1. Introduction
Human action recognition (HAR) has been an active research field to interpret human intentions. HAR studies aim to develop real-world and reliable applications to perceive, study and identify human actions in videos [
1]. The advancement in depth data acquisition hardware technologies such as the ASUS Xtion Pro or the Microsoft Kinect has led to the rise of noticeable HAR research outcomes in both commercial products and studies. Some prominent HAR applications include visual surveillance [
2,
3], human computer interaction [
4,
5], physical rehabilitation [
6], and autonomous driving vehicles [
7].
The simplicity and accuracy of extracting three-dimensional (3D)-skeleton-joints from depth images [
8] have driven our work to focus on 3D-skeleton-joints-based HAR. The research works on 3D-skeleton-joints-based HAR still remains demanding. Current studies consider skeleton-joints human actions as multivariate time-series of five body parts (left arm, right arm, left leg, right leg and a central trunk) and attempt to identify and model the dynamical temporal features in 3D space. Echo State Networks (ESNs) [
9] are such a popular Reservoir Computing (RC) method which is suitable for learning the temporal context. Its simplicity by randomly initializing and fixing the ESN’s input and reservoir weights during training, as compared with backpropagation through time of Recurrent Neural Networks (RNNs), diminishes the computational complexity. Furthermore, short-term memory property which ensures history information of the reservoir is not broadcasted to other neurons too rapidly, makes ESN suitable to capture the dynamical temporal features in HAR. Recently, Ma et al. [
10] proposed an integrated architecture for HAR tasks, the Convolutional Echo State Network (ConvESN), by combining the RC with convolutional deep learning. Owing to ESN multiscale memory, echo state representations (ESRs) of input action series produced by ConvESN contains the history information which make it suitable to characterize and capture temporal dynamics in 3D skeleton series. Additionally, in ConvESN, the Convolutional Neural Network (CNN) [
11] substitutes the linear regression in ESN output layer to understand the complex action echo states. In spite of ESN-based approaches achieved encouraging recognition performance, in this work we have identified three research avenues for our investigation: (1) Despite the random initialization of the ESN’s input and reservoir weights may reduce computational cost, on the other hand, this may rise instability and variance in generalization and hence diminish reproducibility [
12]. In the context of HAR, a stable and reproducible multiscale feature extraction mechanism is needed to guarantee the performance of action recognition, in particular, when 3D skeleton joints are considered as multivariate time-series. Randomly fixed neuron weights may diversify the recognition performance of ESN-based approaches even in performing the same task with the identical set of hyperparameter configurations [
13]. It hardly reproduces the same performance due to the randomized input and reservoir weights in different repeated runs. (2) Building an ESN model requires a set of hyperparameters to be configured. Hyperparameters are external to the model and are commonly tuned based on rule of thumb or empirically fixed via trial-and-error by researchers’ past experiences. Moreover, ESN remains as a black box algorithm. Particularly, it lacks of explainability consideration to understand the input-dependent reservoir dynamics for HAR. Using the explanatory information about the knowledge learned by ESN in tuning the hyperparameters seems to be promising. (3) Following the body of work of ConvESN, it has incorporated modelling dynamics and multiscale temporal feature in a unified framework. However, the model may be very sensitive to the selection of hyperparameters in CNN. Notably, ConvESN implemented Adam [
14] optimizer in which the learning rate monotonically decreases based on the training iteration index. Careful selection of initial learning rate is required to alleviate training traps in local minima. Moreover, finding the optimal set of CNN hyperparameters can become computational costly [
15], particularly, ConvESN implemented manual hyperparameter tuning for CNN stage.
To address these problems, in this work we propose a novel reservoir design approach known as the Self-Organizing Reservoir Network with Explainability (SORN-E) which is characterised by (i) the integration of Adaptive Resonance Theory (ART) [
16] architecture and topology construction based on Instantaneous Topological Mapping (ITM) [
17] for the self-organization of the input weights and reservoir weights, and ii) hyperparameter tuning based on the explainability of self-organizing reservoir through Recurrent Plots (RPs) and Recurrence Quantification Analysis (RQA) technique [
18]. Input-driven and self-organization have been proven to be crucial for the cortex to adapt the neurons in accordance with input topology or distribution [
19]. This previous effort motivates our work to take unsupervised self-organizing learning into account as a potential biologically plausible approach for self-organizing reservoir design. Combining the advantages of ART and ITM, SORN-E has similar network architecture to handle plasticity and stability dilemma and the number of network nodes is not required to be defined prior the learning. The unsupervised learning process of SORN-E is composed of best-matching node selection, vigilance test, and node learning. SORN-E encodes human actions as multivariate time-series signals. It performs unsupervised learning from training dataset to generates a self-organizing clustered topology of nodes which maintains the topological properties of the input at a greatly reduced dimensionality. The generated maps are represented by clustered node centroids and interconnectivity maps. Input samples with sufficiently high similarity are often characterized by a single node or a cluster of nodes.
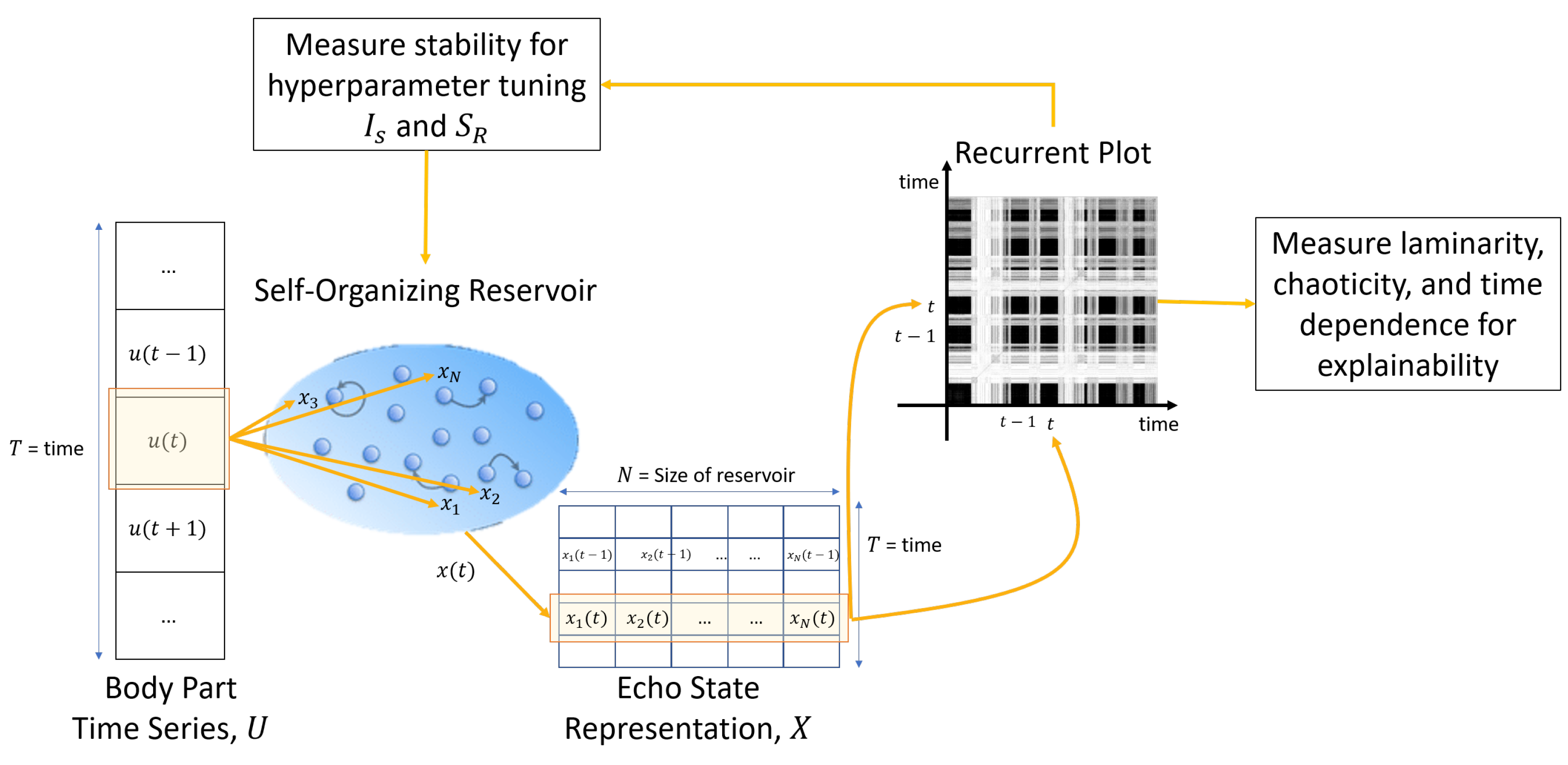
Furthermore, to guarantee stability and echo state property (ESP) [
9], we exploit a state-of-the-art qualitative stability criterion for reservoirs of ESN called maximum diagonal line length,
[
18]. This RQA qualitative metric is used to quantify the reservoir stability. By measuring this metric at different configurations of input scaling (
) and spectral radius (
) of the reservoir, the optimal values for stability can be identified. With the aim to provide explanatory information of the dynamics and improve insights of SORN-E, RPs and RQA are used as descriptive approach to examine the dynamics of self-organizing reservoir and to gain a clear idea of the echo state representations (ESRs).
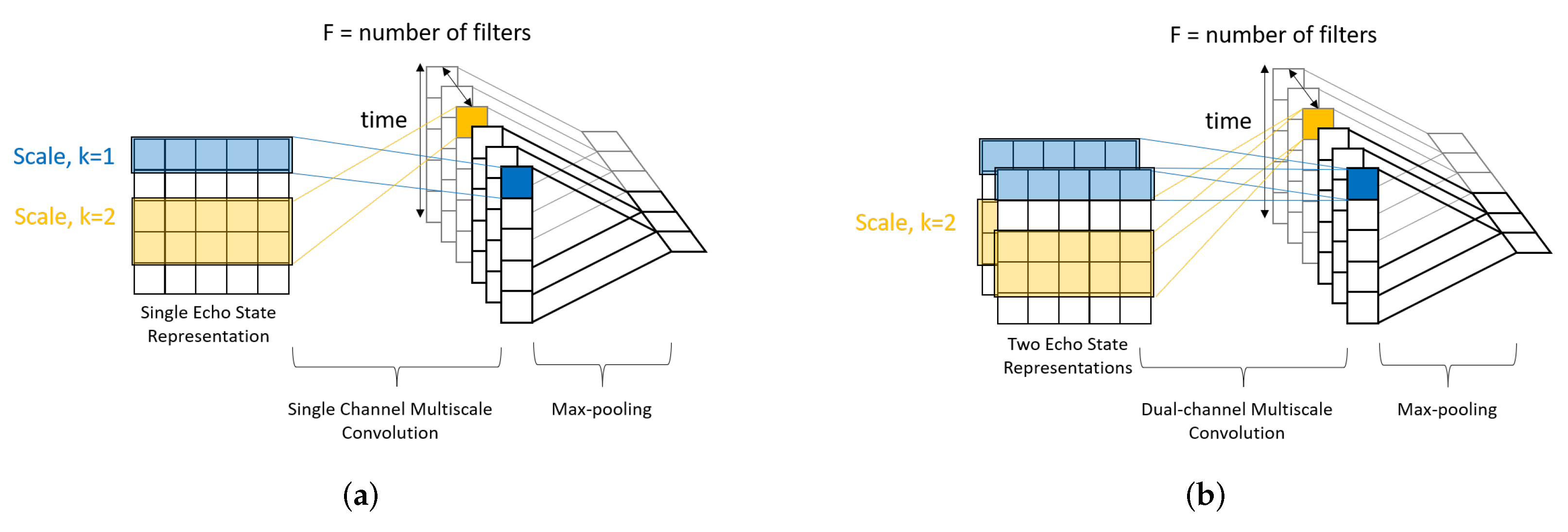
Referring to the body of work of ConvESN, the proposed SORN-E is cascaded with a simple CNN. The feature maps generated by SORN-E are applied to initialize the input weights and recurrent hidden weights in the ESN to yield optimized self-organizing reservoirs. CNN then learns the multiscale temporal features from ESRs for action recognition. This resultant novel implementation is named Self-Organizing Convolutional Echo State Network (SO-ConvESN). With respect to the learning of the CNN stage of the proposed approach, sequential, parallel, sequential-parallel hyperparameter optimization (HPO) algorithms are investigated with the intention of obtaining optimal HAR performance. SO-ConvESN has also been deployed to HAR tasks to demonstrate the feasibility and applicability.
