
Φ-OTDR Signal Identification Method Based on Multimodal Fusion



Abstract
:1. Introduction
2. Distributed Fiber Technology Based on -OTDR
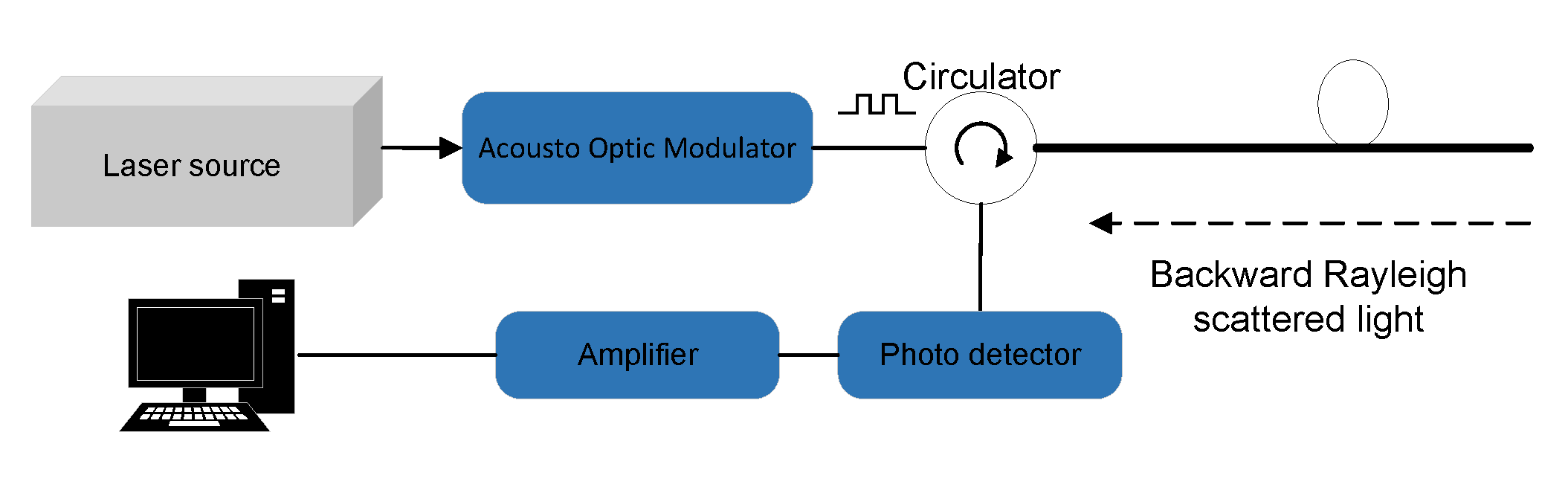
2.1. System Structure and Principle
2.2. Data Collection
3. Method Construction
3.1. Preprocessing
- Framing of the signal using the Hamming window function;
- Fourier transform is calculated for each frame of data, and the results are stacked to generate a spectrogram;
- The spectrum is Gouraud processed and then downsampled to produce the final input image.
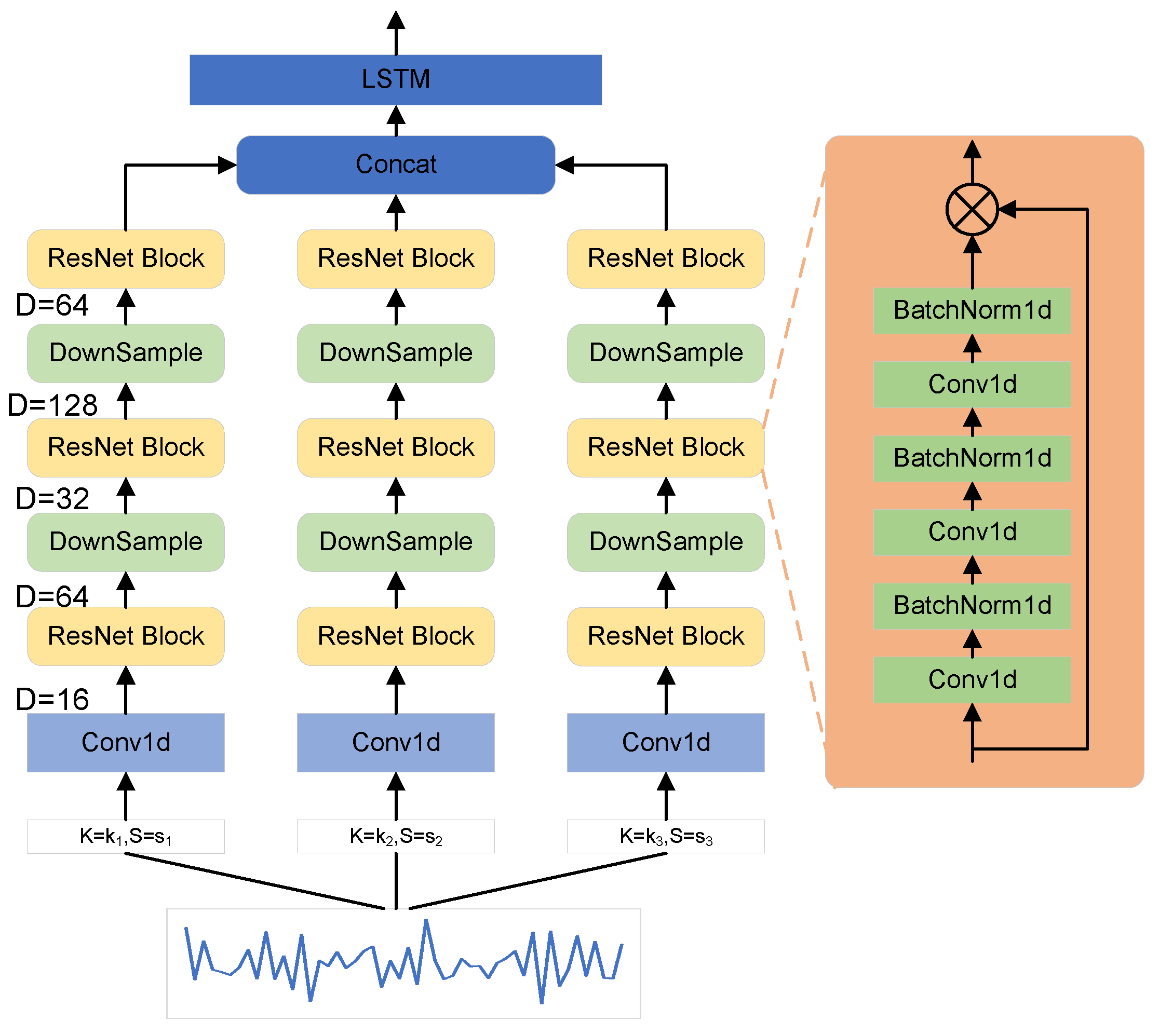
3.2. Time Domain Signal Feature Extraction
3.3. Frequency Domain Feature Extraction
3.4. Feature Fusion and Classification
4. Experimental Results and Evaluation
4.1. Network Training and Testing
4.2. Results and Discussion
- The time-domain features are extracted using a multiscale 1D-CNN, and the features extracted from CNNs of different scales are fused by the Transformer and finally classified by a fully connected layer;
- The frequency domain features are extracted using 2D-CNN, and the features are fused using the Transformer, and finally, the fully connected layer is used for classification;
- The features are extracted using a multiscale 1D-CNN and 2D-CNN for time domain and frequency domain data, respectively, and finally the features are fused and classified using a multilayer perceptron.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hornman, J.C. Field trial of seismic recording using distributed acoustic sensing with broadside sensitive fibre-optic cables. Geophys. Prospect. 2017, 65, 35–46. [Google Scholar] [CrossRef]
- Min, R.; Liu, Z.; Pereira, L.; Yang, C.; Marques, C. Optical fiber sensing for marine environment and marine structural health monitoring: A review. Opt. Laser Technol. 2021, 140, 107082. [Google Scholar] [CrossRef]
- Qin, Z. Distributed Optical Fiber Vibration Sensor Based on Rayleigh Backscattering; University of Ottawa: Ottawa, ON, Canada, 2013. [Google Scholar]
- Wang, Z.; Pan, Z.; Ye, Q.; Cai, H.; Qu, R.; Fang, Z. Fast Pattern Recognition Based on Frequency Spectrum Analysis Used for Intrusion Alarming in Optical Fiber Fence. Chin. J. Lasers 2015, 42, 0405010. [Google Scholar] [CrossRef]
- Qu, H.; Zheng, T.; Pang, L.; Li, X. A new two-dimensional method to detect harmful intrusion vibrations for optical fiber pre-warning system. Opt. Z. Licht- Elektron. = J. Light Electronoptic 2016, 127, 4461–4469. [Google Scholar] [CrossRef]
- Lu, H.; Iseley, T.; Behbahani, S.; Fu, L. Leakage detection techniques for oil and gas pipelines: State-of-the-art. Tunn. Undergr. Space Technol. 2020, 98, 103249. [Google Scholar] [CrossRef]
