3.1. Priority-Based Layered Decoding Schedule
In the layered schedule, the LLR in a layer has not been updated yet while the next layer needs this updated LLR. This is called pipeline conflict. When a pipeline conflict occurs, the practical method is to ignore the update of LLR. However, a small percentage of ignored updates will lead to significant performance degradation [
19]. For this reason, we propose a priority-based layered schedule.
In the layered schedule, the update of LLR can be equivalent to the sum of LLR and difference between the newly calculated check-to-variable messages in the current iteration and the one in the previous iteration [
15]. This difference can be understood as a gain that helps the decoding. The update of LLR can be expressed as (7)
where
represents the LLR for the variable node
v at the
it-th iteration in the
layer,
represents the check-to-variable messages at the
it-th iteration in the
layer and
represents the gain for the variable node
v at the
it-th iteration in the
layer.
In the priority-based layered schedule, when a pipeline conflict happens to two check nodes between two adjacent layers, and , new LLR will be updated in the layer . The gain will be calculated in the layer . The gain then will be added to the newly updated LLR later. In this way, updates of LLRs can be guaranteed no matter how the base graph matrix is dense.
Suppose there are three check nodes in layers , and connected to the same variable nodes. During decoding, pipeline conflicts happen between and , and .
The priority-based layered schedule works as follows. The LLR in layer
can update in priority and get
. Due to pipeline conflicts, the layer
reuses the old LLR value
to calculate the gain
. If the update of LLR in layer
can be done before decoding the layer
, then the layer
can update the value based on the result of
and the gain
can also be added to the updated LLR in layer
. As shown in