In a nutshell, our main contributions can be summarized as follows:
We propose an unsupervised self-organizing network for learning node centroids and interconnectivity maps which are compatible for the deterministic initialization of ESN reservoir weights. To ensure stability and ESP in a self-organizing reservoir, we further exploit the RQA technique for explainability and characterization of the dynamics of self-organizing reservoir and hence tuning two critical ESN hyperparameters: input scaling () and spectral radius ().
Cascading the stable and optimized self-organizing reservoirs with a simple CNN. Self-organizing reservoir ensures that the activation of ESN internal ESRs echoes similar topological qualities and temporal features of the input time-series and CNN efficiently learns the dynamics and multi-scale temporal features from the ESRs for action recognition.
Adopting three different categories of HPO algorithms, namely Sequential method: Bayesian Optimization (BO) [
20], Parallel method: Asynchronous Successive Halving Algorithm (ASHA) [
21], and Parallel-Sequential method: Population-based Training (PBT) [
22] to search for optimal hypermeters of CNN stage in SO-ConvESN for HAR tasks.
Conducting experiments by using several publicly available 3D-skeleton-based action recognition datasets to examine the explainability of self-organizing reservoirs dynamics, investigate the recognition accuracy of SO-ConvESN and the feasibility of implementing HPOs in SO-ConvESN for the HAR task.
The rest of the paper is organized as follows: Reviews of the related works on ESN-based approaches for 3D-skeleton-based HAR and self-organizing approaches for clustering are first presented followed by the concise descriptions of explainability methods for ESN and HPO for CNN. Next, we describe the development framework of SO-ConvESN and the details of each stage: SORN-E, explainability methods, and HPO. The simulation experiments and results are then presented based on several publicly available benchmarking datasets. Last of all, concluding remarks are presented.
4. Results and Discussion
Intending to demonstrate the capability of the SORN-E in generating stable self-organizing reservoirs and investigate the potential of HPO algorithms for optimizing the recognition performance of the SO-ConvESN, several simulation experiments are conducted using three openly available skeleton-based action recognition benchmark datasets: MSR-Action 3D (MSRA3D) [
57], Florence3D-Action (Florence3D) [
58], and AHA3D [
59]. Each dataset includes a different collection of actions and gestures. AHA3D dataset is merely used for the deployment of the proposed framework for rehabilitation application.
We divide the simulation experiments into several parts. In the first experiments, we present the results in evaluating the feasibility and applicability of the proposed SORN-E to generate stable self-organizing reservoirs. Applying RQA techniques helps to investigate the sensitivity of two crucial hyperparameters of the reservoir and hence select the optimal configurations that ensure stability and ESP. We also aim to achieve more insight into the dynamics and reveal the explainability of the self-organizing reservoir by visualizing the ESRs via RPs and heatmaps.
In addition, the proposed SORN-E is cascaded with a CNN to deal with 3D-skeleton-based action recognition tasks. In the second experiment, we demonstrate the applicability and showcasing of the HPO algorithms in hyperparameter tuning for the CNN of SO-ConvESN. Results of different HPO algorithms are compared and investigated to determine the well-suited HPO algorithm for optimizing the CNN of SO-ConvESN. The last part shows the performance comparison with state-of-the-art approaches and the deployment of SO-ConvESN for HAR application.
4.1. Introduction of Benchmark Datasets
As mentioned before, we adopt three public skeleton-based action recognition benchmark datasets. The first dataset is MSRA3D, composed of 567 sequences with 23,797 skeleton frames recorded at 15 fps with each action performed by ten different subjects 2 or 3 times. It is one of the most famous HAR benchmark datasets used by researchers, which employed Kinect-like sensor to acquire 20 skeleton joints for 20 different activities: high-arm wave, horizontal arm wave, hammer, hand catch, forward punch, high throw, draw X, draw tick, draw a circle, hand clap, two-hand wave, side boxing, bend, forward kick, side kick, jogging, tennis swing, tennis serve, golf swing, and pick-up and throw. Instead of discarding some of the skeleton frames with excessive noise which are missing or corrupted, like in the Refs. [
60,
61], this work uses the entire dataset intending to assess the noise handling capability of the proposed self-organizing learning to generate reservoirs.
The second dataset is Florence3D, composed of 215 sequences with each action performed by ten different subjects two or three times. It used a Kinect sensor to record 15 skeleton joints for nine various activities: wave, drink from a bottle, answer phone, clap, tight lace, sit down, stand up, read watch, and bow. In this dataset, the same action is performed with both left and right hands, and it consists of actions with high similarities, such as drinking from a bottle and answering the phone. This high intraclass variation makes the recognition task more challenging.
The last dataset is AHA3D, composed of 79 different 3D skeletal videos with 171,753 skeleton frames, with each exercise action being performed one to three times by 21 subjects. It used a Kinect sensor to capture 21 skeleton joints for four different standard fitness exercises: 30 s chair stand, 8 ft up and go, two-minute step test, and unipedal stance. Similar to Florence3D, high intraclass variation makes the recognition task more challenging. The same exercises were performed by the mixture of 11 young subjects and ten elderly subjects. Five of the subjects were male, and 16 were female.
Adopting these three datasets during the reservoir design, explainability analysis, and the HPO of CNN, the proposed SORN-E and SO-ConvESN can be efficiently and empirically evaluated and compared with the state-of-the-art HAR approaches.
4.2. Implementation Details
To begin with, we performed preprocessing of all the raw skeletal sequences in all datasets before using the datasets to train and evaluate the SORN-E and SO-ConvESN. Since the origin references of the raw skeleton joints in a given sequence are different from each other, we first transformed the raw skeleton joints into a normalized coordinate system. For each skeleton sequence, we determined the average of the center, left, and right hip joints and set the origin of every frame in the skeleton sequence to this average point. Then, we applied a Savitzky–Golay smoothing filter [
62] to smoothen the normalized skeleton sequences containing different smoothness levels. To ensure each sample to have the same length trajectories, we padded the skeleton sequences up to the maximum length with zeros.
We adopted different training and validation protocols according to the standard proposed in each benchmark dataset to support unbiased comparison with the state-of-the-art performances. In the MSRA3D experiment, we implemented the standard validation protocols as in the Ref. [
57]. We created three sets of training and validation configurations where samples from half of the subjects were used as training dataset, and the balance was used as a validation dataset. Meanwhile, in the Florence3D experiment, ten-fold cross-validation protocols as used by the Ref. [
58] were adopted for the training and validation process. As for AHA3D experiment, we followed the protocol proposed in the Ref. [
59]. We split the available 79 skeletal videos into 39 videos for training, 20 videos for validation, and 20 videos for testing. The performance accuracy was measured and averaged over 100 runs. During performance evaluation and comparison, we employed accuracy as in Equation (
24) as the metric for the context of the HAR problem. Better performance is indicated by a higher value of the computed accuracy.
In term of the implementation of SORN-E, we conducted preliminarily experiment of SORN learning to determine the number of self-organizing reservoir neurons. Even though SORN learning adaptively grows the network size, this work used the number of neurons as stopping criterion to fix the size of the reservoir. Whereas for the implementation of RPs and RQA for reservoir explainability, we adjusted the threshold and ensure for detecting recurrences. For SORN reservoir, the configurations of input scaling, and spectral radius, were tuned by RPs and RQA based techniques and later were fixed to optimal values of ( for Florence3D) and , respectively to ensure stability and ESP for the deployment into SO-ConvESN.
In term of the implementation of HPO algorithms for CNN in SO-ConvESN, we configured the same search space of number of filters, learning rate, batch size for BO, ASHA, and PBT according to the benchmark dataset used. We essentially consolidated the optimization efforts on the learning rate with continuous range. We fixed the convolutional kernel size as 2, 3, and 4 for multiscale feature extraction [
10]. PBT is no well-suited to tune hyperparameters that vary the network architecture. Perturbing these hyperparameters may void the weights inherited from best-performing generation. Hence, we fixed the number of filters to adapt PBT during HPO process.
Table 1,
Table 2 and
Table 3 show the search space setups of the MSRA3D, Florence3D, and AHA3D datasets, respectively.
We ran BO, ASHA, and PBT in this experiment with the same respective configuration across all datasets. The hyperparameters of the CNN were optimized with BO algorithm with the expected improvement (EI) as the acquisition function. This process was repeated for 5 iterations for each run with a total of 25 independent runs. For ASHA, we set reduction factor, to 4, minimum resource, r to 1, maximum resource, R to 64 and minimum early-stopping rate, s to 0. For PBT, we ran HPO with a population size of 10 with five generations. We implemented truncation selection for the exploit stage. During exploration, inherited learning rate were perturbed by either 0.8 or 1.2.
All experimental simulations were conducted in an Intel Core i5-9300H, 2.40 GHz CPU. The algorithms were developed and executed in the Python platform. The time elapsed to produce a self-organizing reservoir by the SORN learning consumed average of 1.6 ms per frame, 1.0 ms per frame, and 3.5 ms per frame for MSRA3D, Florence3D, and AHA3D datasets, respectively.
4.3. Effects of Hyperparameters in Self-Organizing Reservoir Network (SORN)
The effects of the hyperparameters configuration were examined by two benchmark datasets: MSRA3D and Florence3D. The results were obtained by empirically experimenting with different hand tuned settings over multiple SORN learning sessions.
As mentioned earlier, the proposed SORN expands the network size adaptively during the learning process. In order to define the size of the self-organizing reservoir, this work used the user-defined maximum number of neurons as stopping criterion. In addition, the learning cycle was set as of the max number of nodes. It implies that the pruning process will be regularly performed for every iteration reaching of the predefined maximum number of nodes. Preliminary experiments showed that as long as the number of reservoir neurons is set to at least three times the input dimension, the reservoir possesses sufficient complexity to capture and hold the information of the input samples. Considering the length of one body part with three skeleton joints, each of them has three coordinate values, contributing to an input length of nine features. Hence, throughout the simulations, we fixed the number of neurons at 36 for MSRA3D. For Florence3D, we set the number of neurons at 27. For AHA3D, we set the number of neurons at 50. Arbitrarily setting the learning rate showed no noticeable impact on the performance. We fixed it at to a moderate learning rate during the update of winner nodes.
