3.1. Data Analysis
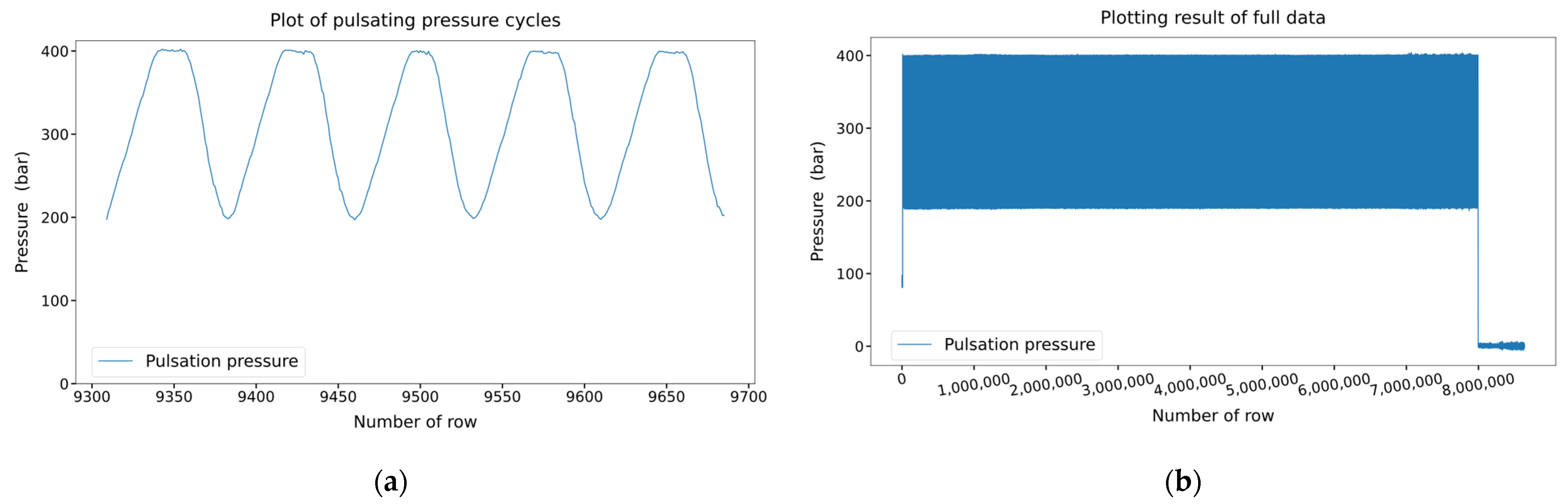
The collected pulsating pressure data had 8,640,140 rows and 2 columns. The first column indicates the time, and the second column indicates the pulsating pressure. We obtained 100 rows of pulsating pressure data per second, and the results of plotting the pulsating pressure cycles are shown in
Figure 4a. As mentioned in
Section 2.2, the on/off state of the pneumatic valve is operated for 0.4 s each, making one cycle 0.8 s long. Since 100 data samples are received in 1 s, 80 data samples are received in 0.8 s. Referring to
Figure 4a, 80 rows form 1 cycle, and it can be observed that the data were received well according to the operation setting of the pneumatic valve.
The plotting results of the pulsating pressure cycles in
Figure 4a over the entire dataset are shown in
Figure 4b.
Figure 4b shows that the pulsating pressure was maintained between 200 and 400 bar and then dropped to zero near the 8,000,000th row. In the 7,995,460th row, the accumulator broke, and pressure was not generated, dropping the pressure to zero. The upper and lower limits of the pulsating pressure tend to increase slightly after the 7,000,000th row. This change occurred approximately 2.7 h before the breakage of the accumulator. If an algorithm that can capture this trend is developed, an accident can be prevented using an anomaly detection algorithm. Therefore, in this study, an algorithm was developed to detect such anomalies in advance.
3.2. Threshold Averaging Algorithm over a Period
Up to the 4,000,000th row in
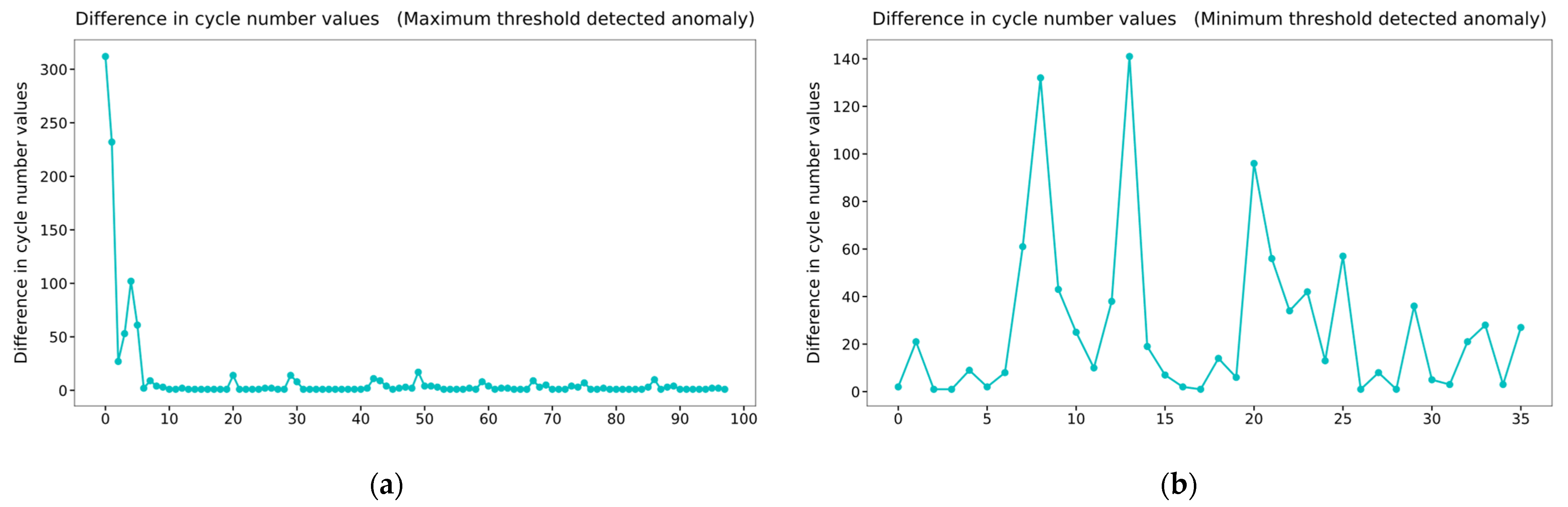
Figure 4b corresponds to half of the data before the breakage of the accumulator. Therefore, in this section, the maximum and minimum thresholds from the data up to the 4,000,000th row will be determined, and anomaly detection for the rest of the data will be performed. We placed the maximum and minimum thresholds in the first 50 pulsation cycles into two arrays of the NumPy library to find the thresholds. The previous process was performed in the subsequent 50 cycles, and this process was repeated until the data of the 4,000,000th row. The values in the two arrays were then averaged to obtain the maximum and minimum thresholds. The average thresholds were obtained as 400.4579 and 189.7104, respectively. When the thresholds of the cycles after the 4,000,000th row deviate from 0.2% of the averaged threshold, the number of cycle values is inserted into 2 new arrays. In other words, cycles exceeding 1.002 times the maximum average threshold or less than 0.998 times the minimum average threshold are detected. Subsequently, the difference between the values in each array was calculated, and their plotting results are shown in
Figure 5. The first point in
Figure 5a indicates that there are more than 300 normal cycles between the cycles in which the abnormality in the maximum threshold is detected. Since these anomalies can occur occasionally, it is not appropriate to use these cycles for anomaly detection. However, from the 10th point, it can be observed that there is almost no difference between the detected cycle numbers, which means that abnormality detection occurs frequently. Therefore, the user can predict that a problem will occur in the accumulator, as there is no difference in values from the 10th to the 20th points based on the plotting result. If it is assumed that the user detects an abnormality at the 20th point, the user predicts a failure 2.5 h before the breakage. This is the case in
Figure 5b, which shows the difference between the values of the minimum threshold cycle number detected as an anomaly. The values are not constant, so abnormal detection cannot be performed.
