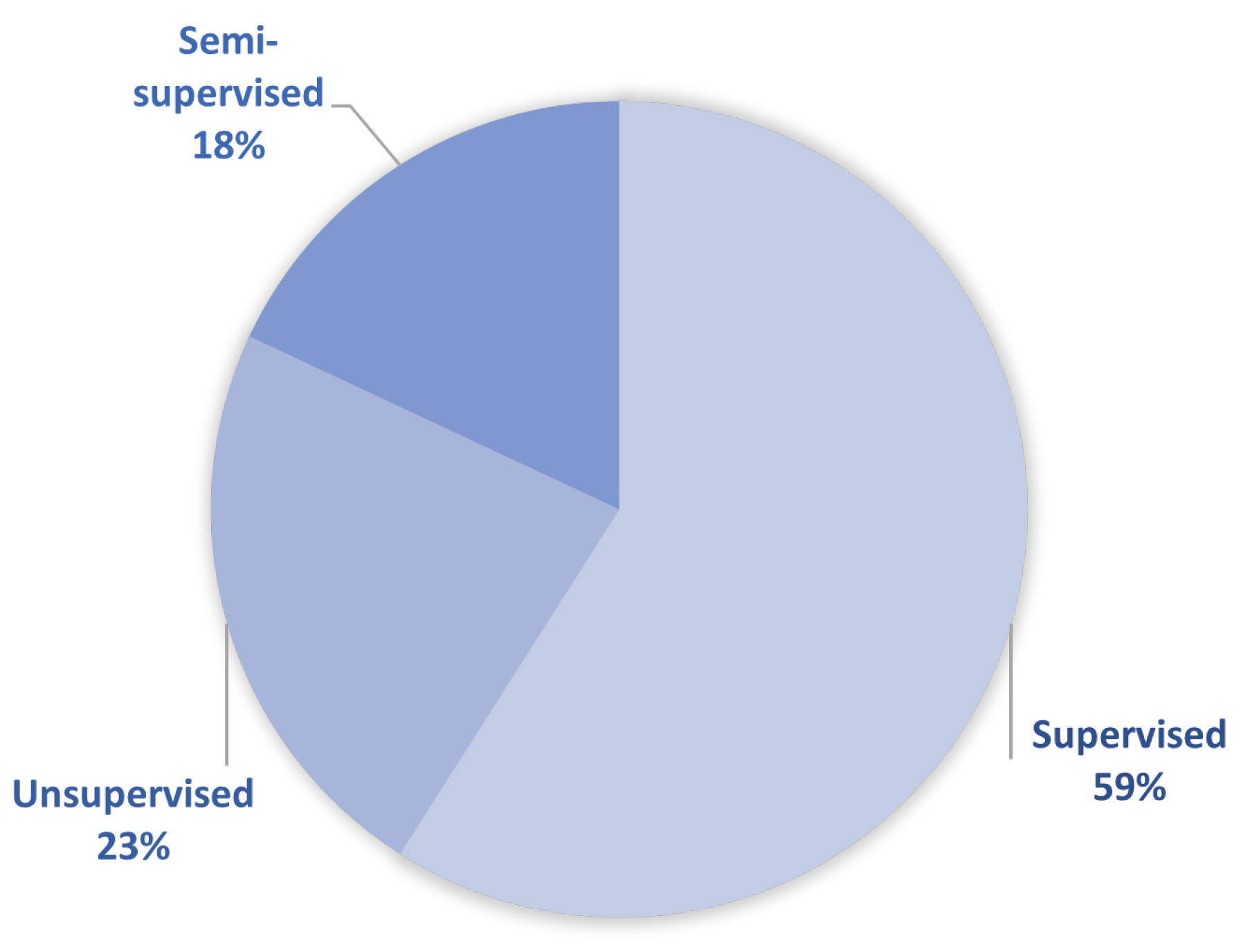
In this Section, we present the most common, yet effective, modeling techniques used to implement FDD models using the data-driven approach. We explain their characteristics using research results from the reviewed literature. Finally, we compare their advantages and disadvantages and provide an intuitive flowchart for selecting the appropriate model for an FDD problem.
