
Rethinking the Role of Normalization and Residual Blocks for Spiking Neural Networks


Abstract
:1. Introduction
- We propose a novel and simple normalization technique based on the firing rate. The experimental results show that the proposed model can simultaneously achieve high classification accuracy and low firing rate;
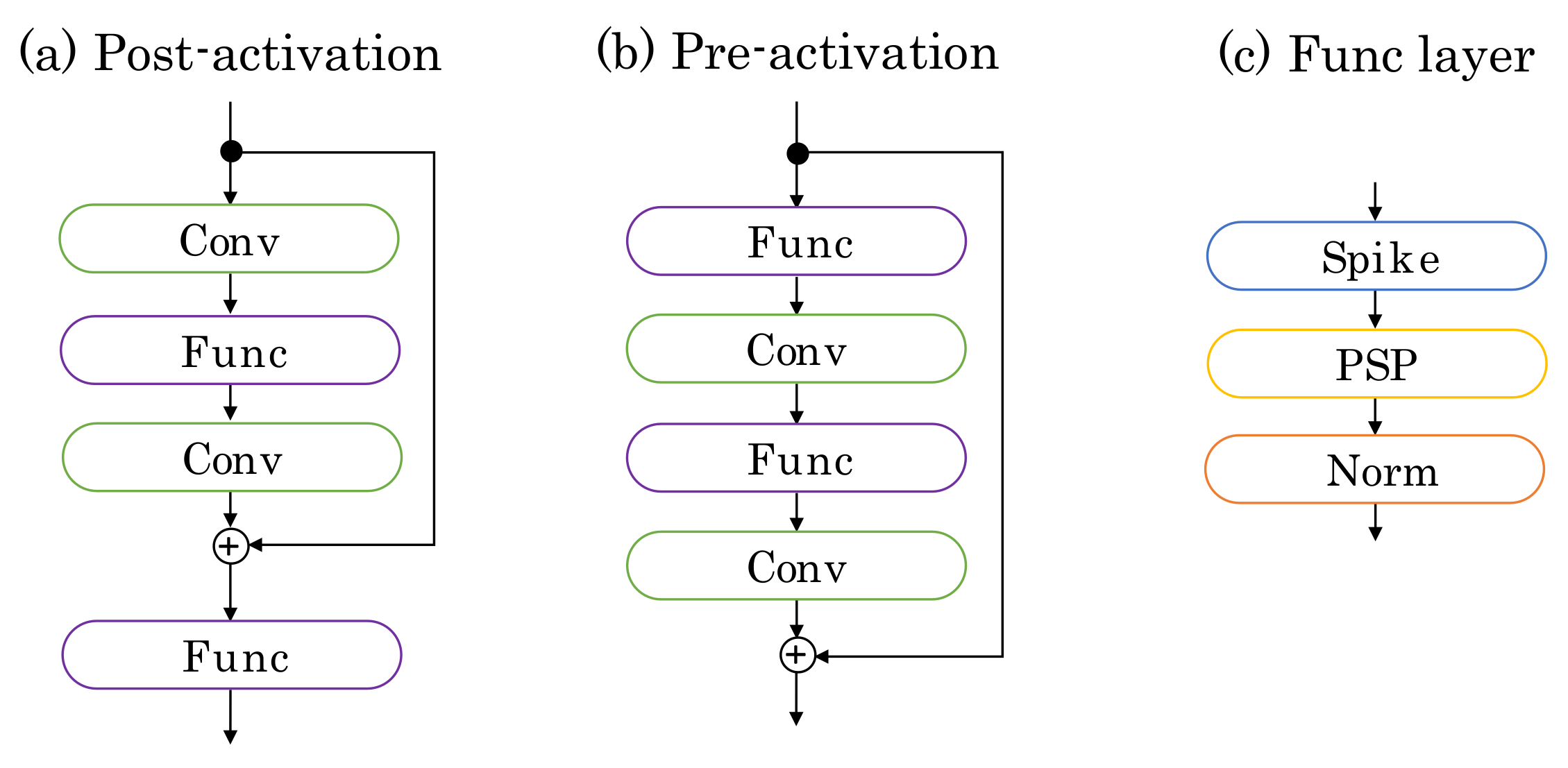
- We trained deep SNNs based on the pre-activation residual blocks [14]. Consequently, we successfully obtained a model with more than 100 layers without other special techniques dedicated to SNNs.
