
Defect Detection of Subway Tunnels Using Advanced U-Net Network


Abstract
:1. Introduction
- Problem 1:Subway tunnel images have a high resolution and limited areas of defects. Hence, the problem of imbalance between the background and foreground in semantic segmentation is prominent.
- Problem 2:Defects in subway tunnels have multi-scale variations. It is necessary to distinguish between these types since the repair action differs depending on the type of defect.
- Problem 3:Subway tunnel image contains a complex background. Although there are no defects in the background area, it often contains structures similar to the defects due to the construction conditions.
- We propose a novel advanced U-Net for defect detection using subway tunnel images.
- We design an architecture that can grasp the characteristics of a variety of defects. The experimental results show the effectiveness of our new architecture.
2. Related Works
2.1. Computer Vision Task for Application
2.2. Deep Learning with U-Net and Its Variants
2.3. Defect Detection in Infrastructures
3. Dataset
4. Methodology
4.1. Data Augmentation
4.2. Network Architecture
5. Experiments and Results
5.1. Settings
5.2. Results
5.2.1. Quantitative Analysis
- Limitation of Deeplab-v3+ (CM1):Deeplab-v3+ used atrous convolution, ASPP module, and a simplified decoder branch, achieving great improvement compared with the baseline. There was a slight difference in the detection accuracy for various kinds of defect. Although Deeplab-v3+ applied multiple kinds of modules to improve detection performance for multi-scale defects, it still lacks detection accuracy for large-scale defects as shown in Table 3.
- FCN and SegNet (CM2, CM3):FCN and SegNet, as classic segmentation networks, show a certain degree of incompatibility in our subway tunnel dataset, not only with a low accuracy but also with a large number of false detection instances as shown in Table 3. Especially, the performance of SegNet is extremely poor. Although the detection accuracy of small targets such as cracks can be maintained, it is almost impossible to detect large defects as shown in Table 4. These result in the low overall detection accuracy and precision of the network. Unlike U-Net, the SegNet decoder uses the max-pooling indices received from the corresponding encoder to perform nonlinear upsampling of the input feature map as a typical symmetric encoder–decoder architecture. It is considered that this function did not work well in the subway tunnel dataset.
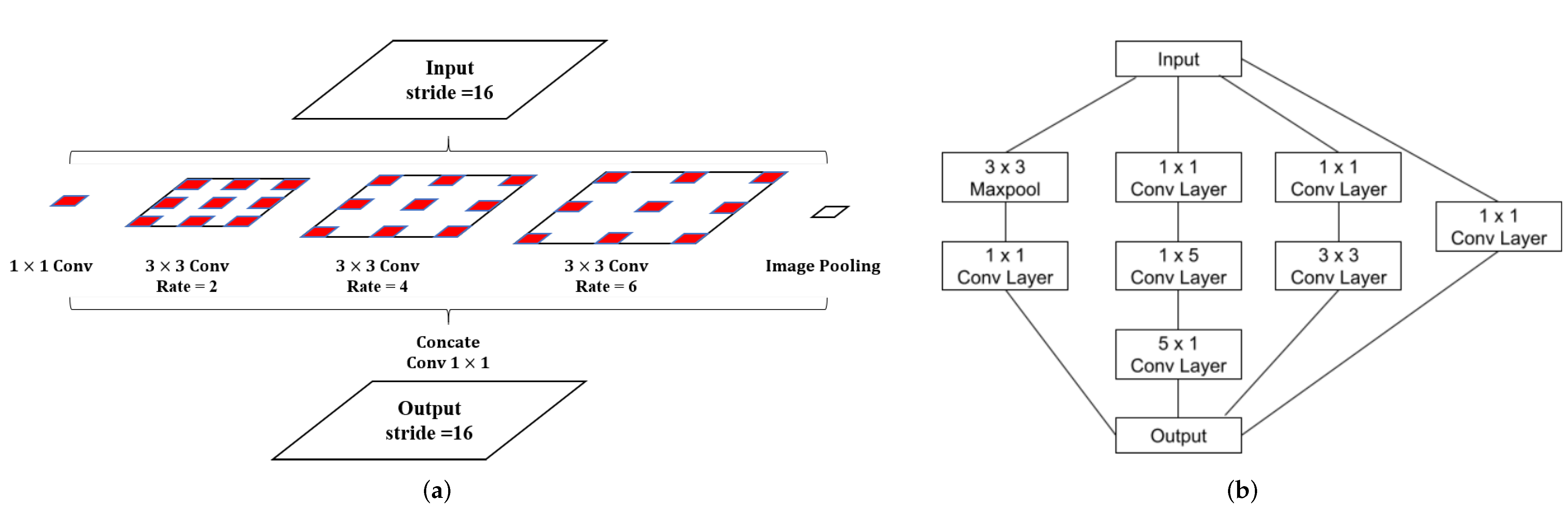
- Effectiveness of ASPP module (CM4):In CM4, this module increases F-measure from 0.428 to 0.444 and IoU from 0.272 to 0.286 compared with the baseline module (CM7) in Table 3. Additionally, the obtained results from Table 4 suggest that the addition of the ASPP module significantly improved the detection performance of small-, medium-, and large-scale defects. The obtained results show the effectiveness of the ASPP module.
