
Efficient Asynchronous Federated Learning for AUV Swarm



Abstract
1. Introduction
- To the authors’ knowledge, this paper is the first to introduce federated learning into the AUV swarm. Federated learning can help AUV swarm train large-scale machine learning models in an environment where underwater communication resources are scarce.
- In order to further reduce the constraints of underwater scarce communication resources on federated learning, we designed an asynchronous federated learning method, which can effectively alleviate the straggler effect and further reduce data interaction.
- We constructed the optimization problem of minimum delay and energy consumption, by jointly optimizing AUV CPU frequency and signal transmission power.
- In order to solve the optimization problem efficiently, we converted it into an MDP and proposed the PPO2 algorithm to solve this problem. The simulation results verify the effectiveness of the proposed algorithm.
- In the third section, a federated learning model based on the AUV swarm is established. First, we established a federal learning model. Second, the communication system model was established. Then the control model was established, the nodes participating in this round of upload were selected locally, and redundant nodes were adaptively skipped. Then a delay model was established to calculate the time and total time of each phase of federated learning. Then the energy consumption model was established as the energy constraint. Finally, the optimization problem is listed.
- In the fourth section, the PPO2 algorithm is used to solve the optimization problem.
- The fifth section is the experimental part. By changing the relevant parameters, we can observe the communication times, model accuracy, and model The simulation results show the convergence of the PPO2 algorithm.
- The last section of this paper is the summary, which summarizes the main points and shortcomings of this work.
2. Related Work
3. System Model
3.1. Federated Learning Model
3.2. Communication Model
3.3. Control Model
3.4. Latency Model
3.4.1. Local Parameter Calculating Latency
3.4.2. Uploading Latency
3.4.3. Global Parameter Aggregating Latency
3.4.4. Global Parameter Updating Latency
3.4.5. Downloading Latency
3.4.6. Total Latency
3.5. Energy Consumption Model
3.5.1. Energy Consumption of Follower AUV
3.5.2. Energy Consumption on Leader AUV
3.5.3. Total Energy Consumption
3.6. Problem Formulation
4. Algorithm Design
4.1. Modeling of Deep Reinforcement Learning Environment
4.2. Proximal Policy Optimization Algorithm
| Algorithm 1 Proximal policy optimization clip. |
|
5. Simulation Results
5.1. The Performance of Each Index in the Gradient Compression Test
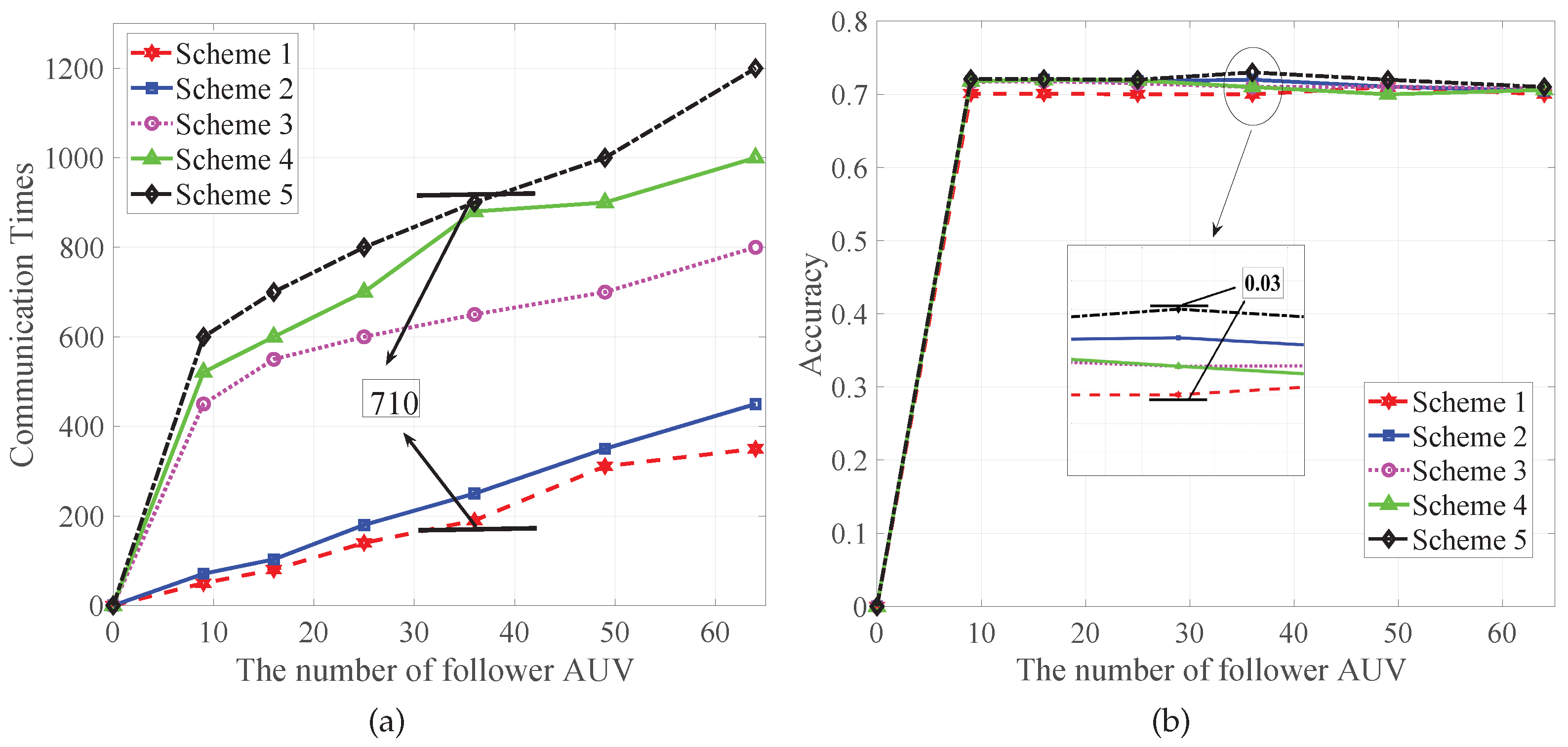
5.2. The Performance Analysis of the Scheme Proposed in This Paper
- Scheme 1: the scheme proposed in this paper.
- Scheme 2: asynchronous federated learning with dynamically optimized
- Scheme 3: asynchronous federated learning with fixed .
- Scheme 4: asynchronous federated learning with LAG.
- Scheme 5: traditional asynchronous federated learning.
