
G-DaM: A Distributed Data Storage with Blockchain Framework for Management of Groundwater Quality Data

 , and
, and 
Abstract
1. Introduction
2. Novel Contributions
2.1. Problem Definition
2.2. Current IoAT Challenges
2.3. Importance of Data Quality in Groundwater Data Transmission
2.4. Why Blockchain in Data Transmission?
2.5. Past Incidents of Insecure Data in Water Plants
2.6. Problem Addressed in the Current Paper
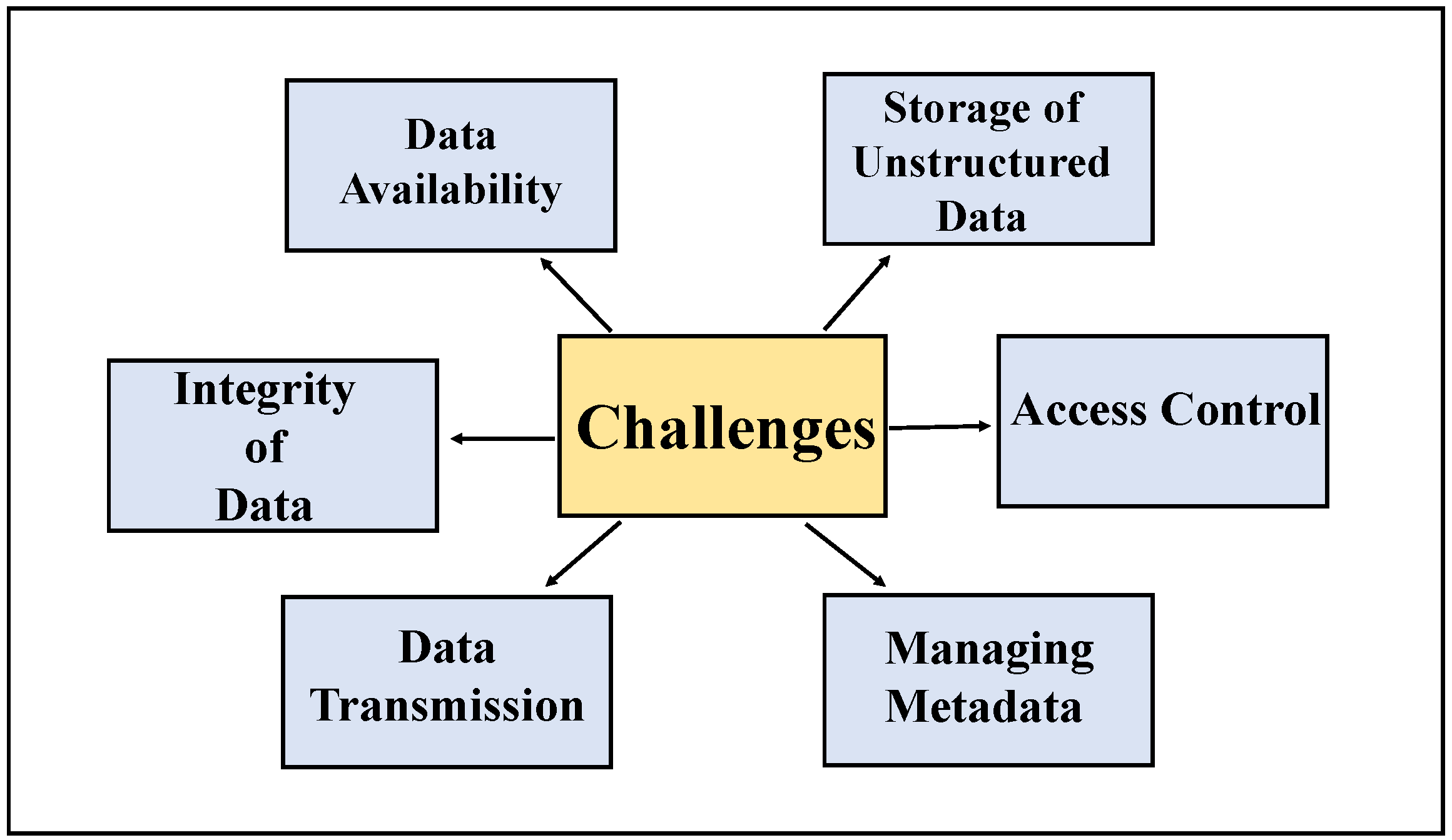
- Groundwater data management challenges can be classified into storage, pre-processing, and secure sharing. Attributes such as integrity, availability, security, access, ingestion, metadata, transformation, and warehousing can be sub-categorical. Figure 1 illustrates different kinds of data management issues.
- Central storage vulnerabilities.
- Disadvantages of the blockchain for slow speed, energy-draining, scaling, and price.
2.7. Solutions Proposed in the Current Paper
- DDS through IPFS for off-chain storage to evade blockchain limitations.
- A blockchain-based data storage solution to overcome IoAT challenges.
- Access control approaches through blockchain smart contracts.
- Achieving privacy by combining both DDS and blockchain technologies.
2.8. State-of-the-Art Solutions
- For improving the quality, overcoming IoAT constraints, and decreasing the uncertainty of the data, unique blockchain technology is used for groundwater data sharing and storing.
- For bulk data to be stored and shared, DDS is used, providing increased security to the derived statistics.
- A state-of-the-art architecture is presented for the current G-DaM with dual hashing security included.
