1. Introduction
Haptic systems enable user interaction in virtual reality by automatically recreating virtual scenes for dynamic interactions through haptic rendering, thus creating a link between a virtual world and the real world. Haptic systems should allow for a wide range of physical interactions and manipulations throughout the user’s workspace, with a physical input that resembles reality. One promising approach to achieve this is the paradigm of encountered-type haptics (EHDs) [
1]. EHDs are devices that autonomously position physical props for virtual objects in the real world at a target appropriately, thus allowing users to reach out to the virtual objects physically, just like in the real world. However, it is challenging for real-time interaction to organize physical props that accurately replicate the virtual world due to practical constraints, such as speed and workspace limits. In addition, the virtual environments are always much more extensive and richer in variety than the tracked physical space [
2]. Speed limitations delay the device’s arrival to some targets, creating discrepancies between what the user can see and what they feel. The resulting position and orientation mismatch between the virtual object and haptic proxy and latency negatively impacts the user experience [
3,
4]. While these issues may be partly solved by improving device hardware, factors such as cost, safety, and complexity often lead to design decisions that make device workspace and speed constraints unavoidable. Control approaches from the state-of-the-art, such as haptic-retargeting [
2] and user motion prediction, have been employed to address speed and latency issues [
5]. Our study addresses this problem through motion prediction using the human eye-gaze tracking and hand motion. Previous studies have shown that the head movement facilitates subsequent gaze shifts toward the future position of the hand to guide object manipulations [
6,
7]. Thus, tracking eye movements is a natural way to learn about an intended reach target [
8]. With eye-gaze information, hand movements, and the information in virtual environment, we can predict the tasks that the user will perform. Eye-tracking systems have been found to play an increasingly important role in assistive robotics as hand-free interaction interfaces for motor-impaired people [
9], social gaze control for humanoids [
10], robotic guidance [
11], creating artistic drawings [
12], and safe robot interactions in patients with speech and motor impairments [
13]. Eye-tracking combined with action observation tasks in a virtual reality display has been used to monitor motor deficits derived from stroke and, consequently, for the rehabilitation of stroke patients [
9,
14].
This study aims to develop and evaluate motion prediction strategies by analyzing the hand motion and eye gaze of adults when selecting targets. The strategies are used for upper limb training exercises to simulate activities of daily living tasks for people with motor impairments.
The main contributions of this work are:
We introduce and compare three strategies to detect human intention using the eye gaze and the hand motion to improve the human immersion.We use the eye-gaze detection rather than the eye-gaze attention used in [
2,
15,
16];
We introduce a framework to implement the strategies;
We implement a proof of concept that illustrates our proposed approach;
We study the effect of the eye-gaze field of view and the threshold by comparing our approach to state-of-the-art eye-gaze-based robot control.
The remaining part of the paper is structured as follows.
Section 2 discusses work related to haptic displays and prediction strategies.
Section 3 describes the context of the study, the intention prediction strategies, the design and setup of the human–robot interaction model to contextualize the contribution of this research, the evaluation criteria, and the experimental design.
Section 4 presents the results of the analysis of the performance of the strategies, and
Section 5 discusses the results.
4. Results
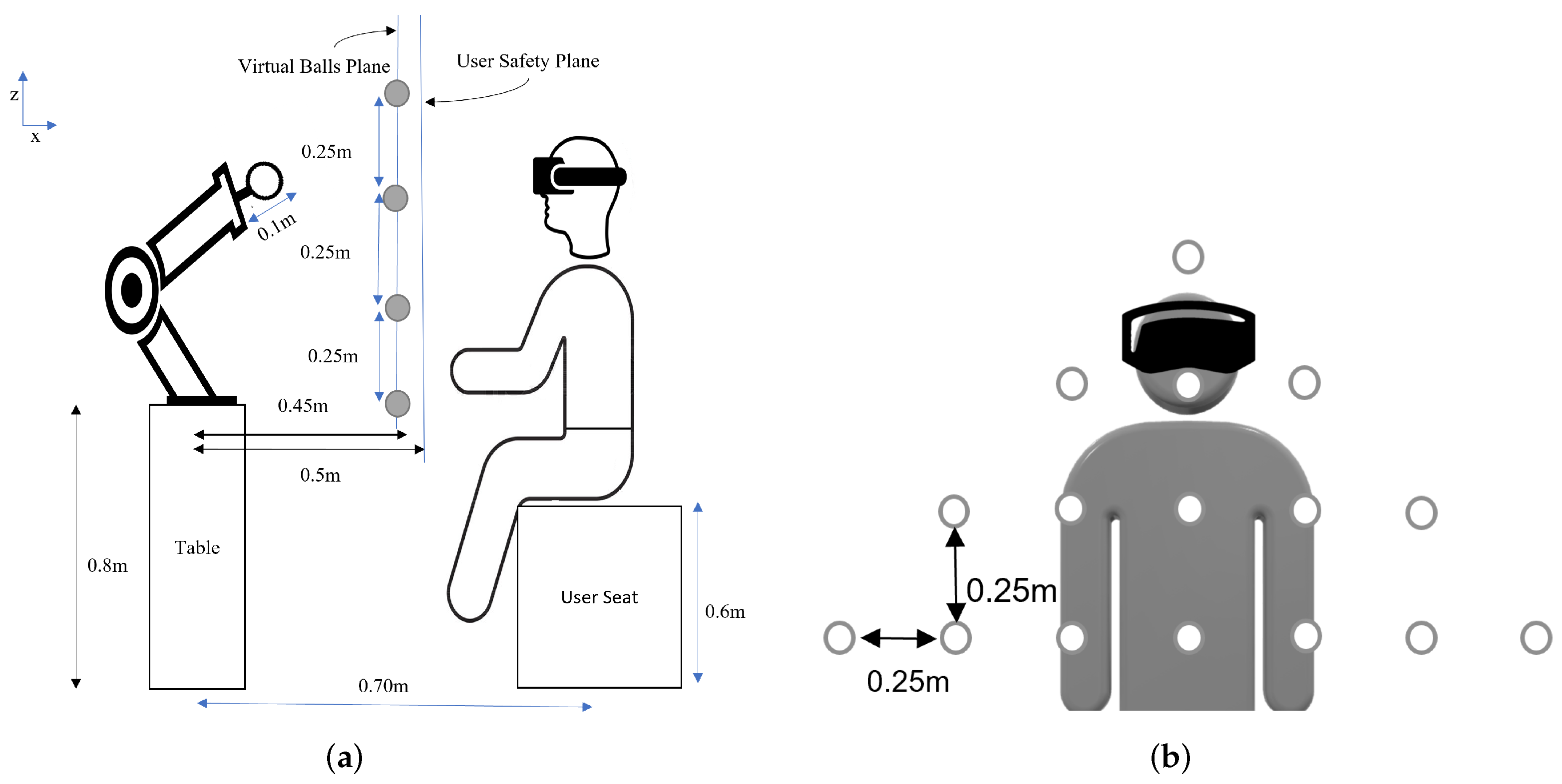
Out of the 39 recorded trajectories, one was discarded due to recording errors, and the remaining 38 were used for analysis. We first present a detailed analysis of an individual trajectory, then a summary of the results from 38 trajectories on Q1, Q2, Q3, and Q4, then an analysis on the effect of the hand threshold, and finally the effect of the eye-gaze window. It is important to note that, for the analysis of the results, the values of = 0.15 m and the value on the eye-gaze threshold in strategy 3 was .
