
Adaptive Slicing Method of the Spatiotemporal Event Stream Obtained from a Dynamic Vision Sensor


Abstract
:1. Introduction
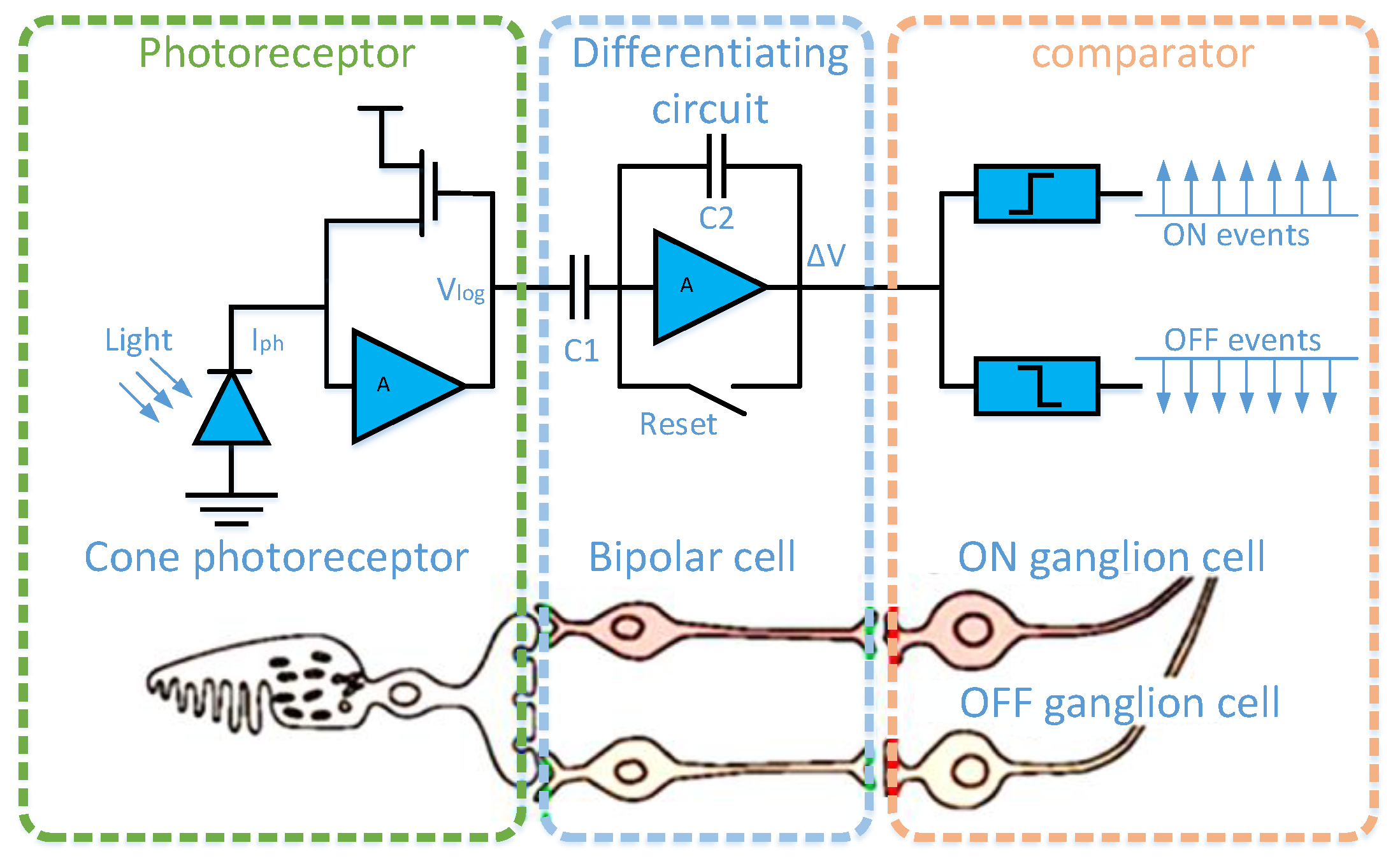
1.1. Dynamic Vision Sensor
1.2. The Related Work to Building Virtual Frames by Accumulating Events
1.3. The Main Contributions of This Paper
- (1)
- A past event elimination mechanism is proposed, which can obtain a virtual frame with clear and sharp edges at any time;
- (2)
- The adaptive slicing of the spatiotemporal event stream will not cause object motion blur or loss of object information;
- (3)
- In order to adapt to different motion scenes, the calculation parameters are updated adaptively.
