
Osmotic Cloud-Edge Intelligence for IoT-Based Cyber-Physical Systems

 ,
,  , , , ,
, , , ,  , and
, and
Abstract
:1. Introduction
- Containerized AI service architecture enabling training and inference to be performed on the Edge, Cloud, or a combination of the two, exploiting available computational resources opportunistically with different trade-offs between computational/storage requirements and prediction accuracy.
- Microservice encapsulation of each architecture module with an exact characterization of roles, responsibilities, and interactions, allowing a direct mapping with Commercial-Off-The-Shelf (COTS) components, in order to increase feasibility as well as to reduce development costs and time to market.
- A fully functional platform prototype implemented on commodity hardware by integrating off-the-shelf open-source software technologies and tools.
- A case study on Cloud-Edge AI in an intelligent manufacturing scenario, with an experimental campaign to validate key value propositions of the approach.
2. Related Work
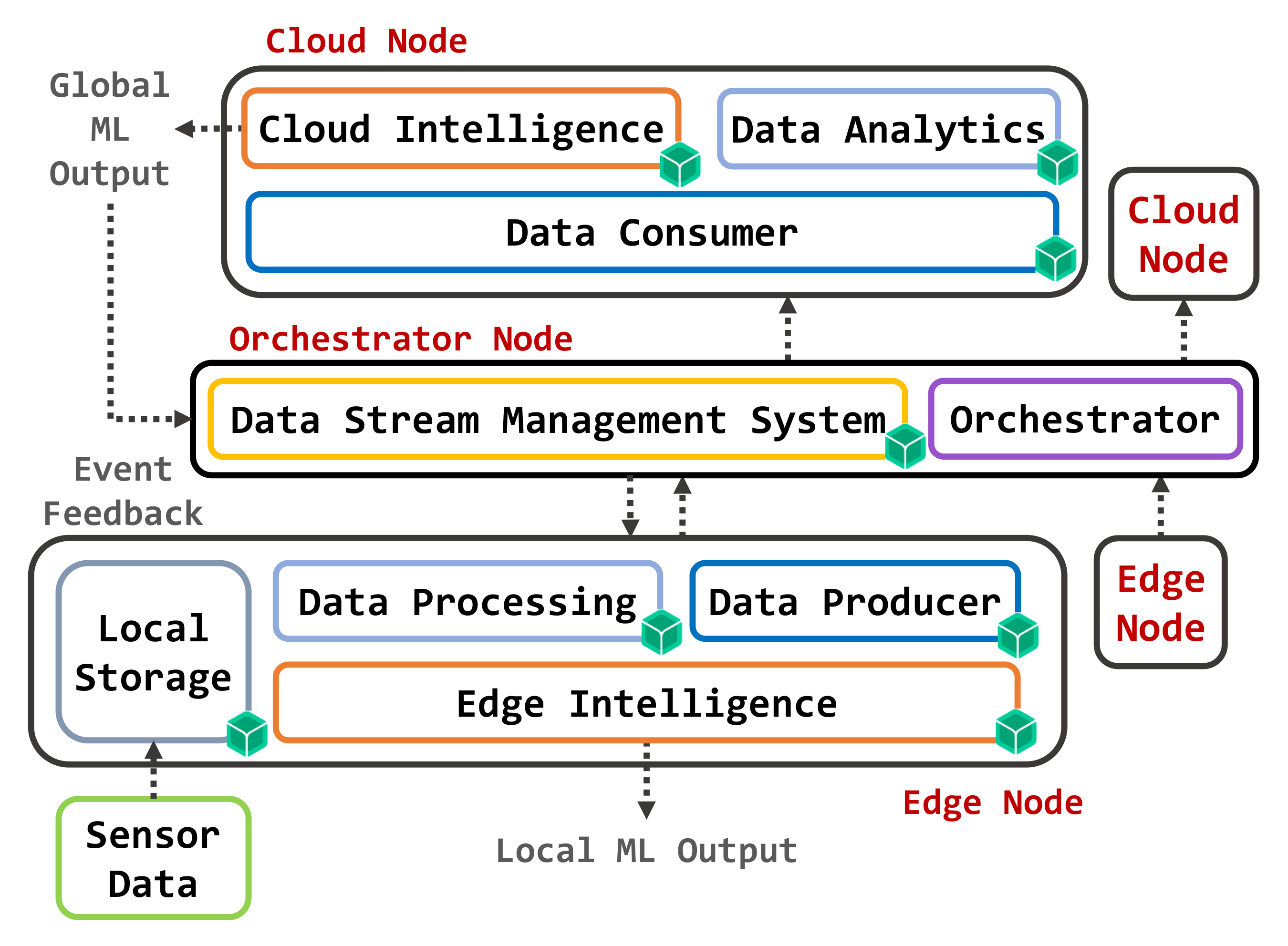
3. Osmotic Cloud-Edge Architecture
- Rate of change of the observed phenomenon;
- Environment and context constraints;
- Ability of the device itself to collect or record data;
- Operational system requirements to be met.
- Decrypting incoming data streams and encrypting outgoing ones, for security;
- Transcoding data streams between different formats;
- Combining multiple data streams from groups of devices;
- Preprocessing and filtering streams to eliminate spurious data, noise, and artifacts;
- Summarizing raw data to reduce volumes with minimal information loss.
- Advanced preprocessing of input data streams, including e.g., function transforms to frequency domain representations;
- Feature extraction and selection for data dimensionality reduction;
- Model training from features;
- Prediction using the trained model.