Figure 1, the update can be expressed as (8) and (9)
where the variable-to-check message at the
it-th iteration in the layer
is denoted as
.
3.2. Structure of the Priority-Based Layered LDPC Decoder with Double Update Queues
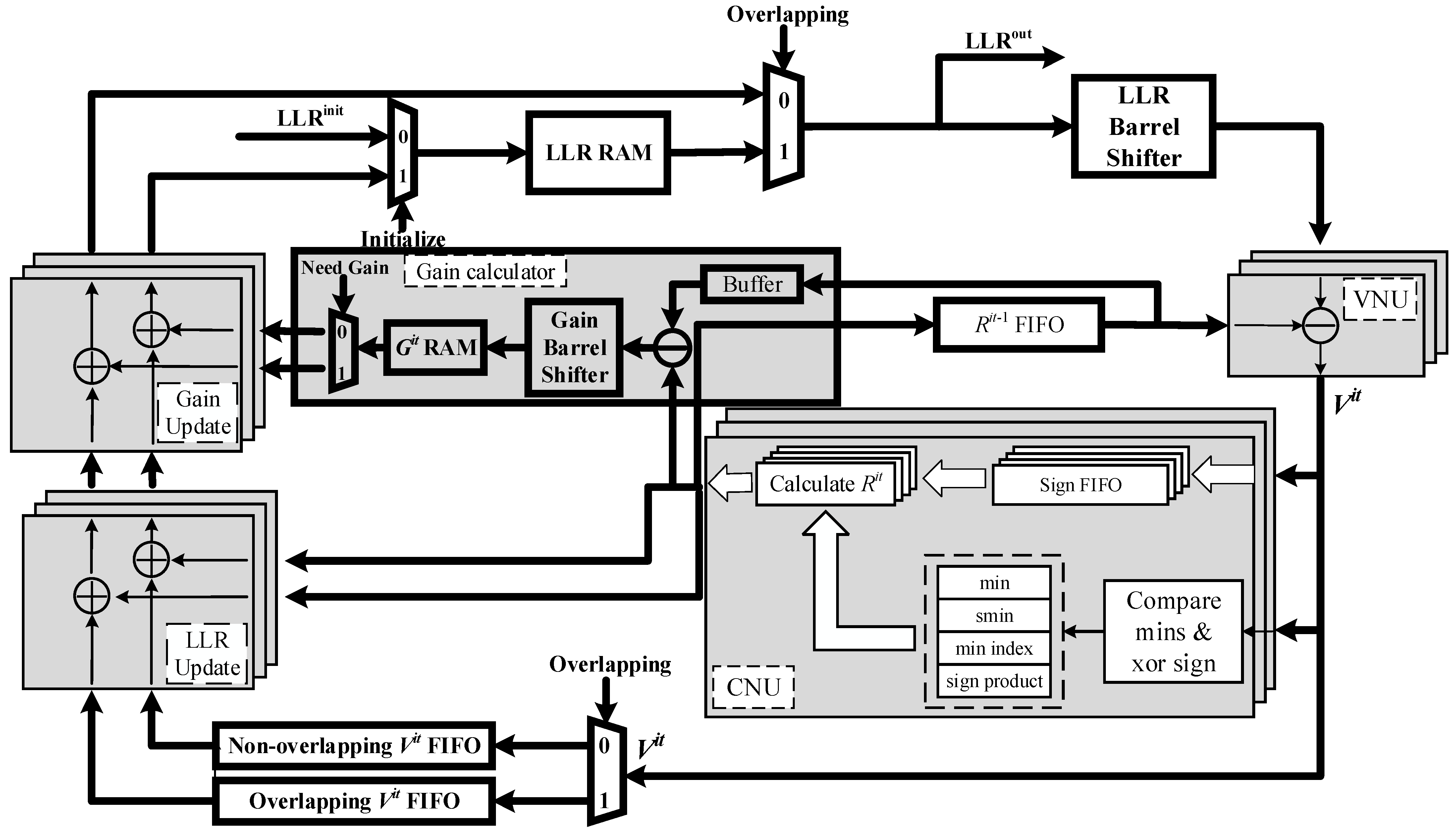
Figure 2 shows the detailed architecture of priority-based layered LDPC decoder with double update queues. The parallelism of processing units is equal to the size of submatrix in the corresponding PCM. In the WiMAX decoder, the parallelism is equal to 96 [
5]. In the 5G NR decoder, the parallelism is equal to 384 [
6].
Before decoding, LLRs are initialized and denoted as s. They are stored into the LLR RAM. LLR RAM is composed of a simple dual-port block RAM (BRAM) which is used to store the latest updated LLR. The old LLR value can be read repeatedly provided that no new LLR value is written in the same address. This feature is conductive to the implementation of the proposed decoding schedule.
When the decoding starts, LLR is read out from RAM according to the address given and sent to the LLR barrel shifter. It is not essential to use the reverse barrel shifter to shuffle the submatrix as the identity matrix before storing back to the LLR RAM [
20]. Instead, the barrel shifter that shuffles based on the absolute shift value can be well applied in the decoder. After shuffling, LLR is sent into variable node units (VNUs) to calculate
s. Then,
s are passed to the CNUs. At the same time,
s are buffered into FIFOs waiting for the update of LLR.
In the CNUs, the minimum (min) and the second minimum (smin) absolute value, the index of the minimum value (min index), and the sign product (sign product) of s are achieved. Then, registers will store this intermediate data until new s are required for update in the next layer. s generated from CNU are added with buffered out from FIFO and achieve the updated LLRs. When LLRs are updated, they are stored back to the LLR RAM.