4.4.1. Support Vector Machine
Support vector machines (SVMs) [
79] are one of the most commonly used modeling approaches for FDD in HVAC. Essentially, an SVM is a binary maximum margin classifier, defined by a boundary that is unit-separated from the nearest instances of both classes using the simplest possible representation (regularization effect). The dimensionality of the boundary depends on the number of data features. The goal of the model is to determine the boundary ensuring the largest distance between it and the closest data instances of the two classes. Increasing the boundary distance provides some reinforcement and allows for a more accurate categorization of the data instances. To successfully model an n-dimensional space, we pinpoint those data instances that are closest to the boundary (i.e., support vectors) and influence the boundary’s position and direction. Because SVMs are linear classifiers, more complex distributions can be encoded seamlessly using kernel functions. A kernel function is basically a computation of high-dimensional relations of input data without the need to explicitly transform the data. It reduces the computational cost by avoiding the transformation of the data, and allows the computation of relations in an unbounded number of dimensions. Polynomial kernels and radial basis function kernels are the most commonly used [
79]. For regression problems, the alternative to SVM is called Support Vector Regression (SVR). Here, support vectors are utilized to form the linear hypothesis [
115]. Because SVM is inherently a binary classifier, multi-class SVM (MCSVM) can be used to classify multiple classes. MCSVMs are typically implemented by incorporating several binary SVMs. There are numerous methods for solving multi-class classification problems for SVM, including Directed Acyclic Graph (DAG), Binary Tree (BT), One-Against-One (OAO), and One-Against-All (OAA) classifiers [
116]. A semi-supervised type of SVMs is also mentioned in the literature, called self-training SVM. Essentially, self-training algorithms work by iteratively learning a classifier by assigning pseudo-labels to a set of unlabeled training instances with a margin greater than a certain threshold. This method is resistant to class imbalances and is able to efficiently use both labeled and unlabeled data, even when the class distribution is highly skewed [
117].
An SVM was used as a regression model in a hybrid approach where its inputs were provided by the physics-based model. The SVM performed poorly when compared to alternative regression models such as Gaussian process regression (GPR) [
81]. An SVM and a self-training SVM performed worse than a GAN, but also showed their advantages over other supervised classifiers in [
54]. Tun et al. [
59] used an SVM as an additional classifier that improved the accuracy of an RF model. In their workflow, RF was better suited for working with large amounts of noisy data and extracting features. The extracted features were then passed to the binary SVM classifier. SVM was better suited for processing low-dimensional data, and in this workflow SVM improved the accuracy of classification. In addition, an SVM was implemented as both a binary classifier and a multi-class classifier. The binary classifier was used to detect if an instance represents a fault first. If the detection was positive, the instance was further classified using the multi-class classifier to diagnose the fault next [
63]. Furthermore, Yan et al. [
67] tried an ensemble of learners and found that SVM-RF-MLP had the best performance among the other ensembles. Martinez-Viol et al. [
66] presented a binary SVM model that demonstrated its resistance to outliers during training. When the number of features and training instances is small, an SVM is considered a very strong technique that can achieve good accuracy without requiring manual fine-tuning of the model. SVM can be combined with a multiscale interval PCA extension that leads to more accurate classification [
91]. Multi-Class Support Vector Machine (MC-SVM) was used to create an automatic FDD system based on categorical data to make the building smarter [
77]. The same authors have previously conducted research on the implementation of MC-SVM where they investigated linear kernel SVM (i.e., not transforming the input space), quadratic kernel SVM and three variations of KNN models. Linear kernel SVM proved to be the best-fit model among the five tested methods [
76].
Although they can work as multiclass classifiers, SVMs work best on low-dimensional data and are preferably used as binary classifiers. They are efficient and, when combined with other models, can increase modeling accuracy.
4.4.2. Artificial Neural Networks
ANNs are models that mimic the processes of the brain to express correlations in highly nonlinear data distributions. Similar to the brain, an ANN consists of neurons (or nodes) that encode outputs as functions of the inputs. Its structure consists of an input layer, one or more processing layers (hidden layers) of connected nodes and an output layer. Model weighting is adjusted until the model has the smallest possible margin of error. Due to their structure, ANNs can encode more complex representations by adding more hidden layers, which consequently enables them to learn useful feature embeddings (i.e., perform DL).
In general, DL is a subset of ML, enveloping those ML techniques that rely on learning latent representations in an end-to-end optimization process—as opposed to non-DL methods that usually rely on feature extraction to simplify the modeling distribution. Essentially, a DL model consists of a collection of basic building blocks of particular types, some of which can be adapted by learning their parameters (i.e., weights) from data to improve overall model prediction accuracy. When a composition is called “deep”, it means that numerous building blocks of that type are stacked in a hierarchy of increasing complexity. ANN building blocks are expressive enough to be used for building DL models. Therefore, they are commonly the first choice when one is interested in building a DL model.
In addition to an ordinary fully-connected feed forward MLP, some of the most popular DL alternatives are CNNs and RNNs. CNNs are a DL modeling technique typically used in computer vision to analyze and recognize visual input, such as digital photographs. RNNs are a DL modeling technique that tolerates and benefits from the sequential nature of inputs, just as CNNs accept the spatial structure of image inputs. In summary, they are intended for the analysis of time series data, event histories or temporal sequences [
118]. Additionally, a form of self-training MLPs were mentioned in the literature [
43,
54], analogous to the term explained in
Section 4.4.1.