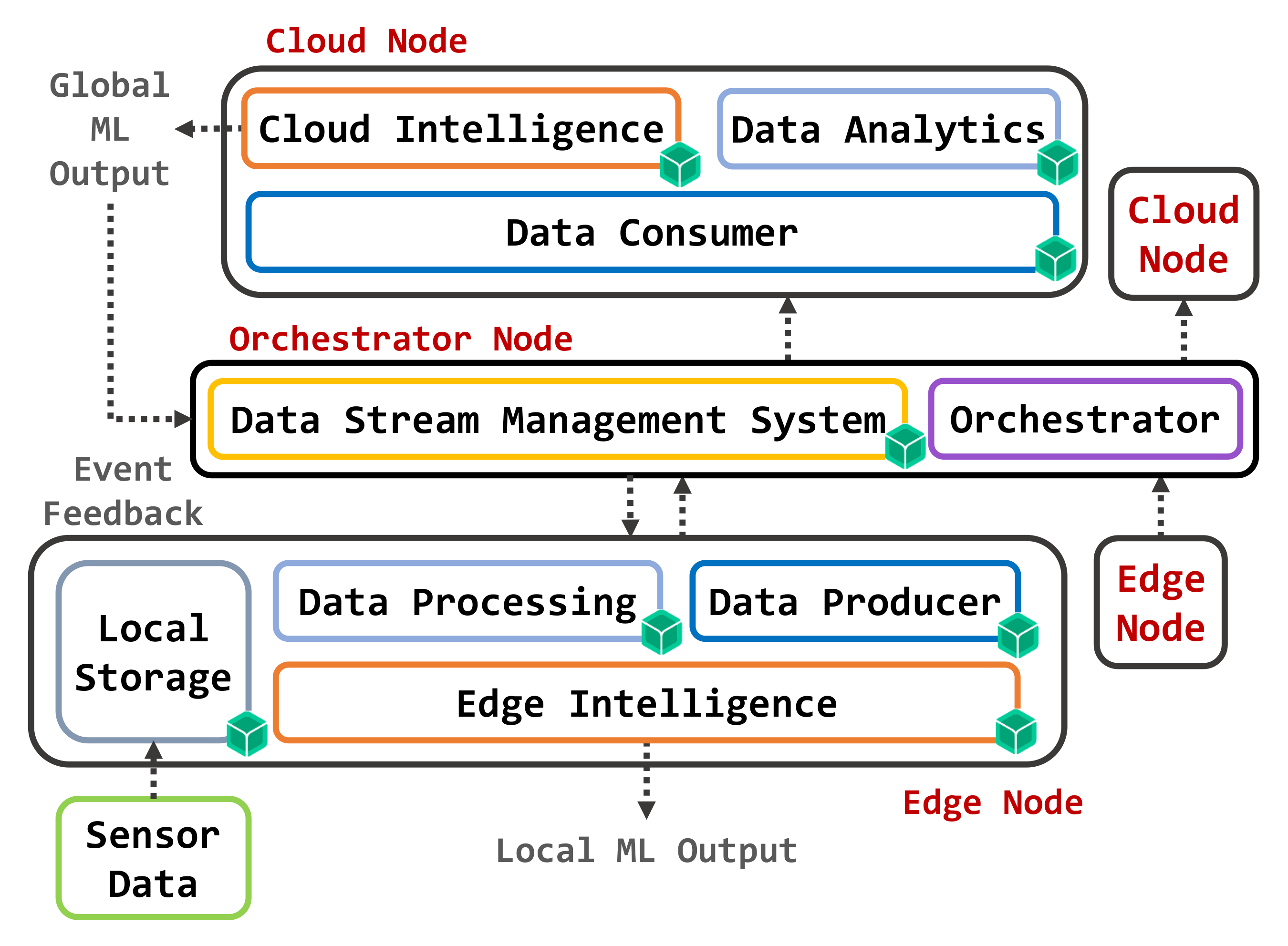
- One or more Edge nodes programmed to acquire raw data and to process them locally using machine learning algorithms for classification or regression tasks.
- One or more Cloud nodes able to receive aggregate data from the Edge nodes and perform classification/regression tasks by operating on a larger and more articulated data set, while also being able to act as backup hosts for Edge microservices in the case of unavailability of Edge nodes.
- A Data Stream Management System (DSMS) capable of conveying data coming between the Edge of the network towards the Cloud components, while also providing support for data storage operations.
- An Orchestrator, following the OC paradigm to manage different containers implementing the required functional blocks as microservices.
3.1. Microservices
3.2. Technologies
- Open source software license with an active developer community;
- Proven track record of reliability, security, and performance;
- Full compatibility with container technologies;
- Interoperability with widespread IoT technologies and protocols;
- Support for multiple hardware architectures;
- Support for innovative functional and architectural methodologies of software engineering.
4. Case Study: Intelligent Manufacturing
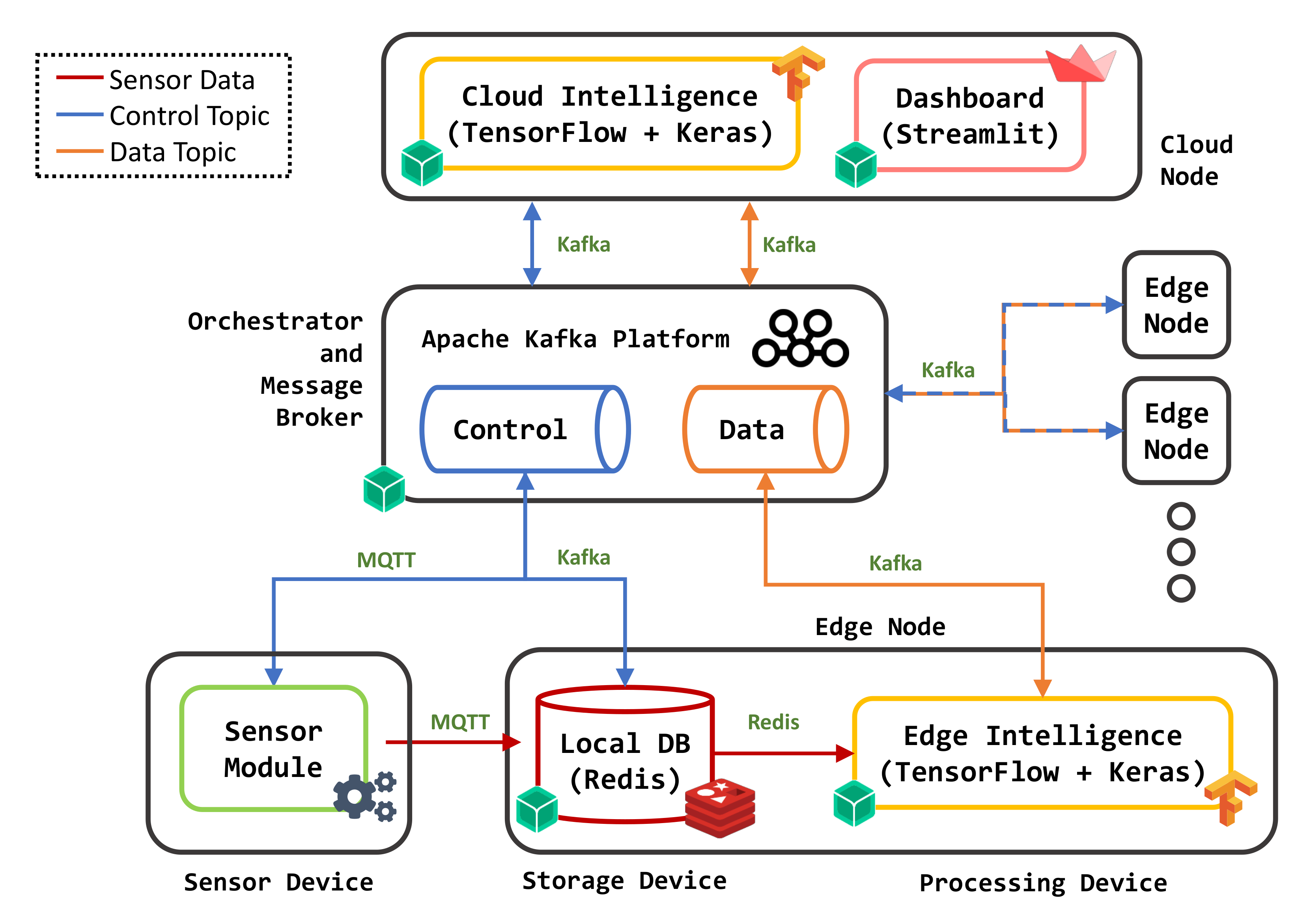
4.1. Prototype
- id: Unique message identifier;
- type: Indicates the kind of control message. Acceptable values are:
- –
- storage_connected (SC): A new Storage module is available on the network;
- –
- storage_disconnected (SD): A Storage module is currently unreachable or down;
- –
- sensor_data (SDT): A Sensor measurement is available on a storage module for running a prediction algorithm;
- –
- dataset (DS): A Sensor dataset, including several sensor measurements, is available on a Storage module for training or updating the ML models;
- –
- query (QR): Used to list available Storage modules and related data;
- –
- response (RS): Indicates a response to a query message.
