
Multi-Task Learning Model for Kazakh Query Understanding



Abstract
:1. Introduction
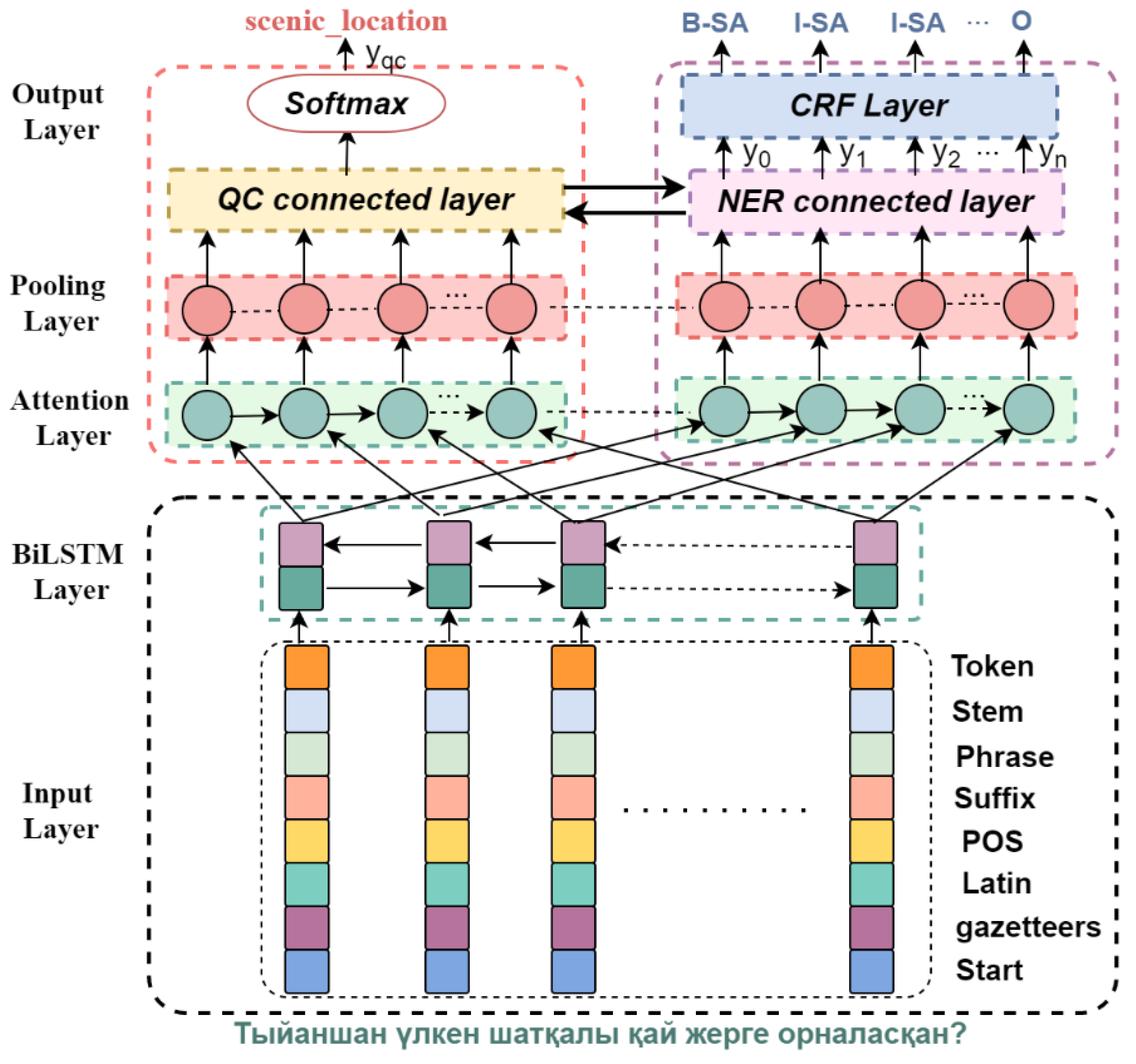
- This paper proposes a deep multi-task learning model (MTQU) that can solve QC and NER tasks, and can learn the interaction mode between the QC and NER through the parameter-sharing mechanism provided by the multi-task learning framework.
