Multi-Color Space Network for Salient Object Detection


Abstract
:1. Introduction
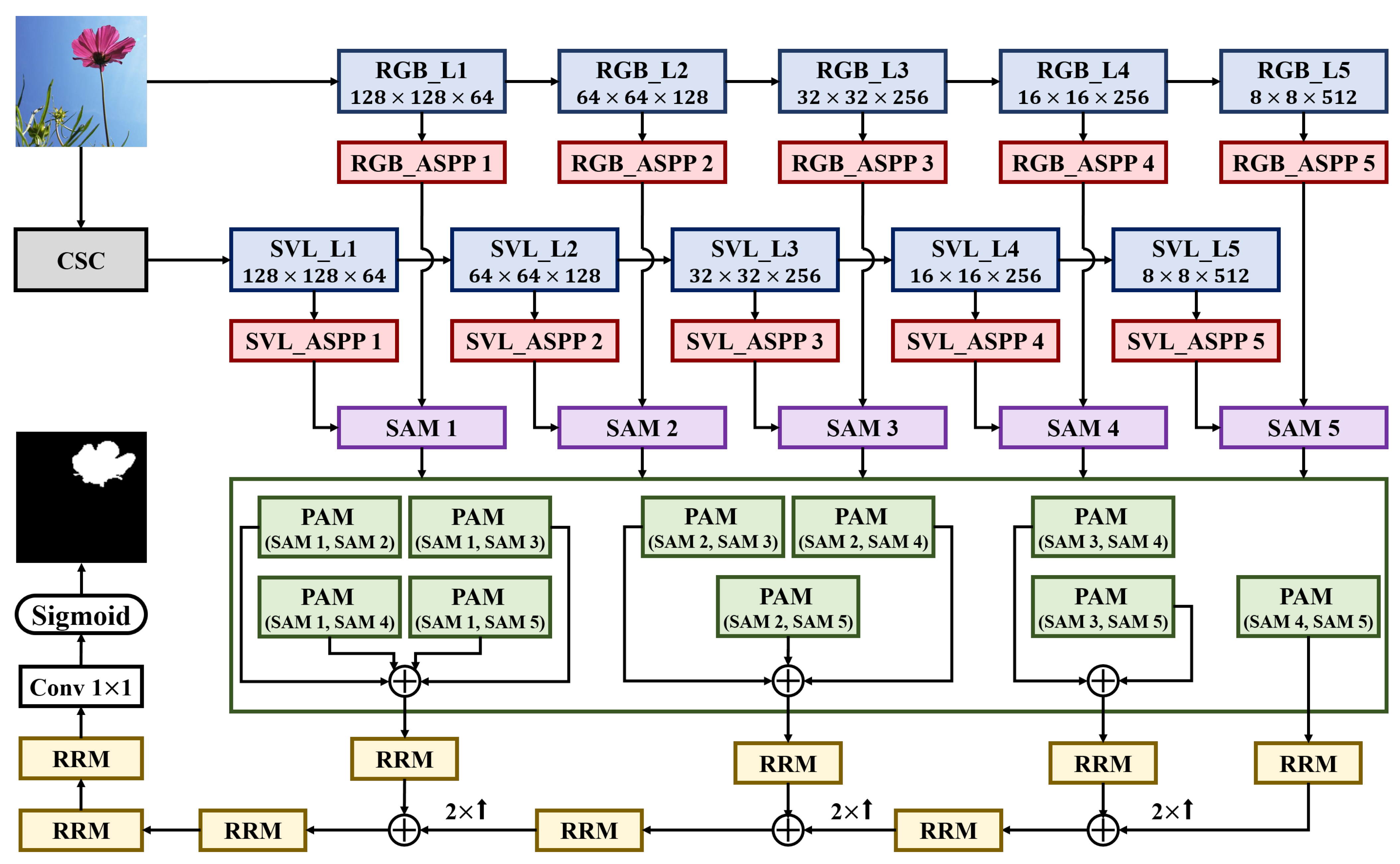
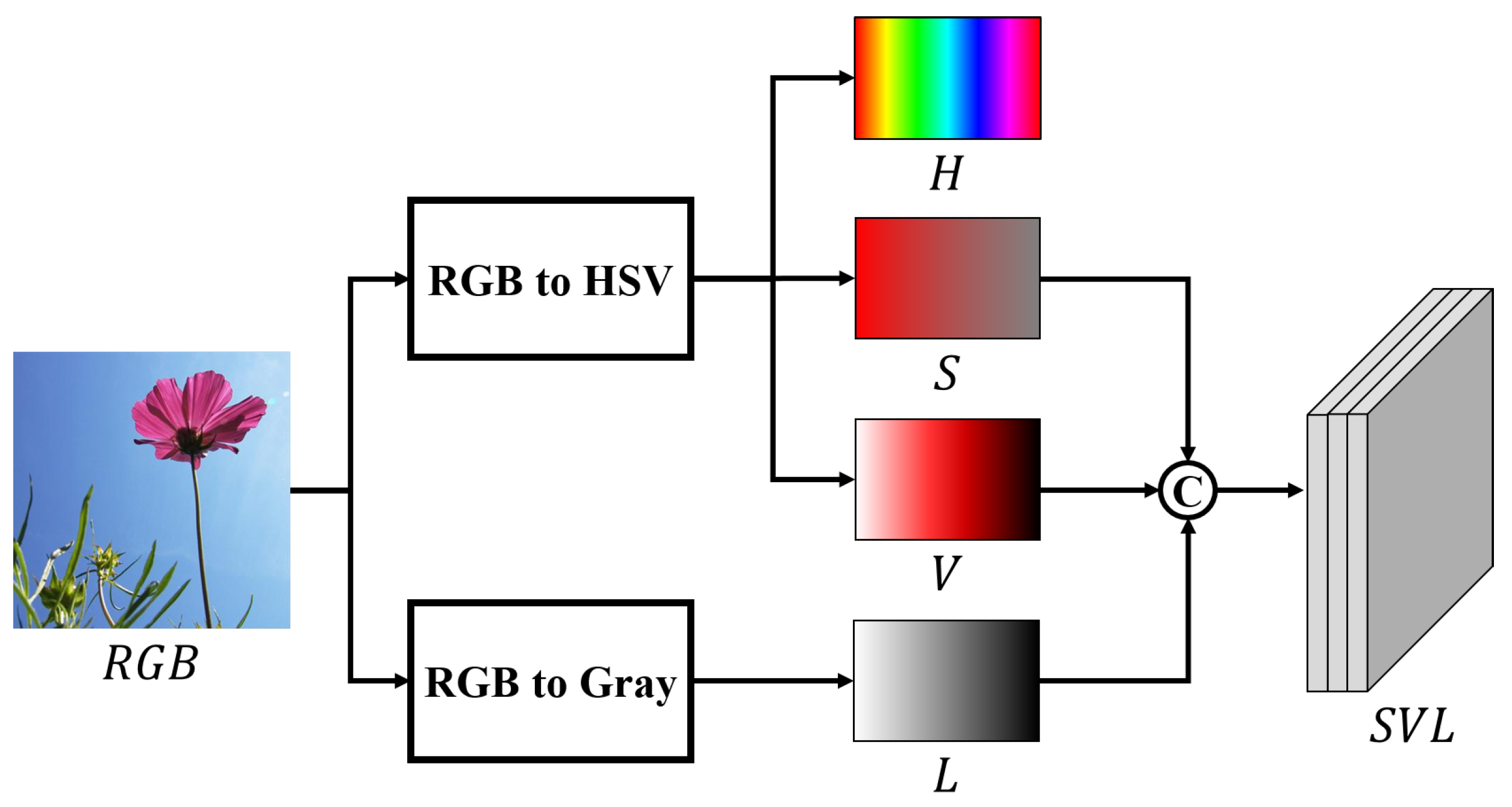
- An MCSNet was developed to achieve more accurate top-down saliency detection. In contrast to conventional methods that only use RGB color cues to learn the characteristics of salient objects, HSV and grayscale color spaces were utilized to leverage the information provided by various saliency cues. The VGG-based backbone network was divided into two parallel paths to extract features from RGB channels as well as channels with saturation and luminance information.