3.3. Anomaly Detection Using SVM
Considering the change in pulsation pressure after the 7,000,000th row in
Figure 4b, an abnormality was detected by classifying before and after the 7,000,000th row as normal or abnormal. The distinction between normal and abnormal based on the 7,000,000th row was equally applied to
Section 3.3,
Section 3.4, and
Section 3.5. When the front part of the graph in
Figure 4b was enlarged, the minimum threshold showed a tendency to gradually decrease until the 25,000th row; therefore, data from the 25,000 to 6,955,000 rows were used.
Among the data from the 25,000th row to the 6,955,000th row, the pulsating pressure data for 15 min were successively contained in a NumPy array. Consequently, a NumPy array with 77 rows and 90,000 columns containing normal pulsating pressure data was created. The data from the 6,955,000th row to the 7,945,000th row were successively contained in a new NumPy array at 15 min intervals, and a NumPy array containing 11 rows and 90,000 columns of abnormal pulsating pressure data was generated. Training and test sets were created at a rate of 60% and 40%, respectively, from the NumPy array of normal pulsating pressure data, and another training set and a test set were created at the same rates from the NumPy array of abnormal pulsating pressure data. These training and test sets were then combined to create a final training set and a test set with normal and abnormal pulsating pressure data. Finally, a training set with 53 rows and 90,000 columns and a test set with 35 rows and 90,000 columns were generated.
Referring to
Figure 4b, it can be seen that the maximum threshold value spikes in the section with abnormal pulsating pressure. Therefore, 100 pulsating pressure data were extracted from 90,000 pulsating pressure data for each row in the training and test sets by sorting them in the order of the largest value. Consequently, a training set with 53 rows and 100 columns and a test set with 35 rows and 100 columns were generated. By doing this, the machine learning model was trained with the maximum threshold values of the normal pulsating pressure data and the spike values of the maximum threshold for the abnormal pulsating pressure data. The training and test sets were labeled zero and one for normal and abnormal, respectively.
The generated training and test sets were subjected to standard scaling, as shown in Equation (10) for standardization. In Equation (10),
is the sample,
is the mean of the samples,
is the standard deviation of the samples, and
is a standardized sample. Equation (10) is as follows:
The scaled training set and training set labels were used as the training data for the support vector classification (SVC) model of scikit-learn library. Among the hyperparameters of the SVC model, C, a regularization parameter, was set to one, and the RBF was used for the kernel trick.
As a result of the performance evaluation of the trained SVC model using the scaled training set and labels of the training set, the accuracy was 0.9811. The performance of the model was evaluated with the scaled test set and the label of the test set, and the accuracy was 0.8571, indicating that the SVC model properly detected anomalies.
3.4. Anomaly Detection Using XGBoost
The same training and test sets obtained in
Section 3.3 were used for the XGBoost model. The XGBClassifier of the DLMC XGBoost library was used to solve the classification problem. The hyperparameters used in the XGBClassifier model and their values are listed in
Table 3. The description of the hyperparameters in
Table 3 is as follows. Variable eta represents the learning rate, and the lower the value of eta, the more robust the model and the better the prevention of overfitting. If eta is large, then the update rate of the model increases. Here, min_child_weight is the minimum sum of the instance weights required in a child. Furthermore, gamma is the minimum loss reduction value that determines the further division of a leaf node in the tree. The maximum depth of the tree was set as max_depth, while colsample_bytree is the subsample ratio of columns when constructing each tree. The lambda is an L2 regularization term for the weights, while alpha is the L1 regularization term of the weights. Finally, scale_pos_weight controls the balance between the positive and negative weights [
20].
The XGBClassifier model with the above-mentioned hyperparameters was trained using the scaled training set and labels of the training set. As a result of measuring the performance of the XGBClassifier model trained with the scaled training set and the labels of the training set, the accuracy was one. The performance was measured with the scaled test set, and the accuracy was 0.8857 for the label of the test set. Referring to accuracy, which is a performance evaluation metric, the XGBClassifier model is better at detecting anomalies than the SVC model.
3.5. Anomaly Detection Using CNN
Considering the change in pulsating pressure after the 7,000,000th row, an abnormality was detected by classifying before and after the 7,000,000th row as normal/abnormal. When the front part of the graph in
Figure 4b was enlarged, the minimum threshold was not constant before the 25,000th row; therefore, data from the 25,000th row to the 6,955,000th row were used.
From the 25,000th to the 6,955,000th row, sequential 15 min pulsating pressure data graphs were saved as jpg files with a size of 256 × 256 pixels by using Matplotlib library. The saved files were normal graphs, and 77 picture files were saved. The data from the 6,955,000th row to the 7,945,000th row were also saved in the same manner as in the previous process. The saved files were abnormal graphs, and 11 picture files were saved. In the normal and abnormal graph picture files, the training and test sets were divided at a rate of 60% and 40%. Therefore, 46 randomized graph picture files out of 77 normal graph picture files and 7 randomized graph picture files out of 11 abnormal graph picture files were used as the training set. In other words, 53 normal and abnormal graph pictures were used as the training set, and 35 normal and abnormal graph pictures were used as the test set. The picture files in the training set were RGB image files with a size of (256, 256, 3). Therefore, these images were converted into an array format to enable the learning of the model. By adding a dimension to this array, it was converted to a size of (1, 256, 256, 3), and all image arrays of the training set were stacked to create an array of size (53, 256, 256, 3) as the training set for the CNN model. A label array of size (53, 1) was created by setting the label to zero for a normal graph image and one for an abnormal graph image. The test set underwent the same process as the training set, and a test set array of size (35, 256, 256, 3) and a test label array of size (35, 1) were created. Since the image data have pixel information as a value between zero and 255, normalization was performed by dividing the training set and the test set by 255 to facilitate model learning.
