

SDC-Net: End-to-End Multitask Self-Driving Car Camera Cocoon IoT-Based System


Abstract
:1. Introduction
- Warn the driver that there is an accident in front of them. Then, the driver will have the ability to take a reasonable corrective action. This is called the forward collision warning (FCW) functionality;
- Apply automatic emergency braking (AEB) functionality; however, this functionality is specific to low speeds.
2. Literature Review
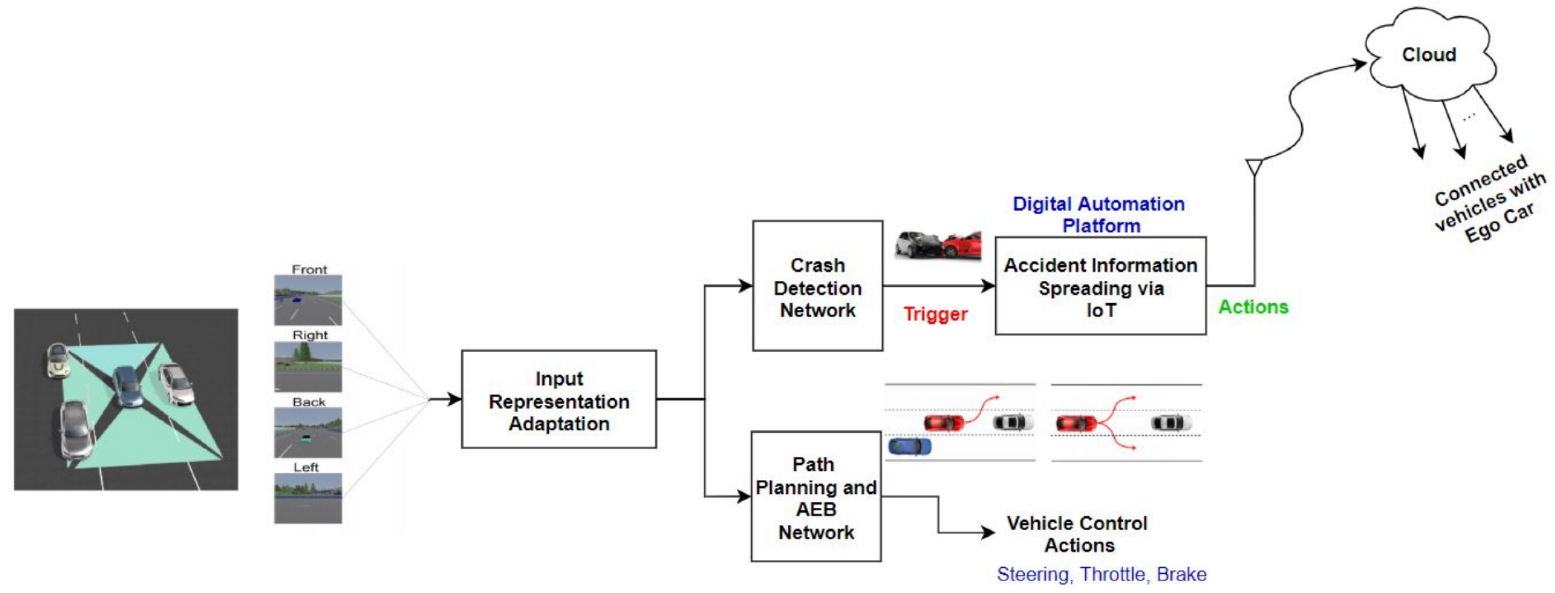
3. System Methodology
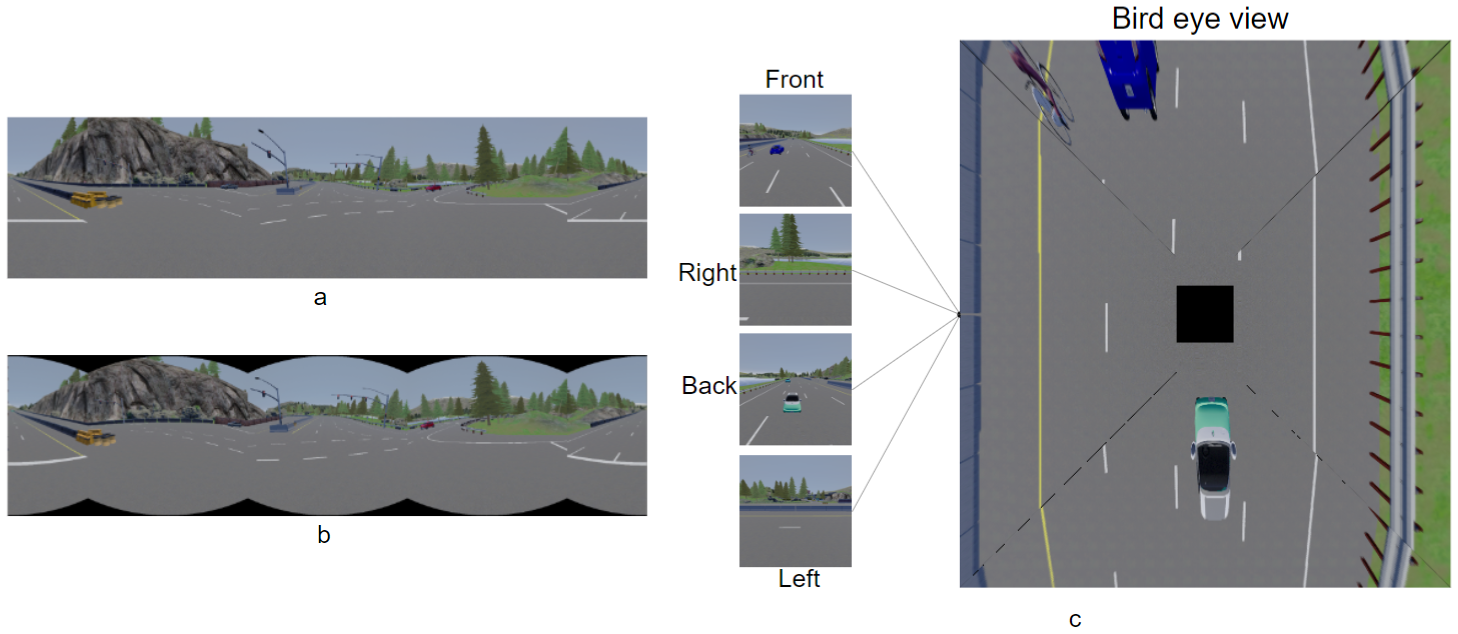
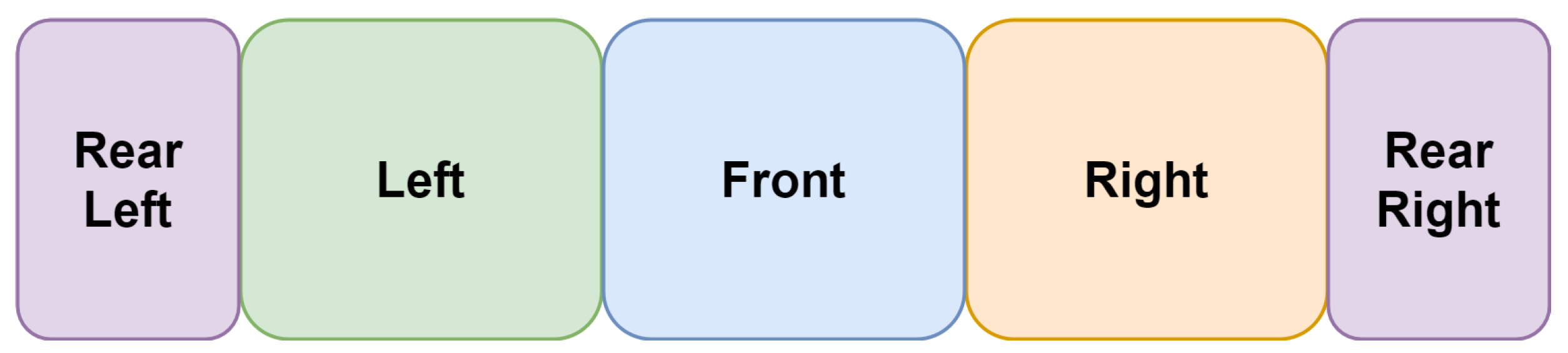
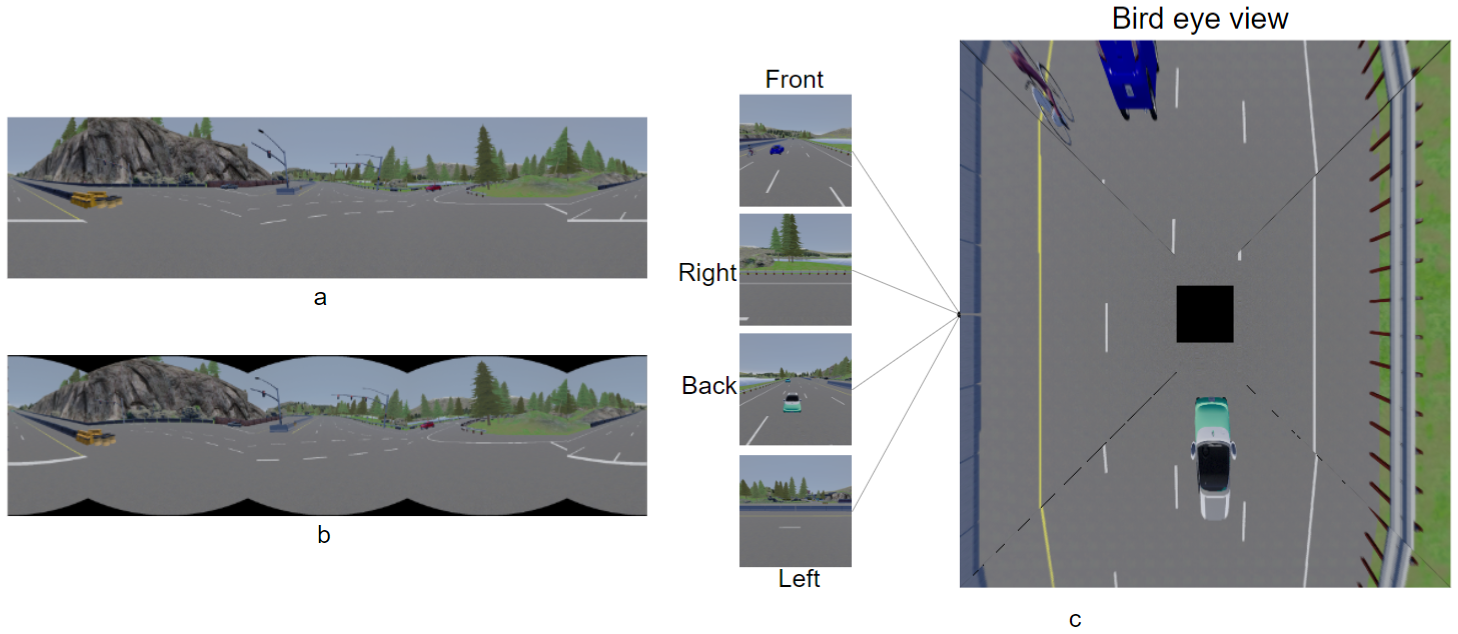