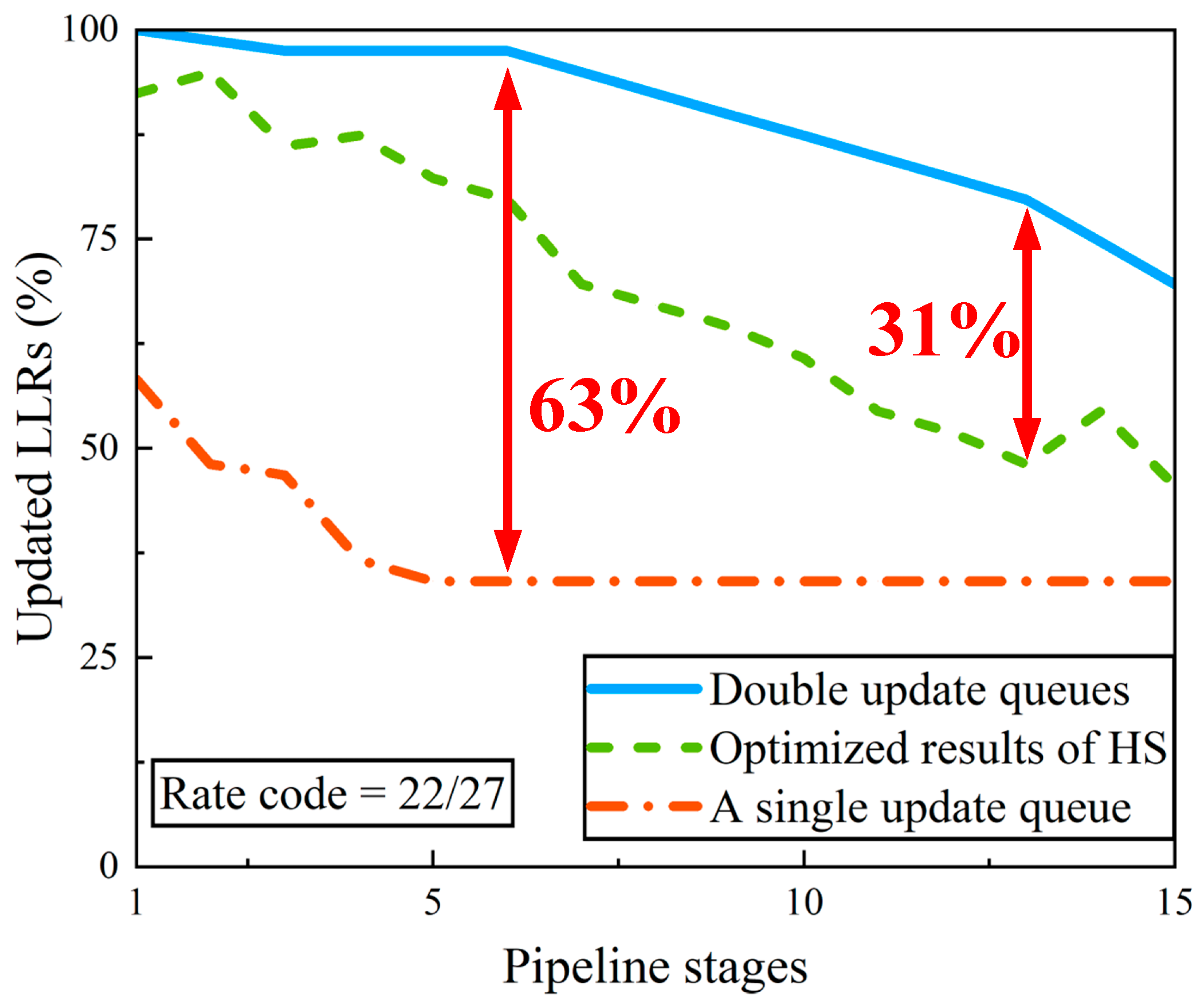
In this paper, we propose double update queues instead of a single update queue [
21] to update the LLRs. Compared with a single update queue, double update queues accelerate the update of LLRs in a layer and decrease the occurrence of pipeline conflicts. This will be discussed in detail in
Section 3.3.
When pipeline conflict happens, the gain calculator module and gain adder module are used to migrate the conflicts. These will also be discussed in detail combining with the flow chart in
Section 3.3.
Due to the design of priority-based schedule and double update queues, the signs of all the s are buffered into four separated FIFOs in the CNU. The two minimum values, the sign product and the index of the minimum are used to generate the for VNU used in the next iteration and s for overlapping submatrices, non-overlapping variable nodes (double update queues) and gain (priority-based schedule).