2. Materials and Methods
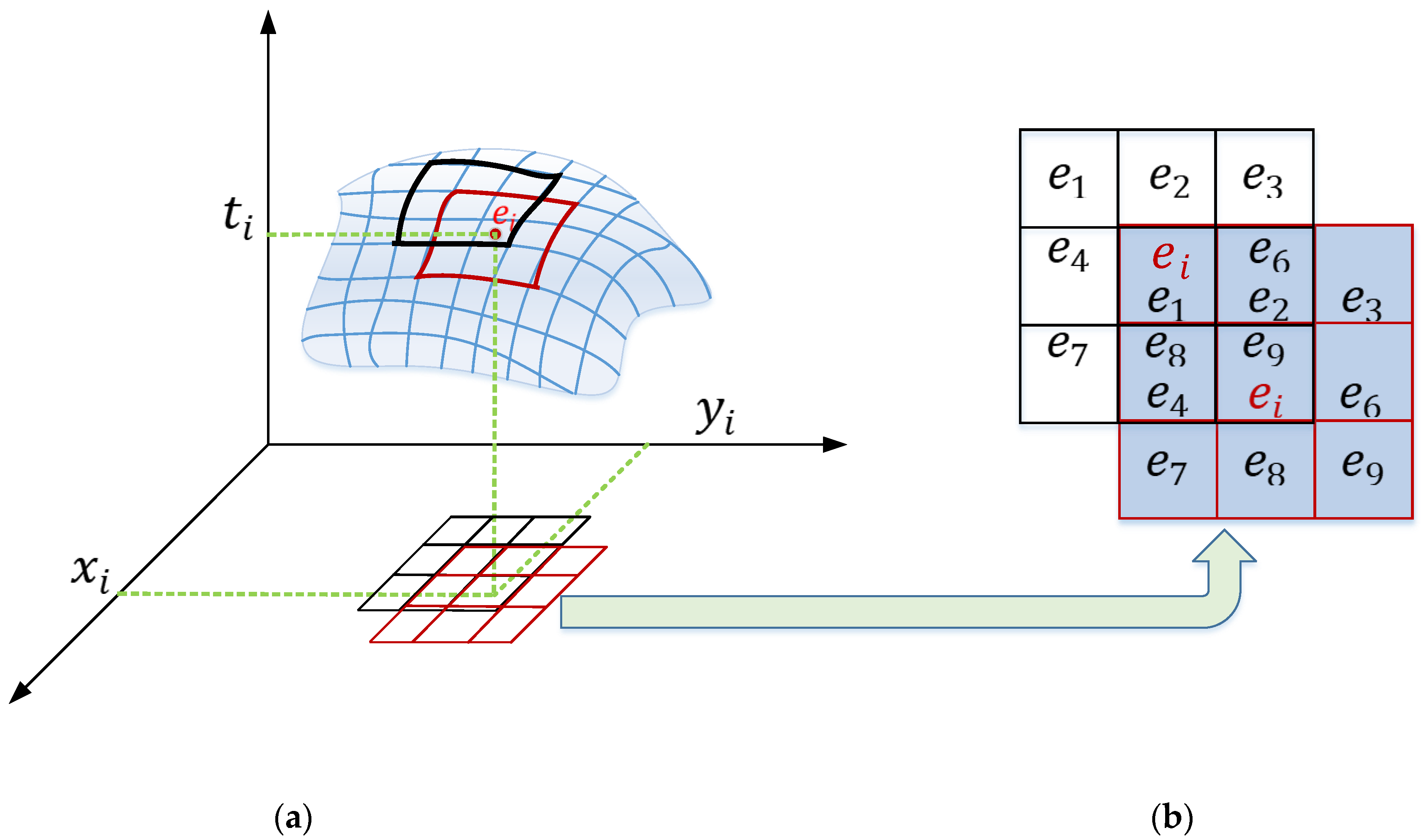
2.1. The Past Events Remove Mechanism
| Algorithm 1 Past events remove mechanism | |
| Input: Spatiotemporal event stream: | |
| Output: An event stream that can form a reference frame with clear and sharp edges: | |
| 1 | For in do |
| 2 | |
| 3 | Calculating the optical flow information of R |
| 4 | Get of by vector synthesis |
| 5 | For ∈R do |
| 6 | 2, 3, and 4 |
| 7 | End |
| 8 | Get of by local consistency |
| 9 | Obtain the past events of according to the movement direction of the event, and remove the past events. |
| 10 | End |
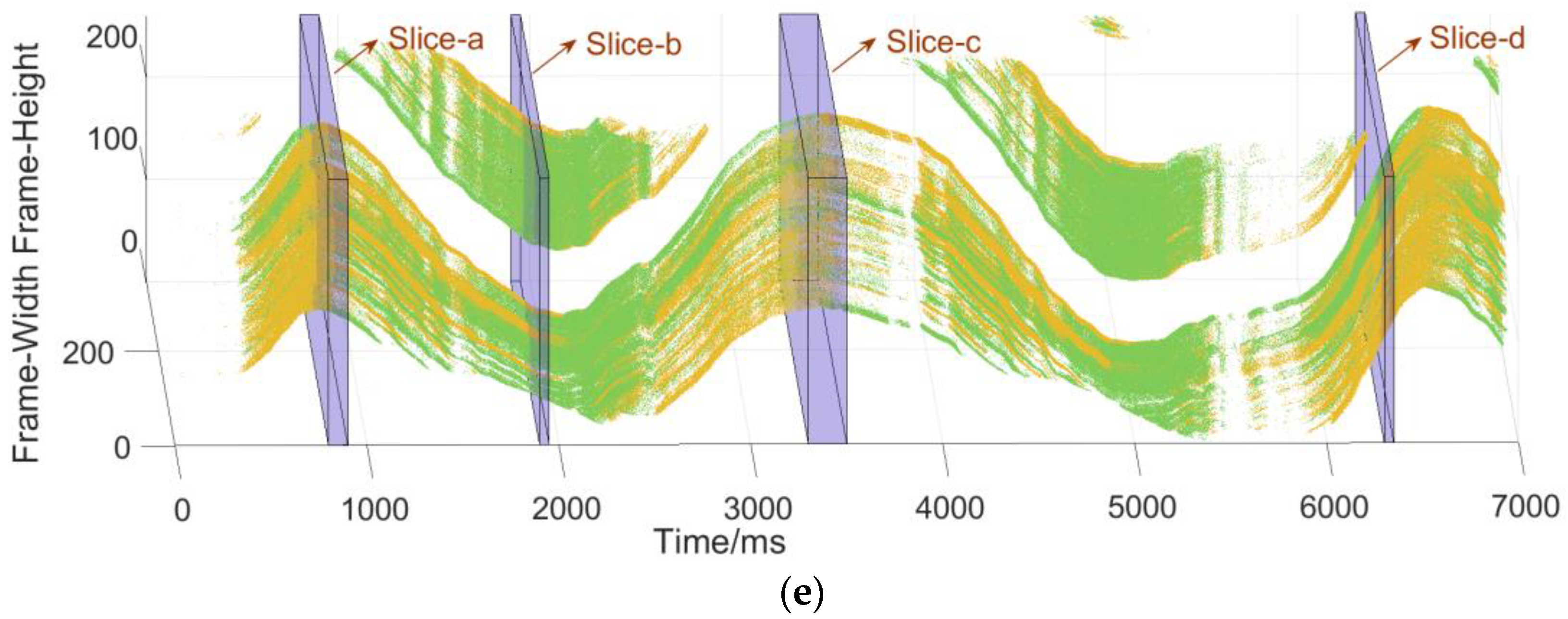
2.2. Adaptive Slicing of the Spatiotemporal Event Stream
| Algorithm 2 Adaptive slicing of spatiotemporal event stream | |