3.1. Input Representations
3.1.1. Panorama—Normal Stitching
3.1.2. Panorama—Equirectangular Stitching
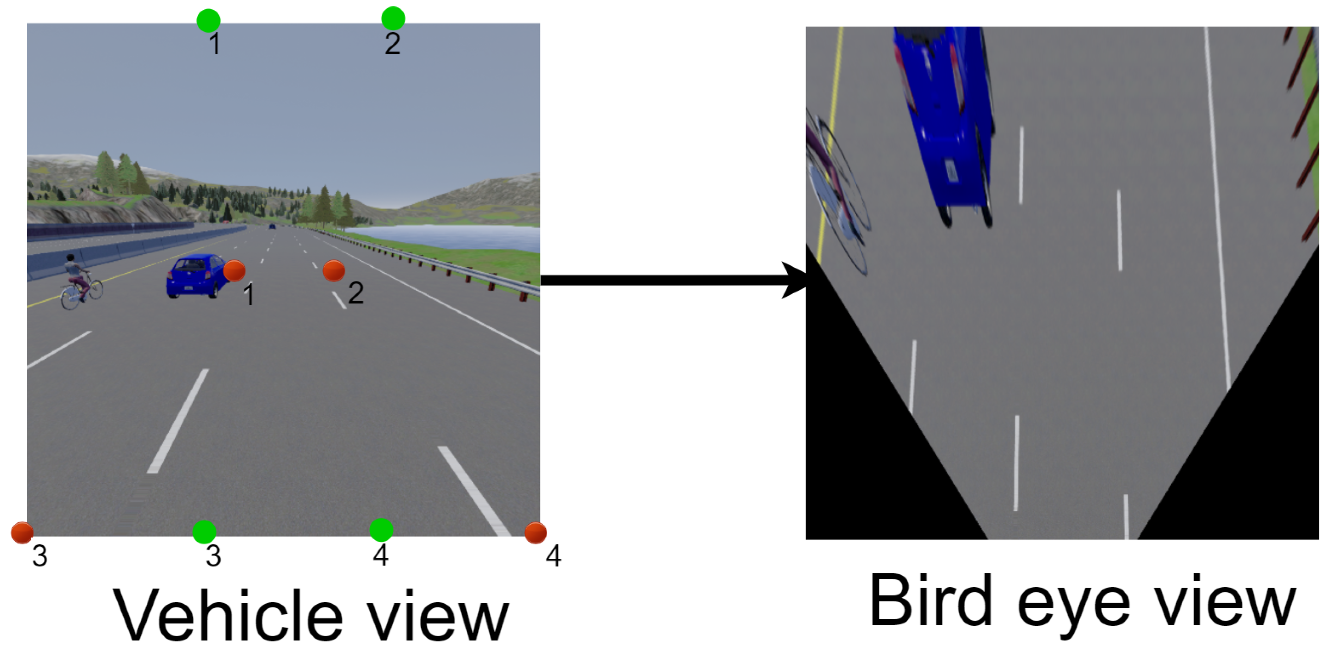
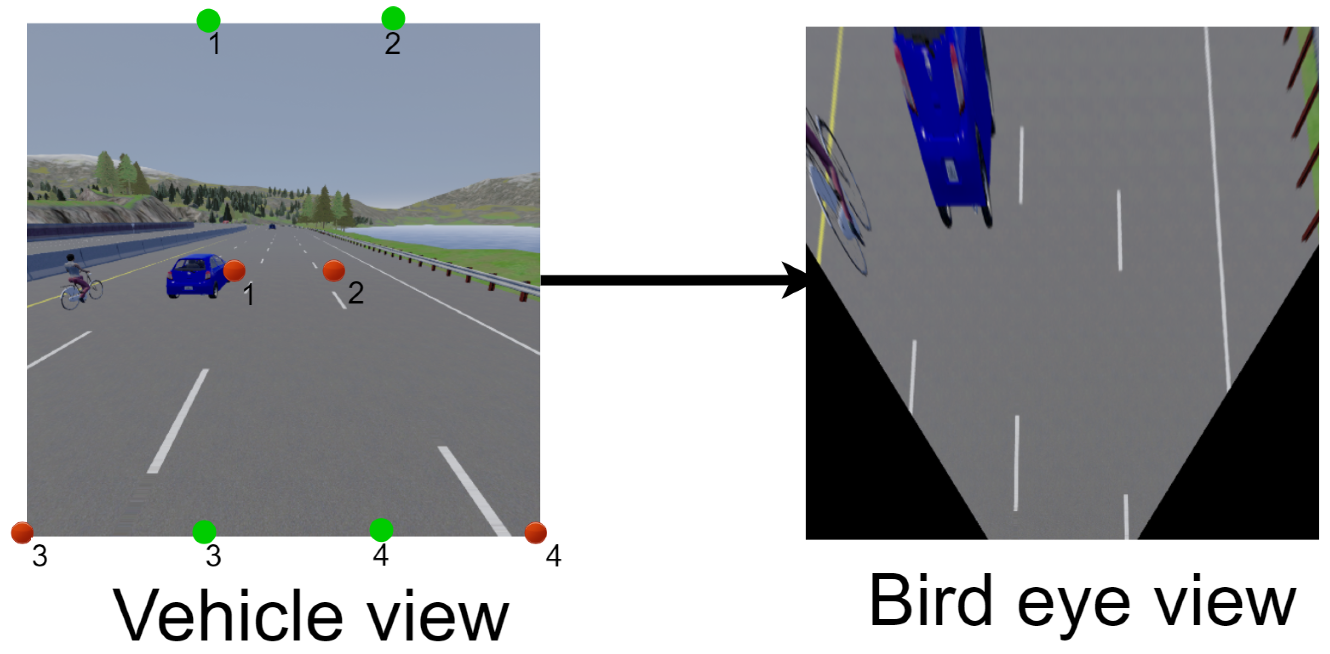
3.1.3. Bird’s Eye View (BEV)
3.2. Multitask Neural Network
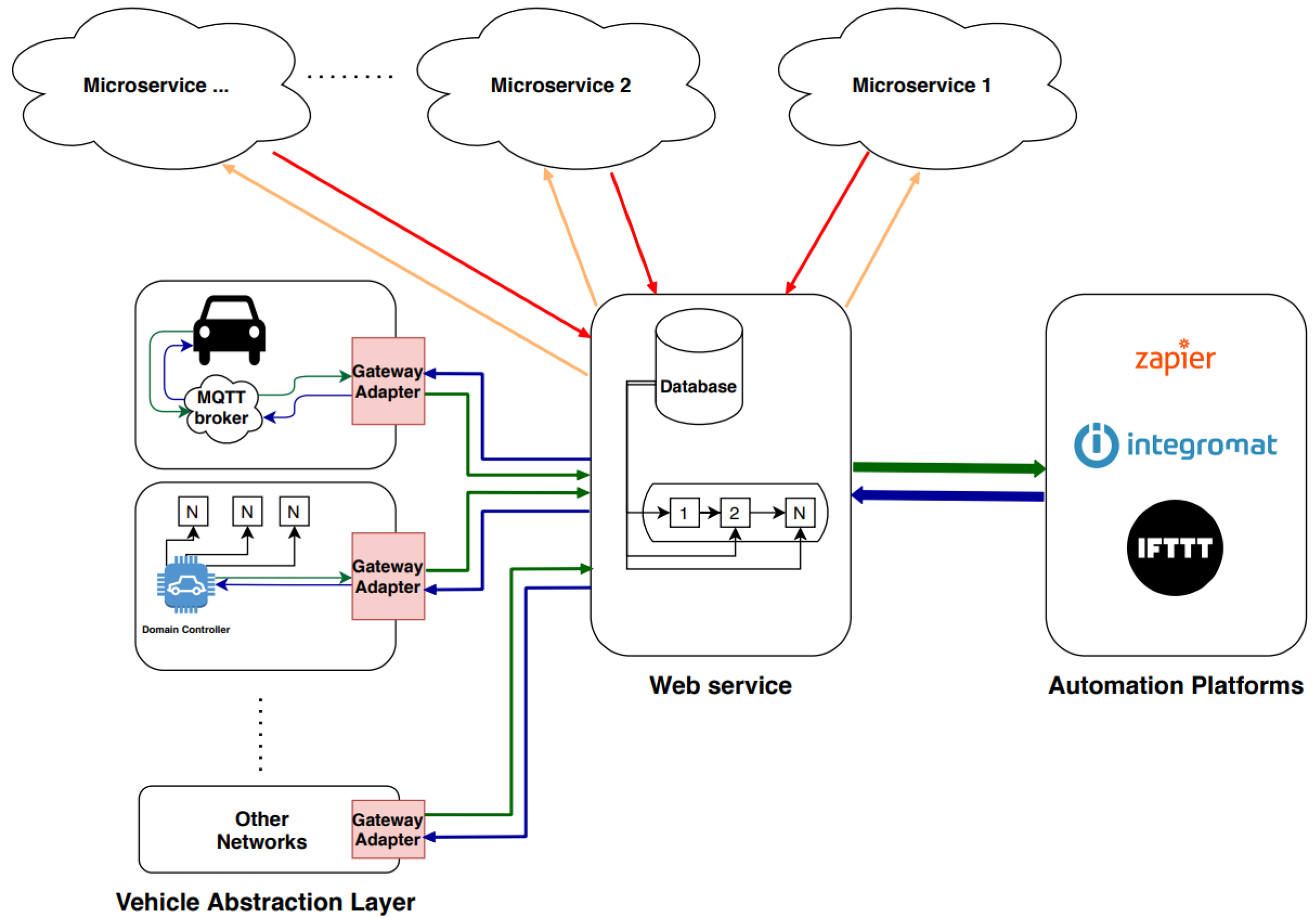
3.3. IoT Automation Platform
4. Dataset Setup
- Front crash when the ego-vehicle moves to right most, left most, and middle lanes;
- Left crash when the ego-vehicle moves the same and to a right lane;
- Right crash when the ego-vehicle moves the same and to a left lane;
- Front vehicle moves with lower speed to check lane overtaking;
