
Vegetable Size Measurement Based on Stereo Camera and Keypoints Detection


Abstract
:1. Introduction
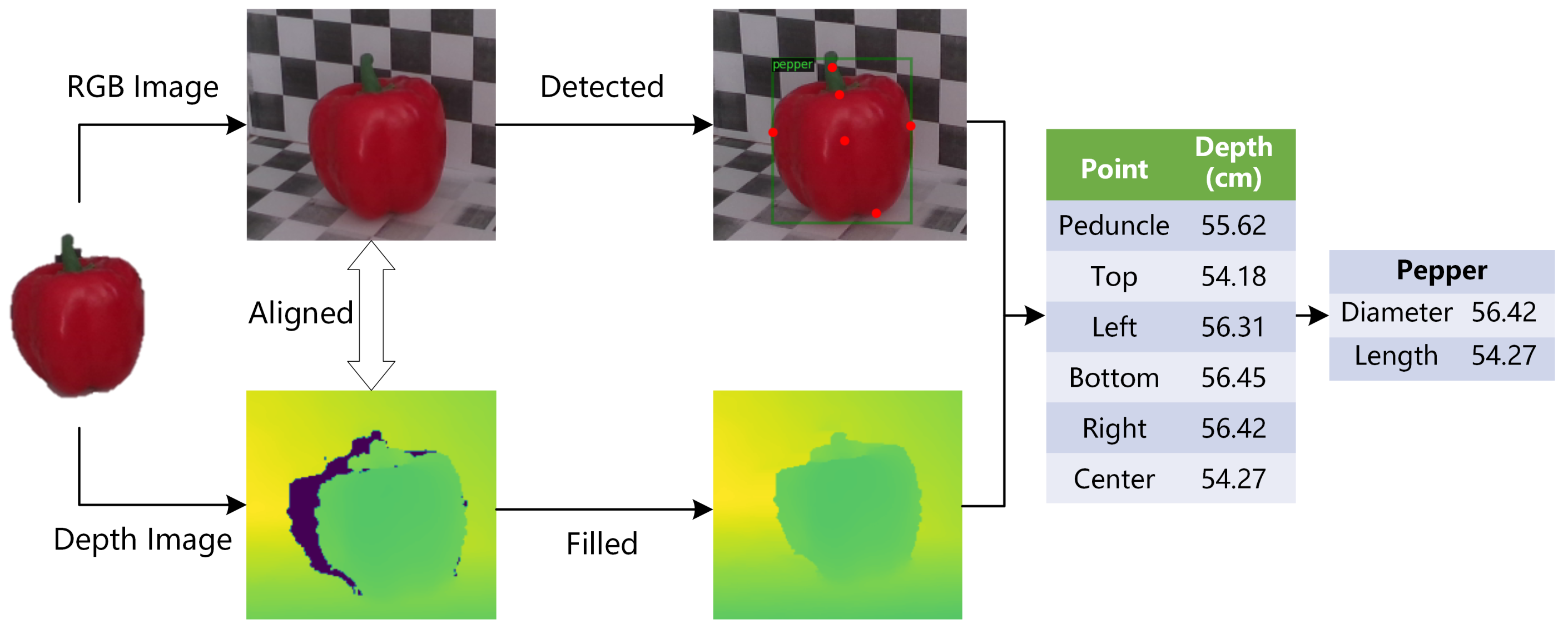
- This paper proposed a non-contact vegetable size measurement method based on keypoint detection and a stereo camera. The method adopts a stereo camera to obtain RGB images and depth maps, then locates six keypoints using the object detection platform named Detectron2. To estimate the vegetables’ size, we propose a method to calculate the diameter and length of objects by fusing the pixel coordinates and depth values of keypoints.
- This paper proposes a vegetable keypoints location method based on depth cameras and object detection. To improve the performance of object detection and keypoint location, we designed a multi-scale strategy named zoom-in. The proposed methods can accurately classify the vegetables and locate six keypoints. The method can not only be applied to the vegetable size estimation but also be used to guide the manipulator to pick and classify vegetables automatically.
- This paper labeled and published a vegetable keypoints data set in standard COCO format with 1600 pictures, including four common vegetables: cucumber, eggplant, tomato, and pepper. Each target contains a region of interest (ROI) and six keypoints. This data set can be widely applied, ranging from classification, 3D position, size detection, manipulator picking, and many other fields.
