1. Introduction
Nonlinear system filtering has always been a difficult problem in the field of target tracking. The extended Kalman filter (EKF), unscented Kalman filter (UKF) and other filtering methods are often used in the application fields of Unmanned Aerial Vehicle (UAV) attitude estimation, autopilot, radar detection and so on. In these fields, the improvement of filtering accuracy will have a great impact on practical applications [
1,
2,
3,
4,
5,
6]. Although there are many filtering algorithms that can be used in nonlinear systems, such as EKF [
7], UKF [
8], particle filter (PF) [
9], etc., though these filtering methods have their limitations. The principle of the EKF algorithm is to linearize a non-linear system, in which only the first-order terms of Taylor expansion are preserved. For non-linear systems, retaining only the first-order terms can result in a very large loss of filtering accuracy. In high order strongly nonlinear systems, it is more difficult to linearize the system by calculating the Jacobian matrix. The error accumulation of error covariance matrix during linearization also results in a loss of filtering accuracy. In actual situations, most of the systems we encounter are nonlinear and non-Gaussian systems. The premise of the EKF algorithm is that the noise of the system is Gaussian noise [
7].
The core of the UKF algorithm is the UT transformation, hich uses an ensemble of sigma sampling points to approximate the nonlinear system model [
10,
11,
12]. The computational effort of the UKF algorithm is the same as that of the EKF, and the filtering accuracy is better than that of the EKF, which can at least reach the second-order accuracy of Taylor expansion. However, the shortcomings of the UKF algorithm are also obvious. It can only be applied to Gaussian systems, and the problem of non-positive definite error covariance matrix will be caused by the emergence of negative weight in the implementation of the algorithm, and the frequency of this problem will be greater as the order of the system increases and the nonlinearity becomes stronger. Particle filter (PF) algorithm uses the random sampling method to obtain the sample points of the state as much as possible. These sample points are used to approximate the distribution of the system as much as possible, so as to estimate the system state [
9,
13]. Particle filter can be applied to nonlinear non-Gaussian systems, but particle filter requires a large number of sample points, the calculation cost is too high and the problem of particle degradation occurs in the calculation process, which makes the implementation of particle filter more difficult [
9].
Ensemble Kalman filter (EnKF) was first proposed by Geir Evensen in 1994 [
14]. When this method was proposed, it was mainly used to solve the nonlinear problems in weather forecasting. In the face of nonlinear weather characteristics and huge meteorological data, it is very difficult to apply EKF directly to atmospheric prediction [
15,
16,
17]. In order to apply Kalman filtering to atmospheric prediction, Geir Evensen introduced the idea of ensemble prediction and proposed a new filtering method. EnKF algorithm combines Kalman filtering with the ensemble prediction idea, uses the Monte Carlo method to design an ensemble of prediction states, takes the average value of the state ensemble as the best estimation value of the state and takes the sample covariance of the ensemble as the approximation of the covariance of the state estimation error [
14,
18]. The ensemble Kalman filter algorithm is an improvement of the Kalman filter. In fact, it adds the idea of ensemble, expands the sample points, supplements a variety of possibilities of the actual state, and essentially changes the sampling method. The random sampling method of EnKF using Monte Carlo also has its limitations [
19,
20,
21,
22,
23]. Although random sampling will get statistical results, the random sampling will be affected by the uncertainty factors of current noise, which will lead to the loss of filtering accuracy. Moreover, there is no definite method to select the range of disturbance [
24,
25,
26,
27]. When calculating the best estimate, the EnKF algorithm uses the set average of states and the average weight, which will also reduce the filtering accuracy [
28,
29,
30].
Therefore, a novel Kalman-filter-design method combining UKF and EnKF sampling mechanism is proposed in this paper. It is mainly used to solve the problems of nonlinear systems and strongly nonlinear systems. It can be applied in the fields of target tracking, marine weather prediction and so on. This method avoids the problem that the sampling set obtained by UKF sampling mechanism is not representative. It overcomes the problem that EnKF Monte Carlo random sampling cannot be constrained by the true statistical characteristics of the state. It reduces the error caused by using equal weight to obtain the set average value in EnKF. It avoids the failure of the UKF algorithm caused by improper selection of parameters. In addition, the method in this paper provides a reliable improvement direction for the UKF algorithm.