5.3. The Performance Analysis of the PPO2 Algorithm
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FL | federated learning |
| AUVs | autonomous underwater vehicles |
| UIoT | underwater Internet of Things |
| PPO2 | proximal policy optimization 2 |
| FEDSGD | federated stochastic gradient descent |
| DNN | deep neural network |
| ANN | artificial neural network |
References
- Fang, Z.; Wang, J.; Jiang, C.; Wang, X.; Ren, Y. Average Peak Age of Information in Underwater Information Collection With Sleep-Scheduling. IEEE Trans. Vehicular Technol. 2022, 71, 10132–10136. [Google Scholar] [CrossRef]
- Guan, S.; Wang, J.; Jiang, C.; Duan, R.; Ren, Y.; Quek, T.Q.S. MagicNet: The Maritime Giant Cellular Network. IEEE Commun. Mag. 2021, 59, 117–123. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, J.; Jiang, C.; Zhang, Q.; Ren, Y. AoI-Inspired Collaborative Information Collection for AUV-Assisted Internet of Underwater Things. IEEE Internet Things J. 2021, 8, 14559–14571. [Google Scholar] [CrossRef]
- Fang, Z.; Wang, J.; Du, J.; Hou, X.; Ren, Y.; Han, Z. Stochastic Optimization-Aided Energy-Efficient Information Collection in Internet of Underwater Things Networks. IEEE Internet Things J. 2022, 9, 1775–1789. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics—AISTATS, Ft. Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Poudel, S.; Moh, S. Medium Access Control Protocols for Unmanned Aerial Vehicle-Aided Wireless Sensor Networks: A Survey. IEEE Access 2019, 7, 65728–65744. [Google Scholar] [CrossRef]
- Shen, C.; Shi, Y.; Buckham, B. Integrated Path Planning and Tracking Control of an AUV: A Unified Receding Horizon Optimization Approach. IEEE/ASME Trans. Mechatron. 2017, 22, 1163–1173. [Google Scholar] [CrossRef]
- Yan, J.; Yang, X.; Luo, X.; Chen, C. Energy-Efficient Data Collection Over AUV-Assisted Underwater Acoustic Sensor Network. IEEE Syst. J. 2018, 12, 3519–3530. [Google Scholar] [CrossRef]
- Cai, L.; Zhou, G.; Zhang, S. Multi-AUV Collaborative Hunting Method for the Non-cooperative Target in Underwater Environment. In Proceedings of the 2018 3rd International Conference on Advanced Robotics and Mechatronics (ICARM), Singapore, 18–20 July 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Cui, R.; Li, Y.; Yan, W. Mutual Information-Based Multi-AUV Path Planning for Scalar Field Sampling Using Multidimensional RRT*. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 993–1004. [Google Scholar] [CrossRef]
- Noguchi, Y.; Maki, T. Path Planning Method Based on Artificial Potential Field and Reinforcement Learning for Intervention the AUVs. In Proceedings of the 2019 IEEE Underwater Technology (UT), Kaohsiung, Taiwan, 16–19 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Huang, H.; Zhu, D.; Yuan, F. Dynamic task assignment and path planning for multi-AUV system in 2D variable ocean current environment. In Proceedings of the 24th Chinese Control and Decision Conference (CCDC), Taiyuan, China, 23–25 May 2012; pp. 3660–3664. [Google Scholar] [CrossRef]