- host: Contains the reference module IP address;
- data_key: Unique identifier used to retrieve data from a specific Redis datastore;
- query_type: Used to retrieve information about a single measurement (sensor_data), a subset of data (dataset) or the whole collection (storage);
- query_id: Message id of the query originating current response;
- storage_id: Unique identifier of the Storage module containing the data.
- type: Indicates the kind of data notification:
- –
- input: Contains data samples for which an inference task is requested;
- –
- output: Contains results of a prediction task;
- –
- model: Returns information about the performance of the trained ML models.
- id: Identifies the processed sensor data (in case of input and output messages) or the Cloud/Edge Intelligence module providing the prediction model;
- data: An array of raw information;
- module_id: Identifies the Intelligence node running the predictive algorithm;
- result: Output of the prediction task;
- time: Prediction time in milliseconds;
- r2: Coefficient of determination (), used as a performance metric for a regression model;
- mse: Mean squared error, i.e., the average squared difference between predicted and real values;
- download_time, training_time, and evaluation_time: Time spent by the Intelligence node to retrieve the whole dataset, train the model, and evaluate performance, respectively.
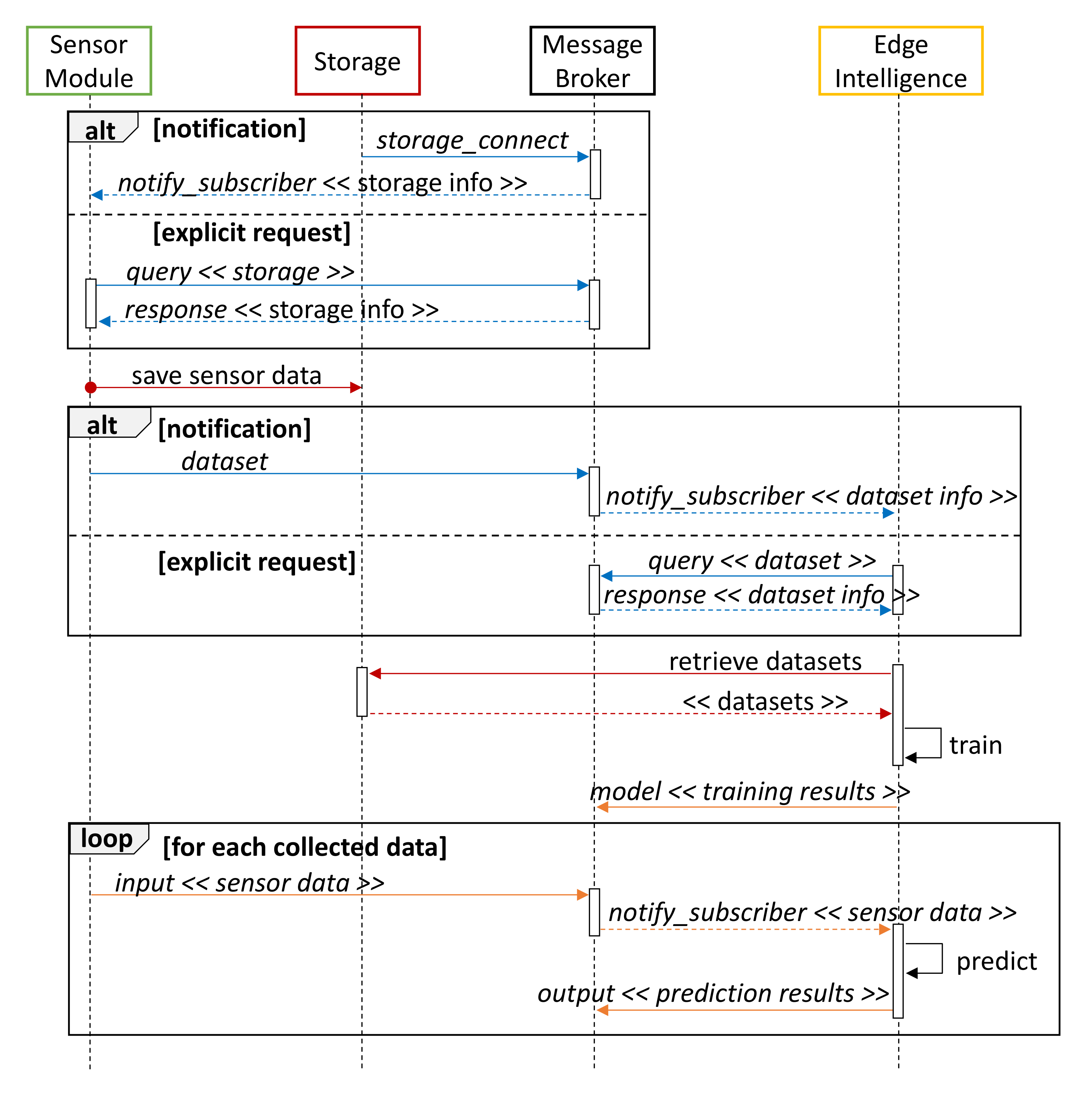
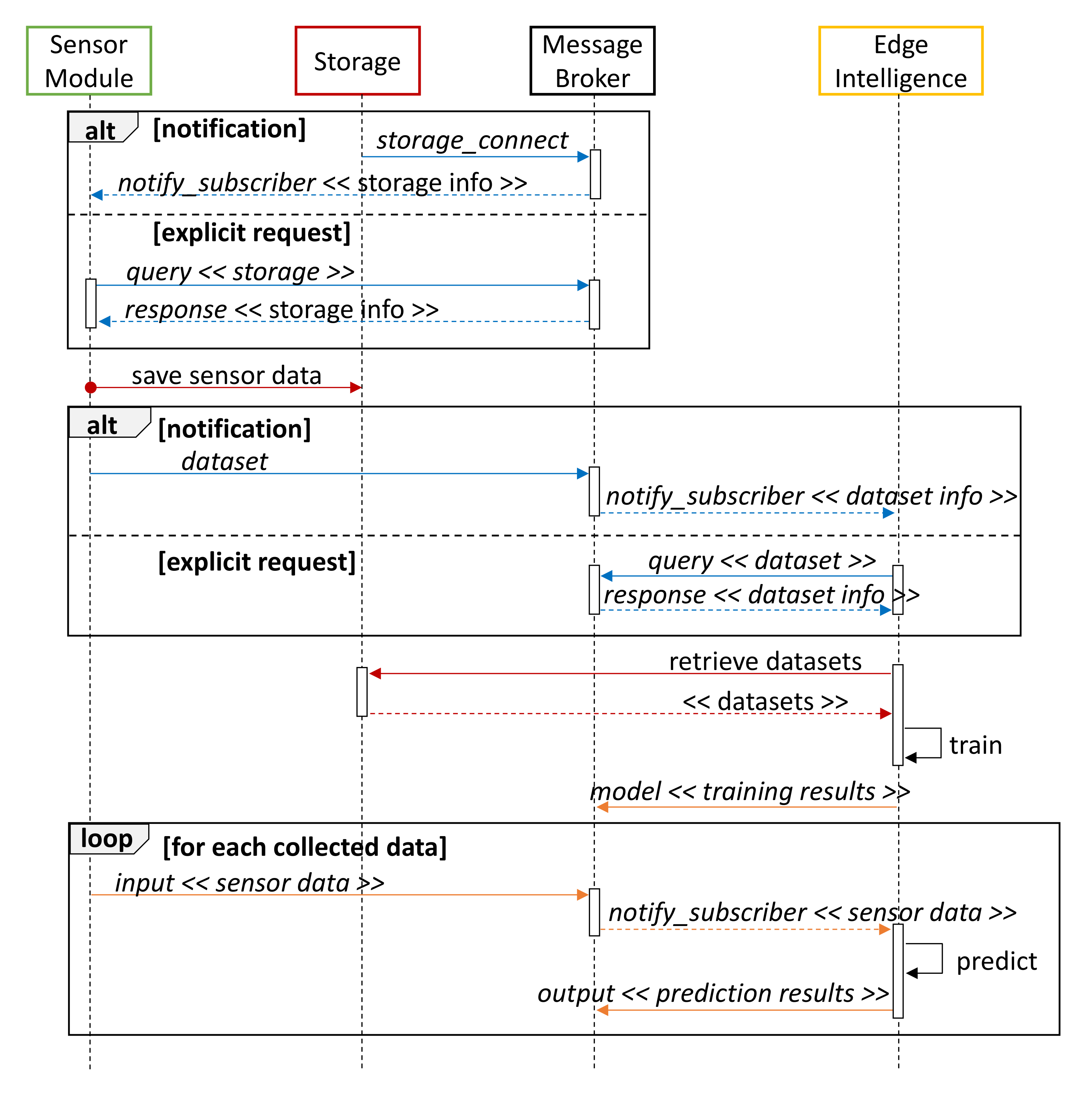
- 1.
- When a Storage module is available on the network, it sends a storage_connect control message to notify all Sensor modules subscribed to the control topic (blue messages in Figure 4). As an alternative, each Sensor module can explicitly perform a query to retrieve all the available Storage devices.
- 2.
- The Sensor module collects data during its observation period and sends it to Storage devices through a dedicated MQTT topic. The Apache Arrow data format is used for message serialization (red color in Figure 4).
- 3.
- A dataset notification is sent to advertise the availability of new data. Datasets can be used to train or update prediction algorithms on active Cloud/Edge modules, but also to plot information on a remote dashboard. Intelligence modules can autonomously query the MB to obtain information about available datasets.
- 4.
- Data are retrieved from one or more Storage devices and used to train a regression model. Performance results are then exposed through a model message on the data topic (drawn in orange in Figure 4).
- 5.
- Subsequently collected sensor data represent the input of the prediction model and are forwarded through the MB to the subscribed Intelligence nodes. Results of the regression process are finally returned through an output notification.
