
HRGAN: A Generative Adversarial Network Producing Higher-Resolution Images than Training Sets




Abstract
:1. Introduction
2. Methods
2.1. Generative Adversarial Networks
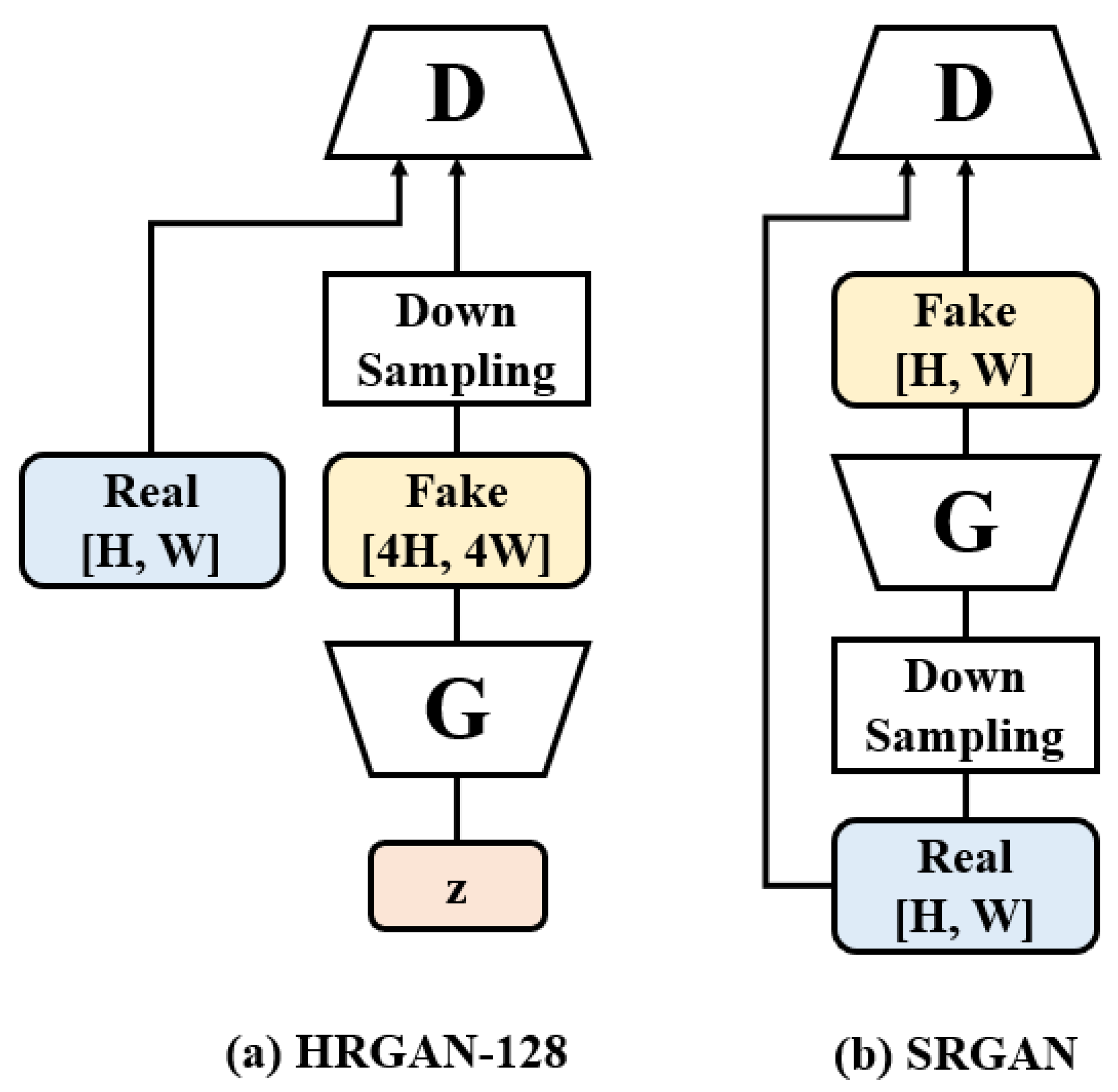
2.2. Generation of Higher Resolution Images
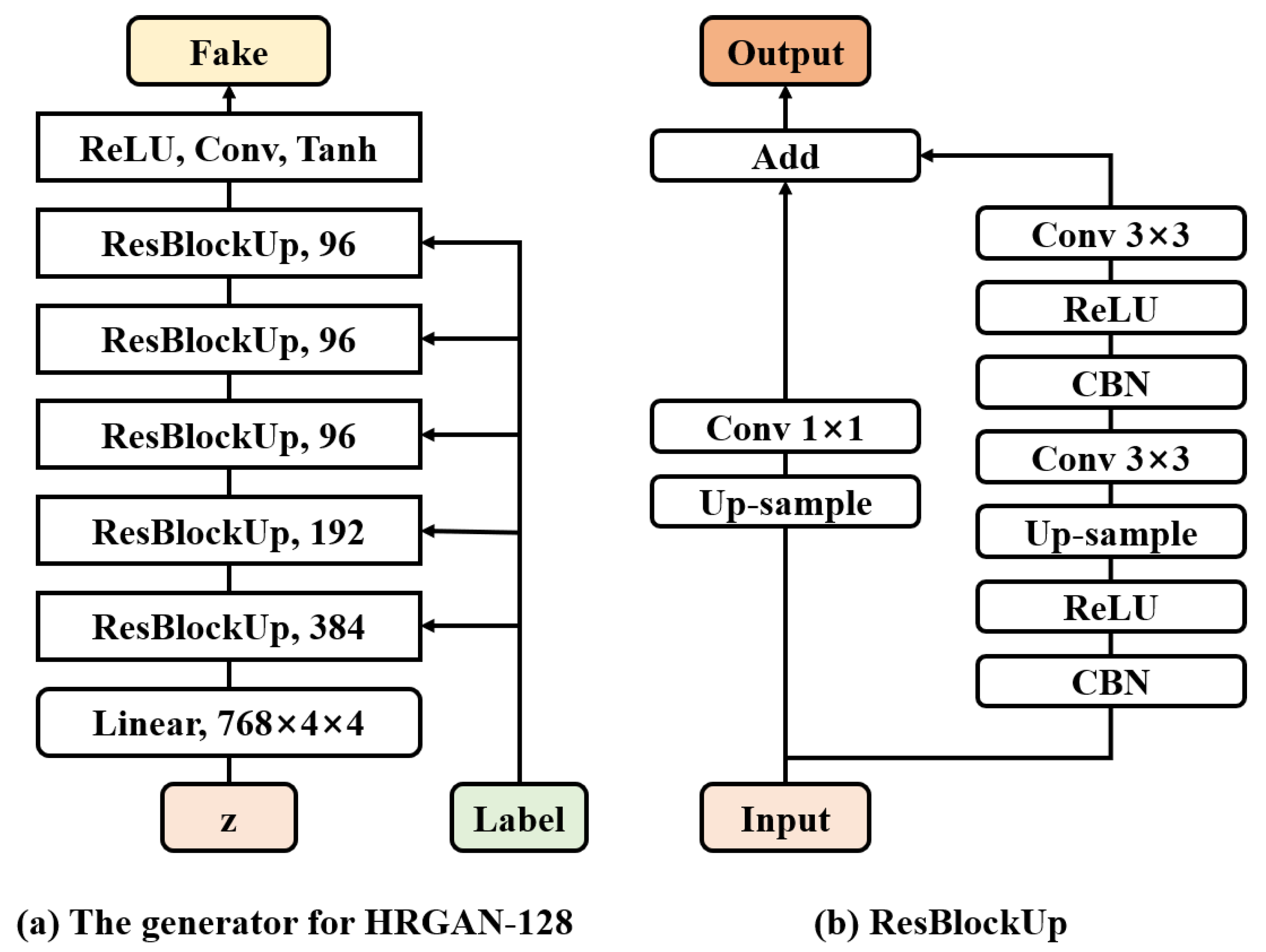
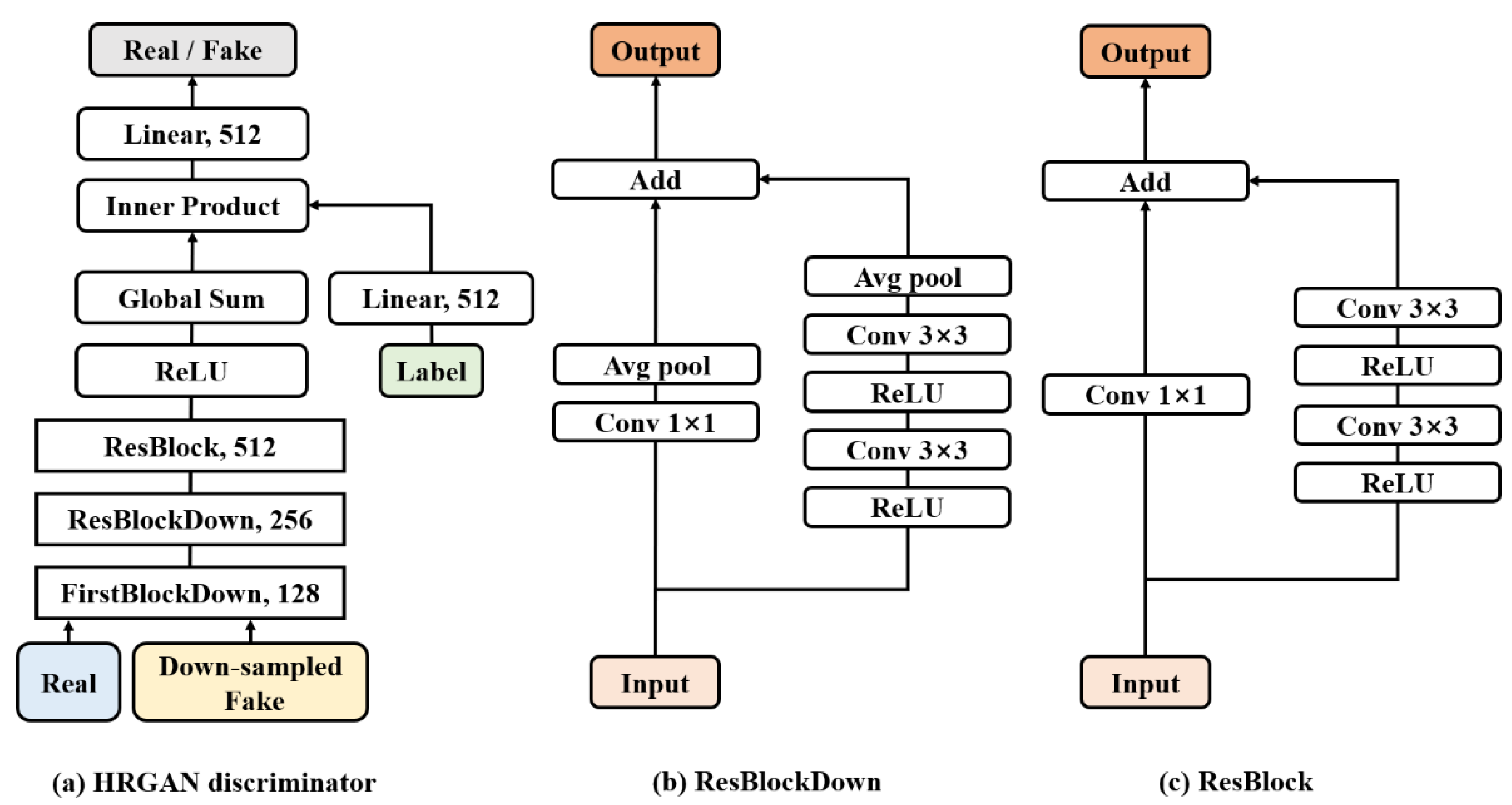
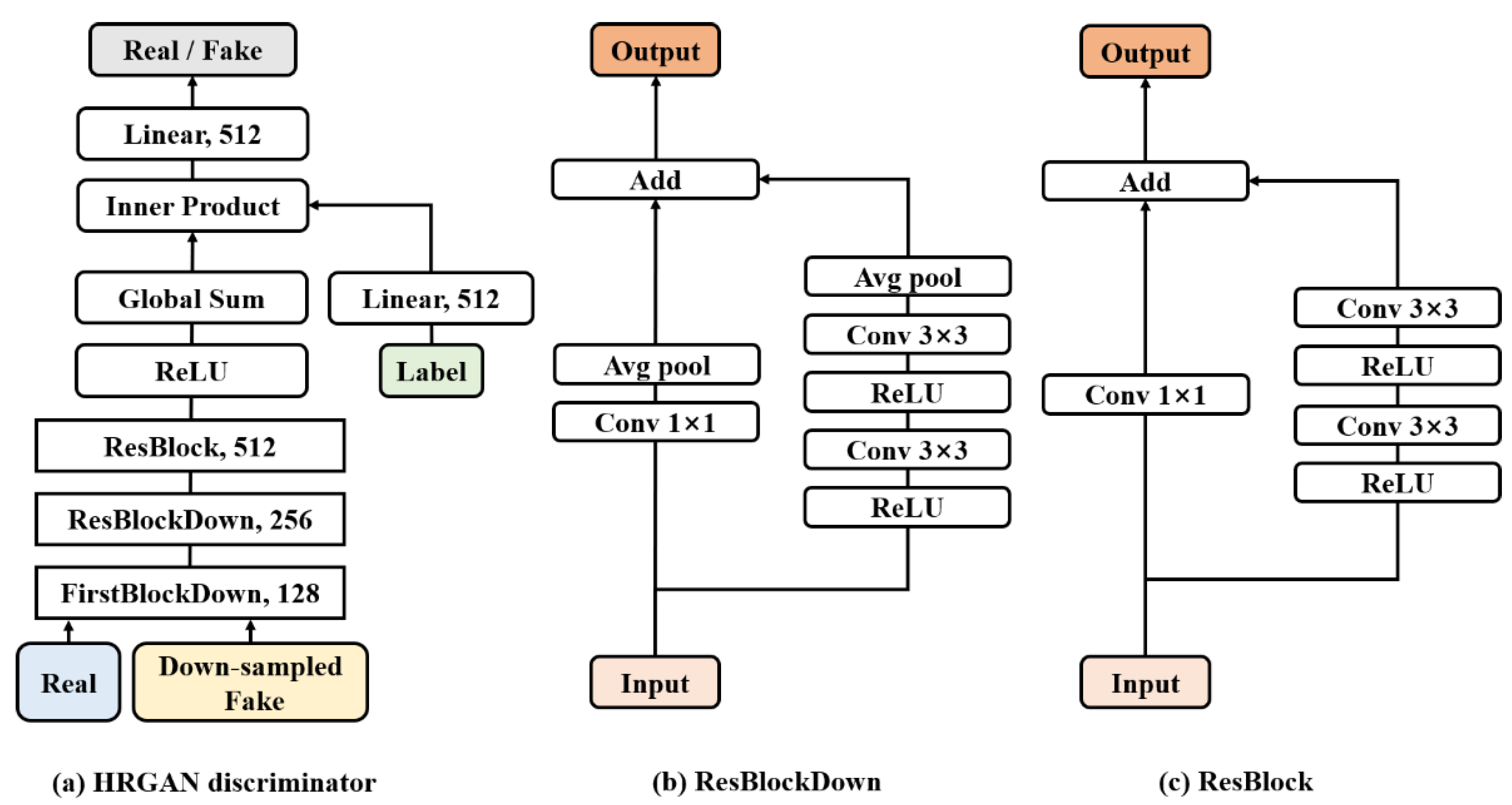
2.3. Architecture
2.3.1. Generator
2.3.2. Discriminator
2.4. Objective Functions
2.5. Training
| Algorithm 1 HRGAN training algorithm. |
| Model: D: discriminator. G: generator. Gd: generator down-sampling. E: pre-trained MobileNetV3-small. Parameter: θdisc: discriminator parameters. θgen: generator parameters. Input: x: data set. y: one-hot encoded label vector. z: random noises sampled from a normal distribution. w: one-hot