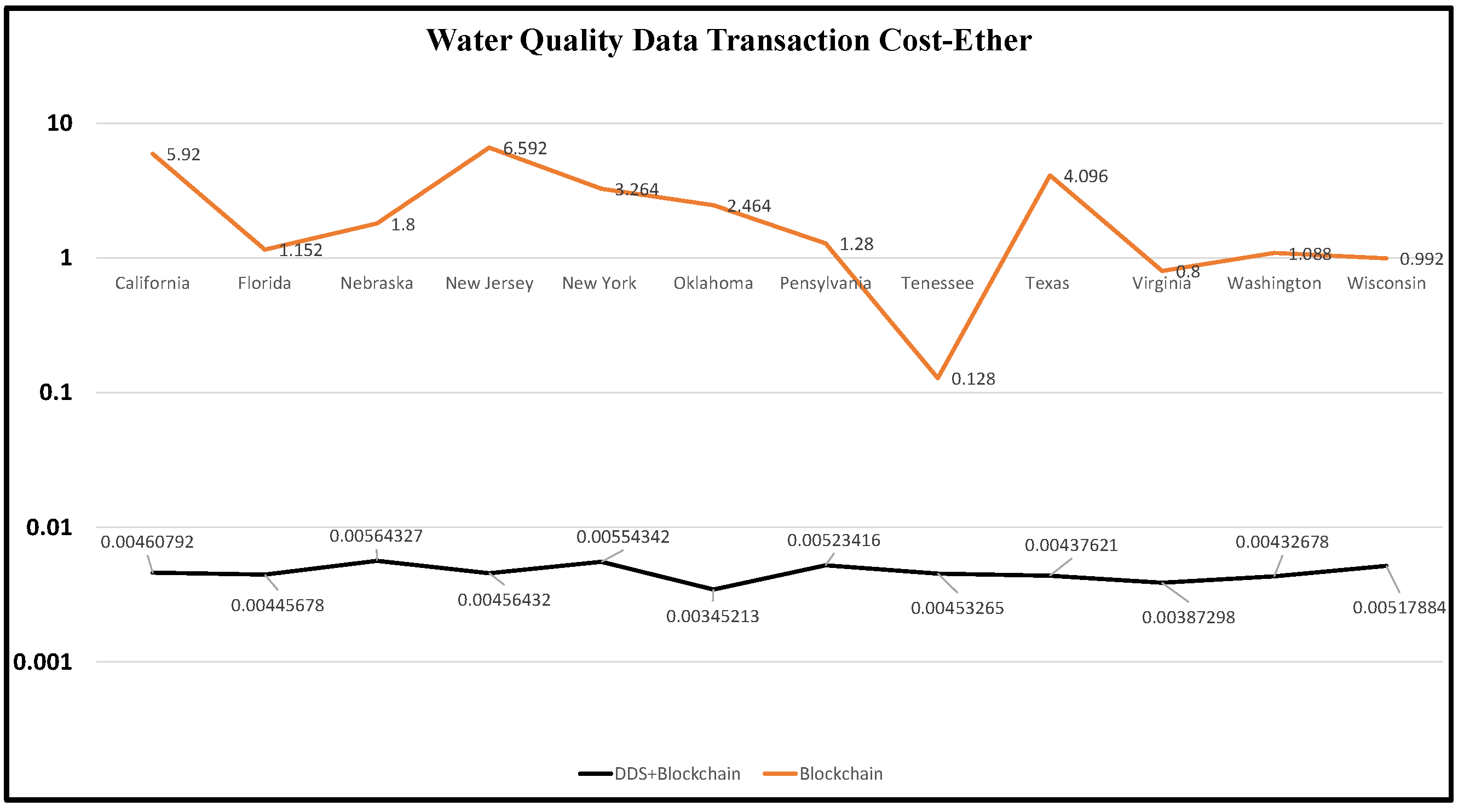
- A result log is shown for comparing transaction times, fees, and costs between traditional blockchain and blockchain with distributed storage systems.
3. Prior Related Works
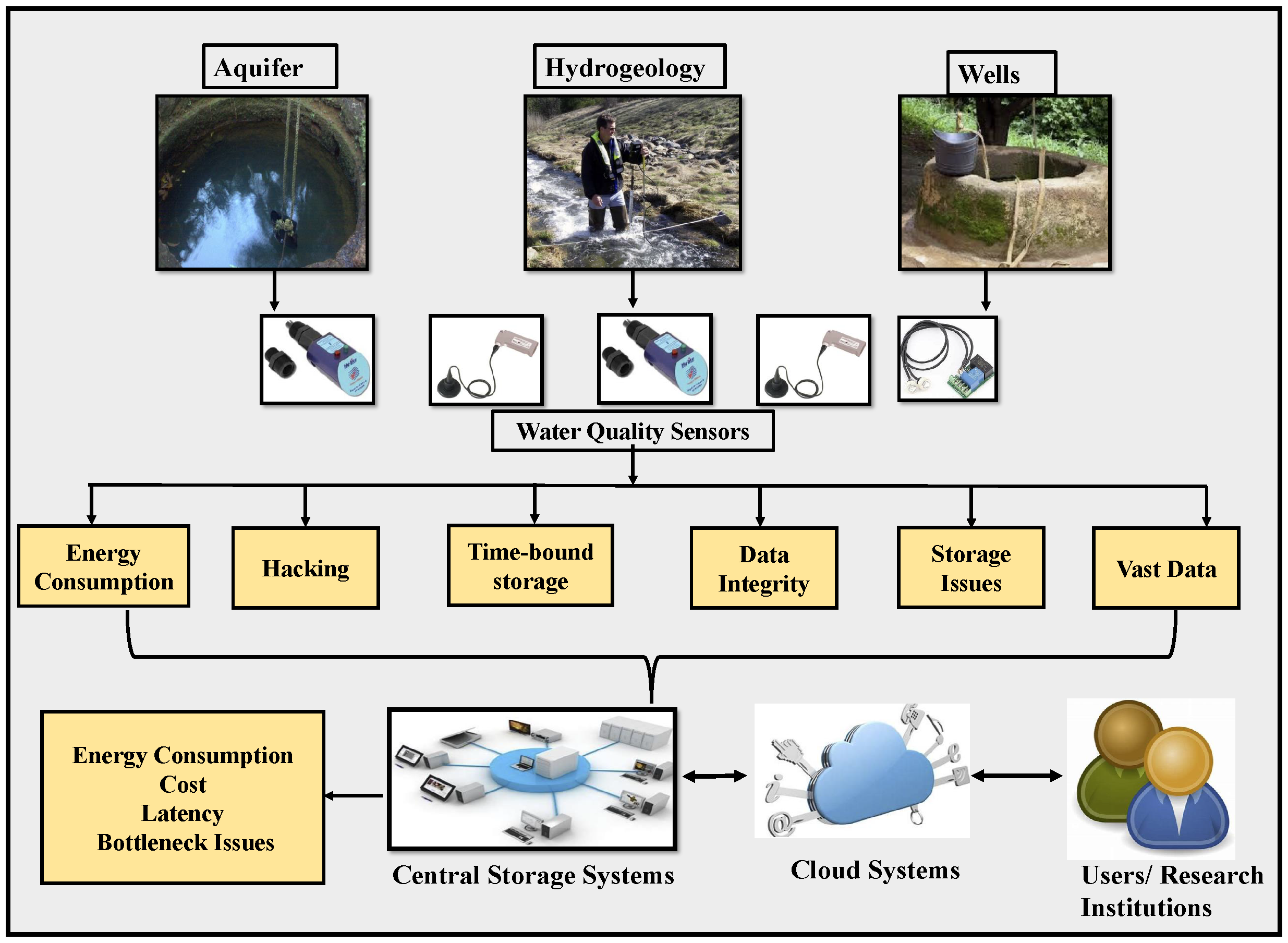
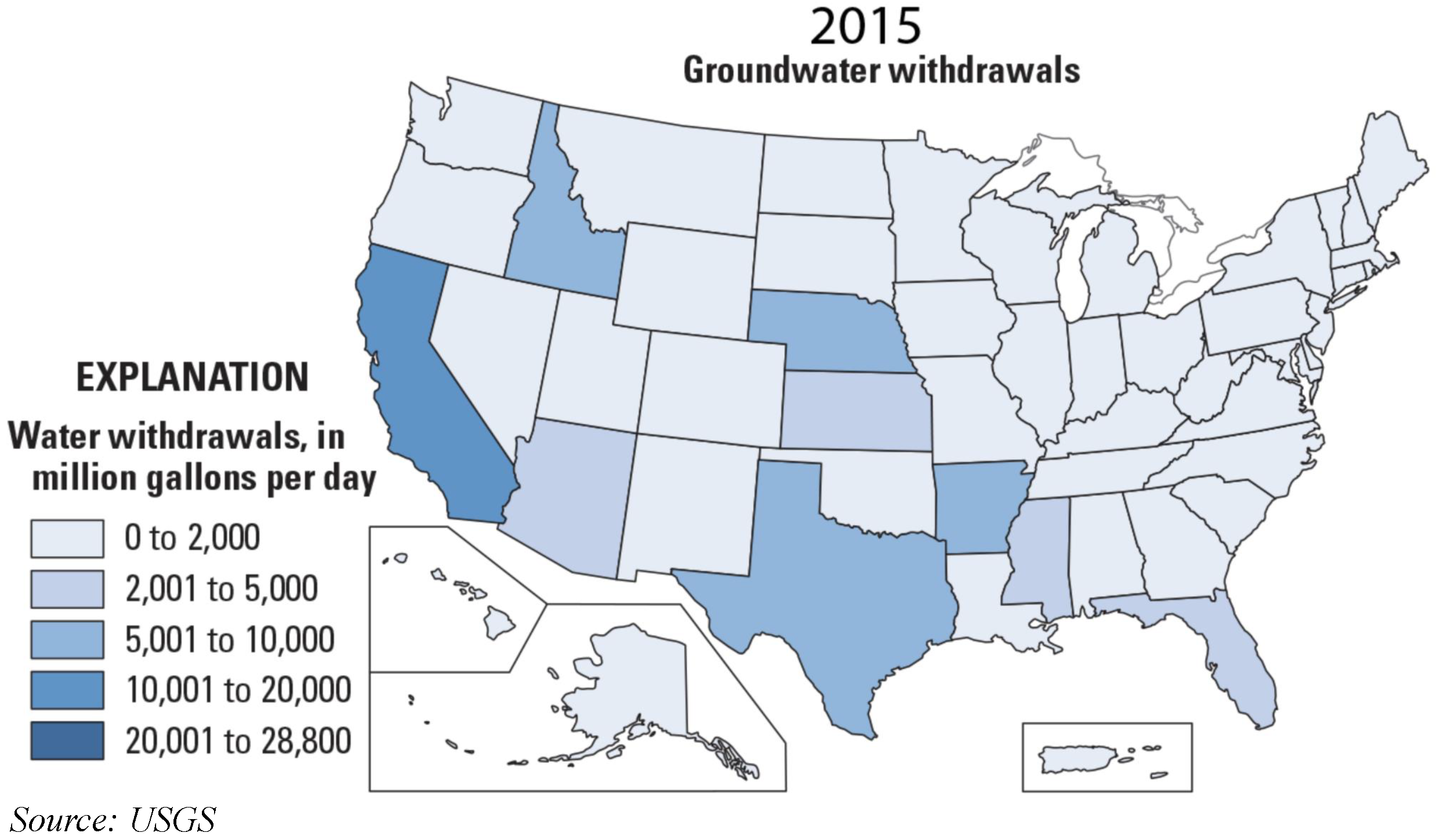
4. Sources for Groundwater Data
4.1. Activities on Field
4.2. Historical
4.3. Remote Sensing
4.4. Computer Simulation
4.5. Web and Social Media
4.6. Internet of Things (IoT)
4.7. Groundwater and Groundwater Quality Data User Domains
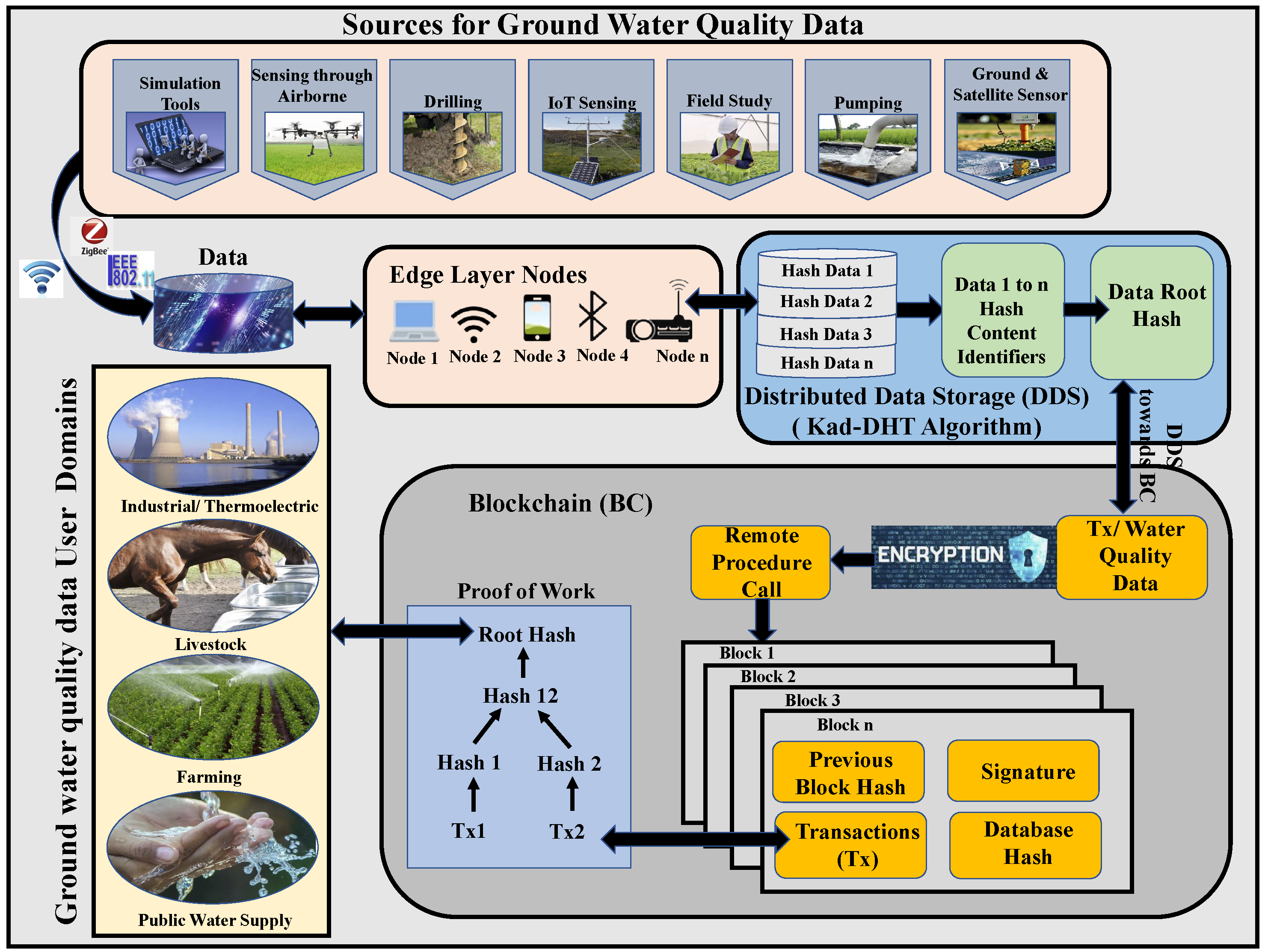
5. A DDS and Blockchain Platform Water-Quality Data Management System Architecture
5.1. Interplanetary File System (IPFS)—DDS
5.2. BC-Ethereum Smart Contract
5.3. Architecture
5.3.1. Adding File
5.3.2. Linking IPFS Data to Ethereum Smart Contracts