The remaining parts of this paper are organized as follows:
Section 1 is the preface, which introduces the development status of filter and the method proposed in this paper;
Section 2 is the description of nonlinear system;
Section 3 and
Section 4 analyze and introduce the advantages and disadvantages of UKF and EnKF; in
Section 5, a new data sampling driven Kalman filter design method is introduced, which combines the characteristic sampling of UKF with the random sampling of EnKF;
Section 6 is the performance analysis of the system;
Section 7 introduces the numerical experiment of this method; and
Section 8 presents a summary and prospect.
2. Nonlinear System Description
Considering the following multidimensional non-linear systems, the state equation and the measurement equation are both non-linear, respectively:
where
is the n-dimensional state vector at time
and
is the measure vector at time
.
is the transformation operator and
is the measurement transformation operator.
is process noise and measurement noise, respectively, and
,
.
Given the initial value
, get the estimated value
of the initial value
Remark 1. If the state is one-dimensional, its expectation is equal to itself.
Given the estimates
and
of the initial values, the estimates
of the time
are obtained
Remark 2. of the above equation is the estimated value of the state at time, andis the predicted value at time, All of the following “” and “” are used for this purpose.
Estimated error covariance
at time
is obtained from the state estimate
at time
In the above way, based on initial values
, measurements
, and systems (1) and (2). Assume that the estimated value and estimation error covariance matrix of state
based on EnKF have been obtained
And the estimation value and estimation error covariance matrix based on UKF are also obtained
The superscript “E” in Equation (
6) denotes the filter result of EnKF; the superscript “U” in Equation (
7) denotes the filter result of UKF.
The objectives of the
Section 3 and
Section 4 below are to give the recursive filtering processes of EnKF and UKF after obtaining
, and to analyze their advantages and disadvantages, which will lay a foundation for further obtaining new filters.
3. Ensemble Kalman Filter Algorithm
The EnKF algorithm is a filtering method based on the Monte Carlo method and the ensemble prediction idea [
14,
15,
16,
17]. The main difference between the EnKF method and Kalman filter method is that it uses ensemble to expand the dimension of state, and then weights its state. Therefore, according to Equation (
6), on the basis that
has been obtained. Based on the EnKF method, the estimated value
of state
and the estimation error covariance matrix
will be derived. The specific algorithm steps are as follows:
Step 1: Based on the Monte Carlo random sampling mechanism, the sampling ensemble of state
is obtained
where,
is an arbitrary random perturbation, for example, a frequently chosen is
,
represents the random function matrix column obeying Gaussian distribution.
Step 2: Calculate the predicted value of state , and calculate the predicted value of measurement based on state predicted value .
Step 3: The self-covariance matrix of measurement prediction error and the mutual covariance matrix of state prediction error and measurement prediction error are obtained.
Step 4: According to the covariance matrix of step 3, the gain matrix is obtained, and through the gain matrix update error, the state estimation members in the state estimation ensemble are obtained.
Step 5: According to step 4, the ensemble average and the estimation error covariance of the estimated values of state are obtained.
Note 3.1: Review of algorithm advantages: the idea of the EnKF algorithm is simple and easy to implement. It uses the Monte Carlo method to generate an ensemble of states, and by obtaining more sampling points, as close as possible to the distribution of the real state, a better filtering effect can be obtained.
Note 3.2: Limitations of the EnKF algorithm: EnKF generates state ensemble by random sampling, which uses uncertain sampling, and the generated samples do not all conform to the distribution of real states. Therefore, it is difficult to approximate the real function and the real statistical characteristics of state variables, which will lead to the estimation error of state. Therefore, it is necessary to improve this random sampling method and find a sampling method that conforms to the real statistical characteristics of state variables as much as possible.
Note 3.3: The EnKF method approximates the best-predicted value and best-estimated value of the state by ensemble average. The disadvantage of this method is that the ensemble average is not necessarily the sample center of the ensemble, and it cannot reflect the true distribution of state variables. Since the ensemble average uses equal weights, the geometric center of the state is obtained, but the geometric center of the sample and the physical center of the sample are not necessarily coincident. Regarding the weight of each sample as the same, it will cause the lack of important information of the state variable, just as the effect of force on the centroid depends on the magnitude of the moment, the contribution of each sample point to the sample center is different. Therefore, it is necessary to improve this equal weight calculation method and find a weight calculation method that can reasonably describe the contribution of each sample.
