
Machine Learning-Based Fault Location for Smart Distribution Networks Equipped with Micro-PMU




Abstract
:1. Introduction
- A novel non-iterative fault location method is presented to identify the faulty sections in the smart distribution network equipped with only DGs using voltage data.
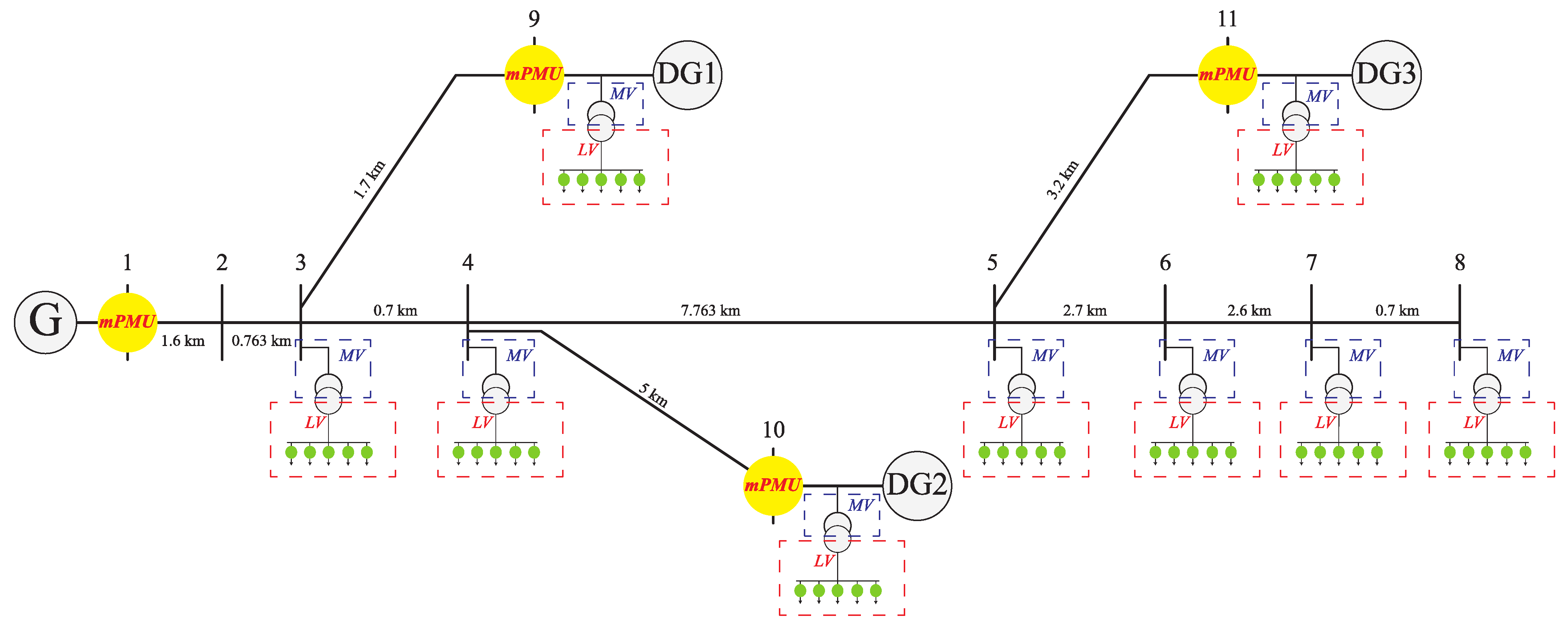
- This strategy uses only the recorded voltage waveform at the sub-station as well as any other network resources with a sampling rate of 5 kHz.
- The proposed machine learning-based method is not sensitive to fault characteristics and functions in real-time without any extra information of protection relays.
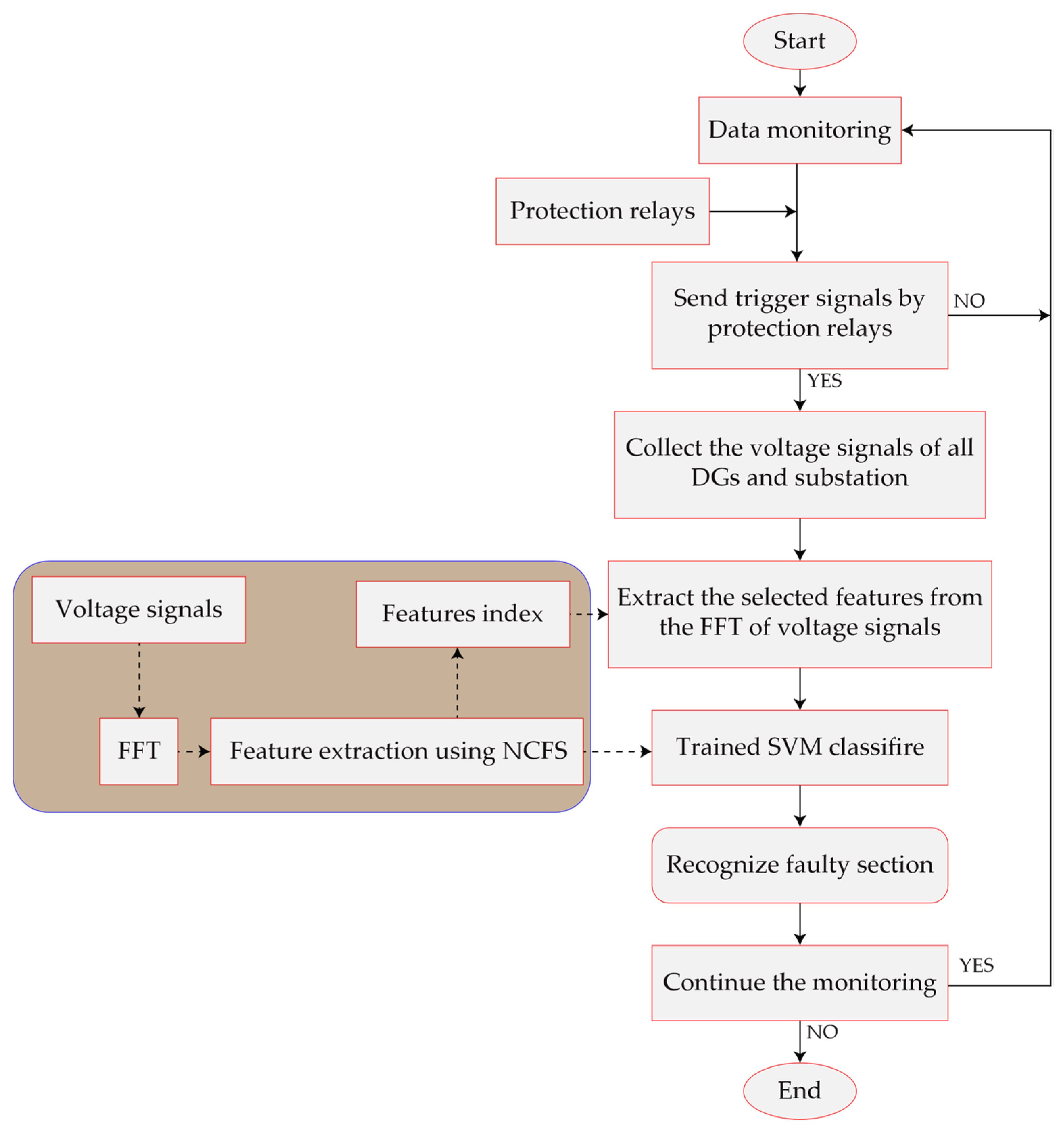
2. Proposed Method
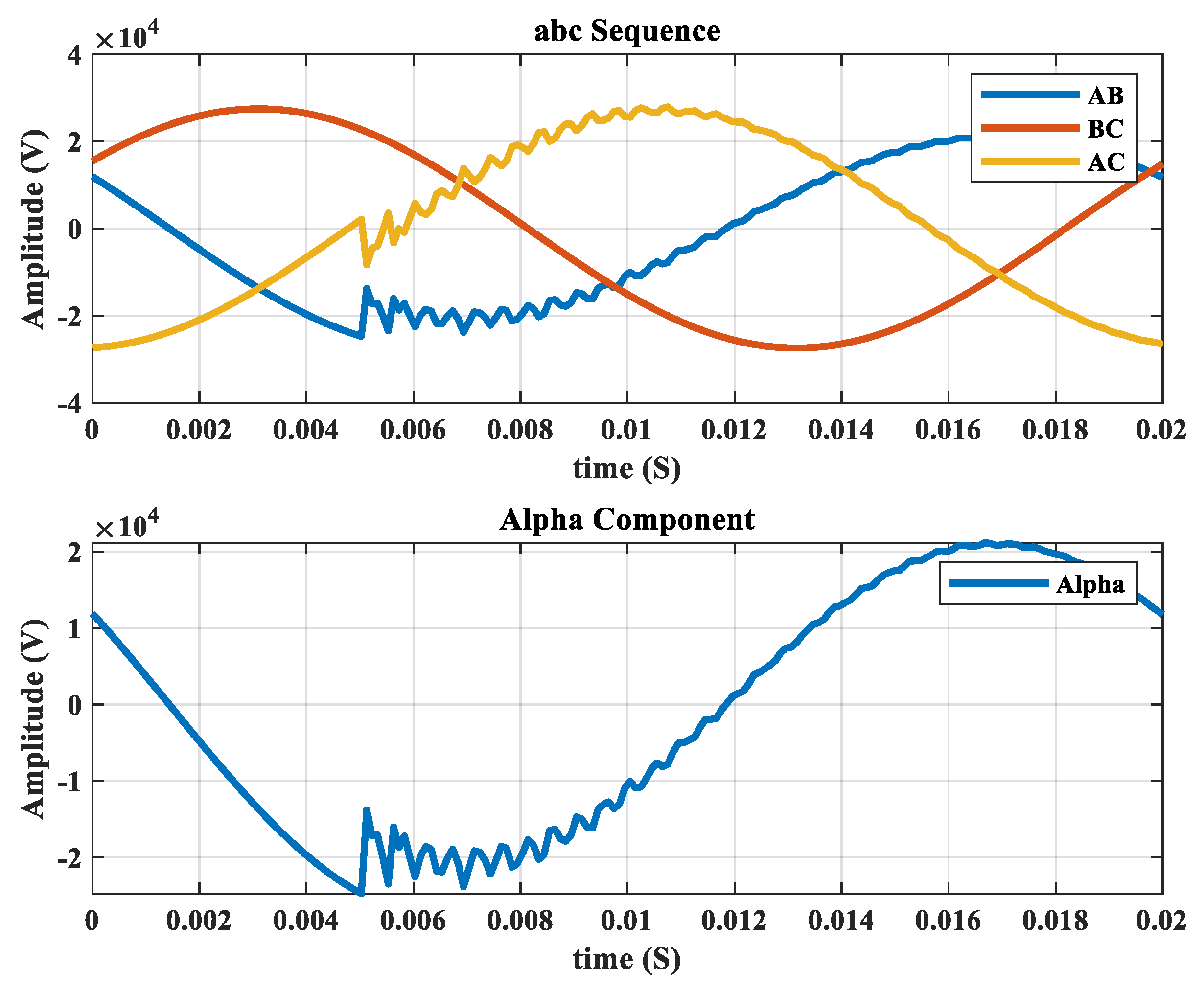
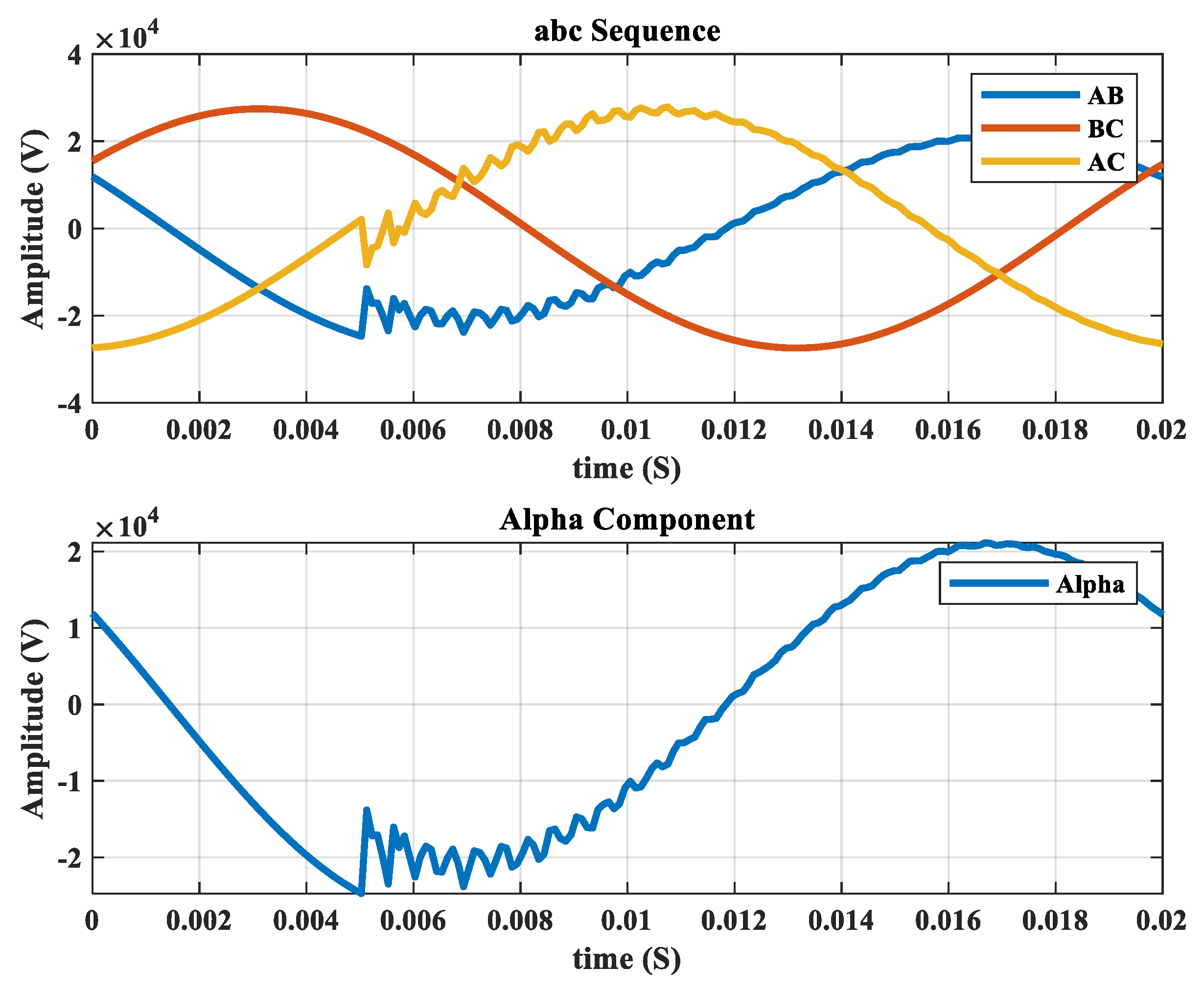
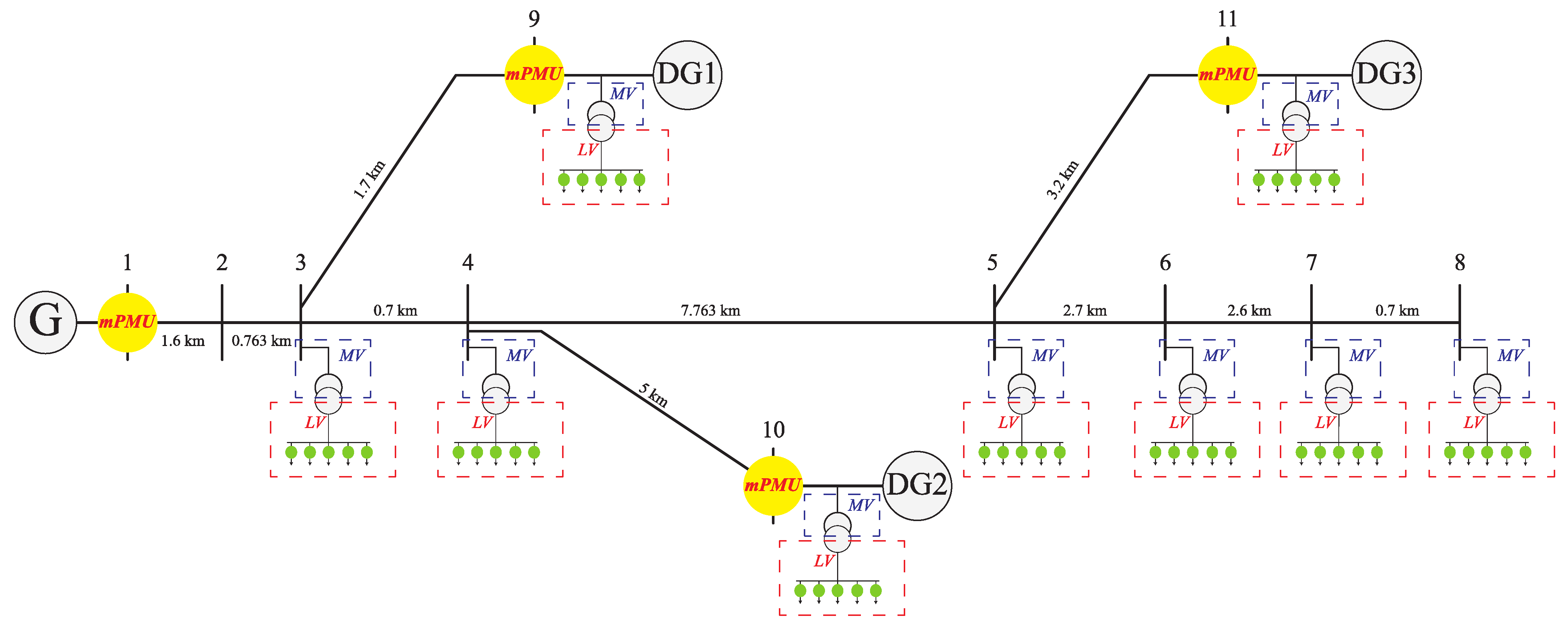
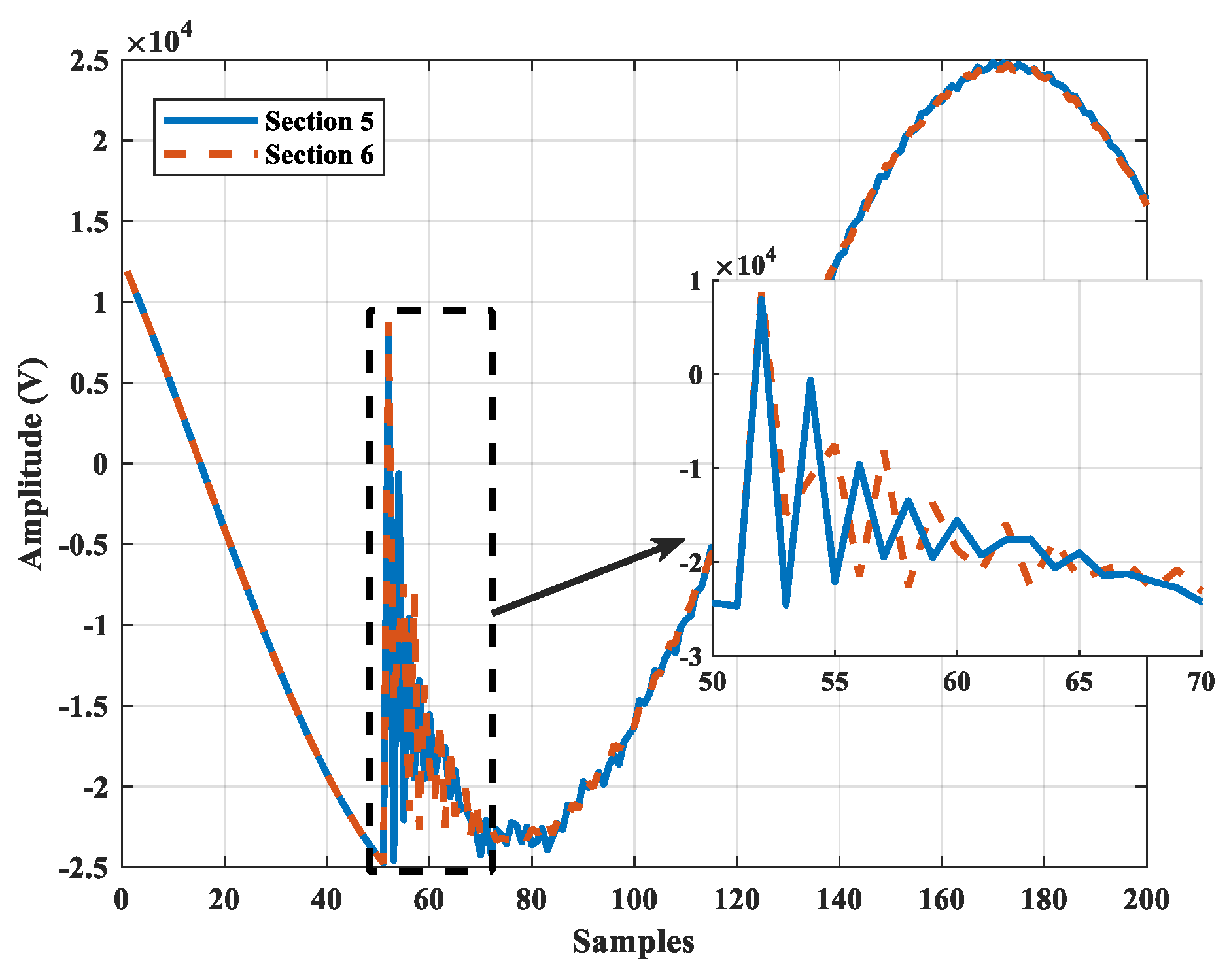
2.1. Data Set
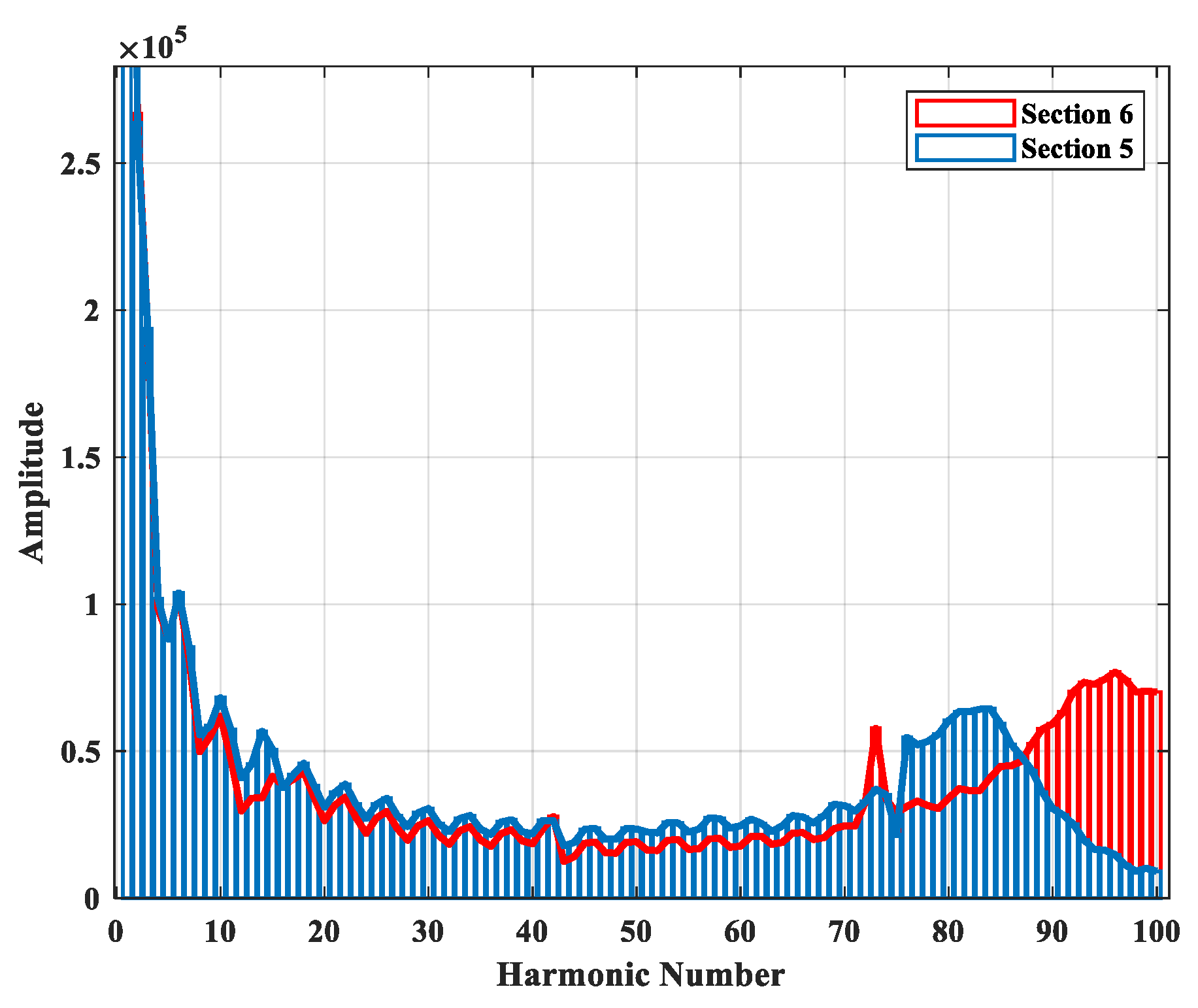
2.2. Neighborhood Component Analysis
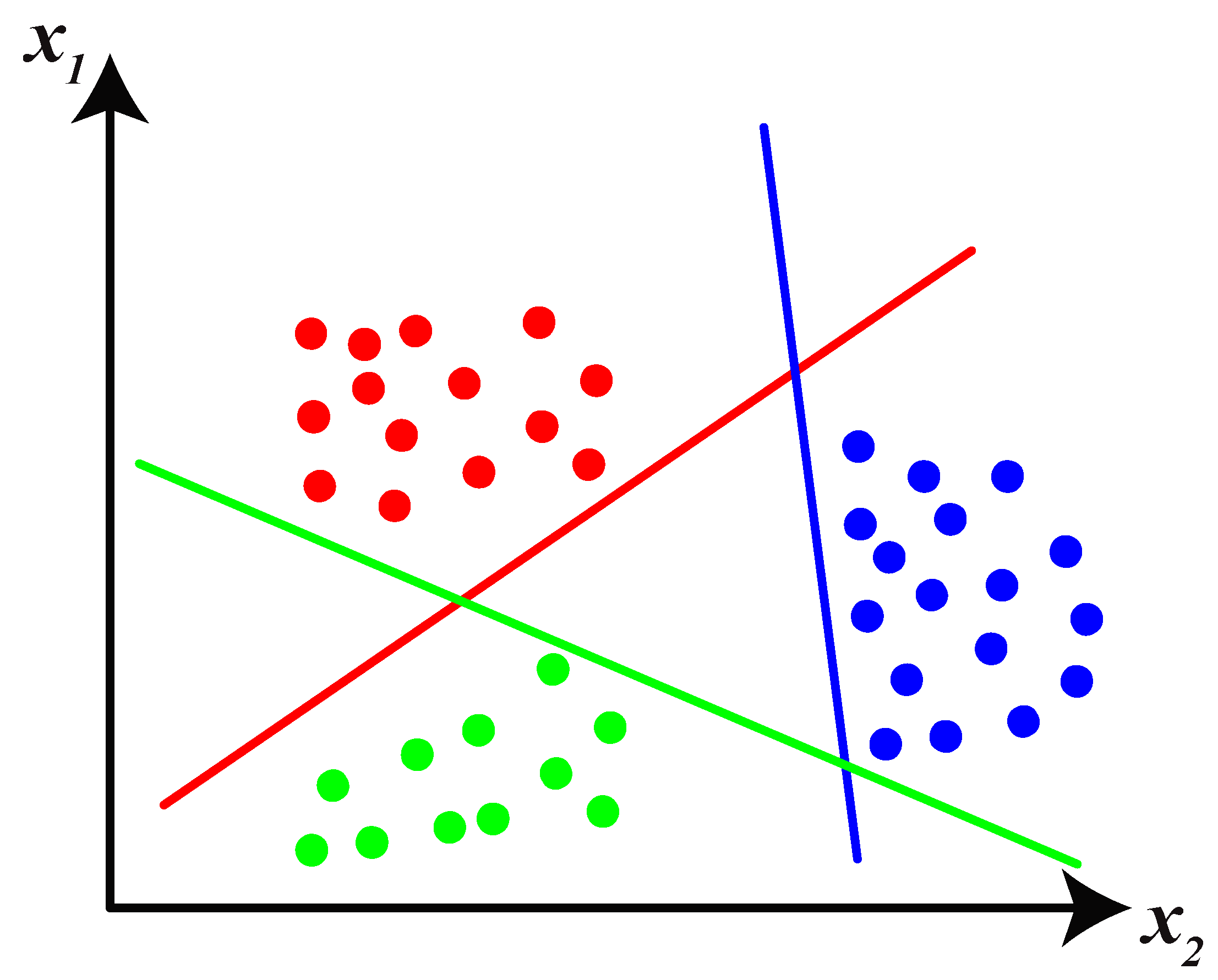
2.3. Support Vector Machine Classifier
| Algorithm 1. Machine Learning-Based Fault Location | ||
| Input—pre-trained platform, recorded voltage of micro-PMUs | ||
| Offline process: Training process | ||
| 1: | Simulate the real-world feeder using monitoring room information for different fault scenarios | |
| 2: | Gather the recorded voltage data of all fault scenarios | |
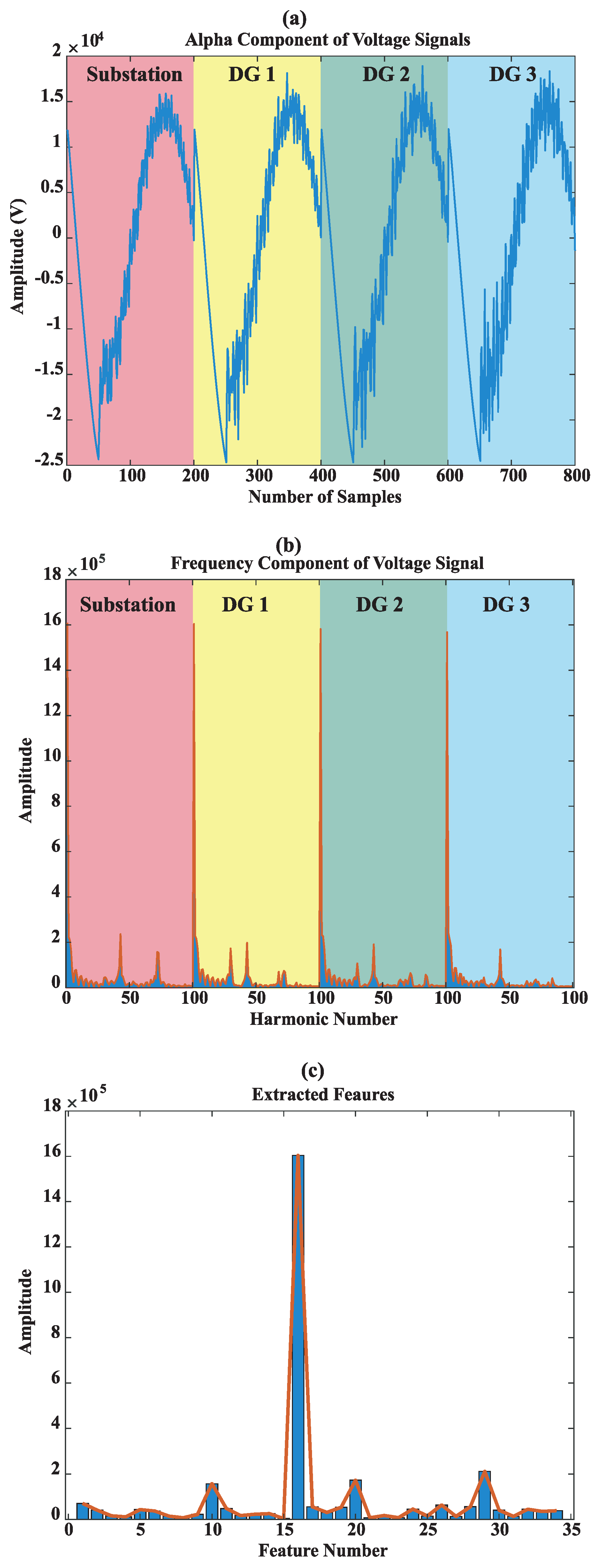
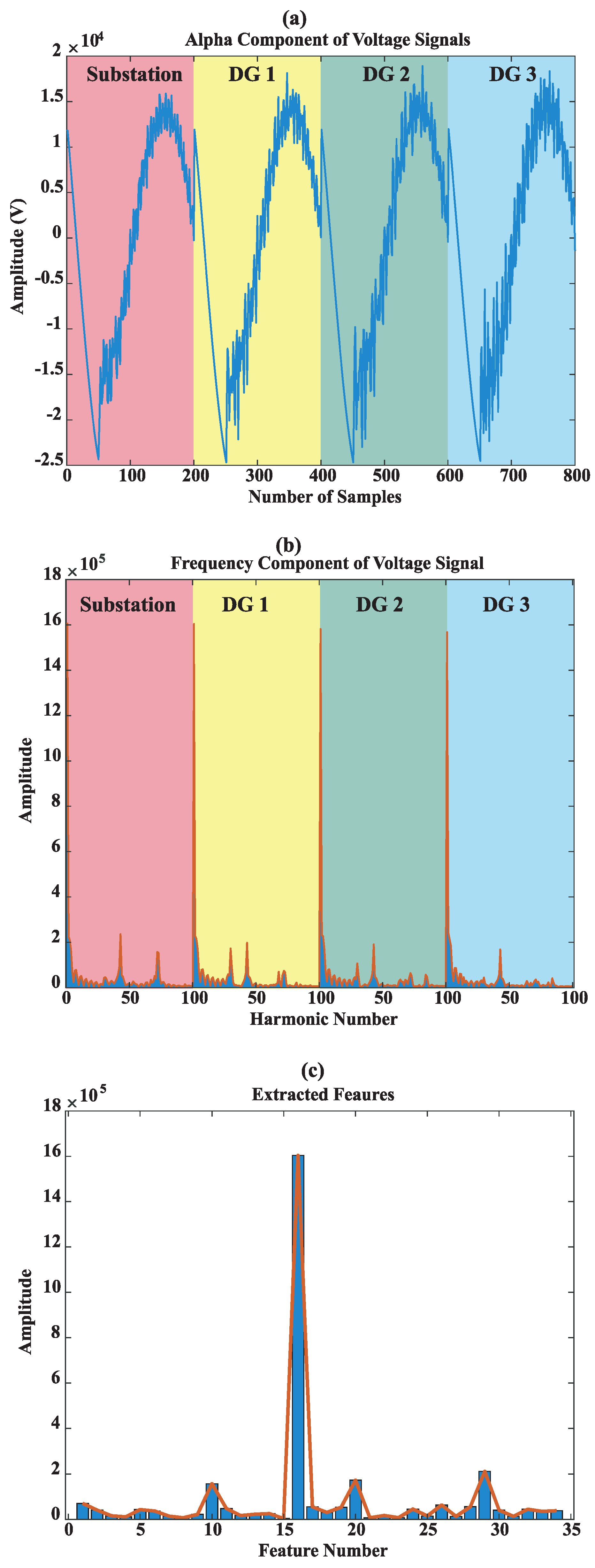
| 3: | Extract the alpha component of the voltage signals | |
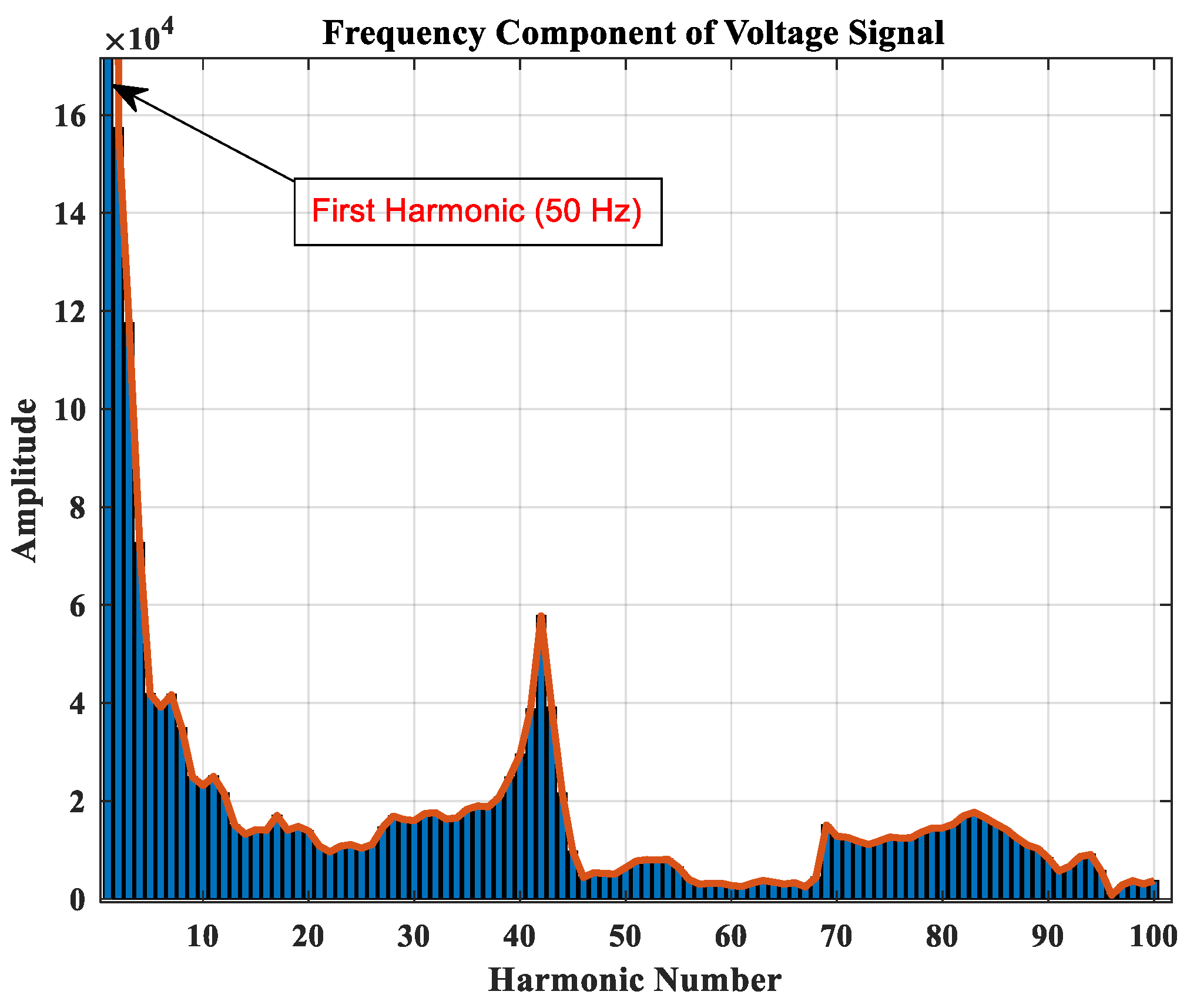
| 4: | Perform frequency spectrum analysis of the voltage signals and generate feature vectors | |
