1. Introduction
Biometric human recognition systems are extensively used, and yet are increasing in demand for various applications in recent years. Among all biological traits used, iris is well suited for the most accurate and secure personal identification/verification because of the distinctive patterns present in the iris textures of individuals. To maintain high level of accuracy, the iris images presented to the iris recognition systems need to possess a relentless virtual quality and perception. Nonetheless, considering interoperability and vendor neutrality, often authorities, regulatory bodies, and international standards organizations specify that biometric data must be stored and preserved in image form, rather than in (or in addition to) extracted templates that may depend on proprietary algorithms. Recording raw (high quality) image data in such systems also allows them to benefit from inevitable future improvements in recognition algorithms. However, storage, processing and transmission of such high quality data comes at high cost. To this extent, efficient storage and rapid transmission of iris biometric records is a driving implementation factor in iris recognition system development (especially on low-powered mobile sensors and for portable devices) currently. Image compression techniques reduce the amount of memory used by reducing the number of bits without losing the important data. Image compression will also reduce the transmission time as the transmission time of any image is directly proportional to size of the image. There are two types of compression algorithms, namely “lossless compression” and “lossy compression”. A lossless compression is a reversible process in which no information is lost, but the compression ratio is lower. It is mainly used in the domain where reliability is important: for example executable files and medical data. Lossy compression is a non-reversible process and some information may be lost, but compression ratio is very high and is mainly used in applications where loss of data is acceptable to a certain degree.
Recent machine learning techniques proposed for lossy image compression have generated considerable interest in both the machine learning and image processing communities. Like all lossy compression methods, such models operate on a simple principle: an image, typically proposed as a vector of pixel intensities, is quantized, reducing the amount of information required to record or transmit it, which incorporates introducing some error at the same time. Typically, it is not the pixel intensities that are quantized directly. Rather, an alternative (latent) representation of the image is found, and quantization takes place in this representation, yielding a discrete-valued vector. To be more precise, deep learning models learn (extract) the key features in the input image through back propagation training and enable the compression of image information, preserving and restoring such features without too much prior knowledge.
In this work, we extend our previous study [
1] on evaluating the expediency of a Deep Semantic Segmentation-based Layered image Compression (DSSLIC) model [
2] for iris compression within a biometric recognition framework. As a distinction to the previous work: We utilize a more powerful deep-learning-based model (End-to-end Optimized Image Compression model (EOIC)) to address the lower performance issue of the Conditional Probability Models for Deep Image Compression (CPDIC), as used as the comparing model in the previous experiments. We further consider three new state-of-the-art (non-learning-based, lossy) image compression models along with a couple of other commonly used image compression algorithms to compress iris images in four well-known iris datasets. To evaluate the compression performance in each case, in addition to the Multi-scale Structural Similarity Index (which was used in our previous work), another “Full-Reference” image quality assessment measure, namely Local Feature Based Visual Security (LFBVS), and a “No-Reference” images quality assessment measure, namely Blind Reference-less Image Spatial Quality Evaluator (BRISQUE) are used. The biometric recognition performance then is evaluated, in terms of Equal Error Rate (EER), by using the compressed iris images in some predefined iris biometric systems. At the end, the compression and the corresponding recognition results are compared and carefully analyzed to figure out a well suited compression algorithm to be employed in iris recognition systems. The rest of the paper is structured as follows:
Section 2 will review related works and state of the art, and
Section 3 will describe the deep-learning based model (DSSLIC).
Section 4 will give the details of the experimental framework, and the experiments and analysis will be presented in
Section 5. Finally,
Section 6 will conclude the paper.
2. Related Work
Many studies have been conducted on iris image compression and the subsequent recognition performance during the past decades). For example: Matschitsch et al. [
3] studied the impact of applying different lossy compression algorithms on the matching accuracy of iris recognition systems, relating rate-distortion performance to the matching scores. The authors in this work concluded that JPEG2000, SPIHT, and PRVQ are almost equally well suited for iris compression. Daugman and Downing [
4] analyzed the effect of severe image compression on iris recognition performance and introduced a schemes that combine region-of-interest isolation with JPEG and JPEG2000 compression at severe levels, and tested them using a publicly available database of iris images. Grother [
5] investigated existing image compression approaches and compared JPEG and JPEG2000 to provide a quantitative support to the revision of the ISO/IEC IS 19794-6, considering: cropped format (IREX K3), masked and cropped format (IREX K7), and an unsegmented polar format (IREX K16) in his experiments. Ives et al. [
6] investigated the effects of image compression on recognition system performance using a commercial version of the Daugman “iris2pi” algorithm along with JPEG-2000 compression, and linked that to image quality. Korvath et al. [
7] evaluated the impact of dedicated lossless image codecs (lossless JPEG, JPEG-LS, PNG, and GIF), lossless variants of lossy codecs (JPEG2000, JPEG XR, and SPIHT), and some general purpose file compression schemes on the iris images. Bergmüller et al. [
8] studied the impact of using pre-compressed data in iris segmentation and evaluated the relation between iris segmentation performance and general image quality metrics. Rathgeb et al. [
9] investigated the impact of image compression on iris segmentation algorithms. In their work, they examined the impact of severe image compression using in particular, JPEG, JPEG 2000, and JPEG-XR algorithms on the performance of different iris segmentation approaches.