3.3. Double Update Queues
There are two reasons for pipeline conflicts in the layered decoder. The first reason is that the inserted pipeline stages result in the highly delayed update to LLRs. When increasing the operating frequency by inserting more pipeline stages, it will inevitably lead to conflict probability. The second reason is the failure to buffer the variable-to-check message out from FIFO and add it to the corresponding check-to-variable message to obtain the updated LLR when the next layer needs this LLR. In order to address this problem, it is necessary to increase the flexibility of data being buffered into FIFO and buffering out from FIFO. If variable-to-check messages in one layer can be stored in several FIFOs separately, then variable-to-check messages can be buffered out in time for the update of LLRs when the next layer needs them. In this way, pipeline conflicts can be eliminated. However, this consumes plenty of memory resources.
To trade off the memory resources and the possibility of pipeline conflicts, we proposed the double update queues. In the double update queues, we use two FIFOs to buffer variable-to-check messages. One FIFO is called overlapping FIFO. The other FIFO is called non-overlapping FIFO. Overlapping FIFO is used to buffer those variable-to-check messages whose LLRs will continue to be decoded in the next layer. A non-overlapping FIFO is used to buffer variable-to-check messages whose LLRs will not be needed in the next layer. Note that if an LLR of a submatrix can be updated regularly in the current layer and would suffer pipeline conflicts in the next layer, the variable-to-check message of this submatrix in the current layer will be buffered into the non-overlapping FIFO and its updated LLR will be written back to the LLR RAM. The variable-to-check message of this submatrix in the next layer will not be buffered into any FIFOs because the corresponding LLR cannot be updated. FIFOs for buffering the signs need to be divided into overlapping and non-overlapping FIFOs as well. Two separate queues to generate new s in CNU are also needed. In each update queue, variable-to-check messages are added with check-to-variable message to achieve their updated LLR separately. In this way, LLRs can be updated in double queues.
Combined with the priority-based schedule and double update queues, we introduce the decoding flow chart in detail as shown in
Figure 3.
In our design, variable nodes in a layer are processed in units of submatrix. For simplicity of presentation, the variable nodes in a submatrix are denoted as variable node group (VNG). Before decoding, the processing order of VNGs in a layer needs to be reordered. In a layer, the VNGs that have not been decoded in the previous layer are decoded first. Next are the VNGs that have been decoded in the previous layer.
When the processing order of VNGs is determined, decoding starts. LLRs are successively read out from LLR RAM. After the processing of barrel shifter and VNU, variable-to-check messages are obtained. According to the mechanism of double update queues, variable-to-check messages are buffered into overlapping FIFO or non-overlapping FIFO. Then, the check-to-variable messages are updated.
The next step is the process of the LLR update when the pipeline conflict occurs or does not occur. If no pipeline conflicts happen, LLRs can be normally updated as the layered schedule. After update, LLRs of non-overlapping VNGs will be written back to the LLR RAM. LLRs of overlapping VNGs will be bypassed to the barrel shifter and participate in the decoding in the next layer. At the end of one iteration, the codeword will be decided according to the sign of LLRs. If the iteration has reached the maximum iteration number or the calculated syndrome is equal to zero, the decoding will end. If not, the decoding will continue.
If pipeline conflicts happen during the decoding, LLRs of the VNG with conflicts will not be updated. Combining with
Figure 2, the impact of pipeline conflicts on decoding can be mitigated as follows. If the LLR in the previous layer has not been updated yet, then the old LLR value is read again from LLR RAM for the current layer. VNU calculates its variable-to-check message
and passes it to the CNU. At the same time,
is not necessary to be buffered into FIFO because its corresponding LLR will not be updated in this layer. Different from the layered schedule,
is calculated separately with sign buffered in a separate FIFO. Then, it will minus the
obtained from the previous iteration and obtain the gain
. Before storing the gain
into RAM, gain
should enter the gain barrel shifter and be shuffled to the corresponding position of the submatrix that it will be added with in the other layer. When the LLR is updated in other layers like in the layered decoding schedule, the gain
then adds to this updated LLR.
