
From Perception to Navigation in Environments with Persons: An Indoor Evaluation of the State of the Art



Abstract
:1. Introduction
- We complete a list of commercial sensors with their characteristics and limitations used in social navigation to ease their selection according to specific application requirements;
- We present different methods for successful navigation, including mapping and trajectory prediction, along with their advantages and limitations, to facilitate their adoption depending on the target scenario;
- We list the available datasets and related work about perception and prediction, which could support the evaluation of social robotics solutions.
2. Perception
2.1. RGB-D Cameras
2.2. 2D LiDARs
2.3. 3D LiDARs
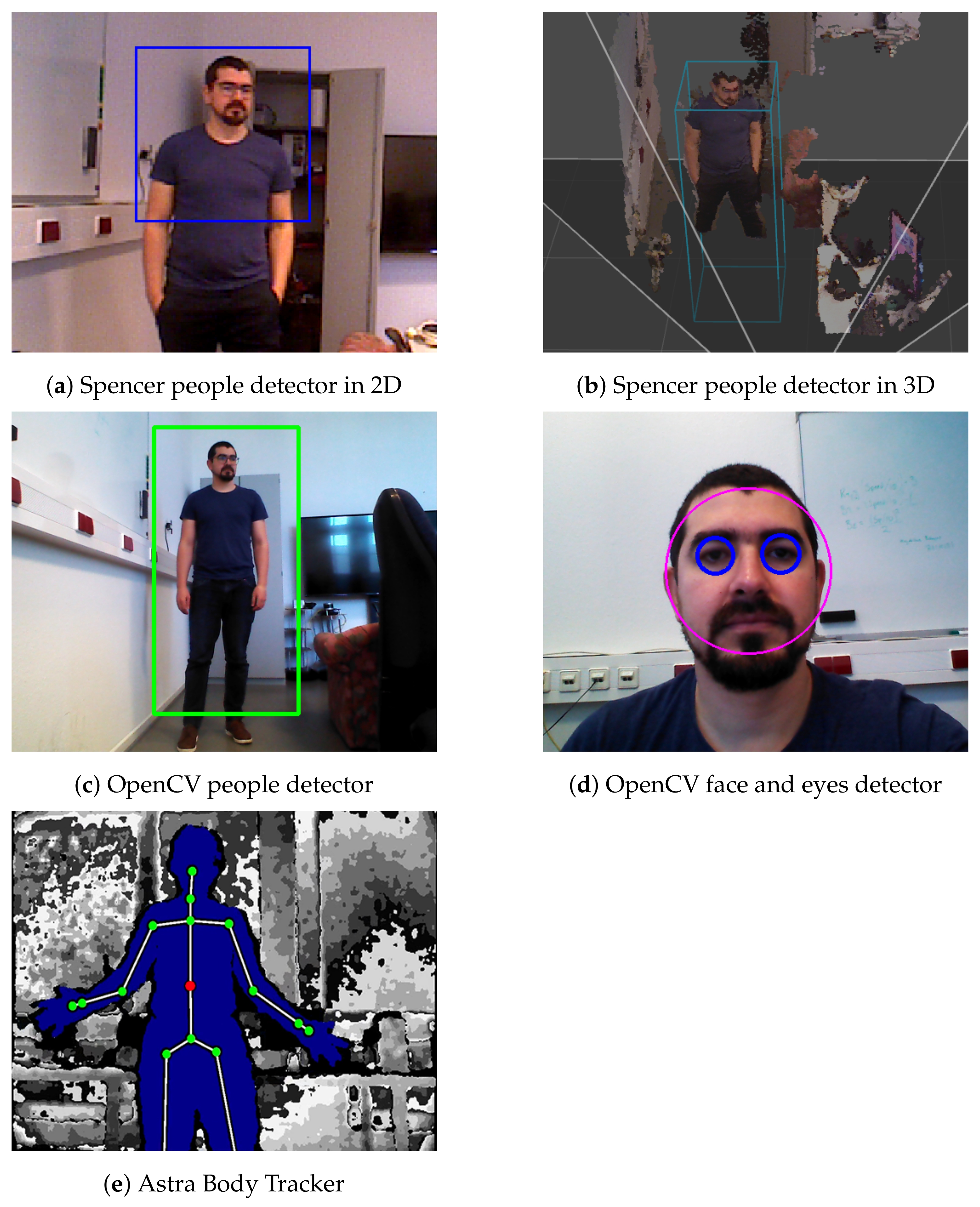
2.4. People Detection
2.5. Summary
3. Mapping
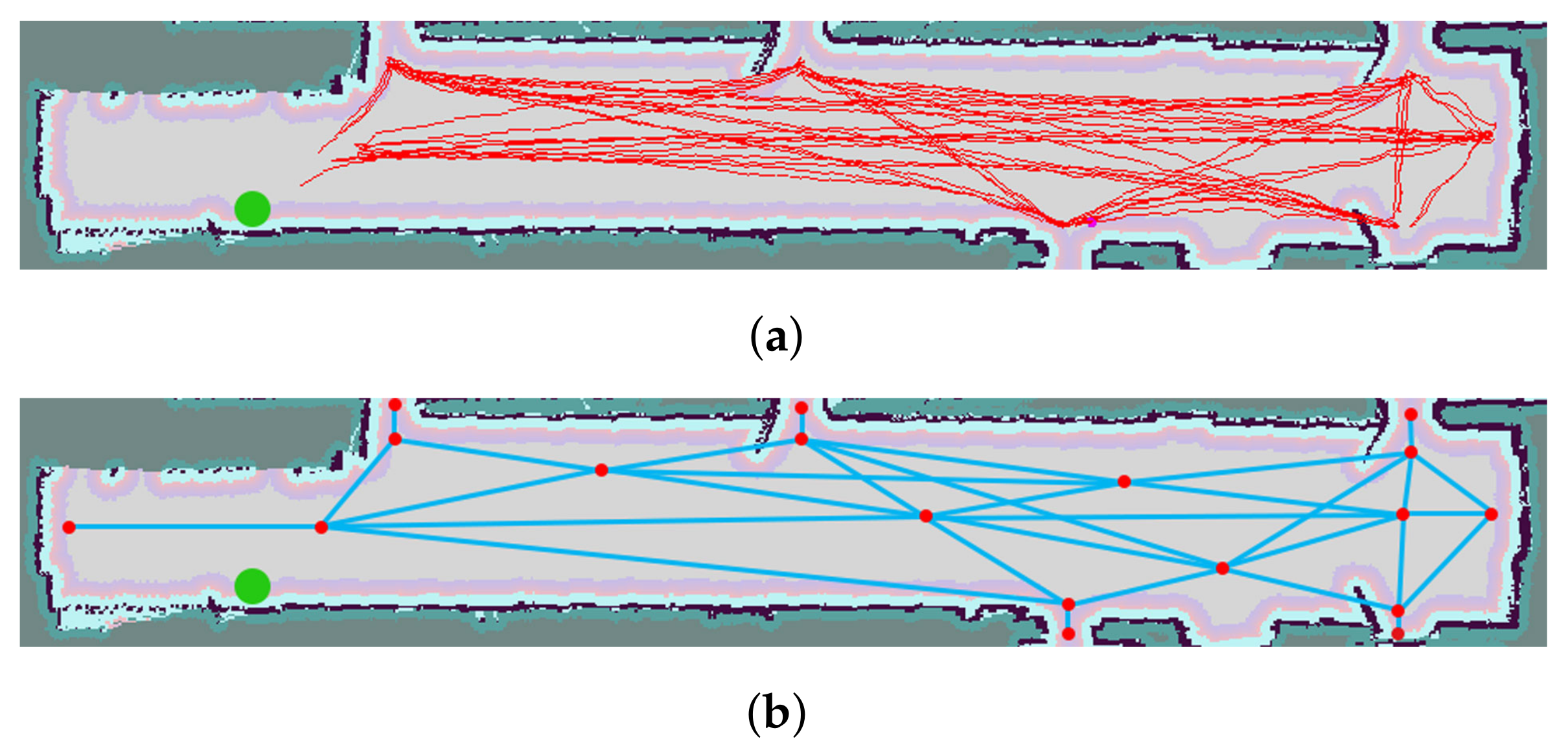
3.1. Geometric Mapping
3.1.1. 2D SLAM
3.1.2. 3D SLAM
3.2. Semantic Mapping
3.3. Summary
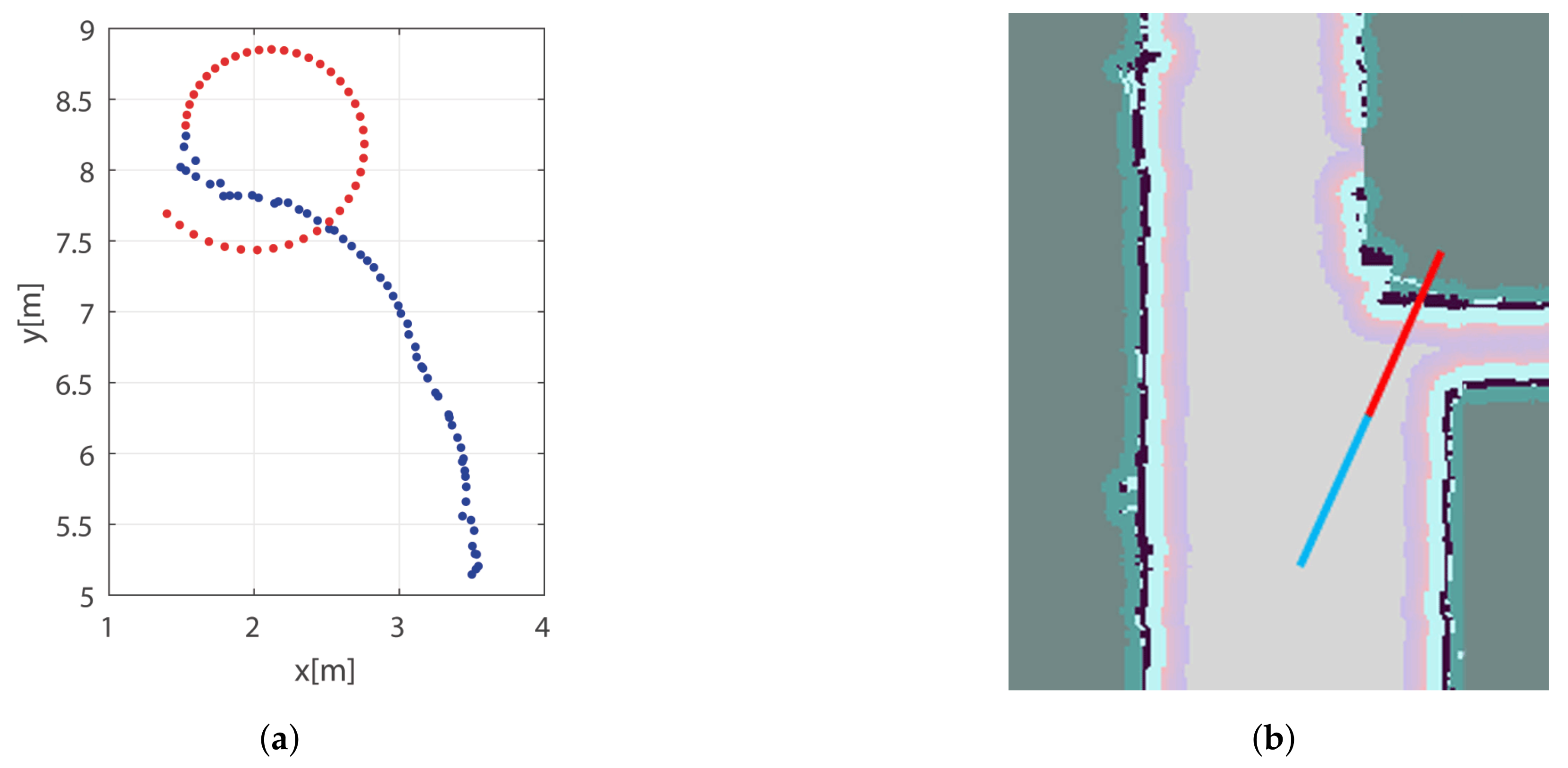
4. Human Motion Prediction
4.1. Physics Based
4.2. Pattern Based
4.3. Planning Based
4.4. Summary
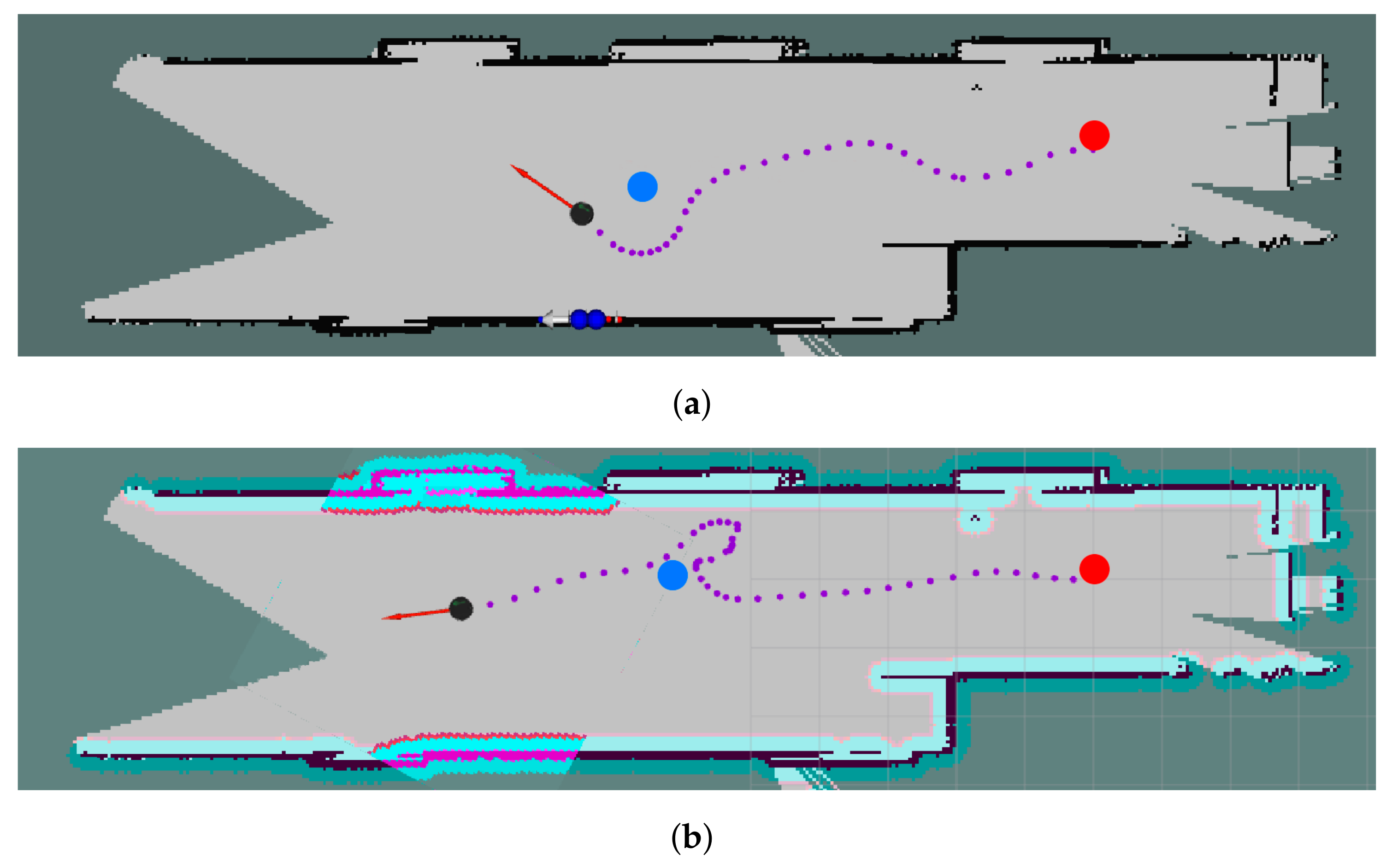
5. Human-Aware Robot Navigation
5.1. Reactive-Based Planning
5.2. Predictive-Based Planning
5.3. Summary
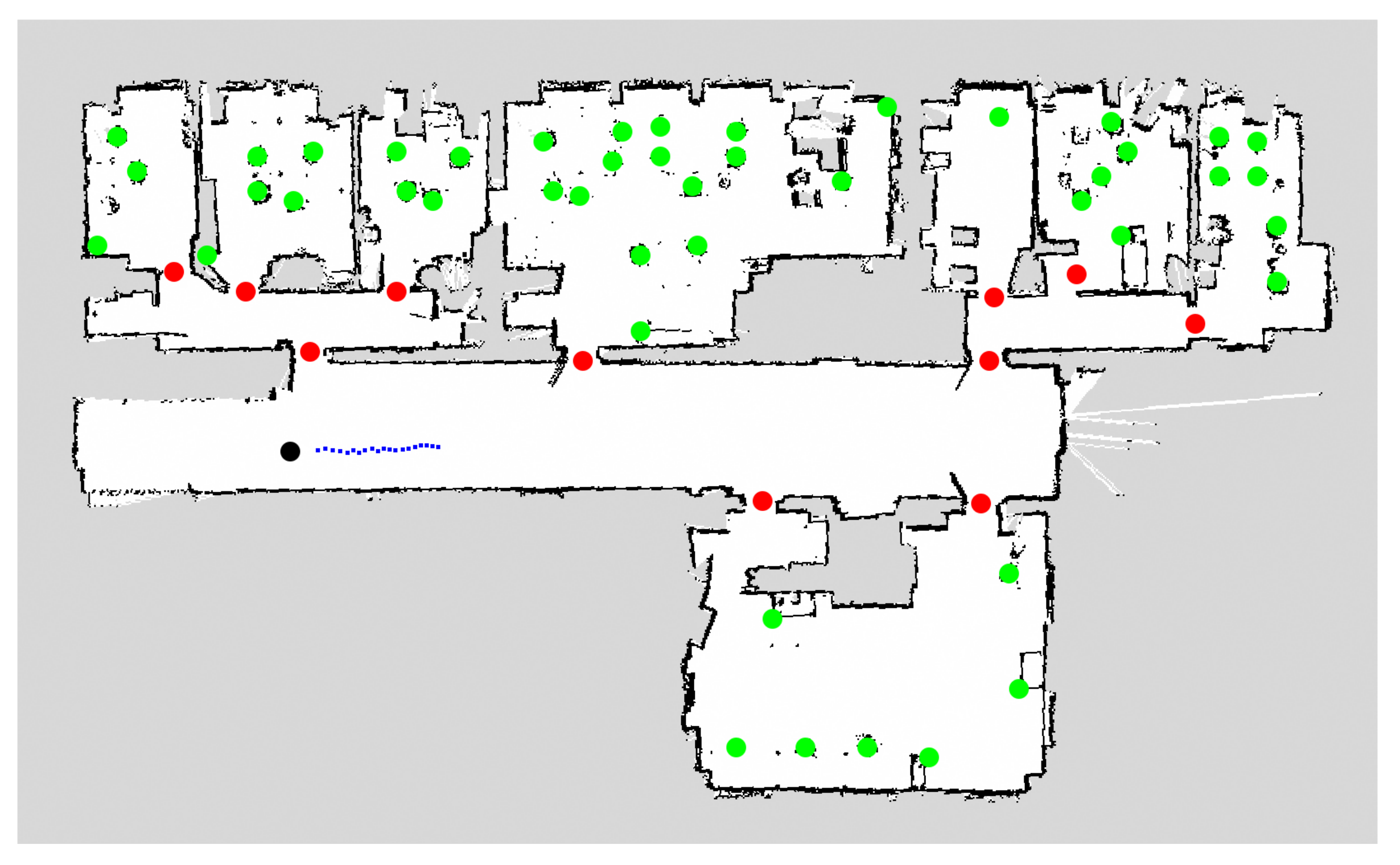
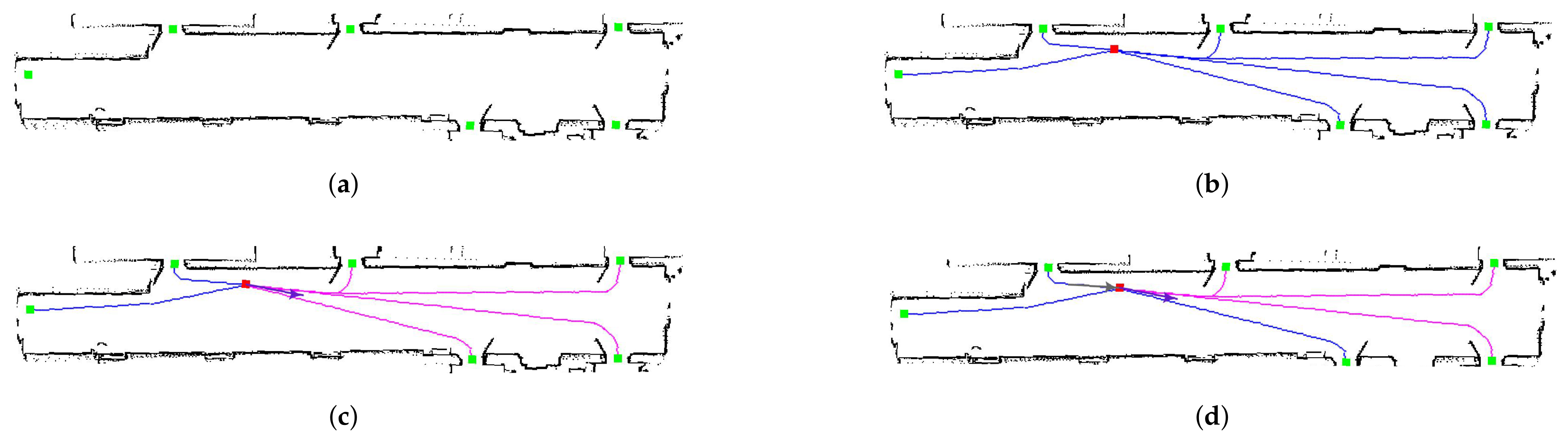
6. Related Datasets
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| FoV | Field of View |
| SSLi | Solid-State LiDARs |
| MLi | Mechanical LiDARs |
| LOAM | LiDAR Odometry and Mapping |
| CNN | Convolutional Neural Networks |
| KF | Kalman Filter |
| EKF | Extended Kalman Filter |