- Effectiveness of layer extend operation (CM5):In CM5, compared with the baseline (CM7), this module increases F-measure from 0.428 to 0.495 and IoU from 0.272 to 0.329 as shown in Table 3. Additionally, Table 4 suggests that CM5 is superior to CM4, CM6, and the baseline (CM7). These results suggest that deeper networks improve the detection of all scales of defects. However, this operation could not be applied to networks with the ASPP module due to patch size limitations in the experimental setting.
- Effectiveness of Inception module (CM6):In CM6, we only replaced all convolution blocks with the inception module. This operation increased F-measure from 0.428 to 0.443 and IoU from 0.272 to 0.285 compared with the baseline (CM7) in Table 3. Additionally, Table 4 shows that the detection rate of each scale significantly improved compared with the baseline. This indicates that the addition of the inception module can contribute to the representation ability of low- and high-level information.
- Analysis of the proposed method:As shown in Table 3, PM outperformed all other methods. Furthermore, from Table 4, we can see that PM achieves better accuracy in detecting large-scale defects but has some limitations in detecting small-scale defects. The limitation of small-scale defects may influence the detection performance of the inspection task. Thus, qualitative analysis is also required.
5.2.2. Qualitative Analysis
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ministry of Land, Infrastructure, Transport and Tourism; White Paper on Land, Infrastructure, Transport and Tourism in Japan. 2019. Available online: https://www.mlit.go.jp/en/statistics/white-paper-mlit-index.html (accessed on 26 June 2019).
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for AI-enabled IoT devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed]
- Underwood, B.S.; Guido, Z.; Gudipudi, P.; Feinberg, Y. Increased costs to US pavement infrastructure from future temperature rise. Nat. Clim. Chang. 2017, 7, 704–707. [Google Scholar] [CrossRef]
- Onuma, A.; Tsuge, T. Comparing green infrastructure as ecosystem-based disaster risk reduction with gray infrastructure in terms of costs and benefits under uncertainty: A theoretical approach. Int. J. Disaster Risk Reduct. 2018, 32, 22–28. [Google Scholar] [CrossRef]
- Lee, J.; Park, G.L.; Han, Y.; Yoo, S. Big data analysis for an electric vehicle charging infrastructure using open data and software. In Proceedings of the Eighth International Conference on Future Energy Systems, Hong Kong, China, 16–19 May 2017; pp. 252–253. [Google Scholar]
- Lv, Z.; Hu, B.; Lv, H. Infrastructure monitoring and operation for smart cities based on IoT system. IEEE Trans. Ind. Informatics 2019, 16, 1957–1962. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Wang, T.; Sherratt, R.S.; Zhang, J. Big data service architecture: A survey. J. Internet Technol. 2020, 21, 393–405. [Google Scholar]
- Arfat, Y.; Usman, S.; Mehmood, R.; Katib, I. Big data tools, technologies, and applications: A survey. In Smart Infrastructure and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 453–490. [Google Scholar]
- Zhu, L.; Yu, F.R.; Wang, Y.; Ning, B.; Tang, T. Big data analytics in intelligent transportation systems: A survey. IEEE Trans. Intell. Transp. Syst. 2018, 20, 383–398. [Google Scholar] [CrossRef]