4.1. Analysis of the Trajectory from to
We took, as an example, one of the user’s motion trajectory from point
to
to analyze the results of the three strategies proposed based on the four criteria Q1, Q2, Q3, and Q4 (as shown in
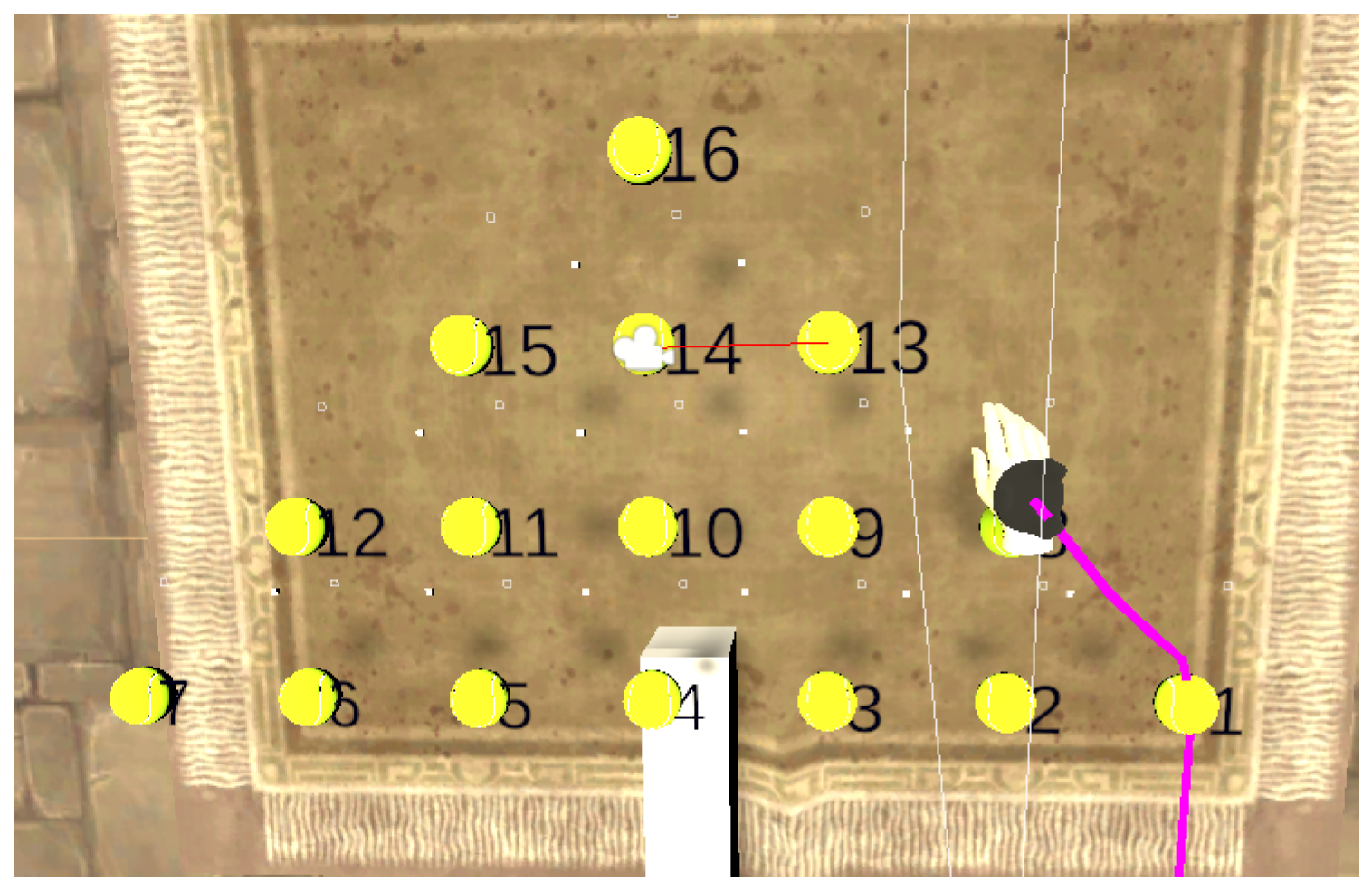
Table 1). A user view is shown in
Figure 9 using strategy 3. The robot motion corresponding to each strategy is shown in
Figure 10 and
Figure 11. In
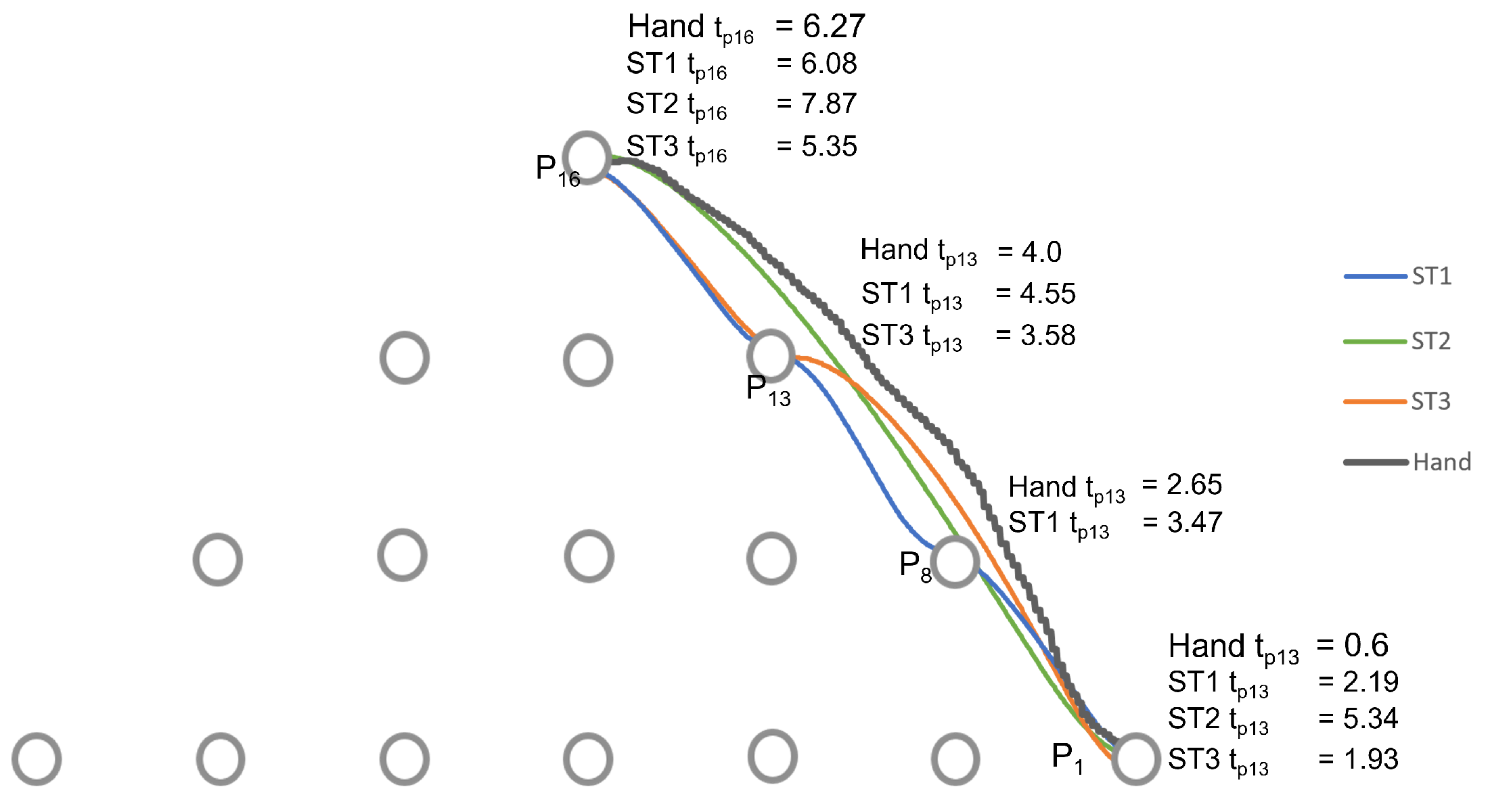
Figure 10, we represent the hand trajectory and the resultant robot motion for the different strategies. For
, we only show when the motion started. For the rest of the points, we indicate the time at which the hand was closest to each point, and the time the robot stopped at any point. A video of a user performing a motion from point
to
and
to
using strategy 3 along with the robot is provided in the
Supplementary Materials.