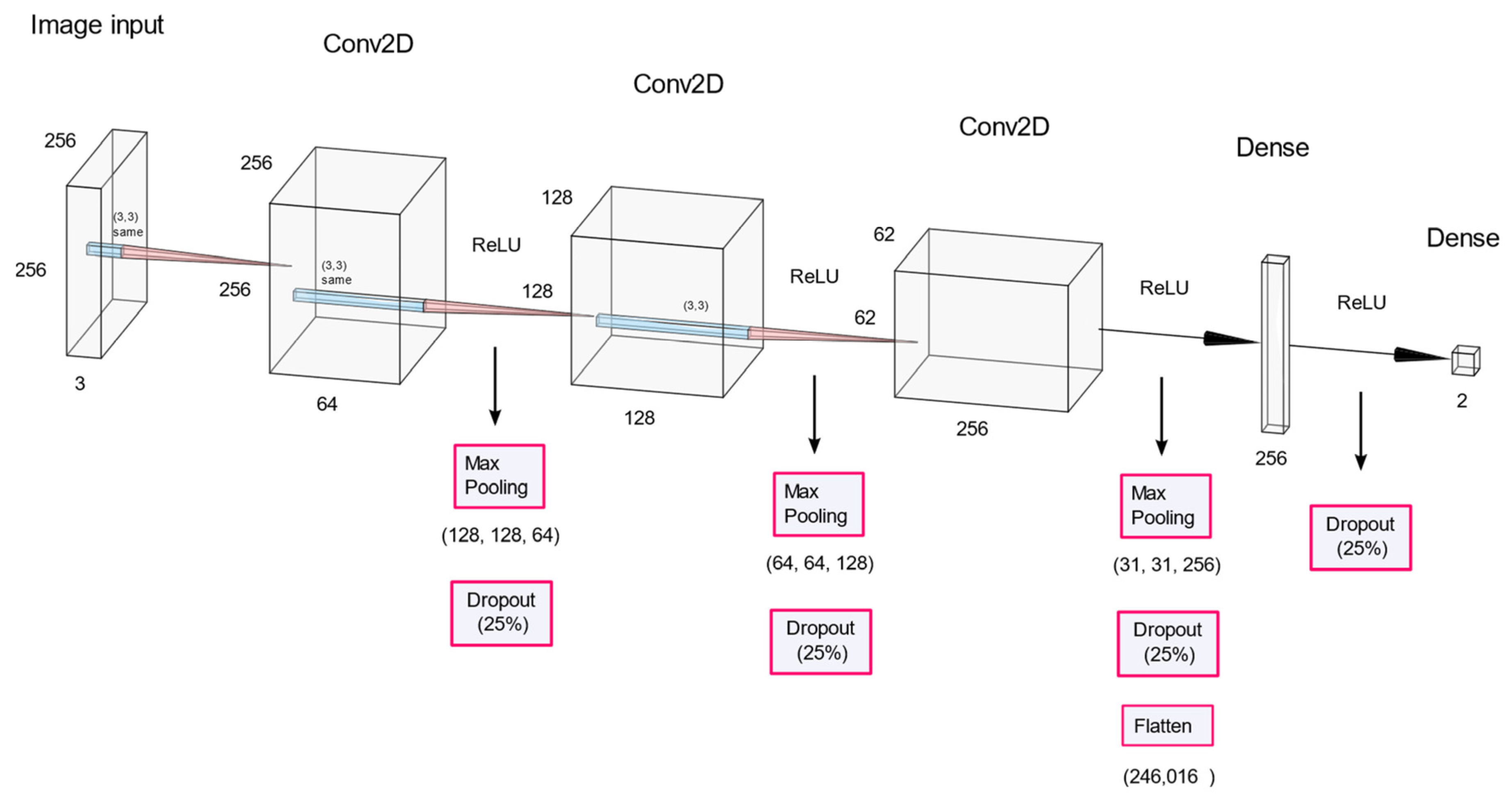
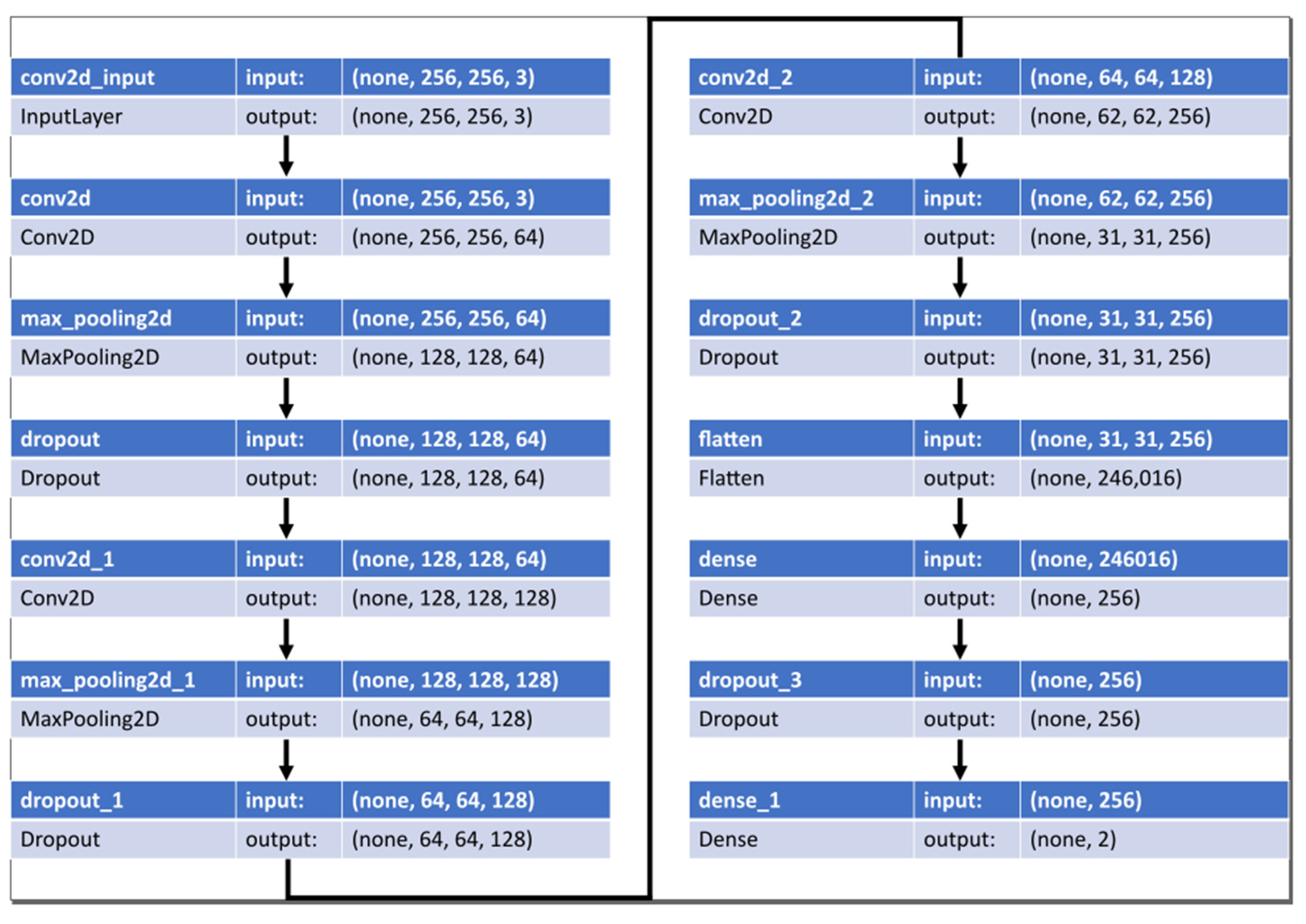
The normalized training set goes through the process of
Figure 6. The CNN model has three convolutional layers, followed by max-pooling and dropout. Subsequently, the final binary classification was performed using two dense layers. The kernel size of the convolutional layer was set to three, padding was set to the same zero padding, and ReLU was used as the activation function. The max pooling size was set to two, and the dropout probability was set to 0.25.
The outputs of the two neurons in the last layer pass through a sigmoid activation function. Adam was used as the model optimizer, and the accuracy of Equation (9) was used as the performance evaluation metric.
