
IPD-Net: Infrared Pedestrian Detection Network via Adaptive Feature Extraction and Coordinate Information Fusion
 , , ,
, , ,
Abstract
:1. Introduction
- In the backbone, an adaptive feature extraction module (AFEM) is designed to extract pedestrian features. By introducing an improved selective kernel attention module into the residual structure, the AFEM obtains a multi-scale receptive field to better distinguish the object from the background and obtains better pedestrian feature information extraction capability.
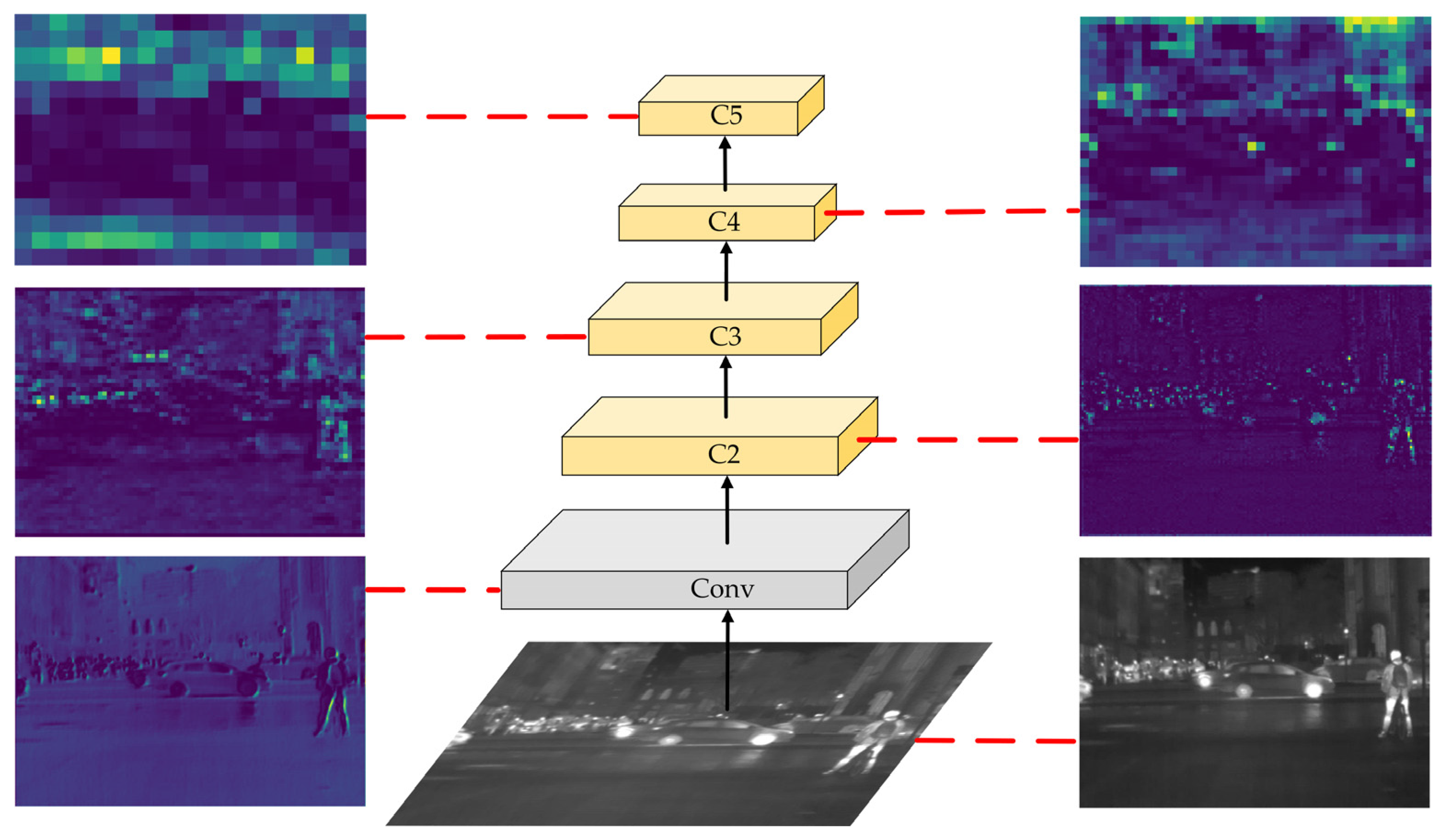
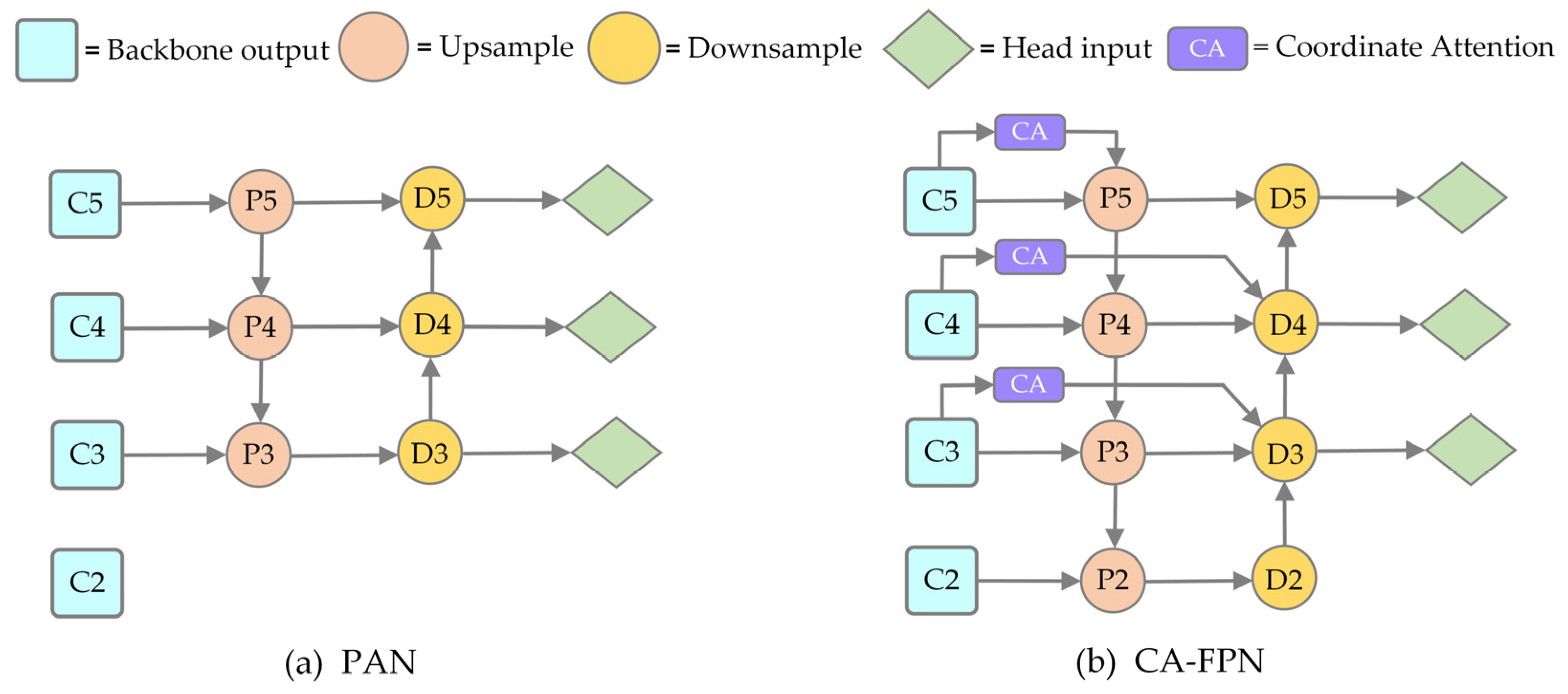
- In the neck, this paper designs a coordinate attention feature pyramid network (CA-FPN). Firstly, aiming at small and weak objects present in the infrared images, we introduced the feature maps of the C2 layer into the feature fusion network, making full use of the small and weak object information contained in the feature maps of the C2 layer. In addition, a coordinate attention module is introduced to encode the feature map position information in layers C3, C4, and C5 to enhance the position information of the objects in the feature map. The fusion by concatenating results in a better balance of positional and semantic information contained in each layer of the feature map, improves the feature representation capability of the network.