Aguilar et al. [
56] created ACODAT, in which an MLP was employed for behavioral prediction which determines the quality of a multi-HVAC system setup. Next, twenty-two different neural network architectures were analyzed, and one was chosen to be coupled with a physical model in order to provide an accurate simulation tool capable of producing faulty and fault-free datasets that can be evaluated and used to determine the impact on energy consumption [
83]. Moreover, MLPs and self-learning MLPs performed worse than GANs, but they also outperformed other supervised classifiers [
54]. In [
43,
49], the authors explore the value of a semi-supervised self-training neural network which in the end shows its effectiveness and the possibility of enhancing unseen fault detection rate in AHU operations. Zhu et al. [
51] succeeded in creating a transferable model by developing a domain adversarial neural network (DANN). DANN combines domain adaptation with deep feature learning in an adversarial training process, so that final classification judgments are based on features that are both discriminative for the target task and invariant to changes in the domain. Next, Piscitelli et al. [
61] combined a MLP and a regression tree built using the algorithm CART (CART, MLP) with an aim to detect anomalous patterns and trends in energy consumption. The combination ensured the interpretability of MLPs. CNNs aim in [
82] is to analyze the correlation between the system variables and to take into account the temporal influence of time series signals without risking the recognition time. The proposed approach eliminates the need for advanced data preprocessing and is computationally efficient. Furthermore, to overcome the disadvantage of DL black-box model interpretability, Li et al. [
60] proposed a novel explainable DL-based fault diagnosis method suitable for HVAC systems. CNNs have been improved to be multi-scale and provide better feature extraction capabilities for FDD of RLT devices [
47]. In [
84], the proposed framework combines the rule-based method and the CNNs-based method. Faults can be identified with a high accuracy of 99.15%, including fast online detection within 2 min. Miyata et al. [
72] used system data visualizations directly as model inputs for the CNN-based FDD approach. For fault diagnosis, a novel FETCN technique was presented. Initially, characteristics describing the dynamics and changes in the chiller system are retrieved and improved using the statistical pooling approach. Following that, a Temporal Convolutional Network (TCN) classifier is used to analyze the features and diagnose the problem [
50]. In [
57], Stacked deep RNN was the ultimate model for fault diagnosis of HVAC systems over a long period of time. Additionally, a variant of the artificial recurrent neural network called LSTM was proposed and it performed the best in prediction performance in comparison to the XGBoost method when the time-series data fluctuated greatly. Next, a framework was developed by Zhu et al. [
103] that provides guidelines for implementing predictive maintenance of building installations. When the data are collected, LSTM network is used to predict faults. Yun et al. [
53] wanted to see if a neural-network-based FDD model could yield substantial inferences for input variables using SAE. The real-time monitoring data are used as model input. The offline model is essentially trained to predict fault-free or faulty class, and additionally generates a reliability value for every predicted label, which is then analyzed using threshold settings.
To summarize, compared to other models, neural networks have seen the highest exploration and utilization in recent years. It is clear that MLPs, CNNs, and RNNs may be successfully applied within FDD solutions. However, for predicting time-series data, RNNs, notably LSTMs, are preferable. CNNs, on the other hand, are said to have great accuracy and exceptional capability in learning complicated functions and interdependence from any given input. Keeping this in mind, CNNs require a large quantity of data to be efficient and accurate when compared to other networks. Finally, MLPs are the most basic sort of network that may be combined with other models such as CART or SVM.
4.4.3. Decision Tree
DT models can be used both for classification and regression tasks. DTs consist of root nodes, decision nodes and leaf nodes. A root node, also called a parent node, represents the entire population and divides the data into two or more nodes. When developing a tree, decisions must be made about which features to include as input, the conditions for splitting and when to stop further branching of the tree. In addition, trees grow randomly. Therefore, pruning techniques are used to improve the performance of the tree by eliminating branches that use less important features. By reducing model complexity up to a point, we reduce overfitting and increase its generalization accuracy. Entropy and information gain are important for branch partitioning. Entropy measures the degree of unpredictability in a series of events and serves as an estimator. These estimates are then calculated using the information gain formula, which provides a sense of certainty about the class of a target variable. A DT model is usually easy to develop and has high interpretability as it can be easily visualized and explained. Moreover, the selection of features is implicit. The main problem is overfitting, as a tree can become an overly complex model that lacks generalization to new data. On the other hand, severe bias can occur if the imbalance of classes in the dataset is not taken into account [
119].
DT has been used as a reference model to interpret MLPs in [
61]. Furthermore, authors examined DTs using a combination of temporal ARM in [
98]. DTs were used for detecting faults on the non-transient period of the dataset. Their rule-based approach provides interpretability and the data-driven side of the methodology enables automatic learning of operational patterns. However, the granularity of the ASHRAE 1312-RP dataset used had to be reduced to obtain optimal model performance. In addition, the DT was used to classify data categories at the zone level, where they were combined with association methods [
69]. In system health monitoring, due to its simplicity, DT model was implemented to distinguish normal operation from abnormal [
55]. The same classification of normal and abnormal data was performed in [
95] as a post-mining tool. On the other hand, the generated residuals were classified using DTs in [
88]. The applications of CART models are mentioned in several articles [
61,
98]. Furthermore, many ML methods were tested on synthetically created as well as real-world datasets where boosted trees produced the best results [
80]. For outlier detection and fault diagnosis, a hybrid deep forest technique was proposed. For outlier detection, the IF approach is used with Pearson’s correlation coefficient. Additionally, a DL model—cascade forest (CF) based on DTs is suggested for fault detection of HVAC systems, achieving high precision accuracy in low-dimensional data [
62]. This model does not require a complex hyperparameter optimization strategy and provides the highest accuracy when compared to Back Propagation Neural Network (BPNN), MLP, SVM and LSTM.