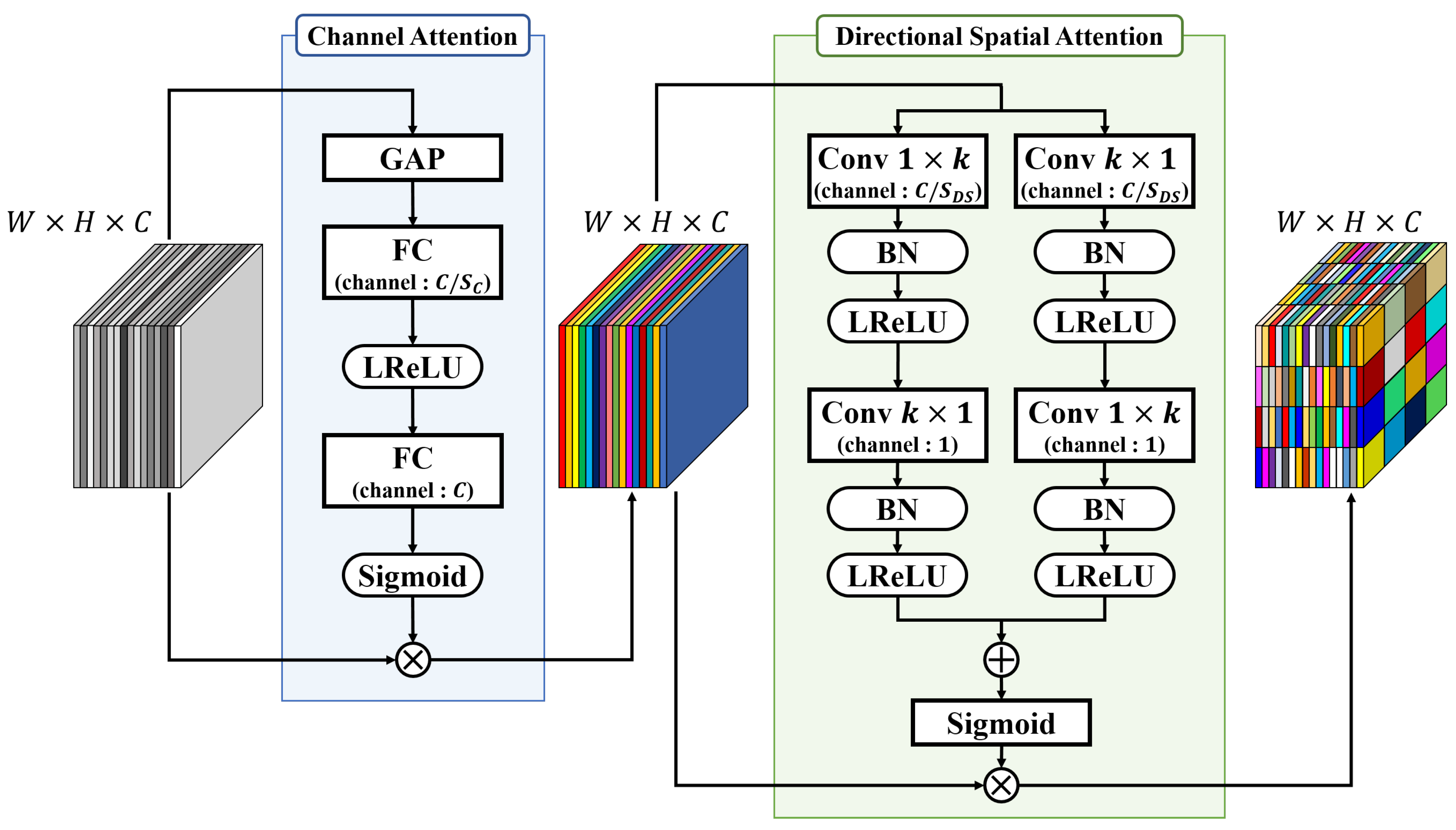
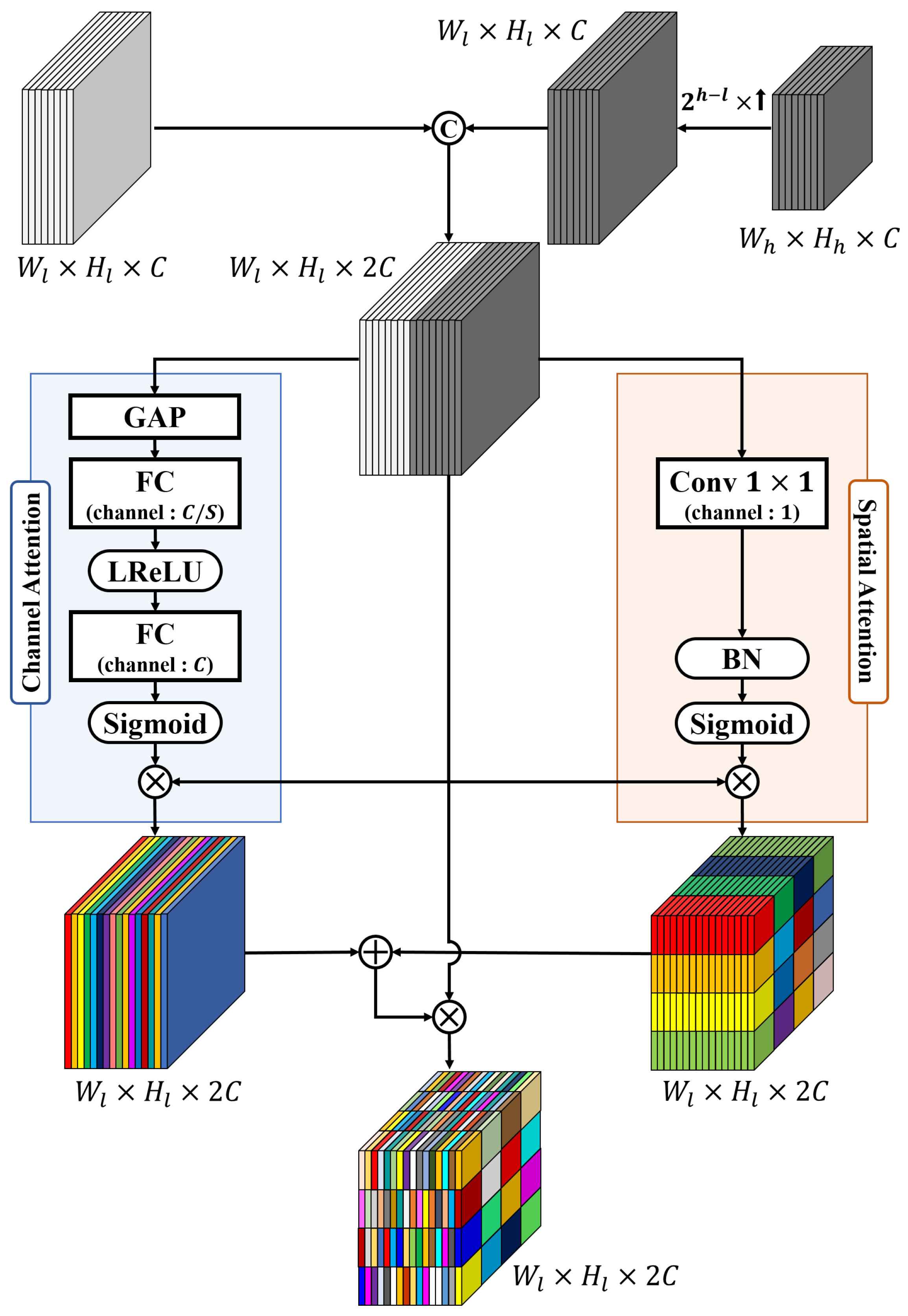
- Contextual information was obtained from the features extracted from the two backbone networks using the ASPP module. In addition, the attention module was applied to classify information according to the importance of features or spatial locations extracted from the color, saturation, and luminance information of the image. Features extracted from each level of the backbone network were mutually fused to create a final saliency map using RRM. Furthermore, bidirectional loss function was implemented to supervise the generation of the final saliency results.
- Five public salient object detection benchmarks were used in the experiment. Experimental results demonstrated that our proposed method achieved superior or comparable performance to the state-of-the-art methods.