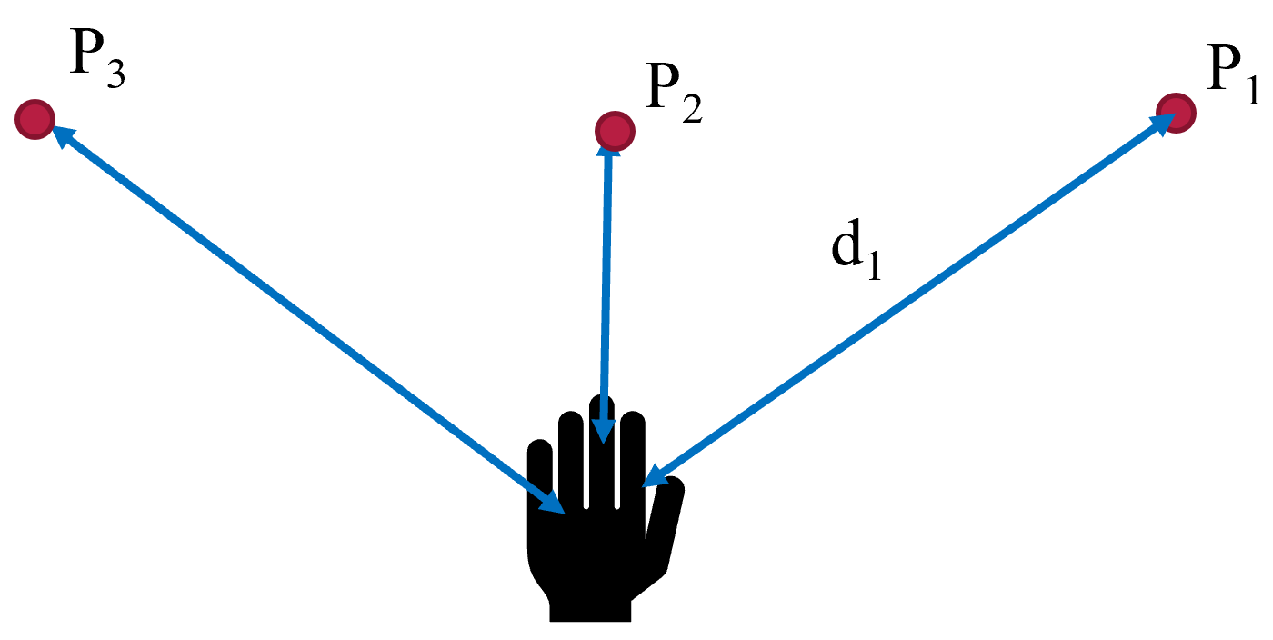
4.1.1. Strategy 1
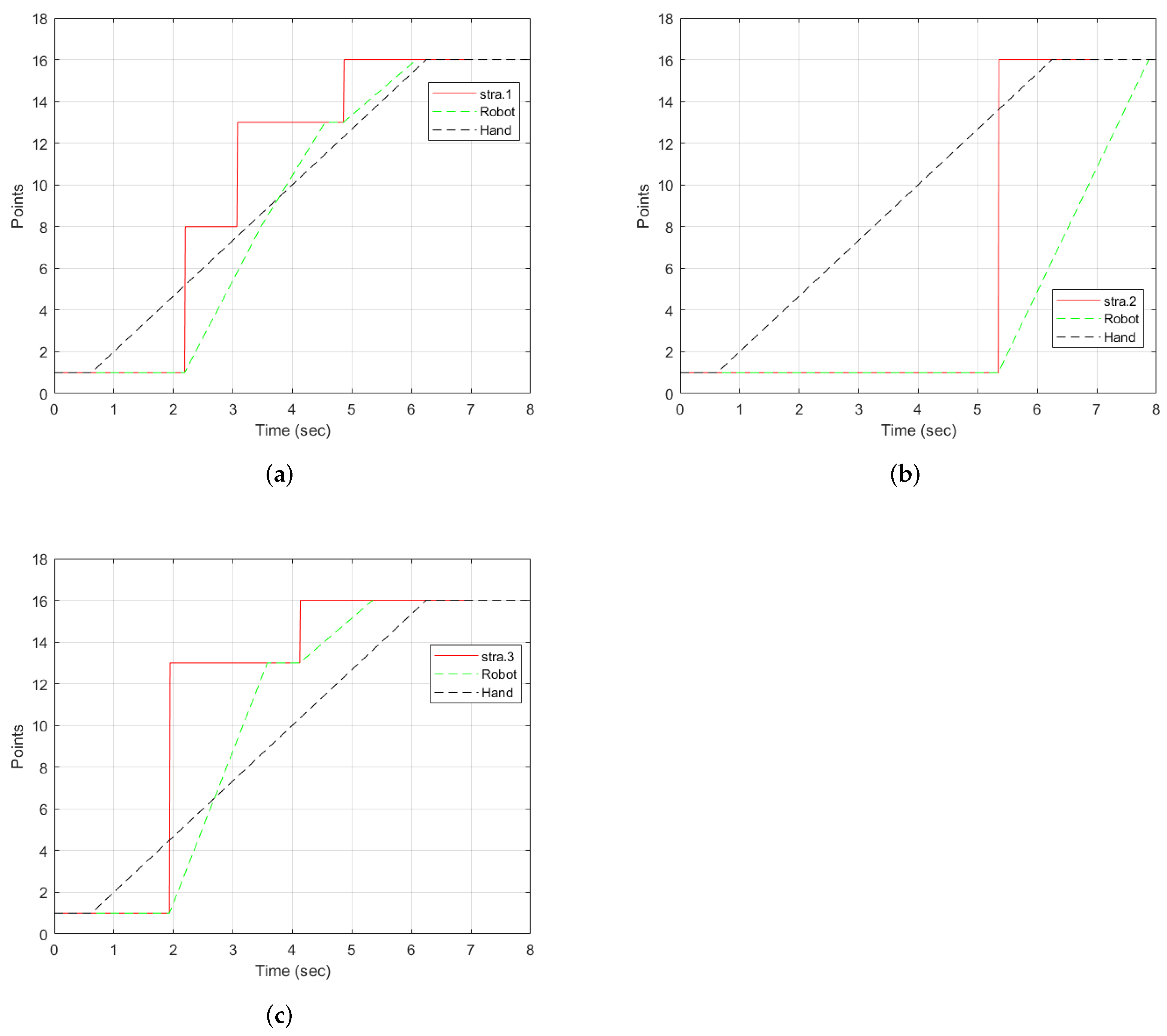
With strategy 1 as illustrated in
Figure 12a, the points detected were
,
,
, and
. The desired point was detected at
s. Two intermediate points were detected:
and
. Points 8 and 13 are along the path of the straight line. Therefore, each of them was detected as the hand moved. The robot stopped at all the points detected, as indicated by the green line. The hand left from
at
s.
was the first point to be detected by the strategy and the robot received the point and moved towards it. However, before reaching
, the strategy detected
. Since the trajectory from
to
was not yet completed, the robot reached
, stopped, and then started a new trajectory from
to
. It then waited for new information to go to
.