2. Related Works
2.1. Spiking Neuron
2.2. Training of Spiking Neural Networks
2.3. Normalization
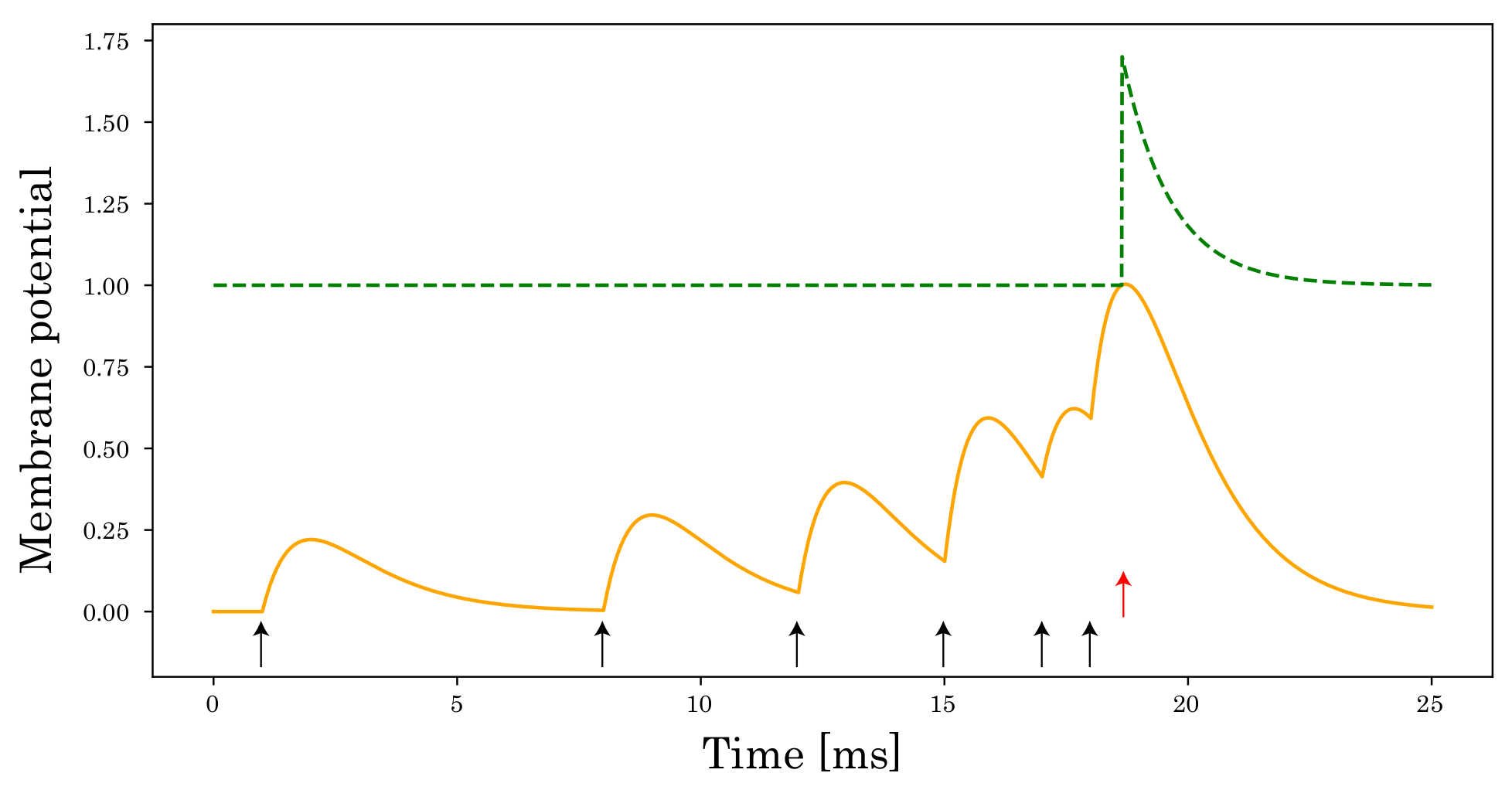
3. Spiking Neural Networks Based on the Spike Response Model
3.1. Spike Response Model
3.2. Multiple Layers Spike Response Model
3.3. Deep SNNs by Pre-Activation Blocks
3.4. Surrogate-Gradient
4. Normalization of Postsynaptic Potential
5. Experiments
5.1. Experimental Setup
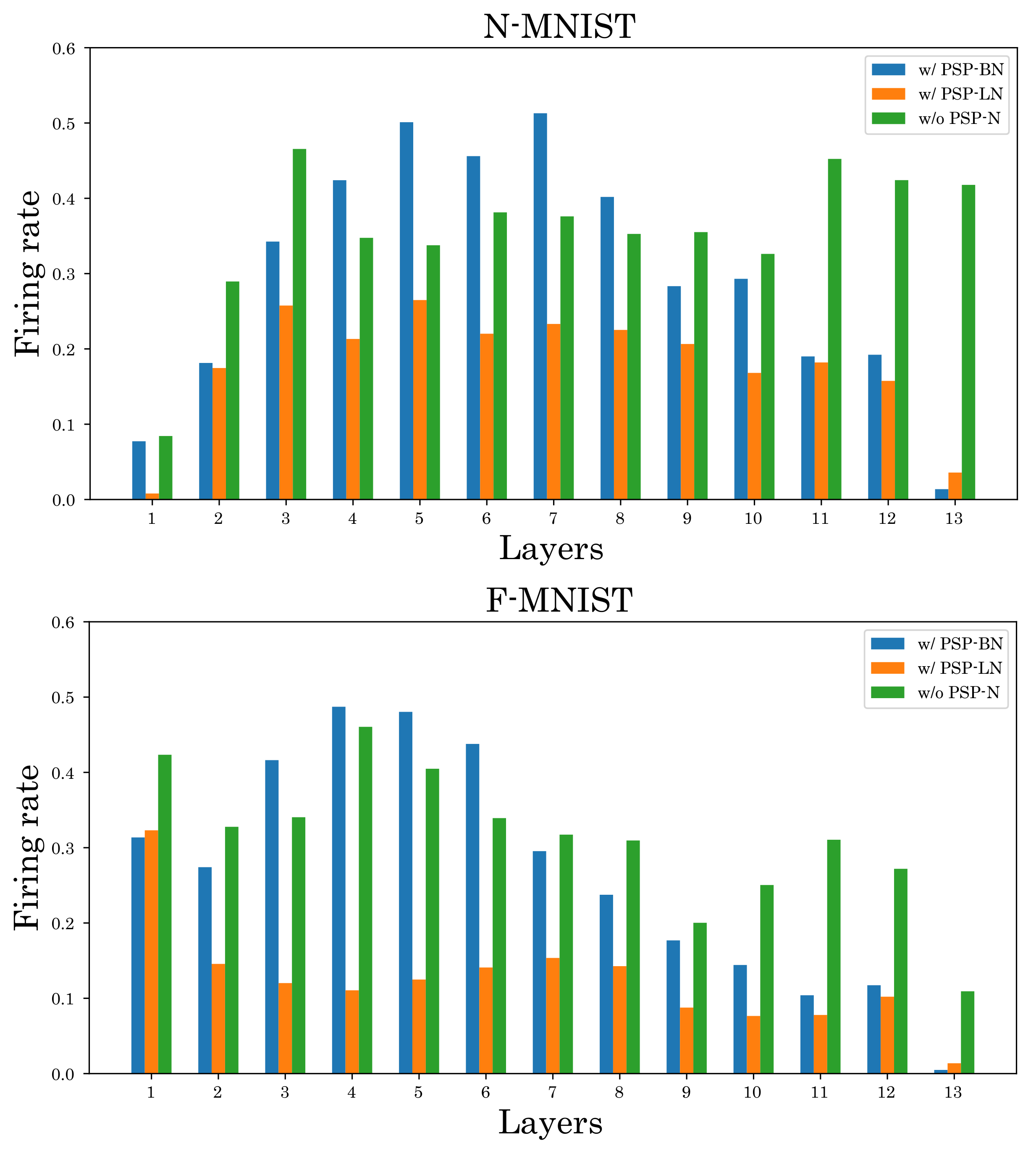
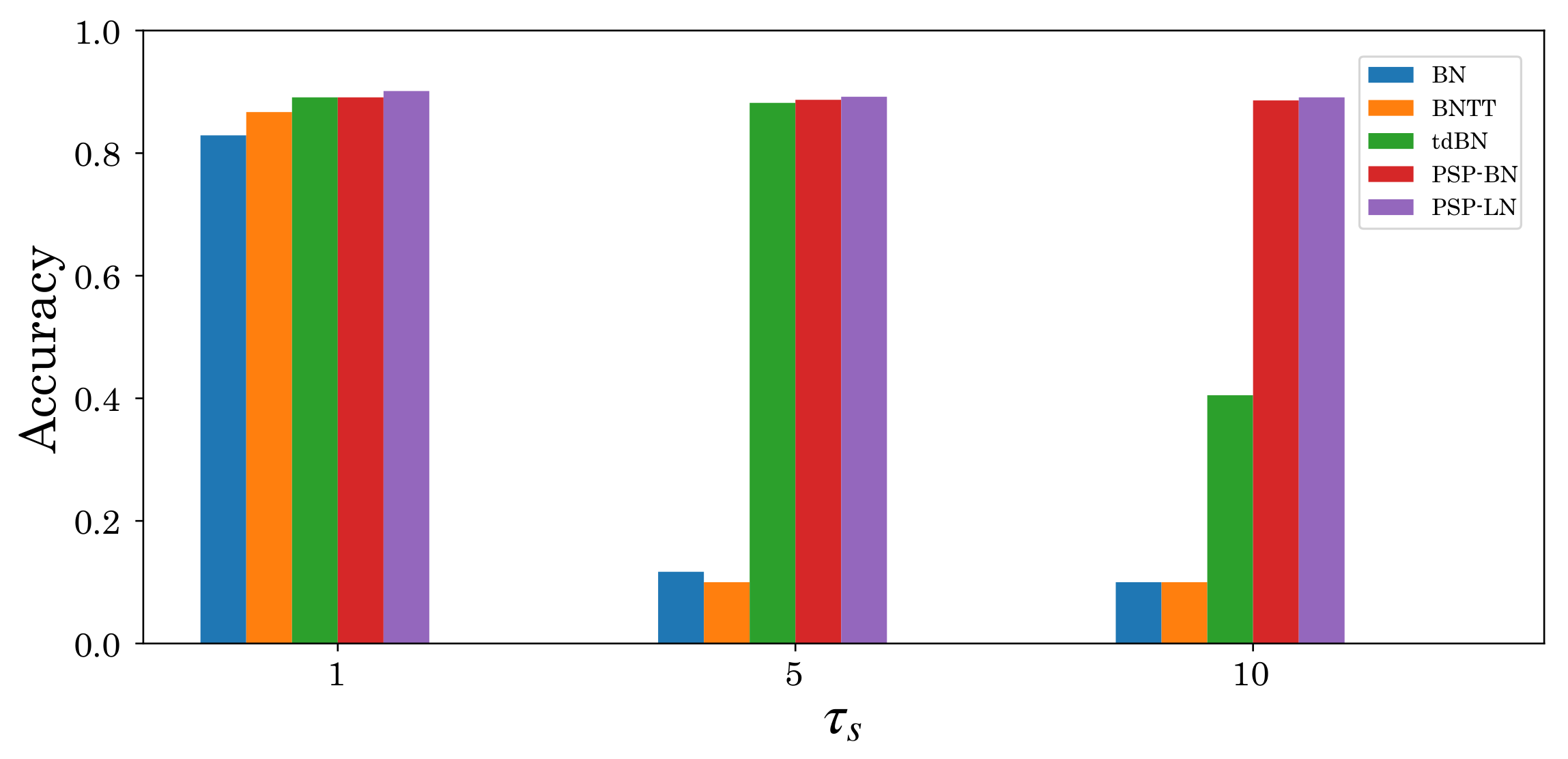
5.2. Effectiveness of Postsynaptic Potential Normalization
5.3. Performance Evaluation of Deep SNNs by Residual Modules
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.-J.; et al. Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.-H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Maguire, L.P.; McGinnity, T.M.; Glackin, B.; Ghani, A.; Belatreche, A.; Harkin, J. Challenges for large-scale implementations of spiking neural networks on FPGAs. Neurocomputing 2007, 71, 13–29. [Google Scholar] [CrossRef]
- Lee, C.; Sarwar, S.S.; Panda, P.; Srinivasan, G.; Roy, K. Enabling spike-based backpropagation for training deep neural network architectures. Front. Neurosci. 2020, 14, 119. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, S.B.; Orchard, G. Slayer: Spike layer error reassignment in time. arXiv 2018, arXiv:1810.08646. [Google Scholar]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef]
- Zenke, F.; Ganguli, S. Superspike: Supervised learning in multilayer spiking neural networks. Neural Comput. 2018, 30, 1514–1541. [Google Scholar] [CrossRef]