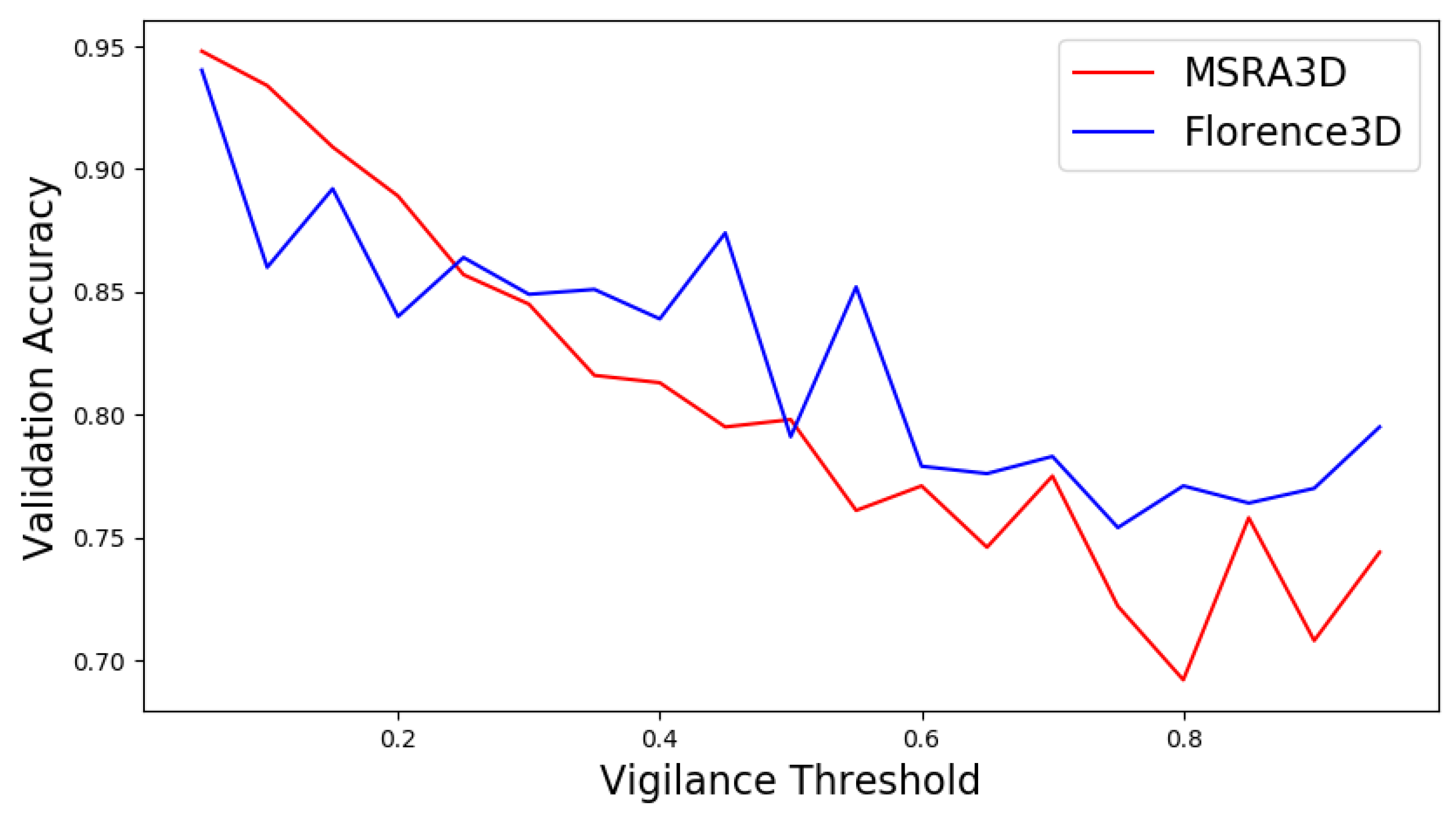
In terms of the vigilance threshold and reservoir perturbation of SORN, we conducted different training sessions by using a range of values and insert the generated self-organizing reservoirs into SO-ConvESN for HAR tasks using only MSRA3D and Florence3D. We manually tuned the vigilance threshold for a range from
to
, and the initial noise distribution scales at 0,
,
, and
to observe the SORN in performing clustering for HAR task. As shown in
Figure 7, the results show that configuring the vigilance threshold to
produced optimal clustering by SORN. Compared to other configurations, setting the vigilance threshold to a low value resulted in the highest validation accuracy in both MSRA3D and Florence3D datasets. Whereas configuring the noise perturbation at
, SO-ConvESN outperformed the noise-less version, and the results showed no noticeable impact for the magnitudes set at
and
.
The results suggest that setting the vigilance threshold at low value is essentially to produce self-organizing clustered topology of nodes with high-granularity. These clusters at a significantly reduced dimensionality can efficiently represent the topological properties of the complete set of input skeleton joint samples. Besides, implementing a tunable noise perturbation as in Equation (
1) to control the amount of the initial noise to be added to the input sample before SORN learning offers adjustment for fast convergence clustering [
54]. Configuring the noise perturbation to 0.1 enabled SORN-generated self-organizing reservoirs unlocked better performance of the SO-ConvESN.
4.4. RQA-Based Hyperparameter Tuning for Self-Organizing Reservoirs
These additional experiments demonstrate the applicability of the proposed SORN-E to adjust the spectral radius, and the input scaling, in generating reservoirs that are stable yet satisfied ESP. We conducted the simulation experiments by using both MSRA3D and Florence3D datasets. As described previously, we divided the hyperparameter tuning process into two stages.
In the first stage, we fixed the spectral radius,
at a constant boundary value of
on the basis of the previous study showing that this value ensures the ESP [
9,
10]. We then generated ESR and measured
that indicates the degree of quantified reservoir stability based on Equation (
20) against the variation of the input scaling,
. A higher value of the
represents a more stable configuration of input scaling. We hand tuned the input scaling for a range from
to
and measure the respective
. We repeated the measurements using MSRA3D and Florence3D datasets. The measured values of
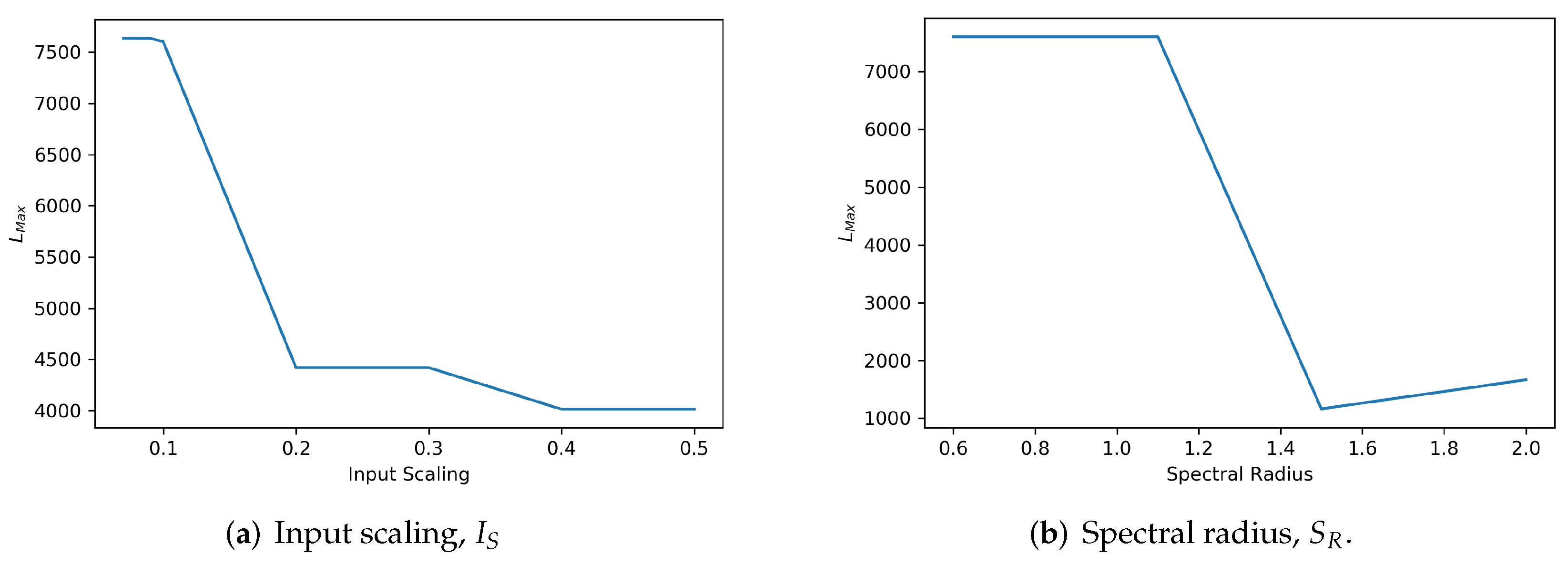
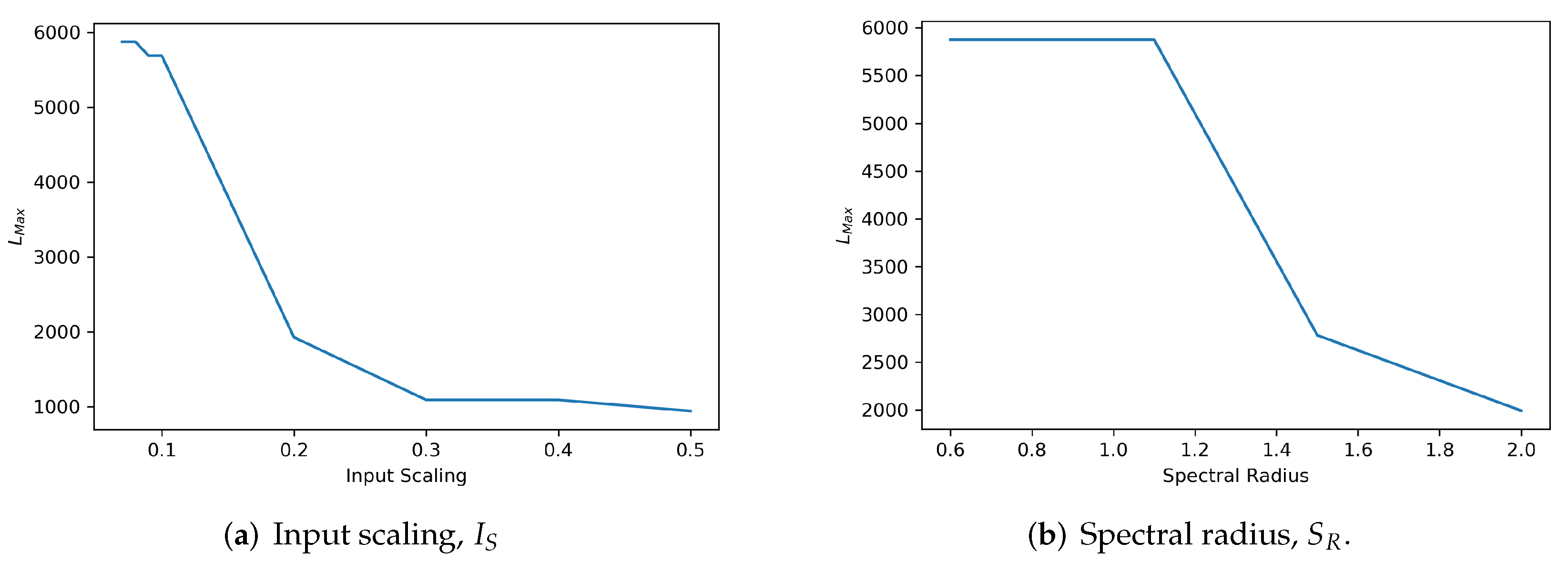
against the different input scaling settings are depicted in
Figure 8a and
Figure 9a, respectively. Setting input scaling at a range less than or equal to 0.1 for the MSRA3D dataset and less than or equal to
for the Florence3D dataset shows optimal stability in which
stays at the highest value.