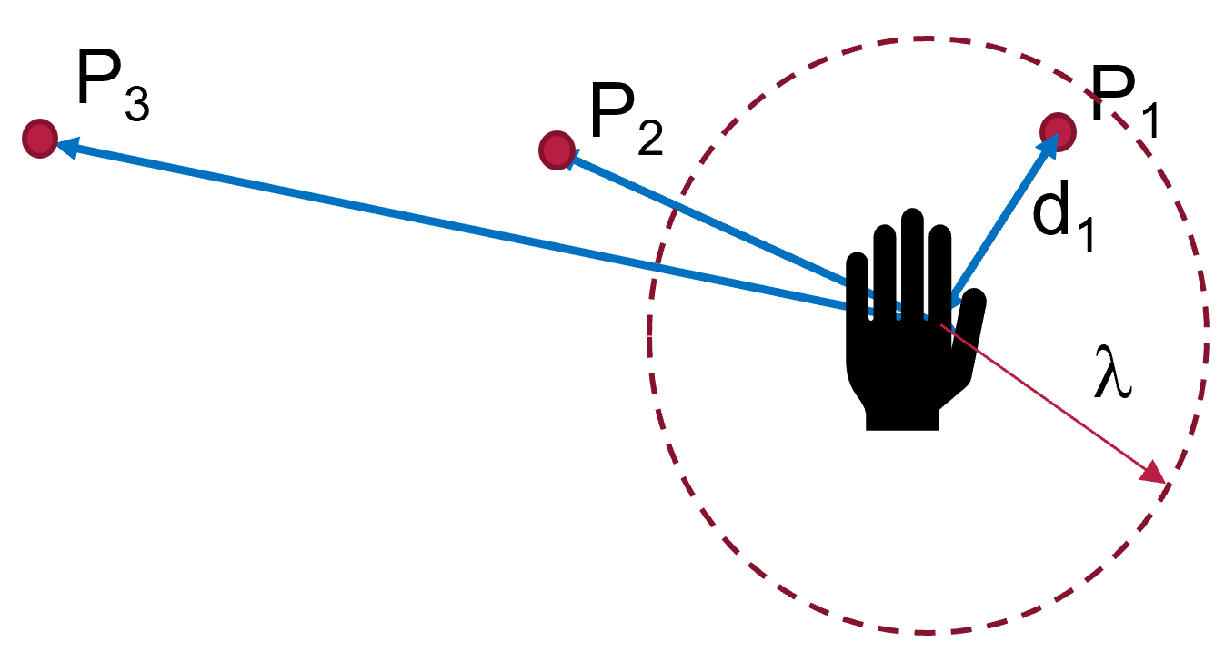
4.1.2. Strategy 2
The motion of the hand, the robot, and the selection by strategy 2 is shown in
Figure 12b. From
, the strategy selected
at
s. There were no intermediate points detected. This was possible because the hand threshold limits the selection of a point until the condition is met. This can be an advantage if the objective is to minimize the detection of unwanted points. However, it comes with a cost of late detection of the desired point when compared to other strategies, as shown in
Figure 11. The robot moves directly to the desired point. However, it arrives after the hand has already reached the point.
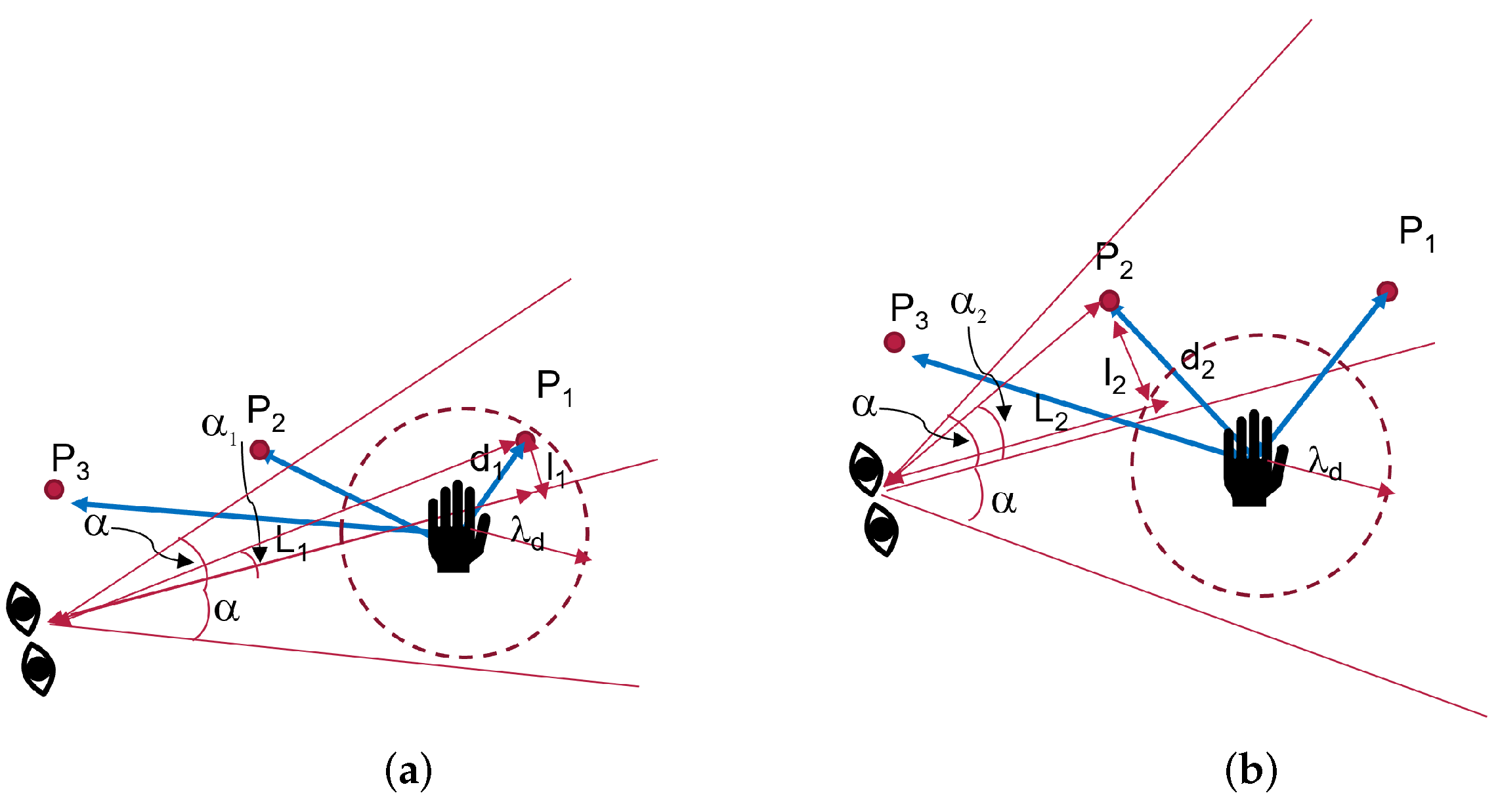
4.1.3. Strategy 3
Figure 12c illustrates the progression of strategy 3. The strategy started with point
, then selected
, the best point in the user eye-gaze direction shown in
Figure 9 by the red line on the camera icon, and, then, finally,
. The robot started from point
, then to the intermediate point
, where it waited for a new point, and then to
. As can be observed in the graph, the robot arrived at the final point earlier than the hand and the other strategies.