Therefore, the selection of a sampling mechanism that can conform to the statistical characteristics of system state , as well as the selection of appropriate weighting coefficients, become key issues to improve the effectiveness of EnKF in practical applications.
4. Unscented Kalman Filter Algorithm
Although EKF solves the situation that KF cannot solve the nonlinear problem [
7], EKF lacks better approximation ability. Since EKF does not use the non-linear characteristics of the original non-linear function, it uses the method of non-linear approximation, discards the non-linear characteristics, and only uses the linear characteristics. The filter performance of its algorithm often degrades continuously with the increase in non-linearity, and it even diverges. For this reason, Julier et al. [
8,
9,
10,
11,
12,
13] introduced UKF to improve EKF. The idea is based on UT transformation, which is used to transfer the mean and covariance during one-step prediction. Therefore, according to Equation (
7), on the basis that
has been obtained. Based on the UKF method, the estimated value
of state
and the estimation error covariance matrix
will be derived. The specific algorithm steps are as follows:
Step 1: According to the estimator and covariance matrix of the state at time , a set of sample points and corresponding weights are obtained.
Step 2: A set of new sample points are obtained through nonlinear function , through the weight, the one-step prediction value of the state is obtained, and the error covariance matrix is calculated.
Step 3: Based on the predicted value at time , the measured predicted value at time is obtained, is obtained by calculating and the self-covariance matrix and mutual covariance matrix are calculated.
Step 4: The gain matrix is calculated based on obtaining and .
Step 5: Calculate the estimated value
at time and the covariance matrix .
Note 4.1: UKF algorithm advantage comment: the algorithm operates normally, experimental analysis shows that the UKF can achieve a nonlinear second-order accuracy approximation close to Taylor expansion, and the filtering performance is superior to the first-order linear approximation of the EKF, thus improving the handling power for nonlinear problems.
Note 4.2: The defects in the selection of UKF parameters often cause the algorithm to fail to perform effectively: the main manifestation is that it is easy to appear negative definite phenomena in the three matrices , , and . Analyses as below:
(1) The reasons of might be negative definite:
In fact, for any
, there is
where, we let
, then
Since matrix
is non-negative definite, thus,
in consideration of
If , there will be .
So, whether is positive depends on the choice of , if , then , otherwise, there is no way to guarantee that matrix is positive definite.
In the same way, the analysis and results are similar for matrix , which mainly depends on the value case of .
(2) Analyze whether
is positive definite. due to
If
is negative definite, because the gain matrix cannot be obtained
This causes the algorithm to fail at this step, and thus causes the algorithm to fail.
(3) If is positive definite and is negative definite, the algorithm will fail in calculating the gain matrix.
This is because we want to make
In fact, for any
, there is
So, is positive definite, the must be positive definite.
From the above analysis, it can be seen that the problems of the UKF algorithm are caused by improper selection of weights in step 1. In actual simulation experiments, they are mainly caused by the negative values of and . Therefore, selecting appropriate weights has become a bottleneck problem that affects the effective operation of UKF.
Note 4.3: Sigma sampling describes the statistical characteristics of the state: The UKF sampling is based on the estimation error covariance matrix of state , which is derived based on the statistical properties of estimation error compared to the unconstrained random sampling of EnKF. However, when the dimension n is small, there are few sampling points, so sampling is difficult to be representative of the statistical characteristics of state ; when n is large, the obtained 2n + 1 sampling points are sparse relative to the n-dimensional space, and it is difficult to form coverage of the target characteristics.
Therefore, if the UKF sampling mechanism is combined with the EnKF random sampling mechanism, it will make up for the corresponding deficiencies of the two methods in the sampling mechanism. At the same time, if a better weight selection mechanism can be changed to overcome the shortcomings of UKF in sampling, it will not only overcome the bottleneck problem of frequent failure of UKF, but also greatly improve EnKF’s filtering performance that meets the statistical characteristics of actual problems.
5. Design of a Novel Kalman Filter
In order to overcome the respective shortcomings of UKF and EnKF, in this section, a novel data sampling driven Kalman filter is designed by combining the characteristic sampling of UKF and the random sampling of EnKF. This section first establishes a state sampling mechanism that combines UKF sampling and EnKF; second, establishes a weight selection method based on sampling ensembles; third, design a new Kalman filter design method combining UKF sampling and adaptive weight selection.
