1. Introduction
With the evolution of technology, people’s lives are surrounded by a greater number of IoT devices. Data in IoT are also growing exponentially. If all this traffic is handed over to the cloud, the computing pressure on the cloud will be enormous [
1]. Therefore, fog computing has arisen, first, to use the idle resources of IoT devices, second, to reduce the flow of cloud center network, and third, to reduce the delay of tasks. So far, fog network has been widely applied, including to the Internet of vehicles, smart buildings, smart cities, and industrial automation. A large number of application scenarios produce a large number of task requirements [
2,
3,
4]. Among them, delay-sensitive tasks pose a great challenge to the computing capability of nodes. If the task cannot be completed within the specified time, it will be meaningless even if the task is completed. Therefore, the task needs to be offloaded into the fog network, and the nodes in the fog network can help the calculations [
5].
The emergence of fog computing provides a solution to this kind of problem. Especially for delay-sensitive tasks, it can meet the needs of applications with high requirements on computing resources and delay, such as AR and online games. These are requirements that the cloud cannot solve, so we use fog networking to help cloud computing. A typical fog computing system consists of a set of fog nodes at different locations. These nodes are deployed on the periphery of the network and have flexible resource configurations such as storage, computing, and network bandwidth [
6]. If the cloud is far from the edge node, the link connected to the cloud may not be reliable, which also causes a lot of delay. Therefore, in many cases, it does not make sense to put edge tasks in the cloud [
7]. Hence, fog computing maximizes efficiency by offloading and distributing the workload of terminal equipment and fog nodes, while minimizing energy consumption and ensuring delay.
Generally speaking, the energy consumption required for processing a task is the sum of the transmission time, transmission power, and processing capability of computing devices. In addition, the transmitted power combines channel state, such as the available bandwidth and data transfer rate. Thus, higher transmission rates can be achieved by increasing transmission power, which also reduces transmission time, but results in a greater energy consumption. Therefore, energy emissivity can be controlled by balancing transmission power and transmission time to achieve the lowest energy consumption while meeting the task delay requirement. The optimal task scheduling strategy should always control this balance and improve the transmission rate when the task delay requirement is high or reduce the transmission rate when the task delay requirement is low to achieve the energy-saving purpose [
8].
In order to solve the above problems effectively, we use a Lyapunov optimization method and Lyapunov drift theory. The reason for using this method is that constraint optimization of the mean can be achieved in a stochastic system without the need to estimate random events that will occur in the future. The method first lists the constraints in the system and then builds a virtual queue. To optimize the objective function in each time slot, a drift-plus-penalty weight parameter is introduced. The reason for adding weights is to use this parameter to control the balance between drift and optimization.
Although Lyapunov optimization function can guarantee the stability of virtual queue, this method is not suitable for the bandwidth limitation and computing resource limitation of task offloading and processing in a fog network, because it has to be adapted to meet our needs. Therefore, we designed the PSO algorithm based on a Lyapunov optimization framework.
Our contributions to this paper are as follows:
The concept of pro-node is proposed and our proposed LPSO algorithm is used to optimize it.
A virtual queue is designed, and the optimization objective function is converted into the utility function under the Lyapunov framework. In addition, the balance between transmitting power and computing resource allocation can be achieved while ensuring queue stability and delay.
We evaluate our proposed strategy by comparing it with different algorithms. In the case of tasks with delay constraints, our proposed method performs better in various QoS parameters, including energy consumption, computing resource, and channel output coefficient.
The following parts of this paper are organized as follows:
Section 2 introduces related work.
Section 3 introduces our system model and the process of problem formulation.
Section 4 mainly analyzes the problem, transforms it into a Lyapunov optimization problem and calculates its upper bound.
Section 5 shows the algorithm we designed.
Section 6 mainly compares the performance of LPSO with other algorithms. Finally,
Section 7 is our conclusion and some expectations for future work.