2. Related Works
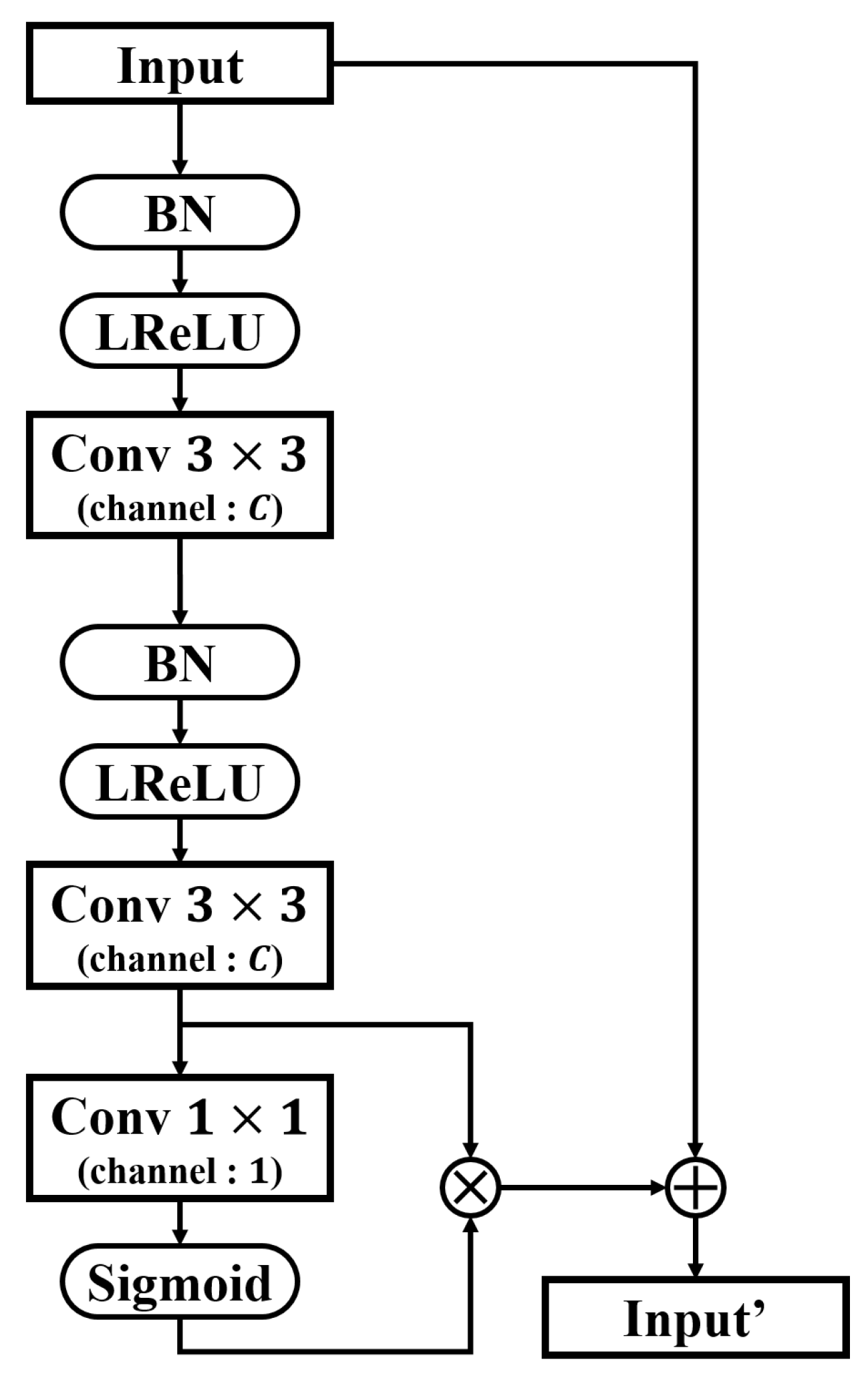
3. Proposed Methodology
3.1. Preprocessing for Additional Saliency Cues
3.2. Backbone
3.3. ASPP Module
3.4. Two Types of Attention Modules
3.5. RRM
3.6. Bidirectional Loss Function
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Comparison with State-of-the-Art Methods
4.4.1. Visual Comparison
4.4.2. Quantitative Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SOD | Salient object detection |
| FCN | Fully convolutional network |
| MCSNet | Multi-color space network |
| ASPP | Atrous spatial pyramid pooling |
| RRM | Residual refinement module |
| HVS | Human visual system |
| CNN | Convolutional neural network |
| FIT | Feature integration theory |
| HED | Holistically-nested edge detection |
| CSC | Color space converter |
| FC layer | Fully connected layer |
| LReLU | Leaky rectified linear unit |
| BN | Batch normalization |
| SAM | Serial attention module |
| GAP | Global average pooling |
| PAM | Parallel attention module |
| PR curve | Precision-recall curve |
| MAE | Mean absolute error |
References
- Li, J.; Gao, W. Visual Saliency Computation: A Machine Learning Perspective; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Donoser, M.; Urschler, M.; Hirzer, M.; Bischof, H. Saliency driven total variation segmentation. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 817–824. [Google Scholar]
- Gao, Y.; Wang, M.; Tao, D.; Ji, R.; Dai, Q. 3-D object retrieval and recognition with hypergraph analysis. IEEE Trans. Image Process. 2012, 21, 4290–4303. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Frintrop, S.; Sihite, D.N.; Itti, L. Adaptive object tracking by learning background context. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 23–30. [Google Scholar]
- Siagian, C.; Itti, L. Rapid biologically-inspired scene classification using features shared with visual attention. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 300–312. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Zhang, L. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. IEEE Trans. Image Process. 2009, 19, 185–198. [Google Scholar]
- Lee, K.J.; Wee, S.W.; Jeong, J.C. Pre-filtering with Contents-based Adaptive Filter Set for High Efficiency Video Coding Standard. In Proceedings of the IEIE International Conference on Electronics, Information, and Communication 2017, Piscataway, NJ, USA, 19–20 May 2017; pp. 857–860. [Google Scholar]
- Katsuki, F.; Constantinidis, C. Bottom-up and top-down attention: Different processes and overlapping neural systems. Neuroscientist 2014, 20, 509–521. [Google Scholar] [CrossRef]
- Wolfe, J.M. Guidance of visual search by preattentive information. Neurobiol. Atten. 2014, 101–104. [Google Scholar] [CrossRef] [Green Version]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Estrada, F.; Wils, P.; Süsstrunk, S. Salient region detection and segmentation. In Proceedings of the International Conference on Computer Vision Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 66–75. [Google Scholar]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1915–1926. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Meur, L.; Luo, S. Superpixel-based saliency detection. In Proceedings of the 2013 14th International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), Paris, France, 3–5 July 2013; pp. 1–4. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [Green Version]