The previous analysis shows that the sampling randomness of EnKF is too strong, and the generation of random samples is not constrained by the statistical characteristics of random state variables. Although UKF is constrained by statistical characteristics, due to its own shortcomings, such as relying too much on parameter selection, the samples obtained are not representative in both low and high dimensions, so it is difficult to approach the statistical characteristics of its real state. Therefore, the new Kalman filter design method proposed in this section mainly solves the following two key problems:
(1) Establishing a large sample collection of objects that is suitable for the random characteristics of the objects and has a wider representation.
(2) Looking for a weight selection mechanism that avoids the failure of the algorithm.
A Novel Data Sampling Driven Kalman Filter Is Designed by Combining the Characteristic Sampling of UKF and the Random Sampling of EnKF
The purpose of this section is to establish a new Kalman filter design method.
(1) Large sample generation and sampling mechanism of a new Kalman filter
1. Sigma sampling mechanism optimized based on UKF. In order to overcome the situation that the state variables in EnKF are not constrained by statistical characteristics. First, the state estimate
and the estimation error covariance matrix
at time k are known, and a set of sigma points is taken through the following sigma sampling mechanism of UKF
where, Equations (
22) and (
23) design parameters
, and
determines the dispersion of sample points; the parameters of the UKF are designed inside the square root sign, where the parameters are placed outside the square root to avoid the creation of negative values inside the square root.
represents the
-th column vector after the square root of
. The superscript “UE” in the equation represents the filtering result of the new Kalman filter.
2. EnKF random sampling large sample ensemble generation based on optimized UKF mechanism. Based on the optimized UKF sigma sampling mechanism established in 1, the sampling samples are expanded by using EnKF’s Monte Carlo random sampling mechanism at each obtained sigma sampling point.
First, for each sigma sampling point obtained from Equations (
21)–(
23)
Using the EnKF Monte Carlo random sampling mechanism established by Equation (
8), the sample expansion based on the sigma sampling point is obtained.
Remark 3. is used to represent the number of columns that need to be increased for a single member in the collection. The value of is generally taken to be within 100.
Where, is an arbitrary random perturbation, for example, a frequently chosen is .
Integrating Equation (
25), the sample ensemble used to describe the state statistical properties of state
was obtained
Remark 4. represents the ensemble of States andrepresents the ensemble of individual members.
Where, the number of samples in sample ensemble is .
(2) State One-step prediction estimation and estimation error covariance matrix based on a large sample ensemble.
1. Based on the Equation (
25), the state prediction at
for each member of the ensemble of time
is computed
2. Calculate the confidence weight of each predicted value
.
where, when
,
. Here the weight at the centroid, we temporarily set it to 0. The reason is to avoid calculating the distances of the centroids themselves and, in the following processing, to reassign weights to the centroids.
3. Calculate the one-step forecast estimate of
.
Calculate the state prediction estimation error of
Note 5.1.1: when calculating the weight at Equation (
29), the weight at the centroid is temporarily set to 0. Here, the weight of the centroid and other members is redistributed.
,
represents the contribution of the centroid to the whole ensemble, and the contribution rate of the centroid in the whole filtering process can be adjusted through
. According to the principle of exponential filtering, in general we take
, which, in experiments, can be increased exponentially, modulating the contribution of the centroid.
4. Obtain the one-step prediction error covariance matrix of
.(3) One step prediction estimation and prediction estimation error covariance matrix of measurement .
1. Based on Equation (
27), calculate the measured predicted value of each member in the ensemble at time k at time
.
2. Calculate the confidence weight of each measured predicted value
.
where, when
,
. Similarly, when measuring the weight at the centroid of the prediction ensemble, we temporarily set it to 0. The reason is to avoid calculating the distances of the centroids themselves and, in the following processing, to reassign weights to the centroids.
3. Calculate the one-step prediction estimate of
.
Calculate the measurement prediction error between the measured predicted value and the real value at
k + 1 time.
4. Obtain the one-step prediction error covariance matrix of
.
(4) Mutual covariance matrix between state prediction error and measurement prediction error.
(5) Design of a novel Kalman filter.
1. Calculate the estimated value
of each member in the ensemble at
.