2. Materials and Methods
2.1. Color Image and Depth Map Acquisition
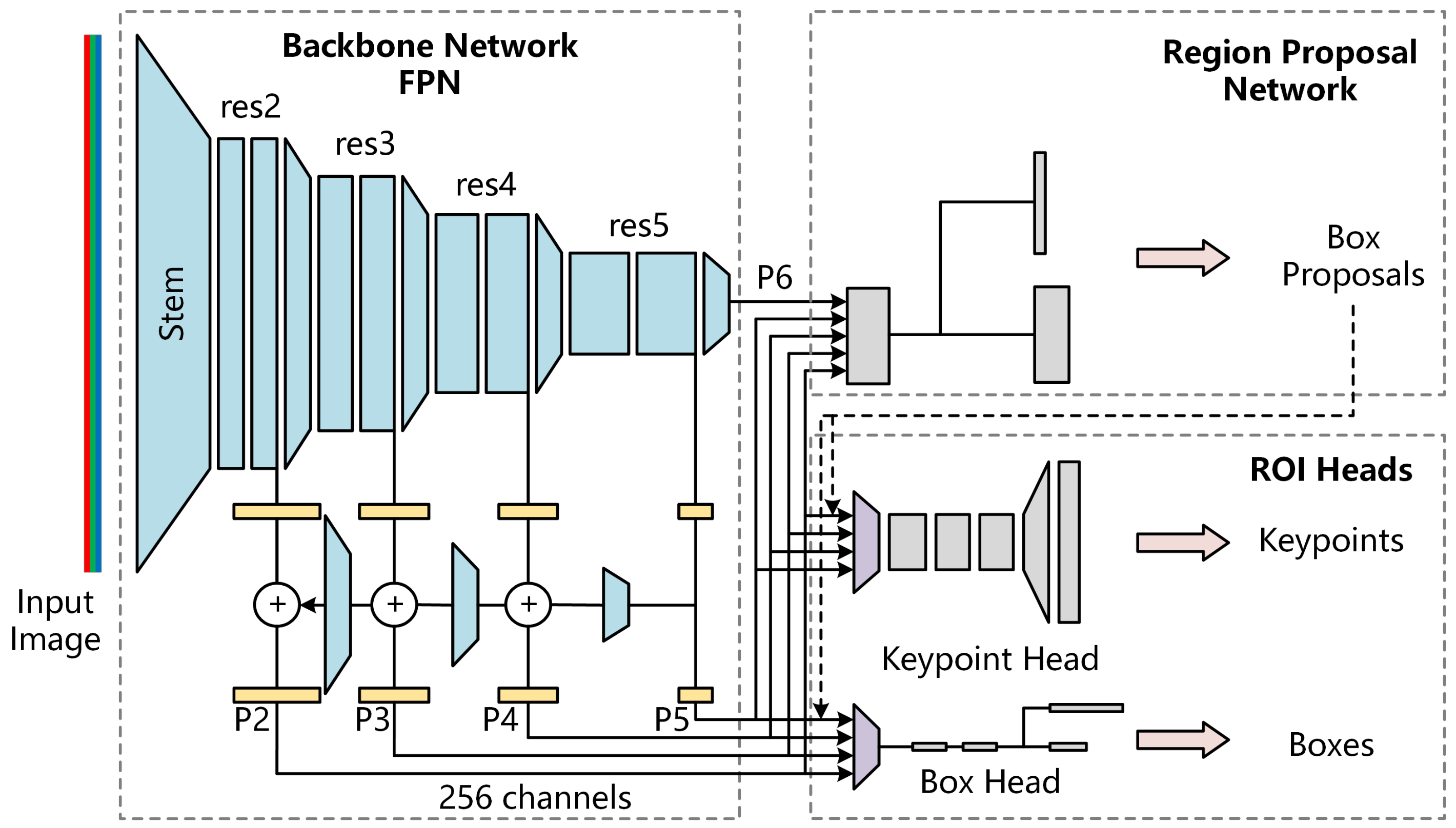
2.2. Keypoint Detection Networks
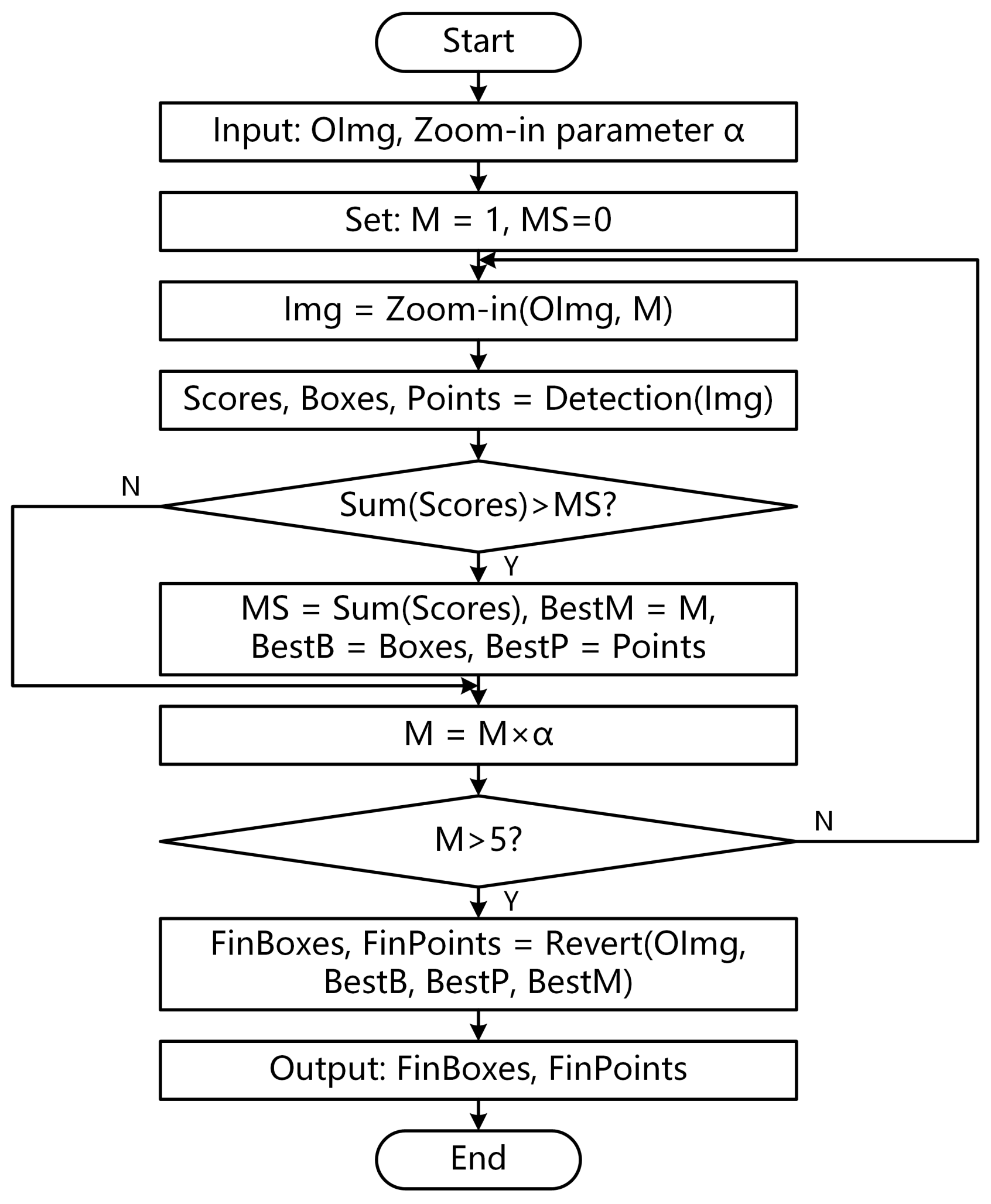
2.3. Multi-Scale Object Detection
- Input the image to be tested and zoom-in parameter .
- Set the magnification to and the maximum score to .
- Execute the detection loop. Magnify the original image to M times using the zoom-in function and obtain a new image named . The execution detail of zoom-in is to magnify the original image to M times with Bilinear Interpolation, then cut a new image with the same size as the original image in the center of the magnified image.