5.3.3. Retrieving the File
6. Algorithms for DDS and Blockchain Based Framework
| Algorithm 1 Data from Groundwater endsystems to IPFS and blockchain. |
|
| Algorithm 2 Data from Blockchain to User Domains. |
|
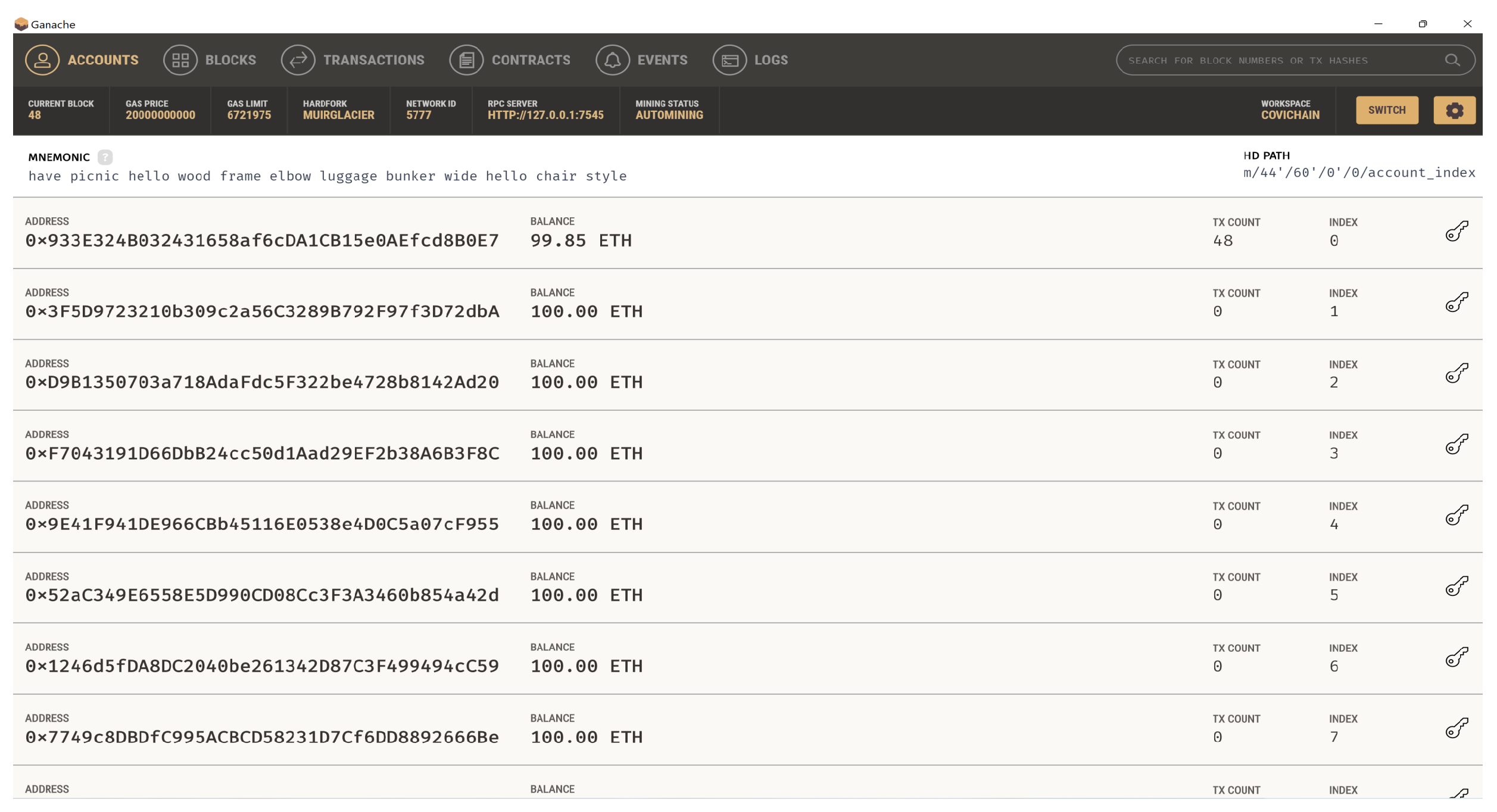
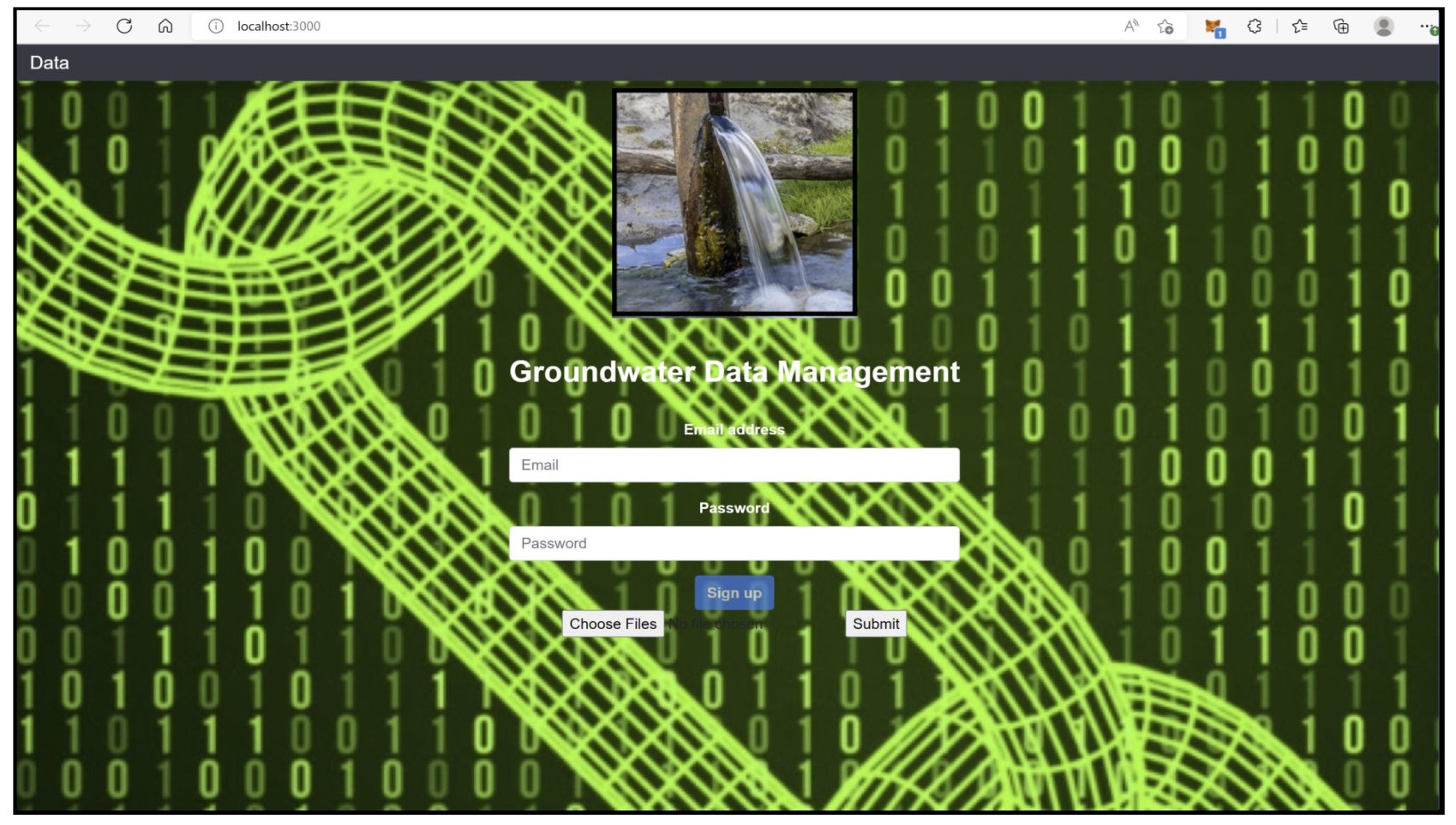
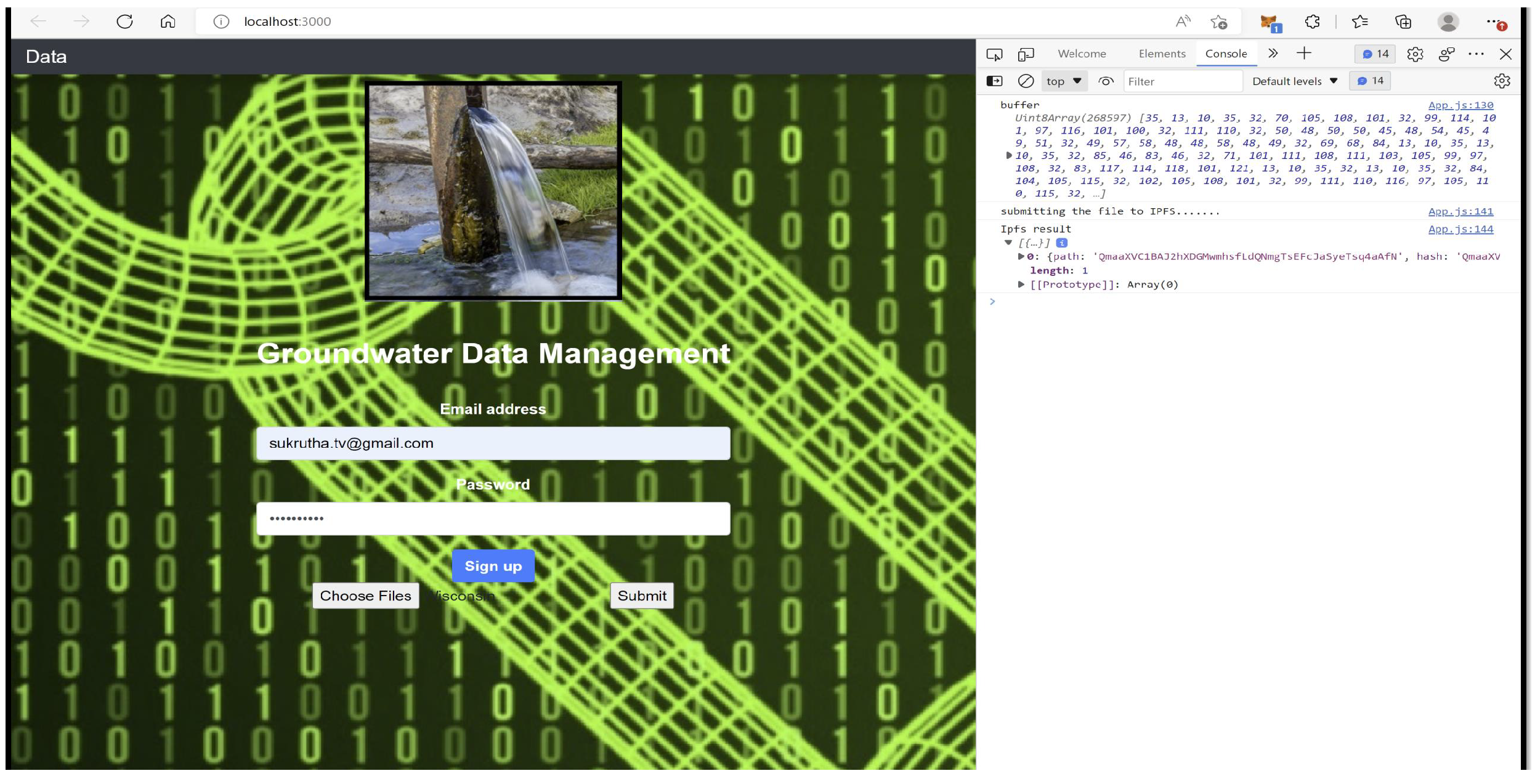
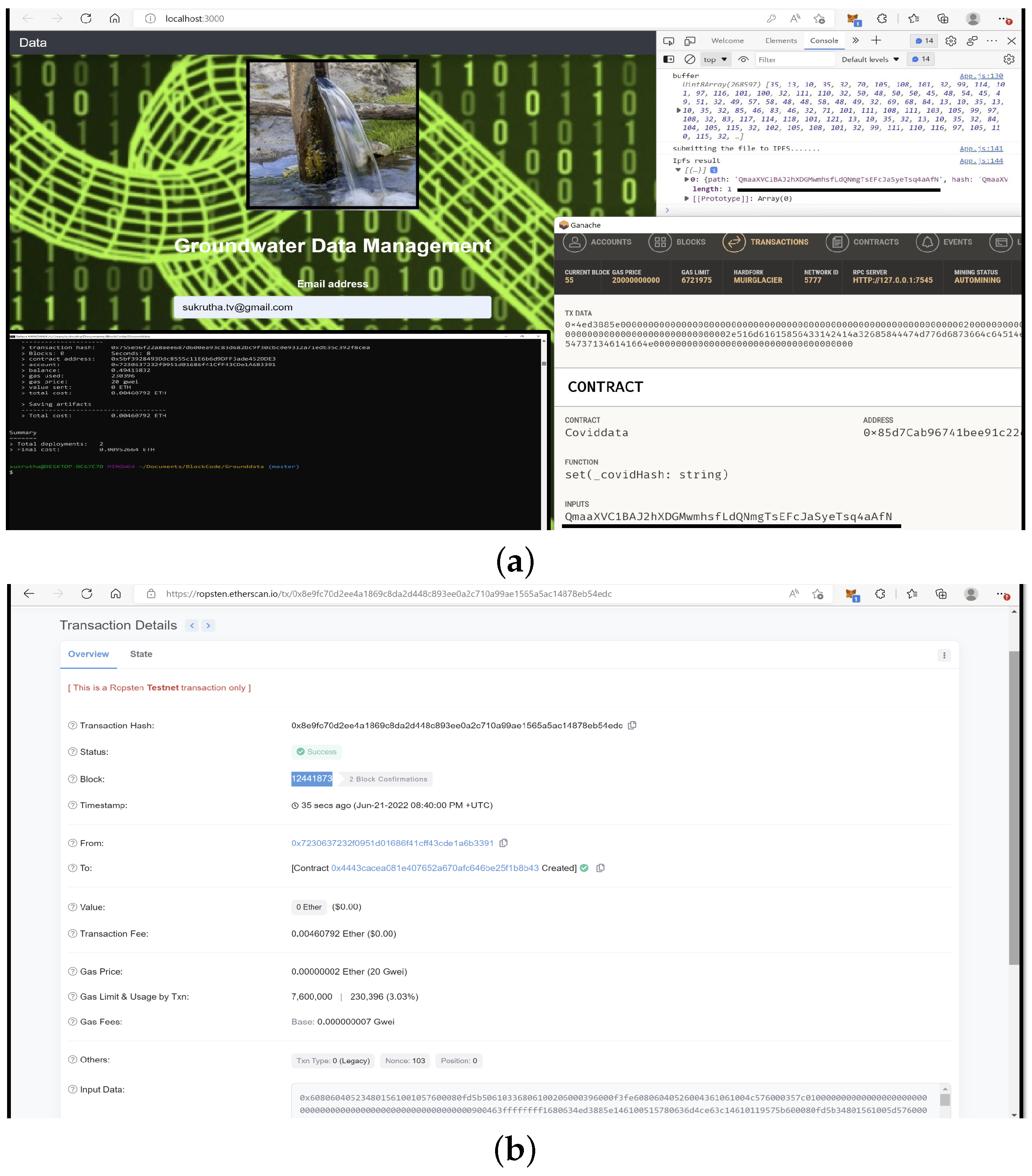
7. G-DaM Implementation
8. G-DaM Results
Datasets
9. Conclusions and Future Direction for Research
Author Contributions
Funding
Conflicts of Interest
References
- Raghav. Groundwater: Origin, Sources and Other Details. 2014. Available online: https://www.geographynotes.com/essay/groundwater-origin-sources-and-other-details-with-diagram/620/ (accessed on 12 July 2021).