2. Calculate the confidence weight of each estimate
.
where, when
,
. Similarly, the weight at the centroid is temporarily set to 0, the reason is to avoid calculating the distances of the centroids themselves and, in the following processing, to reassign weights to the centroids.
3. Calculate the estimate of
.
Calculate the error of the state estimate
(6) Calculate the gain matrix.
According to the orthogonal principle
It can be obtained from Equations (
32),(
39) and (
47).
(7) Calculate the estimation error covariance matrix of state
6. System Performance Analysis
This section mainly analyzes the methods in
Section 5.
6.1. The Shortcomings of UKF and EnKF Sampling Mechanisms
It is known from the analyses in
Section 3 and
Section 4 that both EnKF and UKF have their own insufficiencies in their sampling mechanisms. The way EnKF produces state ensembles is a stochastic sampling, hard to approximate the true function and hard to approximate the true statistical properties of state variables. Although UKF sampling method can represent the statistical characteristics of the state, the number of samples is relatively small.
In response to the above insufficiencies, a new sampling mechanism was established for the novel Kalman filter design method of
Section 5, mainly to solve the problem that EnKF cannot be constrained by the true statistical properties of the states when it is randomly sampled by Monte Carlo, and to obtain more representative sample points.
6.2. Weight Selection Analysis of UKF and EnKF
It can be seen from the analysis in
Section 3 and
Section 4 that there are defects in the weight selection of EnKF and UKF. The weight distribution of EnKF regards the weight of each sample as the same, which will cause the loss of important information of state variables. Just as the effect of force on the center of moment depends on the size of moment, the contribution of each sample point to the center of sample is different. The weight selection of UKF will cause the non-positive definite of error covariance matrix, resulting in the failure of algorithm operation. In view of the above problems, the method in
Section 5 avoids the lack of information caused by EnKF weight. It overcomes the problem of algorithm failure in UKF operation.
6.3. Improvement of Filter Performance
For EnKF, we use the UKF sampling mechanism affected by the statistical characteristics and the statistical characteristics of state , so that EnKF can approach the real statistical characteristics of system state variables when sampling. In terms of weight selection, the distribution of weight coefficients is more reasonable, which makes the state closer to the real distribution and avoids the loss of information.
For UKF, based on the statistical characteristics of UKF, the dense sampling of EnKF sampling mechanism is mainly reflected in that the state prediction is more accurate, the approximate error is reduced, and the approximate error of measurement is reduced. The combination of two points improves the estimation accuracy. Moreover, the selection of weight avoids the failure of the algorithm and enhances the stability of the algorithm.
6.4. Error Analysis
In order to analyze the feasibility of the method proposed in this article, we will conduct error analysis from the following aspects:
1. Analysis of the approximation error of the state
Define
as the
-th state component of the predicted value of
at time
, and
is the approximation error between the predicted state value of EnKF at time
k and the true value.
Then the approximation error of state prediction is
is defined as the
-th state component of the predicted value at
time of
, and
is the approximation error between the predicted value and the real value of new Kalman filter at
time.
We analyze the predicted value of the state and compare the results of Equations (
55) and (
56). From the theoretical analysis, it should be that the method proposed in this paper reduces the approximation error between the predicted value and the real value, so the estimation error also decreases, and has a better filtering effect.
2. Analysis of estimation error of state:
is defined as the
i-th state component of
, and
is the error between the estimated state value and the real value.
We calculate the mean square error between the estimated value and the real value of the state through Equations (
57) and (
58), and compare and analyze them through experiments. If the approximation error decreases and the estimation error decreases accordingly, it is proved that the error result of the estimation value is consistent with the approximation error. The approximation error is small and the estimation error is small, which can show the effectiveness of the method in this paper.
7. Simulation Experiment
7.1. Simulation Experiment One: Single Dimensional Simulation
Consider the following one-dimensional nonlinear system:
where,
,
, are all Gaussian white noise sequences obeying a distribution of
, with initial value m, assuming initial estimate
, initial estimate error covariance
, and
as parameters that regulate the degree of nonlinearity. Here are the comparative trials under different methods:
Remark 5. The row of the table represents the sampling method used, and the column of the table represents the weight method used. The improvement in the row represents the comparison results of different weights selected by the same sampling method, and the improvement in the column represents the comparison results of different samples selected by the same weight method. The improved cross Italic part represents the results of the comparison between the weight and sampling method in this paper and the original EnKF.
