
Imputing Missing Data in Hourly Traffic Counts


Abstract
1. Introduction
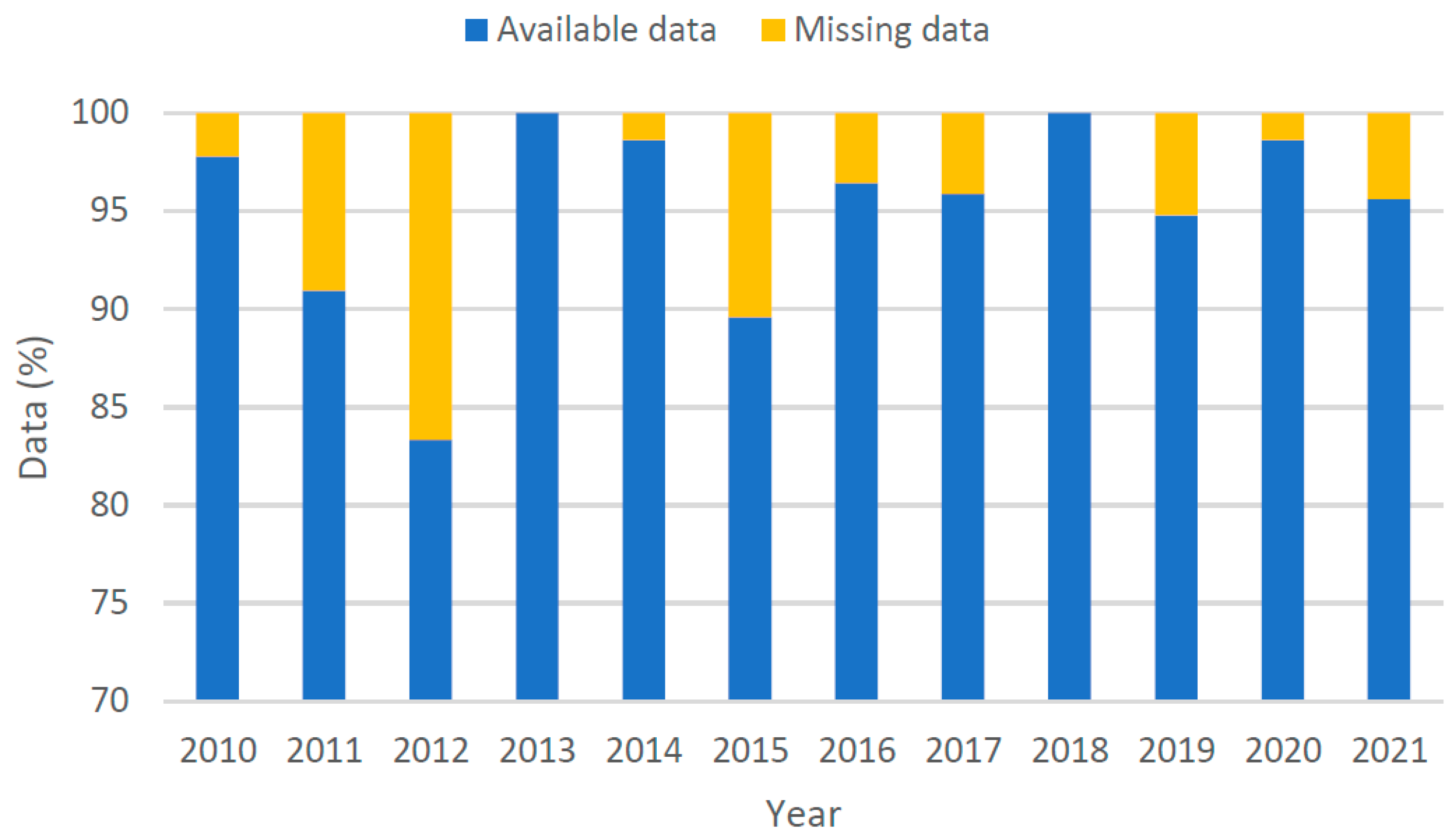
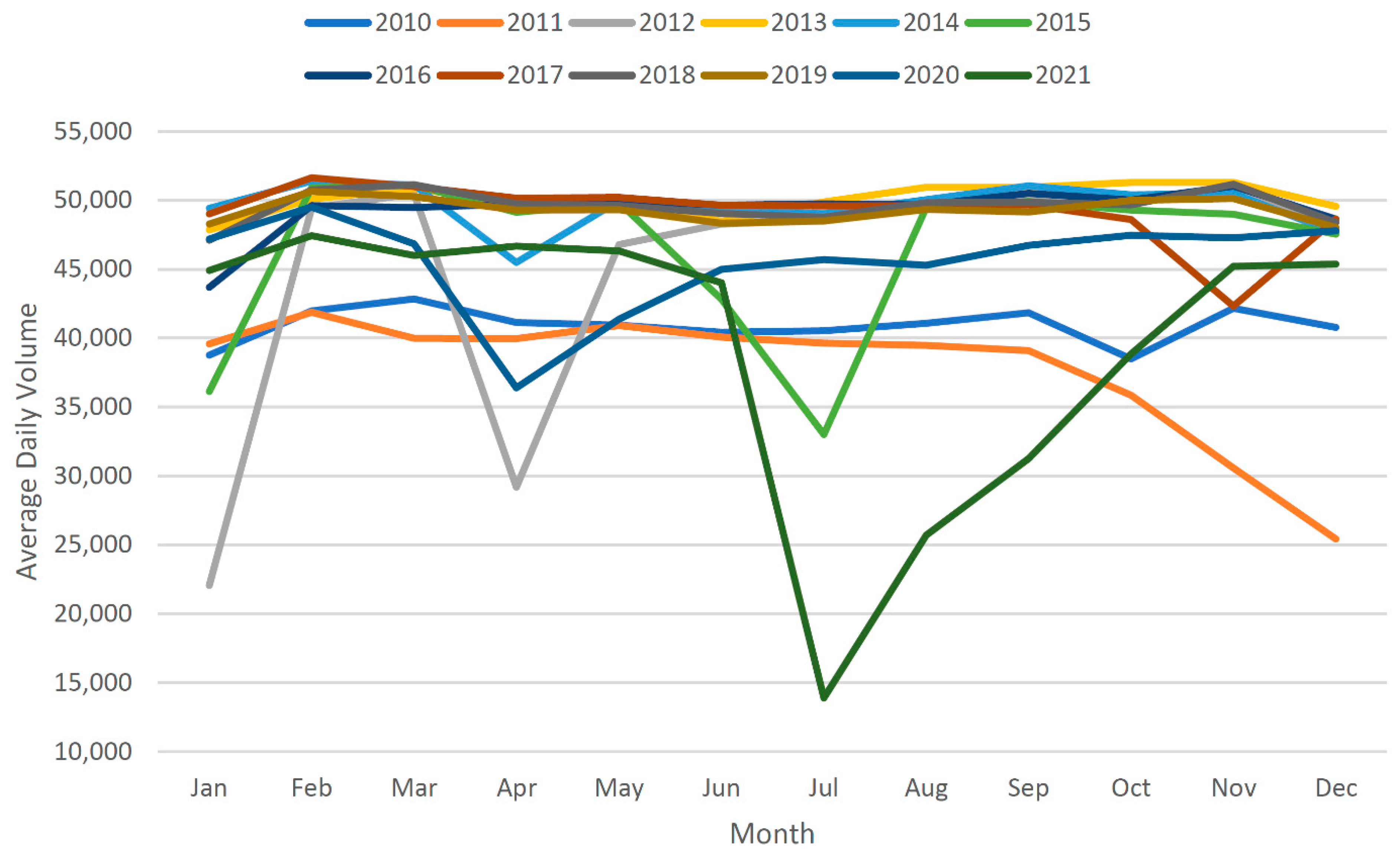
2. Data
- At least 19 hourly observations are required per day.
- At least one value for each day of the week is required per month.