4.2. Experiments
- Inference time: The time elapsed in predicting the regression value for a sample locally, as measured by the Intelligence module.
- Communication latency: The time required for sending and receiving messages between the different components of the architecture in the prediction phase. As Table 9 shows, it is made of four components: (i) from Sensor to Message Broker (S to MB), (ii) from Message Broker to Intelligence (MB to I), (iii) from Intelligence to Message Broker (I to MB), (iv) and from Message Broker to Sensor (MB to S). (In the prototype the last two components simply concern the prediction values, but in general scenarios they could concern set points for appropriate actuators in a control feedback loop, computed on the basis of the ML predictions);
- Turnaround time: The overall time between input sample upload and prediction, evaluated on the Sensor node uploading the samples.
- 1.
- A Sensor module looks for an available Storage service, but the Orchestrator is unable to meet the request due to the unavailability of Storage microservices instances and to the lack of a suitable device to host them. The Orchestrator therefore pushes the Storage container to the Cloud, which—once ready—announces itself through a storage_connect message. The Orchestrator is now able to notify the Sensor module, which can then upload its data. At some point in time, a new Edge device with the required capabilities to act as a Storage host connects to the network. For load balancing purpose, the Orchestrator hangs the Storage microservice to the new device, which can take over the role of Sensor data collector.
- 2.
- In case of a shortage of Edge Intelligence nodes (e.g., due to device failure), the Orchestrator pushes the Intelligence microservice to the Cloud, as it can resume its customary learning and inference tasks, albeit with higher network latency. Eventually, a new device connects to the Edge, and the Orchestrator assesses it as being able to host an instance of the Edge Intelligence service. The microservice is therefore linked to the new device, thus offloading the Cloud and restoring normal operation.
5. Conclusions and Future Work
- Exploiting knowledge representation and reasoning in the orchestrator to dynamically discover the best deployment configuration via context-aware semantic matchmaking [28] between ontology-based annotations of microservices and devices.
- Investigation of more advanced IoT-oriented AI algorithms, by enhancing machine learning with semantic technologies [29] and computational argumentation.
- Further development of the analytics and visualization component, not described in detail in this paper as it is currently at an early stage, even though relevant for the usability of the overall solution.