- Calculate the score of using the pre-trained key point detection networks. Furthermore, detect the box and keypoints contained in the image.
- Sum the scores of all proposal boxes. If the total score is greater than , update the maximum score MS and record the best magnification as M. Otherwise, go to the next step.
- Update magnification to . If , the module will jump out of the loop. Otherwise, it will return to 3.
- Map the boxes and keypoints on back to the original image with Revert according to the magnification and output FinBoxes and FinPoints. The execution detail of the Revert is to calculate the center point of the image according to the size of the original image, then shorten the distance between the predicted points and the center point by times.
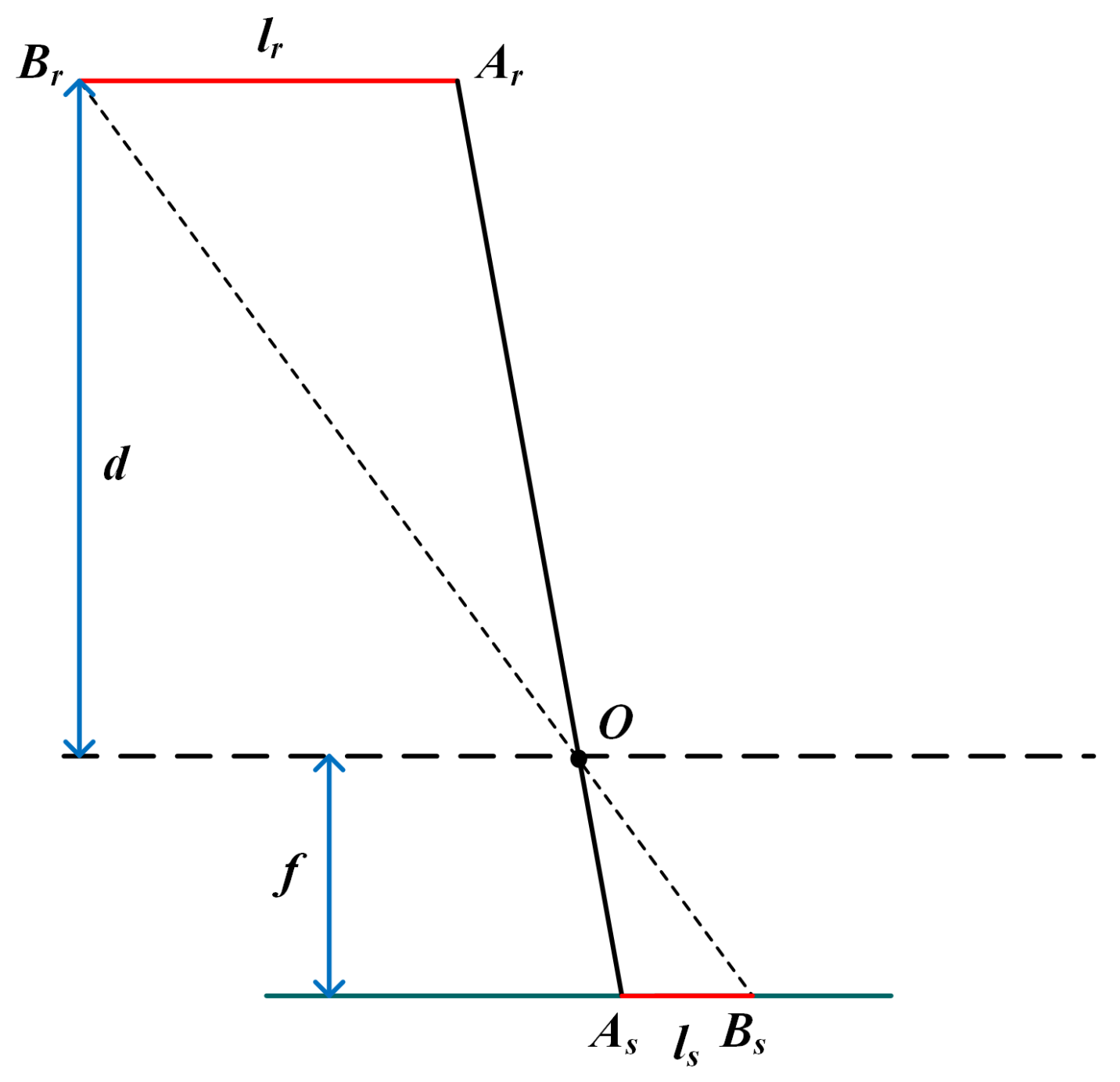
2.4. Vegetable Size Estimation
- •
- Calculate the 3D space coordinates of keypoints by projecting them to the 3D space. Then, use the 3D coordinates to calculate the distance between the two points directly.
- •
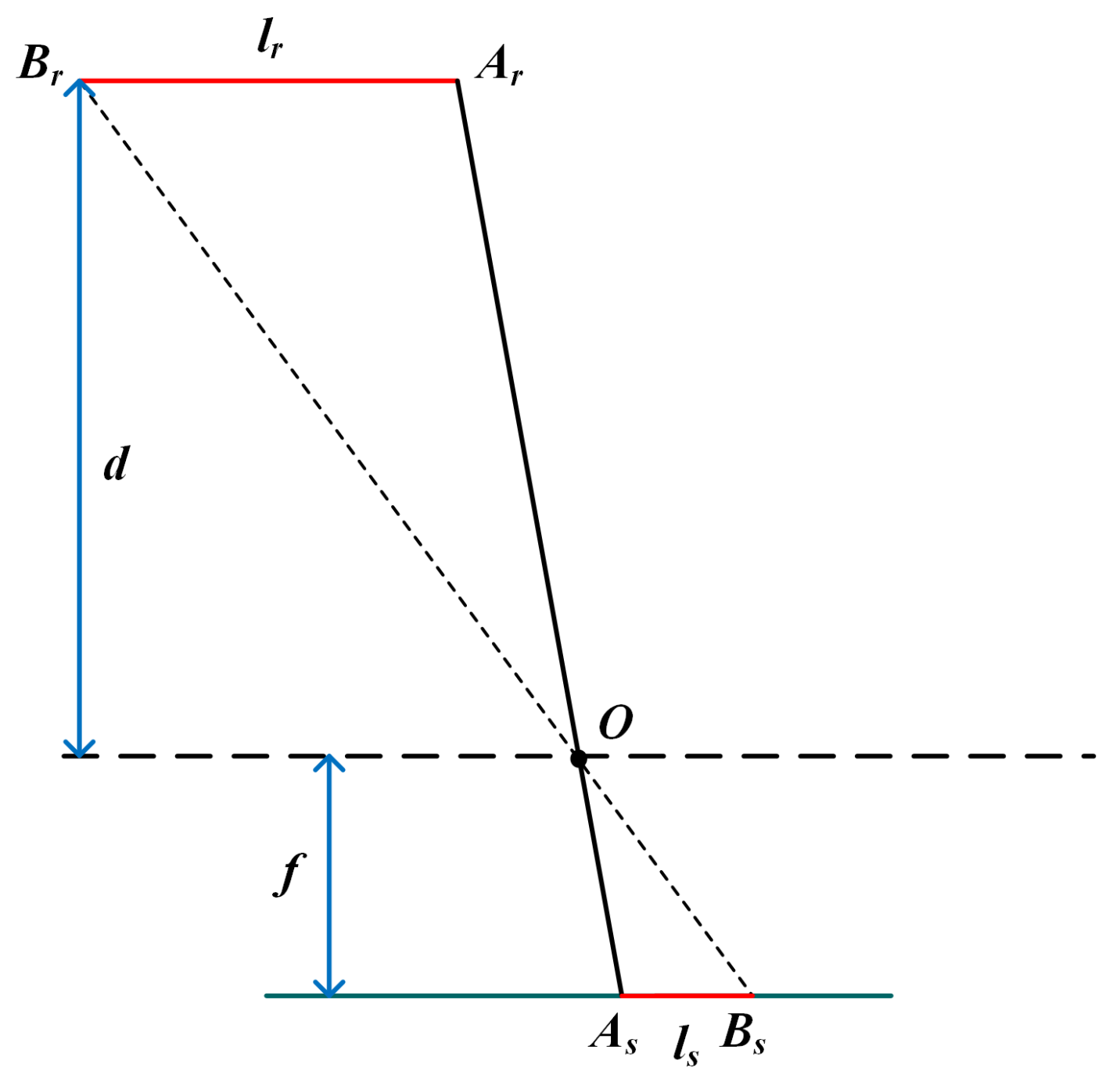
- Calculate the pixel distance d between two points in the RGB image, then map the pixel distance to the 3D space. Meanwhile, correct the distance error caused by the depth difference between different key points with mathematical methods.