- Zadkarami, M.; Shahbazian, M.; Salahshoor, K. Pipeline leakage detection and isolation: An integrated approach of statistical and wavelet feature extraction with multi-layer perceptron neural network (MLPNN). J. Loss Prev. Process. Ind. 2016, 43, 479–487. [Google Scholar] [CrossRef]
- Wu, H.; Liu, X.; Xiao, Y.; Rao, Y. A Dynamic Time Sequence Recognition and Knowledge Mining Method Based on the Hidden Markov Models (HMMs) for Pipeline Safety Monitoring with Φ-OTDR. J. Light. Technol. 2019, 37, 4991–5000. [Google Scholar] [CrossRef]
- Jiang, F.; Li, H.; Zhang, Z.; Zhang, X. An event recognition method for fiber distributed acoustic sensing systems based on the combination of MFCC and CNN. In Proceedings of the 2017 International Conference on Optical Instruments and Technology: Advanced Optical Sensors and Applications, Beijing, China, 28–30 October 2017; Zhang, X., Xiao, H., Arregui, F.J., Dong, L., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2018; Volume 10618, p. 1061804. [Google Scholar]
- Yi, S.; Hao, F.; Yang, A.; Xin, F.; Zeng, Z. Research on wavelet analysis for pipeline pre-warning system based on phase-sensitive optical time domain reflectometry. In Proceedings of the IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Besançon, France, 8–11 July 2014. [Google Scholar]
- Zhang, J.; Lou, S.; Liang, S. Study of pattern recognition based on SVM algorithm for Φ-OTDR distributed optical fiber disturbance sensing system. Infrared Laser Eng. 2017, 46, 0422003. [Google Scholar] [CrossRef]
- Xu, C.; Guan, J.; Bao, M.; Lu, J.; Ye, W. Pattern recognition based on enhanced multifeature parameters for vibration events in Φ-OTDR distributed optical fiber sensing system. Microw. Opt. Technol. Lett. 2017, 59, 3134–3141. [Google Scholar] [CrossRef]
- Li, D.; Zhang, J.; Zhang, Q.; Wei, X. Classification of ECG signals based on 1D convolution neural network. In Proceedings of the 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, M.; Yang, Y.; Xu, Y.; Hu, Y.; Cai, Y.; Lin, J.; Pan, H. A Pipeline Leak Detection and Localization Approach Based on Ensemble TL1DCNN. IEEE Access 2021, 9, 47565–47578. [Google Scholar] [CrossRef]
- Chao, W.; Jian, W.; Zhang, X. Automatic radar waveform recognition based on time-frequency analysis and convolutional neural network. In Proceedings of the IEEE International Conference on Acoustics, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kumar, A.; Gandhi, C.; Zhou, Y.; Kumar, R.; Xiang, J. Improved deep convolution neural network (CNN) for the identification of defects in the centrifugal pump using acoustic images. Appl. Acoust. 2020, 167, 107399. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Specification |