- Zhang, W.; Li, P. Temporal spike sequence learning via backpropagation for deep spiking neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 12022–12033. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Fang, W.; Yu, Z.; Chen, Y.; Huang, T.; Masquelier, T.; Tian, Y. Deep Residual Learning in Spiking Neural Networks. arXiv 2021, arXiv:2102.04159. [Google Scholar]
- Orchard, G.; Jayawant, A.; Cohen, G.K.; Thakor, N. Converting static image datasets to spiking neuromorphic datasets using saccades. Front. Neurosci. 2015, 9, 437. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Lapique, L. Recherches quantitatives sur l’excitation electrique des nerfs traitee comme une polarization. J. Physiol. Pathol. 1907, 9, 620–635. [Google Scholar]
- Stein, R.B. A theoretical analysis of neuronal variability. Biophys. J. 1965, 5, 173–194. [Google Scholar] [CrossRef] [Green Version]
- Izhikevich, E.M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 2003, 14, 1569–1572. [Google Scholar] [CrossRef] [Green Version]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500–544. [Google Scholar] [CrossRef]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: Single Neurons, Populations, Plasticity; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Rall, W. Distinguishing theoretical synaptic potentials computed for different soma-dendritic distributions of synaptic input. J. Neurophysiol. 1967, 30, 1138–1168. [Google Scholar] [CrossRef]
- Comsa, I.M.; Potempa, K.; Versari, L.; Fischbacher, T.; Gesmundo, A.; Alakuijala, J. Temporal coding in spiking neural networks with alpha synaptic function. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8529–8533. [Google Scholar]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.-C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Li, Y.; Deng, S.; Dong, X.; Gong, R.; Gu, S. A Free Lunch From ANN: Towards Efficient, Accurate Spiking Neural Networks Calibration. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 6316–6325. [Google Scholar]