- Integration of the platform prototype with real sensors and actuators in a manufacturing setting, followed by new experiments,
- Additional case studies in challenging IoT-based CPS scenarios, such as (tele)-healthcare, environmental monitoring and urban safety control.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Serpanos, D. The Cyber-Physical Systems Revolution. Computer 2018, 51, 70–73. [Google Scholar] [CrossRef]
- Brown, N.; Sandholm, T. Superhuman AI for multiplayer poker. Science 2019, 365, 885–890. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Internet Things J. 2017, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge Intelligence: The Confluence of Edge Computing and Artificial Intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef] [Green Version]
- Villari, M.; Fazio, M.; Dustdar, S.; Rana, O.; Ranjan, R. Osmotic Computing: A New Paradigm for Edge/Cloud Integration. IEEE Cloud Comput. 2016, 3, 76–83. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; You, X.; Jiang, Y.; Yang, J.; Hu, L. Opportunistic computing offloading in edge clouds. J. Parallel Distrib. Comput. 2019, 123, 69–76. [Google Scholar] [CrossRef]
- Tovazzi, D.; Faticanti, F.; Siracusa, D.; Peroni, C.; Cretti, S.; Gazzini, T. GEM-Analytics: Cloud-to-Edge AI-Powered Energy Management. In International Conference on the Economics of Grids, Clouds, Systems, and Services; Springer: Berlin/Heidelberg, Germany, 2020; pp. 57–66. [Google Scholar]
- Morshed, A.; Jayaraman, P.P.; Sellis, T.; Georgakopoulos, D.; Villari, M.; Ranjan, R. Deep Osmosis: Holistic Distributed Deep Learning in Osmotic Computing. IEEE Cloud Comput. 2017, 4, 22–32. [Google Scholar] [CrossRef]
- Sharma, V.; You, I.; Kumar, R.; Kim, P. Computational Offloading for Efficient Trust Management in Pervasive Online Social Networks Using Osmotic Computing. IEEE Access 2017, 5, 5084–5103. [Google Scholar] [CrossRef]
- Pacheco, A.; Cano, P.; Flores, E.; Trujillo, E.; Marquez, P. A Smart Classroom based on Deep Learning and Osmotic IoT Computing. In Proceedings of the 2018 Congreso Internacional de Innovación y Tendencias en Ingeniería (CONIITI), Bogota, Colombia, 3–5 October 2018; pp. 1–5. [Google Scholar]
- Longo, A.; De Matteis, A.; Zappatore, M. Urban pollution monitoring based on Mobile Crowd Sensing: An osmotic computing approach. In Proceedings of the 2018 IEEE 4th International Conference on Collaboration and Internet Computing, Philadelphia, PA, USA, 18–20 October 2018; pp. 380–387. [Google Scholar]
- Grzelak, D.; Mey, J.; Aßmann, U. Design and Concept of an Osmotic Analytics Platform based on R Container. In Proceedings of the International Conference on Foundations of Computer Science, Las Vegas, NV, USA, 30 July–2 August 2018; pp. 29–35. [Google Scholar]