3.4. Detailed Illustration of the Proposed Decoder with High Performance
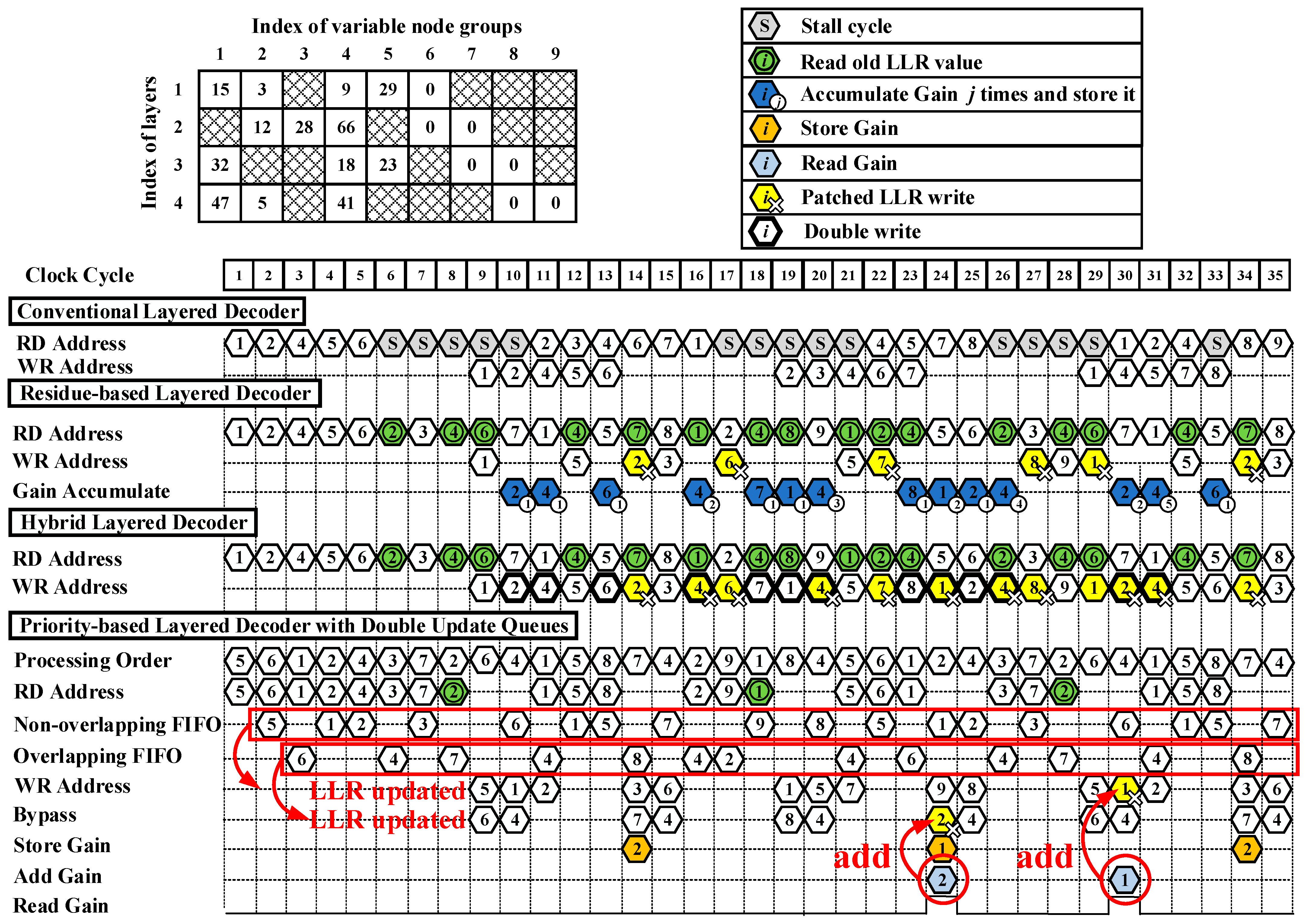
To help understand the mechanism of the priority-based layered decoder with double update queues, here we give an example. The timing diagram of decoding with the QC-LDPC code PCM is shown in
Figure 2. RD address and WR address represent the addresses that LLR reads from and writes to. All the addresses are unified with the index of VNGs. Double update queues work as follows. During decoding, overlapping FIFO buffers variable-to-check messages
s of overlapping VNGs that their newly updated LLRs will participate decoding in the next layer. Bypass means those LLRs will be bypassed to the barrel shifter instead of being written back into LLR RAM. Non-overlapping FIFO buffers
s of non-overlapping VNGs that their newly updated LLRs will be written to memory. LLRs of overlapping and non-overlapping VNGs are updated separately once their respective check-to-variable messages are calculated.