| 5: | Extract more informative features of training data vectors to lower the dimension of feature vectors using NCFS algorithm | |
| 6: | Attach each feature vector label to prepare for the training process | |
| 7: | Train the SVM to determine the linear boundary of each class with hyperplanes | |
| 8: | The machine learning-based fault location platform is ready | |
| 9: | End | |
| Real-time process: Fault location | ||
| 1: | Monitor the network | |
| 2: | If the protection relay sends the trigger signals, then collect the recorded voltage data, otherwise go back to Step 1 | |
| 3: | Perform frequency spectrum analysis of the voltage signals | |
| 4: | Extract the pre-determined features using the feature extraction index | |
| 5: | Feed the data to the pre-trained SVM | |
| 6: | Print the determined class as the faulty section | |
| 7: | Monitor the network as in Step 1 | |
| 8: | End | |
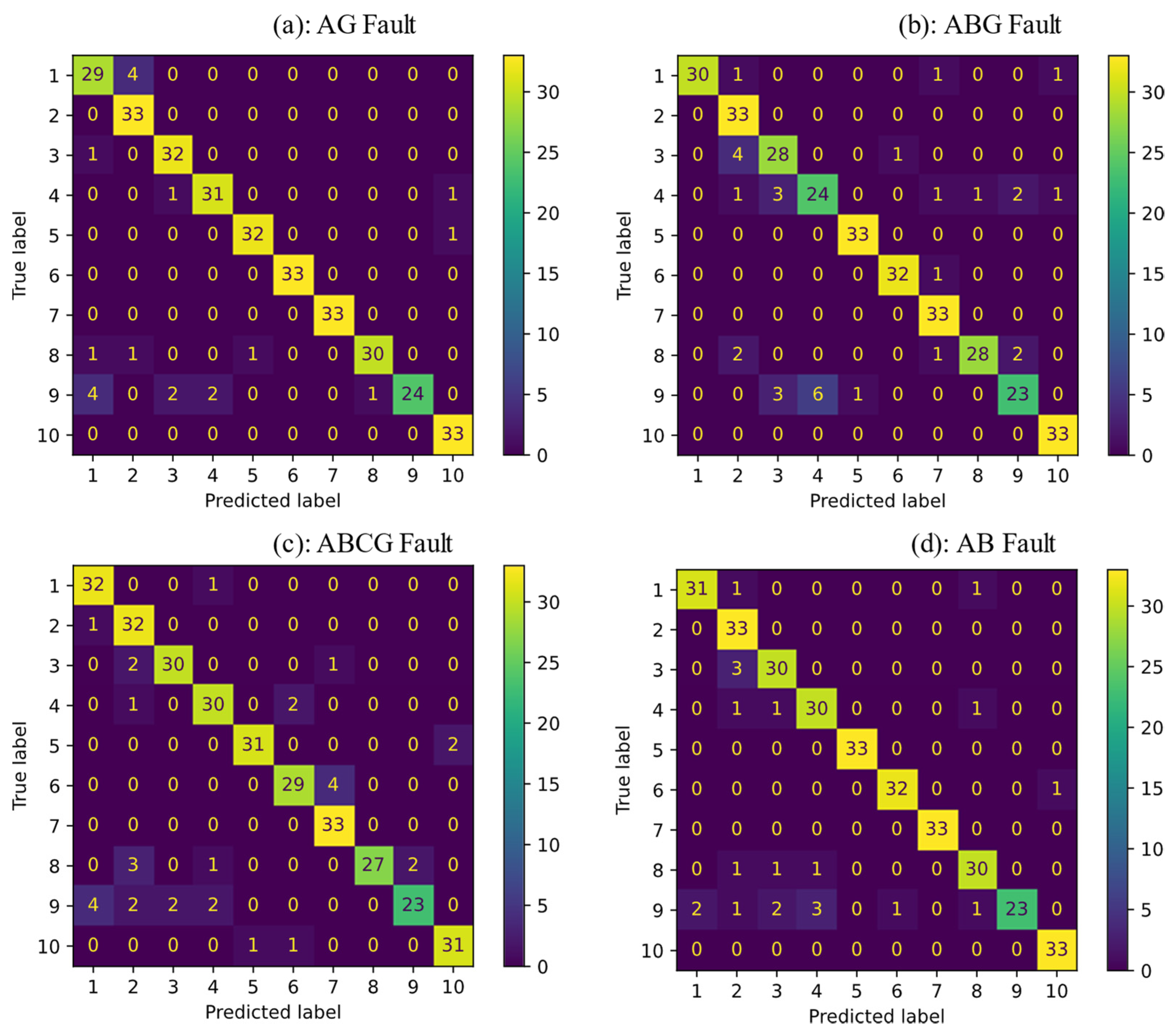
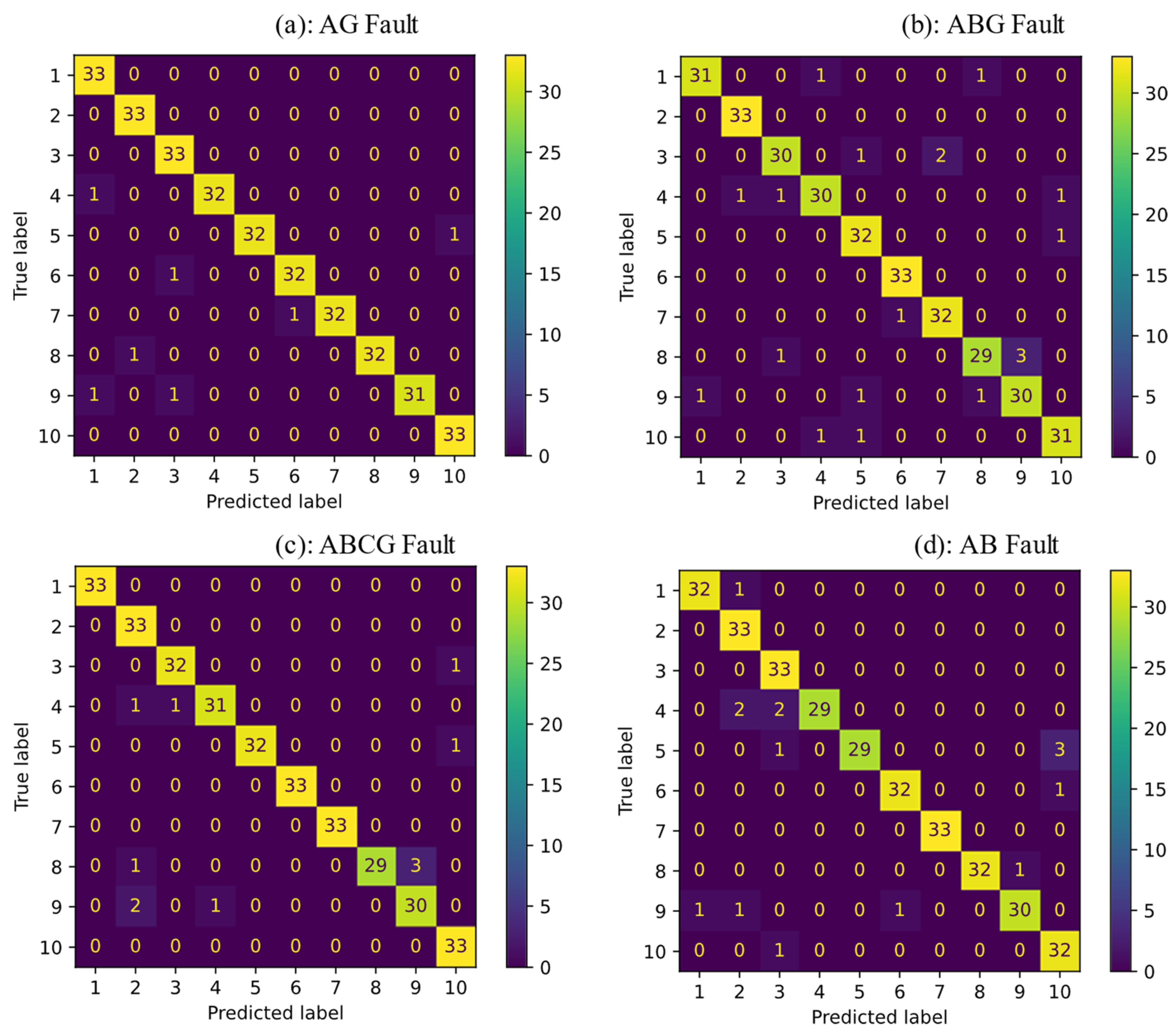
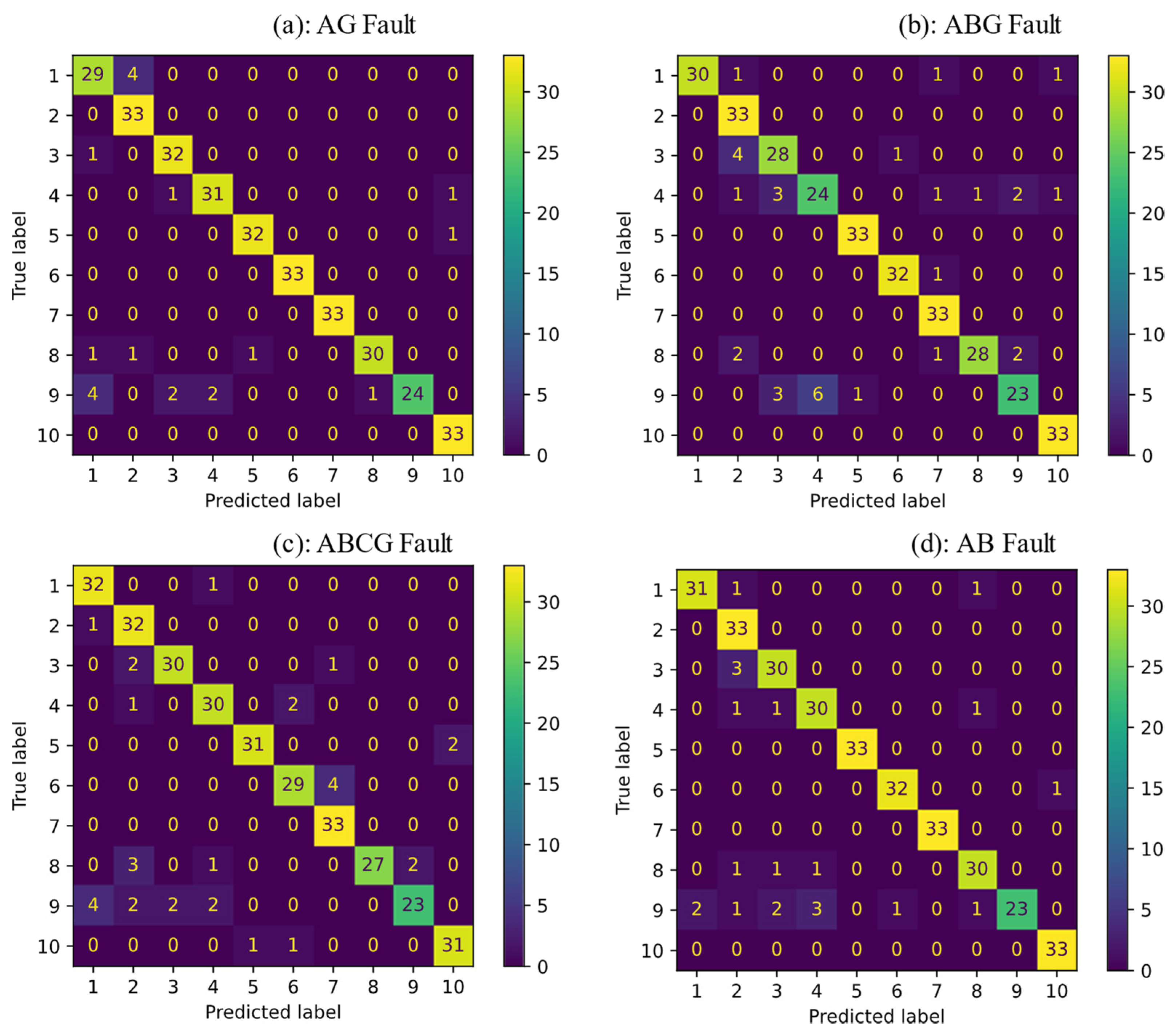
3. Simulation Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mirshekali, H.; Dashti, R.; Shaker, H.R.; Samsami, R.; Torabi, A.J. Linear and Nonlinear Fault Location in Smart Distribution Network under Line Parameter Uncertainty. IEEE Trans. Ind. Inform. 2021, 17, 8308–8318. [Google Scholar] [CrossRef]
- Shadi, M.R.; Ameli, M.T.; Azad, S. A real-time hierarchical framework for fault detection, classification, and location in power systems using PMUs data and deep learning. Int. J. Electr. Power Energy Syst. 2022, 134, 107399. [Google Scholar] [CrossRef]