- The daily volume should be within 20% of the average for that day of the week in the month.
2.1. Data Selection
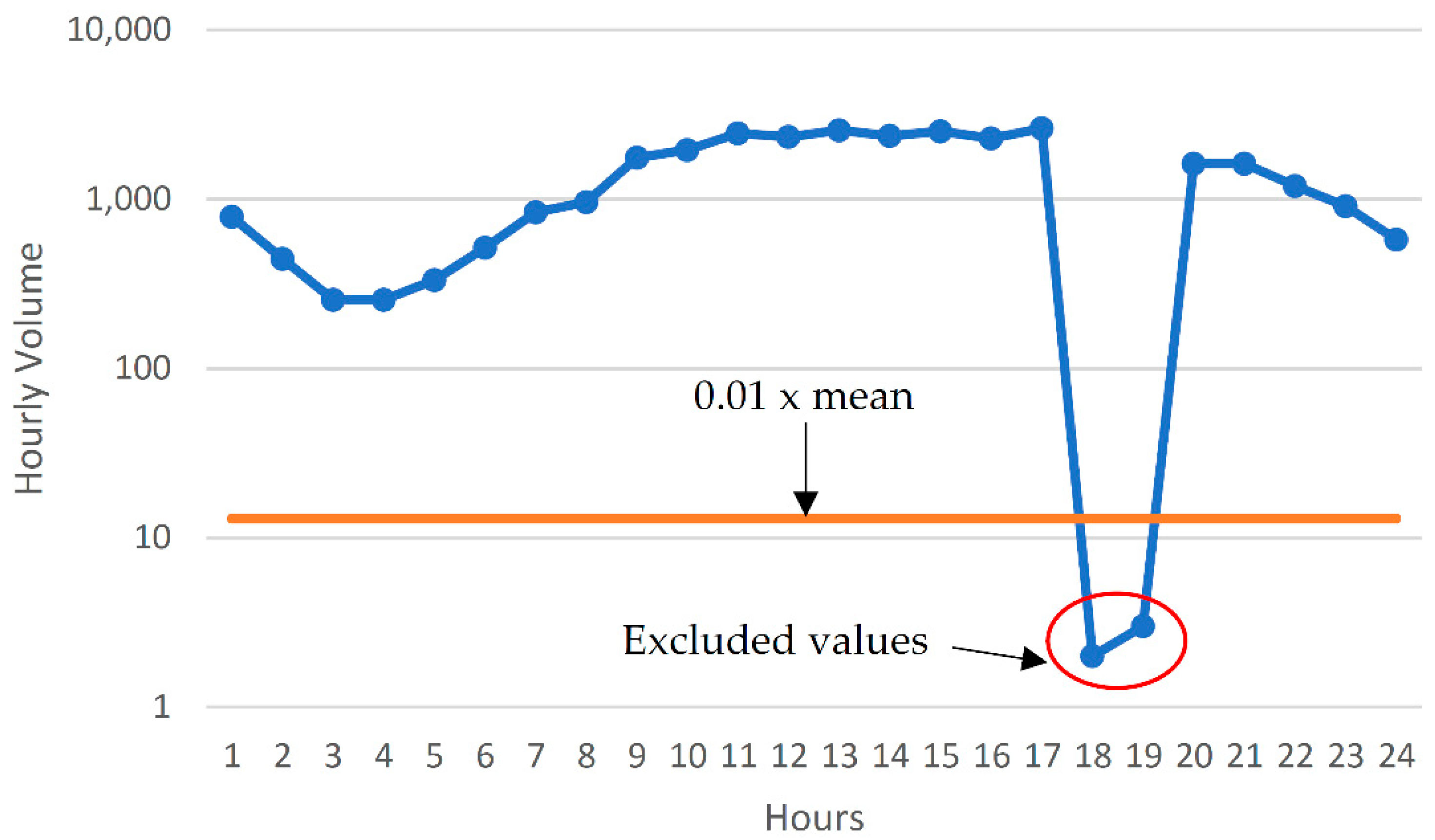
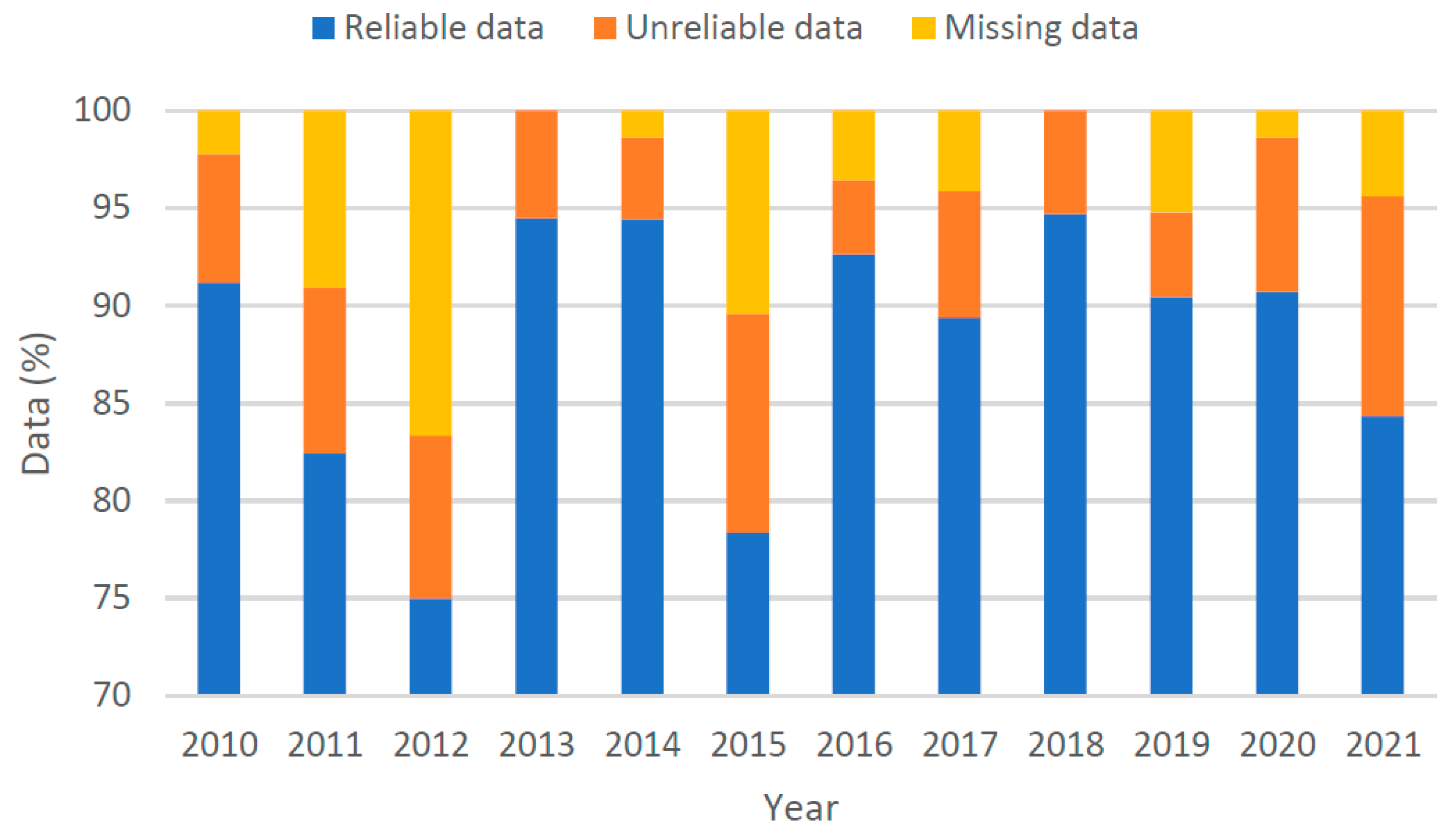
2.2. Data Cleaning
3. Data Imputation Methodologies
3.1. Multivariate Imputation by Chained Equations
