
A Deep Learning Approach to Detect Anomalies in an Electric Power Steering System


Abstract
1. Introduction
- Most existing methods for detecting anomalies in EPS components are physics-based modeling. In this paper, we propose a deep learning (data-driven) approach.
- We propose a two-stage approach for detecting anomalous scenarios in sample EPS data. Training is conducted using normal data and anomaly detection based on the reconstruction error.
- We utilized a dataset obtained experimentally from a test jig of an EPS system and compared the performance analysis to other methods used to detect anomalies.
2. Related Works
2.1. Classical Machine Learning Anomaly Detection
2.2. Deep Learning-Based Anomaly Detection
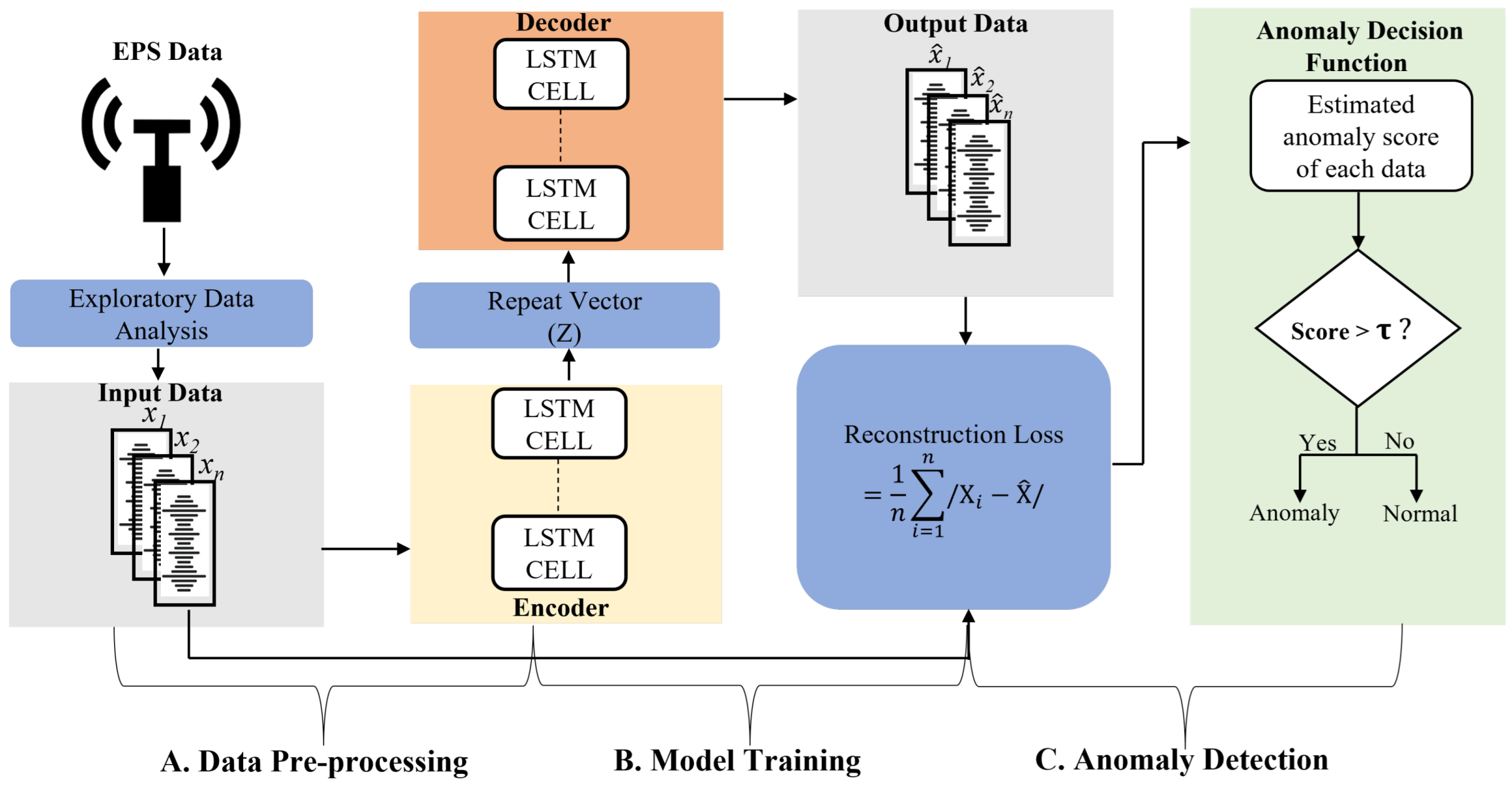
3. Workflow of EPS Anomaly Detection
3.1. Data Preprocessing
3.2. Model Training
3.2.1. (LSTM)
3.2.2. Autoencoder
3.3. Anomaly Detection
4. Experiment and Results
4.1. Data Collection
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Performance Results
4.4.1. Anomaly Detection
4.4.2. Performance Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiaoling, W.; Yan, Z.; Hong, W. Non-conduct steering sensor for Electric Power Steering. In Proceedings of the 2009 International Conference on Information and Automation, Macau, China, 22–24 June 2009; pp. 1462–1467. [Google Scholar] [CrossRef]
- LEARNING MODEL: Electric Power Steering. Exxotest Education, 2007; pp. 1–45. Available online: https://exxotest.com/en/ (accessed on 16 November 2022).