As shown in
Figure 4, the base graph matrix is dense and has four rows and nine columns. The number of pipeline stages is set to three. When an LDPC code is being decoded in a conventional layered decoder, VNGs in a layer are processed as the order shown in PCM. When a pipeline conflict occurs, stall cycles are necessarily inserted to maintain the full decoding performance. As an example, in the first layer, the first, second, fourth, fifth, and sixth VNGs participate in the decoding in order. In the second layer, the second, third, fourth, sixth, and seventh VNGs participate in the decoding in order. At the ninth cycle shown in
Figure 4, LLRs of variable nodes in the first layer are written back to RAM in sequence. To avoid pipeline conflicts, five stall cycles have to be inserted and LLRs of the second VNG in the second layer cannot be read out from RAM until the 11th cycle, since the updated LLRs of the second VNG in the first layer are written back to the RAM at the 10th cycle.
The residue-based layered decoder, hybrid decoder, and priority-based layered decoder with double update queues eliminate stall cycles so that LLRs of a VNG can be read out from memory at each cycle. The solution to pipeline conflicts in the residue-based decoder [
14] works as follows. At the sixth cycle, there exists a pipeline conflict to the second VNG. LLRs of the second VNG have to read the old LLR values from the RAM and use these values for decoding. At the 10th cycle, the gain of the second VNG in the first layer is saved in a register file for patching. The second VNG in the second layer can be updated normally at the 14th cycle and the gain is added with the updated LLRs when the LLR write operation happens, here referred as patched LLR write. In this way, the performance loss is compensated. However, the residue-based decoder has to postpone updates of LLRs when the pipeline conflicts happen to the LLRs in one variable node [
14]. In this example, LLRs in the fourth VNG can never be updated because of the pipeline conflict and postponed patch.
In the hybrid decoder, the solution for pipeline conflicts works as follows. In the first layer, updated LLRs of the second, fourth, and sixth VNGs are written to both the LLR memory and FIFO (double write) [
15]. The patched LLR update of the second, fourth, and sixth VNGs is done as shown in Equation (7) at the 14th, 16th, and 17th cycle, respectively. In this manner, LLR updates are not postponed and check node gains are added as soon as they are ready. However, the number of the occurrence of pipeline conflicts is still high.
In our proposed priority-based decoder with double update queues, the processing of the decoding is shown in detail in
Figure 3. Before the start of decoding, the processing order of VNGs is needed to be reordered. As shown in
Figure 4, in the first layer, the fifth, and sixth VNGs are first decoded since they are not decoded in the fourth layer in the previous iteration. Then, the first, second, and fourth VNGs are decoded. In the second layer, the third, seventh, second, fourth, and sixth VNGs are decoded in turn. In the third layer, the first, fifth, eighth, seventh, and fourth VNGs are decoded in turn. In the fourth layer, the second, ninth, first, eighth, and fourth VNGs are decoded in turn.