| Input: Spatiotemporal event stream: | |
| Output: The spatiotemporal event slice which contains complete moving object information without motion blur. | |
| 1 | Get a reference frame by Algorithm 1 |
| 2 | For = 1:1:n do |
| 3 | = Algorithm3 () |
| 4 | End |
| 5 | Calculate the confidence interval [] of sample [] |
| 6 | = 1 |
| 7 | For do |
| 8 | = Algorithm3 () |
| 9 | If |
| 10 | Break. Here contains complete moving object information without motion blur. |
| 11 | Else if ( or |
| 12 | Break, Update confidence interval, = 1 |
| 13 | Else |
| 14 | continue |
| 15 | End |
2.2.1. Calculation of Similarity
| Algorithm 3 Calculation method of image similarity | |
| Input: Spatiotemporal event stream: And Output of algorithm 1: | |
| Output: Similarity between and : | |
| 1 | Build event stream as a virtual frame: |
| 2 | Build as an idea virtual frame: |
| 3 | DCT() and DCT( |
| 4 | Extract the hash values of and |
| 5 | Compare the similarity of hash values |
2.2.2. Calculation of Confidence Interval
2.2.3. Adaptive Updating of Calculation Parameters
3. Experiment
3.1. Data Sets
3.1.1. Public Data Sets
- The asynchronous event stream;
- Intensity images at about 24 Hz;
- Inertial measurements (3-axis gyroscope and 3-axis accelerometer) at 1 kHz;
- Ground-truth camera poses from a motion-capture system k with sub-millimeter precision at 200 Hz (for the indoor data sets);
- The intrinsic camera matrix.
3.1.2. Our Data Sets
- A single moving object in a static background, such as a tank, plane, or car;