- We demonstrate the importance of multi-feature embedding for QU in agglutinative languages.
- We construct a Kazakh query understanding corpus (KQU).
- The proposed QU learning model on the benchmark dataset is evaluated and the effectiveness is verified experimentally.
2. Related Work
2.1. Named Entity Recognition
2.2. Question Classification
2.3. Joint Model for NER and QC
3. Methodology
3.1. Multi-Task Learning Model Structure
3.2. Feature Extraction Layer
3.3. LSTM Layer
3.4. Attention Layer
3.5. Pooling Layer
3.6. Output Layer
4. Datasets
5. Experimental Settings
5.1. Evaluation Measures
5.2. Baselines
5.3. Implementation Details
6. Results and Analysis
6.1. Comparison with Previous Approaches
6.2. Multi-Task Model vs. Individual Models
6.3. Ablation Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Papers with Code—A Survey of Joint Intent Detection and Slot-Filling Models in Natural Language Understanding [EB/OL]. Available online: https://paperswithcode.com/paper/a-survey-of-joint-intent-detection-and-slot (accessed on 6 October 2022).
- Goo, C.-W.; Gao, G.; Hsu, Y.-K.; Huo, C.-L.; Chen, T.-C.; Hsu, K.-W.; Chen, Y.-N. Slot-Gated Modeling for Joint Slot Filling and Intent Prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 2 (Short Papers), pp. 753–757. [Google Scholar]
- Liu, B.; Lane, I. Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling. arXiv 2016, arXiv:1609.01454. [Google Scholar]
- Zhu, S.; Yu, K. Encoder-decoder with focus-mechanism for sequence labelling based spoken language understanding. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5675–5679. [Google Scholar]
- Guo, D.; Tur, G.; Yih, W.; Zweig, G. Joint semantic utterance classification and slot filling with recursive neural networks. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 554–559. [Google Scholar]
- Falke, T.; Lehnen, P. Feedback Attribution for Counterfactual Bandit Learning in Multi-Domain Spoken Language Understanding. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1190–1198. [Google Scholar]
- Broscheit, S.; Do, Q.; Gaspers, J. Distributionally Robust Finetuning BERT for Covariate Drift in Spoken Language Understanding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; (Volume 1: Long Papers), pp. 1970–1985. [Google Scholar]
- Tur, G.; Hakkani-Tür, D.; Heck, L. What is left to be understood in ATIS? In Proceedings of the 2010 IEEE Spoken Language Technology Workshop, Berkeley, CA, USA, 12–15 December 2010; pp. 19–24. [Google Scholar]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips Voice Platform: An embedded Spoken Language Understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Generative and Discriminative Algorithms for Spoken Language Understanding; ISCA: Singapore, 2007; pp. 1605–1608.