- Baluch, F.; Itti, L. Mechanisms of top-down attention. Trends Neurosci. 2011, 34, 210–224. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Saliency detection with recurrent fully convolutional networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 825–841. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 202–211. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, feedback and focus for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Ullah, I.; Jian, M.; Hussain, S.; Guo, J.; Lian, L.; Yu, H.; Shaheed, K.; Yin, Y. DSFMA: Deeply supervised fully convolutional neural networks based on multi-level aggregation for saliency detection. Multimed. Tools Appl. 2021, 80, 7145–7165. [Google Scholar] [CrossRef]
- Song, D.; Dong, Y.; Li, X. Hierarchical Edge Refinement Network for Saliency Detection. IEEE Trans. Image Process. 2021, 30, 7567–7577. [Google Scholar] [CrossRef] [PubMed]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3085–3094. [Google Scholar]
- Mun, H.; Yoon, S.M. A Study on Various Attention for Improving Performance in Single Image Super Resolution. J. Broadcast Eng. 2020, 25, 898–910. [Google Scholar]
- Navalpakkam, V.; Itti, L. An integrated model of top-down and bottom-up attention for optimizing detection speed. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2049–2056. [Google Scholar]
- Garcia-Diaz, A.; Fdez-Vidal, X.R.; Pardo, X.M.; Dosil, R. Decorrelation and distinctiveness provide with human-like saliency. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Antwerp, Belgium, 18–21 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 343–354. [Google Scholar]
- Zhang, L.; Gu, Z.; Li, H. SDSP: A novel saliency detection method by combining simple priors. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 171–175. [Google Scholar]
- Itti, L.; Dhavale, N.; Pighin, F. Realistic avatar eye and head animation using a neurobiological model of visual attention. In Proceedings of the Applications and Science of Neural Networks, Fuzzy Systems, and Evolutionary Computation VI, San Diegok, CA, USA, 14–19 September 2003; SPIE: Bellingham, WA, USA, 2003; Volume 5200, pp. 64–78. [Google Scholar]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Li, J.; Tian, Y.; Huang, T.; Gao, W. Probabilistic multi-task learning for visual saliency estimation in video. Int. J. Comput. Vis. 2010, 90, 150–165. [Google Scholar] [CrossRef]
- Milanese, R. Detecting Salient Regions in an Image: From Biological Evidence to Computer Implementation. Ph.D. Thesis, The University of Geneva, Geneva, Switzerland, 1993. [Google Scholar]
- Hamker, F.H. The emergence of attention by population-based inference and its role in distributed processing and cognitive control of vision. Comput. Vis. Image Underst. 2005, 100, 64–106. [Google Scholar] [CrossRef]
