1. Introduction
The accelerated development of the Internet of Things (IoT) has attracted attention from stakeholders all over the world due to the combination of the physical world with the virtual world through the Internet for communication and data sharing. IoT has been defined as an interrelated system of mechanical and digital machines, computing devices and objects that is capable of transmitting data over a network without involving human-to-human or human-to-machine interaction. IoT becomes more prevalent every day in many life aspects such as industrial sectors, financial sectors, and healthcare sectors [
1].
In healthcare, IoT has improved the quality of care provided to patients. Indeed, people can lead more comfortable lives as it guarantees their health and safety through continuity monitoring. In addition, it supports a wide range of applications, from implantable medical implants to Wireless Body Area Networks (WBAN). WBAN is composed of tiny devices that are considered the most promising technologies for improving healthcare services. These devices have enabled remote monitoring to enhance the overall quality of care provided to patients in remote areas or medical facilities [
2,
3].
Despite the merits, WBANs are vulnerable to external attacks as sensor data are collected from various locations and people. People with malicious intent may compromise the sensors and insert malicious data that constitute anomalous readings, leading to incorrect diagnoses and inappropriate medication for patients and substantial financial losses for any organizations that adapt the healthcare system [
4,
5]. Anomalies have emerged as a serious issue in healthcare systems. These anomalies may also result from faulty devices and erroneous readings of these devices.