| PF | Particle Filter |
| ROS | Robot Operating System |
| SLAM | Simultaneous Localization and Mapping |
| SDD | Stanford Drone Dataset |
| PSMM | Proactive Social Motion Model |
References
- Perez-Higueras, N.; Ramon-Vigo, R.; Perez-Hurtado, I.; Capitan, J.; Caballero, F.; Merino, L. A social navigation system in telepresence robots for elderly. In Proceedings of the Workshop on the International Conference on Social Robotics, Kansas City, MO, USA, 1–3 November 2016. [Google Scholar]
- Belpaeme, T.; Kennedy, J.; Ramachandran, A.; Scassellati, B.; Tanaka, F. Social robots for education: A review. Sci. Robot. 2018, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Triebel, R.; Arras, K.; Alami, R.; Beyer, L.; Breuers, S.; Chatila, R.; Chetouani, M.; Cremers, D.; Evers, V.; Fiore, M.; et al. Spencer: A socially aware service robot for passenger guidance and help in busy airports. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 607–622. [Google Scholar]
- Pérez-Higueras, N.; Ramón-Vigo, R.; Caballero, F.; Merino, L. Robot local navigation with learned social cost functions. In Proceedings of the 11th International Conference on Informatics in Control, Automation and Robotics (ICINCO), Vienna, Austria, 1–3 September 2014; Volume 2, pp. 618–625. [Google Scholar] [CrossRef]
- Biswas, J.; Veloso, M.M. Localization and navigation of the cobots over long-term deployments. Int. J. Robot. Res. 2013, 32, 1679–1694. [Google Scholar] [CrossRef] [Green Version]
- Irobot. Roomba Vacuum Cleaner. Available online: https://www.irobot.de/ (accessed on 25 November 2021).