encoded label vector converted from random integer sampled from a normal distribution. Require: α: the learning rate of the generator. m: discriminator batch size. n: the ratio of discriminator and generator backpropagation. cls: the number of classes. MSreal: the pre-calculated MobileNet score of real data set. HR: the ratio of high-resolution output images and real images. |
3. Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lee, M.; Seok, J. Score-guided generative adversarial networks. arXiv 2020, arXiv:2004.04396. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier GANs. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Processing 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Miyato, T.; Koyama, M. cGANs with projection discriminator. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- De Vries, H.; Strub, F.; Mary, J.; Larochelle, H.; Pietquin, O.; Courville, A. Modulating early visual processing by language. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Lim, J.H.; Ye, J.C. Geometric GAN. arXiv 2017, arXiv:1705.02894. [Google Scholar]
- Barratt, S.; Sharma, R. A note on the inception score. arXiv 2018, arXiv:1801.01973. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ni, Y.; Song, D.; Zhang, X.; Wu, H.; Liao, L. CAGAN: Consistent adversarial training enhanced GANs. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Grinblat, G.L.; Uzal, L.C.; Granitto, P.M. Class-splitting generative adversarial networks. arXiv 2017, arXiv:1709.07359. [Google Scholar]
- Kavalerov, I.; Czaja, W.; Chellappa, R. cGANs with multi-hinge loss. arXiv 2019, arXiv:1912.04216. [Google Scholar]