- Cao, X.; Sun, C. Multi-AUV cooperative target hunting based on improved potential field in underwater environment. In Proceedings of the 33rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanjing, China, 18–20 May 2018; pp. 118–122. [Google Scholar]
- Van, N.T.T.; Luong, N.C.; Nguyen, H.T.; Shaohan, F.; Niyato, D.; Kim, D.I. Latency Minimization in Covert Communication-Enabled Federated Learning Network. IEEE Trans. Vehicular Technol. 2021, 70, 13447–13452. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Communication-Efficient Federated Learning and Permissioned Blockchain for Digital Twin Edge Networks. IEEE Internet Things J. 2021, 8, 2276–2288. [Google Scholar] [CrossRef]
- Chen, M.; Poor, H.V.; Saad, W.; Cui, S. Convergence Time Optimization for Federated Learning Over Wireless Networks. IEEE Trans. Wirel. Commun. 2021, 20, 2457–2471. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; Ding, G. Accelerating DNN Training in Wireless Federated Edge Learning Systems. IEEE J. Sel. Areas Commun. 2021, 39, 219–232. [Google Scholar] [CrossRef]
- Zhang, J.; Simeone, O. LAGC: Lazily Aggregated Gradient Coding for Straggler-Tolerant and Communication-Efficient Distributed Learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 962–974. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Sun, Y.; Yin, W. Communication-Adaptive Stochastic Gradient Methods for Distributed Learning. IEEE Trans. Signal Process. 2021, 69, 4637–4651. [Google Scholar] [CrossRef]
- Sun, J.; Chen, T.; Giannakis, G.B.; Yang, Q.; Yang, Z. Lazily Aggregated Quantized Gradient Innovation for Communication-Efficient Federated Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2031–2044. [Google Scholar] [CrossRef] [PubMed]
- Jensen, F.B.; Kuperman, W.A.; Porter, M.B.; Schmidt, H.; Tolstoy, A. Computational Ocean Acoustics; Springer: Berlin/Heidelberg, Germany, 2011; Volume 2011. [Google Scholar]
- Stojanovic, M. On the relationship between capacity and distance in an underwater acoustic communication channel. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2007, 11, 34–43. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| k | 0.01 | ||
| 3 | M | 20 | |
| 10 kHz | f | 30 kHz | |
| 10 kHz | s | 0.5 | |
| 4224 | 5 | ||
| 10,000 | 0.4 GHz | ||
| 50 | 0.2 GHz | ||
| 50 | 0.07 W | ||
| 1594*64 bit | 0.8 W | ||
| 1594*64 bit | 1 | ||
| 0.2 W | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, Z.; Li, Z.; Hou, X.; Du, J.; Chen, J.; Wei, W. Efficient Asynchronous Federated Learning for AUV Swarm. Sensors 2022, 22, 8727. https://doi.org/10.3390/s22228727
Meng Z, Li Z, Hou X, Du J, Chen J, Wei W. Efficient Asynchronous Federated Learning for AUV Swarm. Sensors. 2022; 22(22):8727. https://doi.org/10.3390/s22228727
Chicago/Turabian StyleMeng, Zezhao, Zhi Li, Xiangwang Hou, Jun Du, Jianrui Chen, and Wei Wei. 2022. "Efficient Asynchronous Federated Learning for AUV Swarm" Sensors 22, no. 22: 8727. https://doi.org/10.3390/s22228727
APA StyleMeng, Z., Li, Z., Hou, X., Du, J., Chen, J., & Wei, W. (2022). Efficient Asynchronous Federated Learning for AUV Swarm. Sensors, 22(22), 8727. https://doi.org/10.3390/s22228727