- The object having a complex motion state, such as the sudden disappearance or increase of the object in the motion scene along with a change of speed;
- Moving object in a dynamic background.
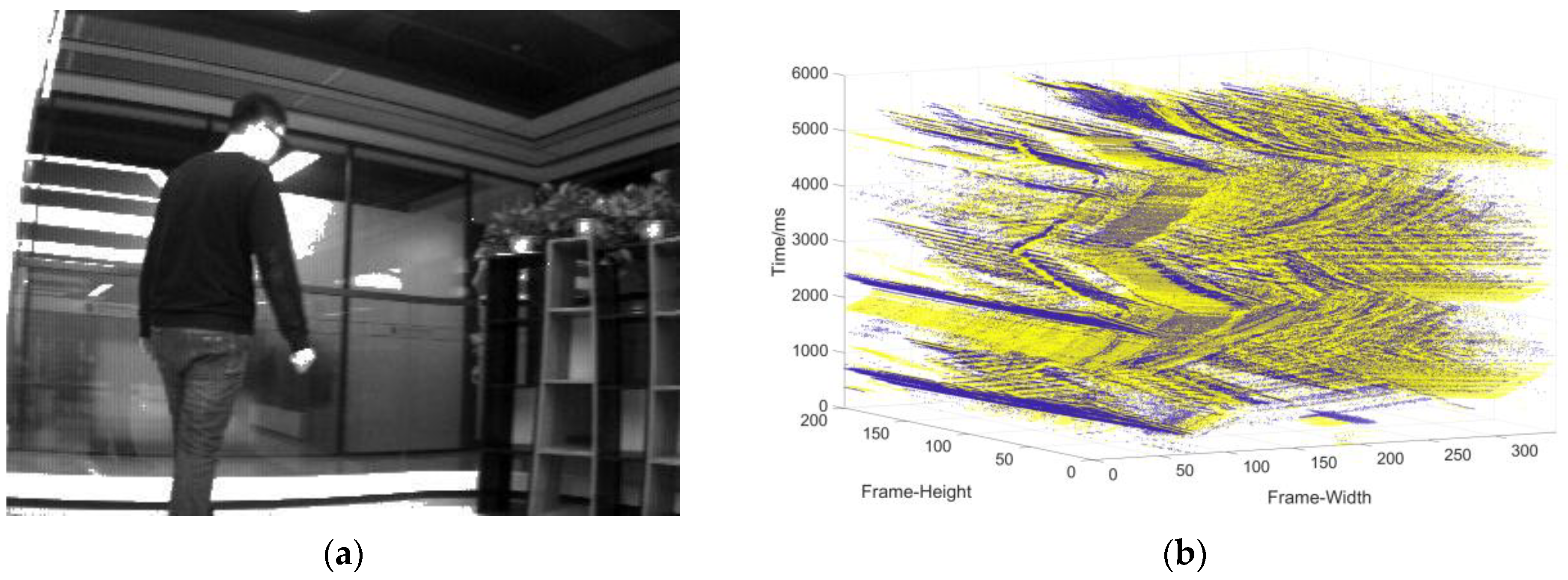
- Data collection of the single moving object in the static background: the camera is stationary, and the object moves at a changing speed (Figure 9).
- Data collection in complex motion: the camera is stationary, there is multi-object motion, and the number of objects sometimes increases and sometimes decreases (Figure 10).
- Data collection in the dynamic background: the object moves at variable speed in a complex background environment with the camera moving (Figure 11).
3.2. Comparisons and Analysis
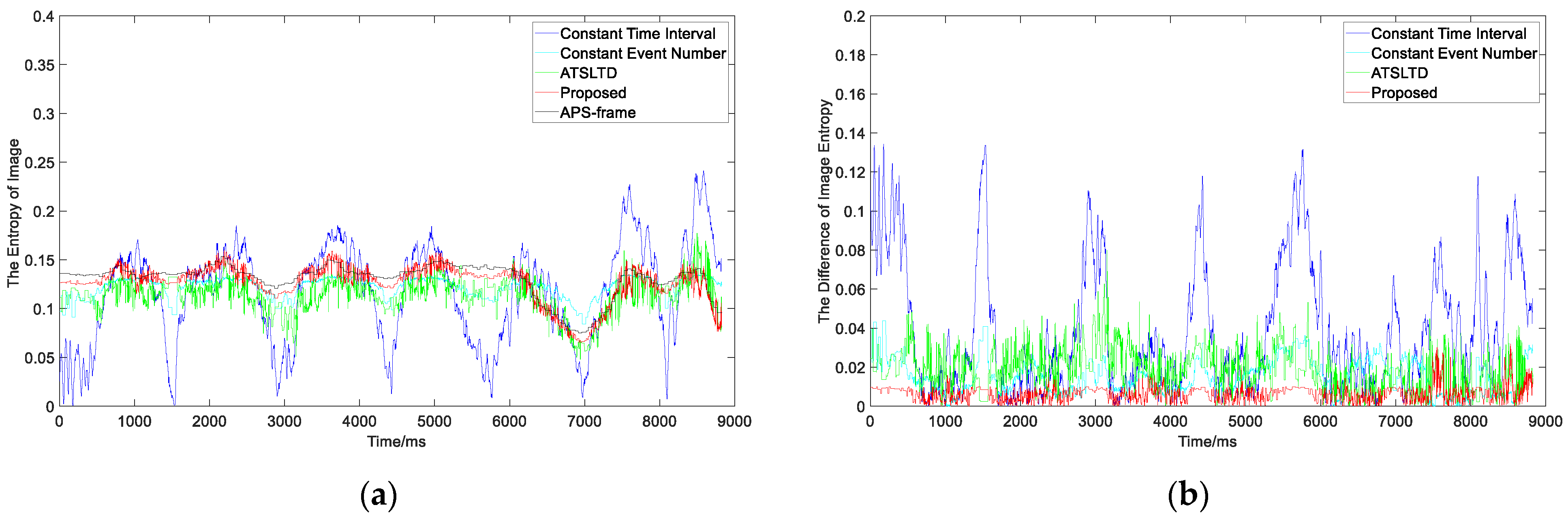
3.2.1. Experiment I
- Experiment
- 2.