In the second stage, we applied the optimal value determined in the previous step and fixed the input scaling. We then repeated the measurement of
against the adjustment of the spectral radius,
. In particular, we investigated the stability of the self-organizing reservoir when violating ESP, which is setting
to be greater than unity. Similarly, the value of the highest
indicates the optimal configuration of
for a stable self-organizing reservoir. The measured values of
against the different spectral radius settings for MSRA3D and Florence3D datasets are depicted in
Figure 8b and
Figure 9b, respectively. Interestingly, setting
to be slightly greater than unity to violate ESP, self-organizing reservoir stays stable but only sustains up to a certain extend. In both MSRA3D and Florence3D scenarios, the results prove that setting spectral radius less than unity guarantees ESP and ensures stability.
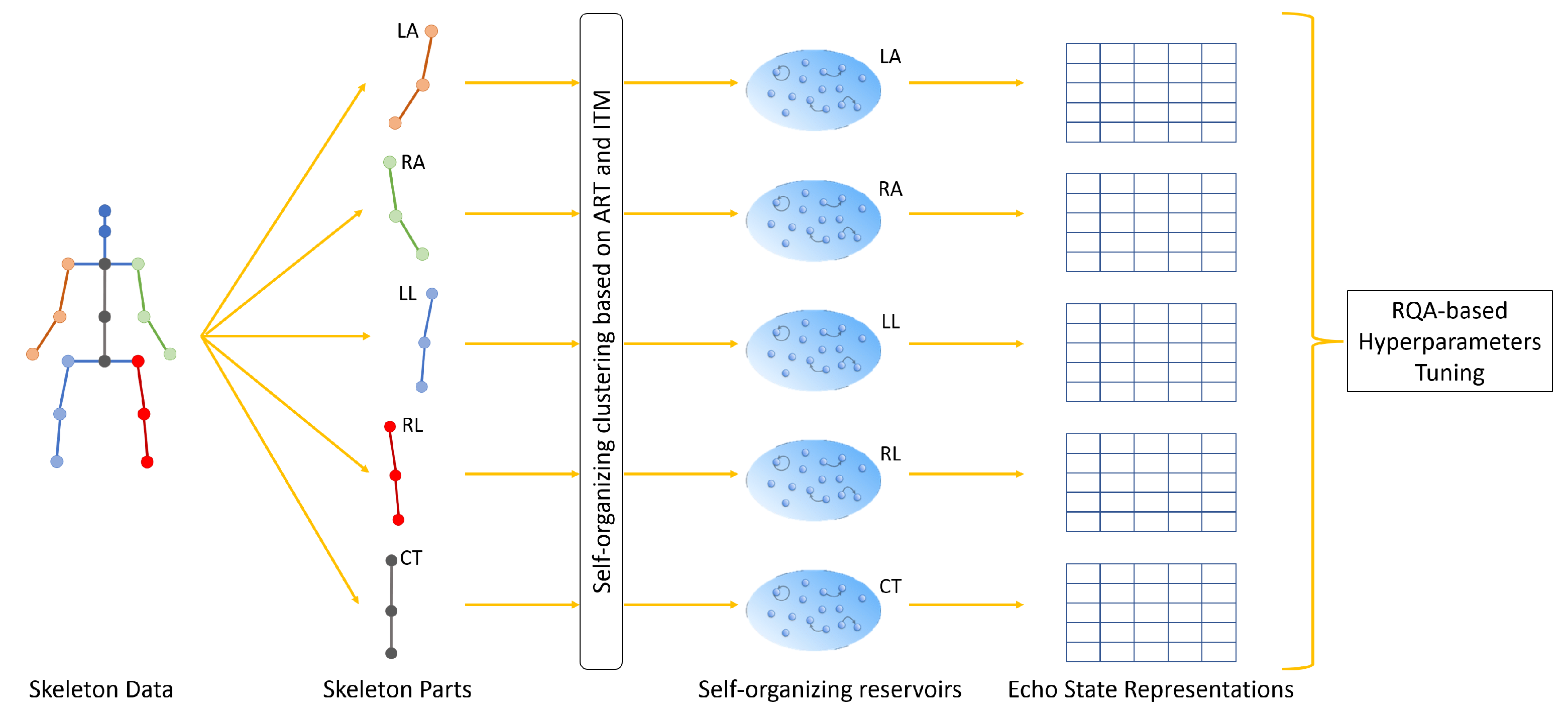
We have applied the proposed SORN-E in generating stable self-organizing reservoirs for all five channels in correspondence to five body parts of the skeleton joints. For simplicity, this section solely showed the results of a single channel self-organizing reservoir. Based on the findings of this experiment, both chosen spectral radius and input scaling affects the stability of the reservoirs. The proposed SORN-E is feasible and applicable to guarantee optimal configuration of and for stable reservoir and the satisfaction of ESP. We demonstrated the applicability and showcasing of the RQA technique in designing stable self-organizing reservoir. Explainability of the metric essentially quantifies the reservoir stability and is one of the helpful tools to guide the reservoir design, especially tuning the hyperparameters. In a nutshell, the proposed SORN-E is capable of generating optimized self-organizing reservoirs that are stable and yet fulfilled ESP.
4.5. Comparison between the Self-Organizing Reservoirs and Randomly Initialized Reservoirs Based on Explainability
In the following, we considered that the proposed SORN-E had generated stable self-organizing reservoirs as described previously. We applied the same hyperparameter configuration to generate randomly initialized reservoirs. We compared the self-organizing reservoirs and randomly initialized reservoirs by quantifying the reservoir dynamics via RQA metrics and the visualization of the RPs of ESRs.
We measured RQA metrics and visualized the RPs of ESRs produced by the reservoirs using the MSRA3D and Florence datasets. We aimed to reveal the explainability of the reservoir dynamics for the context of HAR. We focused on three essential classes of reservoir dynamics: laminarity, time dependence, and chaoticity.
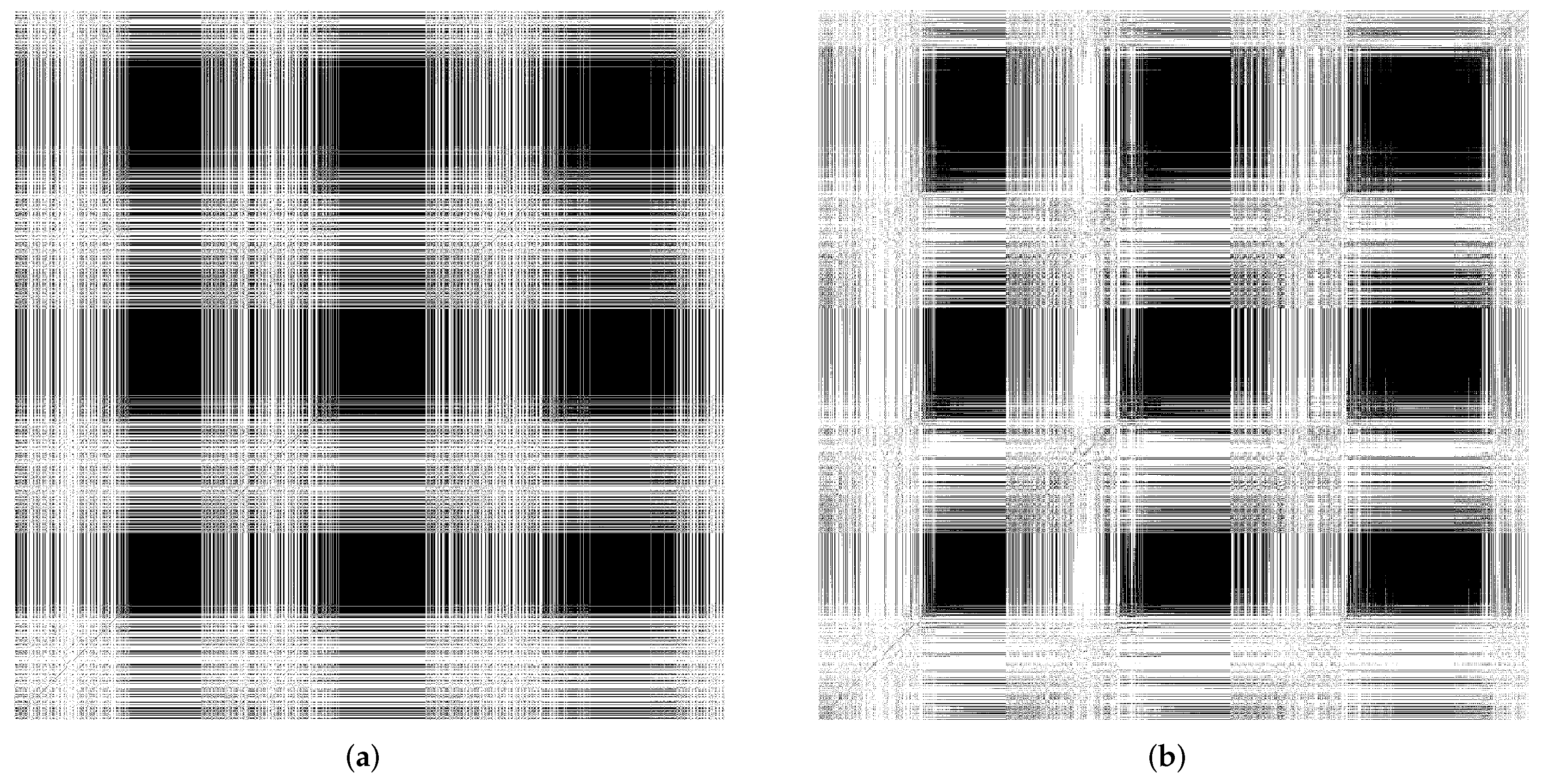
Figure 10a,b depict the recurrent plots generated using the MSRA3D dataset.