Machine learning and statistical techniques have been used to detect anomalies in systems in the past few years. Various researchers have studied the use of these techniques to detect anomalies in healthcare systems and their findings support their effectiveness as in [
6,
7]. However, despite their success, more research is needed to promote their improvement concerning the speed of detection, type of anomalies, the correlation that exists in the collected attributes, and dealing with big data.
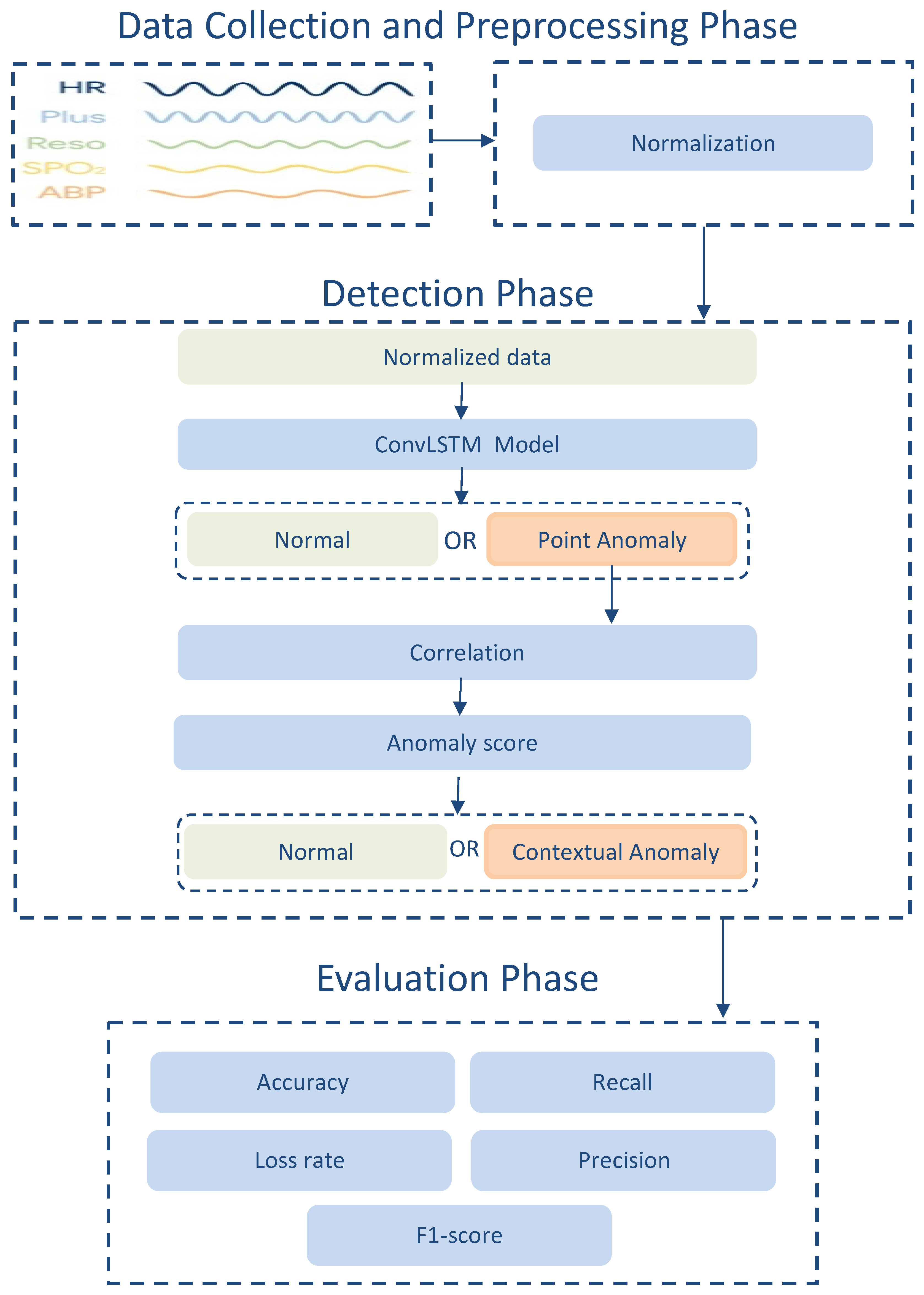
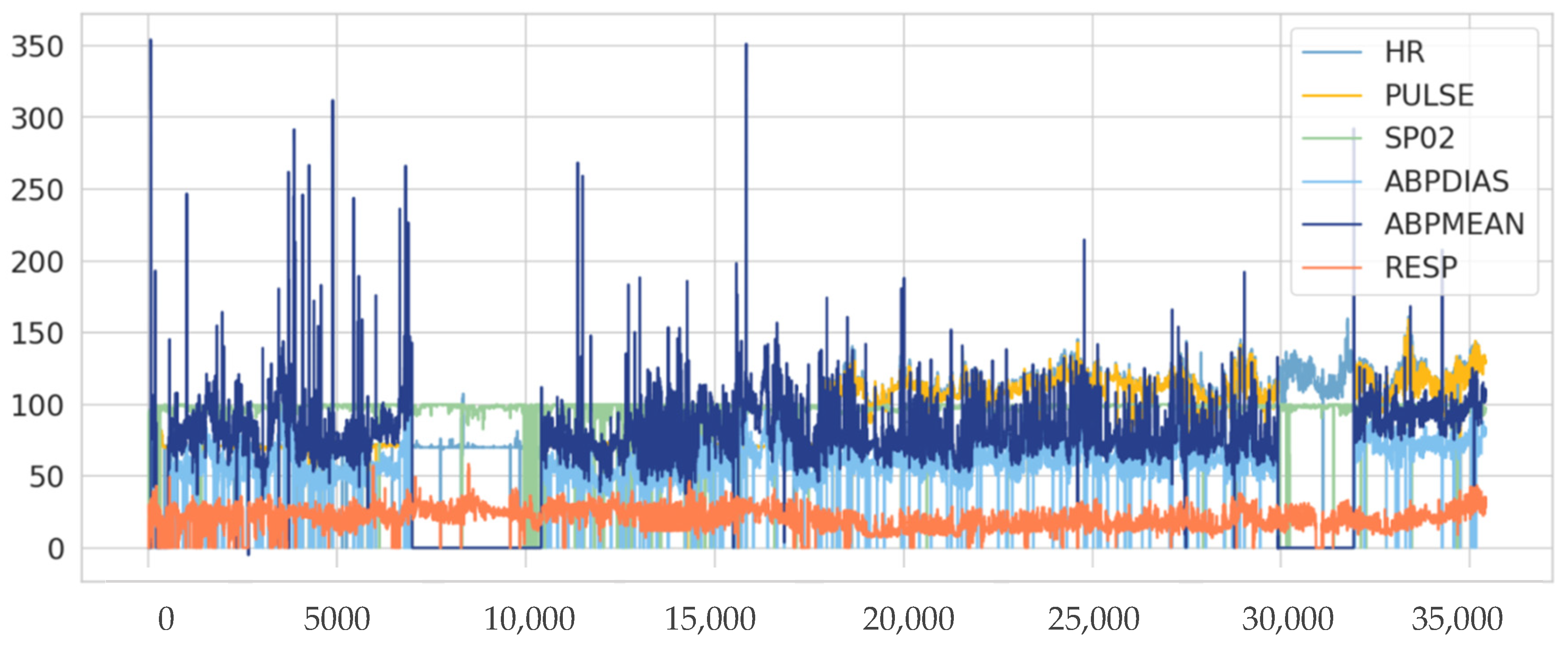
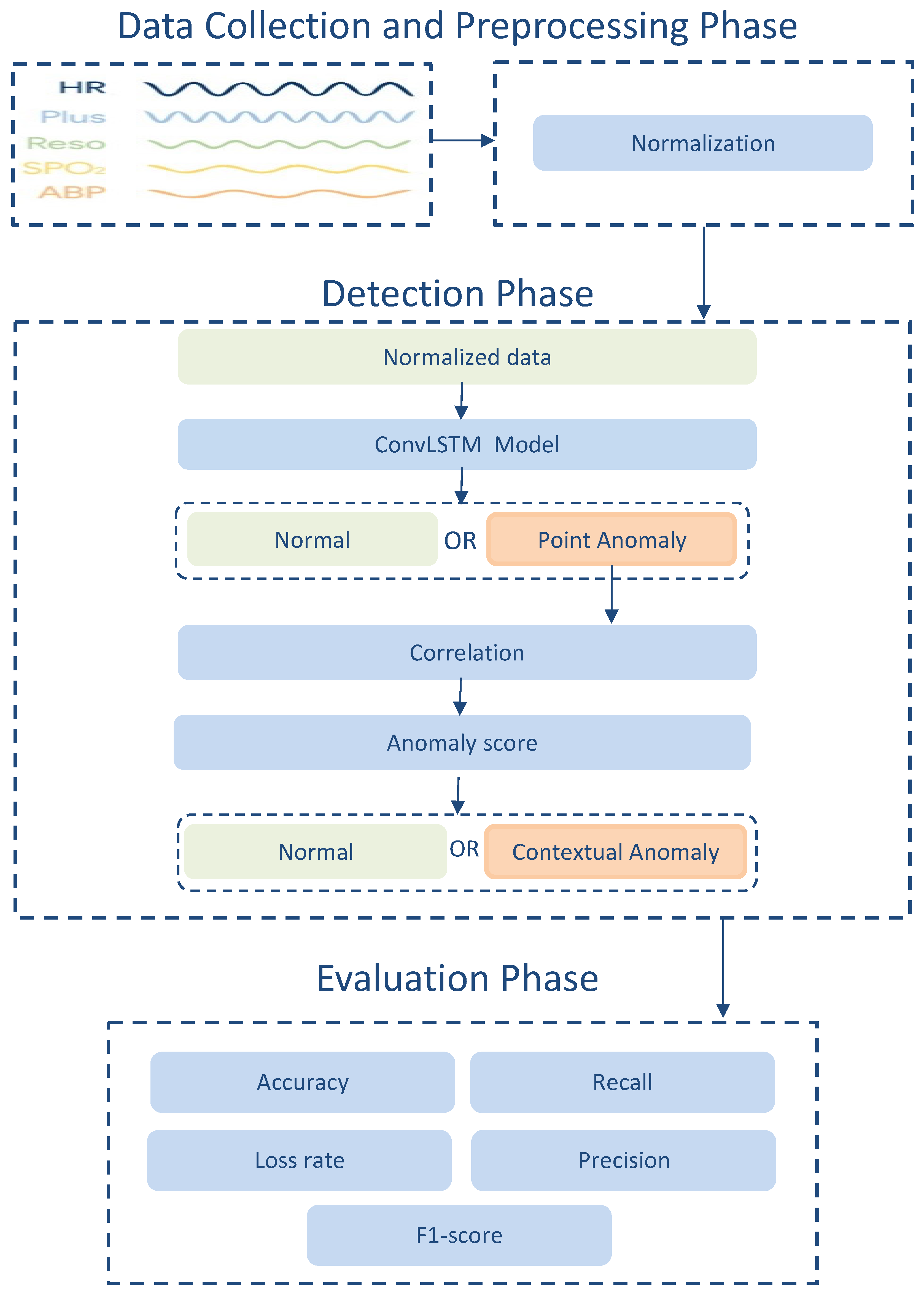
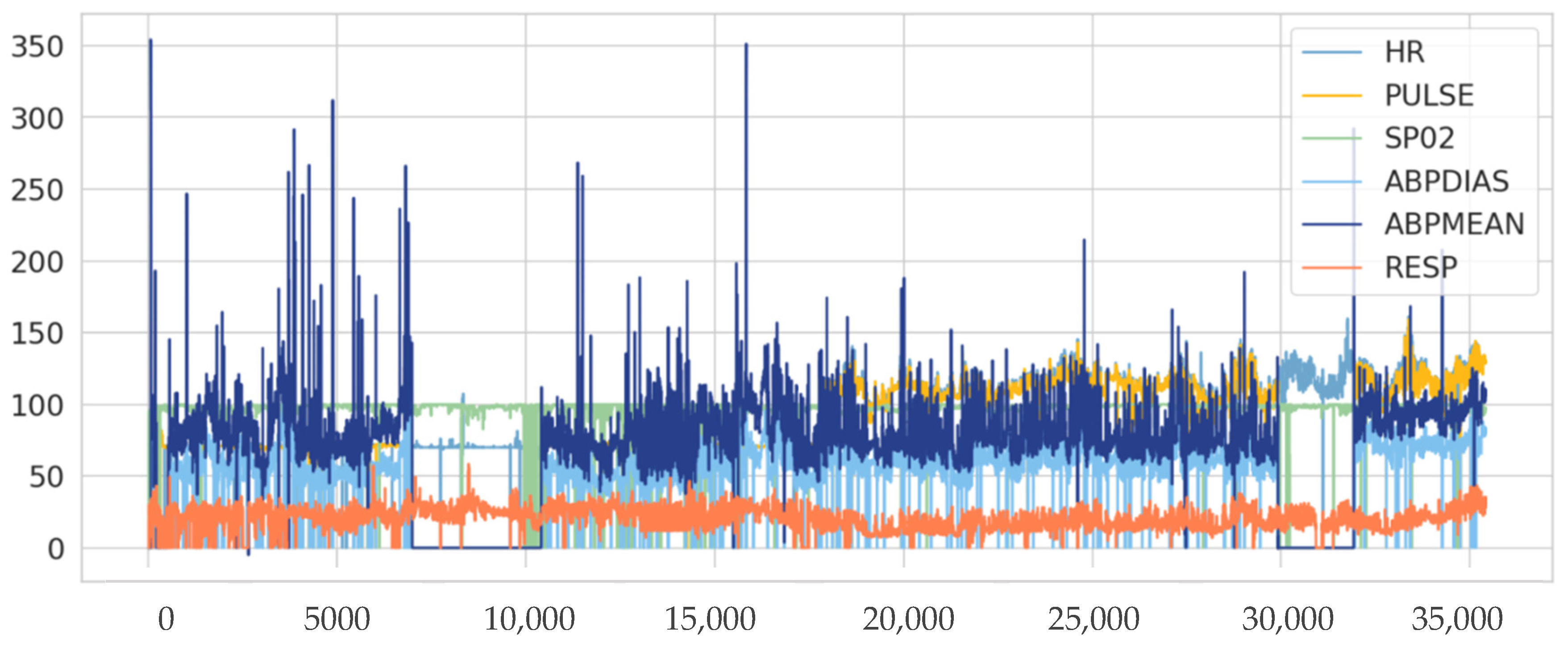
In this light, this paper proposes an anomaly detection model that exploits the correlation that exists in measured attributes of WBAN sensors and uses the hybrid ConvLSTM deep learning technique. This model aims to detect anomalous data in WBAN and consider the requirements of the learning process to identify anomalous behavior and provide a reliable system against sensor faults and anomalous activities with an understanding of the factors that impact patients and healthcare organizations. More specifically, it helps to ensure higher detection accuracy and fewer error rates by exploiting the multivariate spatiotemporal correlation between physiological data in WBAN. The contributions of this paper are summarized as follows:
- (1)
Developing a method that can benefit from the spatiotemporal correlation among physiological data and the contextual data to choose the most appropriate anomaly detection strategy under a given condition (normal and abnormal ranges for physiological data).