With recent advancements in deep learning techniques, researchers have proposed few learning based image compression methods as well. Toderici et al. [
10] used a recurrent neural networks, based on convolution and deconvolution long short-term memory (LSTM), to extract binary representations which are later compressed with entropy coding. Ballé et al. [
11] proposed a compression framework that included a generalized divisive normalization (GDN)-based nonlinear analysis transform, a uniform quantizer, and a nonlinear synthesis transform. Theis et al. [
12] introduced a deep-learning-based auto-encoder in which they used smooth approximation instead of quantization to obtain different rates. Agustsson et al. [
13] used a soft-to-hard vector quantization model along with a unified formulation for both the compression of deep learning models and image compression. Jiang et al. [
14] utilized a compact convolutional neural network (ComCNN) and a reconstruction convolutional neural network (RecCNN) to encode and decode the original image, respectively. Johnston et al. [
15] utilized the structural similarity (SSIM) quality measure and spatially adaptive bit allocation to further improve the performance. Li et al. [
16] introduced a model which was based on image content weighting. They used the edge feature maps, extracted by a convolution neural network, as the importance map of the original image. In this work, an innovative algorithm was introduced to solve the non-differentiated calculation in the quantization rounding function to achieve a backward propagation gradient in the standard image algorithm. Luo et al. [
17] used the benefit of image compression and classification to reconstruct the images and to generate corresponding semantic representations simultaneously. Mantzer et al. [
18] proposed a conditional probability model for deep image compression (CPDIC), with concentration on improving the entropy rate of the latent image representation using a context model (a 3D-CNN which learns a conditional probability model of the latent distribution). During training the auto-encoder makes use of the context model to estimate the entropy of its representation, and the context model is concurrently updated to learn the dependencies between the symbols in the latent representation. Wang et al. [
19] proposed a compression bit allocation algorithm, which allows a recurrent neural network (RNN)-based compression network to hierarchically compress the images according to semantic importance maps.
Some other works utilized Generative Adversarial networks (GAN) in their architecture to learn the image compression. Santurkar et al. [
20] utilized a discriminator to help training of a compression decoder. They calculated a perceptual loss, which was based on the feature map obtained from pretrained ImageNet and AlexNet. Only low-resolution image coding results were reported in this work. Ripple et al. [
21] embedded an auto-encoder in a GAN architecture, where the feature extraction adopted a pyramid of inter-scale alignments. They considered the target and its reconstruction jointly as a single entity and, instead of producing an output for classification at the last layers of the network, accumulated scalar outputs along branches constructed at different roots. The average of these scalars was used as the final value passed to a sigmoid function. Augustesson et al. [
22] proposed an image compression (synthesis) model based on a GAN architecture. They consider two modes of operations namely “generative compression” and “selective generative compression”. The later approach generated parts of image from a semantic label map. Their model was concentrated on obtaining extremely low bit-rates rather than on preserving key features in image, and to this extent a clear trade off between these two factors remained unclear. Balle et al. [
23] proposed an end-to-end trainable encoder–decoder framework for image compression. The encoder part includes a variational generative model, whose out put is quantized, compressed, and transmitted as side information. The decoder recovers the quantized vector from the compressed signal. It then obtains the correct probability estimates to successfully recover and reconstruct the image. Minnen et al. [
24] introduced a model which jointly optimizes an autoregressive component that predicts latents from their causal context (Context Model) along with a hyperprior and the underlying autoencoder. Real-valued latent representations then are quantized to create integer-valued latents and hyperlatents, which are compressed into a bit-stream using an arithmetic encoder and decompressed by an arithmetic decoder. Cheng et al. [
25] used discretized Gaussian Mixture Likelihoods to parameterize the distributions of latent codes, which removes redundancy to achieve an accurate entropy model, and leads to fewer encoding bits. They take advantage of attention modules to make the learned models pay more attention to complex regions. In any case, the main drawback of applying GAN networks (at least on their own and without further information fusion) to reconstruct the images is their inability to preserve key fine features in the images reconstructed. This phenomenon is observable in the corresponding results obtained using the above models too. In fact, this issue can directly affect the iris key traits and their subsequent recognition performance in the reconstructed images.
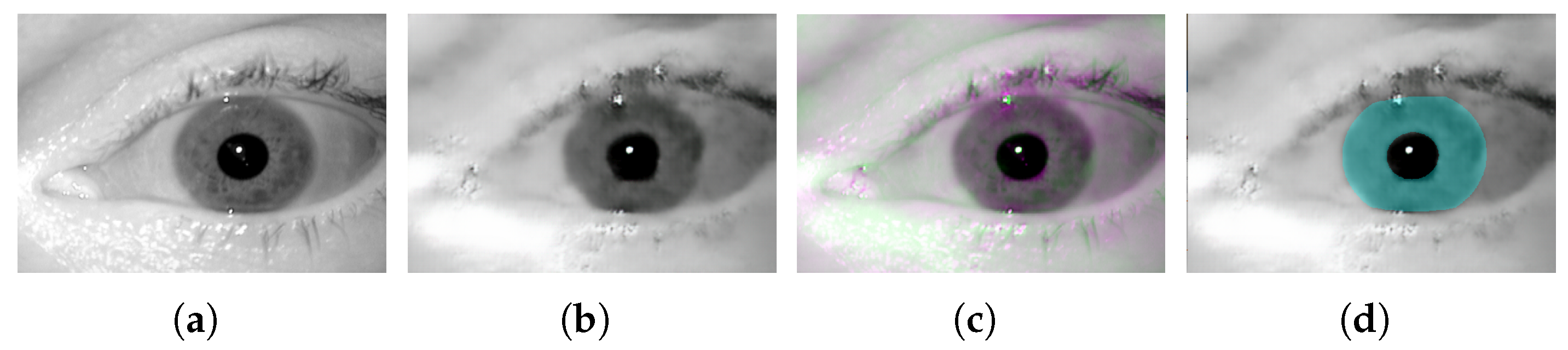
Figure 1 shows a sample iris image (
Figure 1a) (from the Notredame iris dataset, as used in this work), and its compressed version (
Figure 1b), using the last GAN based model, along with their difference image (
Figure 1c), and the overlaid ground-truth mask (
Figure 1d). Gray regions in the difference image show where the two images have the same intensities, and magenta and green regions show where the intensities are different. Furthermore, the overlaid ground-truth mask shows how the actual iris outer and inner boundaries (as specified by the mask) are distorted in the compressed (reconstructed) image. Nevertheless, while the recent architectures (e.g., et al. [
23,
24,
25]) contributed to improve the compressive performance in one way or another, yet their experimental trail (carried out in this research work) revealed that such improvement has come at the cost of loosing some level of scalability. In particular, during our experiments we noticed that on certain data (e.g., Casia5a as used in our experiments), these models are only able to preserve and reconstruct key image features when higher bits rates are used, and simply do not converge to lower bit rates even when highest compression parameters are used. To this extent, we excluded them from our comparison experiments.