|---|---|
| Model | AQ1210A |
| Wavelength (nm) | 1310 ± 25 |
| Measuring distance range (km) | 0.1∼256 |
| Event blindness (m) | ≤0.8 |
| Pulse width (ns) | 5∼20,000 |
| Sampling resolution | Minimum 5 cm |
| Number of sample points | Up to 256,000 |
| Loss measurement accuracy | ±0.03 dB/dB |
| Time Domain | Frequency Domain | |
|---|---|---|
| Input | ||
| Layer 1 | Conv1d(1,16,[3,5,7]) | Conv2d(3,16,3) |
| Layer 2 | BatchNorm1d | BatchNorm2d |
| Layer 3 | ReLU | ReLU |
| Layer 4 | Bottleneck_1d(16) channel | MaxPool2d |
| Layer 5 | Bottleneck_2d(16) | |
| Layer 6 | ||
| Layer 7 | ||
| Layer 8 | ||
| Layer 9 | ||
| Layer 10 | Bottleneck_1d(32) channel | |
| Layer 11 | Bottleneck_2d(32) | |
| Layer 12 | ||
| Layer 13 | ||
| Layer 14 | ||
| Layer 15 | ||
| Layer 16 | Bottleneck_1d(64) channel | |
| Layer 17 | Bottleneck_2d(64) | |
| Layer 18 | ||
| Layer 19 | ||
| Layer 20 | ||
| Layer 21 | ||
| Layer 22 | LSTM(3) | |
| Layer 23 | Transformer Encoder(3,8) | |
| Layer 24 | FC(64,32) | |
| Layer 25 | FC(32,5) | |
| Method | Description | Recognition Rate% |
|---|---|---|
| 1D-CNN+Transformer | Ablation experiments with time-domain feature extraction | 94.18% |
| 2D-CNN+Transformer | Ablation experiments with frequency-domain feature extraction | 95.2% |
| Time-frequency characteristics + MLP | Ablation experiments with MLP feature fusion | 96.78% |
| TL1DCNN [14] | Ensembled transfer learning deep 1DCNN for feature extraction and recognition | 93.54% |
| AWT+2D-CNN [18] | Acquisition of grayscale vibration images by wavelet transform and recognition by 2D-CNN | 94.78% |
| SVM [11] | Recognition method combining SVM and artificial features | 84.22% |
| Proposed method | Multimodal fusion based on attention mechanism | 98.54% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Gao, J.; Hong, B. Φ-OTDR Signal Identification Method Based on Multimodal Fusion. Sensors 2022, 22, 8795. https://doi.org/10.3390/s22228795
Zhang H, Gao J, Hong B. Φ-OTDR Signal Identification Method Based on Multimodal Fusion. Sensors. 2022; 22(22):8795. https://doi.org/10.3390/s22228795
Chicago/Turabian StyleZhang, Huaizhi, Jianfeng Gao, and Bingyuan Hong. 2022. "Φ-OTDR Signal Identification Method Based on Multimodal Fusion" Sensors 22, no. 22: 8795. https://doi.org/10.3390/s22228795
APA StyleZhang, H., Gao, J., & Hong, B. (2022). Φ-OTDR Signal Identification Method Based on Multimodal Fusion. Sensors, 22(22), 8795. https://doi.org/10.3390/s22228795