- ROS Components. Robotics Store. Available online: https://www.roscomponents.com/en/ (accessed on 25 November 2021).
- Robot Shop. Robotics Store. Available online: https://www.robotshop.com/en/ (accessed on 25 November 2021).
- Stereolabs. Zed Cameras. Available online: https://www.stereolabs.com/ (accessed on 25 November 2021).
- Janzon, S.; Sánchez, C.M.; Zella, M.; Marrón, P.J. Person Re-Identification in Human Following Scenarios: An Experience with RGB-D Cameras. In Proceedings of the Fourth IEEE International Conference on Robotic Computing (IRC), Online, 9–11 November 2020; pp. 424–425. [Google Scholar] [CrossRef]
- ORBBEC. Astra Cameras. Available online: https://orbbec3d.com/ (accessed on 25 November 2021).
- Intel. RealSense Cameras. Available online: https://store.intelrealsense.com/ (accessed on 25 November 2021).
- Xtionprolive. Xtion Cameras. Available online: http://xtionprolive.com/ (accessed on 25 November 2021).
- Microsoft. Azure Kinect DK. Available online: https://www.microsoft.com/en-us/p/azure-kinect-dk/8pp5vxmd9nhq?activetab=pivot:techspecstab (accessed on 25 November 2021).
- Yujinrobot. YRL2-05. Available online: https://yujinrobot.com/autonomous-mobility-solutions/components/lidar/ (accessed on 25 November 2021).
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–17 July 2014; Volume 2. [Google Scholar]
- Chen, M.; Yang, S.; Yi, X.; Wu, D. Real-time 3D mapping using a 2D laser scanner and IMU-aided visual SLAM. In Proceedings of the IEEE International Conference on Real-time Computing and Robotics (RCAR), Okinawa, Japan, 14–18 July 2017; pp. 297–302. [Google Scholar]
- Pantofaru, C. Leg Detector. Available online: http://wiki.ros.org/leg_detector (accessed on 25 November 2021).
- Sun, R.; Gao, Y.; Fang, Z.; Wang, A.; Zhong, C. Ssl-net: Point-cloud generation network with self-supervised learning. IEEE Access 2019, 7, 82206–82217. [Google Scholar] [CrossRef]
- Livox. LiDARs Store. Available online: https://www.livoxtech.com/ (accessed on 25 November 2021).
- Leigh, A.; Pineau, J.; Olmedo, N.; Zhang, H. Person tracking and following with 2d laser scanners. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 25–30 May 2015; pp. 726–733. [Google Scholar]
- Bayu Dewantara, B.S.; Dhuha, S.; Marta, B.S.; Pramadihanto, D. FFT-based Human Detection using 1-D Laser Range Data. In Proceedings of the 2020 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 22–23 July 2020; pp. 305–310. [Google Scholar] [CrossRef]
- Bellotto, N.; Hu, H. Multisensor-based human detection and tracking for mobile service robots. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 39, 167–181. [Google Scholar] [CrossRef] [Green Version]
- Beyer, L.; Hermans, A.; Linder, T.; Arras, K.O.; Leibe, B. Deep person detection in 2D range data. arXiv 2018, arXiv:1804.02463. [Google Scholar]
- Jung, E.J.; Lee, J.H.; Yi, B.J.; Park, J.; Yuta, S.; Noh, S.T. Development of a Laser-Range-Finder-Based Human Tracking and Control Algorithm for a Marathoner Service Robot. IEEE/ASME Trans. Mechatron. 2014, 19, 1963–1976. [Google Scholar] [CrossRef]
- Pantofaru, C.; Meyer, O. Cob Leg Detector. Available online: http://wiki.ros.org/cob_leg_detection (accessed on 17 December 2021).
- Leigh, A.; Pineau, J.; Olmedo, N.; Zhang, H. Leg Tracker. Available online: https://github.com/angusleigh/leg_tracker (accessed on 17 December 2021).
- Bellotto, N.; Hu, H. Edge Leg Detector. Available online: https://github.com/marcobecerrap/edge_leg_detector (accessed on 5 January 2022).
- Yan, Z.; Sun, L.; Duckctr, T.; Bellotto, N. Multisensor Online Transfer Learning for 3D LiDAR-Based Human Detection with a Mobile Robot. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 7635–7640. [Google Scholar] [CrossRef] [Green Version]
- Yan, Z.; Duckett, T.; Bellotto, N. Online learning for human classification in 3D LiDAR-based tracking. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 864–871. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, D.; Ma, F.; Qin, C.; Chen, Z.; Liu, M. Robust Pedestrian Tracking in Crowd Scenarios Using an Adaptive GMM-based Framework. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 9992–9998. [Google Scholar] [CrossRef]
- Sánchez, C.M.; Zella, M.; Capitán, J.; Marrón, P.J. Semantic Mapping with Low-Density Point-Clouds for Service Robots in Indoor Environments. Appl. Sci. 2020, 10, 7154. [Google Scholar] [CrossRef]
- Chandra, R.; Bhattacharya, U.; Bera, A.; Manocha, D. DensePeds: Pedestrian Tracking in Dense Crowds Using Front-RVO and Sparse Features. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 468–475. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Learned-Miller, E. Face detection with the faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 650–657. [Google Scholar]
- Jafari, O.H.; Mitzel, D.; Leibe, B. Real-time RGB-D based people detection and tracking for mobile robots and head-worn cameras. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 5636–5643. [Google Scholar] [CrossRef]
- Jafari, O.H.; Yang, M.Y. Real-time RGB-D based template matching pedestrian detection. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 5520–5527. [Google Scholar] [CrossRef] [Green Version]
- Lewandowski, B.; Liebner, J.; Wengefeld, T.; Müller, S.; Gross, H.M. Fast and Robust 3D Person Detector and Posture Estimator for Mobile Robotic Applications. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4869–4875. [Google Scholar] [CrossRef]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Unstructured human activity detection from RGBD images. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 842–849. [Google Scholar] [CrossRef] [Green Version]
- Narayanan, V.; Manoghar, B.M.; Sashank Dorbala, V.; Manocha, D.; Bera, A. ProxEmo: Gait-based Emotion Learning and Multi-view Proxemic Fusion for Socially-Aware Robot Navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 8200–8207. [Google Scholar] [CrossRef]
- Pleshkova, S.; Zahariev, Z. Development of system model for audio visual control of mobile robots with voice and gesture commands. In Proceedings of the 40th International Spring Seminar on Electronics Technology (ISSE), Sofia, Bulgaria, 10–14 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Telembici, T.; Grama, L.; Rusu, C. Integrating Service Robots into Everyday Life Based on Audio Capabilities. In Proceedings of the International Symposium on Electronics and Telecommunications (ISETC), Online, 5–6 November 2020; pp. 1–4. [Google Scholar]
- Lim, J.; Lee, S.; Tewolde, G.; Kwon, J. Indoor localization and navigation for a mobile robot equipped with rotating ultrasonic sensors using a smartphone as the robot’s brain. In Proceedings of the IEEE International Conference on Electro/Information Technology (EIT), DeKalb, IL, USA, 21–23 May 2015; pp. 621–625. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Santos, J.M.; Portugal, D.; Rocha, R.P. An evaluation of 2D SLAM techniques available in robot operating system. In Proceedings of the IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Linkoping, Sweden, 21–26 October 2013; pp. 1–6. [Google Scholar]
- Gerkey, B. Gmapping Algorithm. Available online: http://wiki.ros.org/gmapping (accessed on 25 November 2021).
- Kohlbrecher, S.; Meyer, J. HectorSLAM Algorithm. Available online: http://wiki.ros.org/hector_slam (accessed on 25 November 2021).
- Gerkey, B. KartoSLAM Algorithm. Available online: http://wiki.ros.org/slam_karto (accessed on 25 November 2021).
- The Cartographer Authors. GoogleCartographer Algorithm. Available online: https://google-cartographer-ros.readthedocs.io/en/latest/ (accessed on 25 November 2021).
- Tsardoulias, M. CRSMSLAM Algorithm. Available online: http://wiki.ros.org/crsm_slam (accessed on 25 November 2021).
- Steuxa, B.; El Hamzaoui, O. CoreSLAM Algorithm. Available online: http://library.isr.ist.utl.pt/docs/roswiki/coreslam.html (accessed on 25 November 2021).
- JetBrains Research, Mobile Robot Algorithms Laboratory. TinySLAM Algorithm. Available online: https://github.com/OSLL/tiny-slam-ros-cpp (accessed on 25 November 2021).
- JetBrains Research, OSLL Team. VinySLAM Algorithm. Available online: http://wiki.ros.org/slam_constructor (accessed on 25 November 2021).
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with rao-blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Kohlbrecher, S.; Von Stryk, O.; Meyer, J.; Klingauf, U. A flexible and scalable SLAM system with full 3D motion estimation. In Proceedings of the IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 31 October–5 November 2011; pp. 155–160. [Google Scholar]
- Konolige, K.; Grisetti, G.; Kümmerle, R.; Burgard, W.; Limketkai, B.; Vincent, R. Efficient sparse pose adjustment for 2D mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 22–29. [Google Scholar]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 1271–1278. [Google Scholar] [CrossRef]
- Tsardoulias, E.; Petrou, L. Critical rays scan match SLAM. J. Intell. Robot. Syst. 2013, 72, 441–462. [Google Scholar] [CrossRef]
- Yagfarov, R.; Ivanou, M.; Afanasyev, I. Map comparison of lidar-based 2D slam algorithms using precise ground truth. In Proceedings of the 15th International Conference on Control Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 1979–1983. [Google Scholar]
- Rojas-Fernández, M.; Mújica-Vargas, D.; Matuz-Cruz, M.; López-Borreguero, D. Performance comparison of 2D SLAM techniques available in ROS using a differential drive robot. In Proceedings of the International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula Puebla, Mexico, 21–23 February 2018; pp. 50–58. [Google Scholar]
- Xuexi, Z.; Guokun, L.; Genping, F.; Dongliang, X.; Shiliu, L. SLAM algorithm analysis of mobile robot based on lidar. In Proceedings of the Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 4739–4745. [Google Scholar]
- Krinkin, K.; Filatov, A.; Filatov, A.Y.; Huletski, A.; Kartashov, D. Evaluation of Modern Laser Based Indoor SLAM Algorithms. In Proceedings of the 22nd Conference of Open Innovations Association (FRUCT), Jyvaskyla, Finland, 15–18 May 2018; pp. 101–106. [Google Scholar] [CrossRef]
- Medina, C. Rosbag Dataset for 2D SLAM. To Use This Dataset Cite This Work. Available online: https://drive.google.com/file/d/1-ADUs3CD1qgrY8bW3LF9TOUDvPTtjc8-/view?usp=sharing (accessed on 25 November 2021).
- Medina, C. Rosbag Dataset with RGB-D Camera Data for 3D SLAM. To Use This Dataset Cite This Work. Available online: https://drive.google.com/file/d/15Ew5OEN5oJwmfQLKiepka1cVhMxNgaay/view?usp=sharing (accessed on 25 November 2021).