3. Deep-Learning-Based Image Compression Model (DSSLIC)
Figure 2 demonstrates the overall architecture of the model used in our work, which is derived from the DSSLIC model already introduced in [
2]. As a key distinction to the original model, here we do not use a segmentation network in our model, and instead we provide the manually segmented labels directly to the model. Doing so, we try to provide a better evaluation of the actual performance of the model by introducing more accurate labeling data. In fact, such a configuration is practically justifiable as the recent advancements in the deep-learning-based segmentation techniques has made highly accurate segmentations (that are comparable to the manually segmented labels) available in a timely manner (i.e., [
26]).
The overall architecture of the model is composed of an encoding part and a decoding part. The encoding part includes two deep learning networks, namely “CompNet” and “FiNet” (a GAN-based network). The ComNet network takes the iris image as input, while the corresponding segmentation map is encoded to serve as side information to this network for generating a low-dimensional version of the original image. Both the segmentation map and the compact version are losslessly encoded using the FLIF codec [
27], which is a state-of-the-art lossless image compression algorithm. Having the segmentation map and up-sampled compact image, the FiNet works to obtain a high-quality reconstruction of the input image. Unlike the similar architectures in which the GAN networks operate directly only on the input images, here in this model, the GAN network takes the segmentation map as the input and tries to learn the missing detail information of the up-sampled version of the compacted input image to minimize the distortion of the synthesized images. It should be noted that although GAN-based synthesized images generated with the help of the segmentation maps are visually appealing, their details can be quite different from the original images. To minimize the errors of the synthesized images, the up-sampled version of the compact image, as an additional input, is used. By doing so, the FiNet learns the missing detail information of the up-sampled version of a compact image with respect to the input image, which in turn controls the output of the GAN network. After adding the up-sampled version of the compact image and the FiNet’s output, we obtain a better estimate of the input. The residual difference between the input and the estimate is then obtained and encoded by a lossy codec (H.265/HEVC intra coding-based BPG). In order to deal with negative values, the residual image is re-scaled to [0, 255] with a min-max normalization before encoding. The min and max values are also sent to the decoder for inverse scaling. In this scheme the segmentation map serves as the base layer and the compact image and the residual are the first and second enhancement layers, respectively. At the decoder side the segmentation map and the compact representation are decoded to be used by the FiNet to obtain an estimate of the input image. The output of FiNet is then added to the decoded residual image to obtain the reconstructed image as output.
5. Experiments and Analysis
Addressing the input size requirement of the deep-learning-based models and also a fair evaluation policy, we rescaled all the images in our datasets to the size:
during the compression evaluation experiments. Since the networks are trained on RGB format we cloned each image two times to generate 3 channel (RGB) images (
). We applied a cross-fold scheme to train the (deep-learning-based) models. For this, first we partitioned each dataset into two equal parts and trained the models on one partition and tested it on the other partition. We switched the partitions role next, and doing so we tested the networks on all samples in each dataset without overlapping the training and testing sets. For the DSSLIC model, we set the down-scaling factor
to obtain the compact representation of the inputs.
Table 1 summarizes the training parameters used for each model. Likewise, we applied the other comparison (non-learning-based) compression algorithms to our datasets. To address the preset bandwidth/storage compression limit requirement we defined two bandwidth limits of 0.30 (A) and 0.60 (B), corresponding to the higher and the lower compression levels, respectively, for each dataset in terms of bit-per-pixel (bpp). Obviously, not all algorithms allow to set the exact output file size. Thus, we set the compression parameter for each algorithm in way that the achieved bpp of the resulting compressed images are equal to or less than the predefined bandwidth/storage limit. It is also important to note that the resulting file sizes using the DSSLIC model are among the smallest in the majority of cases (i.e., Casia4i, Casia5a-A, IITD-B, and Notredame).