- In the head, we propose a new bounding box loss function α-EIoU, which improves the bounding box regression capability of the model, speeds up the convergence of the model, and obtains a better object localization capability.
- This paper analyses the problems of pedestrian objects in infrared images, including the lack of feature information and the small scale of pedestrian objects, and proposes an improved infrared pedestrian detection model, IPD-Net, based on YOLOv5s. Through validation on the Zachodniopomorski Uniwersytet Technologiczny (ZUT) dataset [16], IPD-Net achieves higher detection accuracy compared with some current mainstream detection networks.
2. Related Work
3. Proposed Method
3.1. Backbone
3.2. Neck
3.2.1. Shortcomings of the PAN in YOLOv5s
3.2.2. Enhanced Fusion of Shallow Feature Maps
3.2.3. Feature Fusion with Coordinate Attention Model
3.3. Head
4. The Experiment and Result Analysis
4.1. Experimental Environment and Settings
4.2. Dataset
4.3. Ablation Experiment
4.4. Experiments with Different Input Scales
4.5. Comparative Experiments with Different Algorithms
4.5.1. Comparison with YOLO Series Algorithms
4.5.2. Comparison with Other Object Detection Algorithms
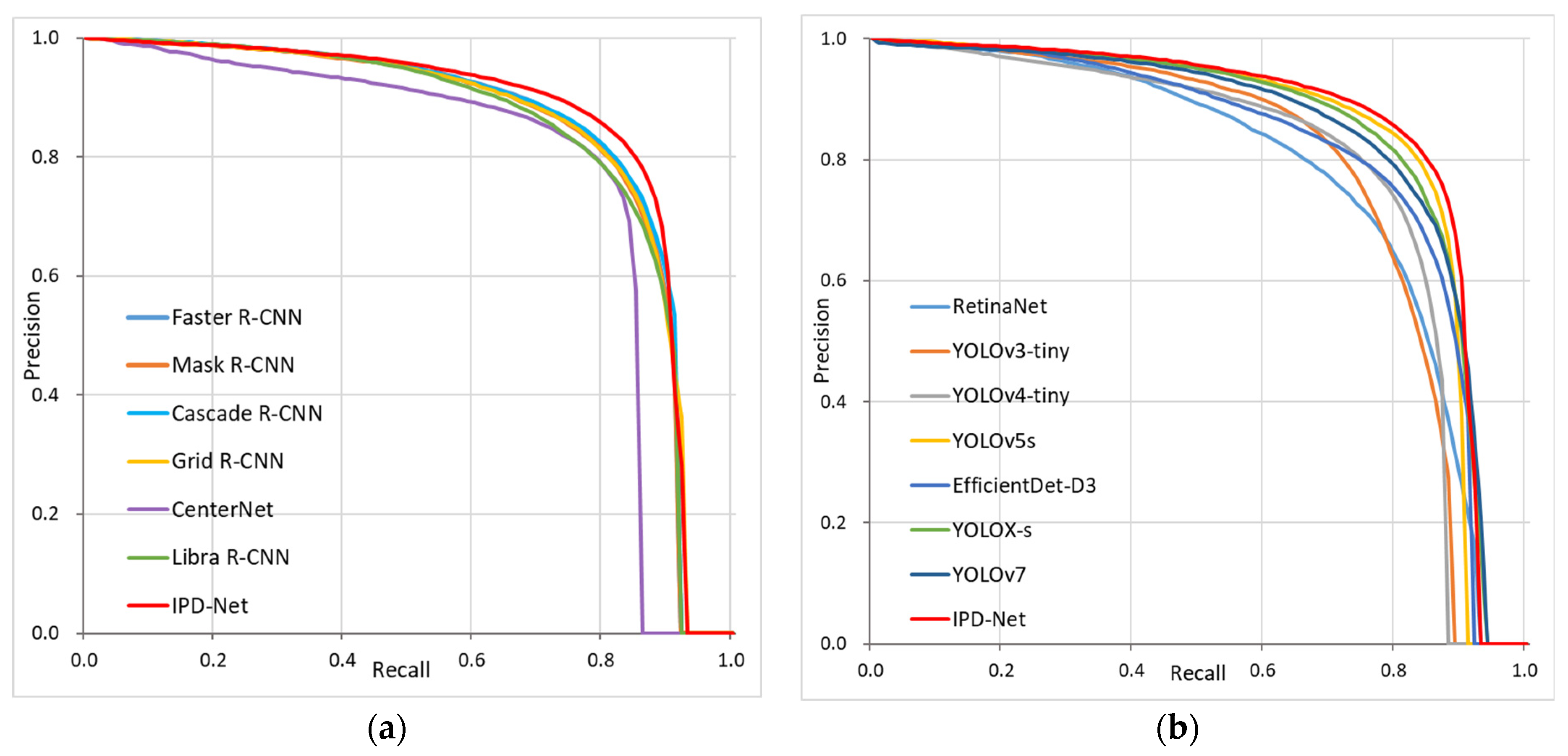
4.5.3. Visualization of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Q.; Zhuang, J.; Ma, J. Robust and fast pedestrian detection method for far-infrared automotive driving assistance systems. Infrared Phys. Technol. 2013, 60, 288–299. [Google Scholar] [CrossRef]
- Bertozzi, M.; Broggi, A.; Fascioli, A.; Graf, T.; Meinecke, M.M. Pedestrian detection for driver assistance using multiresolution infrared vision. IEEE Trans. Veh. Technol. 2004, 53, 1666–1678. [Google Scholar] [CrossRef]
- Garcia, F.; Martin, D.; De La Escalera, A.; Armingol, J.M. Sensor fusion methodology for vehicle detection. IEEE Intell. Transp. Syst. Mag. 2017, 9, 123–133. [Google Scholar] [CrossRef]