- Rueckauer, B.; Lungu, I.-A.; Hu, Y.; Pfeiffer, M.; Liu, S.-C. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going deeper in spiking neural networks: VGG and residual architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Mądry, A. How does batch normalization help optimization? In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 2488–2498. [Google Scholar]
- Shen, Y.; Wang, J.; Navlakha, S. A correspondence between normalization strategies in artificial and biological neural networks. Neural Comput. 2021, 33, 3179–3203. [Google Scholar] [CrossRef] [PubMed]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zheng, H.; Wu, Y.; Deng, L.; Hu, Y.; Li, G. Going Deeper With Directly-Trained Larger Spiking Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11062–11070. [Google Scholar]
- Kim, Y.; Panda, P. Revisiting batch normalization for training low-latency deep spiking neural networks from scratch. Front. Neurosci. 2021, 15, 773954. [Google Scholar] [CrossRef]
- Ledinauskas, E.; Ruseckas, J.; Juršėnas, A.; Buračas, G. Training deep spiking neural networks. arXiv 2020, arXiv:2006.04436. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Aertsen, A.; Braitenberg, V. (Eds.) Brain Theory: Biological Basis and Computational Principles; Elsevier: Amsterdam, The Netherlands, 1996. [Google Scholar]
- Frankenhaeuser, B.; Vallbo, Å.B. Accommodation in myelinated nerve fibres of Xenopus laevis as computed on the basis of voltage clamp data. Acta Physiol. Scand. 1965, 63, 1–20. [Google Scholar] [CrossRef]