- Montero, R.; Victores, J.G.; Martinez, S.; Jardón, A.; Balaguer, C. Past, present and future of robotic tunnel inspection. Autom. Constr. 2015, 59, 99–112. [Google Scholar] [CrossRef]
- Pouliot, N.; Richard, P.L.; Montambault, S. LineScout Technology Opens the Way to Robotic Inspection and Maintenance of High-Voltage Power Lines. IEEE Power Energy Technol. Syst. J. 2015, 2, 1–11. [Google Scholar] [CrossRef]
- Dung, C.V. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Huang, Z.; Fu, H.; Chen, W.; Zhang, J.; Huang, H. Damage detection and quantitative analysis of shield tunnel structure. Autom. Constr. 2018, 94, 303–316. [Google Scholar] [CrossRef]
- Hastak, M.; Baim, E.J. Risk factors affecting management and maintenance cost of urban infrastructure. J. Infrastruct. Syst. 2001, 7, 67–76. [Google Scholar] [CrossRef]
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Hashimoto, S. Fast crack detection method for large-size concrete surface images using percolation-based image processing. Mach. Vis. Appl. 2010, 21, 797–809. [Google Scholar] [CrossRef]
- Liu, Z.; Suandi, S.A.; Ohashi, T.; Ejima, T. Tunnel crack detection and classification system based on image processing. In Proceedings of the Machine Vision Applications in Industrial Inspection X, San Jose, CA, USA, 21–22 January 2002; Volume 4664, pp. 145–152. [Google Scholar]
- Yiyang, Z. The design of glass crack detection system based on image preprocessing technology. In Proceedings of the 2014 IEEE 7th Joint International Information Technology and Artificial Intelligence Conference, Chongqing, China, 20–21 December 2014; pp. 39–42. [Google Scholar]
- Nishikawa, T.; Yoshida, J.; Sugiyama, T.; Fujino, Y. Concrete crack detection by multiple sequential image filtering. Comput.-Aided Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Khoa, N.L.D.; Anaissi, A.; Wang, Y. Smart infrastructure maintenance using incremental tensor analysis. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 959–967. [Google Scholar]
- Zhang, W.; Zhang, Z.; Qi, D.; Liu, Y. Automatic crack detection and classification method for subway tunnel safety monitoring. Sensors 2014, 14, 19307–19328. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications. Foundations and Trends® in Signal Processing. Signal Process 2014, 7, 197–387. [Google Scholar]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M.; Gao, M.; et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote. Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 7263–7271. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Samala, R.K.; Chan, H.P.; Hadjiiski, L.; Helvie, M.A.; Richter, C.D.; Cha, K.H. Breast Cancer Diagnosis in Digital Breast Tomosynthesis: Effects of Training Sample Size on Multi-Stage Transfer Learning Using Deep Neural Nets. IEEE Trans. Med. Imaging 2019, 38, 686–696. [Google Scholar] [CrossRef] [PubMed]
- Togo, R.; Watanabe, H.; Ogawa, T.; Haseyama, M. Deep convolutional neural network-based anomaly detection for organ classification in gastric X-ray examination. Comput. Biol. Med. 2020, 123, 103903. [Google Scholar] [CrossRef]