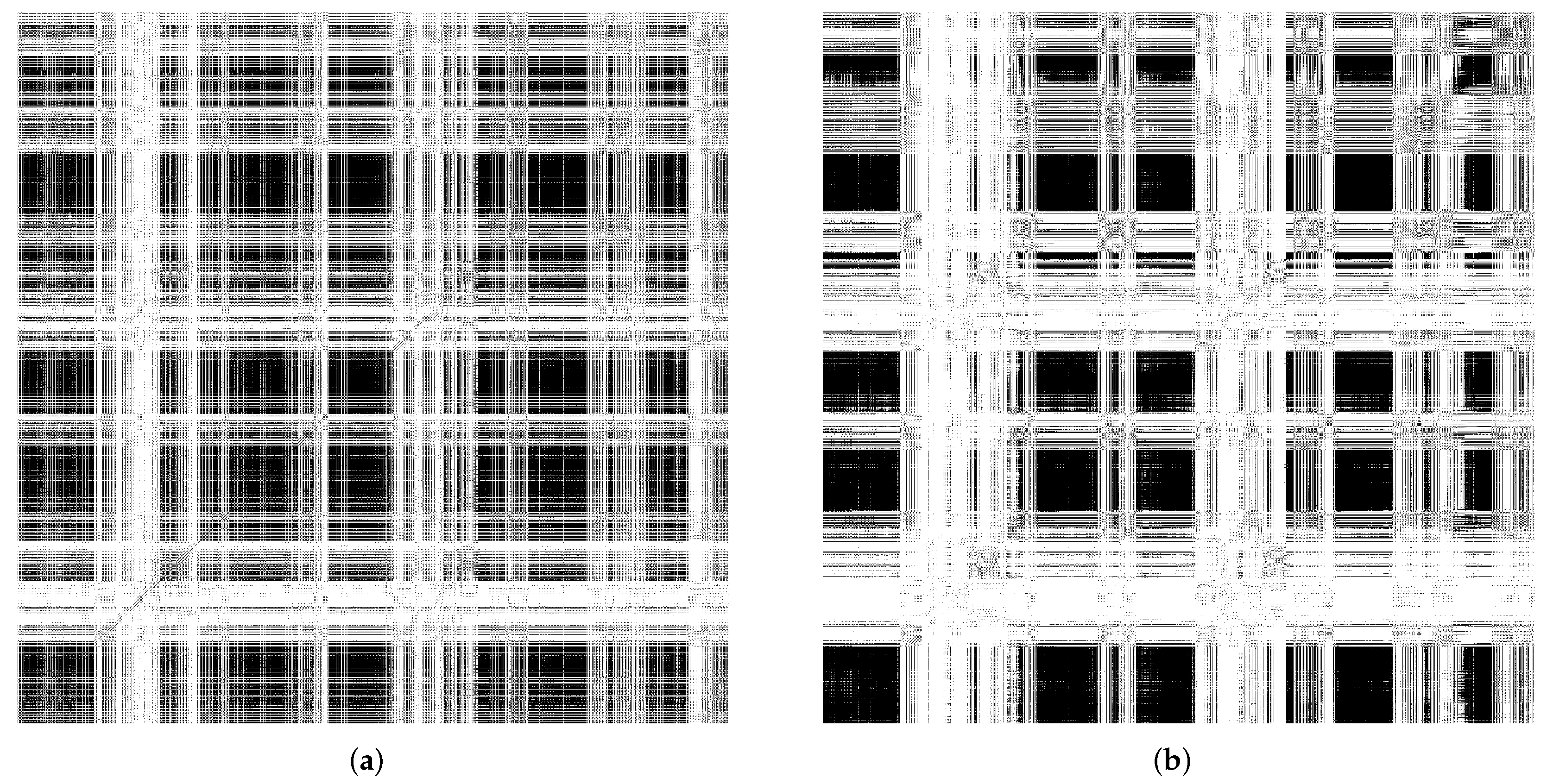
Figure 11a,b depict the recurrent plots generated using the Florence3D dataset. We had discovered similar findings of all five channels of action sequences. For visualization simplicity, we merely included the RPs of a single channel.
Comparing the stability measure via , self-organizing reservoir scores higher values at 7601 and 5874 in MSRA3D and Florence3D datasets, respectively as compared to randomly initialized reservoir. In terms of laminarity, the RPs of both self-organizing reservoir and randomly initialized reservoir shows that echo state varies very gradually over a number of adjacent time steps which can be observed by the presence of large black rectangles. In both MSRA3D and Florence3D, RPs visualizes the existence of laminarity. Comparing the measure , self-organizing reservoir scores higher values at 0.999905 and 0.999980 in MSRA3D and Florence3D dataset, respectively as compared to randomly initialized reservoir. Besides, the RPs are non-uniformly distributed that visualize the time dependence dynamics. It means both reservoirs have captured the correlation of the action sequences. Self-organizing reservoir has superiority in capturing time dependency which can be observed by the measured which is closer to 1 as compared to randomly initialized reservoir in both datasets. The measured of self-organizing is also closer to 1 which indicates lesser chaoticity than the randomly initialized reservoir.
Based on the experimental findings, the proposed SORN-E has successfully generated self-organizing reservoirs that are more stable, pose a higher laminarity phase, higher time dependence, and lesser chaoticity. The self-organizing reservoirs have significantly preserved these essential signature dynamics for HAR, which can be understood via the explanatory information extracted from ESRs. Applying SORN-E for deterministic initialization on the ESN’s weight not only ensures stability and ESP, but self-organization also ensures the action sequences’ dynamics are better reflected and captured by the reservoir neuron activations. The SORN-E can be considered one feasible and biologically plausible self-organizing reservoir design approach, notably, encode human actions’ temporal feature for HAR.
4.6. Comparison between the Self-Organizing Reservoirs and Randomly Initialized Reservoirs Based on Reproducibility
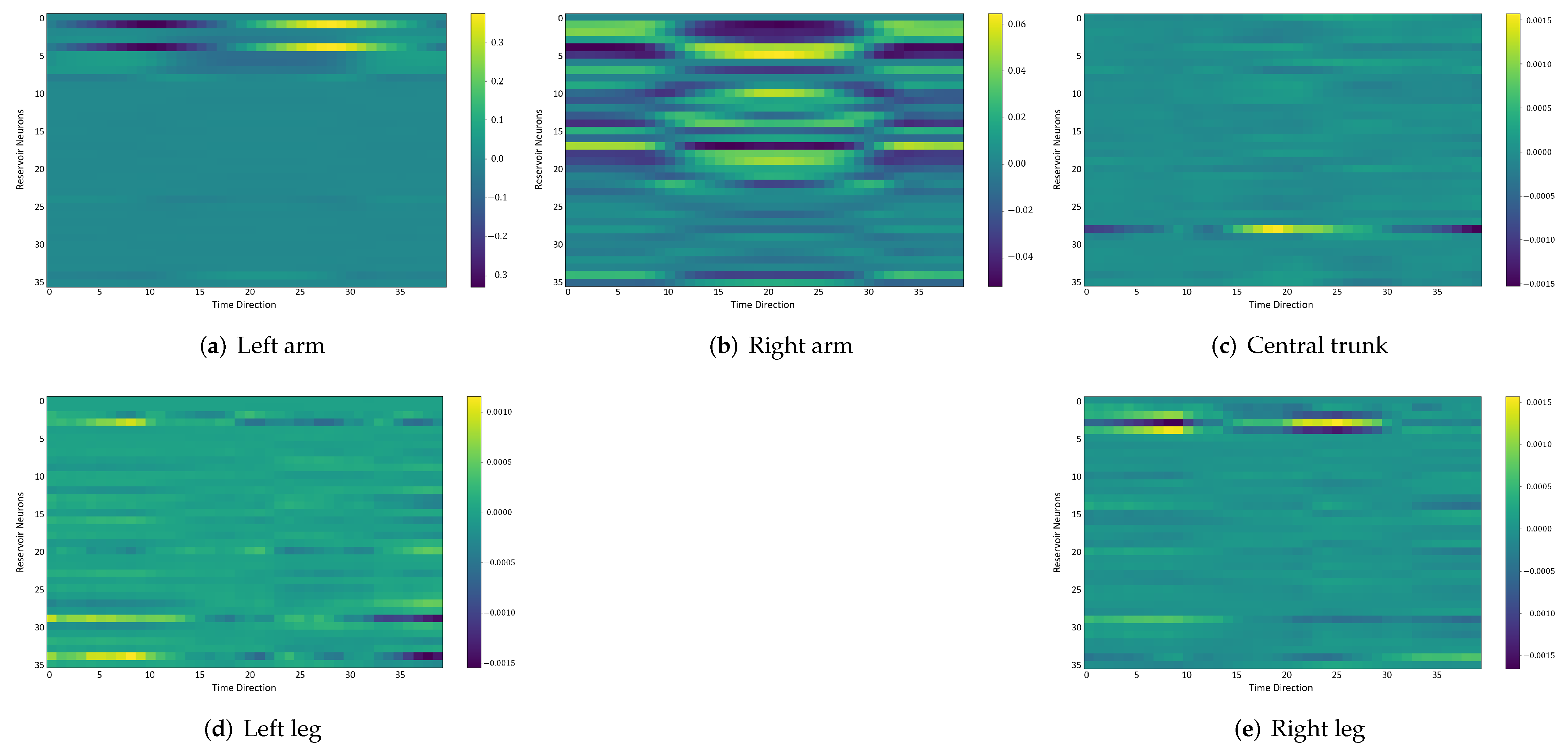
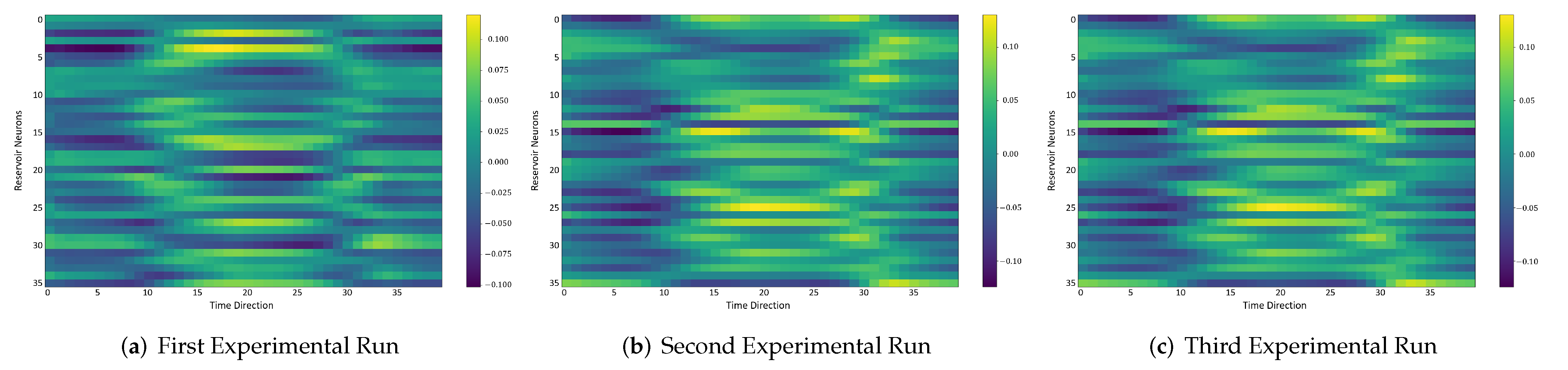
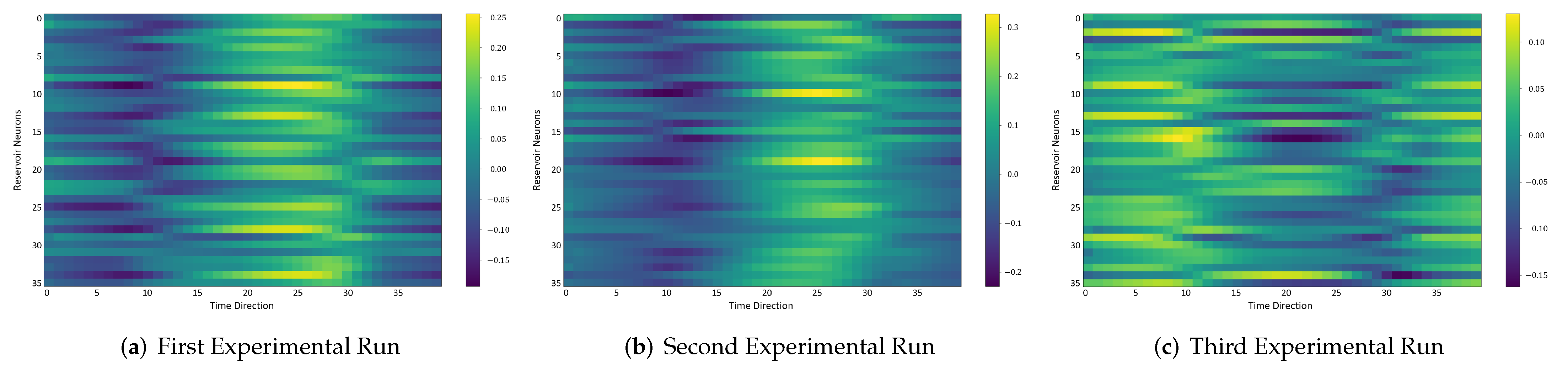
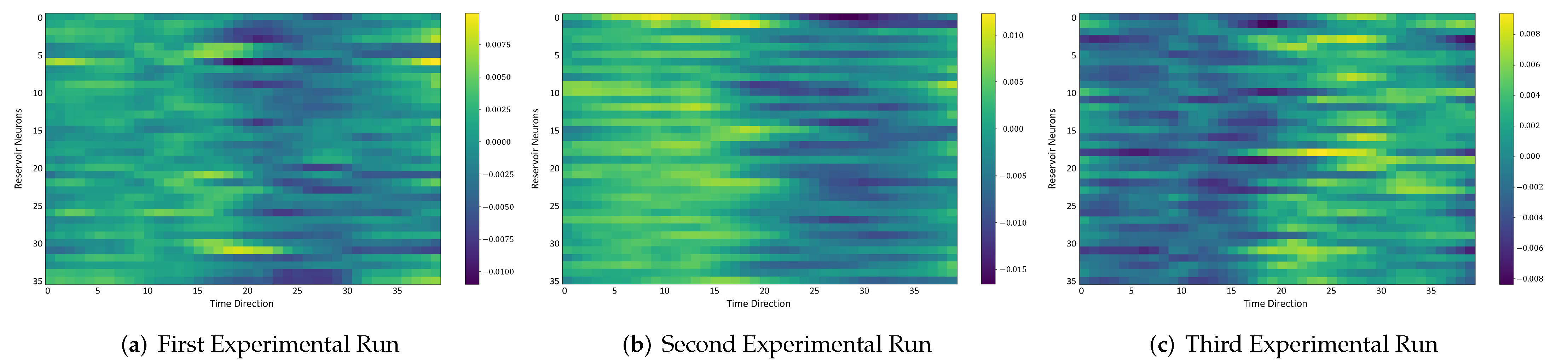
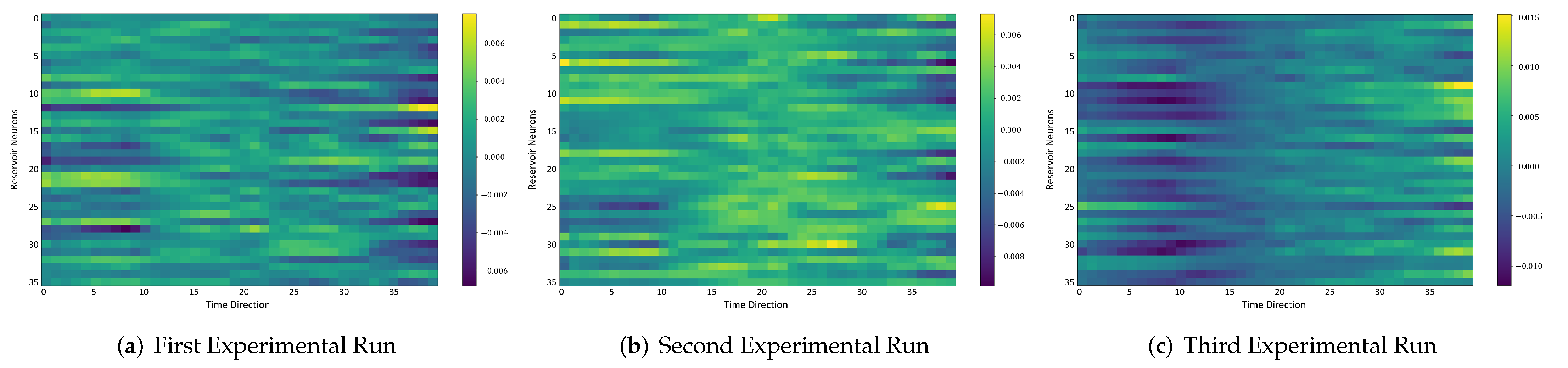
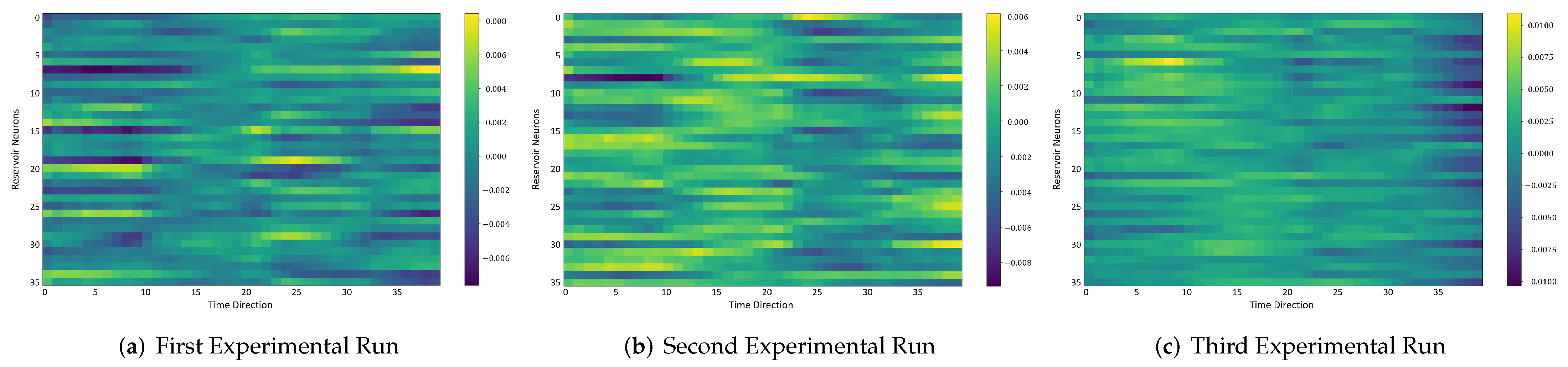