- Schlue, W.R.; Richter, D.W.; Mauritz, K.H.; Nacimiento, A.C. Responses of cat spinal motoneuron somata and axons to linearly rising currents. J. Neurophysiol. 1974, 37, 303–309. [Google Scholar] [CrossRef]
- Stafstrom, C.E.; Schwindt, P.C.; Flatman, J.A.; Crill, W.E. Properties of subthreshold response and action potential recorded in layer V neurons from cat sensorimotor cortex in vitro. J. Neurophysiol. 1984, 52, 244–263. [Google Scholar] [CrossRef]
- Fang, W.; Yu, Z.; Chen, Y.; Masquelier, T.; Huang, T.; Tian, Y. Incorporating learnable membrane time constant to enhance learning of spiking neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2661–2671. [Google Scholar]
- Li, Y.; Guo, Y.; Zhang, S.; Deng, S.; Hai, Y.; Gu, S. Differentiable Spike: Rethinking Gradient-Descent for Training Spiking Neural Networks. Adv. Neural Inf. Process. Syst. 2021, 34, 12022–12033. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | N-MNIST | F-MNIST |
|---|---|---|
| 10 | 10 | |
| 10 | 10 | |
| 10 | 10 | |
| 10 | 10 | |
| 10 | 10 | |
| optimizer | AdaBelief | AdaBelief |
| learning rate | ||
| weight decay | ||
| weight scale | 10 | 10 |
| mini-batch size | 10 | 10 |
| time step | 300 | 100 |
| epoch | 100 | 100 |
| Method | Dataset | Network Architecture | Acc. (%) |
|---|---|---|---|
| BN [35] | N-MNIST | 34×34×2-8c3n-{16c3n}*5-16c3n-{32c3n}*5-10o | 85.1 |
| BNTT [34] | N-MNIST | 34×34×2-8c3n-{16c3n}*5-16c3n-{32c3n}*5-10o | 90.0 |
| tdBN [33] | N-MNIST | 34×34×2-8c3n-{16c3n}*5-16c3n-{32c3n}*5-10o | 81.8 |
| PSP-BN | N-MNIST | 34×34×2-n8c3-{n16c3}*5-n16c3-{n32c3}*5-10o | 97.4 |
| PSP-LN | N-MNIST | 34×34×2-n8c3-{n16c3}*5-n16c3-{n32c3}*5-10o | 98.2 |
| None | N-MNIST | 34×34×2-8c3-{16c3}*5-16c3-{32c3}*5-10o | 40.6 |
| BN [35] | F-MNIST | 34×34-16c3n-{32c3n}*5-32c3n-{64c3n}*5-10o | 10 |