- Parejo, A.; Personal, E.; Larios, D.F.; Guerrero, J.I.; García, A.; León, C. Monitoring and Fault Location Sensor Network for Underground Distribution Lines. Sensors 2019, 19, 576. [Google Scholar] [CrossRef] [Green Version]
- Dashtdar, M.; Dashtdar, M. Fault Location in Distribution Network Based on Phasor Measurement Units (PMU). Sci. Bull. Electr. Eng. Fac. 2019, 19, 38–43. [Google Scholar] [CrossRef] [Green Version]
- Tiwari, S.; Kumar, A. Hybrid Taguchi-Based Technique for Micro-Phasor Measurement Units Placement in the Grid-Connected Distribution System. IETE J. Res. 2021, 67, 1–13. [Google Scholar] [CrossRef]
- Dusabimana, E.; Yoon, S.G. A Survey on the Micro-Phasor Measurement Unit in Distribution Networks. Electronics 2020, 9, 305. [Google Scholar] [CrossRef] [Green Version]
- Mirshekali, H.; Dashti, R.; Shaker, H.R. A novel fault location algorithm for electrical networks considering distributed line model and distributed generation resources. In Proceedings of the 2020 IEEE PES Innovative Smart Grid Technologies Europe (ISGT-Europe), The Hague, The Netherlands, 26–28 October 2020; pp. 16–20. [Google Scholar] [CrossRef]
- Qiao, J.; Yin, X.; Wang, Y.; Xu, W.; Tan, L. A multi-terminal traveling wave fault location method for active distribution network based on residual clustering. Int. J. Electr. Power Energy Syst. 2021, 131, 107070. [Google Scholar] [CrossRef]
- Forouzesh, A.; Golsorkhi, M.S.; Savaghebi, M.; Baharizadeh, M. Support Vector Machine Based Fault Location Identification in Microgrids Using Interharmonic Injection. Energies 2021, 14, 2317. [Google Scholar] [CrossRef]
- Dashti, R.; Daisy, M.; Mirshekali, H.; Shaker, H.R.; Hosseini Aliabadi, M. A survey of fault prediction and location methods in electrical energy distribution networks. Measurement 2021, 184, 109947. [Google Scholar] [CrossRef]