- Two static front adjacent vehicles block the ego-vehicle;
- Two dynamic front adjacent vehicles move at the same velocity;
- Two dynamic front adjacent vehicles move at different velocities;
- Left vehicle moves beside the ego-vehicle at the same velocity;
- Ego-vehicle crashes with a front vehicle (achieved by using large number of time steps N in MPC), etc.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Data | Validation Data | Testing Data | |
|---|---|---|---|
| Crashes | 35 K | 6 K | 15 K |
| No Crashes | 45 K | 9 K | 15 K |
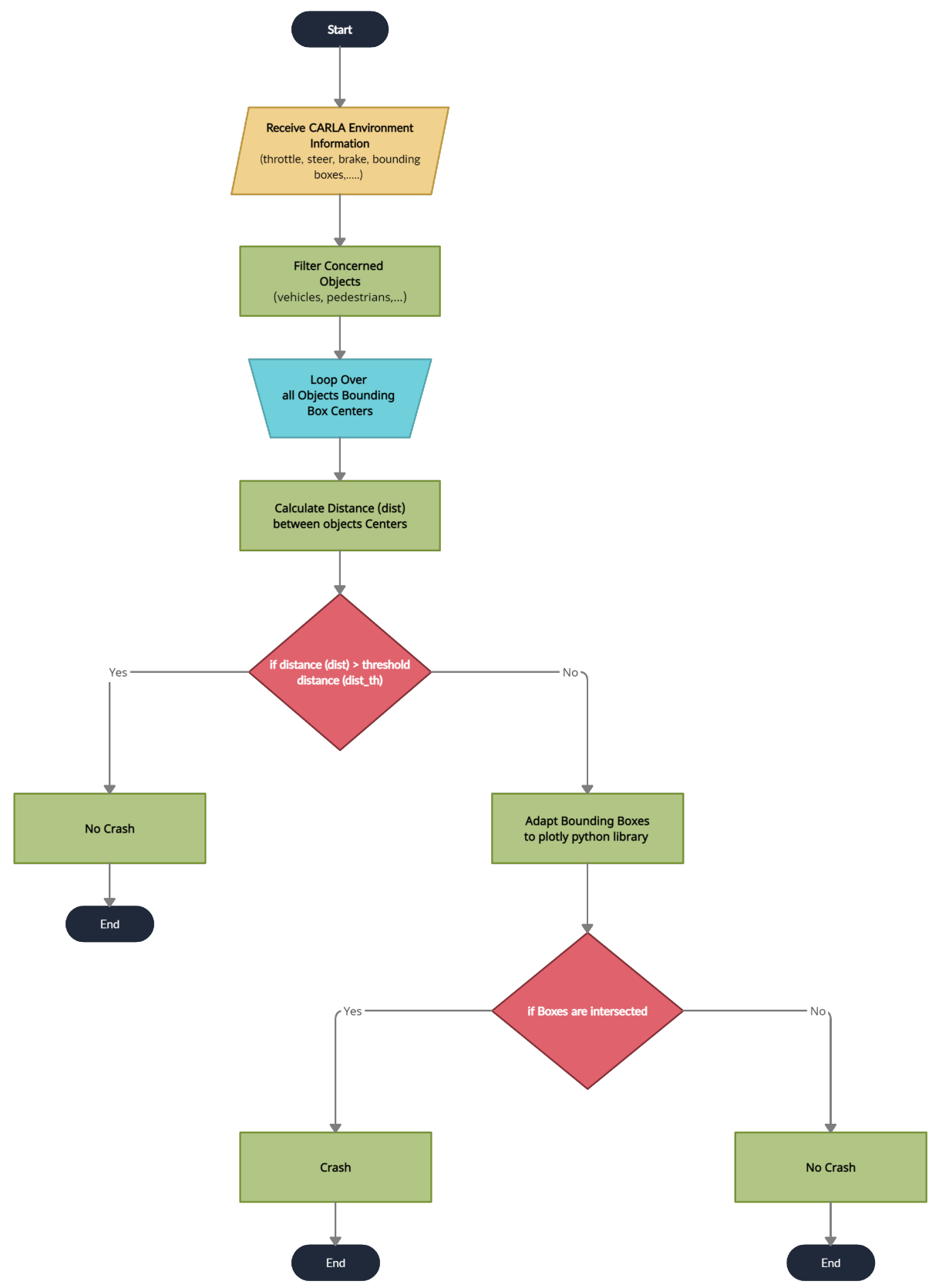
- Filter the objects by keeping only the concerned objects such as vehicles, pedestrians, etc.
- Loop over all the bounding boxes centers received from the CARLA simulator;
- Calculate the distances between bounding boxes centers;
- Check if the distances are greater than the threshold tunable distance. If yes, no crash label is applied; however, if no, this means that we have two or more vehicle centers in close proximity to each other;
- Adapt the bounding boxes information to the plotly [51] python library to check if there are two intersecting boxes;
- Check if the boxes are intersecting. If yes, apply the crash label. If no, apply the no crash label.