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Labbé, M.; Michaud, F. RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. J. Field Robot. 2019, 36, 416–446. [Google Scholar] [CrossRef]
- Nubert, J.; Khattak, S.; Hutter, M. Self-supervised Learning of LiDAR Odometry for Robotic Applications. arXiv 2020, arXiv:2011.05418. [Google Scholar]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Rockey, C. Depth Image to LaserScan. Available online: http://wiki.ros.org/depthimage_to_laserscan (accessed on 25 November 2021).
- Sánchez, C.M.; Zella, M.; Capitan, J.; Marron, P.J. Efficient Traversability Mapping for Service Robots Using a Point-cloud Fast Filter. In Proceedings of the 19th International Conference on Advanced Robotics (ICAR), Belo Horizonte, Brazil, 2–6 December 2019; pp. 584–589. [Google Scholar]
- Meeussen, W.; Wise, M.; Glaser, S.; Chitta, S.; McGann, C.; Mihelich, P.; Marder-Eppstein, E.; Muja, M.; Eruhimov, V.; Foote, T.; et al. Autonomous door opening and plugging in with a personal robot. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 4–8 May 2010; pp. 729–736. [Google Scholar] [CrossRef] [Green Version]
- Bhagya, S.M.; Samarakoon, P.; Chapa Sirithunge, H.P.; Muthugala, M.A.V.J.; Muthugala, J.; Buddhika, A.G.; Jayasekara, P. Proxemics and Approach Evaluation by Service Robot Based on User Behavior in Domestic Environment. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 8192–8199. [Google Scholar] [CrossRef]
- Astra Body Tracker. Available online: https://github.com/KrisPiters/astra_body_tracker (accessed on 25 November 2021).
- Sünderhauf, N.; Pham, T.T.; Latif, Y.; Milford, M.; Reid, I. Meaningful maps with object-oriented semantic mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5079–5085. [Google Scholar]
- Nakajima, Y.; Tateno, K.; Tombari, F.; Saito, H. Fast and accurate semantic mapping through geometric-based incremental segmentation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 385–392. [Google Scholar]
- Ma, L.; Stückler, J.; Kerl, C.; Cremers, D. Multi-view deep learning for consistent semantic mapping with rgb-d cameras. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 598–605. [Google Scholar]
- Linder, T.; Breuers, S.; Leibe, B.; Arras, K.O. On multi-modal people tracking from mobile platforms in very crowded and dynamic environments. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 5512–5519. [Google Scholar] [CrossRef]
- OpenCV Apps for ROS. Available online: http://wiki.ros.org/opencv_apps (accessed on 17 December 2021).
- Xuan, Z.; David, F. Real-Time Voxel Based 3D Semantic Mapping with a Hand Held RGB-D Camera. 2018. Available online: https://github.com/floatlazer/semantic_slam (accessed on 17 December 2021).
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 July 2018; pp. 4490–4499. [Google Scholar]
- Beltrán, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; Garcia, F.; De La Escalera, A. Birdnet: A 3D object detection framework from lidar information. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523. [Google Scholar]
- Ban, Y.; Alameda-Pineda, X.; Badeig, F.; Ba, S.; Horaud, R. Tracking a varying number of people with a visually-controlled robotic head. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4144–4151. [Google Scholar] [CrossRef]
- Breuers, S.; Beyer, L.; Rafi, U.; Leibel, B. Detection- Tracking for Efficient Person Analysis: The DetTA Pipeline. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 48–53. [Google Scholar] [CrossRef] [Green Version]
- Rudenko, A.; Palmieri, L.; Herman, M.; Kitani, K.M.; Gavrila, D.M.; Arras, K.O. Human motion trajectory prediction: A survey. Int. J. Robot. Res. 2020, 39, 895–935. [Google Scholar] [CrossRef]
- Schubert, R.; Richter, E.; Wanielik, G. Comparison and evaluation of advanced motion models for vehicle tracking. In Proceedings of the 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–6. [Google Scholar]
- Yamaguchi, K.; Berg, A.C.; Ortiz, L.E.; Berg, T.L. Who are you with and where are you going? In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1345–1352. [Google Scholar] [CrossRef] [Green Version]
- Pellegrini, S.; Ess, A.; Schindler, K.; van Gool, L. You’ll never walk alone: Modeling social behavior for multi-target tracking. In Proceedings of the IEEE 12th International Conference on Computer Vision, Thessaloniki, Greece, 23–25 September 2009; pp. 261–268. [Google Scholar]
- Kooij, J.F.; Flohr, F.; Pool, E.A.; Gavrila, D.M. Context-based path prediction for targets with switching dynamics. Int. J. Comput. Vis. 2019, 127, 239–262. [Google Scholar] [CrossRef] [Green Version]
- Shi, X.; Shao, X.; Fan, Z.; Jiang, R.; Zhang, H.; Guo, Z.; Wu, G.; Yuan, W.; Shibasaki, R. Multimodal Interaction-Aware Trajectory Prediction in Crowded Space. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11982–11989. [Google Scholar]
- Huang, Y.; Bi, H.; Li, Z.; Mao, T.; Wang, Z. Stgat: Modeling spatial-temporal interactions for human trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6272–6281. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Li, F.F.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Xue, H.; Huynh, D.Q.; Reynolds, M. SS-LSTM: A Hierarchical LSTM Model for Pedestrian Trajectory Prediction. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1186–1194. [Google Scholar] [CrossRef]