- Lee, M.; Seok, J. Controllable generative adversarial network. IEEE Access 2019, 7, 28158–28169. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | Inception Score | Improvement |
|---|---|---|---|
| CIFAR10 | 8.44 ± 0.08 | 0.33 | |
| 8.77 ± 0.09 | |||
| CIFAR100 | 8.81 ± 0.12 | 0.78 | |
| 9.59 ± 0.16 |
| Model | Improvement | ||
|---|---|---|---|
| HRGAN-32 | 8.44 ± 0.08 | 8.77 ± 0.09 | 0.33 |
| HRGAN-64 | 8.69 ± 0.11 | 10.62 ± 0.12 | 1.93 |
| HRGAN-128 | - | 12.32 ± 0.11 | - |
| Model | Inception Score |
|---|---|
| Real Images | 11.26 ± 0.13 |
| Conditional DCGAN [6] | 6.58 |
| AC-WGAN-GP [5] | 8.42 ± 0.10 |
| CAGAN [24] | 8.61 ± 0.12 |
| Splitting GAN [25] | 8.87 ± 0.09 |
| BigGAN [14] | 9.22 |
| MHingeGAN [26] | 9.58 ± 0.09 |
| HRGAN-64 | 10.62 ± 0.12 |
| HRGAN-128 | 12.32 ± 0.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, M.; Lee, M.; Yu, S. HRGAN: A Generative Adversarial Network Producing Higher-Resolution Images than Training Sets. Sensors 2022, 22, 1435. https://doi.org/10.3390/s22041435
Park M, Lee M, Yu S. HRGAN: A Generative Adversarial Network Producing Higher-Resolution Images than Training Sets. Sensors. 2022; 22(4):1435. https://doi.org/10.3390/s22041435
Chicago/Turabian StylePark, Minyoung, Minhyeok Lee, and Sungwook Yu. 2022. "HRGAN: A Generative Adversarial Network Producing Higher-Resolution Images than Training Sets" Sensors 22, no. 4: 1435. https://doi.org/10.3390/s22041435
APA StylePark, M., Lee, M., & Yu, S. (2022). HRGAN: A Generative Adversarial Network Producing Higher-Resolution Images than Training Sets. Sensors, 22(4), 1435. https://doi.org/10.3390/s22041435