5. Results
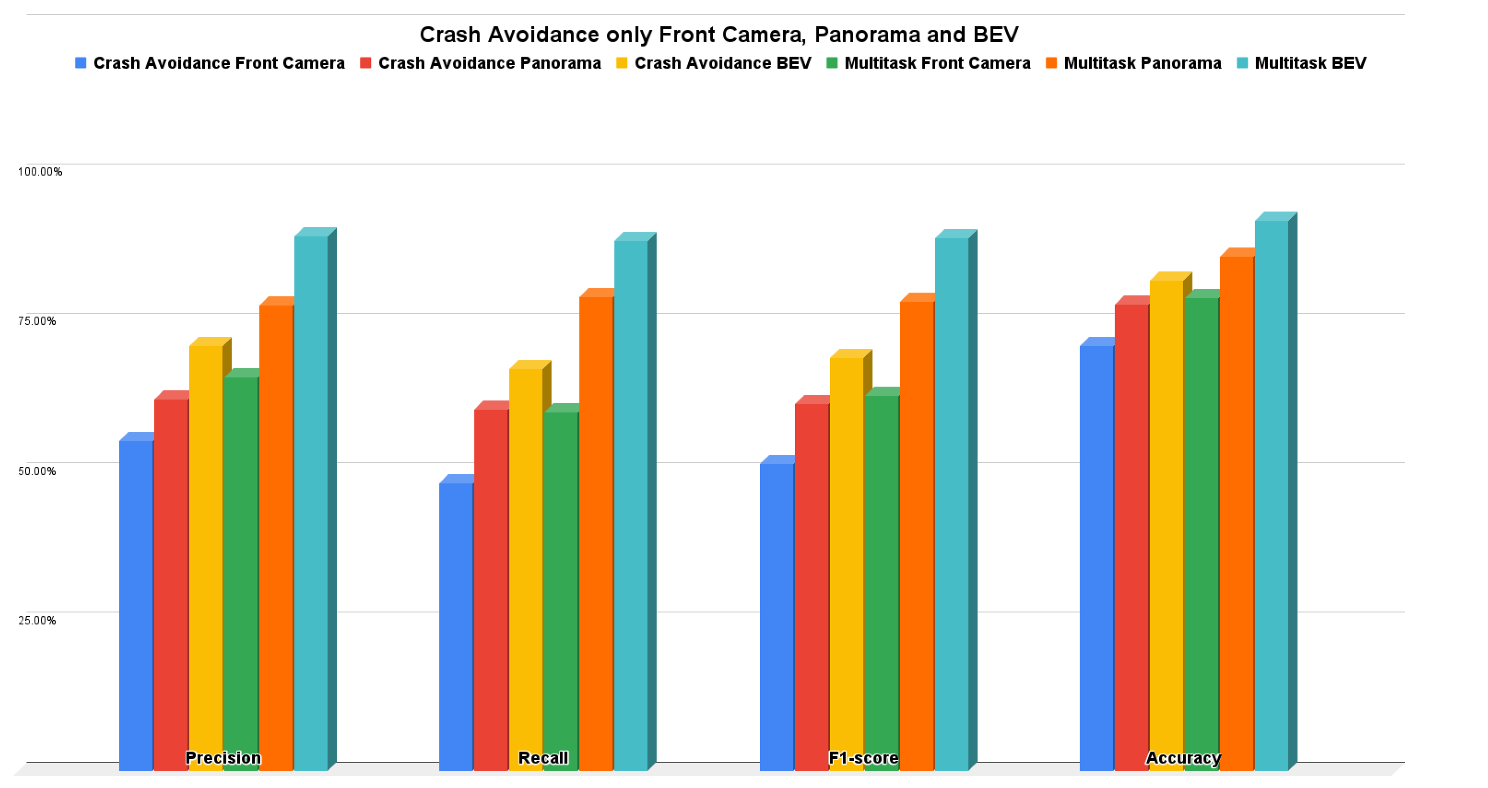
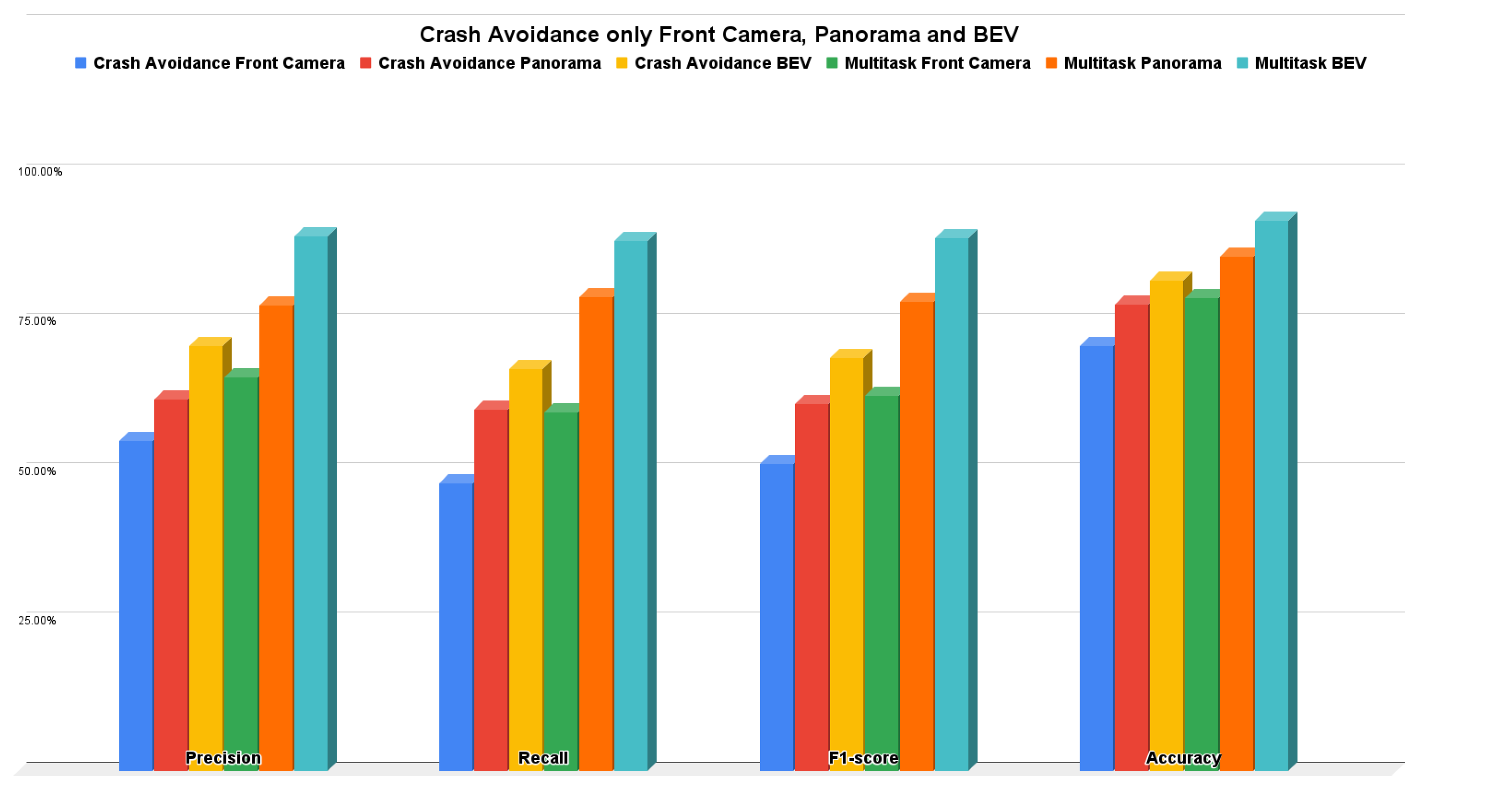
5.1. Crash Avoidance Only Results
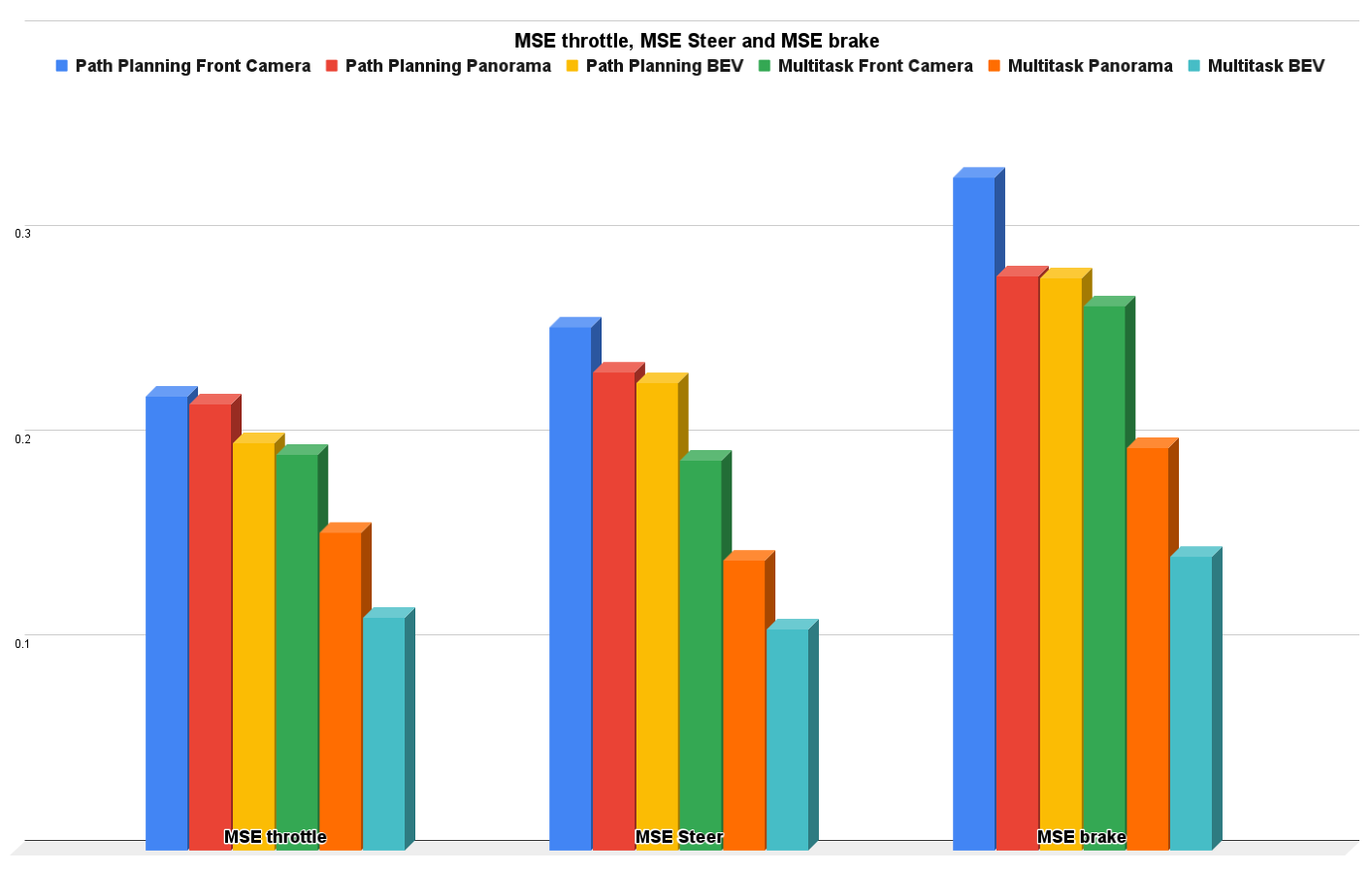
5.2. Path Planning and AEB Only Results
5.3. Crash Avoidance, Path Planning, and AEB Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Liu, B.; Qiao, J. Advanced High-Speed Lane Keeping System of Autonomous Vehicle with Sideslip Angle Estimation. Machines 2022, 10, 257. [Google Scholar] [CrossRef]
- Yu, J.; Liu, G.; Xu, J.; Zhao, Z.; Chen, Z.; Yang, M.; Wang, X.; Bai, Y. A Hybrid Multi-Target Path Planning Algorithm for Unmanned Cruise Ship in an Unknown Obstacle Environment. Sensors 2022, 22, 2429. [Google Scholar] [CrossRef] [PubMed]
- Kamal, M.A.S.; Hashikura, K.; Hayakawa, T.; Yamada, K.; Imura, J.I. Adaptive Cruise Control with Look-Ahead Anticipation for Driving on Freeways. Appl. Sci. 2022, 12, 929. [Google Scholar] [CrossRef]
- Guo, J.; Wang, Y.; Yin, X.; Liu, P.; Hou, Z.; Zhao, D. Study on the Control Algorithm of Automatic Emergency Braking System (AEBS) for Commercial Vehicle Based on Identification of Driving Condition. Machines 2022, 10, 895. [Google Scholar] [CrossRef]
- Ahmed, H.U.; Huang, Y.; Lu, P.; Bridgelall, R. Technology Developments and Impacts of Connected and Autonomous Vehicles: An Overview. Smart Cities 2022, 5, 382–404. [Google Scholar] [CrossRef]
- Xiao, Y. Application of Machine Learning in Ethical Design of Autonomous Driving Crash Algorithms. Comput. Intell. Neurosci. 2022, 2022, 2938011. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Zhang, L.; Yang, J.; Cao, C.; Wang, W.; Ran, Y.; Tan, Z.; Luo, M. A Review of Multi-Sensor Fusion SLAM Systems Based on 3D LIDAR. Remote Sens. 2022, 14, 2835. [Google Scholar] [CrossRef]
- Diaz-Ruiz, C.A.; Xia, Y.; You, Y.; Nino, J.; Chen, J.; Monica, J.; Chen, X.; Luo, K.; Wang, Y.; Emond, M.; et al. Ithaca365: Dataset and Driving Perception Under Repeated and Challenging Weather Conditions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 21383–21392. [Google Scholar]
- Hakak, S.; Gadekallu, T.R.; Ramu, S.P.; Maddikunta, P.K.R.; de Alwis, C.; Liyanage, M. Autonomous Vehicles in 5G and beyond: A Survey. arXiv 2022, arXiv:2207.10510. [Google Scholar]
- Wang, T.H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2vnet: Vehicle-to-vehicle communication for joint perception and prediction. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 605–621. [Google Scholar]
- Aoki, S.; Higuchi, T.; Altintas, O. Cooperative perception with deep reinforcement learning for connected vehicles. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 328–334. [Google Scholar]