- Goldhammer, M.; Doll, K.; Brunsmann, U.; Gensler, A.; Sick, B. Pedestrian’s trajectory forecast in public traffic with artificial neural networks. In Proceedings of the 22nd International Conference on Pattern Recognition, Washington, DC, USA, 24–28 August 2014; pp. 4110–4115. [Google Scholar]
- Xiao, S.; Wang, Z.; Folkesson, J. Unsupervised robot learning to predict person motion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 25–30 May 2015; pp. 691–696. [Google Scholar]
- Luber, M.; Spinello, L.; Silva, J.; Arras, K.O. Socially-aware robot navigation: A learning approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 902–907. [Google Scholar]
- Rösmann, C.; Oeljeklaus, M.; Hoffmann, F.; Bertram, T. Online trajectory prediction and planning for social robot navigation. In Proceedings of the IEEE International Conference on Advanced Intelligent Mechatronics (AIM), Munich, Germany, 3–7 July 2017; pp. 1255–1260. [Google Scholar]
- Vasquez, D. Novel planning-based algorithms for human motion prediction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 3317–3322. [Google Scholar]
- Karasev, V.; Ayvaci, A.; Heisele, B.; Soatto, S. Intent-aware long-term prediction of pedestrian motion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 2543–2549. [Google Scholar]
- Shen, M.; Habibi, G.; How, J.P. Transferable pedestrian motion prediction models at intersections. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4547–4553. [Google Scholar]
- Pfeiffer, M.; Schwesinger, U.; Sommer, H.; Galceran, E.; Siegwart, R. Predicting actions to act predictably: Cooperative partial motion planning with maximum entropy models. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2096–2101. [Google Scholar]
- Chung, S.Y.; Huang, H.P. Incremental learning of human social behaviors with feature-based spatial effects. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 2417–2422. [Google Scholar]
- Bera, A.; Randhavane, T.; Manocha, D. The emotionally intelligent robot: Improving socially-aware human prediction in crowded environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, Z.; Jensfelt, P.; Folkesson, J. Building a human behavior map from local observations. In Proceedings of the 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016; pp. 64–70. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning social etiquette: Human trajectory understanding in crowded scenes. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 549–565. [Google Scholar]
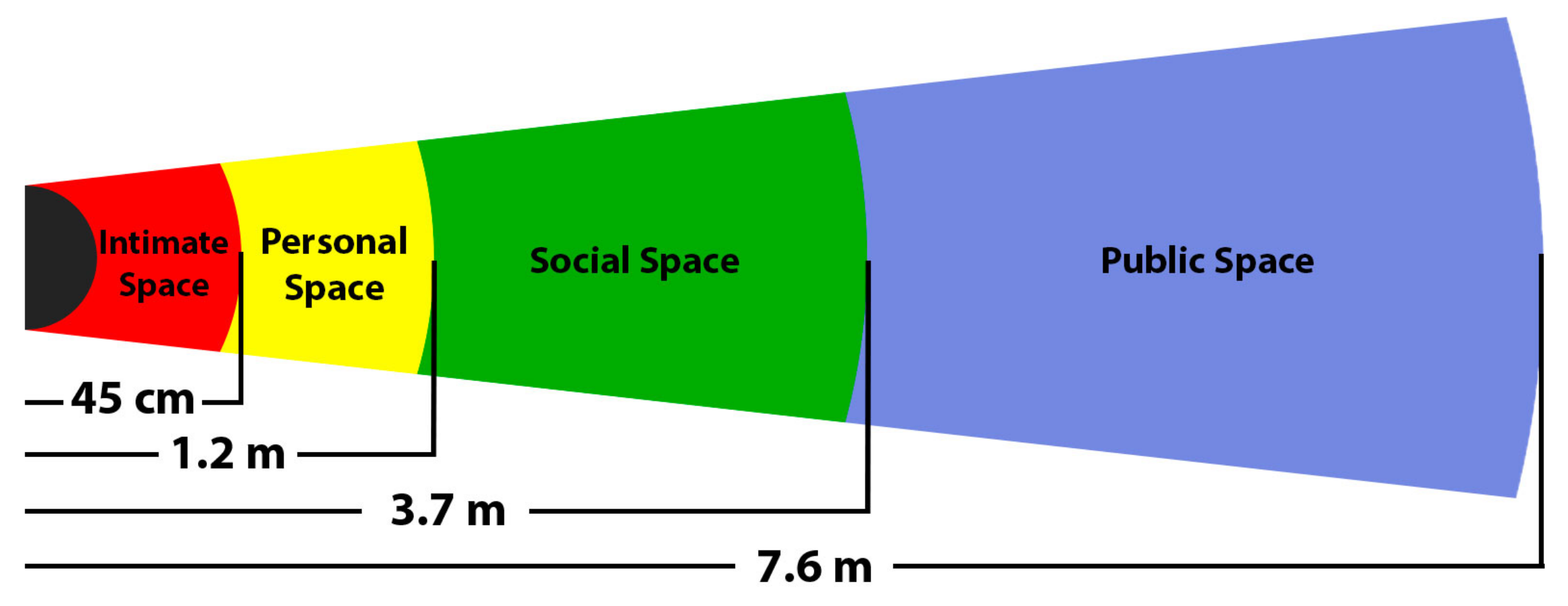
- Rios-Martinez, J.; Spalanzani, A.; Laugier, C. From proxemics theory to socially-aware navigation: A survey. Int. J. Soc. Robot. 2015, 7, 137–153. [Google Scholar] [CrossRef]
- Charalampous, K.; Kostavelis, I.; Gasteratos, A. Recent trends in social aware robot navigation: A survey. Robot. Auton. Syst. 2017, 93, 85–104. [Google Scholar] [CrossRef]
- Kruse, T.; Pandey, A.K.; Alami, R.; Kirsch, A. Human-aware robot navigation: A survey. Robot. Auton. Syst. 2013, 61, 1726–1743. [Google Scholar] [CrossRef] [Green Version]
- Möller, R.; Furnari, A.; Battiato, S.; Härmä, A.; Farinella, G.M. A Survey on Human-aware Robot Navigation. arXiv 2021, arXiv:2106.11650. [Google Scholar] [CrossRef]
- Cheng, J.; Cheng, H.; Meng, M.Q.H.; Zhang, H. Autonomous navigation by mobile robots in human environments: A survey. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1981–1986. [Google Scholar]
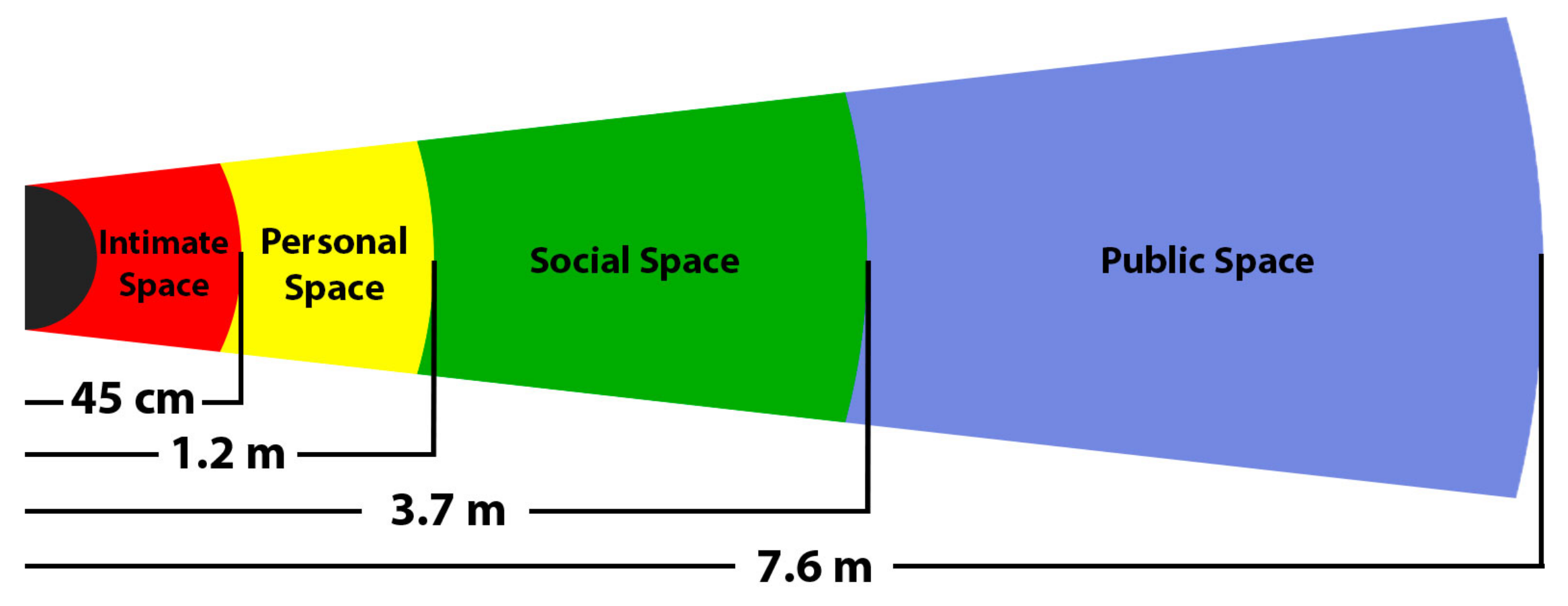
- Hall, E.T.; Birdwhistell, R.L.; Bock, B.; Bohannan, P.; Diebold, A.R., Jr.; Durbin, M.; Edmonson, M.S.; Fischer, J.; Hymes, D.; Kimball, S.T.; et al. Proxemics [and comments and replies]. Curr. Anthropol. 1968, 9, 83–108. [Google Scholar] [CrossRef]
- Tai, L.; Zhang, J.; Liu, M.; Burgard, W. Socially Compliant Navigation Through Raw Depth Inputs with Generative Adversarial Imitation Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–16 May 2018; pp. 1111–1117. [Google Scholar] [CrossRef] [Green Version]
- Choi, S.; Kim, E.; Lee, K.; Oh, S. Real-time nonparametric reactive navigation of mobile robots in dynamic environments. Robot. Auton. Syst. 2017, 91, 11–24. [Google Scholar] [CrossRef]
- Guy, S.J.; Lin, M.C.; Manocha, D. Modeling collision avoidance behavior for virtual humans. Auton. Agents Multiagent Syst. 2010, 2010, 575–582. [Google Scholar]
- Li, K.; Xu, Y.; Wang, J.; Meng, M.Q.H. SARL*: Deep Reinforcement Learning based Human-Aware Navigation for Mobile Robot in Indoor Environments. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 688–694. [Google Scholar] [CrossRef]
- SLAMTEC. RPLiDAR-A2. Available online: https://www.slamtec.com/en/Lidar/A2 (accessed on 25 November 2021).
- Aoude, G.S.; Luders, B.D.; Joseph, J.M.; Roy, N.; How, J.P. Probabilistically safe motion planning to avoid dynamic obstacles with uncertain motion patterns. Auton. Robot. 2013, 35, 51–76. [Google Scholar] [CrossRef]
- Lu, D.V.; Smart, W.D. Towards more efficient navigation for robots and humans. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1707–1713. [Google Scholar]
- Vemula, A.; Muelling, K.; Oh, J. Modeling cooperative navigation in dense human crowds. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Marina Bay Sands, Singapore, 29 May–3 June 2017; pp. 1685–1692. [Google Scholar]