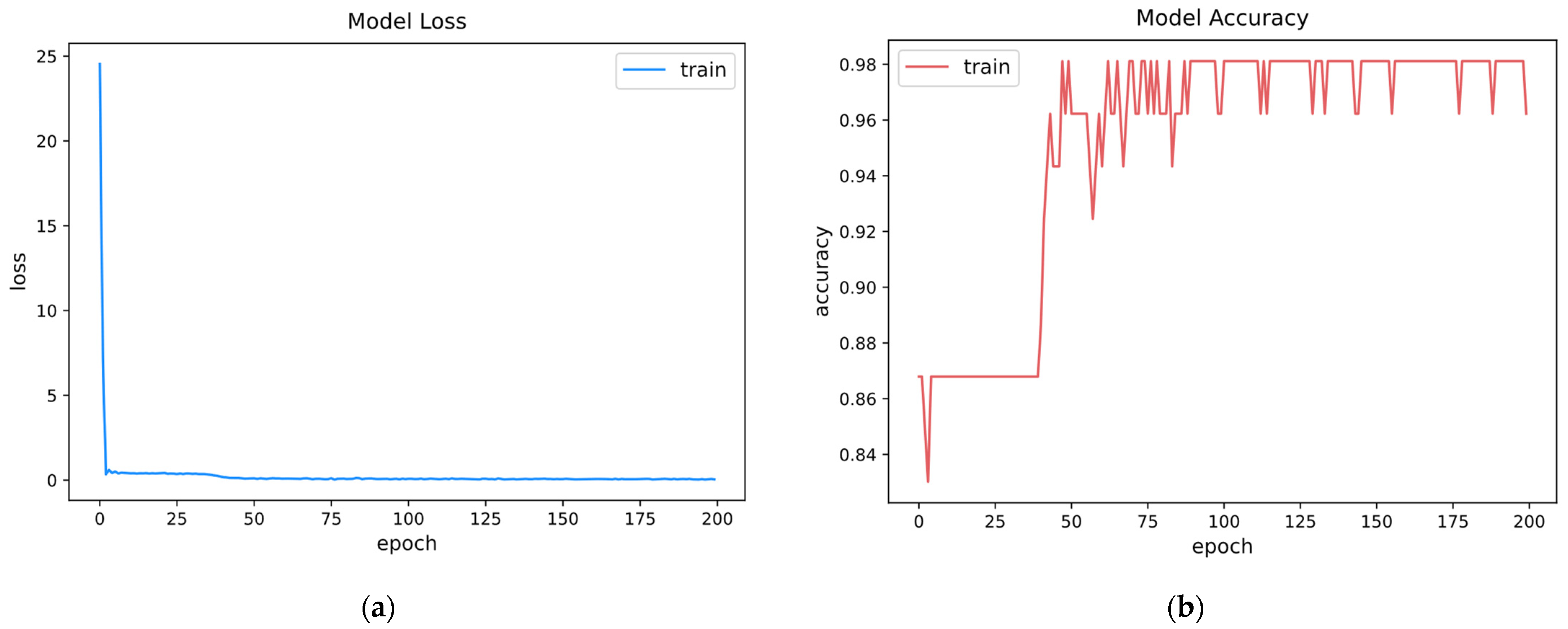
The batch size was set to 30, and the model was trained for 200 epochs. The graphs of the training process and the results are shown in
Figure 7. In the model training process, the loss dropped from approximately 24 to 0.3 in 3 epochs and remained below 1 after that; after 42 epochs, the model accuracy increased from approximately 0.87 to more than 0.9 and remained above 0.9 after that. The model accuracy was measured as 0.9714 using the test set.
3.6. Anomaly Detection Using CNN Autoencoder
To detect anomalies using the CNN autoencoder, 77 normal pulsating pressure images and 11 abnormal pulsating pressure images generated in
Section 3.5 were used. A training set of sizes (77, 256, 256, 3) was created by stacking 77 normal pulsating pressure images of sizes (256, 256, 3). A test set of sizes (11, 256, 256, 3) was created by stacking 11 abnormal pulsating pressure images of sizes (256, 256, 3). The training and test sets were divided by 255 for normalization.
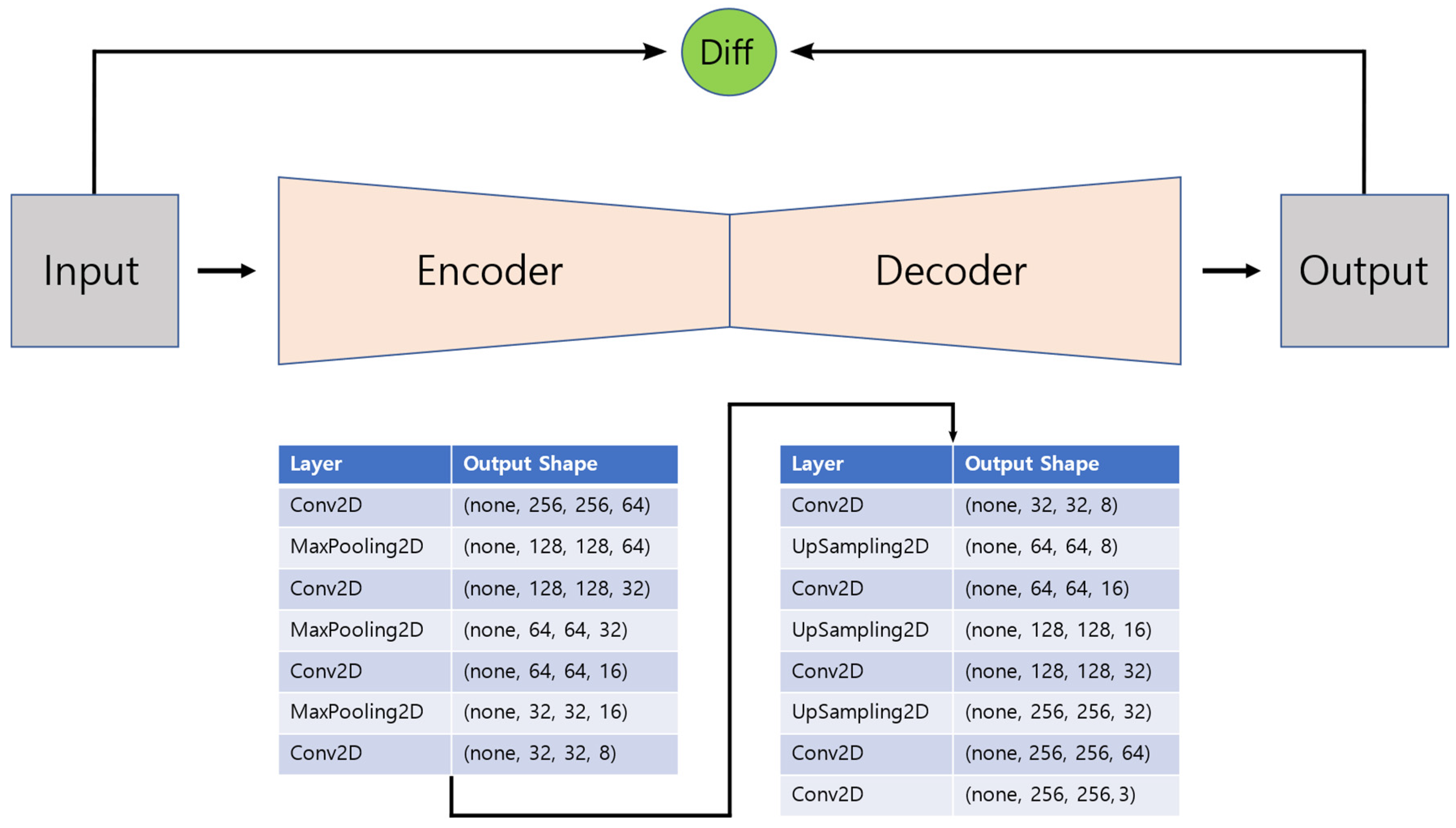
The structure of the CNN autoencoder modeled for anomaly detection is shown in
Figure 8. An input image of size (256, 256, 3) is input to the model. In the encoder part of the model, convolution was performed while lowering the number of filters to 64, 32, 16, and 8 to reduce the number of feature maps and reduce the horizontal and vertical sizes of the image by max pooling 3 times. In the decoder part of the model, convolution is performed while increasing the number of filters to 8, 16, 32, and 64 to increase the number of feature maps and increase the horizontal and vertical sizes of the image by upsampling 3 times. Finally, convolution was performed to obtain an image of the same size as the input image. The kernel size of the convolutional layer was set to three, and the padding was set to the same zero padding. In the last convolution layer, the sigmoid was used as an activation function, and Swish, as shown in the following Equation (11), was used in the convolution layers:
The max pooling size was set to two, and upsampling was performed using the nearest neighbor method. Nadam was used as the model optimizer, and the training set was used as the input and output data. The number of epochs was set to 100, and the batch size was set to 1 for model training.