- Chen, Q.; Tang, S.; Yang, Q.; Fu, S. Cooper: Cooperative perception for connected autonomous vehicles based on 3d point clouds. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 514–524. [Google Scholar]
- Ogbodo, E.U.; Abu-Mahfouz, A.M.; Kurien, A.M. A Survey on 5G and LPWAN-IoT for Improved Smart Cities and Remote Area Applications: From the Aspect of Architecture and Security. Sensors 2022, 22, 6313. [Google Scholar] [CrossRef]
- Riegler, A.; Riener, A.; Holzmann, C. Augmented reality for future mobility: Insights from a literature review and hci workshop. i-com 2021, 20, 295–318. [Google Scholar] [CrossRef]
- Decker, J.A.; Haus, S.H.; Sherony, R.; Gabler, H.C. Potential benefits of animal-detecting automatic emergency braking systems based on US driving data. Transp. Res. Rec. 2021, 2675, 678–688. [Google Scholar] [CrossRef]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. End-to-end deep reinforcement learning for lane keeping assist. arXiv 2016, arXiv:1612.04340. [Google Scholar]
- Yang, Z.; Wang, Z.; Yan, M. An optimization design of adaptive cruise control system based on MPC and ADRC. Actuators 2021, 10, 110. [Google Scholar] [CrossRef]
- Abdou, M.; Mohammed, R.; Hosny, Z.; Essam, M.; Zaki, M.; Hassan, M.; Eid, M.; Mostafa, H. End-to-end crash avoidance deep IoT-based solution. In Proceedings of the 2019 31st International Conference on Microelectronics (ICM), Cairo, Egypt, 15–18 December 2019; pp. 103–107. [Google Scholar]
- Yue, L.; Abdel-Aty, M.; Wu, Y.; Ugan, J.; Yuan, C. Effects of forward collision warning technology in different pre-crash scenarios. Transp. Res. Part F Traffic Psychol. Behav. 2021, 76, 336–352. [Google Scholar] [CrossRef]
- Sang, H.; You, Y.; Sun, X.; Zhou, Y.; Liu, F. The hybrid path planning algorithm based on improved A* and artificial potential field for unmanned surface vehicle formations. Ocean Eng. 2021, 223, 108709. [Google Scholar] [CrossRef]
- Shin, D. A cross-national study on the perception of algorithm news in the East and the West. J. Glob. Inf. Manag. 2021, 29, 77–101. [Google Scholar] [CrossRef]
- Lin, L.; Li, W.; Bi, H.; Qin, L. Vehicle Trajectory Prediction Using LSTMs with Spatial–Temporal Attention Mechanisms. IEEE Intell. Transp. Syst. Mag. 2021, 14, 197–208. [Google Scholar] [CrossRef]
- Wang, C.; Chen, X.; Wang, J.; Wang, H. ATPFL: Automatic Trajectory Prediction Model Design Under Federated Learning Framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 6563–6572. [Google Scholar]
- Quintanar, A.; Fernández-Llorca, D.; Parra, I.; Izquierdo, R.; Sotelo, M. Predicting vehicles trajectories in urban scenarios with transformer networks and augmented information. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1051–1056. [Google Scholar]