- (2)
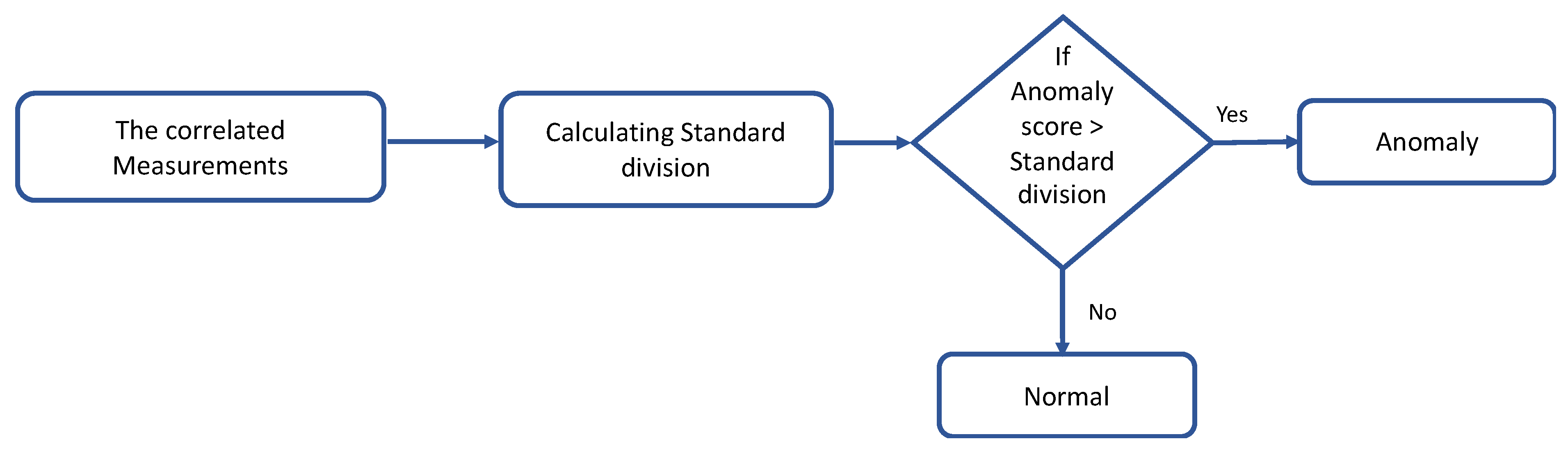
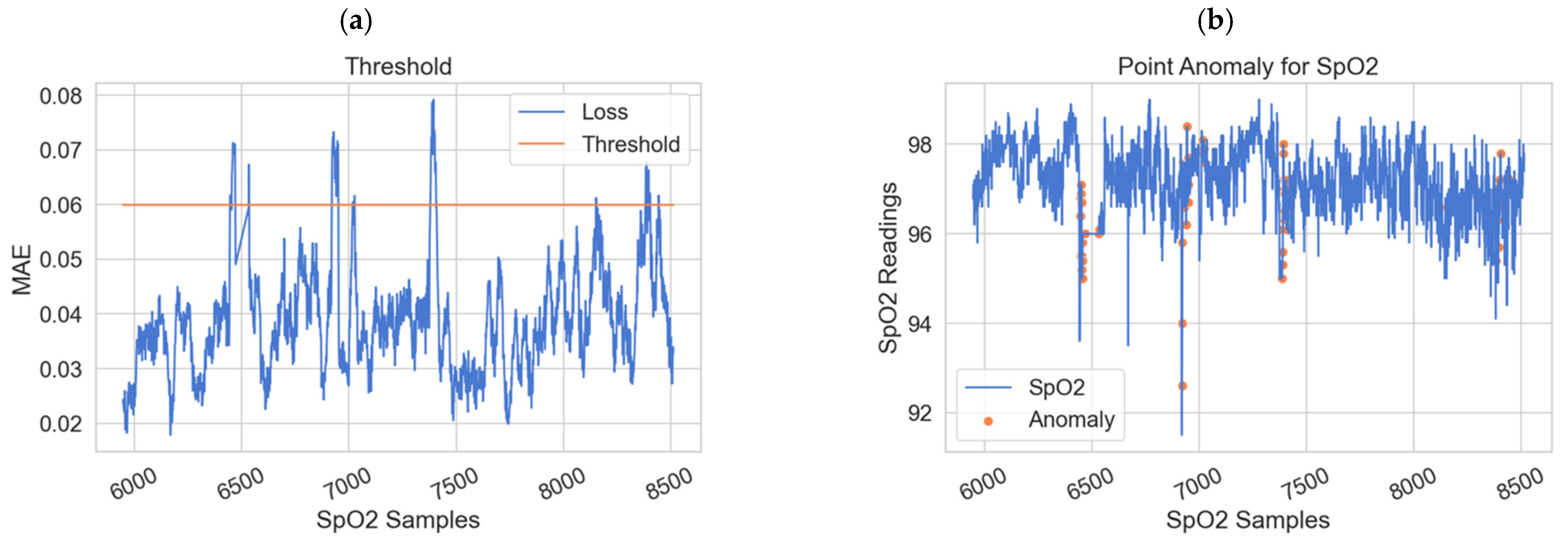
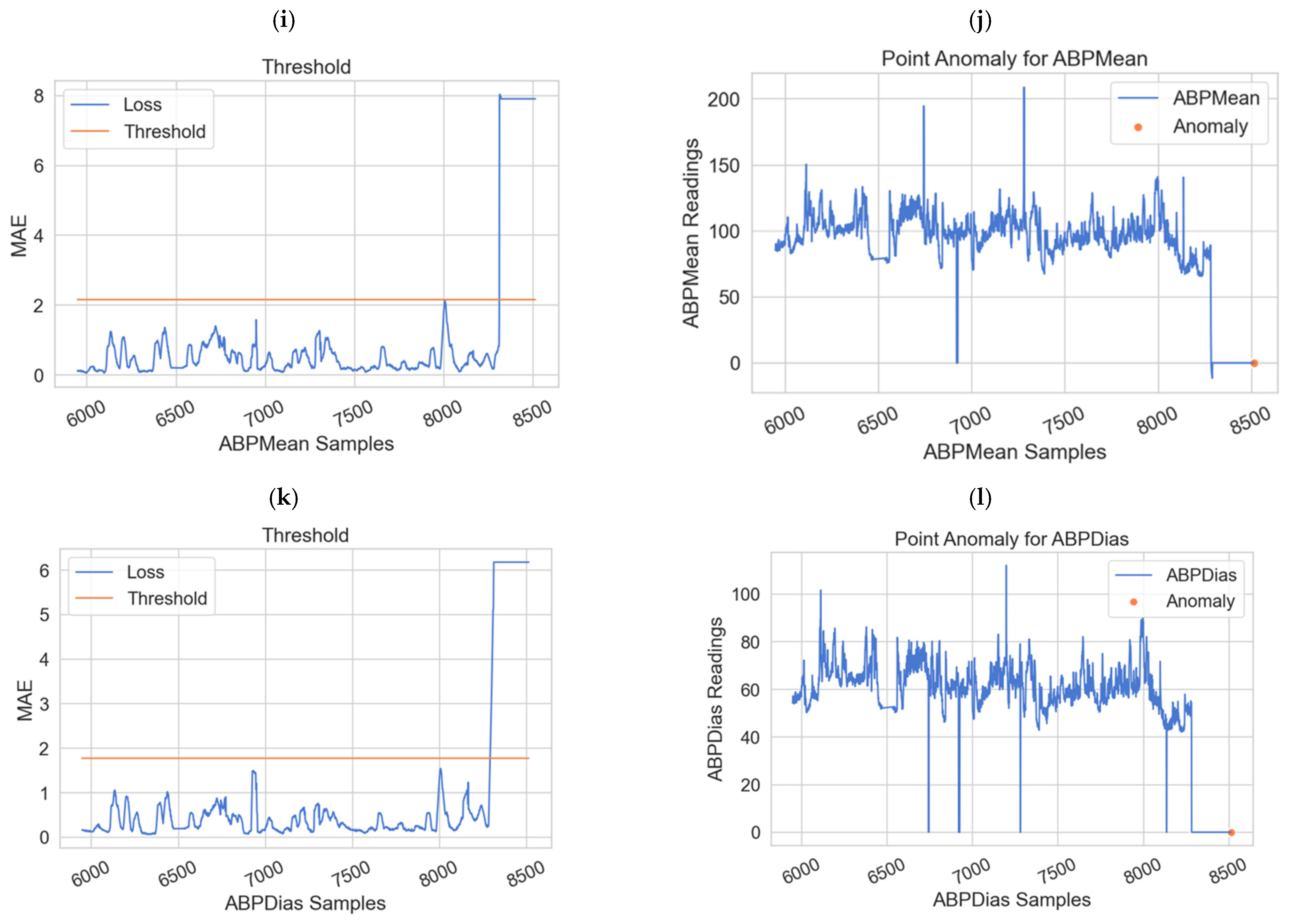
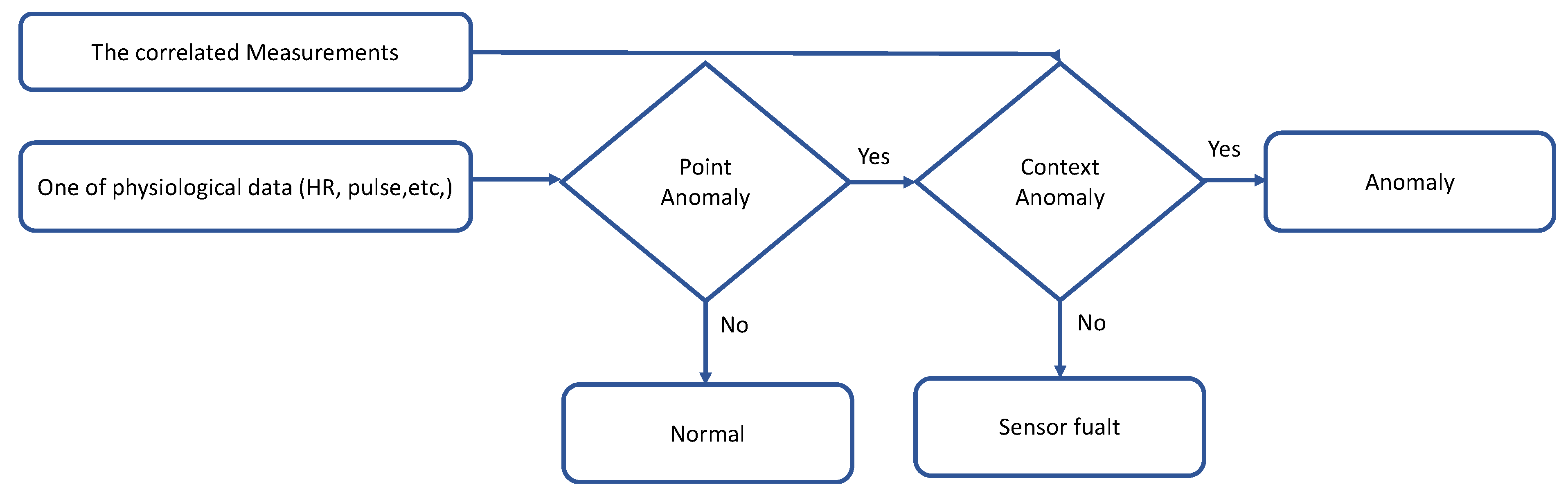
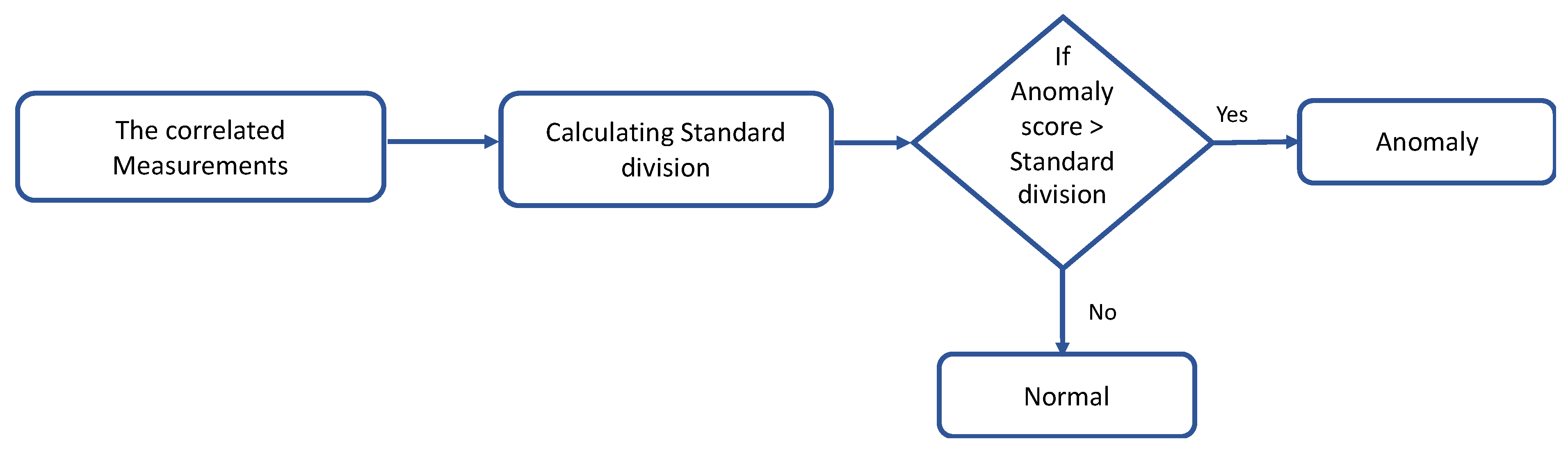
Classifying the physiological data based on point anomaly (using the dynamic thresholds) and contextual anomaly (using anomaly score).