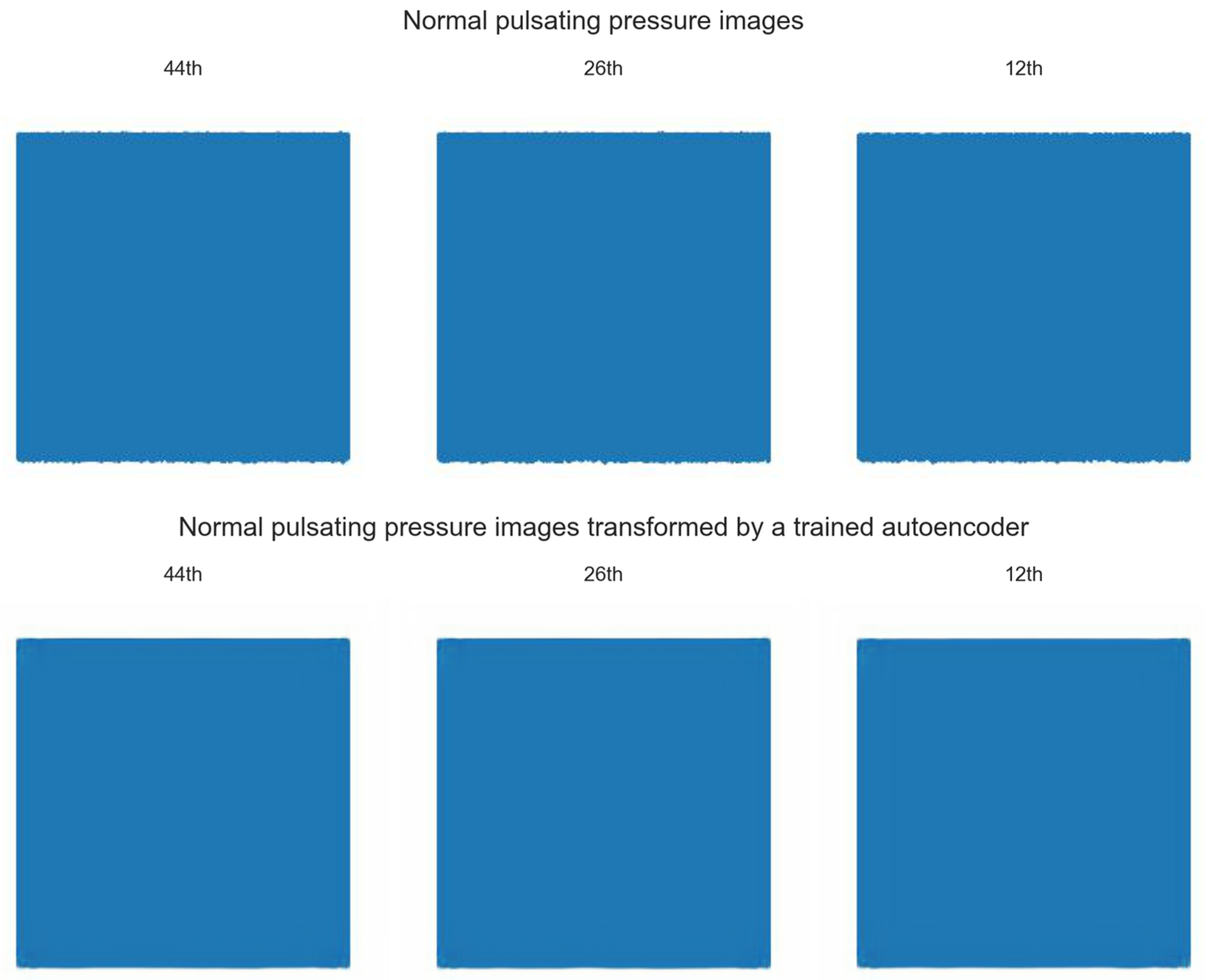
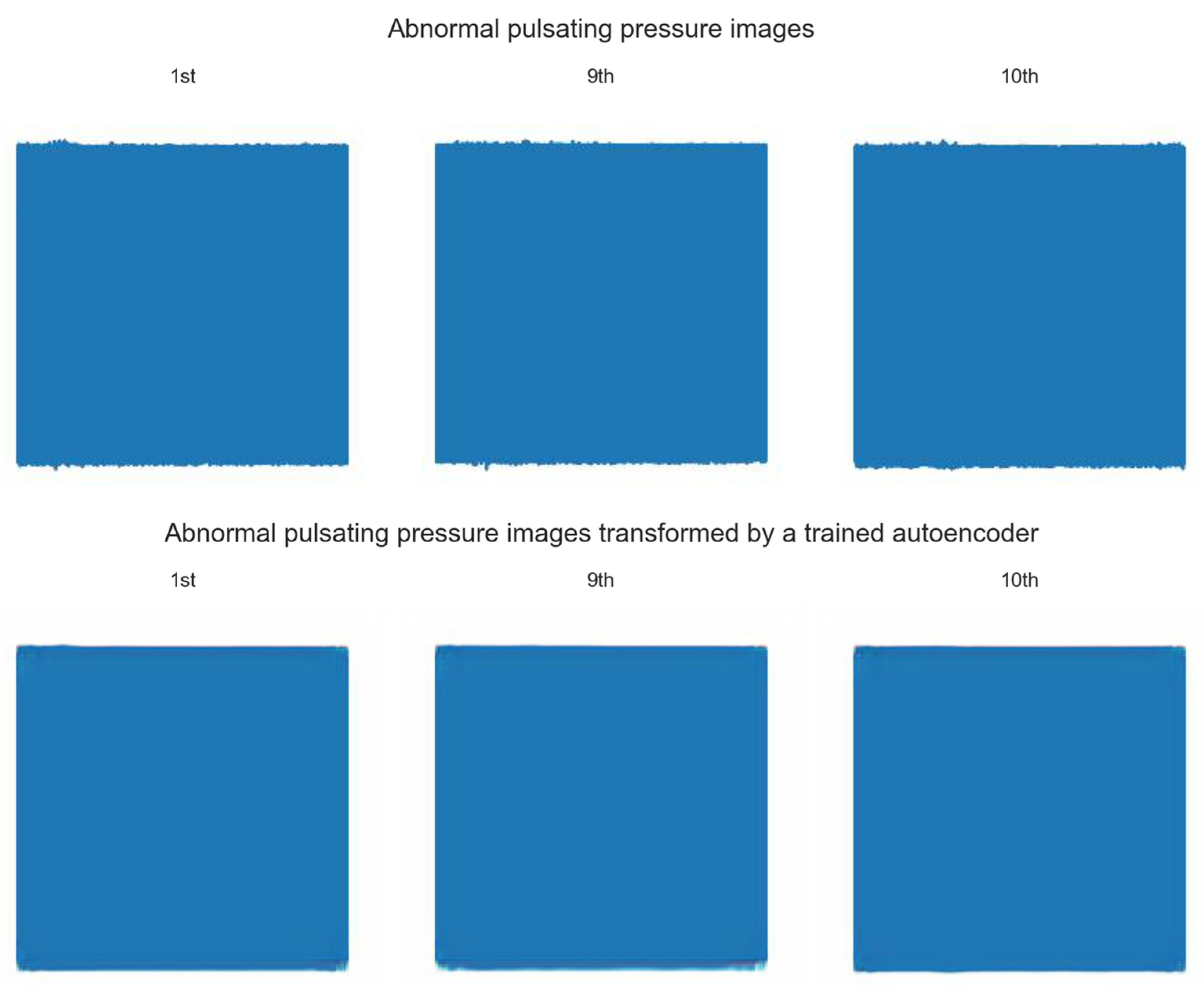
Figure 9 shows 3 randomly sampled images among 77 normal pulsating pressure images and images converted by the CNN autoencoder. As shown in
Figure 9, the normal pulsating pressure images transformed by the trained model are almost similar to the existing normal pulsating pressure images. However, there is a slight deviation between the minimum pulsating pressure values in the existing normal pulsating pressure images, and there is almost no deviation in the minimum pulsating pressure values of the normal pulsating pressure images transformed by the CNN autoencoder.
