] [CrossRef] [PubMed]
- Korbar, B.; Tran, D.; Torresani, L. SCSampler: Sampling salient clips from video for efficient action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Meng, Y.; Lin, C.C.; Panda, R.; Sattigeri, P.; Karlinsky, L.; Oliva, A.; Saenko, K.; Feris, R. Ar-net: Adaptive frame resolution for efficient action recognition. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Sun, X.; Panda, R.; Chen, C.F.R.; Oliva, A.; Feris, R.; Saenko, K. Dynamic network quantization for efficient video inference. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Meng, Y.; Panda, R.; Lin, C.C.; Sattigeri, P.; Karlinsky, L.; Saenko, K.; Oliva, A.; Feris, R. AdaFuse: Adaptive Temporal Fusion Network for Efficient Action Recognition. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Wang, Y.; Chen, Z.; Jiang, H.; Song, S.; Han, Y.; Huang, G. Adaptive focus for efficient video recognition. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, Y.; Yue, Y.; Lin, Y.; Jiang, H.; Lai, Z.; Kulikov, V.; Orlov, N.; Shi, H.; Huang, G. Adafocus v2: End-to-end training of spatial dynamic networks for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Wang, Y.; Yue, Y.; Xu, X.; Hassani, A.; Kulikov, V.; Orlov, N.; Song, S.; Shi, H.; Huang, G. AdaFocus V3: On Unified Spatial-temporal Dynamic Video Recognition. In Proceedings of the European conference on computer vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Ghodrati, A.; Bejnordi, B.E.; Habibian, A. FrameExit: Conditional early exiting for efficient video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar]
- Kim, H.; Jain, M.; Lee, J.T.; Yun, S.; Porikli, F. Efficient action recognition via dynamic knowledge propagation. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Rose, O. Statistical properties of MPEG video traffic and their impact on traffic modeling in ATM systems. In Proceedings of the 20th Conference on Local Computer Networks, Minneapolis, MN, USA, 16–19 October 1995. [Google Scholar]
- Liang, Q.; Mendel, J.M. MPEG VBR video traffic modeling and classification using fuzzy technique. IEEE Trans. Fuzzy Syst. 2001, 9, 183–193. [Google Scholar] [CrossRef]
- Doulamis, A.D.; Doulamis, N.D.; Kollias, S.D. An adaptable neural-network model for recursive nonlinear traffic prediction and modeling of MPEG video sources. IEEE Trans. Neural Netw. 2003, 14, 150–166. [Google Scholar] [CrossRef] [PubMed]
- Dharmadhikari, V.; Gavade, J. An NN approach for MPEG video traffic prediction. In Proceedings of the 2nd International Conference on Software Technology and Engineering, Puerto Rico, USA, 3–5 October 2010. [Google Scholar]
- Wu, C.Y.; Zaheer, M.; Hu, H.; Manmatha, R.; Smola, A.J.; Krähenbühl, P. Compressed video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Piergiovanni, A.; Angelova, A.; Ryoo, M.S. Tiny video networks. Appl. AI Lett. 2022, 3, e38. [Google Scholar] [CrossRef]
- Zolfaghari, M.; Singh, K.; Brox, T. ECO: Efficient convolutional network for online video understanding. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kwon, H.; Kim, M.; Kwak, S.; Cho, M. MotionSqueeze: Neural motion feature learning for video understanding. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Goyal, R.; Kahou, S.E.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fründ, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “Something Something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- The Official Implementation of TimeSformer. Available online: https://github.com/facebookresearch/TimeSformer (accessed on 1 November 2022).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Fei-Fei, L.; Deng, J.; Li, K. ImageNet: Constructing a large-scale image database. J. Vis. 2009, 9, 1037. [Google Scholar] [CrossRef]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Montavon, G., Orr, G.B., Müller, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits. Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits. Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Liu, J.; Wang, S.; Ma, W.C.; Shah, M.; Hu, R.; Dhawan, P.; Urtasun, R. Conditional entropy coding for efficient video compression. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Split | Patch Reduction Ratios | ||