- (3)
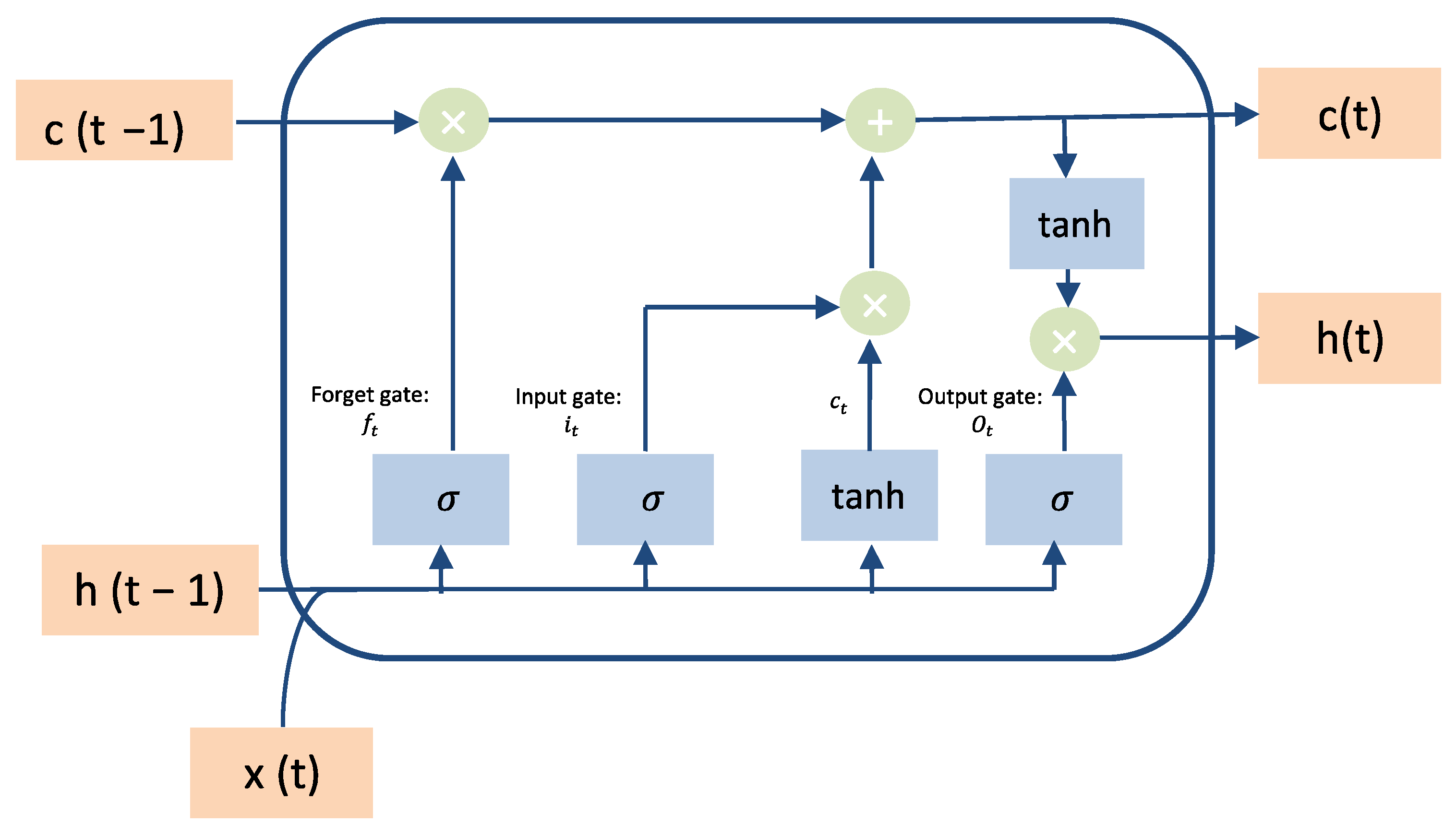
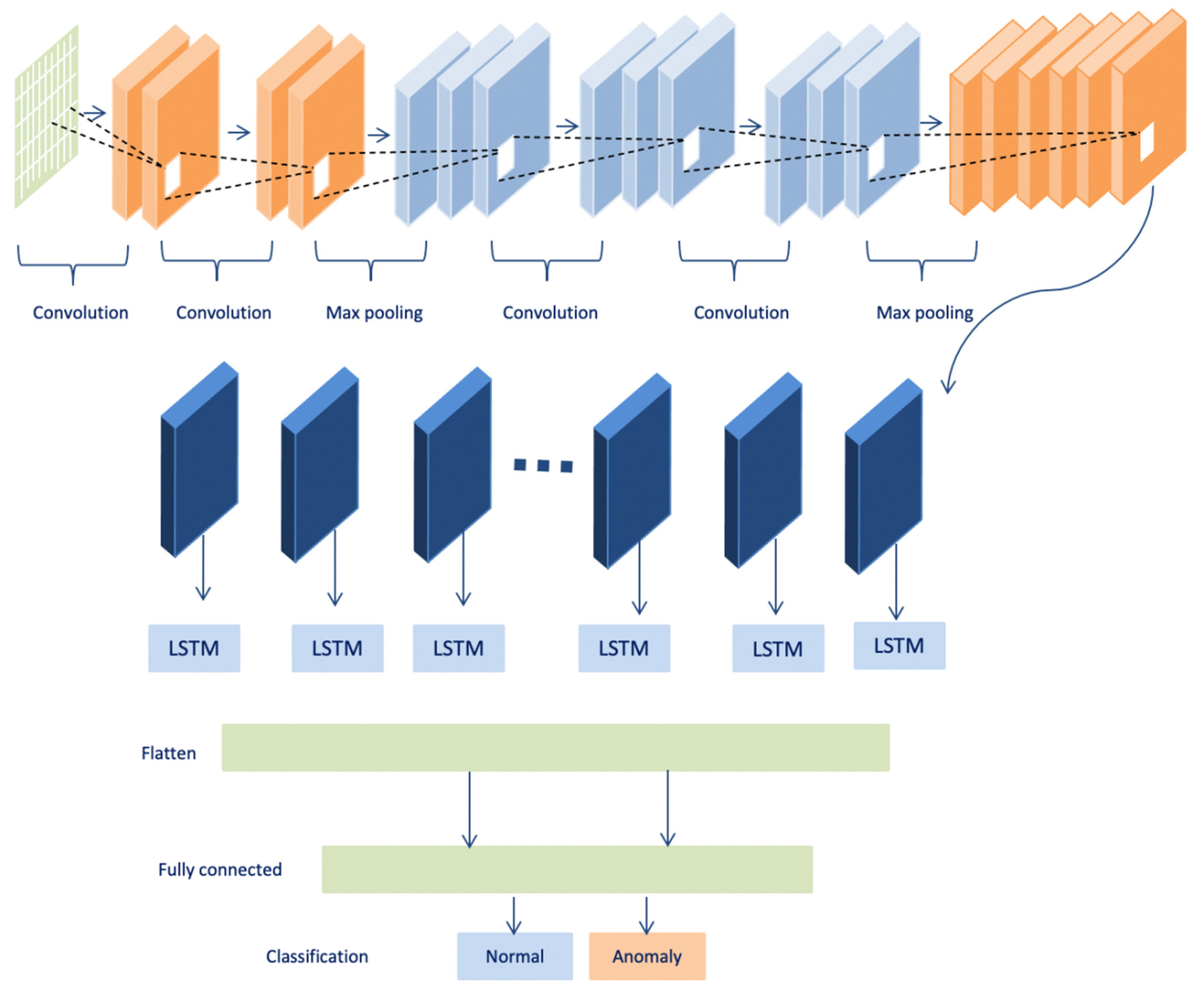
Developing an anomaly detection model based on the ConvLSTM deep learning technique to detect both point and contextual anomalies. The proposed model fits big data requirements and time constraints that are important features of the WBAN.