In the following, we additionally presented the visualization of ESRs using the MSRA3D dataset. We aimed to investigate the reproducibility of the self-organizing reservoirs generated by SORN-E. For simplicity, we visualized the heatmaps for ESRs of the left arm, right arm, central trunk, left leg, and right leg trajectories of a person performing two-hand waving. We projected this same action input sequence of 40 frames onto the ESN reservoirs to repeat three different trial runs independently.
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16 and
Figure 17 show the heatmaps of the ESRs for self-organizing reservoirs and randomly initialized reservoirs, respectively.
The visualizations of ESRs show that a self-organizing reservoir reproduces the same heat maps for the identical action sequences in different runs. Conversely, randomly initialized reservoirs produce different ESRs in separate runs. The generated ESRs do not show regular neuron activations behaviors. It is interesting to note that the neuron activations of the self-organizing reservoir along the time length are highly specific. Only a particular group of signature neurons are activated at a time. This group of neurons relevant to a particular part of the body exhibit higher activations at any one time. Whereas for randomly initialized reservoirs, the behaviors are unpredictable and act stochastically. Randomly initialized reservoir failed to reproduce same ESRs in different runs. Moreover, the activations of the neurons do not show any sign of body part relevancy. In other words, randomly initialized reservoirs hardly achieve reproducibility even using the same set of hyperparameter configurations.
Based on the findings of the visualization experiments, SORN-E generates self-organizing reservoirs that preserve the reproducibility for the same input action sequence due to its deterministic initialization of the ESN’s reservoirs. Additionally, a particular body part explicitly activates a specific group of neurons during an action. This finding shows that neurons of the self-organizing reservoirs could be task-specific neurons. This result may also justify that SORN-E produces self-organizing reservoirs that follow the biological mechanism of adaptation of neuron excitability.
4.7. Optimizing the Performance of SO-ConvESN
As highlighted earlier, we cascaded the optimal self-organizing reservoir generated by SORN-E with a simple CNN to yield the SO-ConvESN. In this section, to ensure optimal HAR performance, we implemented BO, AHSA, and PBT algorithms to optimize the HAR accuracy and compared the results of different HPO techniques for the CNN stage that performs the multiscale convolutional process in SO-ConvESN using the MSRA3D and Florence datasets. We also included the baseline SO-ConvESN hand-tuned manually to explore the optimal number of kernels in CNN by specifying the scales from 16 to 256 and the learning rate from 0.001 and 0.003.
Table 4 depicts the HAR results achieved by the implemented HPO algorithms.