- El Maadi, A.; Maldague, X. Outdoor infrared video surveillance: A novel dynamic technique for the subtraction of a changing background of IR images. Infrared Phys. Technol. 2007, 49, 261–265. [Google Scholar] [CrossRef]
- Zhang, H.; Luo, C.; Wang, Q.; Kitchin, M.; Parmley, A.; Monge-Alvarez, J.; Casaseca-De-La-Higuera, P. A novel infrared video surveillance system using deep learning based techniques. Multimed. Tools Appl. 2018, 77, 26657–26676. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Liu, Q. Far-infrared based pedestrian detection for driverassistance systems based on candidate filters, gradient-based feature and multi-frame approval matching. Sensors 2015, 15, 32188–32212. [Google Scholar] [CrossRef] [Green Version]
- Hurney, P.; Waldron, P.; Morgan, F.; Jones, E.; Glavin, M. Review of pedestrian detection techniques in automotive far-infrared video. IET Intell. Transp. Syst. 2015, 9, 824–832. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Li, J.; Gong, W.; Li, W.; Liu, X. Robust pedestrian detection in thermal infrared imagery using the wavelet transform. Infrared Phys. Technol. 2010, 53, 267–273. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 10 November 2022).
- Tumas, P.; Nowosielski, A.; Serackis, A. Pedestrian detection in severe weather conditions. IEEE Access 2020, 8, 62775–62784. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhang, S.; Bauckhage, C.; Cremers, A.B. Informed haar-like features improve pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 947–954. [Google Scholar]
- Brehar, R.; Nedevschi, S. Pedestrian detection in infrared images using HOG, LBP, gradient magnitude and intensity feature channels. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 1669–1674. [Google Scholar]
- Heikkilä, M.; Pietikäinen, M.; Schmid, C. Description of interest regions with local binary patterns. Pattern Recognit. 2009, 42, 425–436. [Google Scholar] [CrossRef]
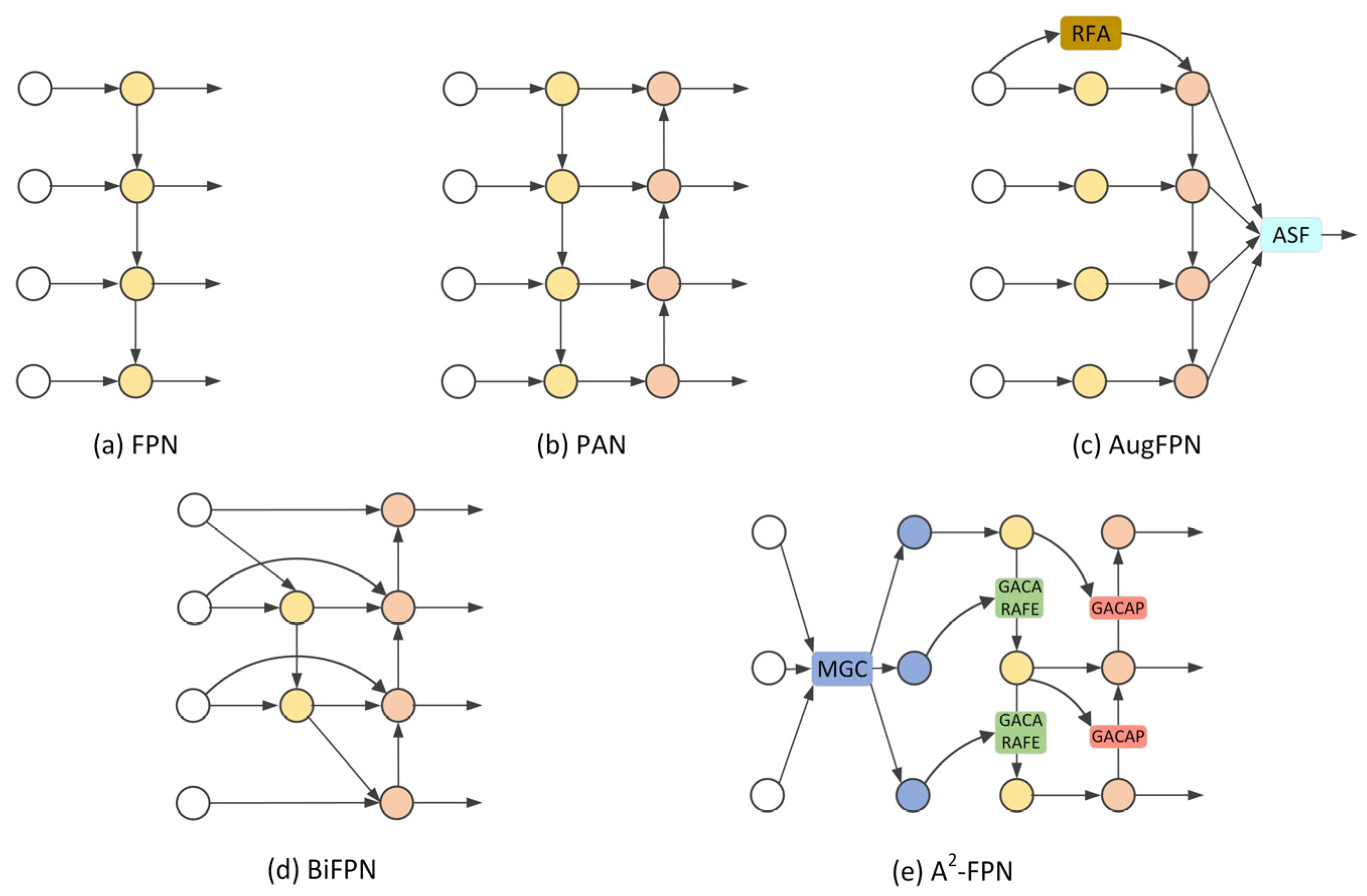