- Pongpun, J.; Daniel, D.S.; Erin, M.H.; Chittaranjan, R. The long term effect of agricultural, vadose zone and climatic factors on nitrate contamination in Nebraska’s groundwater system. J. Contam. Hydrol. 2019, 220, 33–48. [Google Scholar] [CrossRef]
- Exner, M.E.; Aaron; Hirsh, J.; Spalding, R.F. Nebraska’s groundwater legacy: Nitrate contamination beneath irrigated cropland. Adv. Earth Space Sci. 2014, 50, 4474–4489. [Google Scholar] [CrossRef]
- Fitch, P.; Brodaric, B.; Stenson, M.; Booth, N. Integrated Groundwater Data Management; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 667–692. [Google Scholar] [CrossRef]
- Puthal, D.; Malik, N.; Mohanty, S.P.; Kougianos, E.; Das, G. Everything You Wanted to Know About the Blockchain: Its Promise, Components, Processes, and Problems. IEEE Consum. Electron. Mag. 2018, 7, 6–14. [Google Scholar] [CrossRef]
- Ur Rahman, M.; Baiardi, F.; Ricci, L. Blockchain Smart Contract for Scalable Data Sharing in IoT: A Case Study of Smart Agriculture. In Proceedings of the 2020 IEEE Global Conference on Artificial Intelligence and Internet of Things (GCAIoT), Dubai, United Arab Emirates, 12–16 December 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Vangipuram, S.; Mohanty, S.; Kougianos, E. CoviChain: A Blockchain Based Framework for Nonrepudiable Contact Tracing in Healthcare Cyber-Physical Systems during Pandemic Outbreaks. SN Comput. Sci. 2021, 2, 346. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.U.; Min-Allah, N. A Goal Programming Based Energy Efficient Resource Allocation in Data Centers; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Zomaya, A.Y.; Lee, Y.C. Comparison and Analysis of Greedy Energy-Efficient Scheduling Algorithms for Computational Grids. In Energy-Efficient Distributed Computing Systems; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012; pp. 189–214. [Google Scholar] [CrossRef]
- Zomaya, A.Y.; Lee, Y.C. Energy-Efficient Distributed Computing Systems (Wiley Series on Parallel and Distributed Computing); John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012. [Google Scholar]
- The Ohio State University. Water Contamination Disasters. 2016. Available online: https://u.osu.edu/waterpollution2367/water-pollution-crises/ (accessed on 20 October 2022).
- Magill, J. U.S. Water Supply System Being Targeted by Cybercriminals. 2021. Available online: https://www.forbes.com/sites/jimmagill/2021/07/25/us-water-supply-system-being-targeted-by-cybercriminals/?sh=53b19c5328e7 (accessed on 20 October 2022).