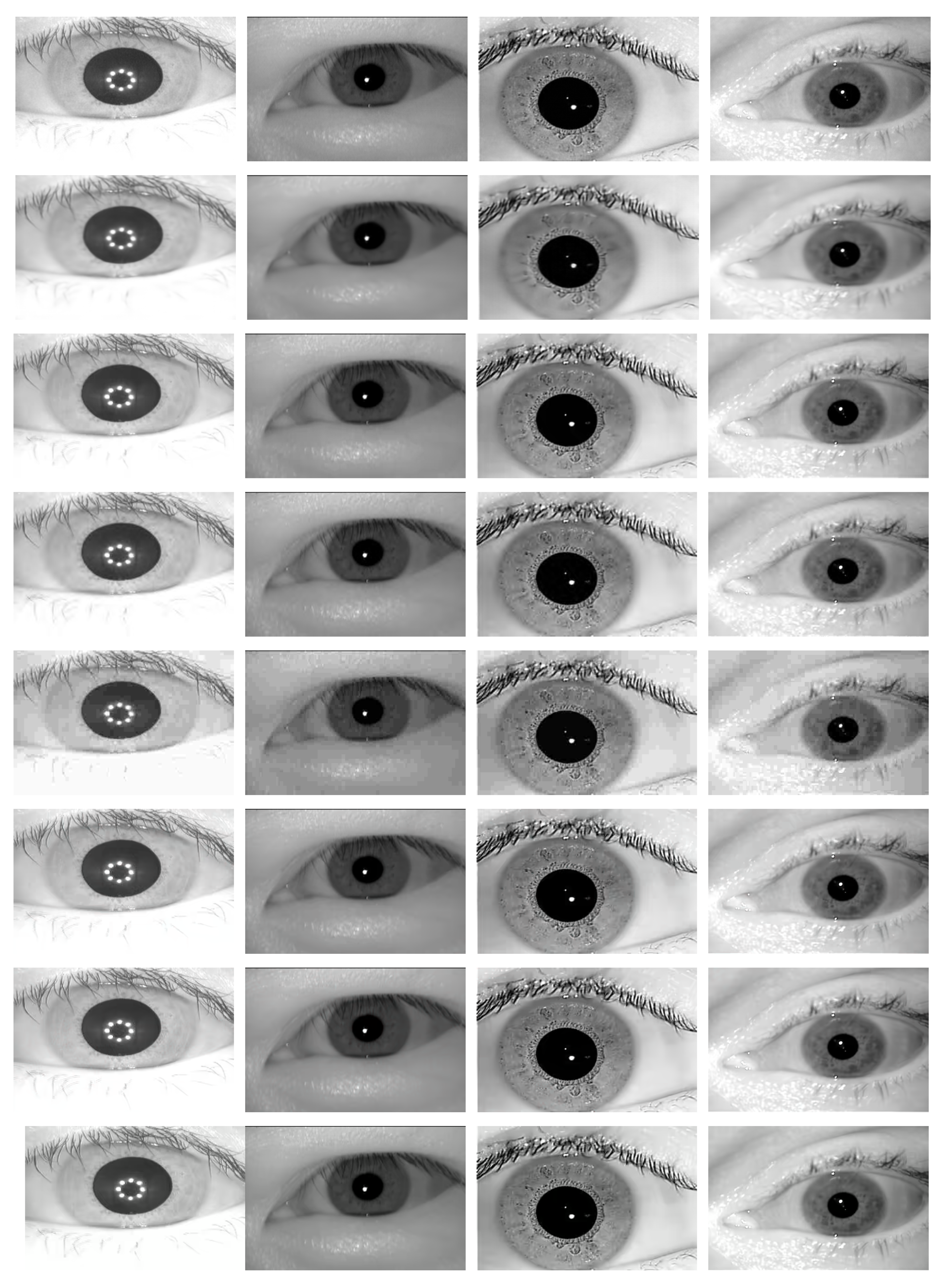
Table 2 shows the selected compression parameters (par) and the resulting bpps per algorithm and dataset. Furthermore, samples of the output (compressed) images in each dataset using the compression methods used are presented in
Figure 3 per column and row, respectively.
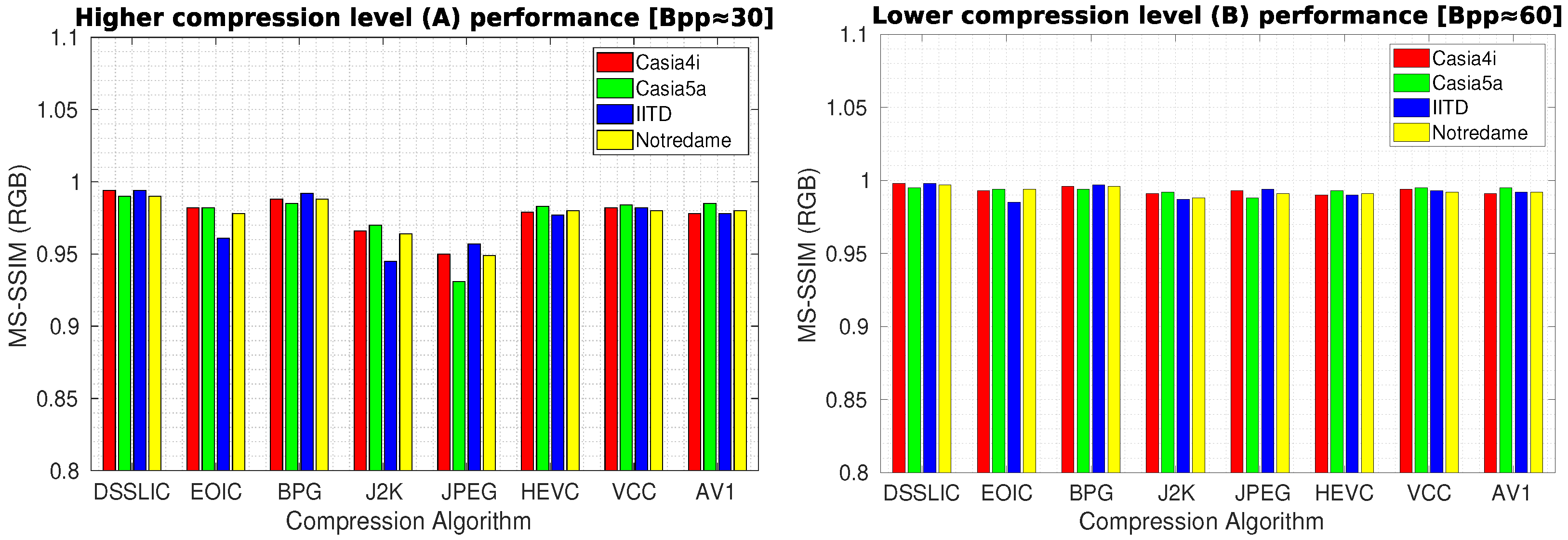
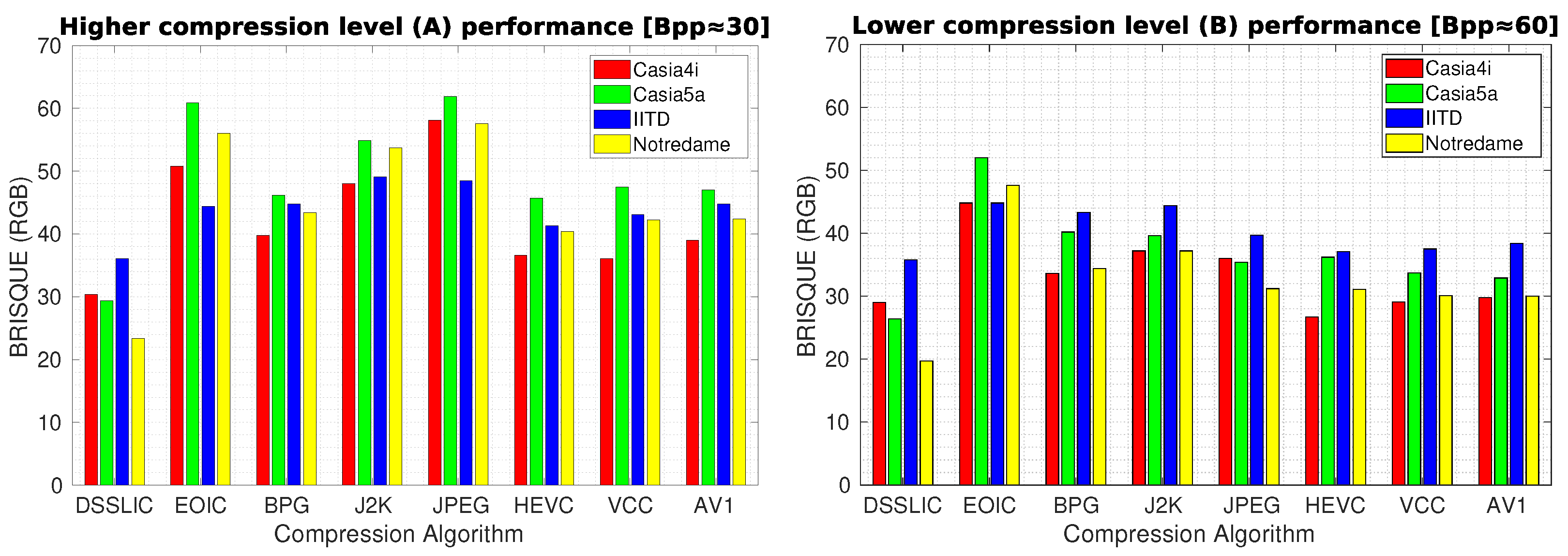
Table 3 presents the quality compression results in terms of MS-SSIM measure for each dataset (averaged over all images) using the different compression algorithms. As it can be seen, the DSSLIC model shows superior performance over all other algorithms for both compression levels considered. This is a quite interesting result given the fact that the files produced by the DSSLIC are among the smallest files produced by the methods applied. Visual inspection of the obtained output iris images as presented in
Figure 3 (the first row) also shows that the model is able to preserve the key iris biometric traits and the structural features very well. Across all datasets, and both compression settings, BPG is (almost) always the second-best. The performance of the other six algorithms vary depending on the datasets: The VCC algorithm shows relatively better performance (compared to the other five algorithms) on the Casia4i, Notredame, and IITD datasets (only when the higher compression rate (A) is considered), while the AV1 algorithm demonstrates overall a better