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-Scale Feature Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12595–12604. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention Aggregation Based Feature Pyramid Network for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15343–15352. [Google Scholar]
- Qu, H.; Zhang, L.; Wu, X.; He, X.; Hu, X.; Wen, X. Multiscale object detection in infrared streetscape images based on deep learning and instance level data augmentation. Appl. Sci. 2019, 9, 565. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Li, M.; Tao, Z.; Cui, W. Research of infrared small pedestrian target detection based on YOLOv3. Infrared Technol. 2020, 42, 176–181. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, D.; Lan, J. Ppdet: A novel infrared pedestrian detection network in a per-pixel prediction fashion. Infrared Phys. Technol. 2021, 119, 103965. [Google Scholar] [CrossRef]
- Yu, L.; Wang, Y.; Sun, X.; Han, S. Thermal imaging pedestrian detection algorithm based on attention guidance and local cross-level network. J. Electron. Imaging 2021, 30, 053012. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Supplementary material for ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13–19. [Google Scholar]
- Dai, X.; Yuan, X.; Wei, X. Tirnet: Object detection in thermal infrared images for autonomous driving. Appl. Intell. 2021, 51, 1244–1261. [Google Scholar] [CrossRef]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. YOLO-FIRI: Improved YOLOv5 for Infrared Image Object Detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6154–6162. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7363–7372. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline | AFEM | CA-FPN | α-EIoU | mAP50/% | mAP(50:95)/% |
|---|---|---|---|---|---|
| √ | 75.7 | 30.3 | |||
| √ | √ | 76.2 | 30.5 | ||
| √ | √ | 77.9 | 31.6 | ||
| √ | √ | 76.7 | 30.7 | ||
| √ | √ | √ | 78 | 31.5 | |
| √ | √ | √ | 77.7 | 31.2 | |
| √ | √ | √ | 78.9 | 31.9 | |
| √ | √ | √ | √ | 79.3 | 32.1 |
| Image Size | Method | mAP50/% | mAP(50:95)/% |
|---|---|---|---|
| 320 × 320 | YOLOv5s | 75.7 | 30.3 |
| IPD-Net | 79.3 | 32.1 | |
| 480 × 480 | YOLOv5s | 82.1 | 33.9 |