2. Related Work
In recent years, many people have been interested in fog computing and edge computing and have also done a lot of related research. Ramadan et al. [
9] proposed an energy-saving framework for fog networks based on multireceiver wireless sensor networks. They used two greedy algorithms to solve the multireceiver deployment problem of Harris hawks optimizer (Hho) and modified Harris hawks optimizer (Mhho), introducing the connection problem of wireless sensor networks (WSN) with fog network through a set of sink nodes (SNs). Arshed et al. proposed a resource-aware scheduler to assign incoming application modules to fog devices by placing application modules from the fog layer to the cloud instead of sending them directly to the cloud. Their placement strategy reduced the cost of using cloud resources with minimal execution time and minimal bandwidth usage [
10]. Lin et al. [
11] proposed a mathematical model for the multiterminal computing offloading problem, optimized the long-term average response delay objective under the constraints of long-term computing and energy consumption, and used the perturbation technique of the Lyapunov optimization method to convert the original problem into a deterministic cap problem. Moreover, a distributed optimization algorithm was used to solve the upper bound problem per time slot, where each IoT device exchanges a limited amount of information with its associated edge nodes and decides on its own for resource allocation and computing offloading.
Liao et al. [
12] used Directed Acyclic Graph (DAG) technology in the edge computing scheme to model the scheduling problem of application-dependent mobile tasks in the application of the allocation and scheduling of complex application-dependent applications and proposed a priority quantification method for application-dependent applications, considering the data volume, effort, deadlines, and dependencies. The estimated priorities were used as heuristics for task assignment and scheduling, effectively solving the NP-hard joint optimization problem.
Wang et al. [
13] proposed a computing offloading architecture consisting of multiple fog nodes with heterogeneous communication and computational capabilities and a cloud center. They model dynamic communication and computing resources as two dynamic queues for recording resource availability and improving resource utilization. The whole problem was decomposed into channel power control and task assignment problems. A modified branch-and-bound method was used to solve the task assignment problem without considering resource availability. Then, they checked the resource availability to refine it with the knapsack problem.
Ren et al. [
14] optimized virtual placeholders for all queues in a distributed fashion to create sufficient queue variance and activated Lyapunov optimizations under an infinite buffer setting. They proved that the optimal virtual placeholder was a new three-layer shortest-path problem and solved it by the Bellman–Ford algorithm.
Chang et al. [
15] proposed a dynamic optimization scheme for an IoT fog computing system with multiple Mobile Devices (MDs) and utilized Lyapunov optimization to design an online dynamic algorithm to solve the joint optimization problem between a mobile device with harvesting energy and a fog node. Specifically, with the objective to minimize the system overhead related to delay, energy consumption, they proposed a joint computation offloading and channel resource allocation algorithm based on Lyapunov optimization, through minimizing the derived upper bound of the Lyapunov drift-plus-penalty function and dividing the main problem into several subproblems at each time slot and addressing them accordingly.
Mukherjee et al. [
16] studied the optimum scheduling policy of the two-queue system in a fog node that allows a higher number of deadline-aware offloaded tasks to be processed while making both queues stable. The proposed approach was decoupled into two strategies: the priority-aware scheduling policy applying the Lyapunov drift-plus-penalty function and the fog nodes collaboration based on each fog node’s queueing status under the scheduling policy. The authors could effectively solve the problem of task completion rate.
Zhang et al. [
17] studied resource scheduling for delay minimization in multiserver cellular edge computing systems. The traditional method defines queue-length-based Lyapunov functions and designs scheduling algorithms which solve the corresponding queue length control problem.
The experiments of Ren et al. were more ideal, as the buffer was not infinite, and they also reduced the delay but did not take into account the optimization of delay-sensitive tasks and the grade of completion of delay-sensitive tasks. In the research of Chang et al., only the energy consumption was optimized without considering the limit of task delay. Mukherjee et al. did not consider the energy consumption. In this paper, we study the combination of channel power and computing resource issues in edge computing networks, where multiple end-users (IoT devices) are considered to generate variable traffic loads. The goal is to minimize long-term system execution overhead when channel resources, computing resources, and task execution time are all limited. By extending the Lyapunov optimization, we transform the original problem into an upper-bound problem and design a scalable distributed algorithm. The symbols used in the paper are defined in
Table 1.