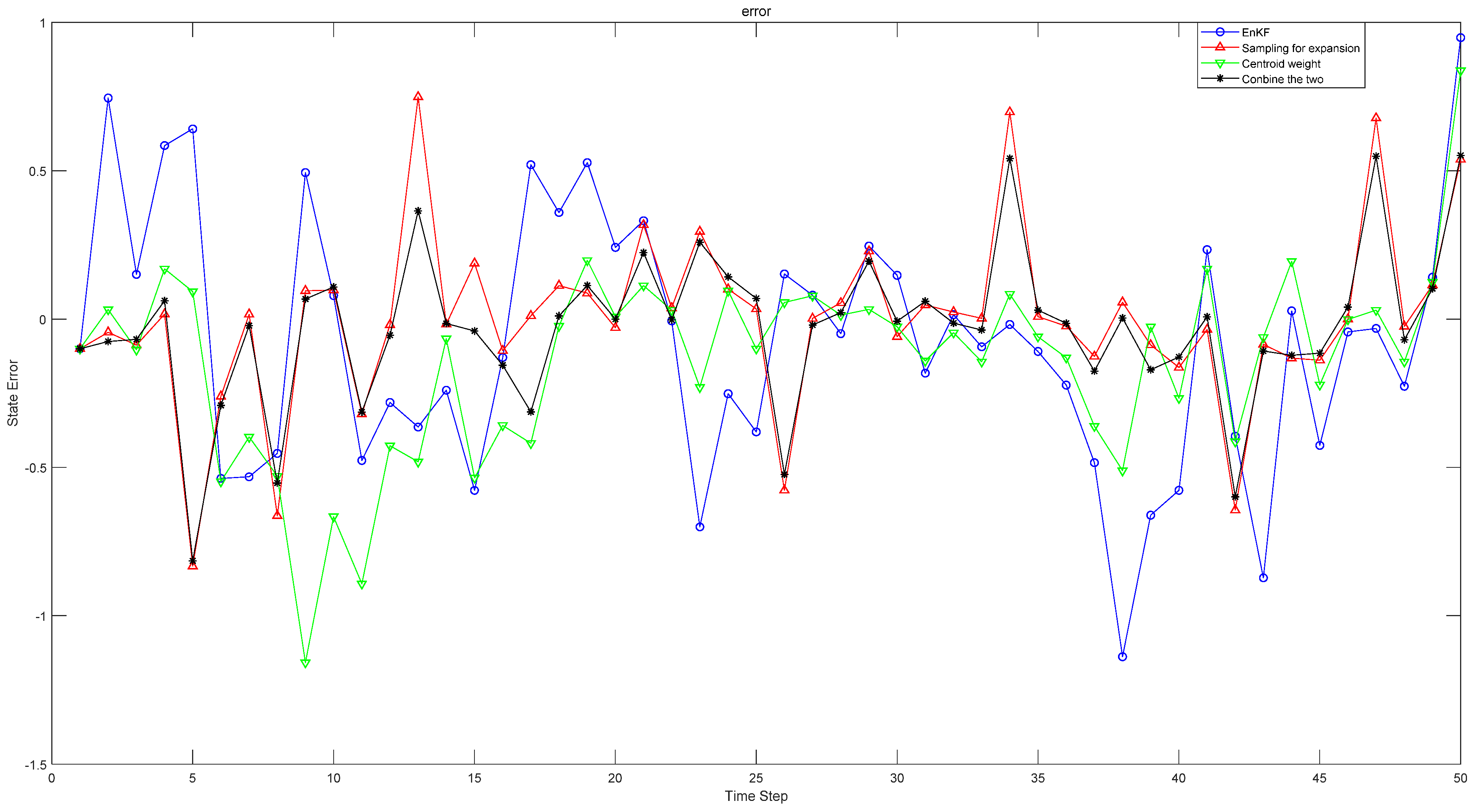
Figure 1 shows the comparison between the errors of estimated value and real value in one-dimensional simulation experiment when
. The methods in the figure are the original EnKF, the EnKF changing the sampling method, the EnKF changing the weight selection and the new Kalman filter method combining the two methods finally adopted in this paper.