|---|---|---|---|
| training set | 30% | 60% | 90% |
| validation set | 29.85% | 59.35% | 89.58% |
| Process | CPU Runtime (ms) | GPU Runtime (ms) | GFLOPs |
|---|---|---|---|
| video decoding (P-frame as RGB) | 32.230 | – | – |
| video decoding (P-frame as motions + residuals) | 39.046 | – | – |
| model inference | 1775.296 | 70.803 | 158 |
| model inference with IPS | 153.209 | 18.778 | 30 |
| P-Frame as | HMDB-51 | SSv2 |
|---|---|---|
| RGB | 55.11 | 56.10 |
| motions + residuals | 56.45 | 59.92 |
| motions + residuals w/accum | 56.16 | 59.56 |
| Base ops. | Methods | Pretrain | HMDB-51 | |
|---|---|---|---|---|
| GFLOPs | Top-1 acc | |||
| convolution | TSN [14] | K400 | 33 | 65.1 |
| ECO [47] | K400 | 64 | 72.4 | |
| TSMNet [16,17] | K400 | 33 | 73.2 | |
| MSNet [48] | IN+K400 | 34 | 75.8 | |
| Transformer | TimeSformer-S | IN | 158 | 55.1 |
| TimeSformer-S (mo+res) | IN | 158 | 56.2 | |
| TimeSformer-S (mo+res, IPS) | IN | 34 | 54.4 | |
| Base ops. | Methods | Pretrain | SSv2 | |
|---|---|---|---|---|
| GFLOPs | Top-1 acc | |||
| convolution | TSN [14] | K400 | 33 | 30.0 |
| TRN [15] | IN | 32 | 55.5 | |
| TSMNet [16,17] | K400 | 33 | 59.1 | |
| MSNet [48] | IN+K400 | 34 | 63.0 | |
| Adafuse [35] | IN | 32 | 59.8 | |
| Adafocus v1 [36] | IN | 34 | 60.7 | |
| Adafocus v2 [37] | IN | 34 | 61.3 | |
| Adafocus v3 [38] | IN | 15 | 59.6 | |
| Transformer | TimeSformer [2] | IN | 590 | 59.5 |
| TimeSformer-HR [2] | IN | 5110 | 62.2 | |
| TimeSformer-L [2] | IN | 7140 | 62.4 | |
| ViViT-L [3] | IN21k | 5800 | 65.4 | |
| VidTr-M [4] | IN21k | 179 | 61.9 | |
| MM-ViT [5] | IN21k | 2250 | 64.9 | |
| VideoSwin-B [49] | K400 | 321 | 69.6 | |
| Transformer | TimeSformer-S | IN | 158 | 57.1 |
| TimeSformer-S (mo+res) | IN | 158 | 60.6 | |
| TimeSformer-S (mo+res, IPS) | IN | 30 | 57.8 | |
| Base ops. | Methods | Pretrain | Mini-Kinetics | |
|---|---|---|---|---|
| GFLOPs | Top-1 acc | |||
| convolution | Adafuse [35] | IN | 23 | 72.3 |
| Dynamic-STE [40] | IN | 18 | 72.7 | |
| FrameExit [39] | IN | 20 | 72.8 | |
| LiteEval [29] | IN | 99 | 61.0 | |
| SCSampler [32] | AS+IN | 42 | 70.8 | |
| ARNet [33] | IN | 32 | 71.7 | |
| VideoIQ [34] | IN | 20 | 72.3 | |
| Adafocus v1 [36] | IN | 27 | 72.2 | |
| Adafocus v2 [37] | IN | 27 | 75.4 | |
| Adafocus v3 [38] | IN | 18 | 75.0 | |
| Transformer | TimeSformer-S | IN | 158 | 72.9 |
| TimeSformer-S (mo+res) | IN | 158 | 73.1 | |
| TimeSformer-S (mo+res, IPS) | IN | 30 | 71.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suzuki, T.; Aoki, Y. Efficient Transformer-Based Compressed Video Modeling via Informative Patch Selection. Sensors 2023, 23, 244. https://doi.org/10.3390/s23010244
Suzuki T, Aoki Y. Efficient Transformer-Based Compressed Video Modeling via Informative Patch Selection. Sensors. 2023; 23(1):244. https://doi.org/10.3390/s23010244
Chicago/Turabian StyleSuzuki, Tomoyuki, and Yoshimitsu Aoki. 2023. "Efficient Transformer-Based Compressed Video Modeling via Informative Patch Selection" Sensors 23, no. 1: 244. https://doi.org/10.3390/s23010244
APA StyleSuzuki, T., & Aoki, Y. (2023). Efficient Transformer-Based Compressed Video Modeling via Informative Patch Selection. Sensors, 23(1), 244. https://doi.org/10.3390/s23010244