3. System Model
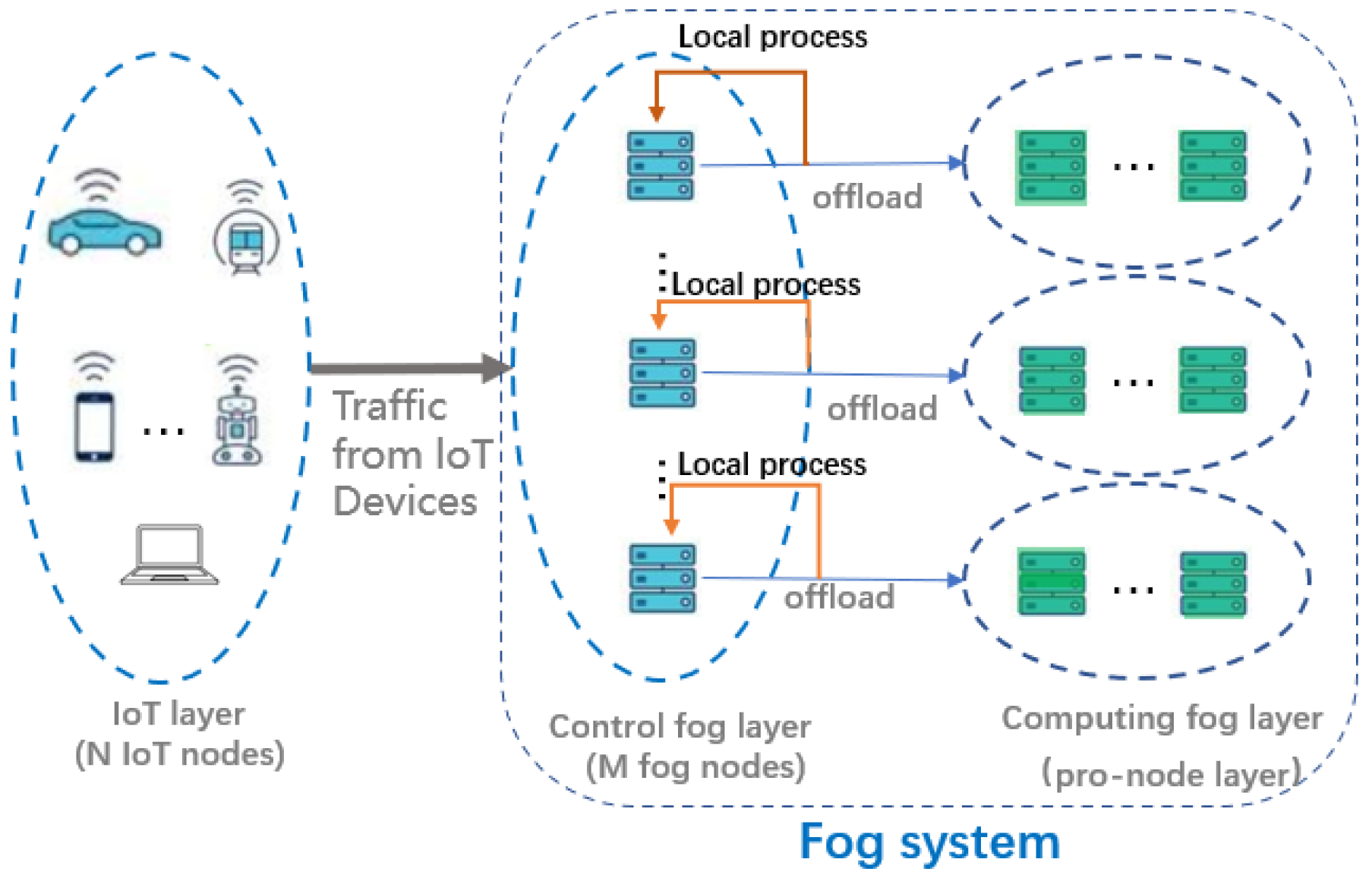
As shown in
Figure 1, our system is modeled by a set
N = {1, 2, …,
Ni} consisting of
N IoT nodes, and a set
M = {1, 2, …,
Mj} consisting of
M fog nodes, and pro-nodes connected to the fog nodes. Tasks are randomly generated at each IoT node, and their arrivals are assumed to be independently and identically distributed. Then, in the long time case, the arrival of tasks can be considered as following the Poisson distribution. Therefore, we adopt M/M/1 as the upload queue model for the tasks. In this section, we propose a dynamic algorithm based on the Lyapunov optimization to solve the problem. The Lyapunov optimization is considered an efficient tool for designing online control algorithms without any prior knowledge [
18,
19,
20]. However, since the power consumption is time-dependent, the decision sets in different time slots are not independently and identically distributed. Therefore, we advocate additional perturbation methods [
19] to solve this problem.