The rest of this paper follows the following structure:
Section 2 explores related works to anomalous detection systems in WBAN.
Section 3 describes the design of the proposed model and its components.
Section 4 presents the experimental results and analysis.
Section 5 reports a comparative analysis with existing models while
Section 6 concludes the paper and provides future research directions.
2. Related Works
Anomaly detection receives more attention in the (IoT) domain, especially for healthcare systems that generate massive data from WBAN. Many anomalies detection models have been proposed for WBAN in the literature based on different mechanisms and are analyzed in the subsequent paragraphs.
In [
3], the study proposed an anomaly detection approach to evaluate the difference between actual sensed data and predicted values that depend on historical measurements. The approach was then applied to real physiological healthcare data. Experimental results showed the effectiveness of the approach by achieving low false-positive rates and high detection rates.
Using a Markov-based chain model, another study [
6], evaluated the reliability of WBAN by detecting the anomalies, patient health status, hardware failure rate, and transient fault correction method. The study proposed a metric for Mean Time to Failure (MTTF) that provided better performance in analyzing the reliability in specification and anomaly detection for WBANs. The results showed a 95% detection rate and a lower MTTF value of 43.01 s. Although the study showed a high detection rate as a reliability metric, the reliability metric is not enough to cope with some types of anomalies (i.e., fault measurements and abnormal readings).
In [
7], the study suggested a dynamic threshold approach to detect the sensor anomaly and differentiate between true and false alarms effectively. This approach used a correlation method to extract the features and estimated the sensor values using random forest algorithms. The proposed approach was used to analyze past historical physiological data and compare it with predicted sensed values. The error value was measured using a dynamic threshold to identify the false and true alarms. The results showed a high detection rate and a low false-positive rate. However, this approach exploits only the spatial correlation between two sensors and ignored the temporal correlation. Although the random forest achieved perfect results, its complexity invokes long training periods.
In [
8], an approach was proposed to detect changes that occurred in data collected by WBAN based on the Kalman filter algorithm. Authors claimed that this approach can automatically detect any physiological change that occurred in WBAN. Nevertheless, the Kalman filter has some downsides such as a larger computational complexity to obtain the best results. In [
9], the study suggested a framework for anomalous sensor data detection. The framework was based on Hadoop Map Reduce-based parallel fuzzy clustering and data compression. The results showed that the proposed framework achieved high accuracy with fewer false alarms, which obtained an accuracy between 97% and 98%. This study used a parametric statistical approach that involves high computational complexity.
In [
10], the study proposed a framework that combined regression techniques and random forest algorithm to detect anomalies in WBAN. This framework considered both temporal and spatial correlations to detect anomalies. An accuracy of 96% was reported for the proposed framework. However, the combination of random forest with regression is not able to detect new forms of anomalies.
In [
11], the study conducted an approach for detecting abnormalities changes such as modifications, forgery, and insertions that occur in electrocardiogram (ECG) data. The approach utilized the Markov model with different window sizes of abnormalities data (5% and 10%). The results reported 99.8% of true negatives with the 5% and 98.7% of true negatives with the 10% windows. This study just used one type of data for detecting abnormality and emergencies. Despite the good performance of this model in terms of time execution, it still has some limitations in terms of memory.
In [
12], researchers proposed a new approach to detect anomalies in WBAN based on Gaussian regression and majority voting. The proposed approach created a system that can distinguish between real medical conditions and false alarms by using a real dataset. Reported findings showed that this approach was effective in terms of high detection rate and low false-positive rate. However, there were some limitations to this approach such as high computation complexity, high false alarm, and bulky data samples.
In [
13], the study suggested enhancing anomaly detection by adding a correlation algorithm for various body sensor types. The suggested algorithm utilized thresholds to detect anomalies. The results showed an improvement in various intersections between analyzed medical signals. However, the study only considered one type of correlation that exploits the spatial relationship between sensors and ignore the temporal correlation at each sensor reading. Two subsequent studies in [
14,
15] measured the faultiness of the sensors that cause high false alarms in healthcare systems. Both studies used dynamic sliding window and weighted moving average to detect the abnormal sensor faulty measurements. However, using the weighted moving average approach often overlooks the complicated relationships that exist in the data.
In [
16], the authors developed an anomaly detection method for WBAN to discard false alarms caused by faulty measurements. The method used the spatiotemporal correlation and a game-theoretic technique. In addition, it applied Mahalanobis distance at the Local Processing Unit (LPU) for multivariate analysis. The proposed method proved superior effectiveness in achieving low false alarm rates with high detection accuracy. A possible weakness of the game-theoretic technique is that it cannot deal with new forms of anomalies.
In [
17], the study developed an anomaly detection model for medical WSN. The model aimed to achieve a low false-positive rate with a high quality of detection. Moreover, this model used a decision tree, linear regression and threshold biasing and was then tested using a real physiological dataset. The empirical results of the study showed a high performance where the false-positive rate was 4.5%. However, machine learning algorithms impact inefficient performance when dealing with complex big data generated by medical WSN. The authors in [
18] proposed a shapelet-base (SH-BASE) approach to detect anomalies. The experiment results revealed that SH-BASE achieved average performance in sensitivity and accuracy. However, the drawbacks of this approach are poor generalization capability and a high computational burden.
In [
19], The work integrated the artificial neural network with ensemble linear regression to detect anomalies in WBAN. This work helped to create distinction in anomalous data by classifying the physiological data and then applying regression to identify the anomalous data. Experiments revealed that the proposed approach was able to reduce false alarms by 4.2%. Moreover, linear regression has some certain limitations such as that it cannot give feedback and sensitivity with anomalies.
In [
20], the research proposed an anomaly detection system for WBAN based on the data sampling approach with Modified Cumulative Sum (MCUSUM). The sampling method was applied to increase the speed of detecting anomalies, while the MCUSUM algorithm was applied to accurately detect anomalies. The results showed that the proposed approach provided the lowest execution time and high energy efficiency of the sensors. However, the approach cannot detect random anomalies in various physiological parameters.
In [
21], the authors recommended an approach founded on the Markov model to detect anomalies in WBANs. The approach used forecasting data to lower the amount of energy consumed in healthcare facilities. This approach aimed to determine whether a system is operating normally or not. Moreover, when the system is operating abnormally, the approach determines whether the anomalies are psychological. Experimental results revealed that the approach had a low false alarm rate of 5.2% and achieved high detection accuracy. The demerit of the approach came from the fact that Markov models are inappropriate regarding memory and computing time.
In [
22], authors evaluated five machine learning approaches (random forests, local outlier factor, isolation forests, support vector machines, and K-Nearest neighbors) in their ability to detect anomalies in heart rate data. The best results were reported for random forests and local outlier factor approaches, where random forests achieved 100% and the local outlier factor 96.89% of correct rejection rate. Nevertheless, applying machine learning algorithms may have drawbacks since the output depends on the input set to predict; therefore, these algorithms are not effective when dealing with a new pattern of anomalies.
Recently, in [
23], the authors proposed an anomaly detection approach for wearable computing devices (WCDs) to measure the faulty and malicious data that might endanger the patient’s life under monitoring. The approach used data classification methods for four classification algorithms: FURIA, ID3, J48, and PRISM. The four algorithms have obtained different results such that the FURIA outperforms other algorithms with 95.87% of the true-positive rate and 0.5% of the false-positive rate compared to ID3 with 69.9%, J48 with 84.28%, and PRISM with 79.3% true-positive rate.
In [
24], the study conducted a lightweight anomaly detection (LWAD) framework for detecting anomalies in WBAN. The framework was based on distance correlation with a statistical-based improvised dynamic sliding window algorithm for efficient prediction in short-range. The validation of the framework was verified using three real-time datasets. The proposed LWAD obtained a high detection rate of 99.65% for dataset 1 (DS1), 98.75% for DS2, and 98.18% or DS3. The statistical techniques are faster and less complex, but cannot deal with the normal data distribution and the dynamic nature of WBAN.
Based on the above discussion of the existing works, the following subsections analyze them based on two aspects that are the anomaly-related factors, and the used techniques.