- Villari, M.; Fazio, M.; Dustdar, S.; Rana, O.; Jha, D.N.; Ranjan, R. Osmosis: The Osmotic Computing Platform for Microelements in the Cloud, Edge, and Internet of Things. Computer 2019, 52, 14–26. [Google Scholar] [CrossRef]
- Carnevale, L.; Celesti, A.; Galletta, A.; Dustdar, S.; Villari, M. Osmotic computing as a distributed multi-agent system: The Body Area Network scenario. Internet Things 2019, 5, 130–139. [Google Scholar] [CrossRef]
- Rausch, T.; Dustdar, S.; Ranjan, R. Osmotic Message-Oriented Middleware for the Internet of Things. IEEE Cloud Comput. 2018, 5, 17–25. [Google Scholar] [CrossRef]
- Kaur, K.; Garg, S.; Kaddoum, G.; Ahmed, S.H.; Jayakody, D.N.K. En-OsCo: Energy-aware Osmotic Computing Framework using Hyper-heuristics. In Proceedings of the ACM MobiHoc Workshop on Pervasive Systems in the IoT Era, Catania, Italy, 2 July 2019; pp. 19–24. [Google Scholar]
- Sharma, V.; Jayakody, D.N.K.; Qaraqe, M. Osmotic computing-based service migration and resource scheduling in Mobile Augmented Reality Networks (MARN). Future Gener. Comput. Syst. 2020, 102, 723–737. [Google Scholar] [CrossRef]
- Banks, A.; Briggs, E.; Borgendale, K.; Gupta, R. MQTT Version 5.0; Technical Report; OASIS: Burlington, MA, USA, 2019. [Google Scholar]
- Shelby, Z.; Hartke, K.; Bormann, C. The Constrained Application Protocol (CoAP); Technical Report; RFC 7252; IETF: Wilmington, DE, USA, 2014. [Google Scholar]
- Oztemel, E.; Gursev, S. Literature review of Industry 4.0 and related technologies. J. Intell. Manuf. 2020, 31, 127–182. [Google Scholar] [CrossRef]
- Magalhães Oliveira, E. Quality Prediction in a Mining Process. Available online: https://www.kaggle.com/edumagalhaes/quality-prediction-in-a-mining-process (accessed on 2 November 2021).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. Conference Track Proceedings. [Google Scholar]
- Deutsch, P.; Gailly, J.L. RFC1950: ZLIB Compressed Data Format Specification Version 3.3; Technical Report; Internet Engineering Task Force: Fremont, CA, USA, 1996. [Google Scholar]
- Bond, J. The Enterprise Cloud: Best Practices for Transforming Legacy IT; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Althnian, A.; AlSaeed, D.; Al-Baity, H.; Samha, A.; Dris, A.B.; Alzakari, N.; Abou Elwafa, A.; Kurdi, H. Impact of Dataset Size on Classification Performance: An Empirical Evaluation in the Medical Domain. Appl. Sci. 2021, 11, 796. [Google Scholar] [CrossRef]
- Scioscia, F.; Ruta, M.; Loseto, G.; Gramegna, F.; Ieva, S.; Pinto, A.; Di Sciascio, E. Mini-ME matchmaker and reasoner for the Semantic Web of Things. In Innovations, Developments, and Applications of Semantic Web and Information Systems; IGI Global: Hershey, PA, USA, 2018; pp. 262–294. [Google Scholar]