DTs used for classification tasks are more commonly used than regression trees because the main objective is to detect errors. On the other hand, regression trees are better suited for model predictive control (MPC), where the goal is to predict certain values such as time to failure or energy consumption. In summary, the classification DT model performs best with a smaller number of classes and has the advantage over other models for its simplicity and interpretability. Furthermore, outliers do not have a significant impact on the model and the same variables can be used multiple times in different parts of the tree, allowing a model to reveal dependencies between groups of variables.
4.4.4. Random Forests
If a DT model exhibits too much variance in spite of using appropriate regularization techniques, it can be replaced by implementing an ensemble of DTs called the RF model instead. An RF model predicts a class by averaging the results of multiple trees, and its accuracy improves as the number of trees increases. This is accomplished through a process of sampling with replacement called bagging coupled with random feature selection at each tree-building step to train ensembles of trees for attaining higher predictive accuracy. Essentially, it is a model that can handle encoding more complex distributions by using highly expressive individual models whose variance is in turn constrained through voting during inference. However, training an RF model requires more computational time compared to a DT. Moreover, they do not handle sparse data well and cannot extrapolate properly, so classification random trees are used more often than regression trees [
79].
RF is studied and compared with an autoregressive (ARX) model to predict fault-free operation by predicting the total heating capacity of a building, followed by the detection of faults using residual analysis [
68]. RF is more difficult to interpret, but has minimal problems with overfitting and provides an efficient nonlinear modeling strategy. Parzinger et al. [
87] extended their earlier research by developing an algorithm to determine the best decision rule for determining errors. Wu et al. [
58] employed a novel hybrid method of classifier chains with integrated RF method (CC-RF) to treat concurrent faults in RLT units as a multi-label problem. Another novel hybrid method was proposed in [
59], wherein a combination of RF and SVM (RF-SVM) classifiers was utilized. RF is used to extract the most important features, which improves the generalization ability of the proposed FDD system.
RF is often used in hybrid approaches to improve accuracy. It is advisable to use this approach when a large number of classes needs to be predicted. Although lack of interpretability can be a problem in the field of HVAC system monitoring, it has shown good predictive performance.
4.4.5. Extreme Gradient Boosting
Some shortcomings of RF modeling can be solved using Extreme gradient boosting (XGboost)—an ensemble learning technique based on gradient boosting, a potent algorithm in which each consequtive predictor corrects the cumulative error of its predecessors. In XGBoost, particular models that form the ensemble (DTs) are built sequentially, on the residual of the previous models. These individual classifiers/predictors then ensemble to form a strong and more accurate model [
120].
In [
46], a hybrid reference model called multi-region XGBoost is used as a classifier, which integrates a type of DT called CART. Results of this model show its high accuracy in identifying errors, indicating that it generalizes well and is a reliable and efficient model for FDD purposes. The model outperformed the SVM and the regular XGBoost model. Furthermore, XGBoost was employed as a prediction model for energy usage in [
93], where it was combined with a novel dynamic threshold approach for FDD. The method detects fault occurrences and dynamically modifies the threshold value based on the real-time moving average and moving standard deviation of the forecasts.
In spite of not being used commonly for HVAC FDD, XGBoost models are efficient with large datasets, can handle class imbalances and can outperform SVMs, among others, in FDD tasks. Moreover, due to its foundation in the decision tree boosting principle, which employs a sampling technique, XGBoost models are insensitive to distribution skewness.
4.4.6. Clustering
Even though we focused mostly on common supervised types of learning methods, for unsupervised type we singled out clustering as a proposed method if the dataset is unlabeled. Clustering involves the automatic identification of natural groups of data instances. A cluster can be defined as a dense region in the feature space where observations in one area are closer to one group than another. Clustering can be used as knowledge or pattern recognition due to its ability to discover relationships between unlabeled data instances. In addition, it can also be used as a feature engineering method where groups of clusters can be labeled as one cluster. An expert may be required to evaluate the identified clusters, as the results may be subjective to a particular research area. Clustering algorithms attempt to find dense regions of observations using similarity or distance metrics between instances in the feature space. Therefore, data must be scaled before applying clustering techniques. It should be noted that some clustering methods require a parameter for the number of clusters the user wants to find. Other algorithms require a parameter that defines the minimum distance between data instances in order to appropriately group the data [
119].