- Jin, H.; Feng, L.; Liang, R.; Xing, S. Design of urban and rural water resources information management system based on Delphi. In Proceedings of the 2011 Second International Conference on Mechanic Automation and Control Engineering, Hohhot, China, 15–17 July 2011; pp. 7284–7287. [Google Scholar] [CrossRef]
- Ma, D.; Cui, J. Design and realization of water quality information management system based on GIS. In Proceedings of the 2011 International Symposium on Water Resource and Environmental Protection, Xi’an, China, 20–22 May 2011; Volume 1, pp. 775–778. [Google Scholar] [CrossRef]
- Peng, Z.; Chen, Y.; Zhang, Z.; Qiu, Q.; Han, X. Implementation of Water Quality Management Platform for Aquaculture Based on Big Data. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications (CIBDA), Guiyang, China, 17–19 April 2020; pp. 70–74. [Google Scholar] [CrossRef]
- Beshah, W.T.; Moorhead, J.; Dash, P.; Moorhead, R.J.; Herman, J.; Sankar, M.S.; Chesser, D.; Lowe, W.; Simmerman, J.; Turnage, G. IoT Based Real-Time Water Quality Monitoring and Visualization System Using an Autonomous Surface Vehicle. In Proceedings of the OCEANS 2021: San Diego—Porto, San Diego, CA, USA, 20–23 September 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Rathna, R.; Anbazhagu, U.V.; Mary Gladence, L.; Anu, V.M.; Sybi Cynthia, J. An Intelligent Monitoring System for Water Quality Management using Internet of Things. In Proceedings of the 2021 8th International Conference on Smart Computing and Communications (ICSCC), Kochi, Kerala, India, 1–3 July 2021; pp. 291–297. [Google Scholar] [CrossRef]
- Drăgulinescu, A.M.; Constantin, F.; Orza, O.; Bosoc, S.; Streche, R.; Negoita, A.; Osiac, F.; Balaceanu, C.; Suciu, G. Smart Watering System Security Technologies using Blockchain. In Proceedings of the 2021 13th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Pitesti, Romania, 1–3 July 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Alharbi, N.; Althagafi, A.; Alshomrani, O.; Almotiry, A.; Alhazmi, S. A Blockchain Based Secure IoT Solution for Water Quality Management. In Proceedings of the 2021 International Congress of Advanced Technology and Engineering (ICOTEN), Taiz, Yemen, 4–5 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Turganbaev, E.; Rakhmetullina, S.; Beldeubayeva, Z.; Krivykh, V. Information system of efficient data management of groundwater monitoring the Republic of Kazakhstan. In Proceedings of the 2015 9th International Conference on Application of Information and Communication Technologies (AICT), Rostov on Don, Russia, 14–16 October 2015. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Liu, J.; Zhang, Y. The design and applications of services platform system for water data basing on WebGIS. In Proceedings of the 2010 2nd IEEE International Conference on Information Management and Engineering, Chengdu, China, 16–18 April 2010. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhu, S.; Yu, M. Study on groundwater data sharing based on metadata. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, 2005. IGARSS ’05, Seoul, Korea, 29 July 2005; Volume 2. [Google Scholar] [CrossRef]
- Takuya, I.; Sondoss, E.S.; Anthony, J. Design and Implementation of a Web-Based Groundwater Data Management System; Elsevier: Amsterdam, The Netherlands, 2013; Volume 93. [Google Scholar] [CrossRef]
- Gul, O. Blockchain-Enabled Internet of Things (IoTs) Platforms for Vehicle Sensing and Transportation Monitoring. In Machine Learning, Blockchain Technologies and Big Data Analytics for IoTs: Methods, Technologies and Applications; Institution of Engineering and Technology: London, UK, 2022; pp. 351–373. [Google Scholar] [CrossRef]
- Xia, Y.; Kwon, H.; Wander, M. Developing County Level Data of Nitrogen Fertilizer and Manure Inputs for Corn Production in the United States; Elsevier: Amsterdam, The Netherlands, 2021; Volume 309. [Google Scholar] [CrossRef]
- Grounwater Data. 2021. Available online: https://maps.waterdata.usgs.gov/mapper/nwisquery.html (accessed on 11 July 2021).
- Hugo, L.; Randall, C.; Lorne, E.; Graham, F. Review of Ground Water Quality Monitoring Network Design. J. Hydraul. Eng. 1992, 118, 11–37. Available online: https://ascelibrary.org/doi/10.1061/(ASCE)0733-9429(1992)118:1(11) (accessed on 10 October 2022).
- Zhang, Z.; Moore, J.C. Mathematical and Physical Fundamentals of Climate Change; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar] [CrossRef]
- Tang, Q.; Gao, H.; Lu, H.; Lettenmaier, D.P. Remote Sensing: Hydrology; SAGE: Thousand Oaks, CA, USA, 2009. [Google Scholar] [CrossRef]
- Hisashi, S.; Akihiko, I.; Akinori, I.; Takashi, I.; Etsushi, K. Current status and future of land surface models. Soil Sci. Plant Nutr. 2014, 61, 34–47. [Google Scholar] [CrossRef]
- Vasileios, L.; Nello, C. Nowcasting Events from the Social Web with Statistical Learning. Assoc. Comput. Mach. 2012, 3, 72. [Google Scholar] [CrossRef]
- Macaulay, T. RIoT Control: Understanding and Managing Risks and the Internet of Things; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar] [CrossRef]
- Udutalapally, V.; Mohanty, S.P.; Pallagani, V.; Khandelwal, V. sCrop: A Novel Device for Sustainable Automatic Disease Prediction, Crop Selection, and Irrigation in Internet-of-Agro-Things for Smart Agriculture. IEEE Sens. J. 2020, 21, 17525–17538. [Google Scholar] [CrossRef]
- Tripathy, P.K.; Tripathy, A.K.; Agarwal, A.; Mohanty, S.P. MyGreen: An IoT-Enabled Smart Greenhouse for Sustainable Agriculture. IEEE Consum. Electron. Mag. 2021, 10, 57–62. [Google Scholar] [CrossRef]
- Rachakonda, L.; Bapatla, A.K.; Mohanty, S.P.; Kougianos, E. SaYoPillow: Blockchain-Integrated Privacy-Assured IoMT Framework for Stress Management Considering Sleeping Habits. IEEE Trans. Consum. Electron. 2021, 67, 20–29. [Google Scholar] [CrossRef]
- Who Uses Groundwater? 2015. Available online: http://gwhub.srw.com.au/who-uses-groundwater (accessed on 14 July 2021).
- Tabora, V. Using IPFS for Distributed File Storage Systems. 2020. Available online: https://medium.com/0xcode/using-ipfs-for-distributed-file-storage-systems-61226e07a6f/ (accessed on 26 June 2021).
- Maymounkov, P.; Eres, D. Kademlia: A Peer-to-Peer Information System Based on the XOR Metric; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2429. [Google Scholar] [CrossRef]
- Baumgart, I.; Mies, S. S/Kademlia: A practicable approach towards secure key-based routing. In IEEE Parallel and Distributed Systems; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar] [CrossRef]
- Solidity 0.8.6 Documentation. 2018. Available online: https://docs.soliditylang.org/en/v0.8.6/ (accessed on 26 June 2021).
- Andreas, M.A.; Gavin, W. Mastering Ethereum; O’Reilly: Sebastopol, CA, USA, 2018. [Google Scholar]
- Survey, U.G. Water Quality. 2022. Available online: https://waterdata.usgs.gov/usa/nwis/qw (accessed on 10 July 2021).