- Tsotsos, J.K.; Culhane, S.M.; Wai, W.Y.K.; Lai, Y.; Davis, N.; Nuflo, F. Modeling visual attention via selective tuning. Artif. Intell. 1995, 78, 507–545. [Google Scholar] [CrossRef] [Green Version]
- Kootstra, G.; Nederveen, A.; De Boer, B. Paying attention to symmetry. In Proceedings of the British Machine Vision Conference (BMVC2008), The British Machine Vision Association and Society for Pattern Recognition, Leeds, UK, 1–4 September 2008; pp. 1115–1125. [Google Scholar]
- Parkhurst, D.; Law, K.; Niebur, E. Modeling the role of salience in the allocation of overt visual attention. Vis. Res. 2002, 42, 107–123. [Google Scholar] [CrossRef] [Green Version]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3Net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Menlo Park, CA, USA, 2018; pp. 684–690. [Google Scholar]
- Hu, X.; Zhu, L.; Qin, J.; Fu, C.W.; Heng, P.A. Recurrently aggregating deep features for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse attention for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect globally, refine locally: A novel approach to saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3127–3135. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive attention guided recurrent network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 714–722. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Chen, Z.; Xu, Q.; Cong, R.; Huang, Q. Global context-aware progressive aggregation network for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10599–10606. [Google Scholar]
- Qu, L.; He, S.; Zhang, J.; Tian, J.; Tang, Y.; Yang, Q. RGBD salient object detection via deep fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Chen, H.; Liu, N.; Yan, C.; Li, X. CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion. IEEE Trans. Cybern. 2017, 48, 3171–3183. [Google Scholar] [CrossRef] [PubMed]
- Piao, Y.; Ji, W.; Li, J.; Zhang, M.; Lu, H. Depth-induced multi-scale recurrent attention network for saliency detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7254–7263. [Google Scholar]
- Chen, H.; Li, Y.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Recommendation, ITURBT. 709-6: Parameter Values for the HDTV Standards for Production and International Programme Exchange; Basic parameter values for the HDTV standard for the studio and for international programme exchange, now ITU-R BT; ITU: Geneva, Switzerland, 2015. [Google Scholar]
- Munsell, A.H. A Color Notation; GH Ellis Company: Indianapolis, IN, USA, 1907; Volume 1. [Google Scholar]
- Munsell, A.H. A pigment color system and notation. Am. J. Psychol. 1912, 23, 236–244. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Mohammadi, S.; Noori, M.; Bahri, A.; Majelan, S.G.; Havaei, M. CAGNet: Content-aware guidance for salient object detection. Pattern Recognit. 2020, 103, 107303. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Shi, J.; Yan, Q.; Xu, L.; Jia, J. Hierarchical image saliency detection on extended CSSD. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 717–729. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the Saliency Detection by Multi-Context Deep Learning, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Layer | Size | Channel | Kernel Size | Stride | ||