2.5. Datasets
3. Results
3.1. Experimental Settings
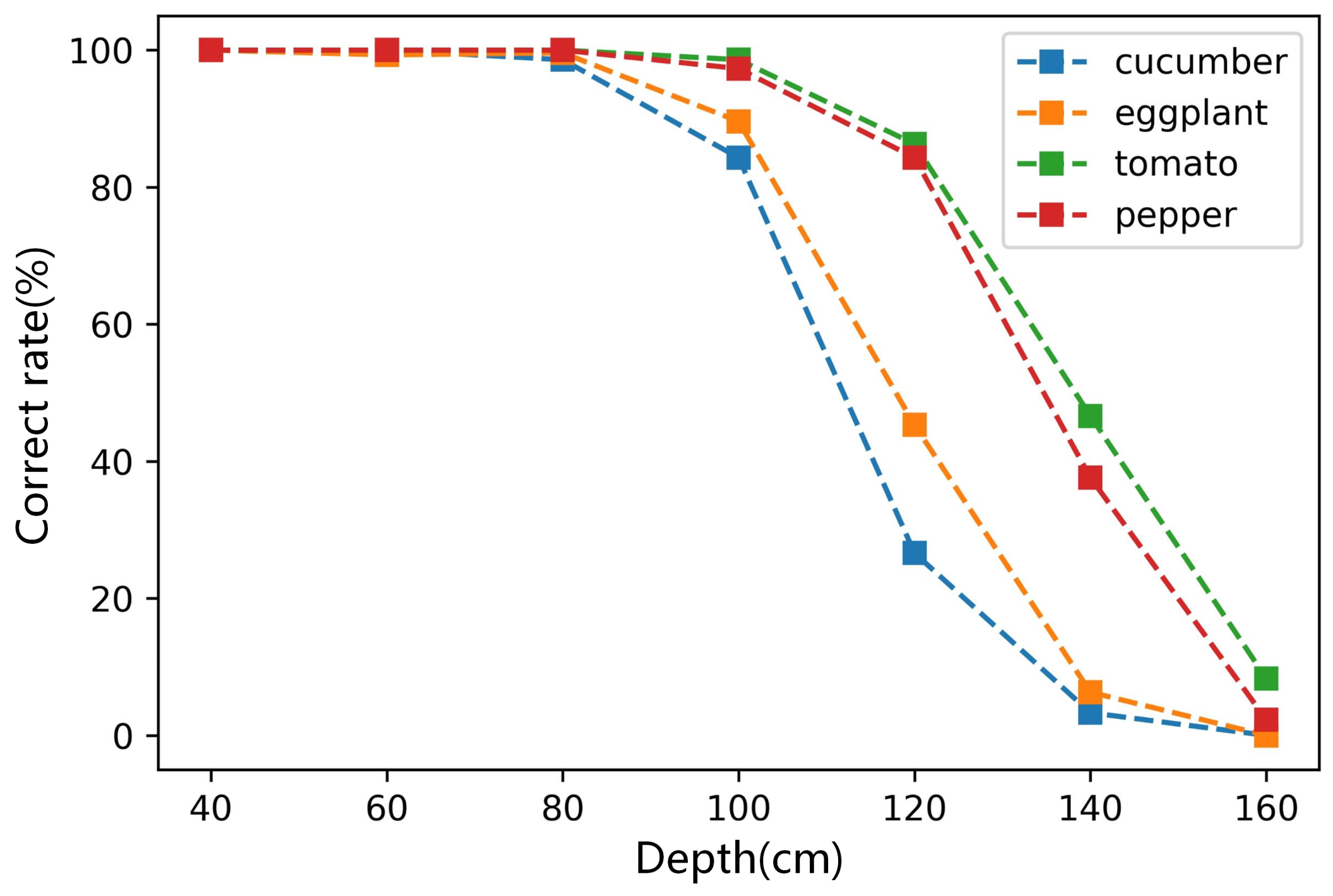
3.2. Results of Vegetables Classification
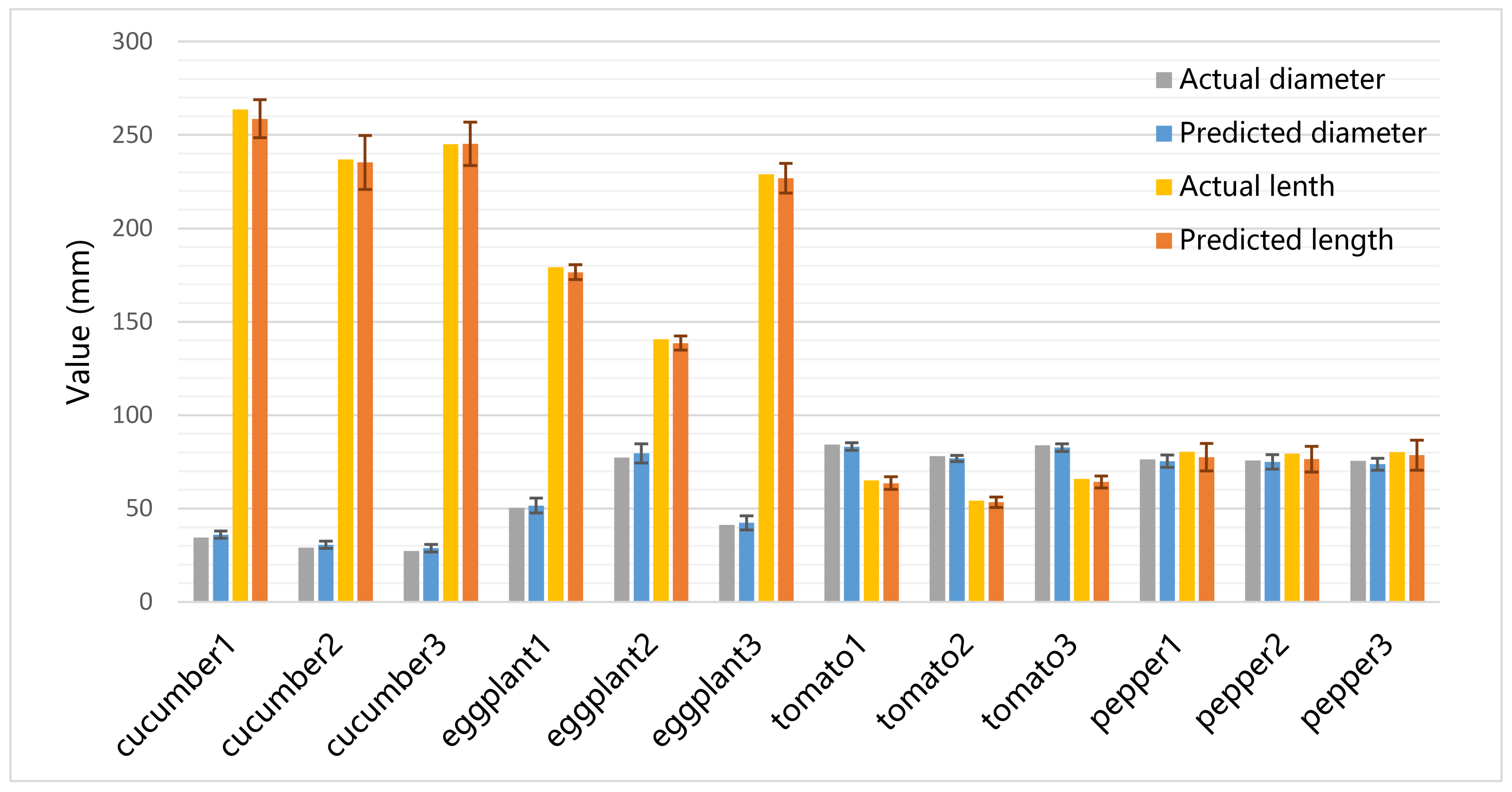
3.3. Results of Size Estimation
3.4. Multiple Object Detection
3.5. Comparison with State-of-Art Methods
4. Discussion
4.1. Effectiveness of the Proposed Method
4.2. Effectiveness of Zoom-In Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, Q. An approach to apple surface feature detection by machine vision. Comput. Electron. Agric. 1994, 11, 249–264. [Google Scholar] [CrossRef]
- Wen, Z.; Tao, Y. Building a rule-based machine-vision system for defect inspection on apple sorting and packing lines. Expert Syst. Appl. 1999, 16, 307–313. [Google Scholar] [CrossRef]
- Dang, H.; Song, J.; Guo, Q. A fruit size detecting and grading system based on image processing. In Proceedings of the 2010 Second International Conference on Intelligent Human-Machine Systems and Cybernetics, Nanjing, China, 26–28 August 2010; IEEE: New York, NY, USA, 2010; Volume 2, pp. 83–86. [Google Scholar]
- Vivek Venkatesh, G.; Iqbal, S.M.; Gopal, A.; Ganesan, D. Estimation of volume and mass of axi-symmetric fruits using image processing technique. Int. J. Food Prop. 2015, 18, 608–626. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rabby, M.K.M.; Chowdhury, B.; Kim, J.H. A modified canny edge detection algorithm for fruit detection & classification. In Proceedings of the 2018 10th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 20–22 December 2018; IEEE: New York, NY, USA, 2018; pp. 237–240. [Google Scholar]
- Wang, Z.; Walsh, K.B.; Verma, B. On-tree mango fruit size estimation using RGB-D images. Sensors 2017, 17, 2738. [Google Scholar] [CrossRef] [Green Version]
- Phate, V.R.; Malmathanraj, R.; Palanisamy, P. Classification and weighing of sweet lime (Citrus limetta) for packaging using computer vision system. J. Food Meas. Charact. 2019, 13, 1451–1468. [Google Scholar] [CrossRef]
- Sobol, Z.; Jakubowski, T.; Nawara, P. Application of the CIE L* a* b* Method for the Evaluation of the Color of Fried Products from Potato Tubers Exposed to C Band Ultraviolet Light. Sustainability 2020, 12, 3487. [Google Scholar] [CrossRef] [Green Version]