4.2. Analysis for All Trajectories
For all of the objectives Q1, Q2, Q3, and Q4, the data distribution was checked for normality using the Shapiro–Wilk test [
45]. We used the strategies as a three-level factor and strategy 1 as the baseline for comparison. A one-way analysis of variance (ANOVA) model was used to fit the data. Results showed that there were significant differences among the strategies
for all the objectives, with Q1 (
and
), Q2 (
and
), Q3 (
and
), and Q4 (
and
). Therefore, we reject the null hypothesis and conclude that the mean detection time, the number of intermediate points detected, robot arrival time, and the intermediate points detected by the robot are different for all the strategies. The results indicated that the effect of the eye-gaze tracking was significant for all of the objectives. A post hoc analysis was performed to find out the strategy-wise differences using the Bonferroni [
46] and the Tukey test [
47].
The Tukey test showed that the time for detection in strategy 3 was significantly lower than strategy 1 (
) and strategy 2 (
). Overall, strategy 3 was the best with the lowest time, as shown in
Table 2 and
Figure 13a. Compared to the baseline, the time difference was 0.92 s, representing a 37% reduction. However, there were no significant differences between the other strategies. These results indicate that the participants always looked in the direction of the desired point before moving their hand. Mutasim et al. [
48] discovered similar results in a study of gaze movements in a VR hand-eye coordination training system. They found that the target was detected, on average, 250 ms before touch with eye gaze. Therefore, the use of eye-gaze direction tracking significantly reduced the detection time.
A post hoc analysis using the Tukey test showed that strategy 2 had a significantly reduced number of intermediate points detected compared to strategy 1 (
). The results can be seen in
Table 2 and
Figure 13b. The difference between strategy 3 and strategy 1 was insignificant, although strategy 3 had a lower number of intermediate points by 20%. Due to the rapid eye movements (the saccades), eye-gaze direction tracking can result in the detection of intermediate points. However, the hand threshold prevented the selection of a new target when the hand was close to a point, hence reducing the number of intermediate points in strategy 3.
Concerning the robot time, a post hoc analysis showed that the overall time taken for strategy 3 was significantly lower than strategy 1
by 23% and strategy 2 (
), as shown in
Table 2 and
Figure 13a. The result indicates that eye-gaze tracking greatly improved the robot time. Even though the number of intermediate points detected by strategy 1 and 3 was similar, the motion planning algorithm ignored many points due to saccades, so they did not affect the results. In addition, strategy 3 improved the arrival time for the robot because of a lower detection time.
The number of robot stops was significantly higher in strategy 1 than strategy 3 (
) by 69% and strategy 2 (
) by 77%, as shown in
Table 2 and
Figure 13b. Although the difference in the number of intermediate points detected was insignificant between strategy 1 and strategy 3, the robot did not stop for all intermediate points. This implies that selections by strategy 3 due to saccades did not significantly affect the robot motion, thanks to the motion planning algorithm, which discarded new information received before a trajectory finished its execution.
4.3. Analysis of the Effect of Parameters on the Performance of the Strategies
The performance of strategy 3 depends on the values of the hand threshold parameter and the eye-gaze window parameter . Therefore, we conducted experiments to determine the effect of and on Q1, Q2, Q3, and Q4.
4.4. The Effect of the Hand Threshold
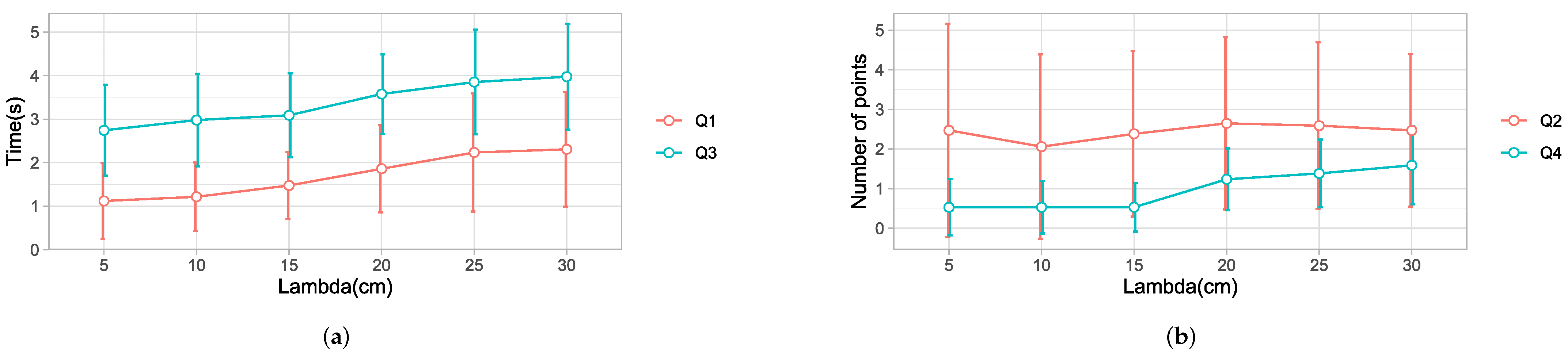
We experimented with different values of , with cm as the baseline, compared to cm, 15 cm, 20 cm, 25 cm, and 30 cm. The results based on a data set with 34 different trajectories are presented below.