3.1. Transmission Model
According to Shannon’s equation, the transmission rate of data transmitted from IoT nodes to fog nodes can be described as
where denote the transmission power,
is the channel gain,
W denotes the bandwidth,
N0 denotes the noise, and
denotes the transmission rate from
i to
j at time
t. From the M/M/1 average delay formula [
20], the uplink delay (including queuing and transmission time) can be given by the following equation
where
τc denotes the delay of transmission, α is the ratio of offloading, and
Di denotes the average data size of task
i. Consider that if the total data size transmitted is constant and it is used to obtain the transmission rate, then it is not necessary to consider the length of an individual packet which does not affect the optimal decision and the optimal solution.
3.2. Energy Consumption Model
First is the energy consumption model for local processing, where the local task queue is in the M/M/1 model, and according to [
20] the local computational delay
can be expressed as the following equation:
λi denotes the arrival rate of task
i,
σ denotes the standard deviation of the task size,
Fi denotes the compute capability of
i, and
Di means the value of the task size for device
i. Therefore, the total energy consumed,
, by performing its tasks is
where
means the energy consumed by IoT device
i,
t is the time slot,
means a parameter that depends on the deployed hardware and is measurable in practice [
18].
We divide the latency tasks into two categories. The first category of delay-sensitive tasks requires a latency less than
τ1, and just a single node can satisfy its computation requirements, such as the local process in
Figure 1.
The second category of delay-sensitive tasks requires a latency less than
τ2, and the compute capability of one node alone cannot meet its latency requirements, so it needs to be offloaded to the pro-node and use the pro-node for joint computation, such as the offload in
Figure 1.
Let the vector τ = [τ1, τ2].
For the first type of delay-sensitive tasks, its total energy consumption
can be expressed as
where
means the energy consumed by fog node
j that can be calculated as
.
means the energy consumption of device
i to transfer tasks to
j.
M denotes the set of IoT nodes, and
N denotes the set of fog nodes.
For the second type of delay-sensitive tasks, its total energy consumption
can be expressed as
where
means the energy consumed by subnode
s in the pro-node that can be expressed as
.
3.3. Problem Formulation
In this section, we optimize the total energy consumption
using the Lyapunov method. Here, we only prove that
and
can be obtained in the same way. Our objective is to minimize the energy consumption
. Here, we use
to express
. Therefore, the whole optimization problem can be transformed into a Lyapunov optimization problem, i.e., to ensure that the energy consumption of the average time slot is minimum:
The objective of P1 is to minimize the long-term average energy consumption of all IoT devices. The decision variables are the offload fraction , the computing resource allocation , the transmit power per time slot , and (or ), where i ∈ N. In P1, the decision variables α are influenced by the size of the tasks, the processing delay requirements, the channel bandwidth, the computational capability of , , and the transmit power of the IoT nodes. In this paper, we assume that the time slots are of the same length.
The constraint in P1 limits the computational capability allocated to the task from device i (8) and the transmission speed of device i (9) as well as the processing delay in the long term (10). In the long term, constrained by the computational capability of , the computational capability allocated by to device i should be less than the computational capability of itself. The size of the channel bandwidth occupied by the task should be smaller than the total channel bandwidth in the long term, due to the limitation of the device i’s own transmission speed. If the task can be processed locally, then only the energy consumption of needs to be calculated.
4. Upper-Bound Analysis Based on Lyapunov Optimization
To solve P1, we convert it into a Lyapunov optimization problem and solve it using our proposed PSO algorithm based on the Lyapunov framework.
4.1. Setting up Virtual Queues
In Lyapunov optimization, the satisfaction of the long-term average constraint is equal to the rate stability of the virtual queue. Specifically, a virtual queue is provided to replace the computing resource constraint at the edge nodes (8), and
A(
t) denotes the random process of the length of the virtual queue
A at time slot
t [
14].