- de Aguiar, R.A.; Dalcastagnê, A.L.; Zürn, H.H.; Seara, R. Impedance-based fault location methods: Sensitivity analysis and performance improvement. Electr. Power Syst. Res. 2018, 155, 236–245. [Google Scholar] [CrossRef]
- Mirshekali, H.; Dashti, R.; Keshavarz, A.; Torabi, A.J.; Shaker, H.R. A Novel Fault Location Methodology for Smart Distribution Networks. IEEE Trans. Smart Grid 2020, 12, 1277–1288. [Google Scholar] [CrossRef]
- Ananthan, S.N.; Bastos, A.F.; Santoso, S. Novel system model-based fault location approach using dynamic search technique. IET Gener. Transm. Distrib. 2021, 15, 1403–1420. [Google Scholar] [CrossRef]
- Dashtdar, M.; Sadegh Hosseinimoghadam, S.M.; Dashtdar, M. Fault location in the distribution network based on power system status estimation with smart meters data. Int. J. Emerg. Electr. Power Syst. 2021, 22, 129–147. [Google Scholar] [CrossRef]
- Mirshekali, H.; Dashti, R.; Handrup, K.; Shaker, H.R. Real fault location in a distribution network using smart feeder meter data. Energies 2021, 14, 3242. [Google Scholar] [CrossRef]
- Merlin Sajini, M.L.; Suja, S.; Merlin Gilbert Raj, S. Impact analysis of time-varying voltage-dependent load models on hybrid DG planning in a radial distribution system using analytical approach. IET Renew. Power Gener. 2021, 15, 153–172. [Google Scholar] [CrossRef]
- Arsoniadis, C.G.; Apostolopoulos, C.A.; Georgilakis, P.S.; Nikolaidis, V.C. A voltage-based fault location algorithm for medium voltage active distribution systems. Electr. Power Syst. Res. 2021, 196, 107236. [Google Scholar] [CrossRef]