performance than VCC on the Casia5a dataset. EOIC performs better (than VCC and AV1) on Notredame datasets (only when the lower compression rate (B) is considered). The other algorithms (J2K, HEVC, and JPEG) come thereafter while their performance in the majority of cases is lower than the other algorithms across different datasets. For the sake of better interpretation, we visualized the corresponding performance in the form of bar-graphs (for each compression level) in
Figure 4.
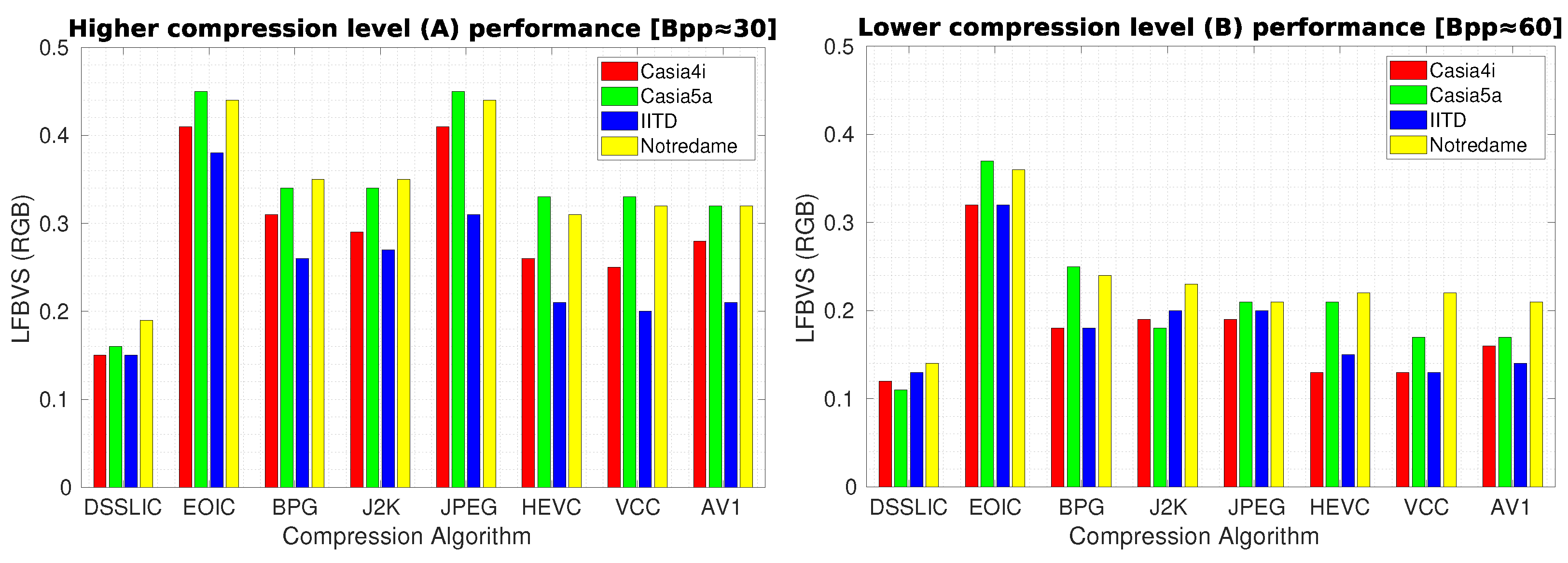
Table 4 shows the corresponding results for each dataset (averaged over all images) in terms of LFBVS. The superior performance of DSSLIC over the other algorithms is visible in these results too. However, when it comes to the other algorithms’ performance, the MS-SSIM experiment rankings do not apply any more. All together HEVC, VCC, and AV1, rank the second best, showing very close performance to each other. Among the other four algorithms: BPG and J2K come thereafter showing better performance than JPEG in the majority of the cases. Yet, their performance seems to vary depending on the compression level applied and across different datasets. For instance, BPG shows better performance (than J2K) when considering IITD dataset or the lower compression rate (B) on the Casia4i dataset, while J2K shows better or at least equal performance in all other cases. At the end comes EOIC which shows the worst performance almost in all cases.