- Abdou, M.; Kamal, H.; El-Tantawy, S.; Abdelkhalek, A.; Adel, O.; Hamdy, K.; Abaas, M. End-to-end deep conditional imitation learning for autonomous driving. In Proceedings of the 2019 31st International Conference on Microelectronics (ICM), Cairo, Egypt, 15–18 December 2019; pp. 346–350. [Google Scholar]
- Guo, K.; Liu, W.; Pan, J. End-to-End Trajectory Distribution Prediction Based on Occupancy Grid Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 2242–2251. [Google Scholar]
- Li, Y.J.; Park, J.; O’Toole, M.; Kitani, K. Modality-Agnostic Learning for Radar-Lidar Fusion in Vehicle Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 918–927. [Google Scholar]
- Wang, Z.; Wu, Y.; Niu, Q. Multi-sensor fusion in automated driving: A survey. IEEE Access 2019, 8, 2847–2868. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 21361–21370. [Google Scholar]
- Xu, R.; Tu, Z.; Xiang, H.; Shao, W.; Zhou, B.; Ma, J. CoBEVT: Cooperative bird’s eye view semantic segmentation with sparse transformers. arXiv 2022, arXiv:2207.02202. [Google Scholar]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2583–2589. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, PMLR Mountain View, California, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Xu, R.; Guo, Y.; Han, X.; Xia, X.; Xiang, H.; Ma, J. OpenCDA: An open cooperative driving automation framework integrated with co-simulation. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 1155–1162. [Google Scholar]
- Li, Y.; Ren, S.; Wu, P.; Chen, S.; Feng, C.; Zhang, W. Learning distilled collaboration graph for multi-agent perception. Adv. Neural Inf. Process. Syst. 2021, 34, 29541–29552. [Google Scholar]
- Chen, D.; Mei, J.P.; Zhang, H.; Wang, C.; Feng, Y.; Chen, C. Knowledge Distillation with the Reused Teacher Classifier. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 11933–11942. [Google Scholar]
- Li, Y.; Ma, D.; An, Z.; Wang, Z.; Zhong, Y.; Chen, S.; Feng, C. V2X-Sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving. IEEE Robot. Autom. Lett. 2022, 7, 10914–10921. [Google Scholar] [CrossRef]
- Cui, J.; Qiu, H.; Chen, D.; Stone, P.; Zhu, Y. COOPERNAUT: End-to-End Driving with Cooperative Perception for Networked Vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17252–17262. [Google Scholar]
- Abdou, M.; Ezz, A.M.; Farag, I. Digital automation platforms comparative study. In Proceedings of the 2021 4th International Conference on Information and Computer Technologies (ICICT), Hawaii, GA, USA, 11–14 March 2021; pp. 279–286. [Google Scholar]
- Zapier. The Easiest Way to Automate Your Work. Available online: https://zapier.com/ (accessed on 10 November 2022).