- Ashtiani, S.H.M.; Rohani, A.; Aghkhani, M.H. Soft computing-based method for estimation of almond kernel mass from its shell features. Sci. Hortic. 2020, 262, 109071. [Google Scholar] [CrossRef]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4903–4911. [Google Scholar] [CrossRef] [Green Version]
- Rong, J.; Dai, G.; Wang, P. A peduncle detection method of tomato for autonomous harvesting. Complex Intell. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Sun, Q.; Chai, X.; Zeng, Z.; Zhou, G.; Sun, T. Multi-level feature fusion for fruit bearing branch keypoint detection. Comput. Electron. Agric. 2021, 191, 106479. [Google Scholar] [CrossRef]
- Weyler, J.; Milioto, A.; Falck, T.; Behley, J.; Stachniss, C. Joint plant instance detection and leaf count estimation for in-field plant phenotyping. IEEE Robot. Autom. Lett. 2021, 6, 3599–3606. [Google Scholar] [CrossRef]
- Gan, H.; Ou, M.; Huang, E.; Xu, C.; Li, S.; Li, J.; Liu, K.; Xue, Y. Automated detection and analysis of social behaviors among preweaning piglets using key point-based spatial and temporal features. Comput. Electron. Agric. 2021, 188, 106357. [Google Scholar] [CrossRef]
- Suo, F.; Huang, K.; Ling, G.; Li, Y.; Xiang, J. Fish Keypoints Detection for Ecology Monitoring Based on Underwater Visual Intelligence. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; IEEE: New York, NY, USA, 2020; pp. 542–547. [Google Scholar]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An improved faster R-CNN for small object detection. IEEE Access. 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Nguyen, N.D.; Do, T.; Ngo, T.D.; Le, D.D. An evaluation of deep learning methods for small object detection. J. Electr. Comput. Eng. 2020, 2020, 3189691. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Huang, J.; Shi, Y.; Gao, Y. Multi-scale faster-RCNN algorithm for small object detection. J. Comput. Res. Dev. 2019, 56, 319. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Saranya, S.M.; Rajalaxmi, R.; Prabavathi, R.; Suganya, T.; Mohanapriya, S.; Tamilselvi, T. Deep Learning Techniques in Tomato Plant—A Review. J. Phys. Conf. Series. 2021, 1767, 012010. [Google Scholar] [CrossRef]