In the literature, a multi-regional XGBoost model (based on CART) was developed using a mean-shift clustering method [
46]. Clustering based on the “Follow The Leader” algorithm was performed, followed by frequency analysis to eventually label anomalous data [
61,
98]. A study in [
70] proposed a ML-based multi-stage automatic fault detection system focusing on FCU subsystem analysis. The method uses sequential two-stage clustering to identify abnormal behavior. The cluster analysis based method was performed in [
65], where the faults were detected by Ward’s linkage method with Euclidean distances in the data, which were otherwise missed by the operational staff and previous commercial FDD tools. Next, anomaly detection at the zone level was performed by using various clustering methods, such as k-means, Gaussian mixture, and agglomerative clustering algorithms. The best algorithm was selected based on the Calinski–Harabasz index [
45]. Feature selection was performed by clustering analysis that included agglomerative hierarchical, k-means, and PAM algorithms [
95]. In a hybrid approach, a physical model was built and evaluated using the clustering technique by measuring the distances between instances to distinguish between normal operation and four types of faults [
26].
From the literature reviewed, it appears that clustering can be used in fault detection, data labeling, feature selection, and as an evaluation technique. In particular, Multi-Objective Clustering-Rapid Centroid Estimation (MOC-RCE) has been shown to be the most efficient feature selection method. When dealing with unlabeled datasets, clusters are a viable option that should be explored and experimented with.
4.4.7. Association Rule Mining
ARM is a data mining technique for finding common patterns, correlations, relationships or causal structures in datasets containing non-numeric, categorical data. The goal of ARM is to find rules that allow predicting the occurrence of a particular element based on the occurrence of other elements in the events. An association rule consists of two components: an antecedent (if) and a consequent (then). An antecedent is something that occurs in the data and a consequent is something that is associated with the antecedent [
119].
In the reviewed literature there have been several implementations of this method [
69,
95,
96,
97,
98]. For example, the work described in [
98] implemented a two rule-extraction method including DT and TARM. TARM methods were used for detecting faults in transient periods. On the other hand, the work described in [
69] focused on metadata inference without any semantic information. The authors developed a zone level inference method which included classification by DT and an association method—episode-based association. After the data points are classified, the association method discovers the functional relationships among these point classes by grouping the data using different matching strategies. Next, authors in [
95] proposed an ARM anomaly detection and dynamic energy performance evaluation method for an HVAC system to evaluate multiple energy performance metrics of individual buildings in a short time interval (i.e., every hour). They used clustering techniques where the ARM method was applied to each data cluster. The post-mining process was further evaluated using DTs. Furthermore, to automatize the selection of rules and improve the performance of the ARM method, authors in [
97] improved the post-mining of associated rules by developing a rule of comparison-based post-mining. It consists of association rule grouping, association rule normalization, association rule comparison and expert rule analysis. Similarly, post-mining method was improved in [
96] by proposing the implementation of a fuzzy analytic hierarchy process. The post-mining method consisted of three criteria and six sub-criteria to evaluate the value of each association rule. Fuzzy set theory was used to evaluate the sub-criteria of association rules. Finally, the analytical hierarchy process was applied to determine the weight of each criterion and sub-criterion, resulting in an overall evaluation of the rules. Finally, k-means clustering algorithm was used to classify the rules based on their Euclidean distance.
To summarize, ARM is often combined with clustering, or even supervised methods such as DT (where applicable). ARM is capable of extracting association rules between variables from massive operational datasets. Even though ARM can be efficient in creating rules, the main drawbacks of ARM include, among others, the excessive generation of non-informative rules that are difficult to filter out if post-processing is not automated. Furthermore, the majority of ARM algorithms (Apriori, Eclat and FP-growth) work with categorical data only. Seeing that HVAC datasets consist primarily of numerical measurements, they must be converted into categorical data which requires additional data preprocessing and tuning [
97].