3.1.1. Predictive Mean Matching
3.1.2. Weighted Predictive Mean Matching
3.1.3. Random Sample from Observed Values
3.1.4. CART within MICE
3.1.5. Random Forest within MICE
3.1.6. Unconditional Mean Imputation
3.1.7. Bayesian Linear Regression
3.1.8. LASSO Linear Regression
3.1.9. LASSO Select + Linear Regression
3.1.10. Random Indicator for Non-Ignorable Data
3.2. Random Forest
3.3. Extreme Gradient Boosting
4. Analysis and Results
4.1. Evaluation Measures
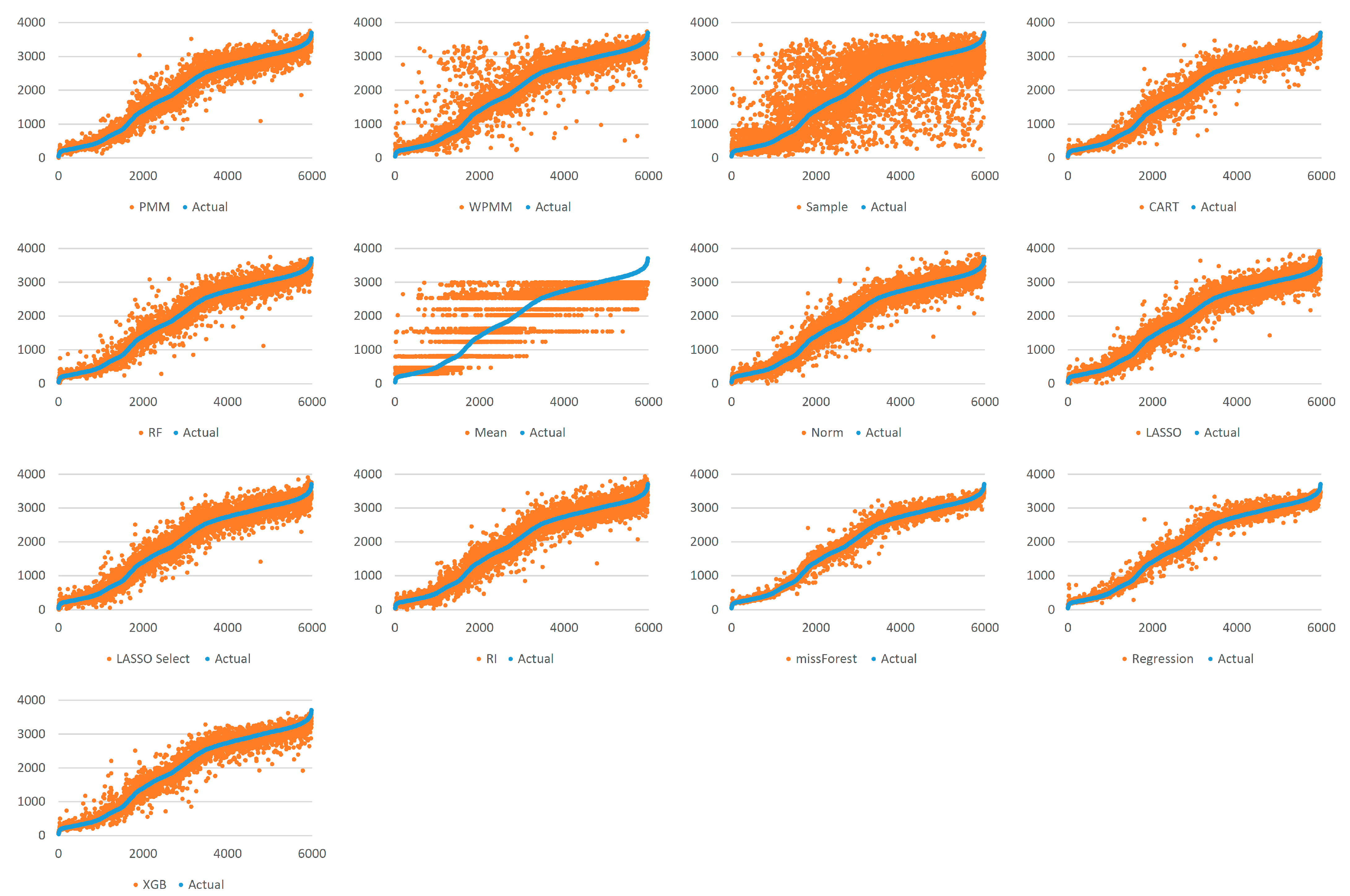
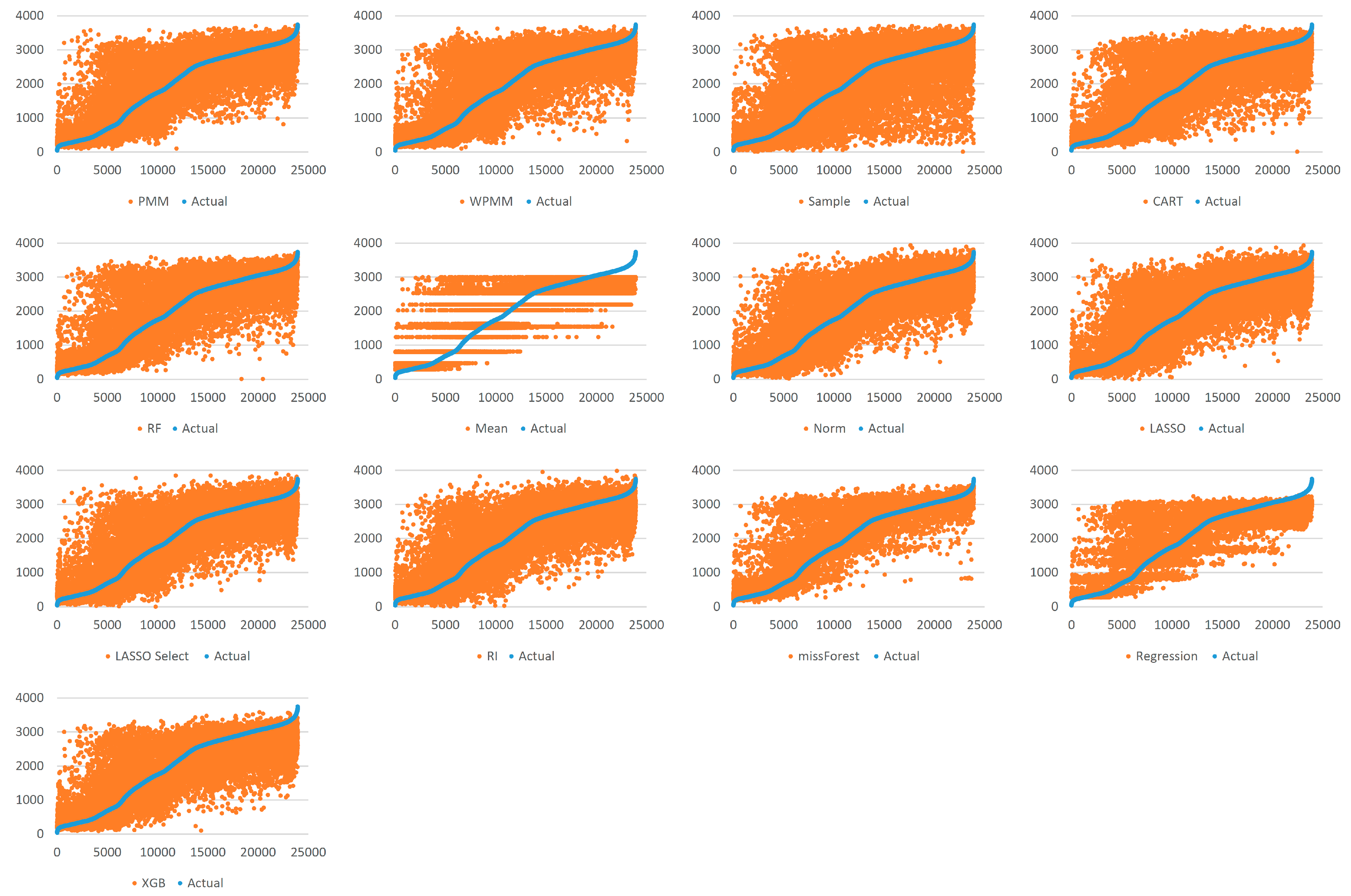