Figure 10 shows 3 randomly sampled images among 11 abnormal pulsating pressure images and images converted by the CNN autoencoder. Referring to the images of the abnormal pulsating pressure, it can be seen that a deviation occurs to the maximum and minimum pulsating pressure values. However, in the abnormal pulsating pressure images transformed by the trained CNN autoencoder, the deviation of the pulsating pressure values is removed so that the values of the maximum/minimum pulsating pressures appear as smooth lines. This is because the CNN autoencoder is trained with normal pulsating pressure images with little deviation in pulsating pressure, and even if abnormal pulsating pressure images with a deviation of pulsating pressure are input to the CNN autoencoder, it outputs images similar to normal pulsating pressure images.
The upper part of
Figure 11 shows the absolute value of the difference between the normal pulsating pressure images in
Figure 9 and those transformed by the CNN autoencoder. Since the absolute value of the difference between the normal pulsating pressure image and that transformed by the CNN autoencoder is almost zero, the majority of the images are black. In the maximum/minimum pulsating pressure area, there was no significant difference between the normal pulsating pressure image and that transformed by the CNN autoencoder; hence, it can be observed that there is a slight color in the maximum/minimum pulsating pressure area. Referring to the lower part of
Figure 11, the color is conspicuously visible in the maximum/minimum pulsating pressure area, making it possible to detect abnormalities. In
Figure 10, due to the difference between the maximum/minimum pulsating pressure area of the abnormal pulsating pressure images and the transformed abnormal pulsating pressure images, it can be observed that a distinct color occurred compared to the upper part of
Figure 11.
If the absolute values of the difference between the normal pulsating pressure images and the transformed images are calculated, a NumPy array of sizes (77, 256, 256, 3) is obtained. By averaging the numerical values of 77 images, 77 values were obtained. If the absolute values of the difference between the abnormal pulsating pressure images and the deformed images are calculated, a NumPy array of sizes (11, 256, 256, 3) is obtained. A total of 11 values were obtained by averaging the numerical values of 11 images. The minimum, average, and maximum values of 77 and 11 are listed in
Table 4.
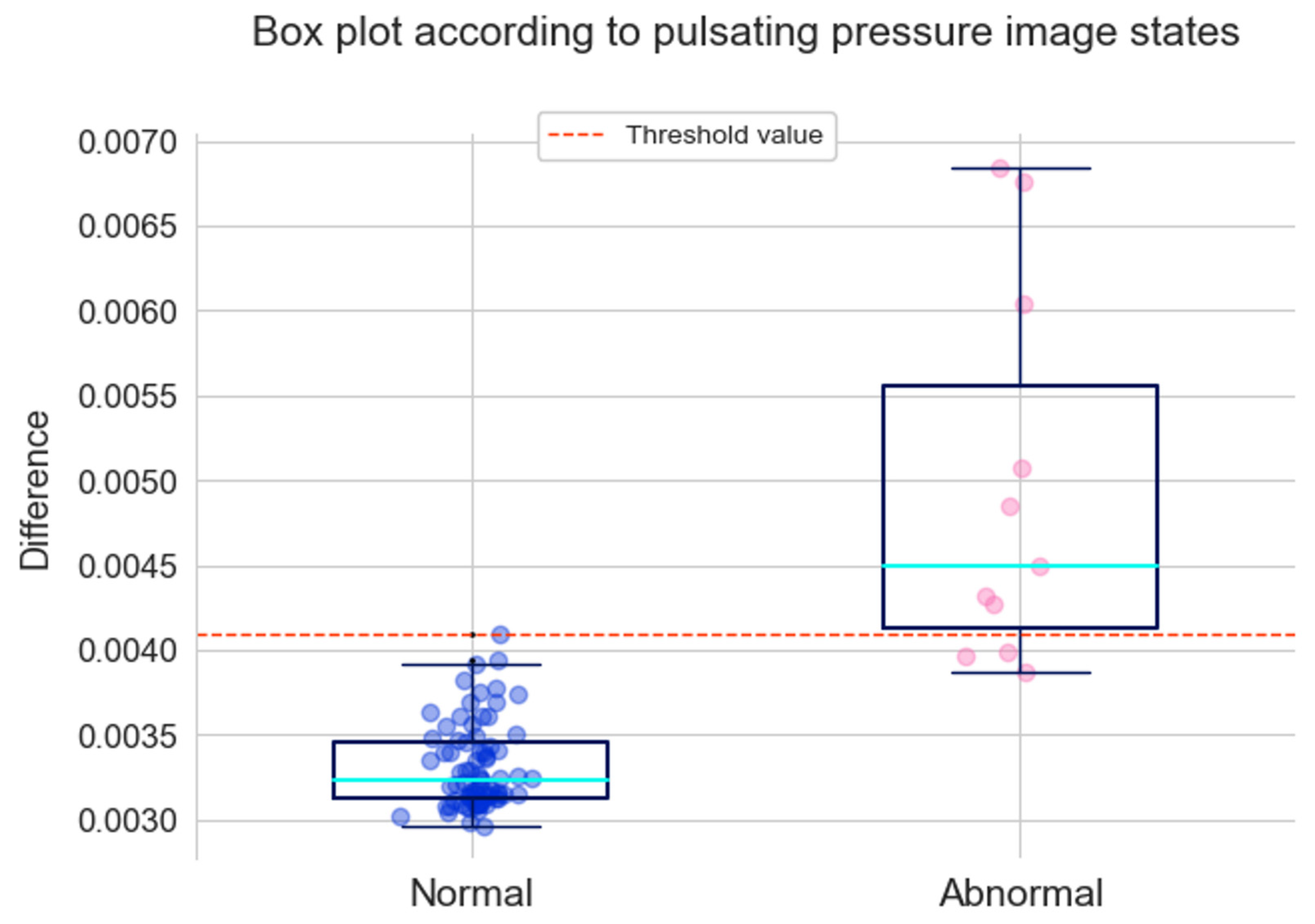
The results of the 77 and 11 values displayed as boxplots are shown in
Figure 12. The top and bottom lines in the boxplot represent the maximum and minimum values, respectively. The top line in the box is the third quartile, which represents the median of the top 50% of values. The bottom line in the box represents the first quartile, which is the median of the bottom 50% of values. The blue-green line represents the median. The maximum value of the normal condition was used as the threshold for classifying the abnormal conditions. Referring to
Figure 12, based on the threshold, it can be confirmed that 8 out of 11 abnormal values were properly detected, except for 3 values.