- Fu, L.; Gao, F.; Wu, J.; Li, R.; Karkee, M.; Zhang, Q. Application of consumer RGB-D cameras for fruit detection and localization in field: A critical review. Comput. Electron. Agric. 2020, 177, 105687. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: New York, NY, USA, 2017; pp. 3626–3633. [Google Scholar]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Gavrilescu, R.; Zet, C.; Foșalău, C.; Skoczylas, M.; Cotovanu, D. Faster R-CNN: An approach to real-time object detection. In Proceedings of the 2018 International Conference and Exposition on Electrical And Power Engineering (EPE), Iasi, Romania, 18–19 October 2018; IEEE: New York, NY, USA, 2018; pp. 0165–0168. [Google Scholar]
- Wu, J.; Kuang, Z.; Wang, L.; Zhang, W.; Wu, G. Context-aware rcnn: A baseline for action detection in videos. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany, 2020; pp. 440–456. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 652–660. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 7103–7112. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Diameter/mm | Length/mm | Object | Diameter/mm | Length/mm |
|---|---|---|---|---|---|
| Cucumber1 | 34.53 | 263.54 | Tomato1 | 84.36 | 65.17 |
| Cucumber2 | 29.03 | 236.96 | Tomato2 | 78.10 | 54.28 |
| Cucumber3 | 27.36 | 245.13 | Tomato3 | 83.79 | 65.81 |
| Eggplant1 | 50.28 | 179.22 | Pepper1 | 76.41 | 80.34 |
| Eggplant2 | 77.37 | 140.64 | Pepper2 | 75.84 | 79.49 |
| Eggplant3 | 41.31 | 229.05 | Pepper3 | 75.55 | 80.17 |
| Object | 40 cm | 60 cm | 80 cm | 100 cm | ||||
|---|---|---|---|---|---|---|---|---|
| Cucumber1 | 6.13% | 3.21% | 6.49% | 3.64% | 10.89% | 7.23% | 18.39% | 13.90% |
| Cucumber2 | 7.24% | 4.19% | 7.93% | 4.91% | 11.23% | 8.98% | 19.77% | 14.13% |
| Cucumber3 | 5.94% | 3.28% | 6.42% | 3.96% | 9.48% | 7.69% | 17.17% | 14.47% |
| Average | 6.44% | 3.56% | 6.95% | 4.17% | 10.53% | 7.97% | 18.44% | 14.17% |
| Eggplant1 | 5.96% | 1.96% | 6.59% | 2.18% | 8.91% | 4.03% | 12.56% | 7.17% |
| Eggplant2 | 5.27% | 2.07% | 5.89% | 2.29% | 9.58% | 4.27% | 13.09% | 7.22% |
| Eggplant3 | 6.68% | 2.43% | 7.23% | 2.89% | 10.89% | 4.94% | 14.84% | 7.89% |
| Average | 5.97% | 2.15% | 6.57% | 2.45% | 9.79% | 4.41% | 13.50% | 7.43% |
| Tomato1 | 1.99% | 3.56% | 2.15% | 4.43% | 4.25% | 6.95% | 7.37% | 11.56% |
| Tomato2 | 2.02% | 4.25% | 2.28% | 4.65% | 4.68% | 7.19% | 7.99% | 12.43% |
| Tomato3 | 1.95% | 3.89% | 2.24% | 4.46% | 4.33% | 6.88% | 7.22% | 10.89% |
| Average | 1.99% | 3.90% | 2.22% | 4.51% | 4.42% | 7.01% | 7.53% | 11.63% |
| Pepper1 | 2.86% | 6.56% | 3.48% | 7.98% | 7.49% | 11.64% | 10.58% | 14.56% |
| Pepper2 | 2.91% | 7.25% | 3.67% | 7.86% | 8.01% | 11.48% | 11.84% | 14.83% |