Figure 5 demonstrates the algorithms’ performance for each compression level in the form of bar-graphs.
In order to provide an objective insight into the quality of images generated, we calculated the BRISQUE measure for the obtained compressed images.
Table 5 shows the corresponding results for each dataset (averaged over all images) in terms of BRISQUE. The dominating performance of DSSLIC over the other algorithms is visible in these results also. When it comes to the other algorithms’ performance, the LFBVS experiment performance rankings rather applies: EOIC again shows the worst performance almost in all the cases, and all together HEVC, VCC, and AV1, rank the second best, showing very close performance to each other. Among the other three algorithms: BPG comes next showing better performance than the other two algorithms (J2K and JPEG) in the majority of the cases (excluding the Lower compression level (B) for the Casia5a, Notredame, and IITD datasets), and J2K and JPEG together come at the end, showing rather similar performance.
Figure 6 demonstrates the algorithms’ performance for each compression level in the form of bar-graphs as well. Unsurprisingly, in all the compression evaluation experiments (MS-SSIM, LFBVS, and BRISQUE), the higher compression rate (reflected in the left graphs in the corresponding figures) decreased the compression performance over all the datasets and algorithms (including DSSLIC).
In the next stage of our experiments, we applied the biometric recognition pipeline (as described in
Section 4) to all the compressed images obtained, and evaluated the biometric comparison accuracy, in terms of EER, for the two levels of compression. In addition to the two segmentation algorithms (Osiris and CAHT) used, we considered an optimal segmentation configuration as well, utilizing the manually annotated segmentation drop masks. The optimal segmentation configuration was used to disentangle the distorting effect of the compression on the iris unique biometric traits (which directly affect their subsequent recognition performance) from the iris structural feature distortions which may cause the segmentation failures.
Table 6 and
Table 7 show the recognition results using the CAHT segmentation and manual segmentation, respectively. As it can be seen in
Table 6, recognition does not work at all for the Casia5a and Notredame datasets when using the CAHT segmentation algorithm. The DSSLIC compression shows the best performance only on the IITD and Casia4i datasets (when higher compression rate (A) considered). However, when we use the manual segmentations (
Table 7): while the recognition still does not work for Notredame data, yet for the remaining datasets, DSSLIC results are never surpassed by any other comparison compression algorithm. Given the fact that the DSSLIC also produces the smallest actual files, these results imply that DSSLIC compression is able to preserve the iris unique biometric traits bests-certainly better than the other comparison algorithms, as the segmentation defects were ruled out using the manual segmentations.
Table 8 demonstrates the results when applying the OSIRIS algorithm for segmentation. As it can be observed, recognition on the Notredame data does not work either, but otherwise the ranking of the algorithms is fairly different. DSSLIC no longer performs best in any case. If we compare the results obtained using CAHT and OSIRIS segmentation algorithms, we can easily interpret that the segmentation methods and the logic behind them can react quite differently to the artifacts introduced to the image during the compression process, and thus deliver very different results having identically compressed iris images as the input. Overall, the clearly higher compression performance of the DSSLIC algorithm is not directly translated into best recognition accuracy, except in the configuration where the manual segmentation is used. It should be noted that by using the manual drop masks, the measures are only impacted by the possible artifacts introduced by the compression to the iris texture, whereas when using CAHT and OSIRIS as the segmentation modules, the measures are impacted by both the eventual segmentation failures introduced by the segmentation modules, as well as the artifacts introduced by the compression.