B(
t) and
C(
t), represent the channel constraint (9) and the computational delay constraint (10), respectively. Specific forms of
A(
t),
B(
t) and
C(
t) can be expressed as the following equations
It is not difficult to find that in Equation (14a), if the request from i is larger than the computational capability of , then queue A will get longer and longer and finally cause blocking, and vice versa, its queue will not increase. Queue B(t + 1) (14b) represents the next time slot of the B(t) state, i.e., the existing channel bandwidth occupation queue plus the channel bandwidth occupation of each node, then subtracting the total bandwidth yields the bandwidth occupation of the next time slot. Similarly to B(t + 1), C(t + 1) (14c) also represents the next time slot of the C(t) state, i.e., adding the upcoming delay to the existing delay queue, and then subtracting the delay requirements yields the delay queue of the next time slot. The initialization of virtual queues A, B and C consists in setting them to 0.
If virtual queue
A is rate-stable, then by the definition of [
19], only
can satisfy the restriction (8). Virtual queue
B and virtual queue
C can be obtained in the same way. The proof is as follows:
First, we prove that virtual queue
A is stable:
For
, there exists
If
A(0) = 0, then we can find that
Therefore, queue A is stable, and similarly, queue B and queue C are stable, so virtual queues A, B, and C can satisfy constraints (8), (9), and (10), respectively.
The proof is complete.
Using the above proof, we can convert P1 to P2:
4.2. Setting the Drift-Plus-Penalty
We use the Lyapunov drift-plus-penalty [
21] to solve for P2. According to [
21], we first set up the virtual queueing vector.
With stable rates across queues, P2 can then be converted to P3, because the original problem with a long-term average objective and constraints can be approximated to a problem with a drift-plus-penalty.
For convenience, here we assume that
Hence, P3 can be expressed as:
where
V denotes the weight of the objective function,
denotes the drift of the queue, i.e., the stability performance of the queue.
Next, we show the specific form in preparation for P4 to find the upper bound. First, we show the proof of
.
Here, the value
D1, which is fixed, can be expressed as
Here, the value
D2, which is fixed, can be expressed as
The proof of queue
C’s drift is as follows.
Here, the value D3, which is fixed, can be expressed as .
Therefore, the P3 problem can be expanded to generate the P4 problem as follows:
Assume that P4 has an upper bound, and its upper bound is the constant
C. First, we have to prove that virtual queue
A, virtual queue
B, and virtual queue
C are stable. The proof is as follows.
Let
, then we can get
Therefore, its queues are stable, so it is possible to use an approximate analysis to analyze the upper bound of P4.
4.3. Proof of the Upper-Bound Calculation
Previously, we proved that P4 was upper-bounded, so next, we try to find its specific value. First, substituting the computational drift into the formula, we prove that
where
is the upper bound of P4, and the Lyapunov drift-plus-penalty [
21] enables the problem to be solved optimally within a certain range of deviations.
By moving
to the right and dividing by
V at the same time, the original expression can be converted to the following inequality.
Next, we unfold
to obtain the upper bound
The proof is complete.
5. Algorithm Design
Based on the theoretical proof, we designed the PSO algorithm under the Lyapunov framework (LPSO) and used Algorithms 1 and 2 to solve P4.
| Algorithm 1 LPSO for Task Type 1 |
![Sensors 22 03527 i001]() |
Line 1: Initialize the required parameters in the IoT device, such as the controlling parameter V, iterations, population size.
Line 3–7: For all tasks, calculate the value of P* by node.
Line 8–16: Compare each calculated value and choose the minimum value to update the queue until it remains stable.
| Algorithm 2 LPSO for Task Type 2 |
![Sensors 22 03527 i002]() |
Line 1: Initialize the required parameters in the IoT device, such as the controlling parameter V, iterations, population size.
Line 3–7: For all tasks, calculate the value of P* by the pro-node
Line 8–16: Compare each calculated value and choose the minimum value to update the queue until it remains stable.
The difference between Algorithms 1 and 2 is that Task 2 requires scheduling more nodes to perform the computation.