- Ycharts. Ethreum Price. 2022. Available online: https://ycharts.com/indicators/ethereum_price (accessed on 14 August 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Data Storage | Security Level | Cost | Computation |
|---|---|---|---|---|
| Urban Rural Water Quality Data [13] | Centralized | Low-High Risks on Data | High | High |
| Water Quality Data with GIS [14] | Centralized | Low-High Risks on Data | High | High |
| Water Quality information in Big data [15] | Centralized | Low-High Risks on Data | High | High |
| Water Quality data with ASV [16] | Centralized | Low-High Risks on Data | High | High |
| Water Quality Data from IoT [17] | Centralized | Low-High Risks on Data | High | High |
| Water Quality Data from IoT [18] | Decentralized | High-Single Hashing | High | High |
| Water Quality Data from IoT [19] | Decentralized | High-Single Hashing | High | High |
| Groundwater quality Data [20] | Centralized | Low-High Risks on Data | High | High |
| Groundwater quality Data [21] | Centralized | Low-High Risks on Data | High | High |
| Groundwater quality Data [22] | Centralized | Low-High Risks on Data | High | High |
| Groundwater quality Data [23] | Centralized | Low-High Risks on Data | High | High |
| G-DaM [Current-Paper] | Decentralized-OffChain storage | High-DoubleHashing | Low | Low |
| Data Name | Dataset Size | Compressed.zip Size | Link |
|---|---|---|---|
| California Water Quality | 1.64 MB | 186 KB | https://waterdata.usgs.gov/ca/nwis/qw (accessed on 10 October 2022) |
| Florida Water Quality | 328 KB | 36 KB | https://waterdata.usgs.gov/fl/nwis/qw (accessed on 10 October 2022) |
| Nebraska Water Quality | 709 KB | 84 KB | https://waterdata.usgs.gov/ne/nwis/qw (accessed on 10 October 2022) |
| New Jersey Water Quality | 1.76 MB | 206 KB | https://waterdata.usgs.gov/nj/nwis/qw (accessed on 10 October 2022) |
| New York Water Quality | 883 KB | 102 KB | https://waterdata.usgs.gov/ny/nwis/qw (accessed on 10 October 2022) |
| Oklahoma Water Quality | 669 KB | 77 KB | https://waterdata.usgs.gov/ok/nwis/qw (accessed on 10 October 2022) |
| Pennsylvania Water Quality | 385 KB | 40 KB | https://waterdata.usgs.gov/pa/nwis/qw (accessed on 10 October 2022) |
| Tennessee Water Quality | 20 KB | 4 KB | https://waterdata.usgs.gov/tn/nwis/qw (accessed on 10 October 2022) |
| Texas Water Quality | 1.12 MB | 128 KB | https://waterdata.usgs.gov/tx/nwis/qw (accessed on 10 October 2022) |
| Virginia Water Quality | 191 KB | 25 KB | https://waterdata.usgs.gov/va/nwis/qw (accessed on 10 October 2022) |
| Washington Water Quality | 288 KB | 34 KB | https://waterdata.usgs.gov/wa/nwis/qw (accessed on 10 October 2022) |
| Wisconsin Water Quality | 262 KB | 31 KB | https://waterdata.usgs.gov/wi/nwis/qw (accessed on 10 October 2022) |
| File | File-Size | IPFS-Hash | Tx Hash/BC Hash | Tx Deploying Time (s) |
|---|---|---|---|---|
| California Water Quality data | 186 KB | QmcMnYyywy5No 5eP25gcRirPymv4YAFL s3AyamC66X6dpv | 0x9c9ff748384e2 3a50ddfcc6f2fbca49 ce55638e1b6136e 51d50bed19fb60b37c | 8 |
| Florida Water Quality data | 36 KB | QmTTSJLxoAYSgQFpA q5z2MmSMuq1NfMY6 MGogKoSVbMhgw | 0x833374419e5ac21 9f7f3591df7335ad508d0 bd6865897da3a935 212662fd051d | 8 |
| Nebraska Water Quality data | 84 KB | QmY3y84FBmnzc2 EukKS3wyT6J5teGnT 3Y5aMXKhfGAW65C | 0x3e65d503b14aed 2bbc1e4c393da861 857f1b137c9f185322 dec77c6cb41dea84 | 32 |
| New Jersey Water Quality data | 206 KB | QmSkQ2FsCywsfkv EiFmQwWY97evqWk CBqBgEBUNpLZd1tE | 0x82e3011ea9c91 0d76a2faf759310920 3378a6950c3c2e8d8 2dbd2ebc29bed5fc | 20 |
| New York Water Quality data | 102 KB | QmYmKPhKWvGs7 R1guBnPpwk8usNXqn 7j4ikX1ByvKtUagh | 0x71285afe6a050cde bdd4c2e650cca2d3759 8ab459e3a0a77c5 19b1b87bbecc54 | 36 |
| Oklahoma Water Quality data | 77 KB | QmeDzZvmzkkCgf mC8UN8NbVT18oavX 7ZEtTVmpsirj4ndu | 0x7ab98459b29b5 71fb654dbf90f884167dc4 4c8386115c381d8c9e 3c831611853 | 8 |
| Pennsylvania Water Quality data | 40 KB | QmPDXu4qMJHQR MTJC2T3rCB9CfFzQhRD thW6HsbRLUogo2 | 0xfdd3de4eb8b3 3d82120df40187fb51 b1fe6d4bcd1074df0519 80e6c5e5233210 | 20 |
| Tennessee Water Quality data | 4 KB | QmU4BmcNbTb uTe9LQxkTSHPiWmN9xj3F 9uQu624sieQVGs | 0x8e9fc70d2ee4a 1869c8da2d448c89 3ee0a2c710a99ae156 5a5ac14878eb54edc | 32 |
| Texas Water Quality data | 128 KB | QmVoN2iNU3T zDPy1QrG8Ck2nHMrqt PcAZN72E4i1MtPKsf | 0xc9360e9e1d5b7d6 be2c8d9811ca427407 82aaf10c6a72866813b d4484c26c20d | 20 |
| Virginia Water Quality data | 25 KB | QmRZDbew3iU9U gH3S9WZhPgi2n4gAq nUR7uvd9v67cncfD | 0x9d547180ce0b f1f437f3f3934c1f759 bbfdbab8fc47c22c 73903e8f46392cb6f | 8 |
| Washington Water Quality data | 34 KB | QmT5GrgoPH92nu a5WTbCUcDpiCs2RWC kxVkqJnRY7CY3Jq | 0xf86cd670ff4e6 74f522d64badf7b 2674ac9a3846bbd91 b863f8ed012f944317 | 8 |
| Wisconsin Water Quality data | 31 KB | QmYTPr445A72L uscbaavgqppZKmMKrAY 9HV3U7dmbBB5dF | 0xc544ef6ded8dc 865ada99b79b74faeae f897a55bc4c827c21 1fa9da95f758b68 | 20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vangipuram, S.L.T.; Mohanty, S.P.; Kougianos, E.; Ray, C. G-DaM: A Distributed Data Storage with Blockchain Framework for Management of Groundwater Quality Data. Sensors 2022, 22, 8725. https://doi.org/10.3390/s22228725
Vangipuram SLT, Mohanty SP, Kougianos E, Ray C. G-DaM: A Distributed Data Storage with Blockchain Framework for Management of Groundwater Quality Data. Sensors. 2022; 22(22):8725. https://doi.org/10.3390/s22228725
Chicago/Turabian StyleVangipuram, Sukrutha L. T., Saraju P. Mohanty, Elias Kougianos, and Chittaranjan Ray. 2022. "G-DaM: A Distributed Data Storage with Blockchain Framework for Management of Groundwater Quality Data" Sensors 22, no. 22: 8725. https://doi.org/10.3390/s22228725
APA StyleVangipuram, S. L. T., Mohanty, S. P., Kougianos, E., & Ray, C. (2022). G-DaM: A Distributed Data Storage with Blockchain Framework for Management of Groundwater Quality Data. Sensors, 22(22), 8725. https://doi.org/10.3390/s22228725