- Lin, W.C.; Ghoneim, Y.A. Model-based fault diagnosis and prognosis for Electric Power Steering systems. In Proceedings of the 2016 IEEE International Conference on Prognostics and Health Management (ICPHM), Ottawa, ON, Canada, 20–22 June 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Lee, J.; Lee, H.; Kim, J.; Jeong, J. Model-based fault detection and isolation for electric power steering system. In Proceedings of the 2007 International Conference on Control, Automation and Systems, Seoul, Republic of Korea, 17–20 October 2007; pp. 2369–2374. [Google Scholar] [CrossRef]
- Choi, K.; Yi, J.; Park, C.; Yoon, S. Deep Learning for Anomaly Detection in Time-Series Data: Review, Analysis, and Guidelines. IEEE Access 2021, 9, 120043–120065. [Google Scholar] [CrossRef]
- Cook, A.A.; Mısırlı, G.; Fan, Z. Anomaly Detection for IoT Time-Series Data: A Survey. IEEE Internet Things J. 2020, 7, 6481–6494. [Google Scholar] [CrossRef]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar] [CrossRef]
- Hu, H.; Luo, H.; Deng, X. Health Monitoring of Automotive Suspensions: A LSTM Network Approach. Hindawi 2021, 2021, 6626024. [Google Scholar] [CrossRef]
- Na, S.; Li, Z.; Qiu, F.; Zhang, C. Torque Control of Electric Power Steering Systems Based on Improved Active Disturbance Rejection Control. Hindawi 2020, 2020, 6509607. [Google Scholar]
- Syafrudin, M.; Alfian, G.; Fitriyani, N.L.; Rhee, J. Performance Analysis of IoT-Based Sensor, Big Data Processing, and Machine Learning Model for Real-Time Monitoring System in Automotive Manufacturing. Sensors 2018, 18, 2946. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, R.J.; Chou, J.; Ho, C.H. Unsupervised Online Anomaly Detection on Multivariate Sensing Time Series Data for Smart Manufacturing. In Proceedings of the 2019 IEEE 12th Conference on Service-Oriented Computing and Applications (SOCA), Kaohsiung, Taiwan, 18–21 November 2019; pp. 90–97. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep Learning for Anomaly Detection: A Survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Yu, Y. A Survey of Anomaly Intrusion Detection Techniques. J. Comput. Sci. Coll. 2012, 28, 9–17. [Google Scholar]
- Lee, J.; Noh, S.D.; Kim, H.J.; Kang, Y.S. Implementation of Cyber-Physical Production Systems for Quality Prediction and Operation Control in Metal Casting. Sensors 2018, 18, 1428. [Google Scholar] [CrossRef]
- Salman, T.; Bhamare, D.; Erbad, A.; Jain, R.; Samaka, M. Machine Learning for Anomaly Detection and Categorization in Multi-Cloud Environments. In Proceedings of the 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, 26–28 June 2017; pp. 97–103. [Google Scholar] [CrossRef]
- Park, D.; Kim, H.; Hoshi, Y.; Erickson, Z.; Kapusta, A.; Kemp, C.C. A multimodal execution monitor with anomaly classification for robot-assisted feeding. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5406–5413. [Google Scholar] [CrossRef]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Editorial: Special Issue on Learning from Imbalanced Data Sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Saeedi Emadi, H.; Mazinani, S.M. A Novel Anomaly Detection Algorithm Using DBSCAN and SVM in Wireless Sensor Networks. Wirel. Pers. Commun. 2018, 98, 2025–2035. [Google Scholar] [CrossRef]