- Ruta, M.; Scioscia, F.; Loseto, G.; Pinto, A.; Di Sciascio, E. Machine learning in the Internet of Things: A semantic-enhanced approach. Semant. Web 2019, 10, 183–204. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Containerized Services | Osmotic Orchestration | AI | Model Training |
|---|---|---|---|---|
| Pacheco et al. [12]—2018 | ✗ | ✗ | ✓ | Pre-Trained |
| Apollon [13]—2018 | ✓ | ✓ | ✓ | On Cloud |
| Grzelak et al. [14]—2018 | ✓ | ✓ | ✓ | ✗ |
| Carnevale et al. [16]—2019 | ✓ | ✓ | ✗ | ✗ |
| En-OsCo [18]—2019 | ✓ | ✓ | ✗ | ✗ |
| Osmosis [15]—2019 | ✓ | ✓ | ✗ | ✗ |
| Sharma et al. [19]—2020 | ✗ | ✓ | ✗ | ✗ |
| Tovazzi et al. [9]—2020 | ✓ | ✗ | ✓ | On Cloud |
| This work | ✓ | ✓ | ✓ | On Cloud and Edge |
| Service/Module | Technology | Version | License | Release Date |
|---|---|---|---|---|
| Container technology | balenaOS | 2.54.2 | Apache 2.0 | 12 August 2020 |
| Orchestrator | openBalena | 3.1.1 | GNU Affero GPL 3.0 | 10 November 2020 |
| Data Stream Management System | Apache Kafka | 2.5.0 (with Scala 2.12) | Apache 2.0 | 15 April 2020 |
| Data Producer | Kafka Producer API | 2.0.1-python | Apache 2.0 | 19 February 2020 |
| Data Consumer | Kafka Consumer API | 2.0.1-python | Apache 2.0 | 19 February 2020 |
| Local Storage | Redis | 6.0.9 | 3-Clause BSD | 26 October 2020 |
| Data Processing | Python scripts | 3.9.0 | PSF & Zero-Clause BSD | 5 October 2020 |
| Edge/Cloud Intelligence | TensorFlow Keras API | 2.3.1 2.4.3 | Apache 2.0 MIT | 12 Sepember 2020 25 June 2020 |
| Data Analytics & Visualization | Streamlit | 0.72.0 | Apache 2.0 | 2 December 2020 |
| Type | Id | Host | Data Key | Query Type | Query ID | Storage ID |
|---|---|---|---|---|---|---|
| SC | ✓ | ✓ | ||||
| SD | ✓ | |||||
| SDT | ✓ | ✓ | ✓ | |||
| DS | ✓ | ✓ | ✓ | |||
| QR | ✓ | ✓ | ||||
| RS | ✓ | ✓ | ✓ |
| Type | Id | Data | Module ID | Result | Time |
|---|---|---|---|---|---|
| input | ✓ | ✓ | |||
| output | ✓ | ✓ | ✓ | ✓ | |
| model | ✓ | ||||
| R | MSE | Download Time | Training Time | Evaluation Time | |
| input | |||||
| output | |||||
| model | ✓ | ✓ | ✓ | ✓ | ✓ |
| Node | Device | Label | Download (kB) | Upload (kB) |
|---|---|---|---|---|
| Broker | broker | MB | 4768 | 7603 |
| intelligence | 33,386 | 993 | ||
| Edge 1 | storage | 35,951 | 36,043 | |
| sensor | 2379 | 35,259 | ||
| intelligence | 33,685 | 1142 | ||
| Edge 2 | storage | 35,522 | 35,858 | |
| sensor | 2193 | 35,088 |
| Node | R | MSE | Download Time (s) | Training Time (s) | Validation Time (s) |
|---|---|---|---|---|---|
| Cloud | 0.983 | 0.0222 | 50.788 | 437.986 | 3.081 |