- (a)
Anomaly-Related Factors
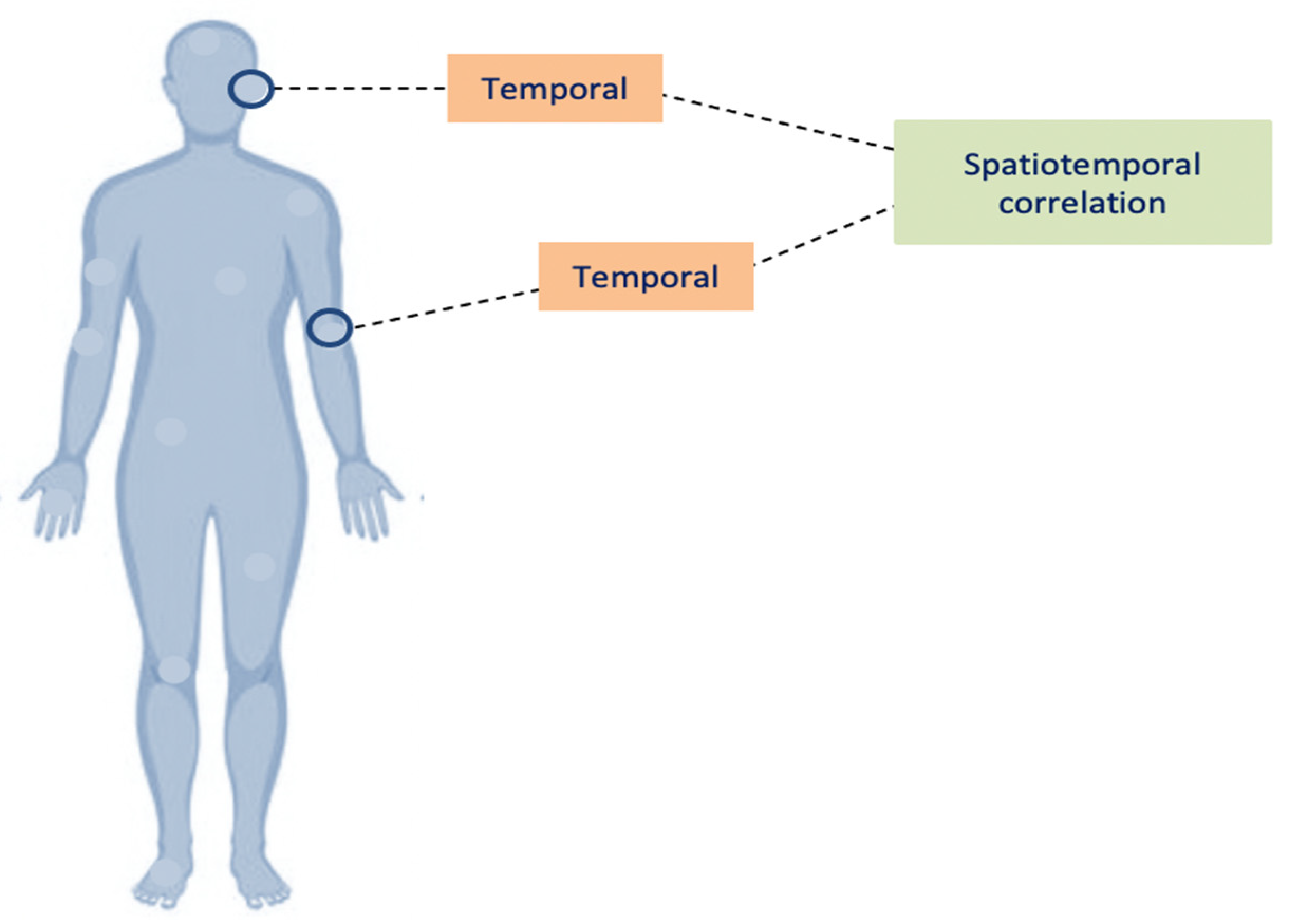
Table 1 summarizes and presents an analysis of existing anomaly detection models for WBAN based on the anomaly type, correlation approach, threshold type, and the consideration of fault measurements. In terms of anomaly type, the point anomaly refers to utilizing individual attributes of the dataset, whereas multiple attributes are considered together in the contextual anomaly approaches. In terms of the correlation approach, temporal correlation corresponds to the readiness of a single node in time instants while the spatial correlation corresponds to the readings of nodes compared with their neighboring nodes [
25]. Two types of thresholds are adopted that are dynamic and static. The dynamic threshold is the prediction of a sensor value based on some historical dataset measurements, while the static threshold is manually selected based on previous knowledge of the field [
3,
26]. Finally, when only one of the attributes is found to be anomalous, the measurement is considered faulty and is therefore known as fault measurement [
16].
Looking at
Table 1, the challenges in the existing techniques can be attributed to the following grounds:
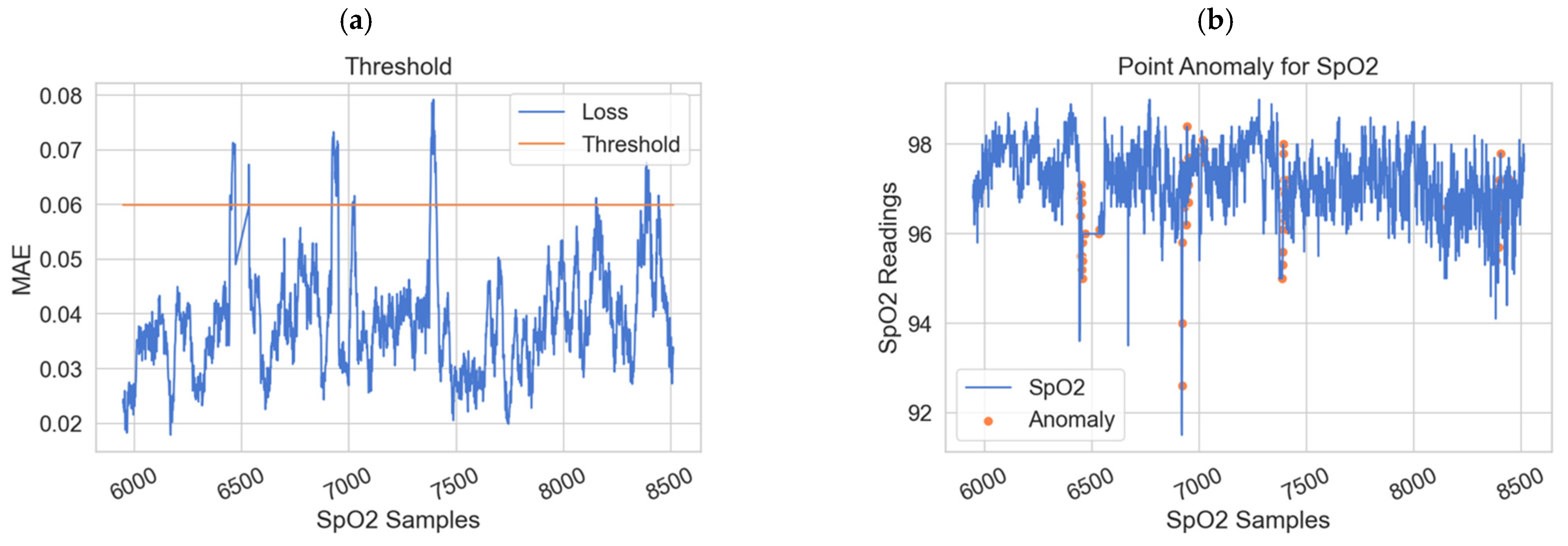
Most existing studies focused on detecting point anomalies in sensor readings to predict the next potential sensor value and compare it to the actual reading. Few studies considered the case of contextual anomaly between various sensor readings.
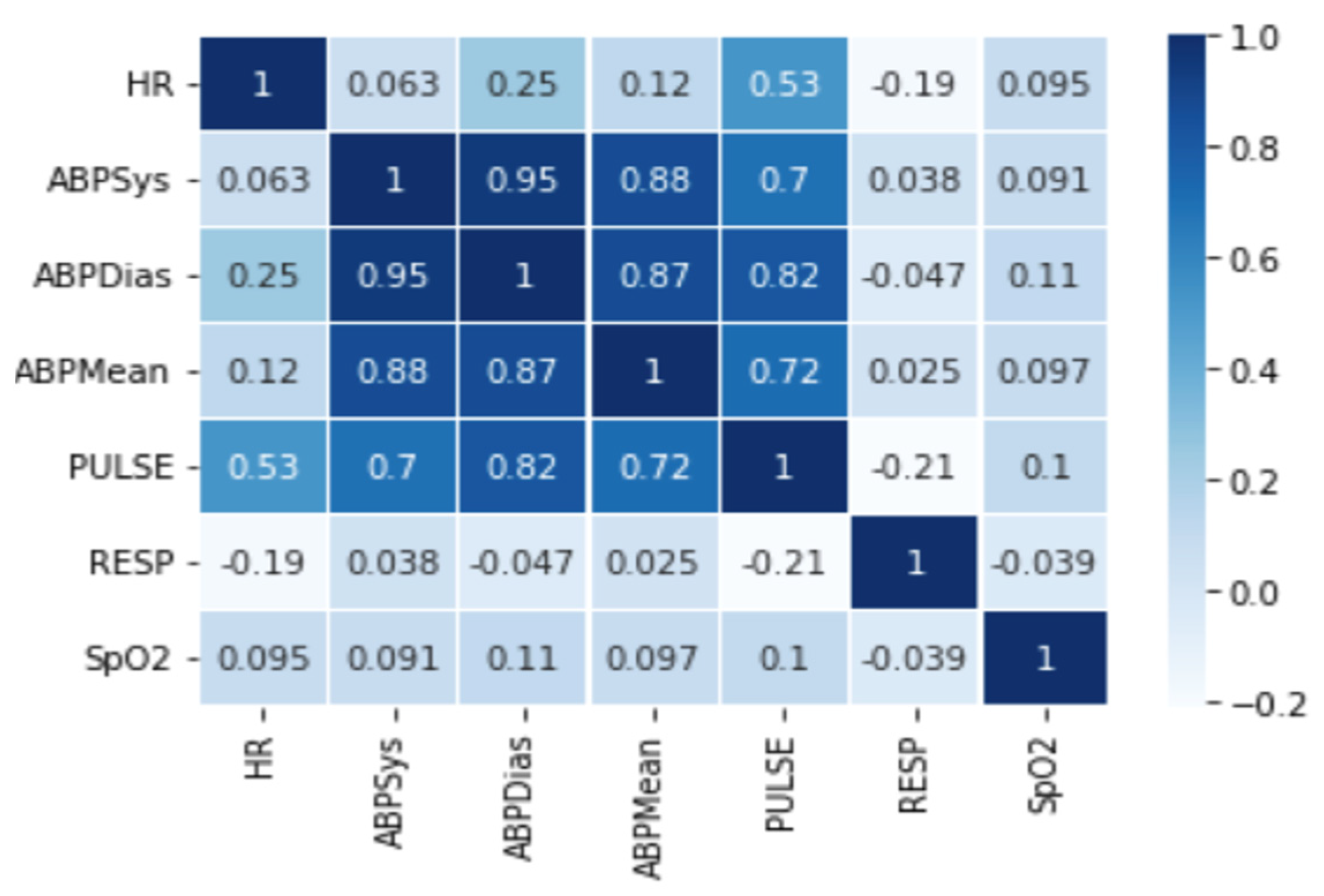
The temporal correlations play an important role in anomaly detection as the various attributes of multi-variant data may show varying temporal correlations. In addition, the attributes are characterized by frequent changes in data distributions with time. Spatial correlations imply that the data values at a particular sensor node are related to the data samples of the neighboring sensors nodes. As shown in
Table 1, most of the previous studies take the correlations separately, either temporal or spatial. The optimal anomaly detection technique must incorporate these correlations to achieve the following types of dependencies (between sensor node characteristics, sensor node readings are dependent on time and their history, and sensor node reading is dependent on its neighboring nodes).