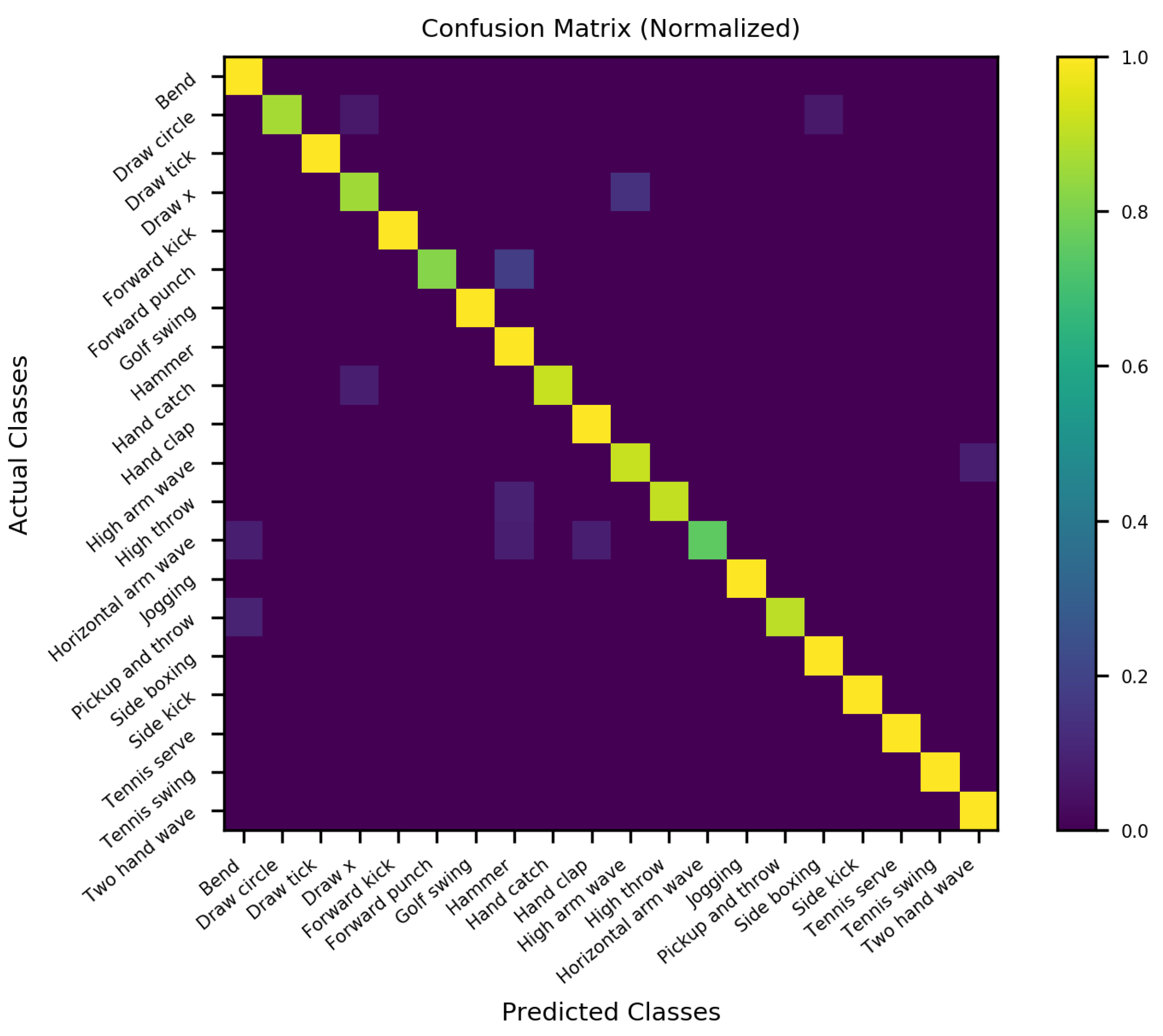
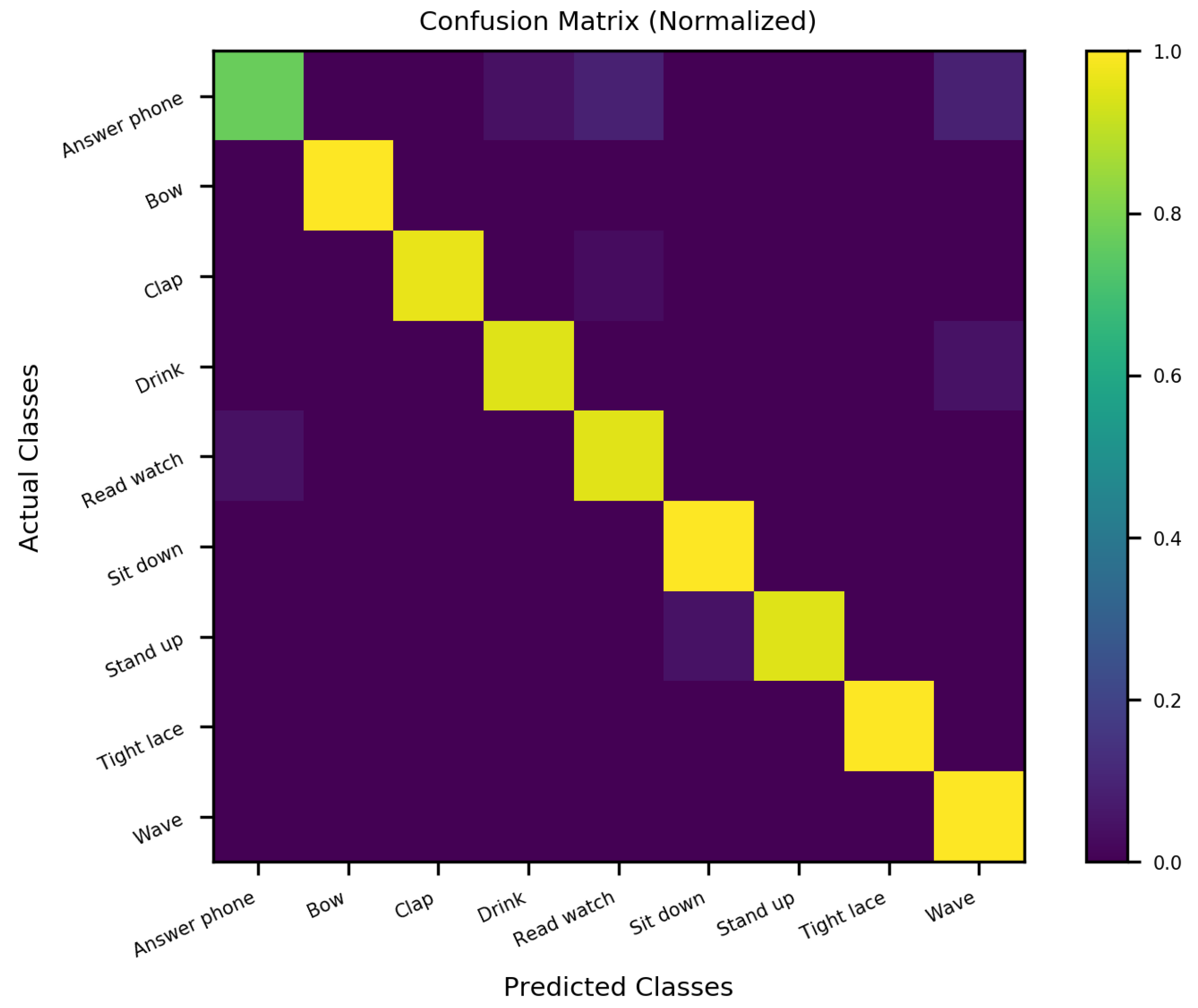
Figure 18 and
Figure 19 show the normalized confusion matrices of the recognition accuracy achieved by SO-ConvESN-ASHA for MSRA3D dataset and Florence3D dataset, respectively.
We demonstrate the applicability and showcasing of the HPO algorithms in hyperparameter tuning of CNN in SO-ConvESN to justify that HPO is required to further improve the recognition accuracy in the baseline SO-ConvESN. Based on the experimental observations, all implemented HPO algorithms have improved the recognition accuracy of SO-ConvESN. In MSRA3D models, as compared to the baseline performance, BO improved the accuracy by 0.63%, ASHA achieved improvement of 0.93%, and PBT showed 0.30% better accuracy. Whereas in the Florence3D models, BO showed 4.83% improvement, ASHA achieved 7.10% improved accuracy, and PBT improved the performance by 2.47%. The ASHA significantly showed the best accuracy improvement in optimizing SO-ConvESN in both datasets, whereas BO outperformed PBT in both experiments.
The results demonstrate the effectiveness of ASHA in optimizing the proposed SO-ConvESN for HAR. The inherently sequential optimization of BO makes this method unsuitable for optimizing CNN in SO-ConvESN. For PBT, it could be due to the nature of hyperparameters that variances in the network architecture needs to be fixed. Manual setting of the number of filters in this experiment may degrade the optimization effect when applying PBT. It is also interesting to note that the recognition accuracy in MSRA3D experiments using either of the HPO algorithms exhibit a smaller factor of improvement as compared to Florence3D experiments. We inferred that including the noisy data from the MSRA3D dataset during SORN learning seems to be challenging for SO-ConvESN. We developed the SORN learning based on the ART model. It could be potentially sensitive to noise and makes the SORN-E unable to tolerate unmanageable, noisy MSRA3D data.
In the next section, we further compared the performances of the optimized SO-ConvESNs with the existing HAR approaches using the MSRA3D and Florence datasets. We abbreviated the SO-ConvESN optimized by BO, ASHA, and PBT as SO-ConvESN-BO, SO-ConvESN-ASHA, and SO-ConvESN-PBT, respectively.
Table 5 and
Table 6 tabulate the state-of-the-art HAR performance of cross-subject test on MSRA3D dataset and cross-validation on the Florence3D dataset.
For MSRA3D experiment, even our best-performing SO-ConvESN, that was optimized with ASHA, exhibited 95.09% overall accuracy. Compared to ConvESN, all of optimized SO-ConvESNs shows lower accuracy. The MSRA3D dataset could be a challenging dataset to SO-ConvESN. In particular, many actions are similar to each other, such as the “draw circle” action which was frequently misinterpreted as the “side boxing” action. Noisy data appearing in the MSRA3D dataset also make the noise-sensitive SORN-E fail to cope. However, considering SORN-E ensures stability and ESP in the self-organizing reservoir, reproducibility is more promising than the randomly initialized reservoir in ConvESN. For the Florence3D experiment, SO-ConvESNs outperformed ConvESN. Our best-performing SO-ConvESN, that was optimized with ASHA, exhibited 96.07% overall accuracy. SORN-E could be good at clustering data with low noise and a small number of action classes, as in Florence3D datasets.
Simulation experiments show that our proposed SO-ConvESN achieves competitive HAR performance with respect to the state-of-the-art approaches. The SORN-E considers self-organization inspired by cortex neuron adjustment mechanism and explainability for tuning ESN’s hyperparameters during the learning of reservoir weights ensures the stable self-organizing reservoirs capture the dynamics and topological properties of the input action sequences. The findings also show that the HPO algorithms are necessary to warrant improved recognition accuracy. The SO-ConvESN can be considered as one feasible and biologically plausible self-organizing reservoir design approach for the HAR problem.
4.8. Deployment of SO-ConvESN for Rehabilitation Application
Previous experimental studies have proven the applicability of the proposed SORN-E to generate stable self-organizing reservoirs, and yet satisfied ESP. Integrating SORN-E with a simple CNN has also been optimized via HPO algorithms to yield optimized SO-ConESN. Considering the outperformance of SO-ConvESN optimized by the ASHA, in this section, we demonstrate the deployment of the proposed approach for an assisted living-oriented performance assessment. We aimed to demonstrate the potential and usefulness of the SO-ConvESN-ASHA in an empirical application that recognizes physical fitness exercises for the elderly rehabilitation application using the AHA3D dataset.