- Aftab, M.A.; Hussain, S.M.S.; Ali, I.; Ustun, T.S. Dynamic protection of power systems with high penetration of renewables: A review of the traveling wave based fault location techniques. Int. J. Electr. Power Energy Syst. 2020, 114, 105410. [Google Scholar] [CrossRef]
- Naidu, O.D.; Pradhan, A.K. Precise Traveling Wave-Based Transmission Line Fault Location Method Using Single-Ended Data. IEEE Trans. Ind. Inform. 2021, 17, 5197–5207. [Google Scholar] [CrossRef]
- Zhang, J.; Gong, Q.; Zhang, H.; Wang, Y.; Wang, Y. A Novel Pix2Pix Enabled Traveling Wave-Based Fault Location Method. Sensors 2021, 21, 1633. [Google Scholar] [CrossRef]
- Liang, R.; Wang, F.; Fu, G.; Xue, X.; Zhou, R. A general fault location method in complex power grid based on wide-area traveling wave data acquisition. Int. J. Electr. Power Energy Syst. 2016, 83, 213–218. [Google Scholar] [CrossRef]
- Marín-Quintero, J.; Orozco-Henao, C.; Percybrooks, W.S.; Vélez, J.C.; Montoya, O.D.; Gil-González, W. Toward an adaptive protection scheme in active distribution networks: Intelligent approach fault detector. Appl. Soft Comput. 2021, 98, 106839. [Google Scholar] [CrossRef]
- Chen, Y.Q.; Fink, O.; Sansavini, G. Combined Fault Location and Classification for Power Transmission Lines Fault Diagnosis With Integrated Feature Extraction. IEEE Trans. Ind. Electron. 2018, 65, 561–569. [Google Scholar] [CrossRef]
- Zhang, Y.G.; Tang, J.; He, Z.Y.; Tan, J.; Li, C. A novel displacement prediction method using gated recurrent unit model with time series analysis in the Erdaohe landslide. Nat. Hazards 2021, 105, 783–813. [Google Scholar] [CrossRef]