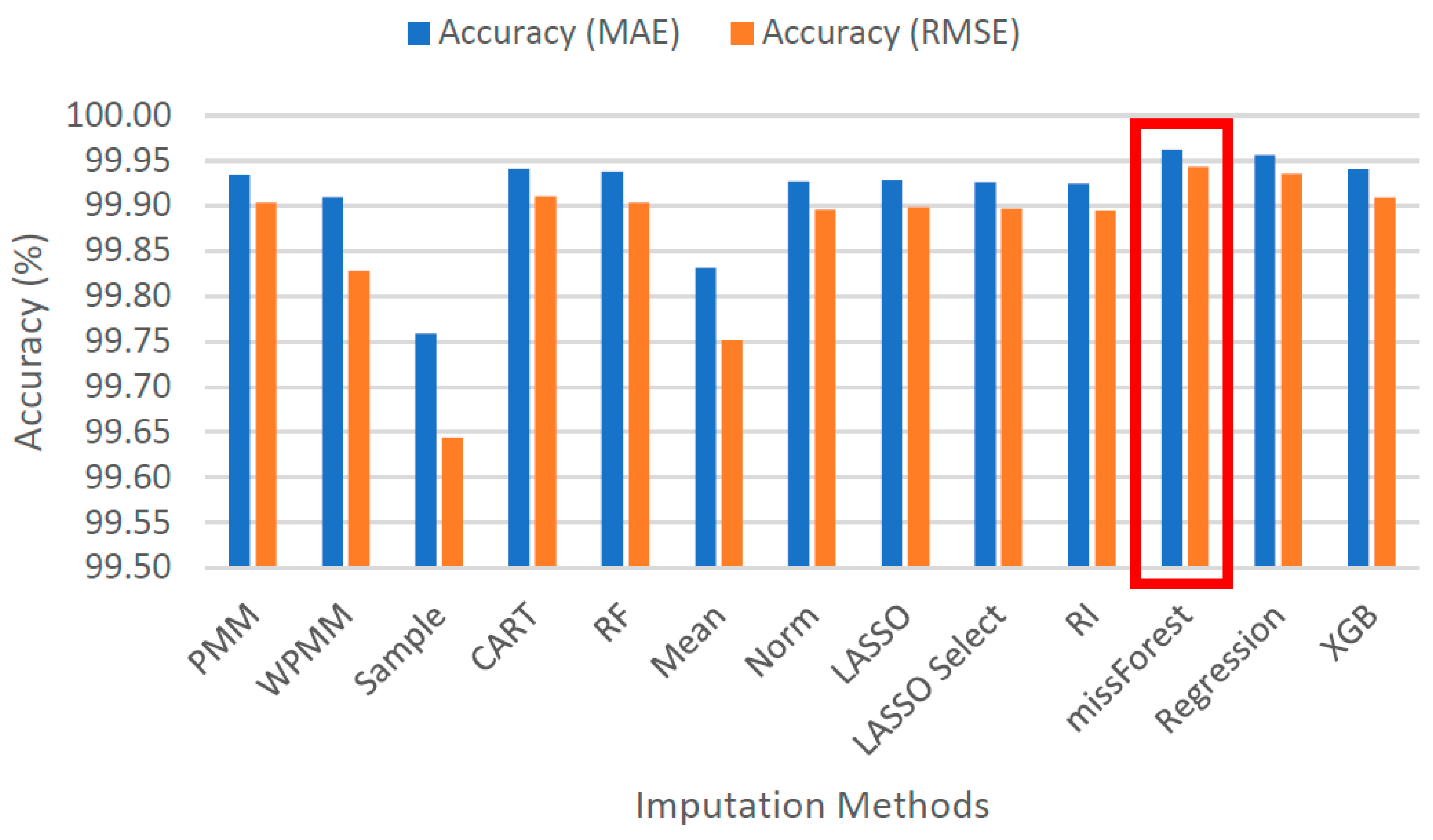
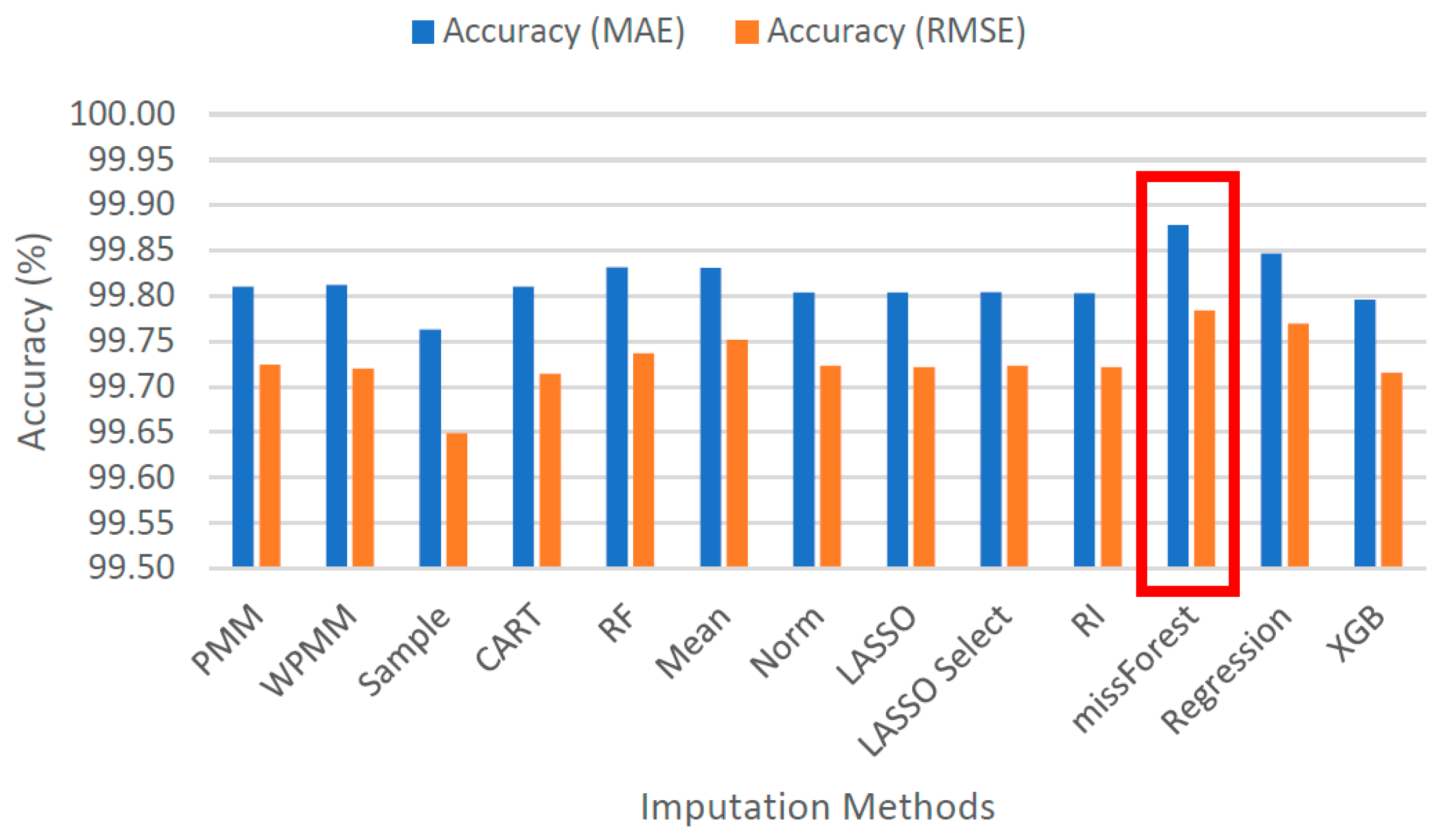
4.2. Analysis
4.3. Results
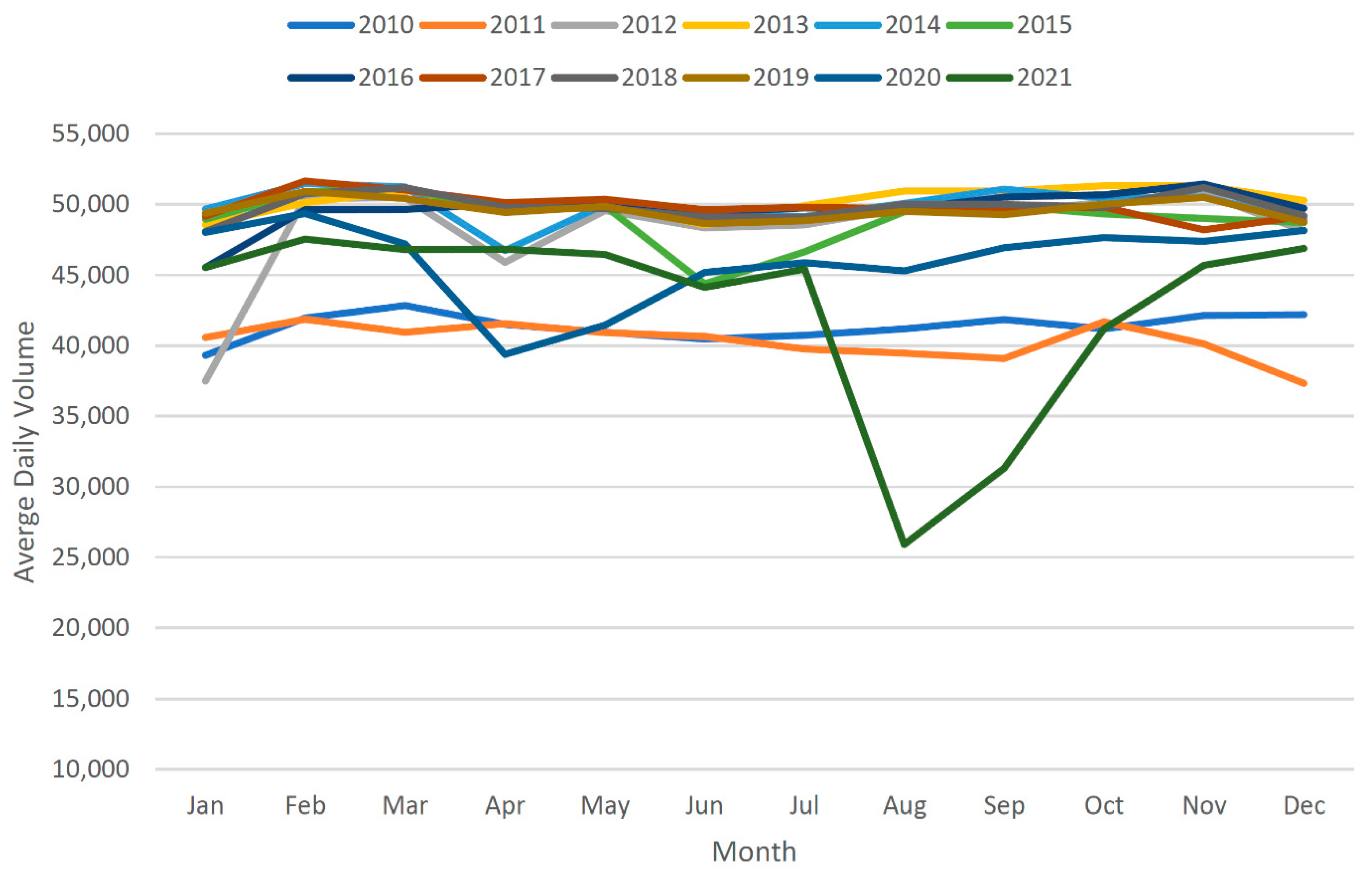
5. Data Imputation and AADT Calculation
6. Discussion
7. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manual, H.C. HCM2010; Transportation Research Board, National Research Council: Washington, DC, USA, 2010; Volume 1207. [Google Scholar]
- Sharma, S.; Zhong, M.; Liu, Z. Traffic Data Collection and Analysis Practice Survey for Highway agencies in West Canada; Faculty of Engineering, University of Regina: Regina, SK, Canada, 2003. [Google Scholar]
- Albright, D. 1990 Survey of Traffic Monitoring Practices among State Transportation Agencies of the United States, Final Report No. FHWA/HPR/NM-90-05; New Mexico State Highway and Transportation Department: Albuquerque, NM, USA, 1990.