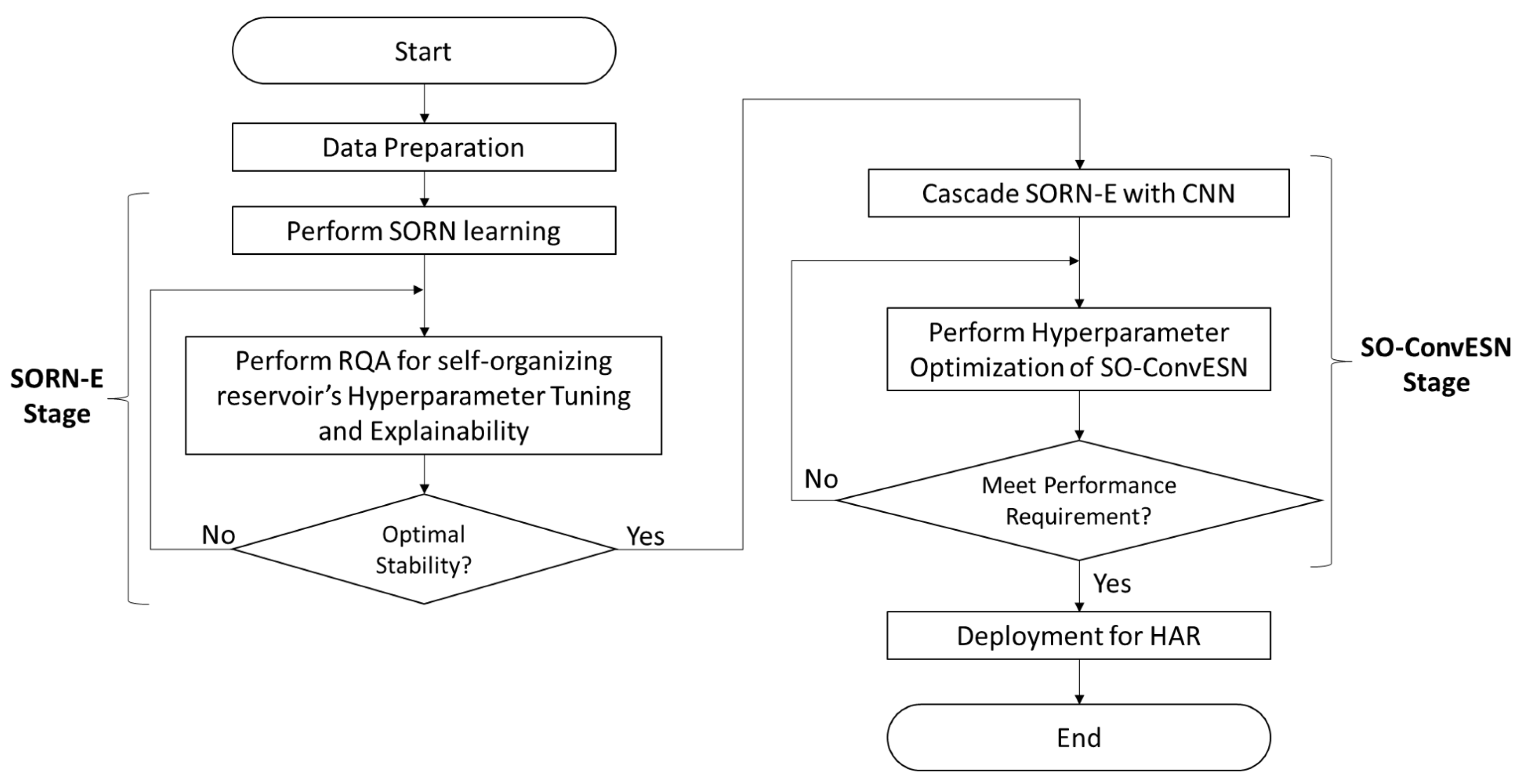
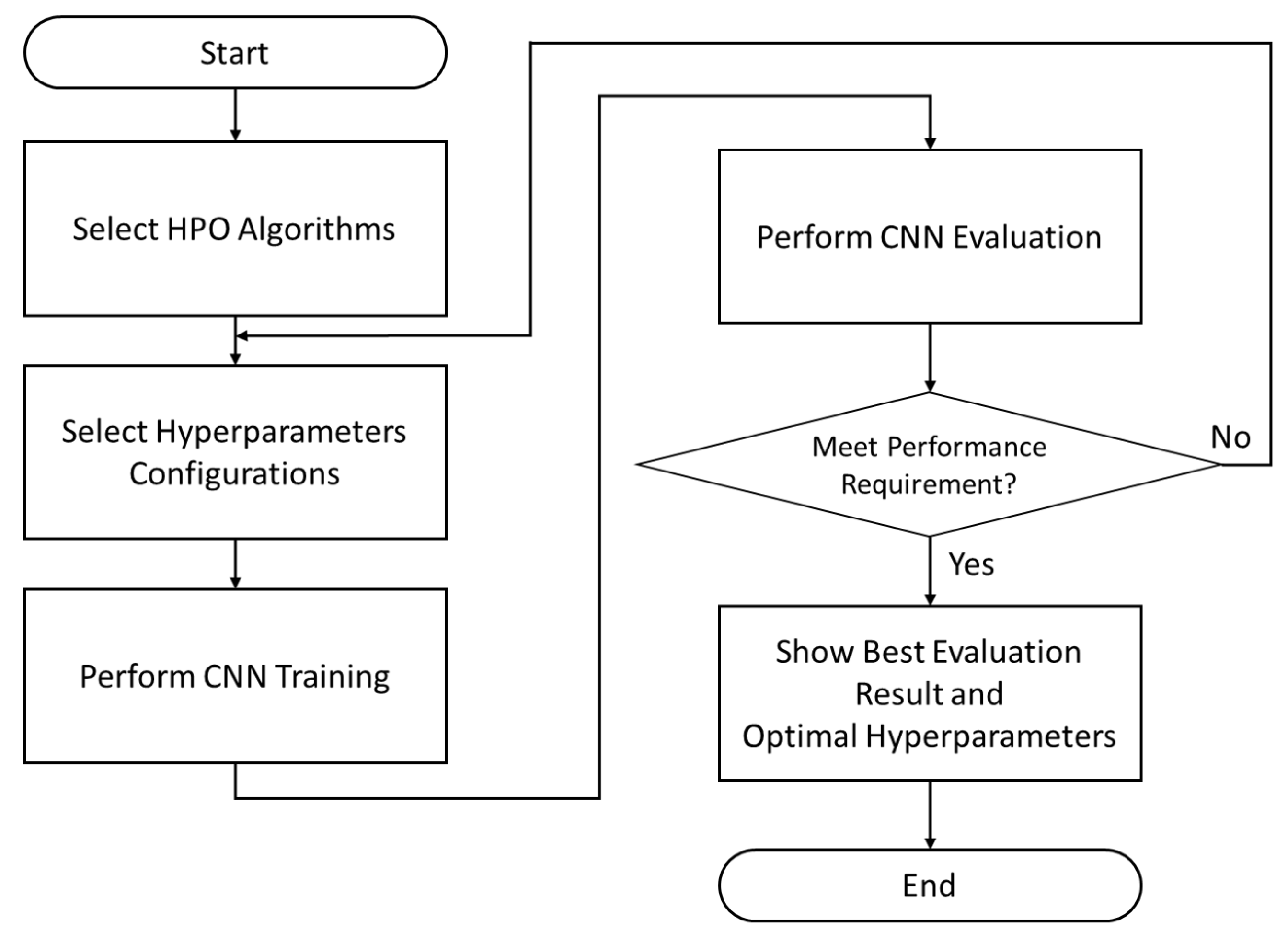
This demonstration followed the proposed development framework as shown in
Figure 1. First, the 79 skeletal videos of the AHA3D dataset were randomly split into 39 videos as the training set, 20 videos as the validation set, and 20 videos as the testing set. The training set was used for SORN learning and reservoir hyperparameter tuning. SORN-E generated node centroids and interconnectivity matrix and the optimal configuration of input scaling and spectral radius, which were then used to perform deterministic initialization of the recurrent weight and input weight in SO-ConvESN. The same training set and the previously selected 20 videos of the validation set were used to train and optimize SO-ConvESN using ASHA. Once trained, 20 videos of the testing set were used to evaluate the physical fitness exercise recognition performance of the SO-ConvESN-ASHA. This development and assessment process was iteratively conducted for 100 runs using 20 videos of testing set to recognize four fitness exercise actions: unipedal stance, 8 ft up and go, 30 s chair stand, and 2 min step.
From the 100-run recognition test, the SO-ConvESN-ASHA achieved an average HAR accuracy of 97.1%, with a median of 100%. More than 50 runs of the tests achieved 100% accuracy. Compared to the baseline approach [
59], which revealed an average accuracy of 91%, SO-ConvESN-ASHA accomplished about 6.7% improvement.
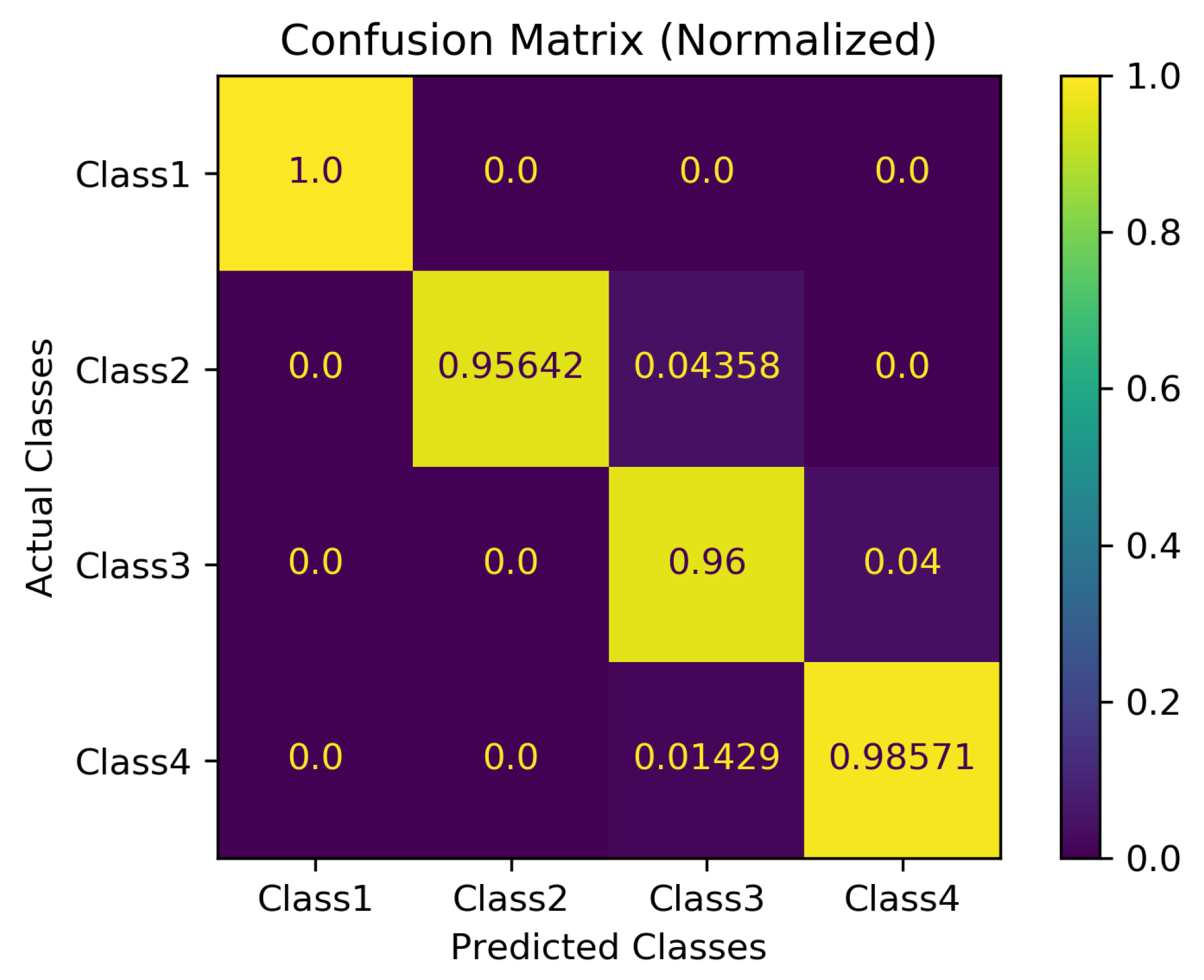
Figure 20 shows the normalized confusion matrix of the overall recognition accuracy for the 100-run experiment. The Class 1 row shows that all 448 videos of “Unipedal Stance” were accurately classified with 100% accuracy. The Class 2 row achievs an accuracy of 95.64%, where 834 of 872 videos representing an “8 ft up and go” were correctly classified, and SO-ConvESN-ASHA wrongly classified 38 videos as “30 s chair stand”. The Class 3 row indicates an accuracy of 96% where 384 of 400 videos for “30 s chair stand” were correctly classified, and SO-ConvESN-ASHA wrongly classified 16 videos as a “2 min step”. The Class 4 row exhibits 98.57% accuracy, with 276 out of 280 were correctly classified as “2 min step”, and SO-ConvESN-ASHA wrongly classified four videos as “30 s chair stand”.
The results of the 100-run performance evaluation show that our proposed development framework, as shown in
Figure 1, has successfully trained and optimized SO-ConvESN to recognize the fitness exercise actions with promising performance. In addition to the outperformed recognition accuracy, false recognition of SO-ConvESN-ASHA only shows up to one class. This achievement demonstrates the practicality of the proposed SO-ConvESN.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}