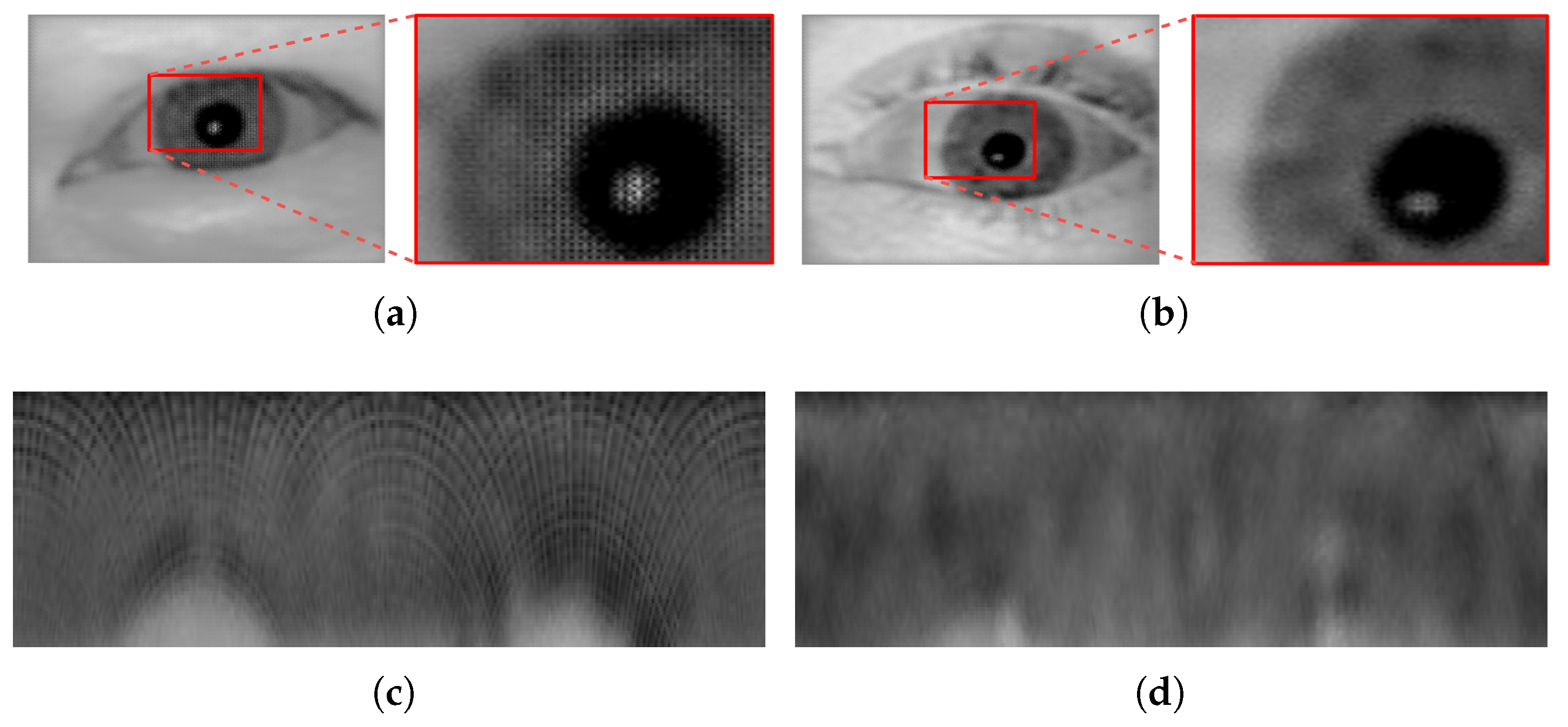
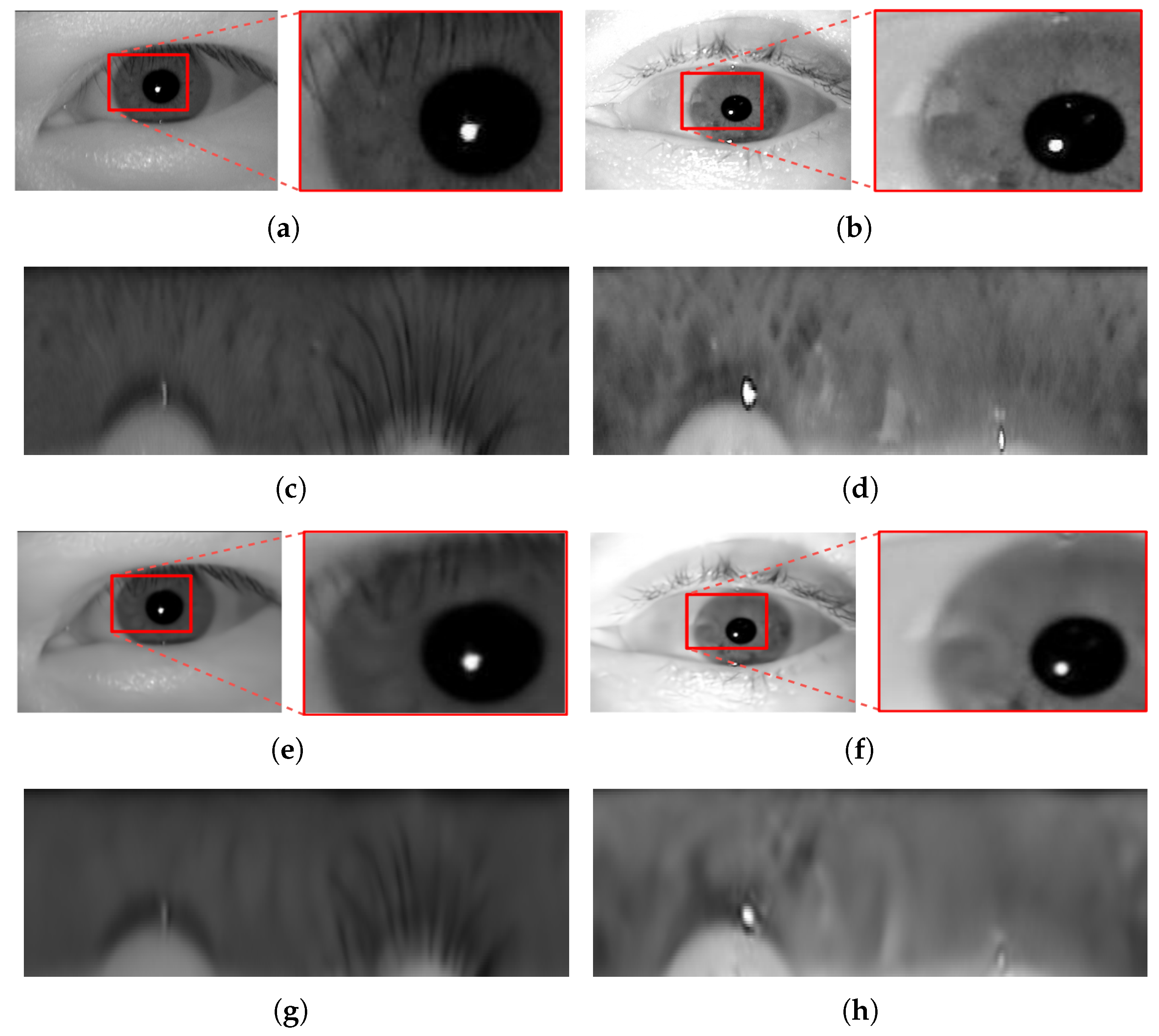
Concerning the other deep-learning-based algorithm (EOIC) performance: The algorithm proved (based on the results obtained) to perform better than the CPDIC model which we used in our previous work [
1]. The analysis of the output images generated by the CPDIC model (see
Figure 7) in our previous work revealed some artifacts which were distributed uniformly over all the images in a block-shaped pattern. These artifacts were more severe and intense in the high texture areas, specifically the iris texture areas. The persistence of these artifacts over all images clearly undermined their recognition performance. When inspecting the iris images obtained using the EOIC model (see
Figure 8), we can clearly observe that such artifacts do not exist, and thus the perceptual quality of the images generated are much better than those generated by CPDIC model. Yet, we should note that the iris unique biometric traits seem not to be well preserved and reconstructed in the generated images compared to the images generated by, e.g., DSSLIC. This in fact directly affects the the corresponding recognition results as reflected in