- Togo, R.; Yamamichi, N.; Mabe, K.; Takahashi, Y.; Takeuchi, C.; Kato, M.; Sakamoto, N.; Ishihara, K.; Ogawa, T.; Haseyama, M. Detection of gastritis by a deep convolutional neural network from double-contrast upper gastrointestinal barium X-ray radiography. J. Gastroenterol. 2019, 54, 321–329. [Google Scholar] [CrossRef] [Green Version]
- Togo, R.; Hirata, K.; Manabe, O.; Ohira, H.; Tsujino, I.; Magota, K.; Ogawa, T.; Haseyama, M.; Shiga, T. Cardiac sarcoidosis classification with deep convolutional neural network-based features using polar maps. Comput. Biol. Med. 2019, 104, 81–86. [Google Scholar] [CrossRef] [Green Version]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Togo, R.; Ogawa, T.; Haseyama, M. Synthetic Gastritis Image Generation via Loss Function-Based Conditional PGGAN. IEEE Access 2019, 7, 87448–87457. [Google Scholar] [CrossRef]
- Iglovikov, V.; Shvets, A. TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted Res-UNet for High-Quality Retina Vessel Segmentation. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar] [CrossRef]
- Guan, S.; Khan, A.A.; Sikdar, S.; Chitnis, P.V. Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal. arXiv 2018, arXiv:1808.10848. [Google Scholar]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Informatics 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Kim, B.; Cho, S. Automated Multiple Concrete Damage Detection Using Instance Segmentation Deep Learning Model. Appl. Sci. 2020, 10, 8008. [Google Scholar] [CrossRef]
- Bai, Y.; Sezen, H.; Yilmaz, A. End-to-end Deep Learning Methods for Automated Damage Detection in Extreme Events at Various Scales. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2020. [Google Scholar]
- Huang, H.; Cheng, W.; Zhou, M.; Chen, J.; Zhao, S. Towards Automated 3D Inspection of Water Leakages in Shield Tunnel Linings Using Mobile Laser Scanning Data. Sensors 2020, 20, 6669. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2020, 67, 8016–8025. [Google Scholar] [CrossRef]
- Chen, H.; Lin, H.; Yao, M. Improving the Efficiency of Encoder-Decoder Architecture for Pixel-Level Crack Detection. IEEE Access 2019, 7, 186657–186670. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Wang, A.; Togo, R.; Ogawa, T.; Haseyama, M. Detection of Distress Region from Subway Tunnel Images via U-net-based Deep Semantic Segmentation. In Proceedings of the IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 766–767. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Size/Stride | Output Size | Depth |
|---|---|---|---|
| Inception Module | 3 × 3/1 | 256 × 256 × 64 | 3 |
| Inception Module | 3 × 3/1 | 256 × 256 × 64 | 3 |
| Inception Module | 3 × 3/1 | 256 × 256 × 64 | 3 |
| Max Pooling | 3 × 3/2 | 128 × 128 × 64 | 1 |
| Inception Module | 3 × 3/1 | 128 × 128 × 128 | 3 |
| Inception Module | 3 × 3/1 | 128 × 128 × 128 | 3 |
| Inception Module | 3 × 3/1 | 128 × 128 × 128 | 3 |
| Max Pooling | 3 × 3/2 | 64 × 64 × 128 | 1 |
| Inception Module | 3 × 3/1 | 64 × 64 × 256 | 3 |
| Inception Module | 3 × 3/1 | 64 × 64 × 256 | 3 |
| Inception Module | 3 × 3/1 | 64 × 64 × 256 | 3 |
| Max Pooling | 3 × 3/2 | 32 × 32 × 256 | 1 |
| Inception Module | 3 × 3/1 | 32 × 32 × 512 | 3 |
| Inception Module | 3 × 3/1 | 32 × 32 × 512 | 3 |
| Inception Module | 3 × 3/1 | 32 × 32 × 512 | 3 |
| Max Pooling | 3 × 3/2 | 16 × 16 × 512 | 1 |
| The ASPP module | – | 16 × 16 × 1024 | 2 |
| Inception Module | 3 × 3/1 | 16 × 16 × 1024 | 3 |
| Deconvolution | 3 × 3/2 | 32 × 32 × 512 | 3 |