- Chen, C.; Liu, Y.; Kreiss, S.; Alahi, A. Crowd-Robot Interaction: Crowd-Aware Robot Navigation With Attention-Based Deep Reinforcement Learning. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6015–6022. [Google Scholar] [CrossRef] [Green Version]
- Bera, A.; Randhavane, T.; Prinja, R.; Manocha, D. SocioSense: Robot navigation amongst pedestrians with social and psychological constraints. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 7018–7025. [Google Scholar] [CrossRef] [Green Version]
- Truong, X.T.; Ngo, T.D. Toward Socially Aware Robot Navigation in Dynamic and Crowded Environments: A Proactive Social Motion Model. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1743–1760. [Google Scholar] [CrossRef]
- Liu, Y.; Fu, Y.; Chen, F.; Goossens, B.; Tao, W.; Zhao, H. Simultaneous Localization and Mapping Related Datasets: A Comprehensive Survey. arXiv 2021, arXiv:2102.04036. [Google Scholar]
- Ramezani, M.; Wang, Y.; Camurri, M.; Wisth, D.; Mattamala, M.; Fallon, M. The Newer College Dataset: Handheld LiDAR, Inertial and Vision with Ground Truth. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020. [Google Scholar]
- Funk, N.; Tarrio, J.; Papatheodorou, S.; Popović, M.; Alcantarilla, P.F.; Leutenegger, S. Multi-resolution 3D mapping with explicit free space representation for fast and accurate mobile robot motion planning. IEEE Robot. Autom. Lett. 2021, 6, 3553–3560. [Google Scholar] [CrossRef]
- Liang, S.; Cao, Z.; Wang, C.; Yu, J. A Novel 3D LiDAR SLAM Based on Directed Geometry Point and Sparse Frame. IEEE Robot. Autom. Lett. 2020, 6, 374–381. [Google Scholar] [CrossRef]
- Cowley, A.; Miller, I.D.; Taylor, C.J. UPSLAM: Union of panoramas SLAM. arXiv 2021, arXiv:2101.00585. [Google Scholar]
- Wang, Y.; Funk, N.; Ramezani, M.; Papatheodorou, S.; Popovic, M.; Camurri, M.; Leutenegger, S.; Fallon, M. Elastic and efficient LiDAR reconstruction for large-scale exploration tasks. arXiv 2020, arXiv:2010.09232. [Google Scholar]
- Wang, Y.; Ramezani, M.; Mattamala, M.; Fallon, M. Scalable and Elastic LiDAR Reconstruction in Complex Environments Through Spatial Analysis. arXiv 2021, arXiv:2106.15446. [Google Scholar]
- Amblard, V.; Osedach, T.P.; Croux, A.; Speck, A.; Leonard, J.J. Lidar-Monocular Surface Reconstruction Using Line Segments. arXiv 2021, arXiv:2104.02761. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. IJRR 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Deschaud, J.E. IMLS-SLAM: Scan-to-model matching based on 3D data. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 2480–2485. [Google Scholar]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguere, P.; Behley, J.; Stachniss, C. Suma++: Efficient lidar-based semantic slam. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 4530–4537. [Google Scholar]
- Chen, X.; Läbe, T.; Milioto, A.; Röhling, T.; Vysotska, O.; Haag, A.; Behley, J.; Stachniss, C. OverlapNet: Loop closing for LiDAR-based SLAM. arXiv 2021, arXiv:2105.11344. [Google Scholar]
- Engel, J.; Stückler, J.; Cremers, D. Large-scale direct SLAM with stereo cameras. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October2015; pp. 1935–1942. [Google Scholar]
- Shin, Y.S.; Park, Y.S.; Kim, A. Direct visual slam using sparse depth for camera-lidar system. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 5144–5151. [Google Scholar]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuniga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef] [Green Version]
- Brasch, N.; Bozic, A.; Lallemand, J.; Tombari, F. Semantic monocular SLAM for highly dynamic environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 393–400. [Google Scholar]
- Ling, Y.; Shen, S. Building maps for autonomous navigation using sparse visual SLAM features. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1374–1381. [Google Scholar]
- Jaramillo-Avila, U.; Aitken, J.M.; Anderson, S.R. Visual saliency with foveated images for fast object detection and recognition in mobile robots using low-power embedded GPUs. In Proceedings of the 19th International Conference on Advanced Robotics (ICAR), Belo Horizonte, Brazil, 2–6 December 2019; pp. 773–778. [Google Scholar]
- Zhang, J.; Liang, X.; Wang, M.; Yang, L.; Zhuo, L. Coarse-to-fine object detection in unmanned aerial vehicle imagery using lightweight convolutional neural network and deep motion saliency. Neurocomputing 2020, 398, 555–565. [Google Scholar] [CrossRef]
- Girisha, S.; Pai, M.M.; Verma, U.; Pai, R.M. Performance analysis of semantic segmentation algorithms for finely annotated new uav aerial video dataset (manipaluavid). IEEE Access 2019, 7, 136239–136253. [Google Scholar] [CrossRef]
- Cengiz, E.; Yılmaz, C.; Kahraman, H.T.; Bayram, F. Pedestrian and Vehicles Detection with ResNet in Aerial Images. In Proceedings of the 4th International Symposium on Innovative Approaches in Engineering and Natural Sciences, Samsun, Turkey, 22–24 November 2019; pp. 416–419. [Google Scholar]
- Cengiz, E.; Yilmaz, C.; Kahraman, H. Classification of Human and Vehicles with the Deep Learning Based on Transfer Learning Method. Düzce Üniv. Bilim. Teknol. Derg. 2021, 9, 215–225. [Google Scholar] [CrossRef]
- Sadeghian, A.; Kosaraju, V.; Sadeghian, A.; Hirose, N.; Rezatofighi, H.; Savarese, S. Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1349–1358. [Google Scholar]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 14–19 June 2020; pp. 14424–14432. [Google Scholar]