| BNTT [34] | F-MNIST | 34×34-16c3n-{32c3n}*5-32c3n-{64c3n}*5-10o | 10 |
| tdBN [33] | F-MNIST | 34×34-16c3n-{32c3n}*5-32c3n-{64c3n}*5-10o | 40.5 |
| PSP-BN | F-MNIST | 34×34-n16c3-{n32c3}*5-n32c3-{n64c3}*5-10o | 88.6 |
| PSP-LN | F-MNIST | 34×34-n16c3-{n32c3}*5-n32c3-{n64c3}*5-10o | 89.1 |
| None | F-MNIST | 34×34-16c3-{32c3}*5-32c3-{64c3}*5-10o | 84.1 |
| Meshod | Dataset | Network Architecture | Acc. (%) |
|---|---|---|---|
| PSP-BN | N-MNIST | Post-activation ResNet-106 | 10.0 |
| PSP-BN | N-MNIST | Pre-activation ResNet-106 | 75.4 |
| PSP-LN | N-MNIST | Post-activation ResNet-106 | 10.0 |
| PSP-LN | N-MNIST | Pre-activation ResNet-106 | 86.8 |
| PSP-BN | F-MNIST | Post-activation ResNet-106 | 10.0 |
| PSP-BN | F-MNIST | Pre-activation ResNet-106 | 81.6 |
| PSP-LN | F-MNIST | Post-activation ResNet-106 | 10.0 |
| PSP-LN | F-MNIST | Pre-activation ResNet-106 | 82.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ikegawa, S.-i.; Saiin, R.; Sawada, Y.; Natori, N. Rethinking the Role of Normalization and Residual Blocks for Spiking Neural Networks. Sensors 2022, 22, 2876. https://doi.org/10.3390/s22082876
Ikegawa S-i, Saiin R, Sawada Y, Natori N. Rethinking the Role of Normalization and Residual Blocks for Spiking Neural Networks. Sensors. 2022; 22(8):2876. https://doi.org/10.3390/s22082876
Chicago/Turabian StyleIkegawa, Shin-ichi, Ryuji Saiin, Yoshihide Sawada, and Naotake Natori. 2022. "Rethinking the Role of Normalization and Residual Blocks for Spiking Neural Networks" Sensors 22, no. 8: 2876. https://doi.org/10.3390/s22082876
APA StyleIkegawa, S.-i., Saiin, R., Sawada, Y., & Natori, N. (2022). Rethinking the Role of Normalization and Residual Blocks for Spiking Neural Networks. Sensors, 22(8), 2876. https://doi.org/10.3390/s22082876