After the LLRs are read from memory, they are used to calculate the variable-to-check messages. In the first layer, the variable-to-check messages of the fifth, first, and second VNGs are buffered into the non-overlapping FIFO since LLRs of the fifth and first VNGs will not participate in the decoding in the second layer and the updated LLRs of the second VNG will not be used in the second layer. In the first layer, the variable-to-check messages of the sixth and fourth VNGs are buffered into overlapping FIFO since these variable nodes are needed in the second layer after their LLRs are updated. The VNGs of other layers also buffer in this way. After the update of LLRs, LLRs of the overlapping submatrices are bypassed to the data path. They continue to be decoded in the next layer. LLRs of the non-overlapping variable nodes are written back to the memory. In the first layer, the fifth, first, and second VNGs are non-overlapping. Their LLRs are written back to memory. On the contrary, LLRs of the non-overlapping sixth and fourth VNGs are bypassed to the data path and participate in the decoding in the second layer. In this way, LLRs are updated in double queues and the occurrence of pipeline conflicts is obviously decreased.
When a pipeline conflict happens, the solution in the priority-based decoder works as follows. According to the priority-based schedule, LLRs of the second VNG in the first layer have priority to update at the 11th clock. At the eighth cycle, a pipeline conflict happens to the second VNG in the second layer. Therefore, it has to read the old LLR values because the LLR values of the second VNG in the first layer have not been updated yet at the eighth cycle. The variable-to-check messages of the second VNG in the second are calculated and passed to CNU but not buffered into overlapping FIFO or non-overlapping FIFO. The second VNG in the second layer calculates the gain on the basis of variable-to-check messages and stores the gain. At the 24th cycle, LLRs of the second VNG in the fourth layer are first updated normally after the occurrence of the pipeline conflict. At this moment, the gain of the second VNG in the second layer is added to the updated LLRs of the second VNG in the fourth layer. In this way, the loss caused by the pipeline conflict is compensated.



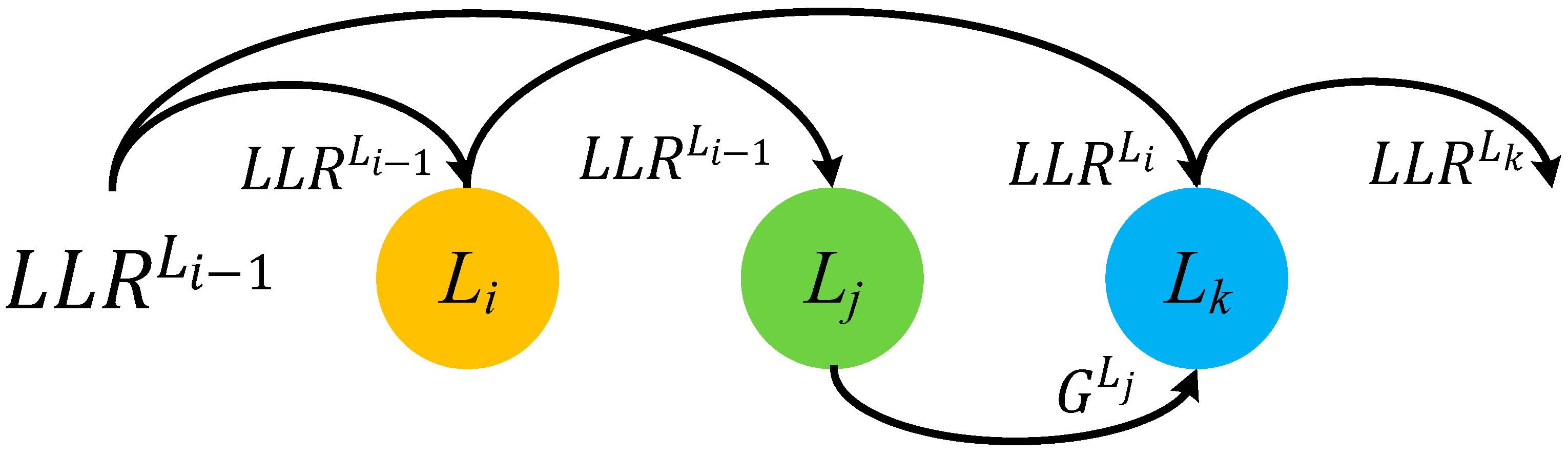




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}