3.7. Anomaly Detection Using LSTM Autoencoder
In
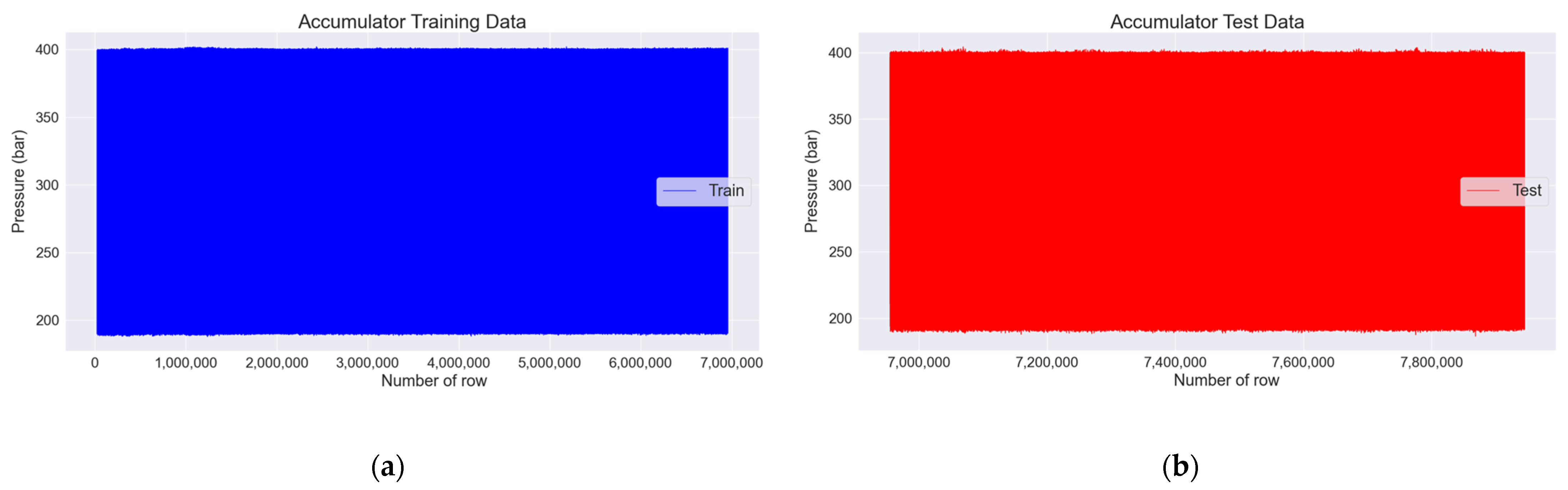
Section 3.7, the normal pulsating pressure, i.e., the 25,000th to 6,955,000th row, was used as the training data, as shown in
Figure 13a, and the abnormal pulsating pressure, i.e., the 6,955,000th to 7,945,000th row, was used as the test data, as shown in
Figure 13b. Accordingly, the training data had 6,930,000 pulsating pressure values, and the test data had 990,000. As shown in
Figure 13a, the maximum and minimum values of the pulsating pressure are relatively constant, and when referring to
Figure 13b, there is a deviation in the maximum and minimum values of the pulsating pressure. Thus, it can be seen that there are spiking values.
As shown in Equation (12), the min–max scaling was applied to the training and test data. When min–max scaling was performed, the scaled data had a value between zero and one. Equation (12) is as follows:
To be input into the LSTM cell, the training data were converted to size (6930000, 1, 1), and the test data were converted to size (990000, 1, 1).
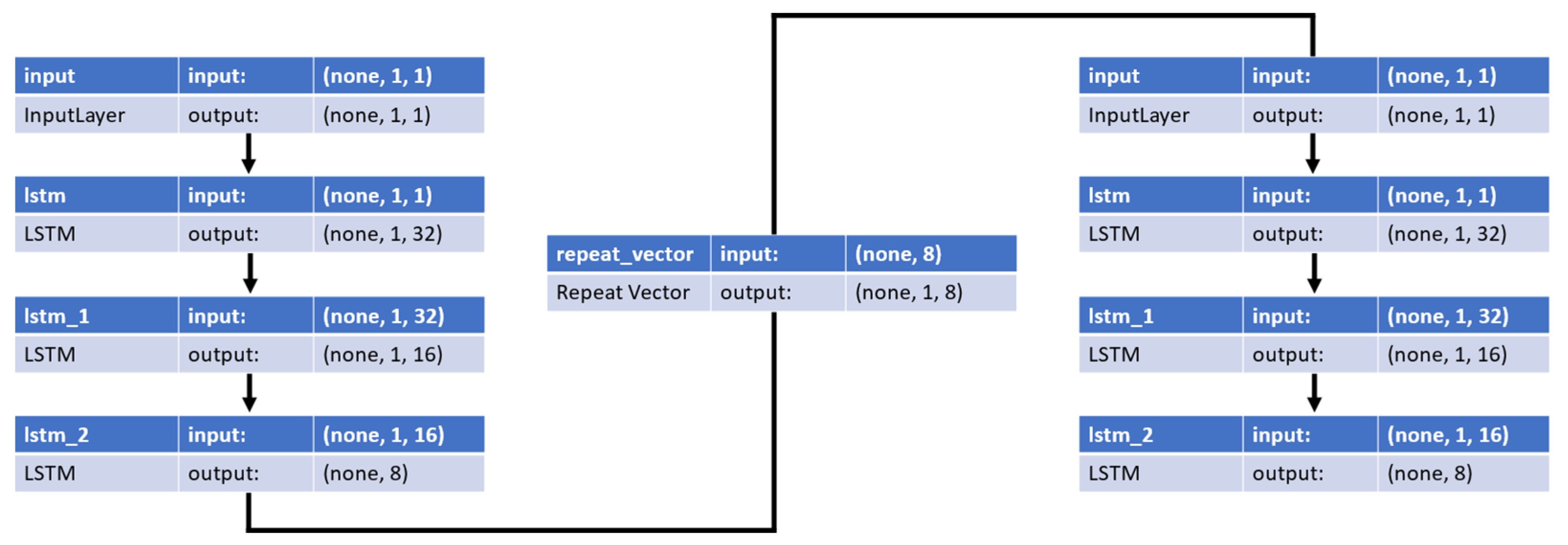
The structure of the LSTM autoencoder used to detect anomalies is shown in
Figure 14. The left part of
Figure 14 shows an encoder that generates compressed input data. In the encoder, the LSTM cells were sequentially composed of 32, 16, and 8 cells, and Swish was used as the activation function. The middle part of
Figure 14 shows a repeat vector layer that distributes the compressed representational vector across the time steps of the decoder. The right side of
Figure 14 shows the decoder that provides the reconstructed input data. In the decoder, 8, 16, and 32 LSTM cells were used, and Swish was used as the activation function. The LSTM autoencoder model uses Nadam as an optimizer and the MAE shown in Equation (13) as a loss function. Here, MAE is a performance metric that converts the difference between actual and predicted values into absolute values and averages them. Equation (13) is as follows:
The model was trained for 100 epochs with a batch size of 1000 and a validation set of 5% of the training set.