- Yao, K.; Peng, B.; Zhang, Y.; Yu, D.; Zweig, G.; Shi, Y. Spoken language understanding using long short-term memory neural networks. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, NV, USA, 7–10 December 2014; pp. 189–194. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual Language Model Pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Ding, R.; Xie, P.; Zhang, X.; Lu, W.; Li, L.; Si, L. A Neural Multi-digraph Model for Chinese NER with Gazetteers. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1462–1467. [Google Scholar]
- Fetahu, B.; Fang, A.; Rokhlenko, O.; Malmasi, S. Dynamic Gazetteer Integration in Multilingual Models for Cross-Lingual and Cross-Domain Named Entity Recognition. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2777–2790. [Google Scholar]
- Zhang, J.; Hao, K.; Tang, X.; Cai, X.; Xiao, Y.; Wang, T. A multi-feature fusion model for Chinese relation extraction with entity sense. Knowl. -Based Syst. 2020, 206, 106348. [Google Scholar] [CrossRef]
- Haisa, G.; Altenbek, G. Deep Learning with Word Embedding Improves Kazakh Named-Entity Recognition. Information 2022, 13, 180. [Google Scholar] [CrossRef]
- Nirob, S.M.H.; Nayeem, M.K.; Islam, M.S. Question classification using support vector machine with hybrid feature extraction method. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 22–24 December 2017; pp. 1–6. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1746–1751. [Google Scholar]
- Dachapally, P.R.; Ramanam, S. In-depth Question classification using Convolutional Neural Networks. arXiv 2018, arXiv:1804.00968. [Google Scholar]
- Xia, W.; Zhu, W.; Liao, B.; Chen, M.; Cai, L.; Huang, L. Novel architecture for long short-term memory used in question classification. Neurocomputing 2018, 299, 20–31. [Google Scholar] [CrossRef]
- Chotirat, S.; Meesad, P. Part-of-Speech tagging enhancement to natural language processing for Thai wh-question classification with deep learning. Heliyon 2021, 7, e08216. [Google Scholar] [CrossRef] [PubMed]
- Haisa, G.; Altenbek, G.; Aierzhati, H.; Kenzhekhan, K. Research on Classification of Kazakh Questions Integrate with Multi-feature Embedding. In Proceedings of the 2021 2nd International Conference on Electronics, Communications and Information Technology (CECIT), Sanya, China, 27–29 December 2021; pp. 943–947. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Mrini, K.; Dernoncourt, F.; Yoon, S.; Bui, T.; Chang, W.; Farcas, E.; Nakashole, N. A Gradually Soft Multi-Task and Data-Augmented Approach to Medical Question Understanding. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; (Volume 1: Long Papers), pp. 1505–1515. [Google Scholar]

{kind=link}
| Query | Тыйаншан | лкен | шатқалы | қай | жерге | oрналасқан | ? |
| NER_tags | B-SA | I-SA | I-SA | O | O | O | O |
| QC_label | Scenic_location | ||||||
| Types | Size |
|---|---|
| train | 5600 |
| dev | 700 |
| test | 700 |
| Question types | 22 |
| NER types | 8 |
| Model | QC-Acc | NER-F1 | Sent-Acc |
|---|---|---|---|
| Attention-BiRNN [3] | 87.81 | 88.65 | 79.76 |
| BiLSTM-LSTM [4] | 88.25 | 88.33 | 80.02 |
| WSGGA-NER [17] | -- | 89.61 | -- |
| Multi-QC [23] | 88.86 | -- | -- |
| MTQU (Ours) | 92.28 | 91.73 | 83.58 |
| Model | QC-Acc | NER-F1 |
|---|---|---|
| MTQU (Only QC) | 90.89 | -- |
| MTQU (Only NER) | -- | 90.61 |
| MTQU (Multi-task model) | 92.28 | 91.73 |
| Word-Level Features | Sentence-Level Features |
|---|---|
| Stem | Gazetteers |
| First-suffix | Noun phrase tagging |
| Second-suffix | Verb phrase tagging |
| Third-suffix | Start of the sentence |
| Nominal-suffix | |
| Latin words |
| Model | QC-Acc | NER-F1 | Sent-Acc |
|---|---|---|---|
| Contacted all-features | 92.28 | 91.73 | 83.58 |
| Remove word-level features | 90.39 | 90.68 | 81.76 |
| Remove sentence-level features | 90.75 | 89.87 | 82.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haisa, G.; Altenbek, G. Multi-Task Learning Model for Kazakh Query Understanding. Sensors 2022, 22, 9810. https://doi.org/10.3390/s22249810
Haisa G, Altenbek G. Multi-Task Learning Model for Kazakh Query Understanding. Sensors. 2022; 22(24):9810. https://doi.org/10.3390/s22249810
Chicago/Turabian StyleHaisa, Gulizada, and Gulila Altenbek. 2022. "Multi-Task Learning Model for Kazakh Query Understanding" Sensors 22, no. 24: 9810. https://doi.org/10.3390/s22249810
APA StyleHaisa, G., & Altenbek, G. (2022). Multi-Task Learning Model for Kazakh Query Understanding. Sensors, 22(24), 9810. https://doi.org/10.3390/s22249810