- Bock, J.; Krajewski, R.; Moers, T.; Runde, S.; Vater, L.; Eckstein, L. The ind dataset: A drone dataset of naturalistic road user trajectories at german intersections. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 23–26 June 2020; pp. 1929–1934. [Google Scholar]
- Ridel, D.; Deo, N.; Wolf, D.; Trivedi, M. Scene compliant trajectory forecast with agent-centric spatio-temporal grids. IEEE Robot. Autom. Lett. 2020, 5, 2816–2823. [Google Scholar] [CrossRef] [Green Version]
- Chai, Y.; Sapp, B.; Bansal, M.; Anguelov, D. Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction. arXiv 2019, arXiv:1910.05449. [Google Scholar]
- Poibrenski, A.; Klusch, M.; Vozniak, I.; Müller, C. Multimodal multi-pedestrian path prediction for autonomous cars. ACM SIGAPP Appl. Comput. Rev. 2021, 20, 5–17. [Google Scholar] [CrossRef]
- Lai, W.C.; Xia, Z.X.; Lin, H.S.; Hsu, L.F.; Shuai, H.H.; Jhuo, I.H.; Cheng, W.H. Trajectory prediction in heterogeneous environment via attended ecology embedding. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 202–210. [Google Scholar]
- Chen, X.Z.; Liu, C.Y.; Yu, C.W.; Lee, K.F.; Chen, Y.L. A Trajectory Prediction Method Based on Social Forces, Scene Information and Motion Habit. In Proceedings of the IEEE International Conference on Consumer Electronics (ICCE), Phu Quoc Island, Vietnam, 13–15 June 2020; pp. 1–3. [Google Scholar]
- Hu, Y.; Chen, S.; Zhang, Y.; Gu, X. Collaborative motion prediction via neural motion message passing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 14–19 June 2020; pp. 6319–6328. [Google Scholar]
- Fragkiadaki, K.; Huang, J.; Alemi, A.; Vijayanarasimhan, S.; Ricco, S.; Sukthankar, R. Motion prediction under multimodality with conditional stochastic networks. arXiv 2017, arXiv:1705.02082. [Google Scholar]
- Monti, A.; Bertugli, A.; Calderara, S.; Cucchiara, R. Dag-net: Double attentive graph neural network for trajectory forecasting. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021; pp. 2551–2558. [Google Scholar]
- Li, J.; Ma, H.; Tomizuka, M. Conditional generative neural system for probabilistic trajectory prediction. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 6150–6156. [Google Scholar]
- Ess, A.; Leibe, B.; Schindler, K.; van Gool, L. A Mobile Vision System for Robust Multi-Person Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’08), Anchorage, AK, USA, 24–26 June 2008. [Google Scholar]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 28–23 June 2018; pp. 2255–2264. [Google Scholar]
- Liang, J.; Jiang, L.; Niebles, J.C.; Hauptmann, A.G.; Fei-Fei, L. Peeking into the future: Predicting future person activities and locations in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5725–5734. [Google Scholar]
- Mangalam, K.; Girase, H.; Agarwal, S.; Lee, K.H.; Adeli, E.; Malik, J.; Gaidon, A. It Is Not the Journey However, the Destination: Endpoint Conditioned Trajectory Prediction. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 759–776. [Google Scholar]
- Jia, D.; Steinweg, M.; Hermans, A.; Leibe, B. Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13301–13307. [Google Scholar]
- Linder, T.; Vaskevicius, N.; Schirmer, R.; Arras, K.O. Cross-Modal Analysis of Human Detection for Robotics: An Industrial Case Study. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 971–978. [Google Scholar]
- Caselles-Dupré, H.; Garcia-Ortiz, M.; Filliat, D. On the sensory commutativity of action sequences for embodied agents. arXiv 2020, arXiv:2002.05630. [Google Scholar]
- Jia, D.; Leibe, B. Person-MinkUNet: 3D Person Detection with LiDAR Point Cloud. arXiv 2021, arXiv:2107.06780. [Google Scholar]
- Jia, D.; Hermans, A.; Leibe, B. Domain and Modality Gaps for LiDAR-based Person Detection on Mobile Robots. arXiv 2021, arXiv:2106.11239. [Google Scholar]
- Tolani, V.; Bansal, S.; Faust, A.; Tomlin, C. Visual navigation among humans with optimal control as a supervisor. IEEE Robot. Autom. Lett. 2021, 6, 2288–2295. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. arXiv 2019, arXiv:1903.11027. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 15–25 June 2021; pp. 11784–11793. [Google Scholar]
- Zhu, X.; Ma, Y.; Wang, T.; Xu, Y.; Shi, J.; Lin, D. Ssn: Shape signature networks for multi-class object detection from point clouds. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 581–597. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4338–4364. [Google Scholar] [CrossRef]
- Nabati, R.; Qi, H. Centerfusion: Center-based radar and camera fusion for 3d object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 June 2021; pp. 1527–1536. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 474–490. [Google Scholar]
- Rasouli, A.; Yau, T.; Rohani, M.; Luo, J. Multi-modal hybrid architecture for pedestrian action prediction. arXiv 2020, arXiv:2012.00514. [Google Scholar]
- Yau, T.; Malekmohammadi, S.; Rasouli, A.; Lakner, P.; Rohani, M.; Luo, J. Graph-sim: A graph-based spatiotemporal interaction modelling for pedestrian action prediction. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 8580–8586. [Google Scholar]
- Yuan, Y.; Weng, X.; Ou, Y.; Kitani, K. AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting. arXiv 2021, arXiv:2103.14023. [Google Scholar]
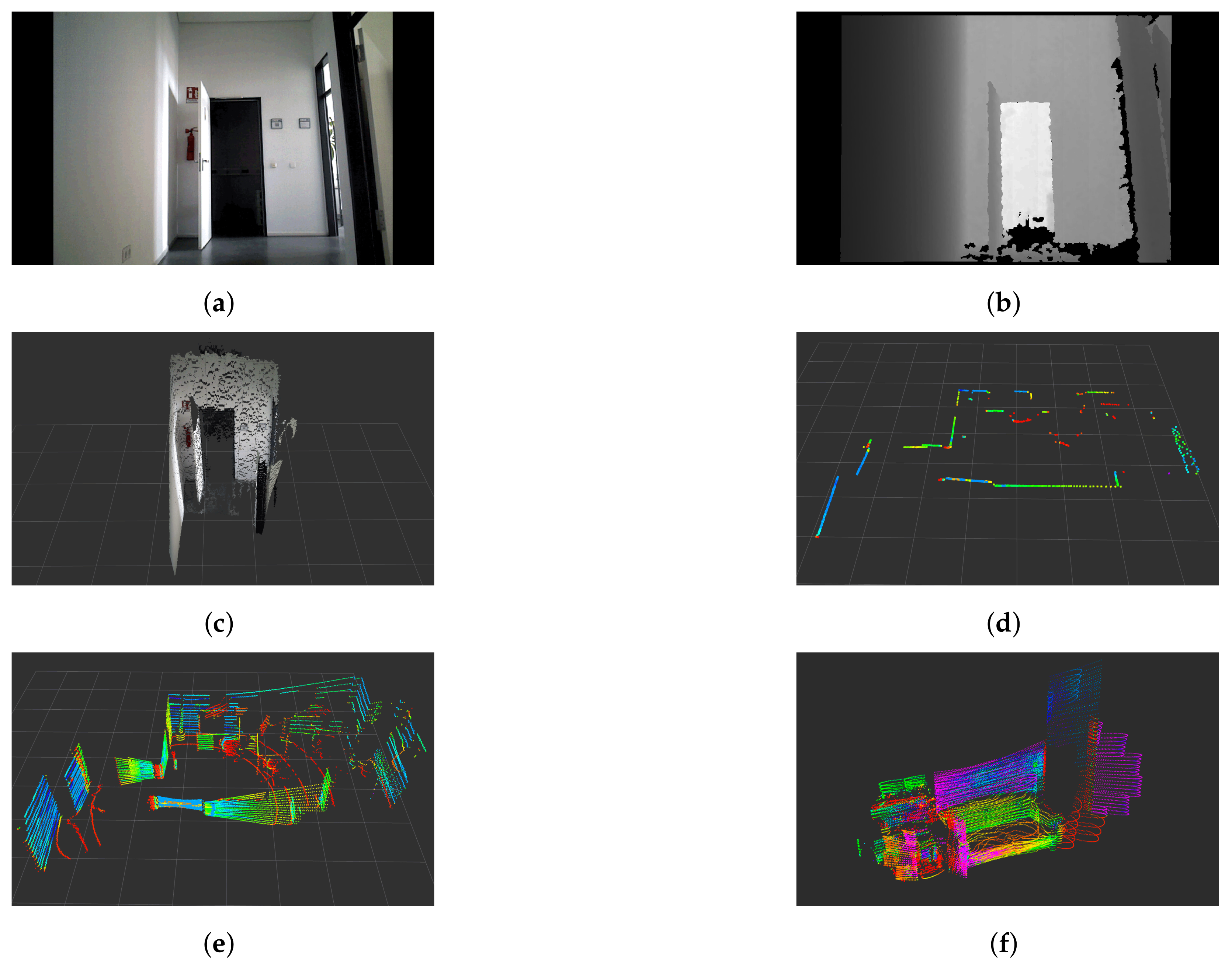