| Edge 1 | 0.972 | 0.0348 | 24.603 | 2086.653 | 25.415 |
| Edge 2 | 0.971 | 0.0337 | 33.085 | 2574.005 | 28.976 |
| Samples | Download Time (s) | Training Time (s) | Validation Time (s) | ||
|---|---|---|---|---|---|
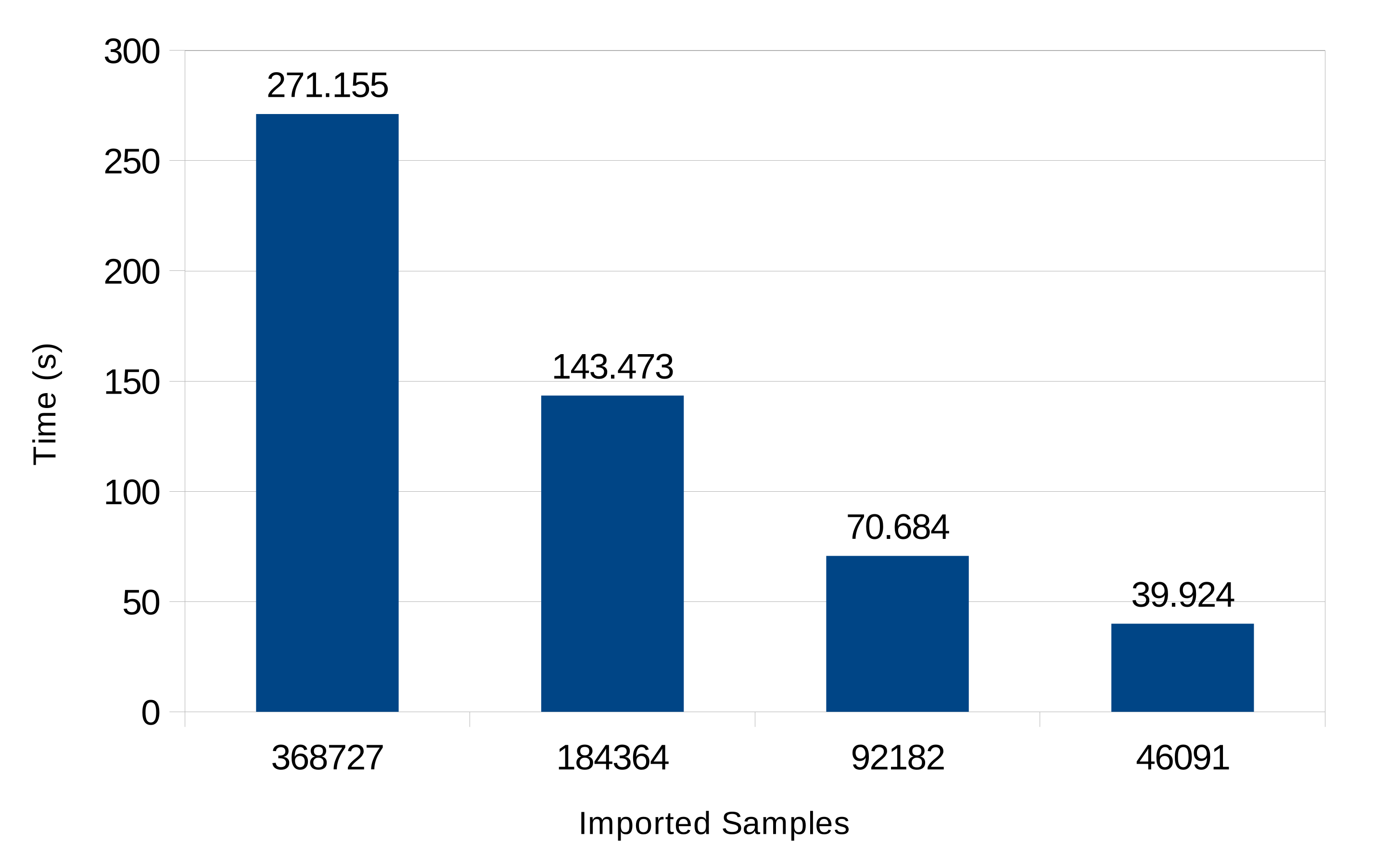
| 737,454 | 0.983 | 0.021 | 42.451 | 5155.740 | 32.072 |
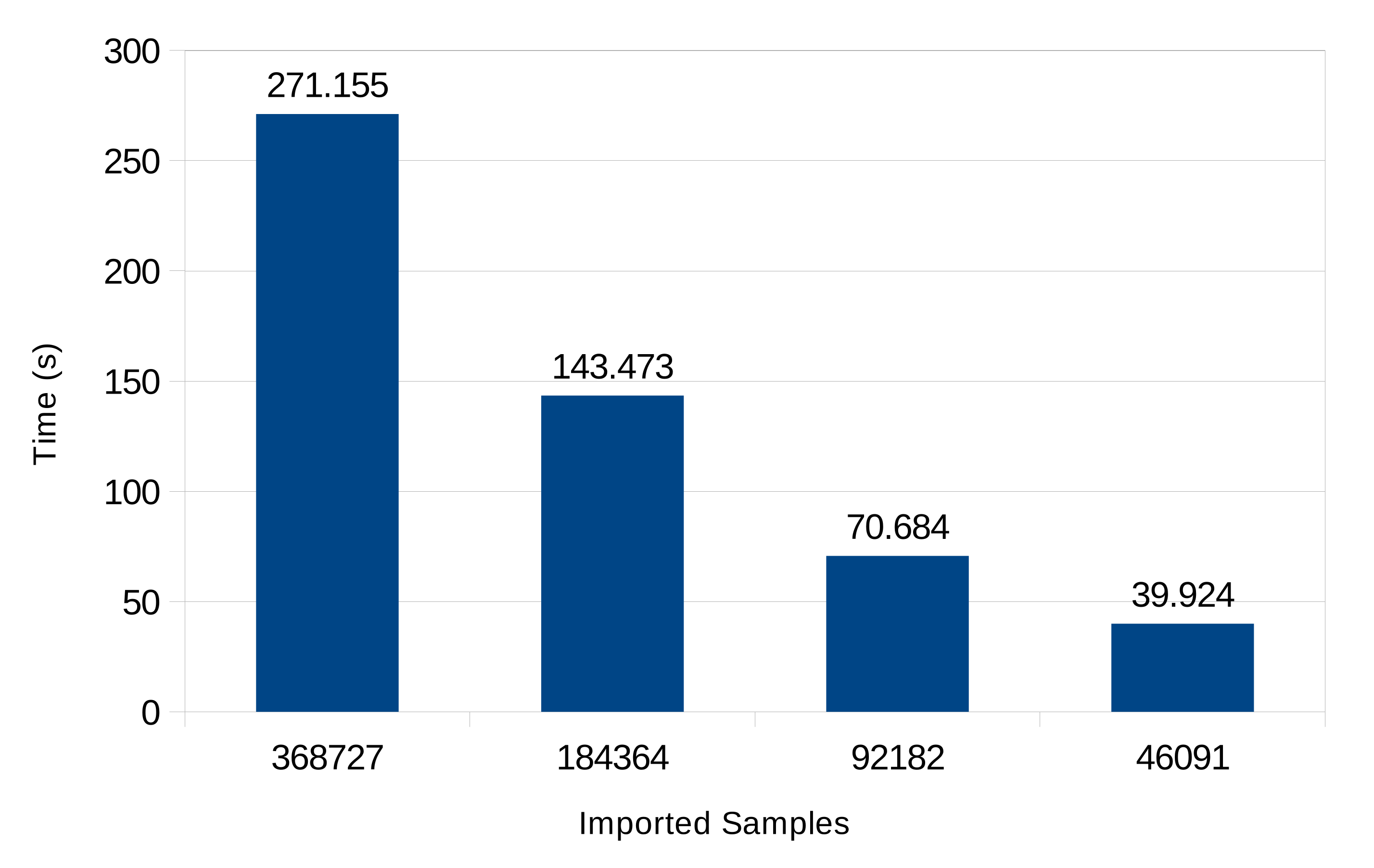
| 368,727 | 0.972 | 0.035 | 24.603 | 2086.653 | 24.608 |
| 184,363 | 0.959 | 0.055 | 10.688 | 1066.539 | 10.688 |
| 92,182 | 0.931 | 0.088 | 5.087 | 564.569 | 5.087 |
| 46,090 | 0.894 | 0.135 | 2.815 | 263.953 | 2.815 |
| Node | Device | Label | Download (kB) | Upload (kB) |
|---|---|---|---|---|
| broker | broker | MB | 42 | 78 |
| Edge 1 | intelligence | 26 | 26 | |
| sensor | 36 | 34 | ||
| Edge 2 | intelligence | 26 | 26 |
| Node | Inference Time | Communication Latency (ms) | Turnaround Time | |||
|---|---|---|---|---|---|---|
| (ms) | S to MB | MB to I | I to MB | MB to S | (ms) | |
| Cloud | 31.377 | 91.510 | 19.752 | 42.549 | 44.970 | 230.158 |
| Edge 1 | 230.598 | 87.259 | 4.362 | 19.461 | 37.773 | 379.453 |
| Edge 2 | 301.887 | 84.812 | 7.590 | 22.844 | 30.555 | 447.688 |
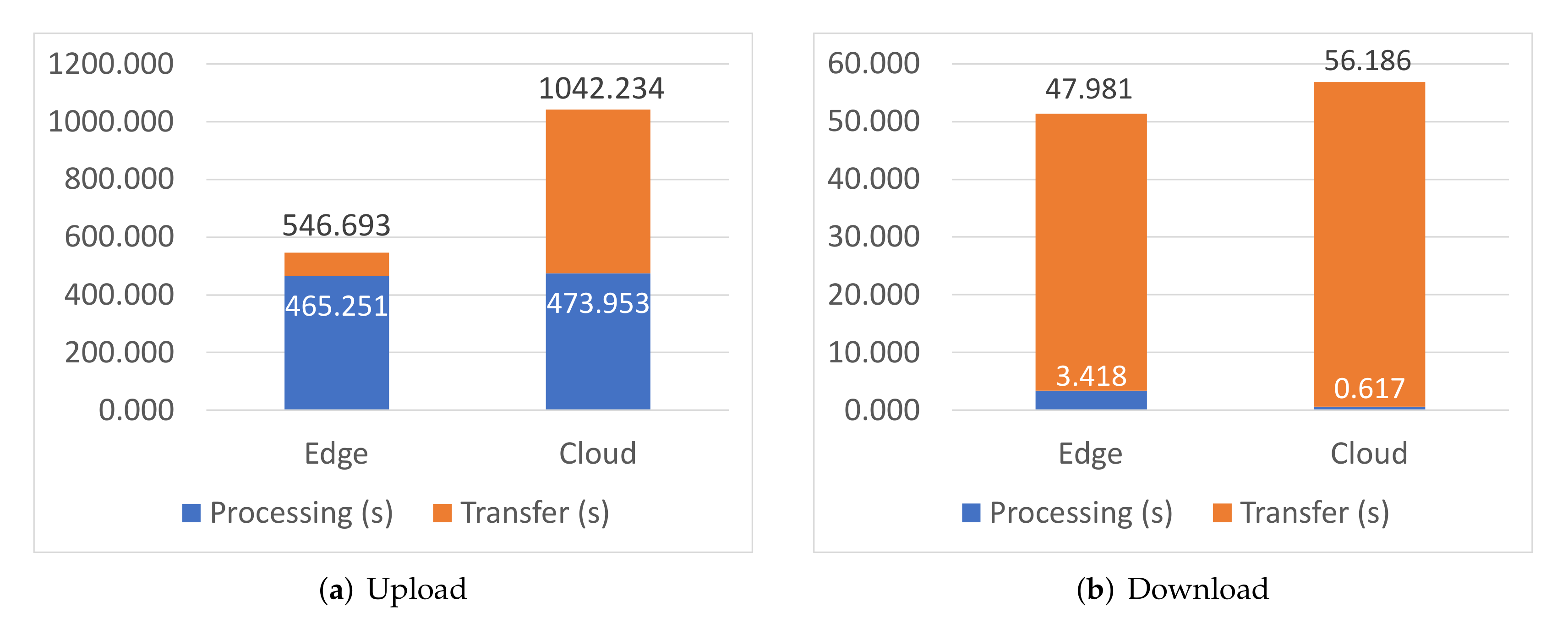
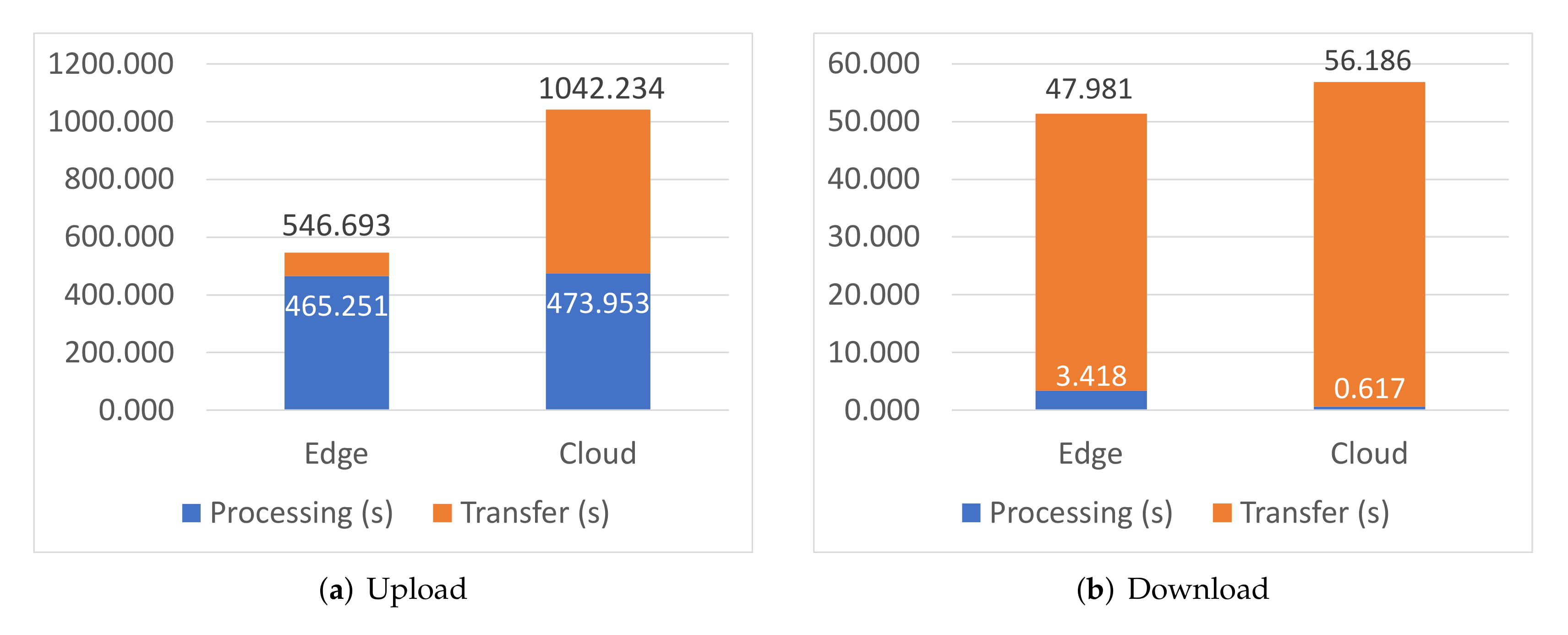
| Node | Service | Load Time (s) | Startup Time (s) | Broker Bandwidth (MB) | Image Size (MB) | |
|---|---|---|---|---|---|---|
| Download | Upload | |||||
| Cloud | Storage | 71.163 | 2.983 | 4.144 | 255.726 | 239.974 |
| Intelligence | 224.451 | 2.768 | 12.648 | 765.300 | 718.205 | |
| Edge | Storage | 314.577 | 23.424 | 1.713 | 149.924 | 137.782 |
| Intelligence | 244.422 | 3.108 | 3.424 | 718.291 | 694.802 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Loseto, G.; Scioscia, F.; Ruta, M.; Gramegna, F.; Ieva, S.; Fasciano, C.; Bilenchi, I.; Loconte, D. Osmotic Cloud-Edge Intelligence for IoT-Based Cyber-Physical Systems. Sensors 2022, 22, 2166. https://doi.org/10.3390/s22062166
Loseto G, Scioscia F, Ruta M, Gramegna F, Ieva S, Fasciano C, Bilenchi I, Loconte D. Osmotic Cloud-Edge Intelligence for IoT-Based Cyber-Physical Systems. Sensors. 2022; 22(6):2166. https://doi.org/10.3390/s22062166
Chicago/Turabian StyleLoseto, Giuseppe, Floriano Scioscia, Michele Ruta, Filippo Gramegna, Saverio Ieva, Corrado Fasciano, Ivano Bilenchi, and Davide Loconte. 2022. "Osmotic Cloud-Edge Intelligence for IoT-Based Cyber-Physical Systems" Sensors 22, no. 6: 2166. https://doi.org/10.3390/s22062166
APA StyleLoseto, G., Scioscia, F., Ruta, M., Gramegna, F., Ieva, S., Fasciano, C., Bilenchi, I., & Loconte, D. (2022). Osmotic Cloud-Edge Intelligence for IoT-Based Cyber-Physical Systems. Sensors, 22(6), 2166. https://doi.org/10.3390/s22062166