- Albright, D. An imperative for, and current progress toward, national traffic monitoring standards. ITE J. 1991, 61, 23–26. [Google Scholar]
- Zhong, M.; Sharma, S.; Liu, Z. Assessing robustness of imputation models based on data from different jurisdictions: Examples of Alberta and Saskatchewan, Canada. Transp. Res. Rec. 2005, 1917, 116–126. [Google Scholar] [CrossRef]
- Liu, Z.; Sharma, S.; Datla, S. Imputation of missing traffic data during holiday periods. Transp. Plan. Technol. 2008, 31, 525–544. [Google Scholar] [CrossRef]
- Khan, Z.; Khan, S.M.; Dey, K.; Chowdhury, M. Development and evaluation of recurrent neural network-based models for hourly traffic volume and annual average daily traffic prediction. Transp. Res. Rec. 2019, 2673, 489–503. [Google Scholar] [CrossRef]
- Song, S.; Sun, Y.; Zhang, A.; Chen, L.; Wang, J. Enriching data imputation under similarity rule constraints. IEEE Trans. Knowl. Data Eng. 2018, 32, 275–287. [Google Scholar] [CrossRef]
- Jia, X.; Dong, X.; Chen, M.; Yu, X. Missing data imputation for traffic congestion data based on joint matrix factorization. Knowl.-Based Syst. 2021, 225, 107114. [Google Scholar] [CrossRef]
- Roll, J. Daily traffic count imputation for bicycle and pedestrian traffic: Comparing existing methods with machine learning approaches. Transp. Res. Rec. 2021, 2675, 1428–1440. [Google Scholar] [CrossRef]
- Rekatsinas, T.; Chu, X.; Ilyas, I.F.; Ré, C. Holoclean: Holistic data repairs with probabilistic inference. arXiv 2017, arXiv:1702.00820. [Google Scholar] [CrossRef]
- Breve, B.; Caruccio, L.; Deufemia, V.; Polese, G. RENUVER: A Missing Value Imputation Algorithm Based on Relaxed Functional Dependencies. In Proceedings of the 25th International Conference on Extending Database Technology EDBT, Edinburgh, UK, 29 March–1 April 2022; pp. 52–64. [Google Scholar]
- Van Buuren, S. Flexible Imputation of Missing Data; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 81. [Google Scholar]
- Siddique, J.; Belin, T.R. Multiple imputation using an iterative hot-deck with distance-based donor selection. Stat. Med. 2008, 27, 83–102. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Long, Q. Multiple imputation in the presence of high-dimensional data. Stat. Methods Med. Res. 2016, 25, 2021–2035. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.; Chang, C.; Ido, M.S.; Long, Q. Multiple imputation for general missing data patterns in the presence of high-dimensional data. Sci. Rep. 2016, 6, 21689. [Google Scholar] [CrossRef] [PubMed]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef]
- Deng, Y.; Lumley, T. Multiple Imputation Through XGBoost. arXiv 2021, arXiv:2106.01574. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Missing % | Number of Variables | Number of Trees | Tolerance |
|---|---|---|---|
| 25% | 1 | 400 | 0.01 |
| 100% | 0.59 | 400 | 0.0001 |
| Year | Original | Imputed | AADT | % Diff | |||
|---|---|---|---|---|---|---|---|
| Annual Volume | Days Recorded | Annual Volume | Days Recorded | Original | Imputed | ||
| 2010 | 13,657,299 | 333 | 15,093,344 | 365 | 41,013 | 41,352 | 0.826 |
| 2011 | 11,755,237 | 307 | 14,714,824 | 365 | 38,291 | 40,315 | 5.286 |
| 2012 | 13,076,838 | 281 | 17,652,549 | 366 | 46,537 | 48,231 | 3.641 |
| 2013 | 17,303,743 | 345 | 18,344,154 | 365 | 50,156 | 50,258 | 0.204 |
| 2014 | 17,156,610 | 345 | 18,202,197 | 365 | 49,729 | 49,869 | 0.281 |
| 2015 | 13,867,853 | 287 | 17,873,202 | 365 | 48,320 | 48,968 | 1.340 |
| 2016 | 16,821,151 | 341 | 18,177,959 | 366 | 49,329 | 49,667 | 0.685 |
| 2017 | 16,249,321 | 328 | 18,194,399 | 365 | 49,541 | 49,848 | 0.620 |
| 2018 | 17,218,272 | 347 | 18,182,104 | 365 | 49,620 | 49,814 | 0.390 |
| 2019 | 16,366,929 | 332 | 18,109,640 | 365 | 49,298 | 49,615 | 0.644 |
| 2020 | 15,191,121 | 333 | 16,830,915 | 366 | 45,619 | 45,986 | 0.805 |
| 2021 | 12,828,239 | 309 | 15,613,213 | 365 | 41,515 | 42,776 | 3.036 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shafique, M.A. Imputing Missing Data in Hourly Traffic Counts. Sensors 2022, 22, 9876. https://doi.org/10.3390/s22249876
Shafique MA. Imputing Missing Data in Hourly Traffic Counts. Sensors. 2022; 22(24):9876. https://doi.org/10.3390/s22249876
Chicago/Turabian StyleShafique, Muhammad Awais. 2022. "Imputing Missing Data in Hourly Traffic Counts" Sensors 22, no. 24: 9876. https://doi.org/10.3390/s22249876
APA StyleShafique, M. A. (2022). Imputing Missing Data in Hourly Traffic Counts. Sensors, 22(24), 9876. https://doi.org/10.3390/s22249876