A one-way ANOVA model revealed a significant effect of the
on
,
. Post hoc comparisons using the Tukey HSD test [
49] indicated that the mean time for
cm was statistically lower than that for
cm
by 1.11 s and
cm
by 1.19 s. Specifically, our results suggest that increasing the value of the threshold generally increased the time to detect the final point. A small threshold allows for the detection of the hand’s intention to move away from the current point. This leads to an early detection of the desired point by the eye gaze. However,
had to be greater than 20 cm to notice a significant effect. Details are shown in
Table 3 and in
Figure 14a.
A one-way ANOVA revealed no significant effect of
on Q2, with (
,
). The results are shown in
Table 3 and in
Figure 14b. The difference was not significant because of the following reasons. First, a lower value of
triggered selection by the eye gaze, which is affected by saccades, as observed in [
16], resulting in a high number of intermediate points. Increasing the threshold would reduce the saccades because the target selection is by hand. However, this would mean that the strategy would tend to behave like strategy 1, increasing the number of intermediate points. Thus, selecting the correct value for this criteria is a trade-off between selection by eye gaze and selection by user’s hand. The best balance was
cm or 15 cm.
A one-way ANOVA model revealed a significant effect of
on Q3
,
). Post hoc comparisons showed significant differences between
cm, 10 cm, 15 cm, and
cm and 30 cm. Overall,
cm took the least time, as shown in
Figure 14a and
Table 3. The results show that the robot took a shorter time to reach the desired point for a small threshold.
A one-way ANOVA test showed that the hand threshold had a significant effect on Q4:
. The results are shown in
Table 3 and in
Figure 14b. Post hoc comparisons revealed that
cm was significantly different from
cm and 30 cm; however, it was not significantly different from
cm and 15 cm. The results show that a larger threshold increased the number of intermediate points detected by the robot. The mean values were similar for the lower values of
cm, 10 cm, and 15 cm. Then, the slope of the graph changed with increasing values of
. This pattern is different from the results obtained from the number of intermediate points selected by the algorithm. The algorithm selected a significant number of intermediate points for lower thresholds due to the saccades in the eye-gaze tracking. Therefore, the robot discards most of them thanks to a robust motion planning algorithm. On the contrary, as the threshold increases, the selection of points is mainly by hand. In this way, the algorithm behaves like strategy 1, which accounts for the increased number of intermediate points detected.
Overall, there was no significant difference between cm, 10 cm, and 15 cm for all of the objectives Q1, Q2, Q3, and Q4. For this study, the best value selected was cm, in accordance with the dimension of the environment. People hold a ball with a diameter of cm. The tracker is placed on the top of the hand at a distance of approximately 5 cm from the palm. Therefore, the total distance from the center of the ball to the tracker was approximately 8 cm.
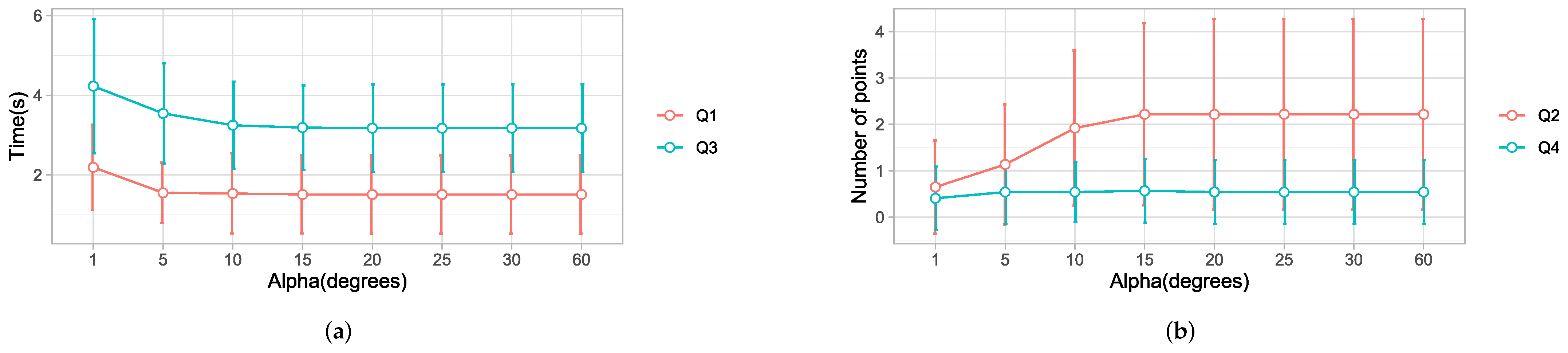
4.5. Eye-Gaze Window
Previous studies [
2,
10,
42,
43] have used different values of
, ranging from
,
, and
, which have been used for selecting objects in the gaze window. However, there was no standard value for the appropriate gaze window size. Based on a data set with 37 different trajectories, we present results of the effect of
by comparing
, and
to the baseline
. Normality checks were carried out and the assumptions were met.
A one-way ANOVA test showed that
had a significant change on Q1, with
and
, as shown in
Table 4 and
Figure 15a. The results from a post hoc analysis showed that
has a significantly longer detection time
than
,
,
, and
, with a difference of 0.68 s. These results show that decreasing
delayed the detection of a point because of the smaller selection. A point cannot be selected until it is within the gaze window. A threshold greater than
would give a view cone greater than
, which would be large enough to accommodate several points in the user’s gaze direction.