Some existing studies used static thresholds, which may not be sufficient for some reasons; the threshold value of the physiological data is different from one person to another, and it relies on the factors of the person’s lifestyle, age, and medical condition. Therefore, the static threshold will not efficiently work for health monitoring, due to the slow error rate computation and response time. In addition, it is not able to adapt to the continuous changes in medical environments and it requires much effort since it is a manual process. Hence, using dynamic thresholds will be the optimal choice because they calculate value based on the input data (physiological data). Consequently, the value will be appropriate and accurate with WBAN data.
- (b)
Techniques
Sensors are used in different healthcare monitoring applications, and the data are growing extremely. Therefore, several techniques have been proposed in the literature to improve the effectiveness of anomaly detection approaches in WBAN such as statistical or machine learning techniques. However, such techniques have certain limitations. For example, the statistical techniques cannot deal with the dynamic nature of WBAN and it serves to choose the appropriate threshold value for evaluation. In addition, the non-parametric statistical method is not suitable for real-time applications due to its computational burden. Many of the current techniques use machine learning algorithms such as decision tree, linear regression, artificial neural network, nearest neighbor and random forest. The use of machine learning may not be the preferred option in a sensitive domain such as healthcare that requires high accuracy and good performance. These algorithms have certain limitations in dealing with complex and big data, slow computation, and expecting new patterns of anomalies.
To conclude, existing studies have focused on designing techniques for anomaly detection based on correlation with statistical or machine learning, but these techniques are still insufficient to solve the issues. In this domain, detecting an anomaly in the healthcare system requires more effort to understand the nature and importance of the data attributes. Furthermore, a more accurate model that can deal with complex real scenarios is required. In opposition, deep learning is an excellent candidate for overcoming the constraints of the existing techniques mentioned above. Deep learning techniques are capable of learning the inherent data characteristics that distinguish a normal data point from an anomalous one. This approach identifies commonalities in the data and therefore facilitates the detection of anomalies. It is also considered a cost-effective approach for detecting abnormalities because it does not require annotated data for training the algorithms [
27]. Furthermore, the architectures of deep learning models are dynamic, allowing them to adapt to new patterns. Therefore, it has the potential to outperform machine learning and statistical methods in dealing with huge amounts of data collected by sensors in WBAN.
5. Comparison with Existing Deep Learning and Machine Learning Techniques
Comparative experiments have been conducted with the best and the latest candidates of deep learning and machine learning models in the following subsections. The parameters of the deep learning methods used for comparison are presented in
Table 9.
For machine learning methods used in the comparison, a multiclass SVM with linear kernel function, a multiple linear regression, a decision tree with gini criterion, and a random forest with a penalty of 12 was used. For all models, the dataset is split into 70:30 for train and test.
- A.
Deep Learning Techniques
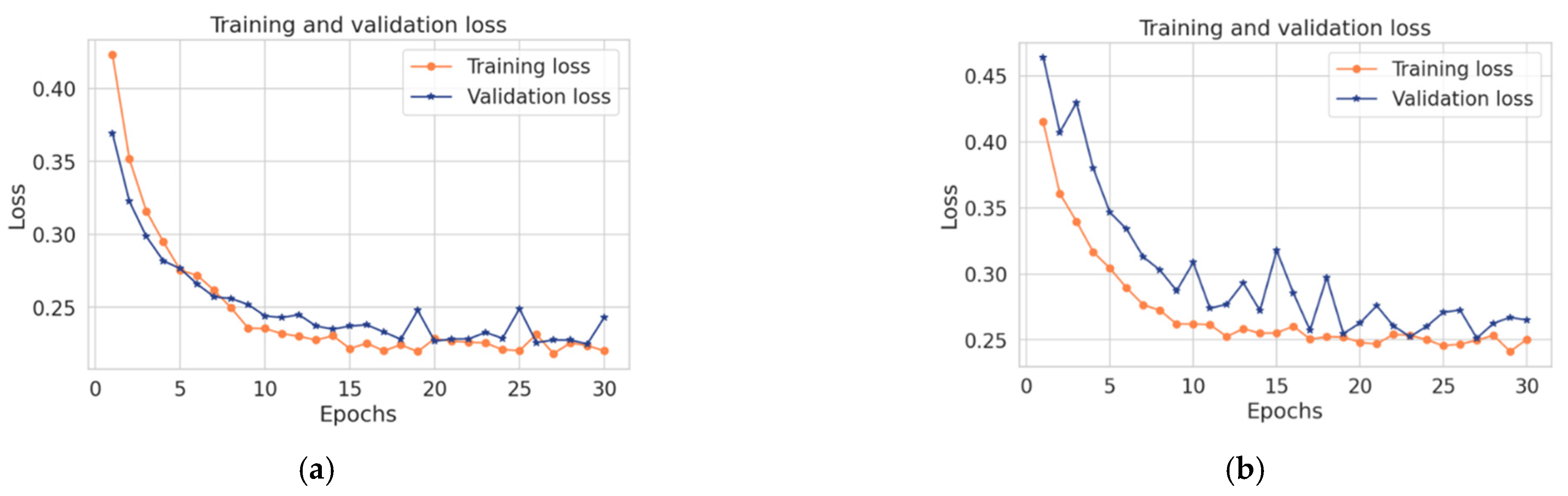
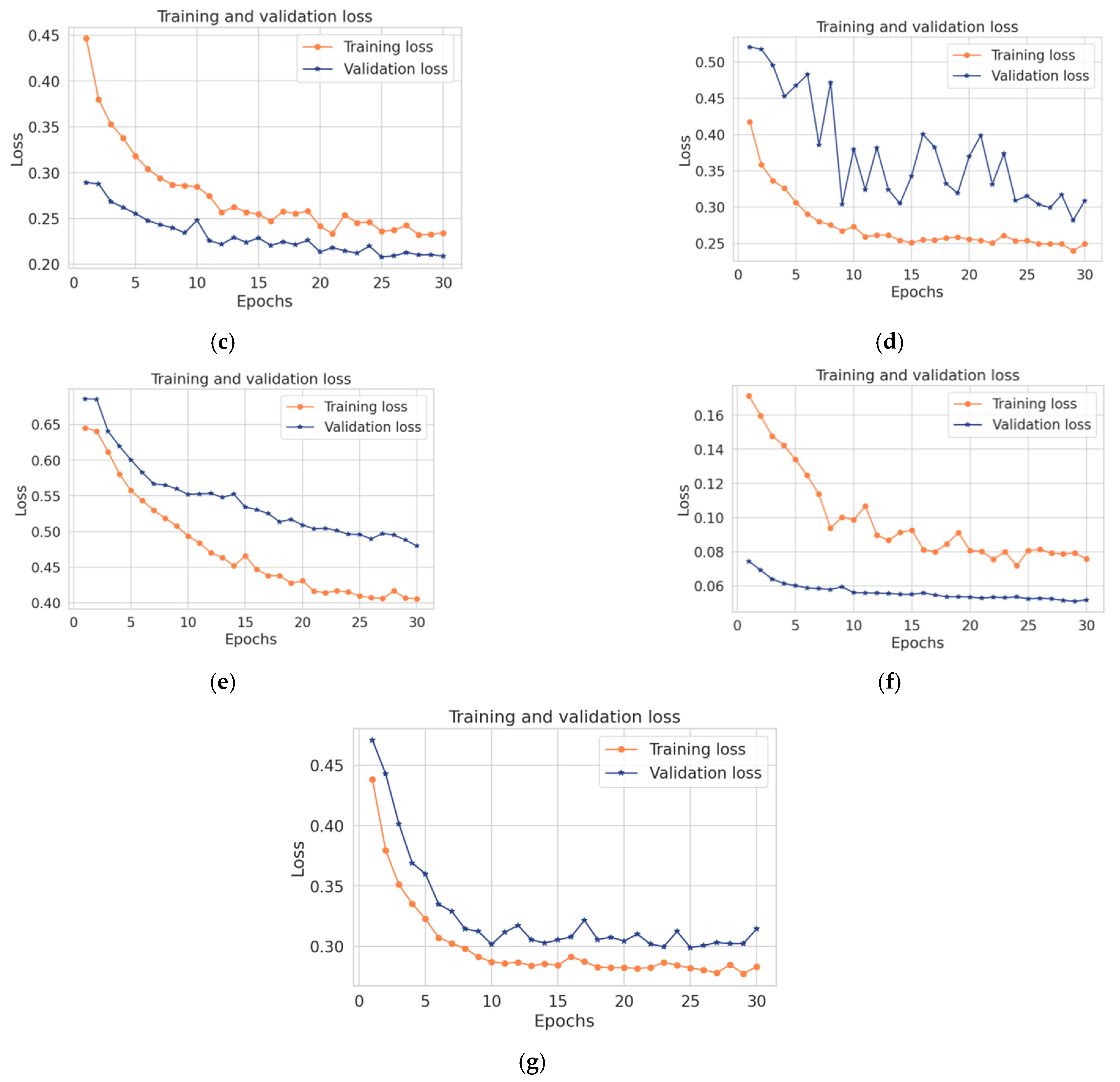