Table 1 shows the comparison results under different parameters, different weights and different sampling methods. When
, under the original weight, the approximation error of the original sampling EnKF method is 0.3445, and the approximation error of the expansion sampling method is 0.2923. In contrast, the EnKF of the expansion sampling method is 15.15% higher than the original. Under the original sampling method, the approximation error of the confidence weight is 0.2824, which is 18.02% higher than the original weight. The approximation error of the method proposed in this paper is 0.2807, which is 18.52% higher than the original EnKF. Compared with the original weight, the EnKF method of capacity expansion sampling is improved by 3.97%, and compared with the EnKF method of confidence weight, the EnKF method of original sampling is improved by 0.6%. In the estimation error analysis in
Table 2, the original weight is increased by 21.97% compared with the original EnKF by using the expansion sampling method, the original sampling is increased by 44.9% compared with the original EnKF by using the confidence weight, and the centroid weight is increased by 46.71% compared with the original EnKF by using the centroid weight expansion sampling method. In addition, the effect of changing both sampling and weight is better than that of changing only one method. With the reduction of approximation error in
Table 1, the corresponding estimation error in
Table 2 is also reduced, and the filtering effect is greatly improved. In
Table 1 and
Table 2, with the change of parameters, the nonlinearity of the system is also changing. When the nonlinearity is enhanced, the method proposed in this paper still has good results. Through experiments, we verify the feasibility of our method in one-dimensional system.
7.2. Simulation Experiment Two: Multidimensional Simulation
Consider the following two-dimensional strongly nonlinear system:
where,
,
, are all Gaussian white noise sequences obeying a distribution of
, assuming an initial true value of
, an initial estimate of
with initial estimation error covariates
, and
is a parameter that regulates the degree of nonlinearity in the nonlinear system. The original EnKF method was contrasted with different methods separately, and the experimental results are shown below:
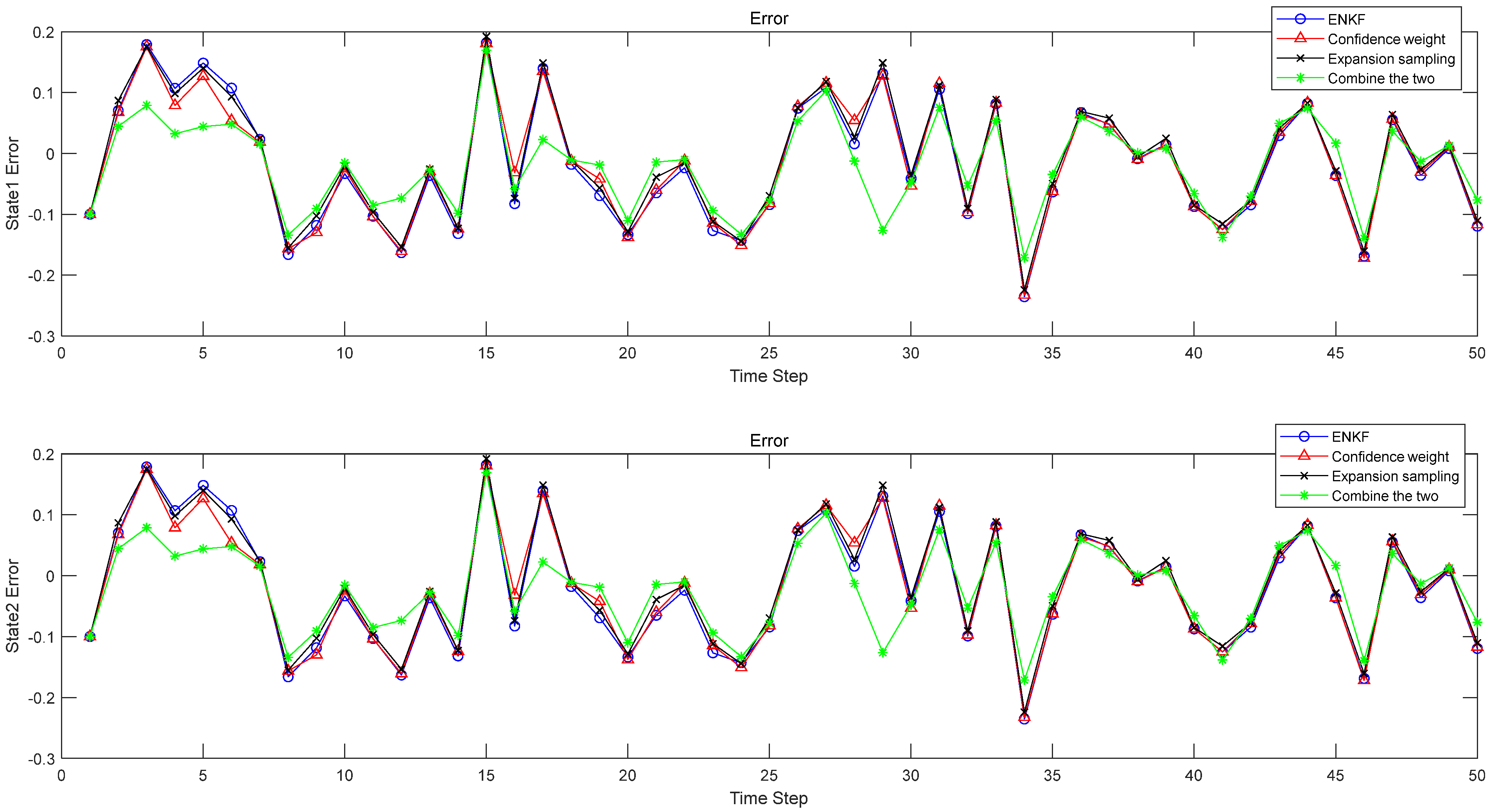
Figure 2 shows the comparison results of the errors of four methods when
.
Table 3,
Table 4,
Table 5 and
Table 6 show the results when
and
are constants and the nonlinearity of the system is changed by
. When
, in
Table 3, the approximation error of state
in the original EnKF method is 0.1064, and the approximation error of the expansion sampling method is 0.1056. In contrast, the EnKF of the expansion sampling method is increased by 0.75% compared with the original. Under the original sampling method, the approximation error of the confidence weight is 0.1055, which is 0.85% higher than the original weight. The approximation error of the method proposed in this paper is 0.1050, which is 1.32% higher than the original EnKF. In the estimation error analysis in