- Shadi, M.R.; Mirshekali, H.; Dashti, R.; Ameli, M.T.; Shaker, H.R. A Parameter-Free Approach for Fault Section Detection on Distribution Networks Employing Gated Recurrent Unit. Energies 2021, 14, 6361. [Google Scholar] [CrossRef]
- Keshavarz, A.; Dashti, R.; Deljoo, M.; Shaker, H.R. Fault location in distribution networks based on SVM and impedance-based method using online databank generation. Neural Comput. Appl. 2021, 33, 1–17. [Google Scholar] [CrossRef]
- Jia, K.; Yang, B.; Bi, T.; Zheng, L. An Improved Sparse-Measurement-Based Fault Location Technology for Distribution Networks. IEEE Trans. Ind. Inform. 2021, 17, 1712–1720. [Google Scholar] [CrossRef]
- Majidi, M.; Arabali, A.; Etezadi-Amoli, M. Fault Location in Distribution Networks by Compressive Sensing. IEEE Trans. Power Deliv. 2015, 30, 1761–1769. [Google Scholar] [CrossRef]
- Carta, D.; Pegoraro, P.A.; Sulis, S.; Pau, M.; Ponci, F.; Monti, A. A Compressive Sensing Approach for Fault Location in Distribution Grid Branches. In Proceedings of the SEST 2019—2nd International Conference on Smart Energy Systems and Technologies (SEST), Porto, Portugal, 9–11 September 2019. [Google Scholar] [CrossRef]
- Rai, P.; Londhe, N.D.; Raj, R. Fault classification in power system distribution network integrated with distributed generators using CNN. Electr. Power Syst. Res. 2021, 192, 106914. [Google Scholar] [CrossRef]
- Mishra, M.; Rout, P.K. Detection and classification of micro-grid faults based on HHT and machine learning techniques. IET Gener. Transm. Distrib. 2018, 12, 388–397. [Google Scholar] [CrossRef]
- Chen, K.; Hu, J.; Zhang, Y.; Yu, Z.; He, J. Fault Location in Power Distribution Systems via Deep Graph Convolutional Networks. IEEE J. Sel. Areas Commun. 2020, 38, 119–131. [Google Scholar] [CrossRef] [Green Version]