|---|---|---|---|---|---|---|---|
| Input | Output | Input | Output | ||||
| L1 | Conv1-1 | 3 | 64 | 1 | |||
| Conv1-2 | 64 | 64 | 1 | ||||
| MaxPool | 2 | ||||||
| L2 | Conv2-1 | 64 | 128 | 1 | |||
| Conv2-2 | 128 | 128 | 1 | ||||
| MaxPool | 2 | ||||||
| L3 | Conv3-1 | 128 | 256 | 1 | |||
| Conv3-2 | 256 | 256 | 1 | ||||
| Conv3-3 | 256 | 256 | 1 | ||||
| MaxPool | 2 | ||||||
| L4 | Conv4-1 | 256 | 256 | 1 | |||
| Conv4-2 | 256 | 256 | 1 | ||||
| Conv4-3 | 256 | 256 | 1 | ||||
| MaxPool | 2 | ||||||
| L5 | Conv5-1 | 256 | 512 | 1 | |||
| Conv5-2 | 512 | 512 | 1 | ||||
| Conv5-3 | 512 | 512 | 1 | ||||
| Methods | DUT-OMRON | DUTS | ECSSD | HKU-IS | PASCAL-S | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | maxF↑ | MAE↓ | maxF↑ | MAE↓ | maxF↑ | MAE↓ | maxF↑ | MAE↓ | maxF↑ | |
| Amulet [20] | 0.0957 | 0.7537 | 0.0816 | 0.7835 | 0.0517 | 0.9254 | 0.0501 | 0.8991 | 0.0923 | 0.8527 |
| DGRL [49] | 0.0651 | 0.7827 | 0.0492 | 0.8324 | 0.0348 | 0.9356 | 0.0343 | 0.9198 | 0.0779 | 0.8649 |
| PAGR [50] | 0.0734 | 0.7790 | 0.0556 | 0.8530 | 0.0569 | 0.9331 | 0.0449 | 0.9230 | 0.0888 | 0.8712 |
| PiCANet [21] | 0.0655 | 0.8074 | 0.0495 | 0.8635 | 0.0405 | 0.9424 | 0.0419 | 0.9227 | 0.0783 | 0.8788 |
| RNet [43] | 0.0707 | 0.8079 | 0.0646 | 0.8233 | 0.0466 | 0.9346 | 0.0449 | 0.9143 | 0.0947 | 0.8475 |
| RADF [44] | 0.0701 | 0.7918 | 0.0704 | 0.8138 | 0.0603 | 0.9161 | 0.0508 | 0.9060 | 0.1009 | 0.8470 |
| RANet [45] | 0.0613 | 0.7904 | 0.0579 | 0.8374 | 0.0499 | 0.9285 | 0.0452 | 0.9154 | 0.0968 | 0.8504 |
| BASNet [51] | 0.0556 | 0.8182 | 0.0197 | 0.9499 | 0.0331 | 0.9467 | 0.0306 | 0.9323 | 0.0795 | 0.8682 |
| CPD-ResNet50 [47] | 0.0636 | 0.7685 | 0.0323 | 0.9195 | 0.0409 | 0.9299 | 0.0437 | 0.9046 | 0.0851 | 0.8403 |
| CPD-VGG16 [47] | 0.0575 | 0.7757 | 0.0226 | 0.9387 | 0.0355 | 0.9332 | 0.0363 | 0.9186 | 0.0778 | 0.8609 |
| PFANet [30] | 0.0763 | 0.7801 | 0.0716 | 0.8677 | 0.0766 | 0.8816 | 0.0604 | 0.8853 | 0.1189 | 0.8173 |
| PoolNet [22] | 0.0549 | 0.8183 | 0.0400 | 0.8783 | 0.0332 | 0.9468 | 0.0298 | 0.9338 | 0.0762 | 0.8772 |
| GCPANet [52] | 0.0553 | 0.8196 | 0.0370 | 0.8865 | 0.0308 | 0.9521 | 0.0295 | 0.9404 | 0.0638 | 0.8899 |
| MCSNet | 0.0518 | 0.8294 | 0.0363 | 0.9224 | 0.0322 | 0.9507 | 0.0313 | 0.9394 | 0.0723 | 0.8842 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Jeong, J. Multi-Color Space Network for Salient Object Detection. Sensors 2022, 22, 3588. https://doi.org/10.3390/s22093588
Lee K, Jeong J. Multi-Color Space Network for Salient Object Detection. Sensors. 2022; 22(9):3588. https://doi.org/10.3390/s22093588
Chicago/Turabian StyleLee, Kyungjun, and Jechang Jeong. 2022. "Multi-Color Space Network for Salient Object Detection" Sensors 22, no. 9: 3588. https://doi.org/10.3390/s22093588
APA StyleLee, K., & Jeong, J. (2022). Multi-Color Space Network for Salient Object Detection. Sensors, 22(9), 3588. https://doi.org/10.3390/s22093588