The proposed model in this paper uses a hybrid model that integrates convolutional and LSTM techniques. This section compares the performance of both convolutional and LSTM separately with the proposed model. As shown in
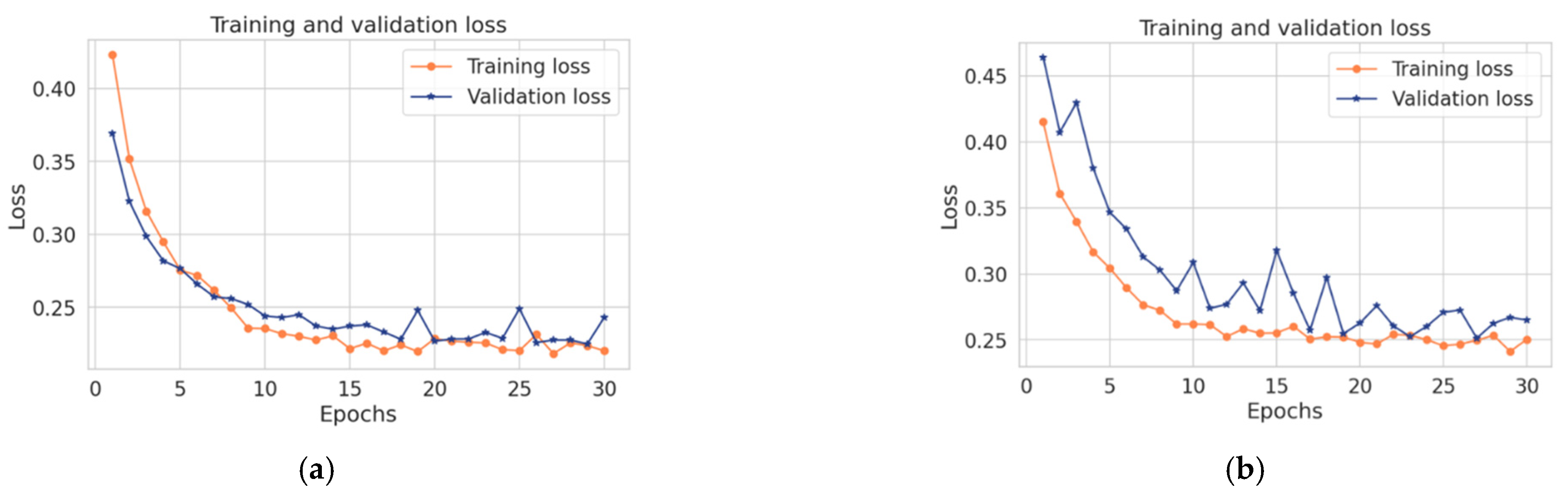
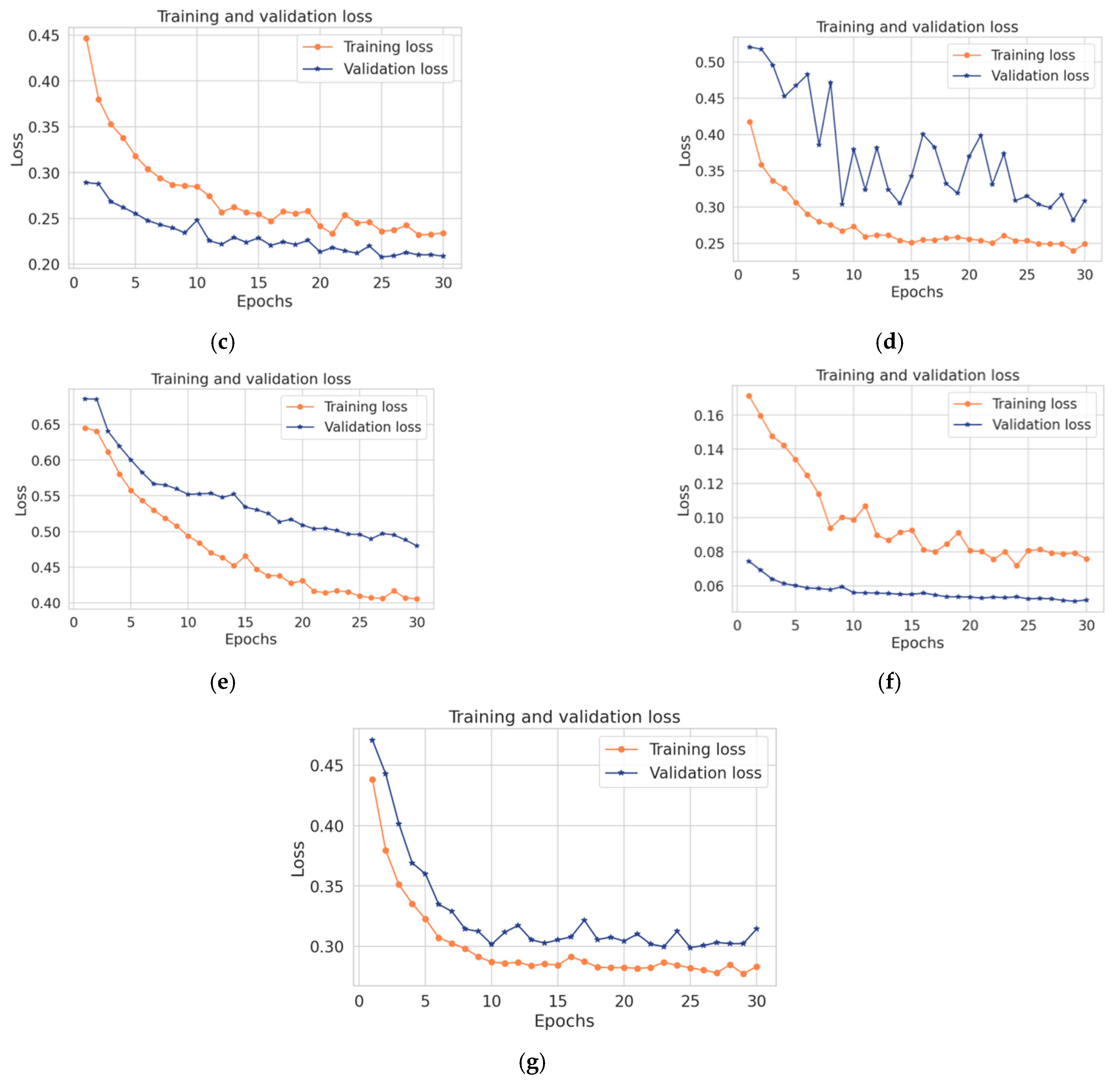
Table 10, the proposed model achieved the best results over convolutional and LSTM, while the convolutional model obtained the lowest accuracy, recall, precision, F1-score, and high loss with less execution time. Likewise, the LSTM model obtained higher accuracy, recall, precision, F1- score, and higher loss with a long execution time. While the hybrid takes the benefits from both LSTM and convolutional, it achieved good results in terms of accuracy, recall, precision, and F1-score within less time. In summary, the combination between the convolutional and the LSTM makes the proposed model more accurate and faster in detecting anomalies in time-series data. Due to the architecture of the convolutional technique that takes benefits from local spatial observations, this allows the model to have fewer weights as some shared data. Consequently, this process makes the model detect the anomaly with high speed. While the cell of LSTM maintains old cell memory at the time, this process helps to understand the behavior of temporal correlations with high accuracy.
- B.
Machine Learning Techniques
In the literature, most anomaly detection studies for WBAN utilized various machine learning models. Therefore, the proposed model will be compared with some existing machine learning models such as Linear Regression (LR), Decision Tree classifier (DT), Random Forest classifier (RF), and Support Vector Machine (SVM) The same random seed is used in the model parameters to ensure that the training data are split in the same way and that each algorithm is evaluated in the same way. The SVM uses a kernel to transform the input data into the required form; the kernel has been called the kernel trick. The reason behind selecting these algorithms is that they are used for classification purposes and are suitable for the dataset pattern.
Table 11 demonstrates the results of these models and it is noted that the decision tree classifier and Random Forest classifier obtained a slightly higher accuracy. Machine learning techniques appear to be not good candidates for detecting the anomaly in light of big data generated by sensors due to the sensitivity to anomalies. For example, in terms of the linear regression technique, the dataset that contains some anomalies can damage the performance of a machine learning model drastically and often lead the model to low accuracy. Any small modification in the dataset can cause a large change in the structure of the decision tree, causing instability. The random forest classifier requires a great deal of time for training as well as much computational power. In addition, the SVM model is not suitable for large datasets. On the contrary, the proposed model, which obtained optimum performance (by improving the accuracy that helps in reducing the false alarm rates) in detecting anomalies, in the context of big data and sensor scalability that makes the healthcare systems more reliable.
To summarize, as shown in
Table 11, deep learning is a great option for overcoming the constraints of machine learning models. It works with several processing layers to learn data representation at various abstraction levels. Because deep learning models’ design is dynamic, they can adapt to new patterns. Additionally, it can efficiently analyze large amounts of data in terms of accuracy, memory, and speed. As a result, it outperforms machine learning on massive amounts of data.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}