- IFTTT. Helps Every Thing Work Better Together. Available online: https://ifttt.com/ (accessed on 10 November 2022).
- Integromat. The Glue of the Internet. Available online: https://www.make.com/en (accessed on 10 November 2022).
- Microsoft Power Automate. Microsoft Power Automate. Available online: https://powerautomate.microsoft.com/en-us/ (accessed on 10 November 2022).
- Parabola. Automate Your Manual, Repetitive Data Tasks. Available online: https://parabola.io/ (accessed on 10 November 2022).
- Ezz, A.M.; Nabil, A.; Ali, W.; Abdou, M.; Azer, M.; Farag, I.; Agamawi, M. Digital Gate: Automotive Gateway to Automation Platforms. In Proceedings of the 2021 4th International Conference on Information and Computer Technologies (ICICT), Hawaii, GA, USA, 11–14 March 2021; pp. 174–180. [Google Scholar] [CrossRef]
- Rahmati, A.; Fernandes, E.; Jung, J.; Prakash, A. IFTTT vs. Zapier: A comparative study of trigger-action programming frameworks. arXiv 2017, arXiv:1709.02788. [Google Scholar]
- Shamon, O.; Carlberg, L. iipax one as a Service in Cloud Integration Platforms: A Comparison of Zapier, IFTTT and Power Automate; Linköping University: Linköping, Sweden, 2020; Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:liu:diva-165631 (accessed on 10 November 2022).
- Naumann, M.; Poggenhans, F.; Lauer, M.; Stiller, C. Coincar-sim: An open-source simulation framework for cooperatively interacting automobiles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1–6. [Google Scholar]
- ElHakim, R.; Elqadi, A.; Torky, M.; Zayed, M.; Farag, I.; Agamawi, M. Let’s DO-Automotive Platform for Interoperability. In Proceedings of the 2021 4th International Conference on Information and Computer Technologies (ICICT), Hawaii, GA, USA, 11–14 March 2021; pp. 294–299. [Google Scholar]
- Afram, A.; Janabi-Sharifi, F. Theory and applications of HVAC control systems—A review of model predictive control (MPC). Build. Environ. 2014, 72, 343–355. [Google Scholar] [CrossRef]
- Plotly Technologies Inc. Collaborative Data Science; Plotly Technologies Inc.: Montreal, QB, Canada, 2015; Available online: https://plotly.com/python/ (accessed on 10 November 2022).







| Layer | Output Shape | Number of Parameters |
|---|---|---|
| Input Layer | (None, 120, 300, 3) | - |
| Conv1 | (None, 120, 300, 32) | 2432 |
| Conv2 | (None, 120, 300, 32) | 9248 |
| MaxPool1 | (None, 60, 150, 32) | - |
| Conv3 | (None, 60, 150, 64) | 18,496 |
| Conv4 | (None, 60, 150, 64) | 36,928 |
| MaxPool2 | (None, 30, 75, 64) | - |
| Conv5 | (None, 30, 75, 128) | 73,856 |
| Conv6 | (None, 30, 75, 128) | 147,584 |
| MaxPool3 | (None, 15, 38, 128) | - |
| Conv7 | (None, 15, 38, 256) | 295,168 |
| Conv8 | (None, 15, 38, 256) | 590,080 |
| MaxPool4 | (None, 8, 19, 256) | - |
| Flatten | (None, 38,912) | - |
| FC1-256 | (None, 256) | 9,961,728 |
| FC2-256 | (None, 256) | 65,792 |
| Input Speed | (None, 1) | - |
| FC1-128 | (None, 128) | 256 |
| FC2-128 | (None, 128) | 16,512 |
| Concat (FC2-256, FC2-128) | (None, 384) | - |
| FC3-256 | (None, 256) | 98,560 |
| FC4-256 | (None, 256) | 65,792 |
| Crash Head (FC1-10) | (None, 10) | 2570 |
| Crash Head (FC2-1) | (None, 1) | 11 |
| Softmax | (None, 1) | - |
| Control Head (FC1-10) | (None, 10) | 2570 |
| Control Head (FC2-3) | (None, 3) | 33 |
| Sigmoid | (None, 3) | - |
| 11,387,616 |
| Experiments | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Crash Avoidance Only | Path Planning and AEB Only | Crash Avoidance, Path Planning and AEB | |||||||||||||
| Input Representations | Precision | Recall | F1-Score | Accuracy | MSE throttle | MSE Steer | MSE brake | Precision | Recall | F1-Score | Accuracy | MSE throttle | MSE Steer | MSE brake | |
| Front Camera | 0.5513 | 0.4804 | 0.5134 | 0.71 | 0.2214 | 0.2552 | 0.3285 | 0.6589 | 0.6 | 0.628 | 0.79 | 0.1933 | 0.1902 | 0.2655 | |
| Panorama | 0.6218 | 0.604 | 0.6127 | 0.78 | 0.2176 | 0.2333 | 0.2805 | 0.7785 | 0.7915 | 0.7849 | 0.86 | 0.1552 | 0.1414 | 0.1966 | |
| Bird Eye View (BEV) | 0.7106 | 0.6715 | 0.6904 | 0.82 | 0.1988 | 0.2279 | 0.2794 | 0.8947 | 0.8858 | 0.8902 | 0.92 | 0.1135 | 0.1081 | 0.1433 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdou, M.; Kamal, H.A. SDC-Net: End-to-End Multitask Self-Driving Car Camera Cocoon IoT-Based System. Sensors 2022, 22, 9108. https://doi.org/10.3390/s22239108
Abdou M, Kamal HA. SDC-Net: End-to-End Multitask Self-Driving Car Camera Cocoon IoT-Based System. Sensors. 2022; 22(23):9108. https://doi.org/10.3390/s22239108
Chicago/Turabian StyleAbdou, Mohammed, and Hanan Ahmed Kamal. 2022. "SDC-Net: End-to-End Multitask Self-Driving Car Camera Cocoon IoT-Based System" Sensors 22, no. 23: 9108. https://doi.org/10.3390/s22239108
APA StyleAbdou, M., & Kamal, H. A. (2022). SDC-Net: End-to-End Multitask Self-Driving Car Camera Cocoon IoT-Based System. Sensors, 22(23), 9108. https://doi.org/10.3390/s22239108