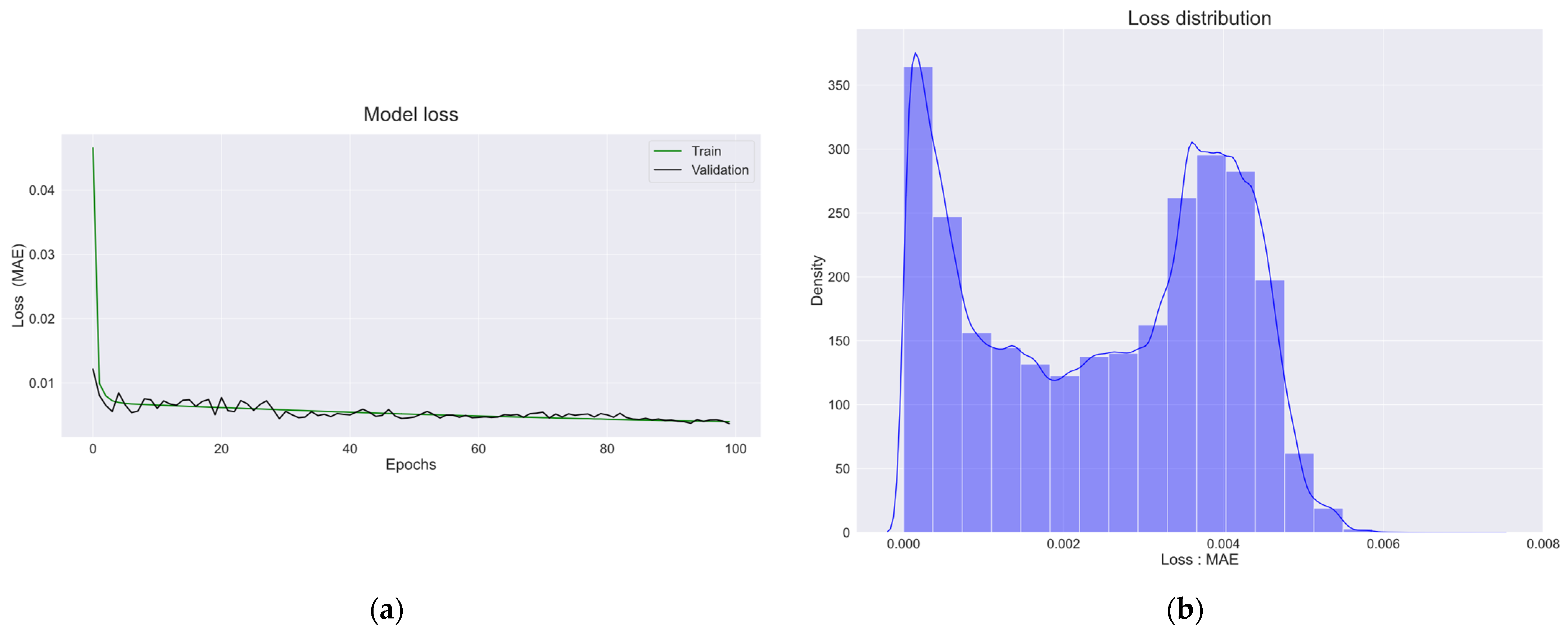
Figure 15a shows the training and validation sets trained for 100 epochs. As shown in
Figure 15a, the MAE values for the training and validation sets decreased as the number of epochs increased, indicating that the model was well-trained.
Figure 15b shows the distribution of MAE values calculated using the actual and predicted values of the training set of the trained LSTM autoencoder model. Referring to
Figure 15b, the MAE values were mostly zero. The density of MAE decreased from 0 to 0.002 of the MAE value, and it increased again from 0.002 to 0.004. It can be seen that the density of MAE starts to decrease from 0.004 of the MAE value, and the density becomes almost zero at 0.006.
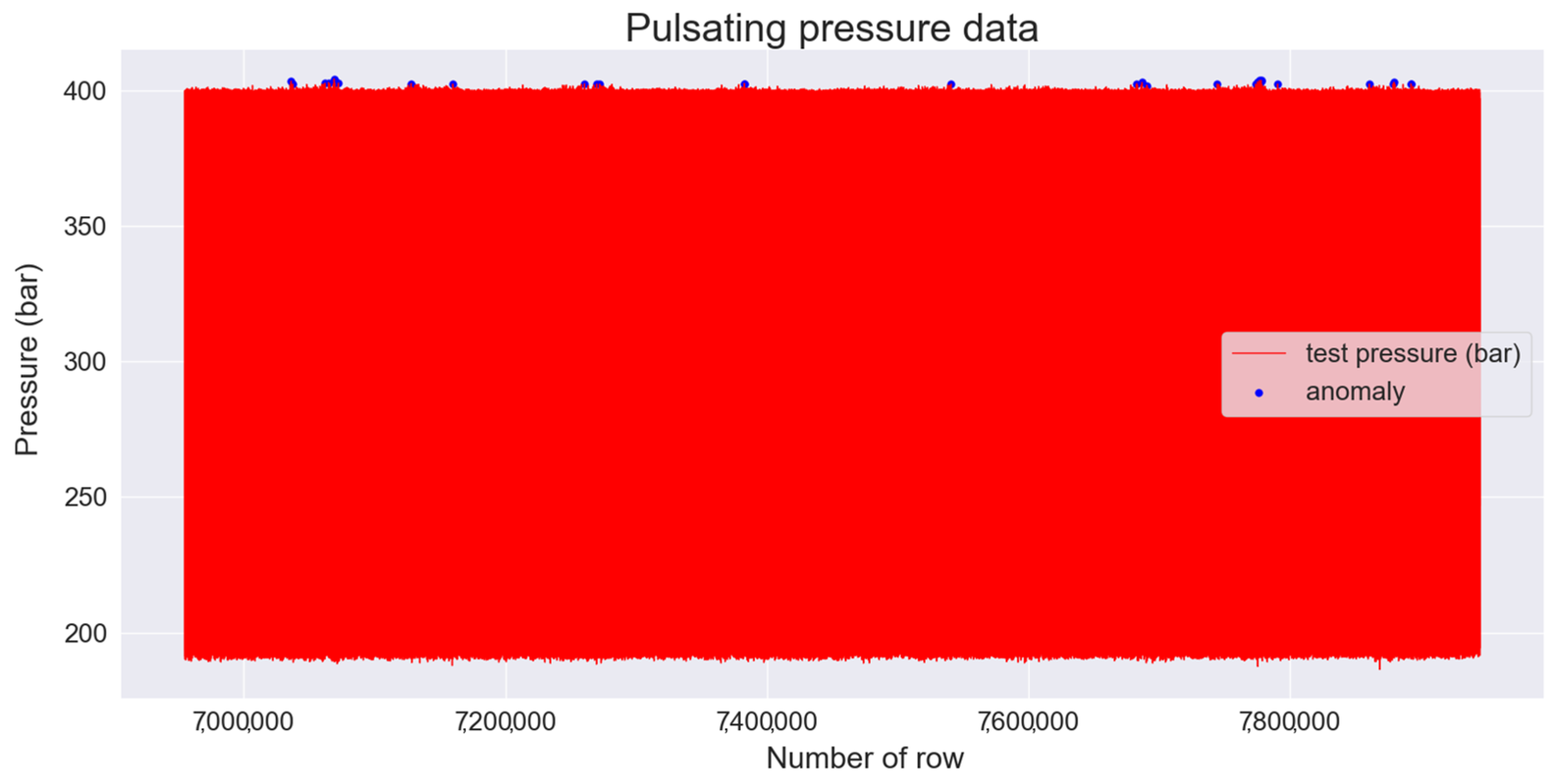
Anomalies were detected using the largest MAE value obtained by the training set as the threshold, and the obtained threshold value was 0.0073. To detect anomalies in the test set, the MAE value was obtained from the values predicted by the test set and the trained LSTM autoencoder. When the obtained MAE value exceeded the threshold, an abnormality was detected, and 36 data points were detected. The 36 data points that detected anomalies in the test set are indicated by blue dots in
Figure 16.
3.8. Comparison of Six Anomaly Detection Algorithms
In
Section 3.8, the six algorithms mentioned above were compared and analyzed. Threshold averaging algorithms detected anomalies based on maximum and minimum thresholds. However, as shown in
Figure 5, it could detect anomalies well at the maximum threshold, but not well at the minimum threshold. Therefore, depending on the data acquired, the selection of a maximum or minimum threshold may be necessary. Unlike threshold averaging algorithms, the five algorithms mentioned later are models trained by training data.
Here, SVM and XGBoost used the same training set and test set and, when comparing accuracy, XGBoost was more robust. The CNN model required a process of saving images, but the accuracy was 0.9714, which was significantly higher than both SVM and XGBoost. The CNN autoencoder detected anomalies using the images used in the CNN model and correctly classified 8 out of 11 abnormal images as abnormal images. This model has the advantage of being able to visualize the anomalous detected area through the difference between the image that passed through the autoencoder and the image that did not. In the case of the LSTM autoencoder model, time series data was used, and 36 data points exceeding the threshold were detected among the entire test set.



 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}