- Mishra, S.; Chawla, M. A Comparative Study of Local Outlier Factor Algorithms for Outliers Detection in Data Streams. In Proceedings of the IEMIS 2018, West Bengal, Kolkata, 23–25 February 2019; Volume 2, pp. 347–356. [Google Scholar] [CrossRef]
- Liu, Z.; Qin, T.; Guan, X.; Jiang, H.; Wang, C. An Integrated Method for Anomaly Detection From Massive System Logs. IEEE Access 2018, 6, 30602–30611. [Google Scholar] [CrossRef]
- Münz, G.; Li, S.; Carle, G. Traffic Anomaly Detection Using KMeans Clustering. In Proceedings of the In GI/ITG Workshop MMBnet, Hamburg, Germany, 13 September 2007. [Google Scholar]
- MacQueen, J. Classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1967; pp. 281–297. [Google Scholar]
- Jolliffe, I.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Kudo, T.; Morita, T.; Matsuda, T.; Takine, T. PCA-based robust anomaly detection using periodic traffic behavior. In Proceedings of the 2013 IEEE International Conference on Communications Workshops (ICC), Budapest, Hungary, 9–13 June 2013; pp. 1330–1334. [Google Scholar] [CrossRef]
- Ben Amor, L.; Lahyani, I.; Jmaiel, M. PCA-based multivariate anomaly detection in mobile healthcare applications. In Proceedings of the 2017 IEEE/ACM 21st International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Rome, Italy, 18–20 October 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, C.; Shen, W. A Deep Learning Approach for Heating and Cooling Equipment Monitoring. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 228–234. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, J.; Yan, R.; Mao, K. Machine health monitoring with LSTM networks. In Proceedings of the 2016 10th International Conference on Sensing Technology (ICST), Nanjing, China, 11–13 November 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Web traffic anomaly detection using C-LSTM neural networks. Expert Syst. Appl. 2018, 106, 66–76. [Google Scholar] [CrossRef]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the 2018 International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection. arXiv 2016, arXiv:1607.00148v2. [Google Scholar] [CrossRef]
- Son, H.; Jang, Y.; Kim, S.E.; Kim, D.; Park, J.W. Deep Learning-Based Anomaly Detection to Classify Inaccurate Data and Damaged Condition of a Cable-Stayed Bridge. IEEE Access 2021, 9, 124549–124559. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Muhammad Ali, P.; Faraj, R. Data Normalization and Standardization: A Technical Report. Mach. Learn. Tech. Rep. 2014, 1, 1–6. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef]
- Landi, F.; Baraldi, L.; Cornia, M.; Cucchiara, R. Working Memory Connections for LSTM. Neural Netw. 2021, 144, 334–341. [Google Scholar] [CrossRef] [PubMed]
- Siegel, B. Industrial Anomaly Detection: A Comparison of Unsupervised Neural Network Architectures. IEEE Sens. Lett. 2020, 4, 7501104. [Google Scholar] [CrossRef]
- Liu, P.; Sun, X.; Han, Y.; He, Z.; Zhang, W.; Wu, C. Arrhythmia classification of LSTM autoencoder based on time series anomaly detection. Biomed. Signal Process. Control. 2022, 71, 103228. [Google Scholar] [CrossRef]
- Kang, J.; Kim, C.S.; Kang, J.W.; Gwak, J. Anomaly Detection of the Brake Operating Unit on Metro Vehicles Using a One-Class LSTM Autoencoder. Appl. Sci. 2021, 11, 9290. [Google Scholar] [CrossRef]