A one-way ANOVA test showed that Q2 was significantly affected by
, with
F(7, 288) = 4.237
p = 0.000. More specifically, a post hoc analysis showed that
had the lowest number of intermediate points, with a value significantly lower than
,
,
,
,
, and
. The results are shown in
Table 4 and
Figure 15b. This suggests that, when
was set to a value less than
, the detection of intermediate points decreased significantly. A small selection window will block out many points, whereas a large window gives room for saccades. This relationship is depicted in
Figure 15b.
There were significant differences in the time taken by the robot to reach the desired point:
,
. The time taken using
was significantly greater than the rest
. These results showed that reducing
to a value
significantly delayed the robot. However, the difference was not noticeable between large values, as can be observed in
Figure 15a.
There was no significant effect of
on Q4. Adjusting the threshold had no effect on the intermediate stops of the robot, as observed in
Figure 15b. These results follow a similar pattern to the results from Q2. However, in this case, the number was lower thanks to the robust motion planning algorithm.
5. Discussion
This study on the development and evaluation of strategies for user motion prediction was motivated by the need to improve detection speeds and increase the response time in EHDs.
Most importantly, our solution relied on the eye-gaze direction and hand position to determine human motion intention and desired targets. We analyzed data from three participants to determine the time taken by each strategy to detect the desired point, the number of intermediate points detected, the time taken by the robot to reach the final point, and the total number of intermediate stopping points of the robot. Strategy 3 gave the best detection time, robot time, and fewer robot stops. These results showed that the eye gaze significantly improved the response time while minimizing the number of robot stops. Our results were coherent with the literature on hand-eye coordination and target selection, which has identified that humans typically fix their gaze in the direction of the target, slightly before or after the hand begins to move, as shown in
Figure 9.
The results suggest that visual behaviour for target selection with a haptic system is similar to behaviour when carrying out the task with hands in everyday life. Thus, the proposed system should work for people with motor impairments.
The prediction strategy based on the eye-gaze direction demonstrated a pattern to detect more intermediate points because of the saccadic movements. To minimize this behaviour, recent studies [
15] in which the gaze direction is used to predict human intention utilized gaze attention models. In such models, they wait for a window period ranging from 200 ms to 4 s when the gaze is fixated on an object to validate it as a target. Such models affect robot arrival times and are applicable for large objects. In our case, the balls are not big. Thus, we used a threshold on the hand to limit the selection of the next point. The detection by the eye gaze was cut off when the point-to-hand distance was less than a threshold. In addition, the path-planning algorithm of the robot was designed to complete a trajectory before starting a new one. Thus, rapid trajectory changes due to saccades were always discarded. This implies that our model can be used for both small and large objects, as long as a suitable threshold on the hand is selected.
In this study, the hand threshold plays a vital role in detecting human motion intention. In studies where the nearest point to the hand method is used [
2,
18], the target was detected whenever the hand had crossed half the distance between any two points. However, when coupled with the eye gaze, a hand threshold was used to detect the user’s intention to move to another point. In this way, the hand-to-point was below the threshold, and the user intention was interpreted as a desire to remain at a point. Therefore, the robot remained stationed at the point. The threshold also served to restrict the detection of a new point. Thus a threshold plays a significant role in determining the detection time of the target and the intermediate points. Thus, it affects the robot arrival time and the intermediate points detected along the robot trajectory. We experimented with different threshold values on the hand to determine a suitable threshold value. The analysis revealed that a lower threshold was associated with a faster detection time. We attribute this to the fact that a lower threshold value indicated an earlier detection of the intention by the user to move to another point.
Due to the lack of clear agreement on the standard size of the gaze view window in studies investigating eye gaze and hand coordination patterns [
2,
10,
42,
43], we examined the effect of the threshold on the eye gaze. Our results showed that a view angle greater than
, as used in strategy 3, had similar results for all of the research questions Q1, Q2, Q3, and Q4. However, a reduced threshold
was associated with a significantly increased time for detection, but reduced the number of intermediate points. A small threshold implied that a few points would be selected at a time. Thus, it would take longer to have a valid selection, which greatly increased the time to detect the desired point and consequently delayed the robot. From the analysis, we discovered that the gaze fixation model, as used in [
2], increased the detection time, hence delaying the robot.
Previous studies [
16,
50] pointed out that the visual gaze is full of rapid eye movements between fixed points (saccades), and it was the primary reason why gaze fixation was the widely used approach. However, we do not use gaze fixation because it takes longer to detect a point. In addition, it is unsuitable for smaller objects. Instead, we used a threshold on the hand to restrict robot motion when a point lies within the stated threshold. We select the best point depending on the angle
and not the visual ray directly. By combining the hand threshold and a good motion-planning algorithm, saccadic movements do not significantly affect the robot motion when a large threshold on the eye gaze is used. Thus, our approach is robust to saccades and highly responsive.
Our findings show that prediction based on the eye gaze improved the response time for the robot. However, optimizing the detection time from human predictions comes at the cost of increasing the intermediate points detected. We observed this through an analysis of the threshold values on the hand. A lower value resulted in a good detection time and a higher value of intermediate points detected. Thus, a compromise has to be made to improve the detection time and reduce the detection of the intermediate points. Therefore, we recommend finding a suitable threshold on the hand and the eye-gaze window to suit the task.
In addition, our system only uses positions in a 3D space; it would be good to extend the interaction to 6-DOF to study the implications of prediction and robot time in haptic rendering systems where positions and orientations of virtual objects are essential. Although VR hand-eye coordination significantly improved the detection time, we observed that participants spent some time searching for a target. Therefore, further research is needed to minimize the time spent searching for the next target to increase the user’s performance and the eye-hand coordination training system. Our work was preliminary on the proof of concept with a few healthy participants. It would be essential to evaluate the haptic system with many people with motor disabilities.
Eye-gaze detection to predict targets for haptic devices is a promising solution to improve intention detection and robot response. However, due to saccades during decision making and target search, additional studies are needed on methods to process gaze data.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}