- Dashtdar, M. Fault Location in Distribution Network Based on Fault Current Analysis Using Artificial Neural Network. Mapta J. Electr. Comput. Eng. 2018, 1, 18–32. [Google Scholar] [CrossRef]
- Zhan, L.; Liu, Y.; Liu, Y. A Clarke transformation-based DFT phasor and frequency algorithm for wide frequency range. IEEE Trans. Smart Grid 2018, 9, 67–77. [Google Scholar] [CrossRef]
- Yang, W.; Wang, K.; Zuo, W. Neighborhood component feature selection for high-dimensional data. J. Comput. 2012, 7, 162–168. [Google Scholar] [CrossRef]
- Gao, X.; Fan, L.; Xu, H. Multiple rank multi-linear kernel support vector machine for matrix data classification. Int. J. Mach. Learn. Cybern. 2018, 9, 251–261. [Google Scholar] [CrossRef]
- Farshad, M.; Sadeh, J. Accurate single-phase fault-location method for transmission lines based on K-nearest neighbor algorithm using one-end voltage. IEEE Trans. Power Deliv. 2012, 27, 2360–2367. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics/References | [30] | [31] | [32] | [33] | Proposed Method |
|---|---|---|---|---|---|
| Network type | R/L | R/L | R/L | R | R/L |
| Line type | DLM | DLM | DLM | DLM | DLM |
| Method type | CNN | NBC–SVM–ELM | GCN | ANN | SVM |
| Features | Wavelet | HHT | Phasor | Wavelet | FFT |
| Data type | Voltage and current | Current | Voltage and current | Current | Voltage |
| Fault type | All | All | All | All | All |
| DG | Yes | Yes | No | No | Yes |
| Feature extraction | Automatic | No | No | No | NCA |
| Complexity | High | Low | Normal | Normal | Low |
| Number of measurements | All nodes | All nodes | Limited nodes | At the sub-station | Equal to the resources |