- Han, P.; Ellefsen, A.L.; Li, G.; Holmeset, F.T.; Zhang, H. Fault Detection With LSTM-Based Variational Autoencoder for Maritime Components. IEEE Sens. J. 2021, 21, 21903–21912. [Google Scholar] [CrossRef]
- Liebert, A.; Weber, W.; Reif, S.; Zimmering, B.; Niggemann, O. Anomaly Detection with Autoencoders as a Tool for Detecting Sensor Malfunctions. In Proceedings of the 2022 IEEE 5th International Conference on Industrial Cyber-Physical Systems (ICPS), Coventry, UK, 16–19 May 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, L.W.; Du, R.; Cheng, Y. The Analysis of The Fault of Electrical Power Steering. MATEC Web Conf. 2016, 44, 02003. [Google Scholar] [CrossRef]
- Ibrahim, M.; Alsheikh, A.; Awaysheh, F.M.; Alshehri, M.D. Machine Learning Schemes for Anomaly Detection in Solar Power Plants. Energies 2022, 15, 1082. [Google Scholar] [CrossRef]
- Lee, S.; Jin, H.; Nengroo, S.H.; Doh, Y.; Lee, C.; Heo, T.; Har, D. Smart Metering System Capable of Anomaly Detection by Bi-directional LSTM Autoencoder. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–9 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; Wang, Q.; Yang, R.; Xin, B. Unsupervised Anomaly Detection for Container Cloud Via BILSTM-Based Variational Auto-Encoder. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3024–3028. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Model Framework | PyTorch 1.12.1 |
| Layers | 2 |
| Learning Rate | 0.0009 |
| Optimizer | Adam |
| Loss Function | MAE |
| Number of Epoch | 50 |
| Model | TP | FP | FN | TN | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|
| BiLSTM-AE | 423 | 0 | 78 | 12,632 | 0.9940 | 0.9999 | 0.8443 | 0.9155 |
| GRU-AE | 446 | 0 | 55 | 12,632 | 0.9958 | 0.9999 | 0.8902 | 0.9419 |
| LSTM-AE | 492 | 0 | 9 | 12,632 | 0.9993 | 0.9999 | 0.9820 | 0.9809 |
| Model | Source | Datasets | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| C-LSTM | [28] | Webscope S5 | 98.6 | 96.2 | 89.7 | 92.3 |
| LSTM-AE | [31] | IPC-SHM2020 | 0.9998 | 0.9568 | 0.9201 | 0.9381 |
| LSTM-AE | [38] | ECG | 98.57 | 97.74 | 98.85 | - |
| LSTM-AE | [39] | BOU | 0.9444 | 0.9794 | 0.8577 | 0.9145 |
| LSTM-AE | [43] | Solar plant generation | 0.8963 | 0.9474 | 0.9432 | 0.9453 |
| BILSTM-AE | [44] | Smart meter | 0.9957 | 0.9958 | 0.9999 | 0.9978 |
| BILSTM-VAE | [45] | UNM | 90.01 | 84.59 | 97.87 | 90.75 |
| LSTM-AE | Ours | EPS | 0.9993 | 0.9999 | 0.9820 | 0.9809 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alabe, L.W.; Kea, K.; Han, Y.; Min, Y.J.; Kim, T. A Deep Learning Approach to Detect Anomalies in an Electric Power Steering System. Sensors 2022, 22, 8981. https://doi.org/10.3390/s22228981
Alabe LW, Kea K, Han Y, Min YJ, Kim T. A Deep Learning Approach to Detect Anomalies in an Electric Power Steering System. Sensors. 2022; 22(22):8981. https://doi.org/10.3390/s22228981
Chicago/Turabian StyleAlabe, Lawal Wale, Kimleang Kea, Youngsun Han, Young Jae Min, and Taekyung Kim. 2022. "A Deep Learning Approach to Detect Anomalies in an Electric Power Steering System" Sensors 22, no. 22: 8981. https://doi.org/10.3390/s22228981
APA StyleAlabe, L. W., Kea, K., Han, Y., Min, Y. J., & Kim, T. (2022). A Deep Learning Approach to Detect Anomalies in an Electric Power Steering System. Sensors, 22(22), 8981. https://doi.org/10.3390/s22228981