6. Numerical Results
In this section we simulated the construction of a fog environment consisting of
N = {1, 5, 10} and
M = 2. The
N IoT nodes were randomly distributed around the coverage area of the fog nodes. We used the experimental setup of [
8] with a channel bandwidth of
W = 5 MHz and background noise
N0 = −100 dm. The specific parameters in the experiments are shown in
Table 2. The configuration of our simulation machine was an Intel Core i7-10200H CPU, RAM 32 GB system with Windows 10. The simulation platform used in this article was EdgeCloudSim.
We studied the relationship between the number of different IoT nodes and the energy consumption in
Figure 2. Here, the LPSO parameters we chose to calculate are the task standard deviation
, the weight
V = 50, the arrival rate
. The average energy consumption grows with the number of IoT nodes, because as the number of nodes increases, the number of arrivals of random tasks also increases, thus the average energy consumption of the three algorithms also increases. With the same number of nodes, we can see that LPSO has the lowest average energy consumption, PSO has the middle energy consumption, and the greedy algorithm has the highest energy consumption. Since in the same situation, compared to PSO, LPSO increases the control of virtual queues (including channel virtual queues, computing resource virtual queues), the realization of LPSO is better than that of PSO.
We also studied the average energy consumption of LPSO for different weights V in
Figure 3. The performance varies at different weights, with the highest energy consumption at
V = 1 and the lowest energy consumption at
V = 50, where
V is the weight parameter for energy consumption, and a larger value of
V means that the energy consumption value has a greater impact on the objective value. This is because when the value of
V increases, a small decrease in energy consumption leads to a large decrease in the value of the objective function, and then the optimization process tends to reduce the value of the energy consumption, which leads to a lower value of the objective function. In the experiments, we considered the standard deviation
and the arrival rate
.
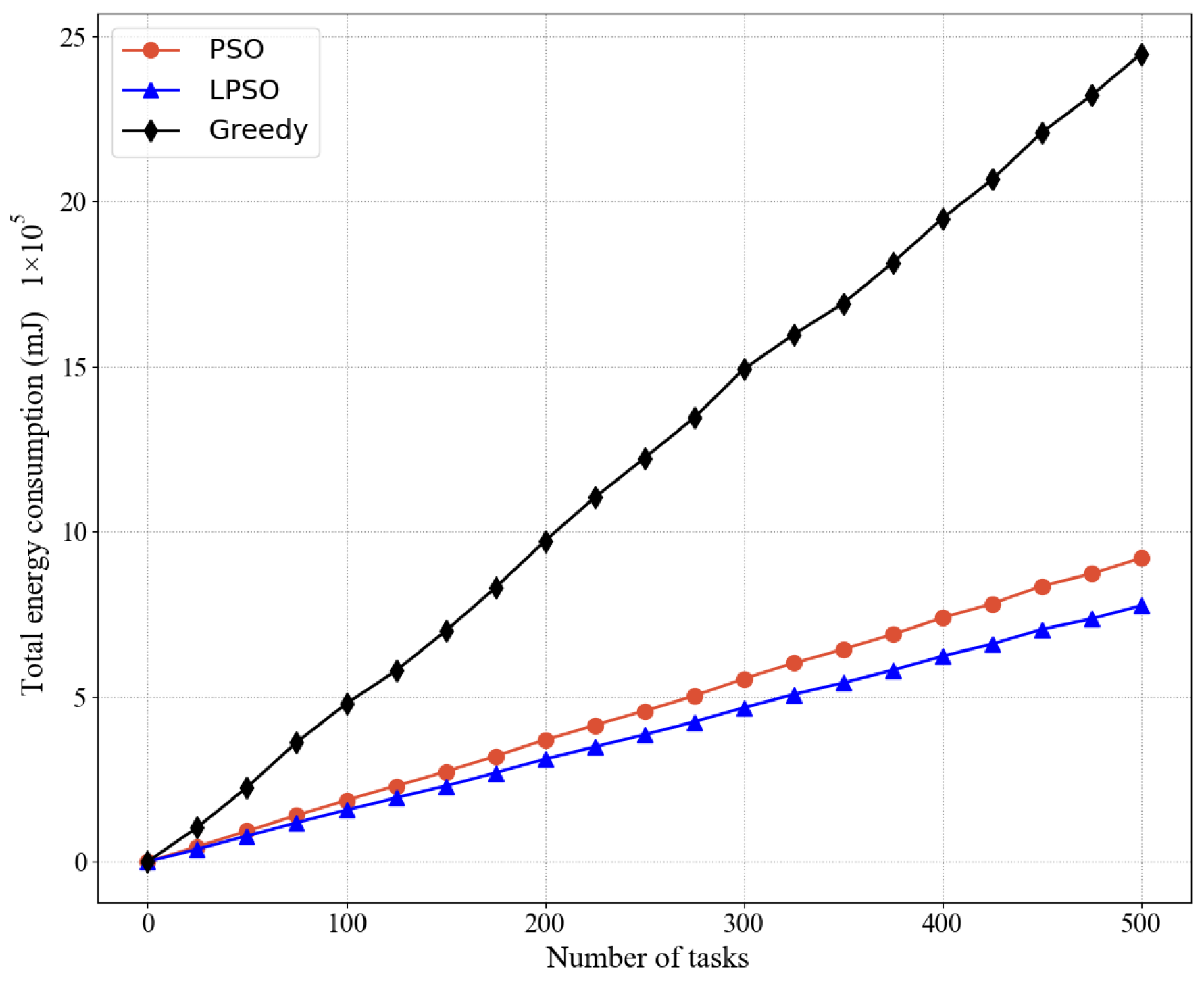
Figure 4 and
Figure 5 show the comparison between LPSO, PSO, and the greedy algorithm for the same number of nodes and other cases, including the total energy consumption and average energy consumption, where our proposed LPSO outperforms the other two. Because the measure taken by the greedy algorithm is to complete all task requests as much as possible, the power of all devices is set to the maximum based on the greedy algorithm. PSO is more reasonable for resource allocation than the greedy algorithm. Compared with the greedy algorithm, PSO pays more attention to the rationality of resource utilization. On the basis of PSO, LPSO increases the control of computing resources and channel resources, thus LPSO performs better than PSO and the greedy algorithm.