Table 7.
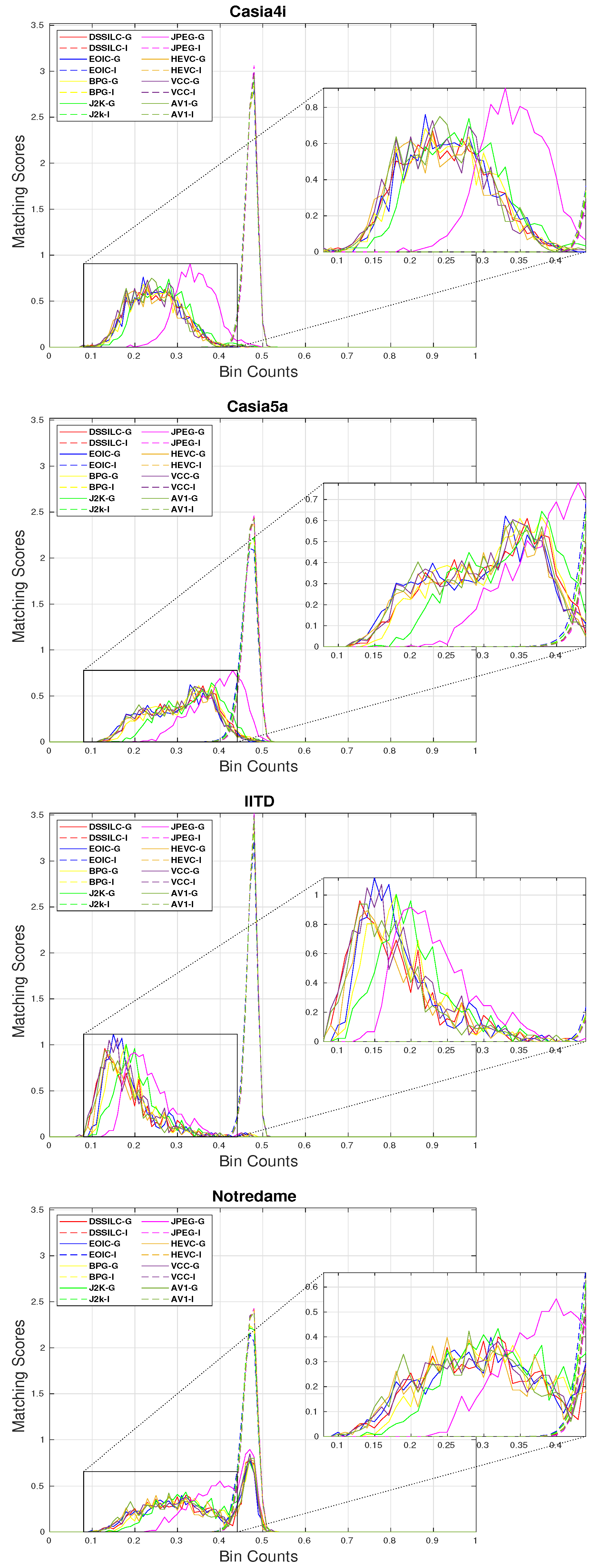
We further analyzed the distribution of the genuine and impostor scores obtained during the recognition experiments, to provide a better understanding of how the quality of biometric traits in the compressed images can affect their actual recognition performance.
Figure 9 demonstrates the genuine and impostor distributions for the different compression methods for each dataset when considering the optimal segmentation configuration (to exclude the influence of probable segmentation errors). Each pair of curves (genuine and impostor) are indicated by color while line-type distinguishes between impostor (dashed) and genuine (solid). As it can be seen, the impostor curves remain virtually unchanged, while the genuine curves fluctuate almost in all cases. This leads us to the observation that the compression process affects the genuine scores, by introducing artifacts into the iris images which subsequently alter the distinct patterns that are present in the genuine samples, making the compressed images more dissimilar, and thus deteriorating the overall EER scores at the end.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}