| Pepper3 | 2.75% | 6.89% | 3.33% | 8.13% | 7.28% | 11.99% | 10.02% | 14.21% |
| Average | 2.84% | 6.90% | 3.49% | 7.99% | 7.59% | 11.70% | 10.81% | 14.53% |
| Objects | 40 cm | 80 cm | ||||
|---|---|---|---|---|---|---|
| Cucumber | 6.89% | 3.87% | 100% | 11.25% | 8.53% | 97.67% |
| Eggplant | 6.34% | 2.21% | 100% | 10.77% | 5.03% | 98.33% |
| Tomato | 2.02% | 3.96% | 100% | 4.93% | 7.58% | 99.33% |
| Pepper | 2.95% | 7.16% | 100% | 8.47% | 12.69% | 99.00% |
| Objects | Methods | 40 cm | 60 cm | 80 cm | 100 cm | ||||
|---|---|---|---|---|---|---|---|---|---|
| Cucumber | Edge Detection | 28.73% | 6.18% | 30.74% | 7.89% | 33.96% | 12.24% | 38.19% | 19.18% |
| Bounding Box | 48.19% | 24.84% | 49.56% | 26.87% | 54.12% | 29.10% | 60.42% | 34.93% | |
| Ours | 6.44% | 3.56% | 6.95% | 4.17% | 10.53% | 7.97% | 18.44% | 14.17% | |
| Eggplant | Edge Detection | 11.58% | 4.12% | 13.17% | 4.87% | 18.93% | 7.98% | 25.76% | 12.89% |
| Bounding Box | 27.81% | 10.65% | 31.76% | 14.98% | 38.71% | 18.12% | 48.52% | 20.70% | |
| Ours | 5.97% | 2.15% | 6.57% | 2.45% | 9.79% | 4.41% | 13.50% | 7.43% | |
| Tomato | Edge Detection | 2.21% | 5.03% | 3.31% | 6.98% | 7.11% | 10.94% | 13.25% | 18.61% |
| Bounding Box | 2.54% | 5.86% | 4.17% | 7.81% | 7.29% | 11.18% | 14.13% | 16.37% | |
| Ours | 1.99% | 3.90% | 2.22% | 4.51% | 4.42% | 7.01% | 7.53% | 11.63% | |
| Pepper | Edge Detection | 14.91% | 13.37% | 16.16% | 15.52% | 19.96% | 19.48% | 24.35% | 25.67% |
| Bounding Box | 9.33% | 8.52% | 10.84% | 10.03% | 15.06% | 14.23% | 19.72% | 18.63% | |
| Ours | 2.84% | 6.90% | 3.49% | 7.99% | 7.59% | 11.70% | 10.81% | 14.53% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, B.; Sun, G.; Meng, Z.; Nan, R. Vegetable Size Measurement Based on Stereo Camera and Keypoints Detection. Sensors 2022, 22, 1617. https://doi.org/10.3390/s22041617
Zheng B, Sun G, Meng Z, Nan R. Vegetable Size Measurement Based on Stereo Camera and Keypoints Detection. Sensors. 2022; 22(4):1617. https://doi.org/10.3390/s22041617
Chicago/Turabian StyleZheng, Bowen, Guiling Sun, Zhaonan Meng, and Ruili Nan. 2022. "Vegetable Size Measurement Based on Stereo Camera and Keypoints Detection" Sensors 22, no. 4: 1617. https://doi.org/10.3390/s22041617
APA StyleZheng, B., Sun, G., Meng, Z., & Nan, R. (2022). Vegetable Size Measurement Based on Stereo Camera and Keypoints Detection. Sensors, 22(4), 1617. https://doi.org/10.3390/s22041617