| Cat | – | 32 × 32 × 512 | 1 |
| Inception Module | 3 × 3/1 | 32 × 32 × 512 | 3 |
| Inception Module | 3 × 3/1 | 32 × 32 × 512 | 3 |
| Deconvolution | 3 × 3/2 | 64 × 64 × 256 | 1 |
| Cat | – | 64 × 64 × 512 | 1 |
| Inception Module | 3 × 3/1 | 64 × 64 × 256 | 3 |
| Inception Module | 3 × 3/1 | 64 × 64 × 256 | 3 |
| Deconvolution | 3 × 3/2 | 128 × 128 × 128 | 1 |
| Cat | – | 128 × 128 × 256 | 1 |
| Inception Module | 3 × 3/1 | 128 × 128 × 128 | 3 |
| Inception Module | 3 × 3/1 | 128 × 128 × 128 | 3 |
| Deconvolution | 3 × 3/2 | 256 × 256 × 64 | 1 |
| Cat | – | 256 × 256 × 128 | 1 |
| Inception Module | 3 × 3/1 | 256 × 256 × 64 | 3 |
| Inception Module | 3 × 3/1 | 256 × 256 × 64 | 3 |
| Sigmoid | 1 × 1/1 | 256 × 256 × 1 | 1 |
| Method | Inception | ASPP | Layer Extend |
|---|---|---|---|
| PM | ✓ | ✓ | - |
| CM4 | - | ✓ | - |
| CM5 | - | - | ✓ |
| CM6 | ✓ | - | - |
| CM7 (Baseline) | - | - | - |
| Method | Recall | Precision | F-Measure | IoU |
|---|---|---|---|---|
| PM | 0.660 | 0.436 | 0.525 | 0.356 |
| CM1 [55] | 0.564 | 0.375 | 0.451 | 0.291 |
| CM2 [56] | 0.494 | 0.315 | 0.385 | 0.238 |
| CM3 [57] | 0.410 | 0.136 | 0.204 | 0.158 |
| CM4 | 0.493 | 0.405 | 0.444 | 0.286 |
| CM5 | 0.532 | 0.463 | 0.495 | 0.329 |
| CM6 | 0.617 | 0.346 | 0.443 | 0.285 |
| CM7 | 0.588 | 0.336 | 0.428 | 0.272 |
| Defect | Recall | |||||||
|---|---|---|---|---|---|---|---|---|
| PM | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | |
| Peeling | 0.921 | 0.866 | 0.729 | 0.191 | 0.795 | 0.905 | 0.711 | 0.655 |
| Floating | 0.802 | 0.711 | 0.568 | 0.199 | 0.708 | 0.782 | 0.651 | 0.533 |
| Crack (0.3 mm–0.5 mm) | 0.173 | 0.230 | 0.163 | 0.209 | 0.159 | 0.140 | 0.125 | 0.110 |
| Crack (0.5 mm–1 mm) | 0.358 | 0.385 | 0.430 | 0.334 | 0.407 | 0.382 | 0.361 | 0.326 |
| Crack (1 mm–2 mm) | 0.402 | 0.463 | 0.384 | 0.422 | 0.455 | 0.434 | 0.409 | 0.388 |
| Crack(2mm+) | 0.414 | 0.409 | 0.394 | 0.431 | 0.467 | 0.444 | 0.426 | 0.389 |
| Cold joint | 0.013 | 0.017 | 0.016 | 0.014 | 0.016 | 0.016 | 0.007 | 0.005 |
| Honeycomb | 0.084 | 0.251 | 0.230 | 0.010 | 0.030 | 0.210 | 0.090 | 0.080 |
| Patching (intermediate pile) | 0.819 | 0.734 | 0.616 | 0.159 | 0.721 | 0.816 | 0.656 | 0.591 |
| Alligator crack | 0.362 | 0.308 | 0.216 | 0.063 | 0.317 | 0.368 | 0.306 | 0.244 |
| Early construction repair | 0.423 | 0.375 | 0.271 | 0.061 | 0.394 | 0.504 | 0.306 | 0.297 |
| Deposition | 0.054 | 0.049 | 0.015 | 0.001 | 0.080 | 0.012 | 0.005 | 0.010 |
| Construction repair | 0.591 | 0.307 | 0.167 | 0.078 | 0.413 | 0.556 | 0.364 | 0.375 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, A.; Togo, R.; Ogawa, T.; Haseyama, M. Defect Detection of Subway Tunnels Using Advanced U-Net Network. Sensors 2022, 22, 2330. https://doi.org/10.3390/s22062330
Wang A, Togo R, Ogawa T, Haseyama M. Defect Detection of Subway Tunnels Using Advanced U-Net Network. Sensors. 2022; 22(6):2330. https://doi.org/10.3390/s22062330
Chicago/Turabian StyleWang, An, Ren Togo, Takahiro Ogawa, and Miki Haseyama. 2022. "Defect Detection of Subway Tunnels Using Advanced U-Net Network" Sensors 22, no. 6: 2330. https://doi.org/10.3390/s22062330
APA StyleWang, A., Togo, R., Ogawa, T., & Haseyama, M. (2022). Defect Detection of Subway Tunnels Using Advanced U-Net Network. Sensors, 22(6), 2330. https://doi.org/10.3390/s22062330