4.4.8. Choosing the Right Model
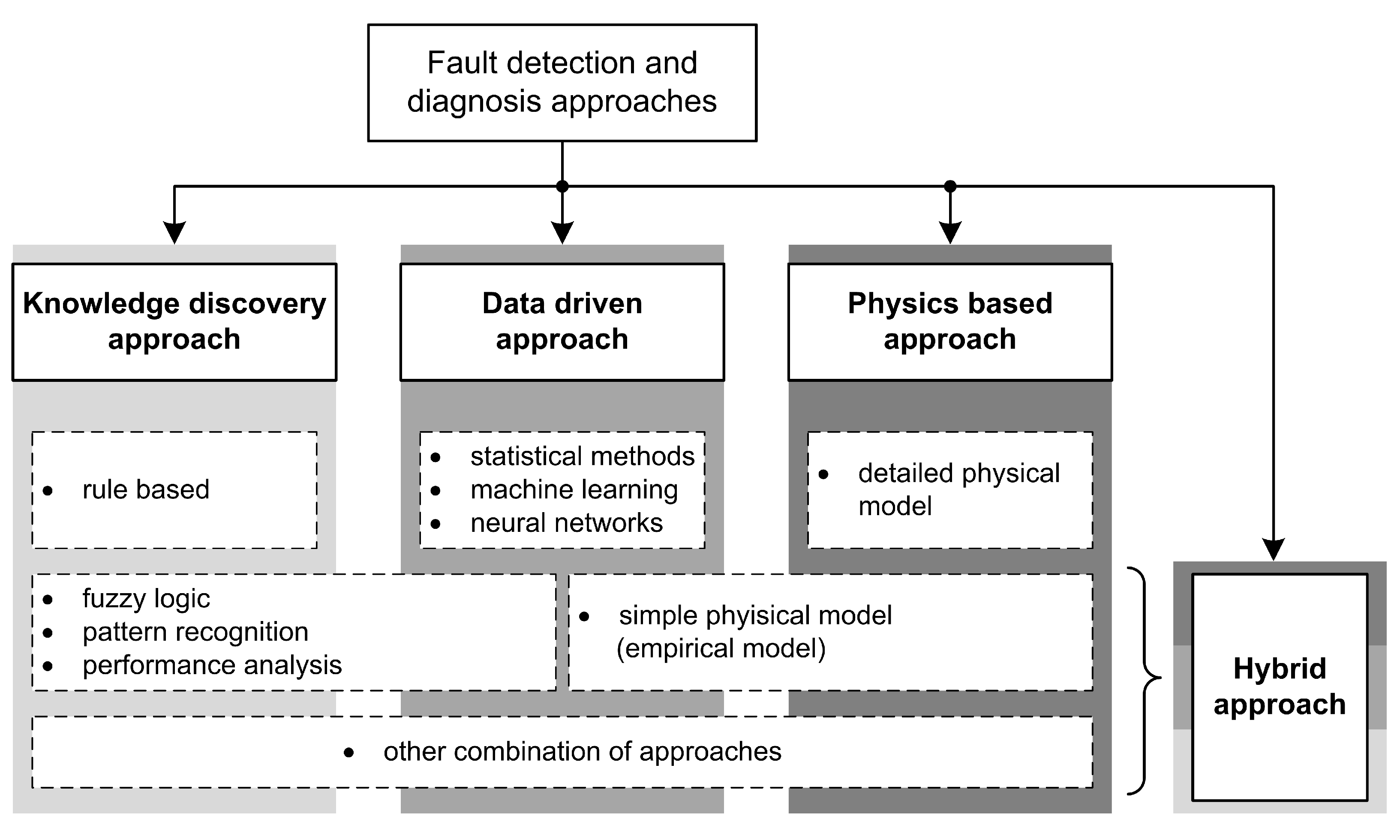
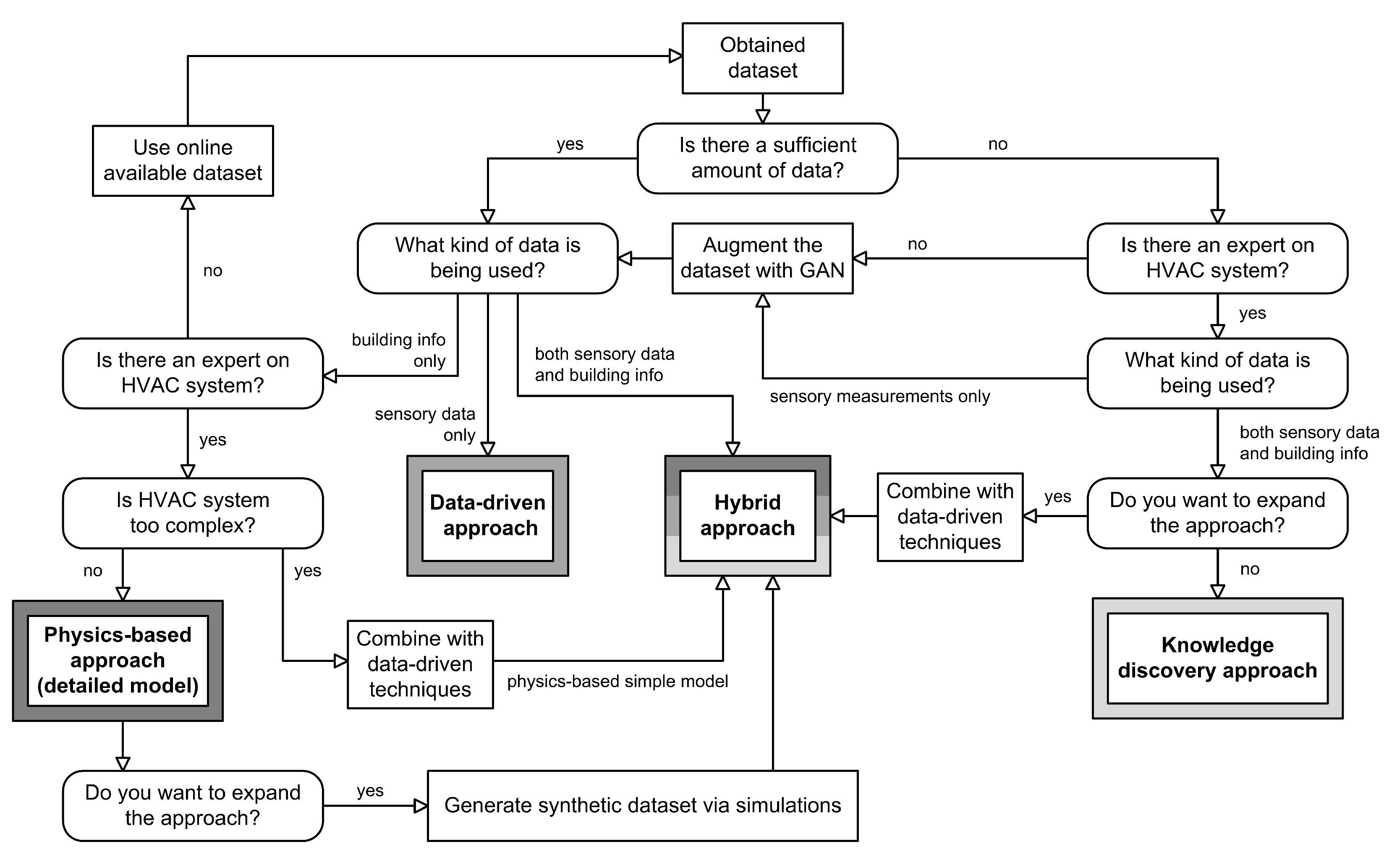
Figure 9 shows the proposed workflow for developing a model for HVAC FDD.
First of all, we assume that we have at our disposal the data from the sensor infrastructure in a building (e.g., a hotel). The usual data that a typical monitored HVAC system can provide in such a context are: user-set desired temperature, current achieved temperature in the room, HVAC fan speed, HVAC valve status, room occupancy, window status (open/closed), etc. Meteorological data related to the building’s microsite can often be added to this data, whether it comes from an internally installed weather station or is supplied by a third party (vendor). Typical meteorological data that affect the thermodynamics of the building and can be collected include radiation (solar radiation falling on a surface), humidity (the amount of vapor present in the atmosphere), and outdoor temperature. Generally, all of the above data are collected in a time series format that matches the sampling frequency of the sensor readings in the HVAC system.
Next, the clean dataset should be obtained, meaning that the original raw dataset was previously preprocessed, as mentioned in
Section 4.2. The preprocessing steps depend on the raw data and may consist of cleaning up outliers and missing values, either manually or using specific methods mentioned in
Section 4.2.1. In addition, normalization and standardization can be applied if needed to make data points uniform.
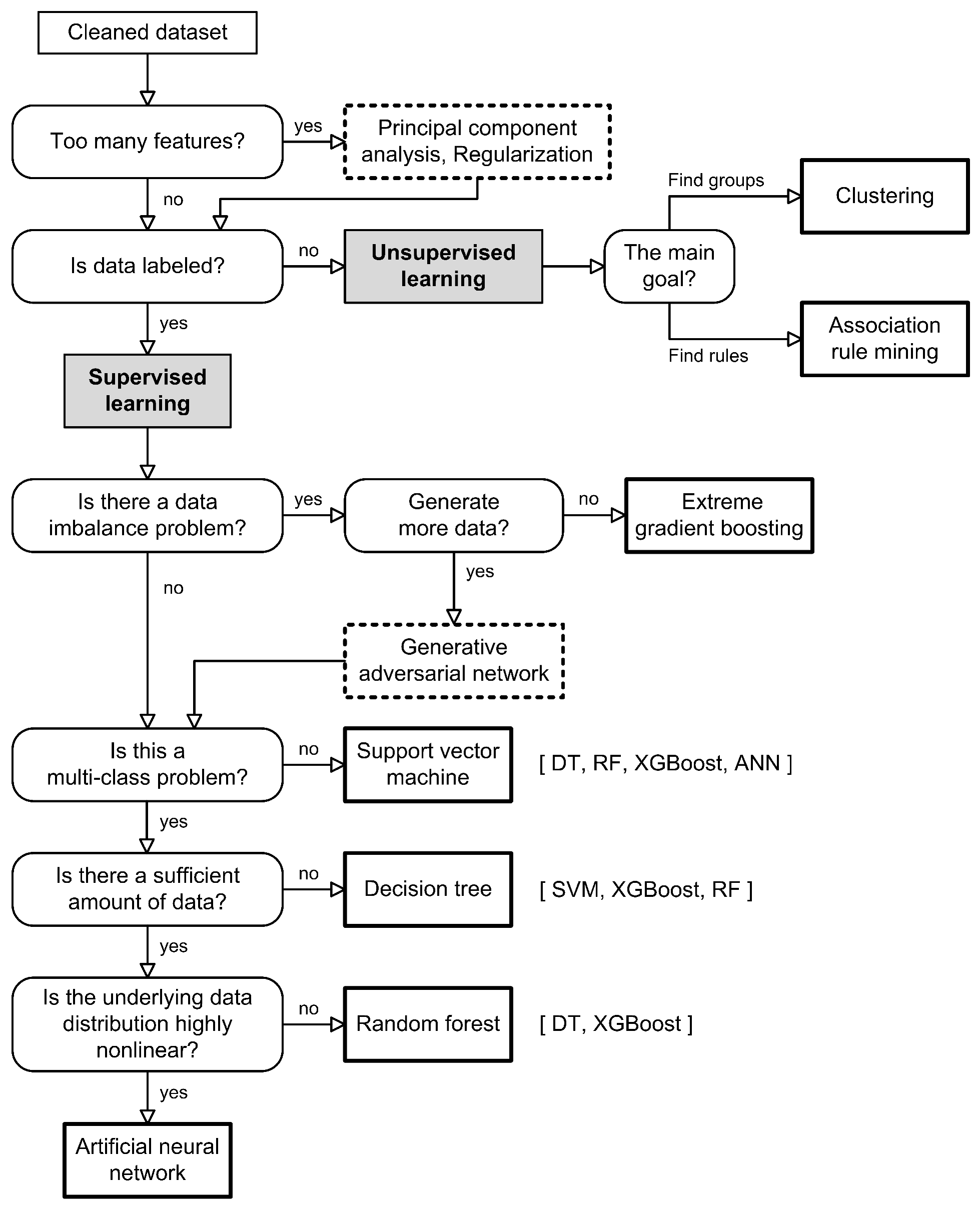
After the target dataset has been cleaned and prepared, it is ready for feature selection. If the number of features is too high compared to the computational power at our disposal, we can use feature selection or dimensionality reduction techniques to obtain a denser version of the same dataset, as a one-time preprocessing step. Alternatively, regularization should be preferred for dealing with noise removal and overfitting. Next, we need to determine whether the dataset is labeled with faulty classes or not. Based on this, we narrow down the choice of algorithms available to us, depending on their learning type:
Learning from unlabeled data can be performed using unsupervised learning techniques. Proposed methods include clustering and ARM. ARM is normally used when the main goal is to find connections between attributes in the data, whereas clustering is used when the goal is to find relationships within data points.
For labeled data, if there is an imbalance between classes, we recommend using XGBoost models or GANs. XGBoost models can deal with class imbalance by providing a way to tune the algorithm to pay more attention to minority class misclassification in datasets having a skewed class distribution. On the other hand, GANs can be used to augment the existing dataset by generating a larger amount of labeled and/or unlabeled data. In this way, all upcoming supervised learning techniques will achieve better results because their inputs will be class balanced. At this stage, there are a number of options for creating supervised models:
- –
If a binary classifier is needed, SVMs are advisable because they maximize the margin between the neighboring points of opposed classes. All the other models mentioned are also suitable for binary classification, but seeing that SVMs are inherently a binary classifier, it is advisable to try them first.
- –
If the number of data instances is not overwhelming, and multi-class classification is needed, DTs are likely the best option since they are highly interpretable, and are therefore reliable to implement in an actual HVAC system. As an alternative, it is advisable to compare DTs with models such as SVM, RF and XGBoost.
- –
If the underlying data distribution is highly non-linear in nature, then ANNs offer more flexibility—albeit at the expense of additional complexity—CNN models for spatial data, RNN/LSTM for temporal data, and MLP for everything else. If not, then an RF model may be more suitable for this purpose, because it requires tuning less hyperparameter values.
Although the workflow described above provides a simple way to select appropriate modeling techniques, in practice it may differ slightly depending on the type of the problem researchers are trying to solve. One rule cannot be applied to all FDD problems, so it is important to consider several other things when developing FDD solutions for HVAC systems. This leads us to a parametric and non-parametric categorization of such models. This is a fundamental ML concept for categorizing individual models based on their capabilities. The main difference is that parametric models have a fixed number of parameters, while non-parametric models have an increasing number of parameters related to the growth of the training data. Parametric models such as ANN, clustering, naive Bayes classifiers, and linear and logistic regression (LR) are faster to compute, but can tend to make stronger assumptions about the nature of the data distributions. Non-parametric models such as SVM, XGBoost, DT, CART, ARM and KNN classifier are more flexible, but can be computationally intensive for large datasets. It is also important to note that SVM can only be listed as a parametric method if it is used as a one-class or binary classifier. For highly flexible models (non-parametric models), it is also important to be careful not to overfit by not modeling all minor variations, as these often represent noise rather than important data [
121]. This is usually circumvented by the use of regularization.
In order to compare the main features of all the models mentioned, we have summarized their advantages and disadvantages in
Table 8.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}