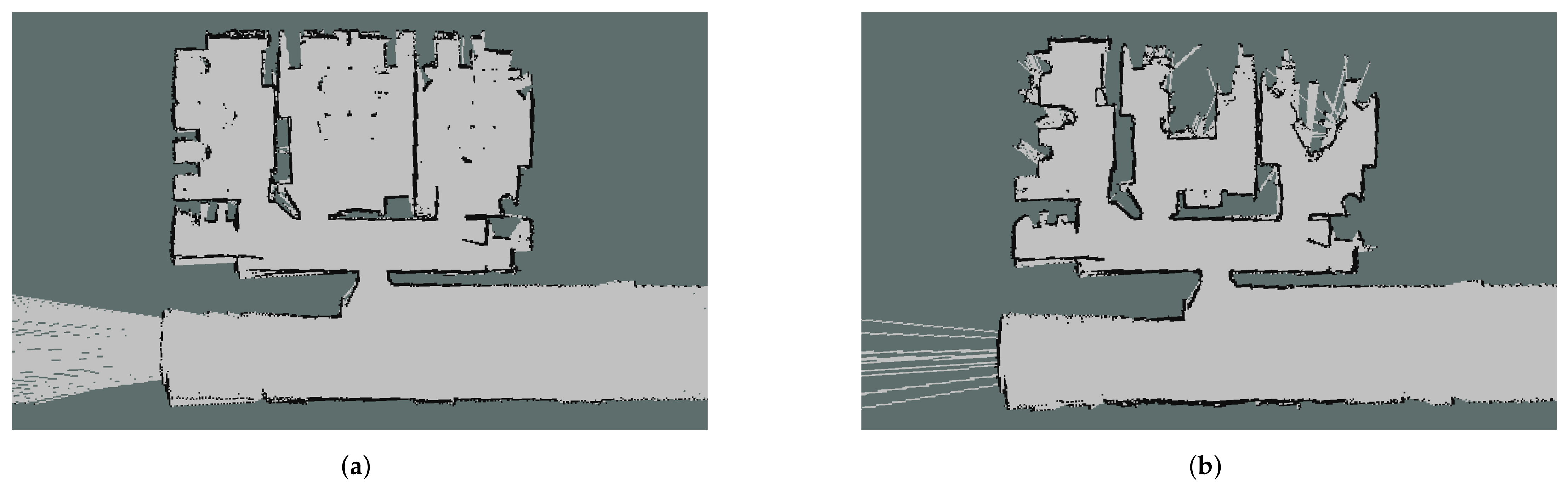


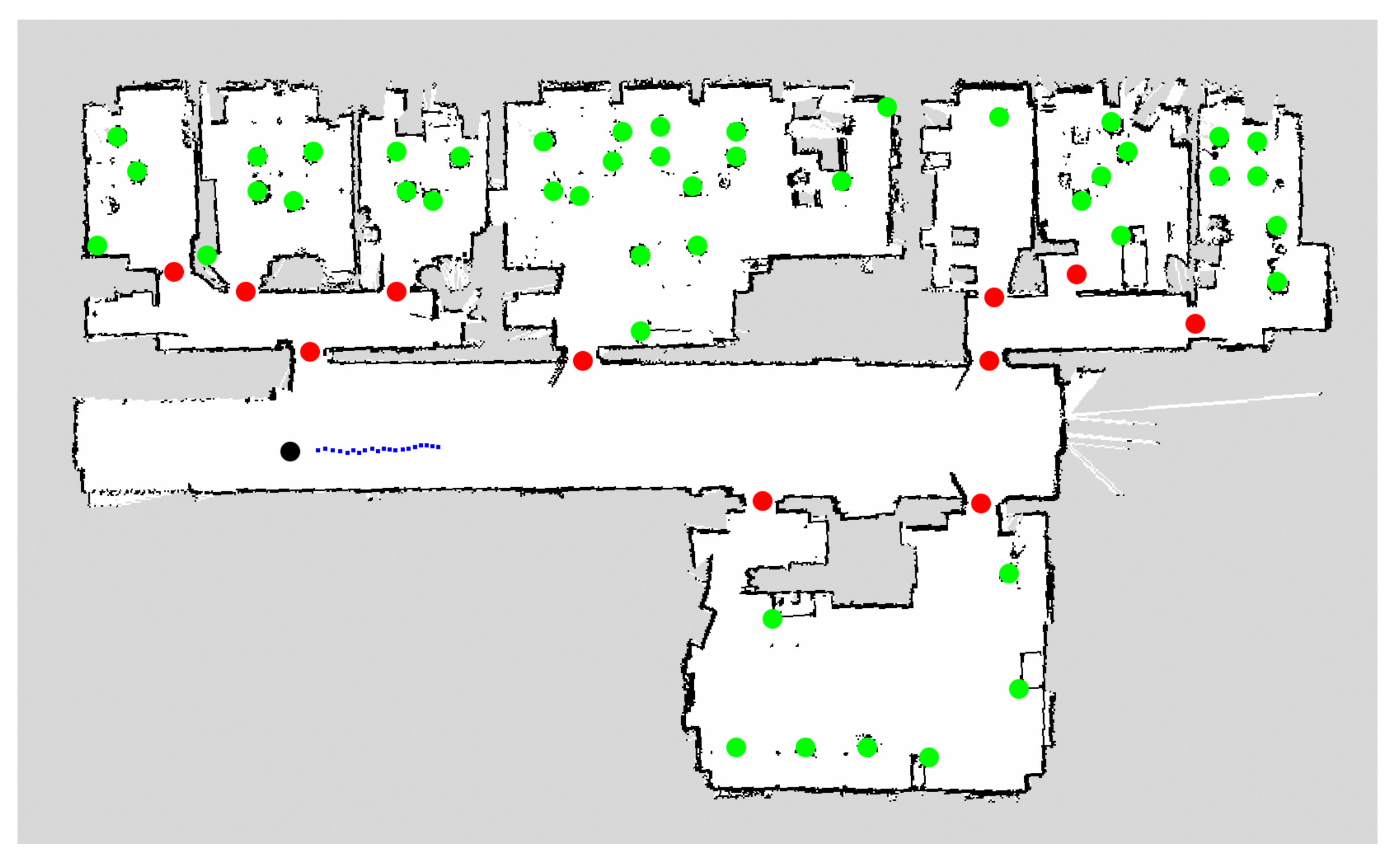




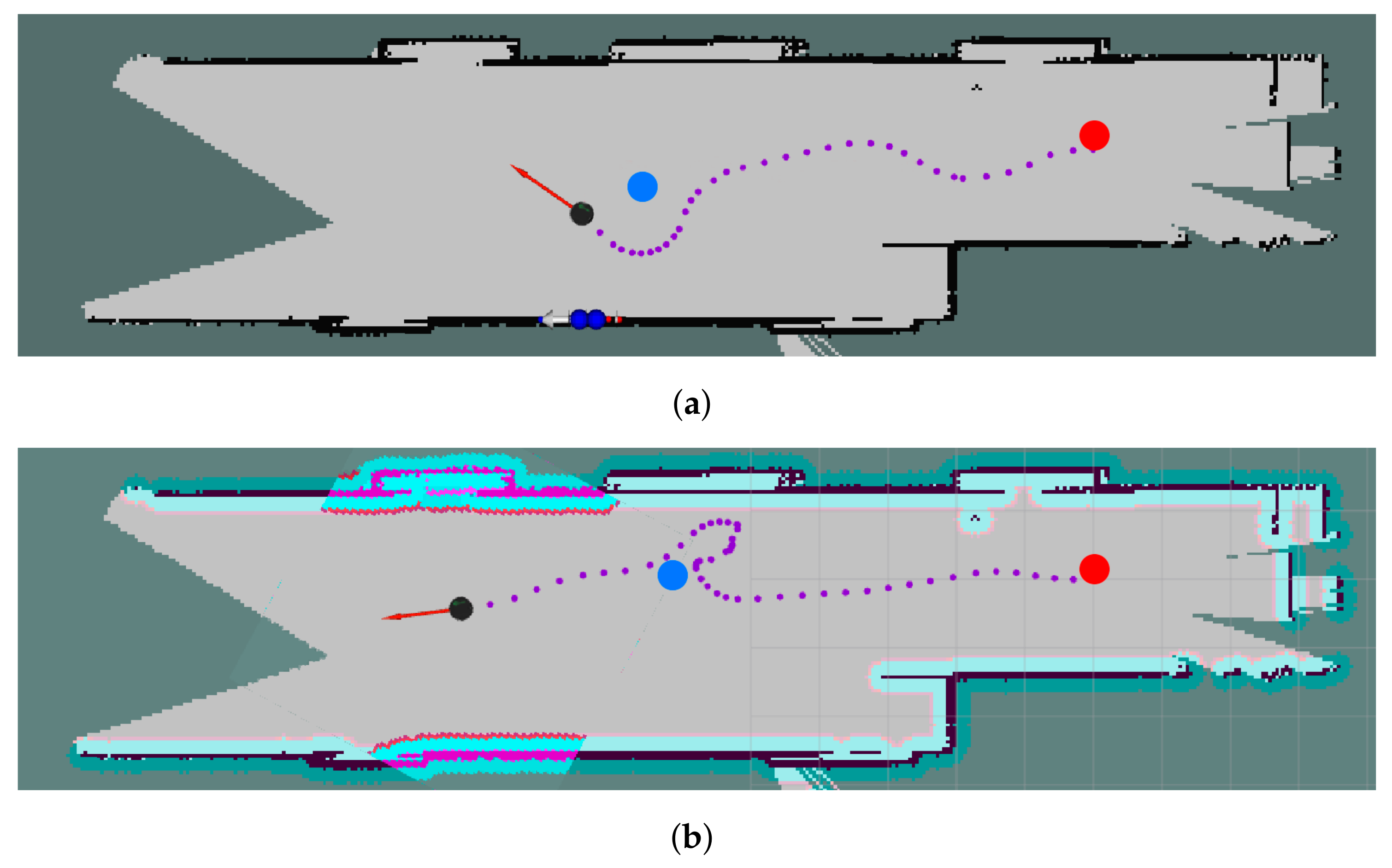

{kind=link}
{kind=link}
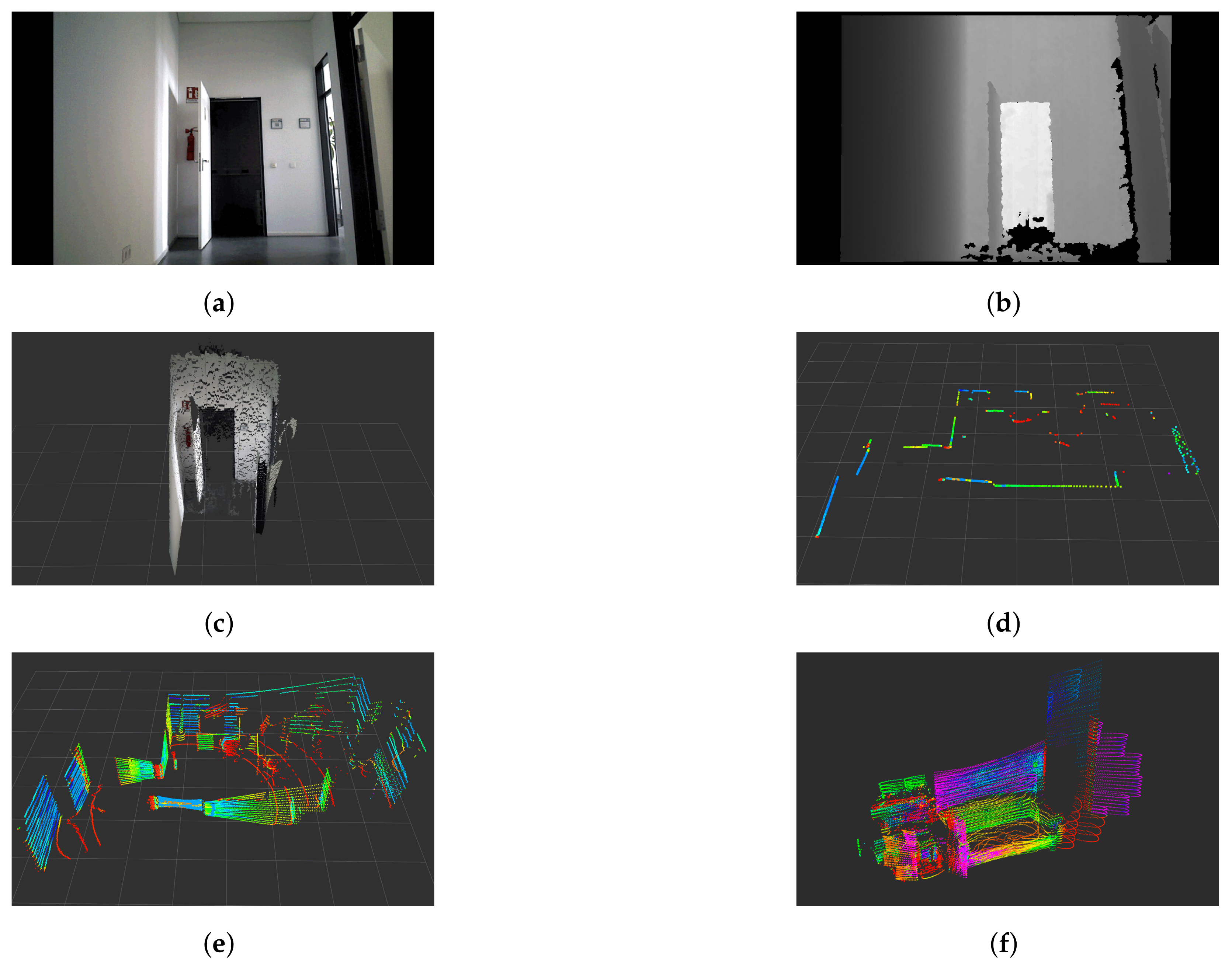
{kind=link}
{kind=link}
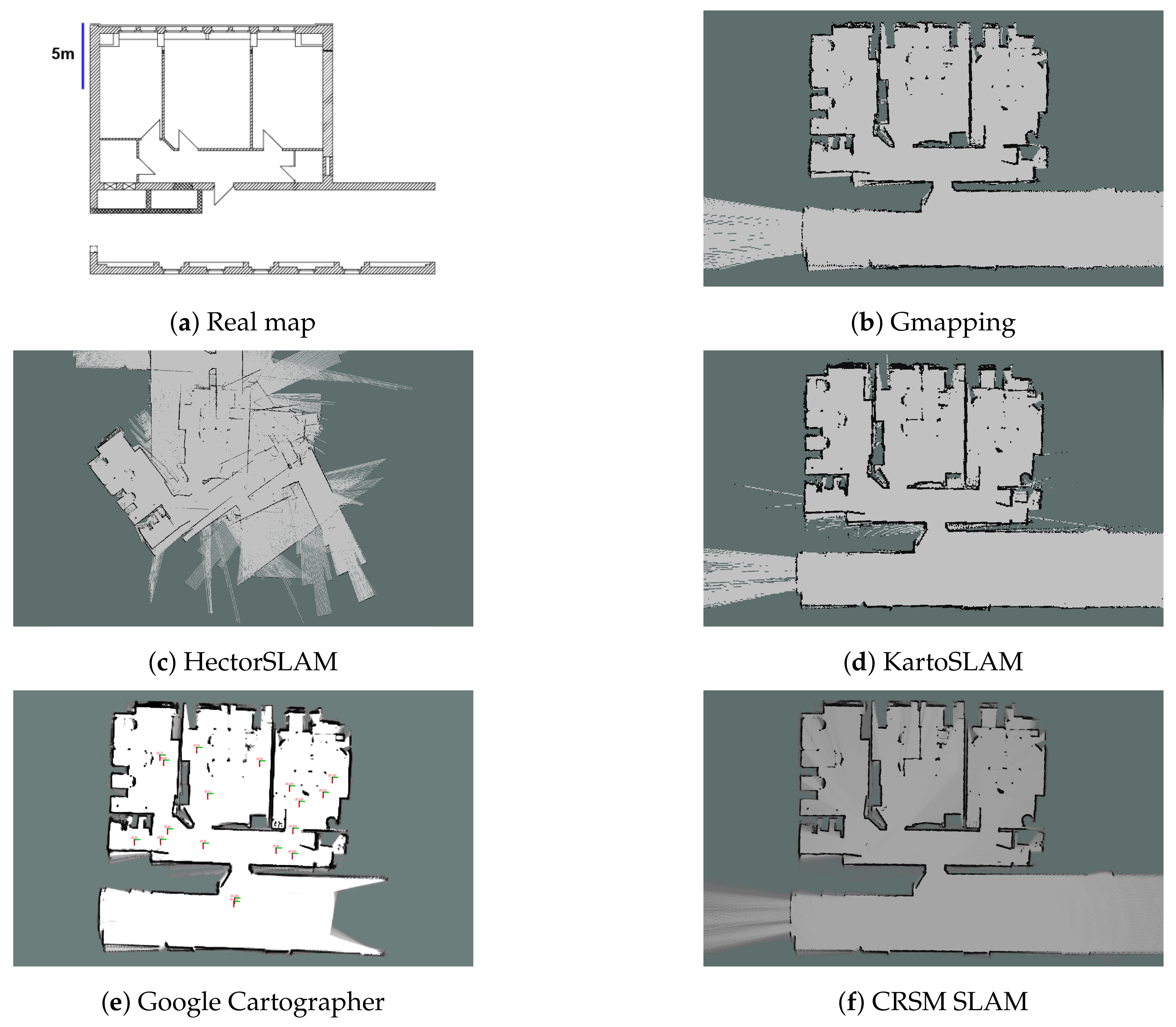
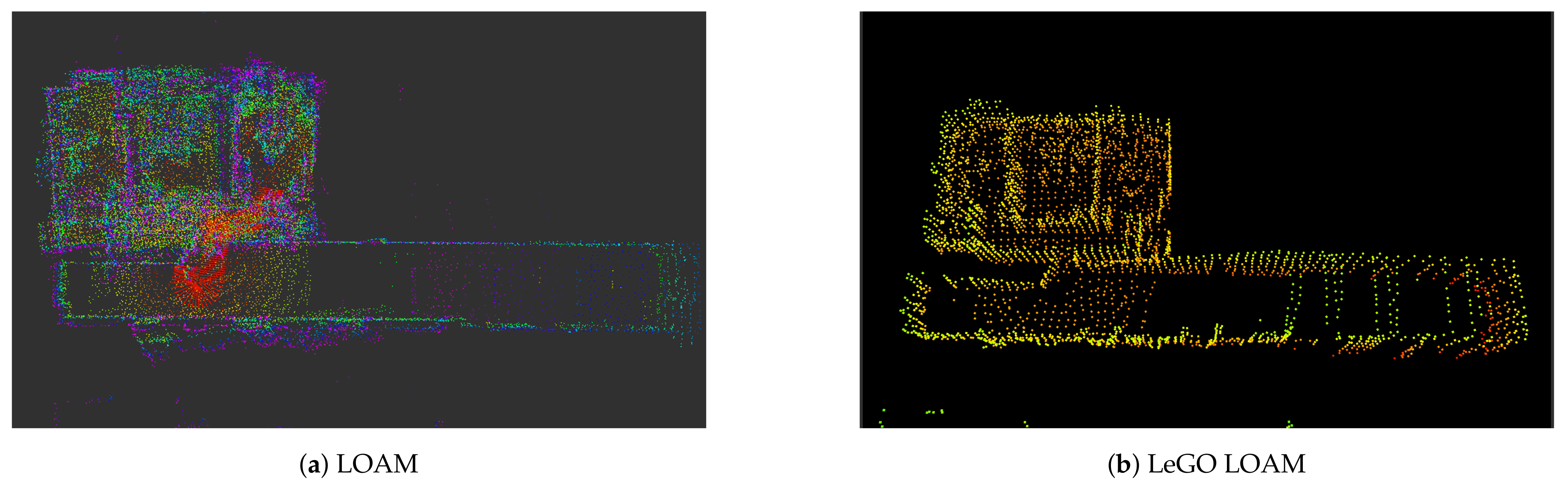{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | FoV (H × V) | Depth Range (m) | RGB Resolution | Depth Resolution | Price |
|---|---|---|---|---|---|
| Orbbec Astra Pro [11] | 60° × 49.5° | 0.4–8 | 1280 × 720 | 640 × 480 | USD 149.99 |
| Orbbec Persee [11] | 60° × 49° | 0.6–8 | 1280 × 720 | 640 × 480 | USD 239.99 |
| RealSense D435i [12] | 87° × 58° | 0.3–3 | 1920 × 1080 | 1280 × 720 | USD 209 |
| RealSense D455 [12] | 87° × 58° | 0.6–6 | 1280 × 800 | 1280 × 720 | USD 249 |
| × tion Pro Live [13] | 58° × 45° | 0.8–3.5 | 1280 × 1024 | 640 × 480 | USD 300 * |
| × tion 2 [13] | 74° × 52° | 0.8–3.5 | 2592 × 1944 | 640 × 480 | USD 430 |
| Azure Kinect DK [14] | 75° × 65° | 0.5–3.86 | 3840 × 2160 | 640 × 576 | USD 399 |
| ZED [9] | 90° × 60° | 0.5–25 | 1920 × 1080 | 1920 × 1080 | USD 349 |
| ZED 2 [9] | 110° × 70° | 0.2–20 | 1920 × 1080 | 1920 × 1080 | USD 449 |
| Reference | FoV | Range (m) | Resolution | Frecuency | Price |
|---|---|---|---|---|---|
| Hokuyo UST-10LX [7] | 270° | 0.06–10 | 0.25° | 40 Hz | USD 1600 |
| Hokuyo URG-04LX [7] | 240° | 0.06–4.095 | 0.36° | 10 Hz | USD 2100 |
| Hokuyo UST-20LX [7] | 270ΰ | 0.06–20 | 0.25ΰ | 40 Hz | USD 2700 |
| Sick TIM551 [7] | 270° | 0.05–10 | 1° | 15 Hz | USD 1880 |
| Sick TIM571 [7] | 270° | 0.05–25 | 0.33° | 15 Hz | USD 1623 |
| RPLIDAR A1M8 [8] | 360° | 0.15–12 | 1° | 5.5 Hz | USD 330 |
| RPLIDAR A2M8 [7] | 360° | 0.15–6 | 0.9° | 10 Hz | USD 389 |
| RPLIDAR A2M6 [7] | 360° | 0.2–18 | 0.45° | 15 Hz | USD 636 |
| RPLIDAR A3 [7] | 360° | 0.2–25 | 0.225° | 15 Hz | USD 549 |
| Yujin YRL2-05 [8] | 270° | 0.1–5 | 0.55° | 20 Hz | USD 650 |
| Reference | FoV H × V | Range (m) | Resolution H × V | Frequency | Price |
|---|---|---|---|---|---|
| RS-LiDAR-16 [8] | 360° × 30° | 150 | 0.2° × 2° | 10 Hz | USD 5312 |
| OLEI LR-16F [8] | 360° × 30° | 100 | 0.18° × 2° | 10 Hz | USD 1750 |
| LS 32 Channel [8] | 360° × 30° | 150 | 0.18° × 1° | 10 Hz | USD 5000 |
| M8-1 Plus LIDAR [8] | 360° × 20° | 150 | 0.132° × 2.85° | 10 Hz | USD 5007 |
| Velodyne Puck | 360° × 30° | 100 | 0.2° × 2° | 10 Hz | USD 4000 |
| Reference | FoV H × V | Range (m) | Resolution H × V | Frequency | Price |
|---|---|---|---|---|---|
| Livo × Mid-40 [20] | 38.4° circular | 260 | 0.03° × 0.28° | N/A | USD 599 |
| Livo × Horizon [20] | 81.7° × 25.1° | 260 | 0.3° × 0.28° | N/A | USD 800 |
| Livo × TELE-15 [20] | 14.5° × 16.2° | 500 | 0.02° × 0.12° | 10 Hz | USD 1200 |
| CE30-D [8] | 60° × 40° | 150 | N/A × 2° | 30 Hz | USD 1199 |
| CE30-A [8] | 132° × 9° | 4 | N/A | 20 Hz | USD 650 |
| Sensor | 2D Mapping | 3D Mapping | Semantic Mapping | People Detection | People Recognition |
|---|---|---|---|---|---|
| 2D LiDARs | + + | − − | − − | − | − − |
| 3D MLi | + + | + + | + | + + | − − |
| 3D SSLi | + | + + | + | + + | − − |
| RGB-D cameras | + | + + | + + | + + | + + |
| Method | Processing Time (without Map Update) | Processing Time (with Map Update) |
|---|---|---|
| Gmapping | 0.192 ms | 2137.34 ms |
| HectorSLAM | 79 ms | 125.84 ms |
| KartoSLAM | 0.387 ms | 52.87 ms |
| Google Cartographer | 0.231 ms | 12.43 ms |
| CRSM SLAM | 97 ms | 97 ms |
| Name | Data | Related Work | ||||
|---|---|---|---|---|---|---|
| Point-Cloud | ||||||
| RGB Images | Camera | 2D LiDAR | 3DLiDAR | Annotations | ||
| NCD [124] | ✓ | x | x | ✓ | x | LiDAR-based SLAM: [125,126,127,128,129,130] |
| KITTI [131] | ✓ | x | x | ✓ | ✓ | LiDAR-based SLAM: [124,126,132,133,134] Visual SLAM: [135,136,137,138,139] |
| SDD [105] | ✓ | x | x | x | ✓ | People detection: [140,141,142,143,144] Trajectory prediction: [145,146,147,148,149,150,151,152,153,154,155,156] |
| ETH [157] | ✓ | x | x | x | ✓ | People detection: [36] Trajectory prediction: [93,119,145,146,150,151,158,159,160] |
| UCY | ✓ | x | x | x | ✓ | Trajectory prediction: [93,145,146,150,151,158,159,160] |
| JRDB [105] | ✓ | x | x | ✓ | ✓ | People detection: [161,162,163,164,165] Social navigation: [166] |
| nuScenes [167] | ✓ | x | x | ✓ | ✓ | People detection: [168,169,170,171,172] Trajectory prediction: [173,174,175] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Medina Sánchez, C.; Zella, M.; Capitán, J.; Marrón, P.J. From Perception to Navigation in Environments with Persons: An Indoor Evaluation of the State of the Art. Sensors 2022, 22, 1191. https://doi.org/10.3390/s22031191
Medina Sánchez C, Zella M, Capitán J, Marrón PJ. From Perception to Navigation in Environments with Persons: An Indoor Evaluation of the State of the Art. Sensors. 2022; 22(3):1191. https://doi.org/10.3390/s22031191
Chicago/Turabian StyleMedina Sánchez, Carlos, Matteo Zella, Jesús Capitán, and Pedro J. Marrón. 2022. "From Perception to Navigation in Environments with Persons: An Indoor Evaluation of the State of the Art" Sensors 22, no. 3: 1191. https://doi.org/10.3390/s22031191
APA StyleMedina Sánchez, C., Zella, M., Capitán, J., & Marrón, P. J. (2022). From Perception to Navigation in Environments with Persons: An Indoor Evaluation of the State of the Art. Sensors, 22(3), 1191. https://doi.org/10.3390/s22031191