Table 4, under the original weight the expansion sampling method is 5.85% higher than the original EnKF; under the original sampling, the confidence weight is 6% higher than the original EnKF, and the centroid weight expansion sampling method is 45.44% higher than the original EnKF. As can be seen from the table, the effect of improving the two methods is better than changing only one. The experimental results show that the approximation error is reduced, the corresponding estimation error is also reduced, and the filtering effect is significantly improved. Similarly, in
Table 5 and
Table 6, the status
has the same effect. Moreover, as can be seen from
Table 3,
Table 4,
Table 5 and
Table 6, with the enhancement of nonlinearity, the filtering effect of the method proposed in this paper is still very good. This experiment proves that the estimation error can be reduced when the approximation error is reduced. By reducing the approximation error and estimation error, the filtering accuracy is improved, and the feasibility of this method is verified.
8. Summary and Prospect
This paper improves the performance of Kalman filter for nonlinear system, contains the respective advantages of UKF and EnKF, overcomes the shortcomings of UKF and EnKF and establishes a new design method of Kalman filter based on sampling data drive. Firstly, a new sampling mechanism is proposed. Based on the sigma sampling with UKF statistical constraints, the sampling mechanism performs random sampling similar to EnKF around each sampling point, so as to obtain the large sample data ensemble of the characteristics of the system variables to be estimated. It overcomes the shortcomings of UKF and EnKF in the sampling mechanism. Secondly, a sample weight selection and assignment mechanism based on the centroid of data set is established, which overcomes the defects of UKF and EnKF in weight selection. Thirdly, combining the advantages of the two methods, a new Kalman filter driven by large data sample ensemble is established. Finally, through computer numerical simulation experiments, via different parameters, the best estimates under different conditions are obtained, which verify the effectiveness of the method in this paper.
Prospect: Although the method proposed in this paper solves the defects of UKF and EnKF, it is still insufficient. These sampling mechanisms are based on the assumption that the state to be estimated is normal distribution, but the state to be estimated is often a non-Gaussian variable that is difficult to conform to the normal distribution. How to establish a sampling mechanism that conforms to the real characteristics is the direction that still requires hard work. For non-Gaussian systems, further research is needed.




{kind=link}
{kind=link}