In addition, we also compared the energy consumption of LPSO for different arrival rates, as shown in
Figure 6, and as expected, the higher the value of the arrival rate
, the more energy is consumed. Here we set the weight
V = 50 because LPSO performs best at
V = 50. A higher arrival rate leads to more computational tasks competing for the limited network and computing resources, thus increasing the queuing time of the computing workload, which requires more computing resources to ensure that it can be completed within the specified time.
Finally,
Figure 7 shows the completion degree of different algorithms under different arrival rates. When all conditions are the same, including the number of nodes, task size, and task delay, we can compare LPSO and the other algorithms in the number of tasks completed at different task arrival rates. LPSO performs better than PSO because PSO only considers the most ideal resource allocation scenario (i.e., each task just has to match its requirements), which causes the queue to block. This leads to an increase in queuing time, and LPSO combines the optimization of computing resources and channel resources in the case of a long time, where every time slot maximizes the use of resources while keeping the queue stable. Moreover, the reason why the greedy algorithm does not complete tasks on time is because it completes as many tasks as possible; in other words, all the equipment power is turned on to the maximum, and the energy consumption is exchanged for the number of completed tasks.
7. Conclusions
The Lyapunov-based PSO algorithm we designed achieved a balanced distribution of transmission power and computing resources through the control of channel resources and computing resources and minimized the energy consumption value while ensuring that as many tasks as possible were completed. Comparing LPSO and PSO, our algorithm was better than the original PSO algorithm and the greedy algorithm in the performance index of energy consumption required to complete the task. The number of tasks completed was slightly lower than that of the greedy algorithm, because the greedy algorithm used a larger amount of energy than the LPSO algorithm to achieve its result, which obviously outweighed the gains. Regarding future work, we will set up nodes without mobility and fog nodes without energy constraints, as some tasks may not be completed if there are energy constraints. We hope to increase these constraints in future work, and further increase the number of tasks completed. Furthermore, regarding the task decomposition, since some subtasks might have a sequential relationship of backward and forward processing, we consider using a directed acyclic graph (DAG) in future work.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}