- Analysis
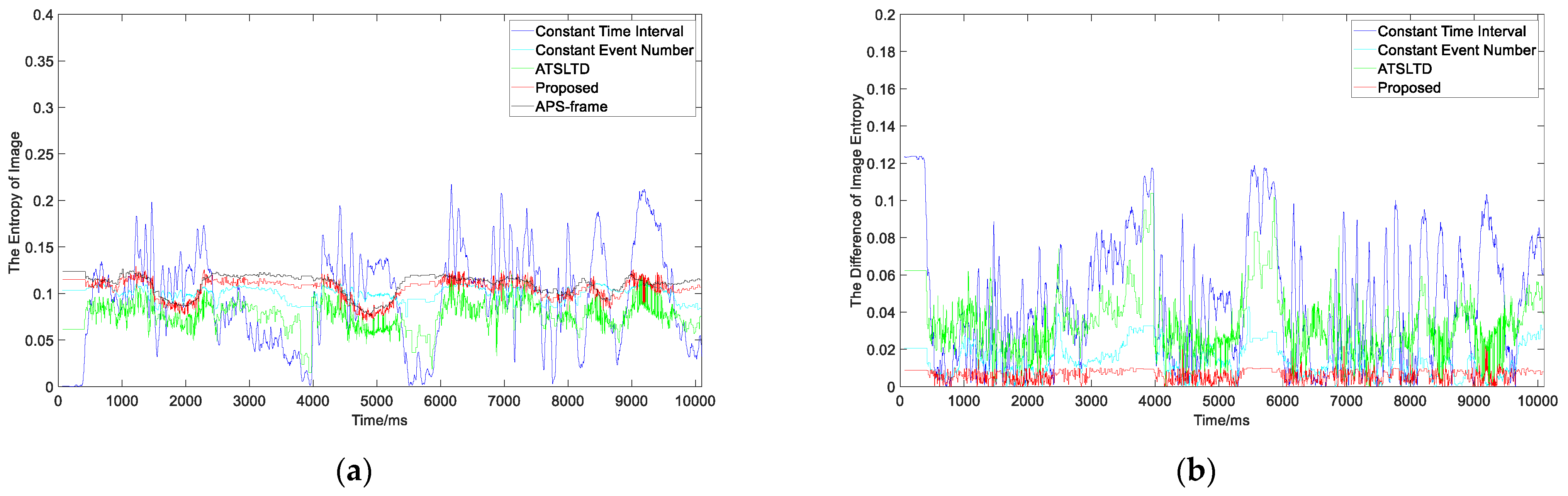
3.2.2. Experiment II
- Experiment
- 2.
- Analysis
3.2.3. Experiment III
- Experiment
- 2.
- Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 × 128 120 dB 15 µ Latency Asynchronous Temporal Contrast Vision Sensor. IEEE J. Solid-State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef] [Green Version]
- Posch, C.; Matolin, D.; Wohlgenannt, R. A QVGA 143 dB dynamic range frame-free PWM image sensor with lossless pixellevel video compression and time-domain CDS. IEEE J. Solid-State Circuits 2011, 46, 259–275. [Google Scholar] [CrossRef]
- Brandli, C.; Berner, R.; Yang, M.; Liu, S.C.; Delbruck, T. A 240 × 180 130 db 3 µs latency global shutter spatiotemporal vision sensor. IEEE J. Solid-State Circuits 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Gallego, G.; Delbruck, T.; Orchard, G.M.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.; Conradt, J.; Daniilidis, K.; et al. Event-based Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell 2020, 44, 154–180. [Google Scholar] [CrossRef] [PubMed]
- Delbruck, T. Neuromorphic vision sensing and processing. In Proceedings of the Conference on Solid-State Device Research (ESSDERC), Lausanne, Switzerland, 12–15 September 2016. [Google Scholar]
- Glover, A.; Bartolozzi, C. Event-driven ball detection and gaze fixation in clutter. In Proceedings of the IEEE International Workshop on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016. [Google Scholar]
- Piatkowska, E.; Belbachir, A.N.; Schraml, S.; Gelautz, M. Spatiotemporal multiple persons tracking using dynamic vision sensor. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Glover, A.; Bartolozzi, C. Robust visual tracking with a freely-moving event camera. In Proceedings of the IEEE International Workshop on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Du, B.; Li, W.; Wang, Z.; Xu, M.; Gao, T.; Li, J.; Wen, H. Event Encryption for Neuromorphic Vision Sensors: Framework, Algorithm, and Evaluation. Sensors 2021, 21, 4320. [Google Scholar] [CrossRef] [PubMed]
- Litzenberger, M.; Kohn, B.; Belbachir, A.N.; Donath, N.; Gritsch, G.; Garn, H.; Kohn, B.; Posch, C.; Schraml, S. Estimation of vehicle speed based on asynchronous data from a silicon retina optical sensor. In Proceedings of the IEEE International Conference on Intelligent Transportation, Toronto, ON, Canada, 17–20 September 2006. [Google Scholar]
- Colonnier, F.; Della Vedova, L.; Orchard, G. ESPEE: Event-Based Sensor Pose Estimation Using an Extended Kalman Filter. Sensors 2021, 21, 7840. [Google Scholar] [CrossRef] [PubMed]
- Perez-Peña, F.; Morgado-Estevez, A.; Linares-Barranco, A.; Jimenez-Fernandez, A.; Gomez-Rodriguez, F.; Jimenez-Moreno, G.; Lopez-Coronado, J. Neuro-inspired spike-based motion: From dynamic vision sensor to robot motor open-loop control through spike-VITE. Sensors 2013, 13, 15805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Won, J.-Y.; Ryu, H.; Delbruck, T.; Lee, J.H.; Hu, J. Proximity Sensing Based on a Dynamic Vision Sensor for Mobile Devices. IEEE Trans. Ind. Electron. 2015, 62, 536–544. [Google Scholar] [CrossRef]
- Chin, T.J.; Bagchi, S.; Eriksson, A.; Van Schaik, A. Star tracking using an event camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Posch, C.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Delbruck, T. Retinomorphic Event-Based Vision Sensors: Bioinspired Cameras with Spiking Output. Proc. IEEE 2014, 102, 1470–1484. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; Lv, H.; Liu, H.; Zhang, Y.; Xiao, Y.; Han, C. Event density based denoising method for dynamic vision sensor. Appl. Sci. 2020, 10, 2024. [Google Scholar] [CrossRef] [Green Version]