| Advantages | 1, 2, 3, 14, | 2, 3, 7, 12, 14, 23 | 1, 2, 9, 14, 22 | 2, 3, 19 | 2, 3, 7, 12, 14, 15, 20, 23 |
| Disadvantages | 4, 5, 6, 11, 16, 18 | 4, 13, 17, 18 | 4, 6, 9, 10, 11, 13, 16, 21 | 4, 5, 6, 8, 11, 17 | 4, 13 |
| Parameters | Details | Count |
|---|---|---|
| Structure | Radial | 1 |
| Line sections | All lines of 11-node ieee bus | 10 |
| Fault type | AG, ABG, ABCG, AB | 4 |
| Fault spots in each section | 10%, 20%, 30%, 40%, 50% 60%, 70%, 80% and 90% of each section | 9 |
| Fault resistance | 11 | |
| All scenarios | Each fault type | 990 |
| Methods\Fault Type | AG | ABG | ABCG | AB |
|---|---|---|---|---|
| SVM | 97.87% | 94.24% | 96.66% | 95.45% |
| KNN | 93.93% | 90% | 90.3% | 93.33% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mirshekali, H.; Dashti, R.; Keshavarz, A.; Shaker, H.R. Machine Learning-Based Fault Location for Smart Distribution Networks Equipped with Micro-PMU. Sensors 2022, 22, 945. https://doi.org/10.3390/s22030945
Mirshekali H, Dashti R, Keshavarz A, Shaker HR. Machine Learning-Based Fault Location for Smart Distribution Networks Equipped with Micro-PMU. Sensors. 2022; 22(3):945. https://doi.org/10.3390/s22030945
Chicago/Turabian StyleMirshekali, Hamid, Rahman Dashti, Ahmad Keshavarz, and Hamid Reza Shaker. 2022. "Machine Learning-Based Fault Location for Smart Distribution Networks Equipped with Micro-PMU" Sensors 22, no. 3: 945. https://doi.org/10.3390/s22030945
APA StyleMirshekali, H., Dashti, R., Keshavarz, A., & Shaker, H. R. (2022). Machine Learning-Based Fault Location for Smart Distribution Networks Equipped with Micro-PMU. Sensors, 22(3), 945. https://doi.org/10.3390/s22030945