| IPD-Net | 84.3 | 35.2 | |
| 640 × 640 | YOLOv5s | 84.4 | 35.5 |
| IPD-Net | 86.5 | 36.6 |
| Method | Image Size | mAP50/% | mAP(50:95)/% |
|---|---|---|---|
| YOLOv3-tiny | 320 | 64.3 | 24.3 |
| YOLOv4-tiny | 320 | 70.4 | 25.4 |
| YOLOv5s | 320 | 75.7 | 30.3 |
| YOLOX-s | 320 | 78.4 | 31.3 |
| YOLOv7 | 320 | 72.4 | 28.1 |
| IPD-Net | 320 | 79.3 | 32.1 |
| Category | Method | Image Size | mAP50/% | mAP(50:95)/% |
|---|---|---|---|---|
| Two-stage | Faster R-CNN | 640 | 83.7 | 34.7 |
| Mask R-CNN [43] | 640 | 83.4 | 34.8 | |
| Cascade R-CNN [44] | 640 | 84 | 36.3 | |
| Grid R-CNN [45] | 640 | 83.8 | 36.2 | |
| CenterNet [46] | 640 | 77.5 | 30.3 | |
| Libra R-CNN [47] | 640 | 82.9 | 34.8 | |
| One-stage | RetinaNet | 640 | 77.2 | 31.3 |
| YOLOv3-tiny | 640 | 78.8 | 32.1 | |
| YOLOv4-tiny | 640 | 79.1 | 32.6 | |
| YOLOv5s | 640 | 84.4 | 35.5 | |
| EfficientDet-D3 | 640 | 81.4 | 33.5 | |
| YOLOX-s | 640 | 82.7 | 34 | |
| YOLOv7 | 640 | 84 | 34.4 | |
| IPD-Net | 640 | 86.5 | 36.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Gao, S.; Wang, S.; Zhang, H.; Liu, R.; Liu, J. IPD-Net: Infrared Pedestrian Detection Network via Adaptive Feature Extraction and Coordinate Information Fusion. Sensors 2022, 22, 8966. https://doi.org/10.3390/s22228966
Zhou L, Gao S, Wang S, Zhang H, Liu R, Liu J. IPD-Net: Infrared Pedestrian Detection Network via Adaptive Feature Extraction and Coordinate Information Fusion. Sensors. 2022; 22(22):8966. https://doi.org/10.3390/s22228966
Chicago/Turabian StyleZhou, Lun, Song Gao, Simin Wang, Hengsheng Zhang, Ruochen Liu, and Jiaming Liu. 2022. "IPD-Net: Infrared Pedestrian Detection Network via Adaptive Feature Extraction and Coordinate Information Fusion" Sensors 22, no. 22: 8966. https://doi.org/10.3390/s22228966
APA StyleZhou, L., Gao, S., Wang, S., Zhang, H., Liu, R., & Liu, J. (2022). IPD-Net: Infrared Pedestrian Detection Network via Adaptive Feature Extraction and Coordinate Information Fusion. Sensors, 22(22), 8966. https://doi.org/10.3390/s22228966