- Mohamed, S.A.; Haghbayan, M.H.; Rabah, M.; Heikkonen, J.; Tenhunen, H.; Plosila, J. Towards dynamic monocular visual odometry based on an event camera and IMU sensor. In Proceedings of the Springer International Conference on Intelligent Transport Systems, Braga, Portugal, 4–6 December 2019. [Google Scholar]
- Alzugaray, I.; Chli, M. Asynchronous corner detection and tracking for event cameras in real time. IEEE Robot. Autom. Letters 2018, 3, 3177–3184. [Google Scholar] [CrossRef] [Green Version]
- Baby, S.A.; Vinod, B.; Chinni, C.; Mitra, K. Dynamic vision sensors for human activity recognition. In Proceedings of the IEEE Asian Conference on Pattern Recognition (ACPR), Nanning, China, 26–29 November 2017. [Google Scholar]
- Lagorce, X.; Orchard, G.; Galluppi, F.; Shi, B.E.; Benosman, R.B. Hots: A hierarchy of event-based time-surfaces for pattern recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1346–1359. [Google Scholar] [CrossRef]
- Chen, H.; Wu, Q.; Liang, Y.; Gao, X.; Wang, H. Asynchronous tracking-by-detection on adaptive time surfaces for event-based object tracking. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Liu, M.; Delbruck, T. Adaptive time-slice block-matching optical flow algorithm for dynamic vision sensors. In Proceedings of the British Machine Vision Conference, Northumbria, UK, 6 September 2018. [Google Scholar]
- Mueggler, E.; Forster, C.; Baumli, N.; Gallego, G.; Scaramuzza, D. Lifetime estimation of events from dynamic vision sensors. In Proceedings of the 2015 IEEE international conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Aung, M.T.; Teo, R.; Orchard, G. Event-based plane-fitting optical flow for dynamic vision sensors in FPGA. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018. [Google Scholar]
- Zhan, Z.; Wang, C.; Wang, X.; Liu, Y. Optimization of incremental structure from motion combining a random kd forest and pHash for unordered images in a complex scene. J. Electron. Imaging 2018, 27, 013024. [Google Scholar] [CrossRef]
- Mueggler, E.; Rebecq, H.; Gallego, G.; Delbruck, T.; Scaramuzza, D. The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM. Int. J. Robot. Res. 2017, 36, 142–149. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Method | The Mean of Average Difference |
|---|---|
| Constant Event Number | 0.0150 |
| Constant Time Interval | 0.0390 |
| ATSLTD | 0.0186 |
| Proposed | 0.0064 |
| The Method | The Mean of Average Difference |
|---|---|
| Constant Event Number | 0.0135 |
| Constant Time Interval | 0.0459 |
| ATSLTD | 0.0335 |
| Proposed | 0.0061 |
| The Method | The Mean of Average Difference |
|---|---|
| Constant Event Number | 0.0393 |
| Constant Time Interval | 0.2064 |
| ATSLTD | 0.2884 |
| Proposed | 0.0071 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhao, Y.; Lv, H.; Feng, Y.; Liu, H.; Han, C. Adaptive Slicing Method of the Spatiotemporal Event Stream Obtained from a Dynamic Vision Sensor. Sensors 2022, 22, 2614. https://doi.org/10.3390/s22072614
Zhang Y, Zhao Y, Lv H, Feng Y, Liu H, Han C. Adaptive Slicing Method of the Spatiotemporal Event Stream Obtained from a Dynamic Vision Sensor. Sensors. 2022; 22(7):2614. https://doi.org/10.3390/s22072614
Chicago/Turabian StyleZhang, Yisa, Yuchen Zhao, Hengyi Lv, Yang Feng, Hailong Liu, and Chengshan Han. 2022. "Adaptive Slicing Method of the Spatiotemporal Event Stream Obtained from a Dynamic Vision Sensor" Sensors 22, no. 7: 2614. https://doi.org/10.3390/s22072614
APA StyleZhang, Y., Zhao, Y., Lv, H., Feng, Y., Liu, H., & Han, C. (2022). Adaptive Slicing Method of the Spatiotemporal Event Stream Obtained from a Dynamic Vision Sensor. Sensors, 22(7), 2614. https://doi.org/10.3390/s22072614