
IBD: An Interpretable Backdoor-Detection Method via Multivariate Interactions


Abstract
:1. Introduction
- Taking advantage of information theory techniques, we theoretically analyze the multivariate interactions of features from different categories and reveal how the backdoor works in infected models (addressing Challenge 1);
- Following the theoretical analysis, we propose a theoretical-guaranteed defense method IBD, an interpretable backdoor-detection method via multivariate interactions. IBD outperforms existing defense methods for detecting both baseline attacks (attacks that existing defense methods have taken into consideration) and new attacks (attacks that can bypass existing defense methods) (addressing Challenge 2);
- Guided by the theoretical foundations of IBD, we further accelerate IBD by simply calculating the summation of the logits of several input examples from different categories. Therefore, defenders can detect malicious models without additional information about the parameters and structures of the target model (addressing Challenge 3).
2. Related Work
2.1. Deep Backdoor Attack
2.2. Deep Backdoor Defense
2.3. Shapley Value
3. Methodology
3.1. Problem Formulation
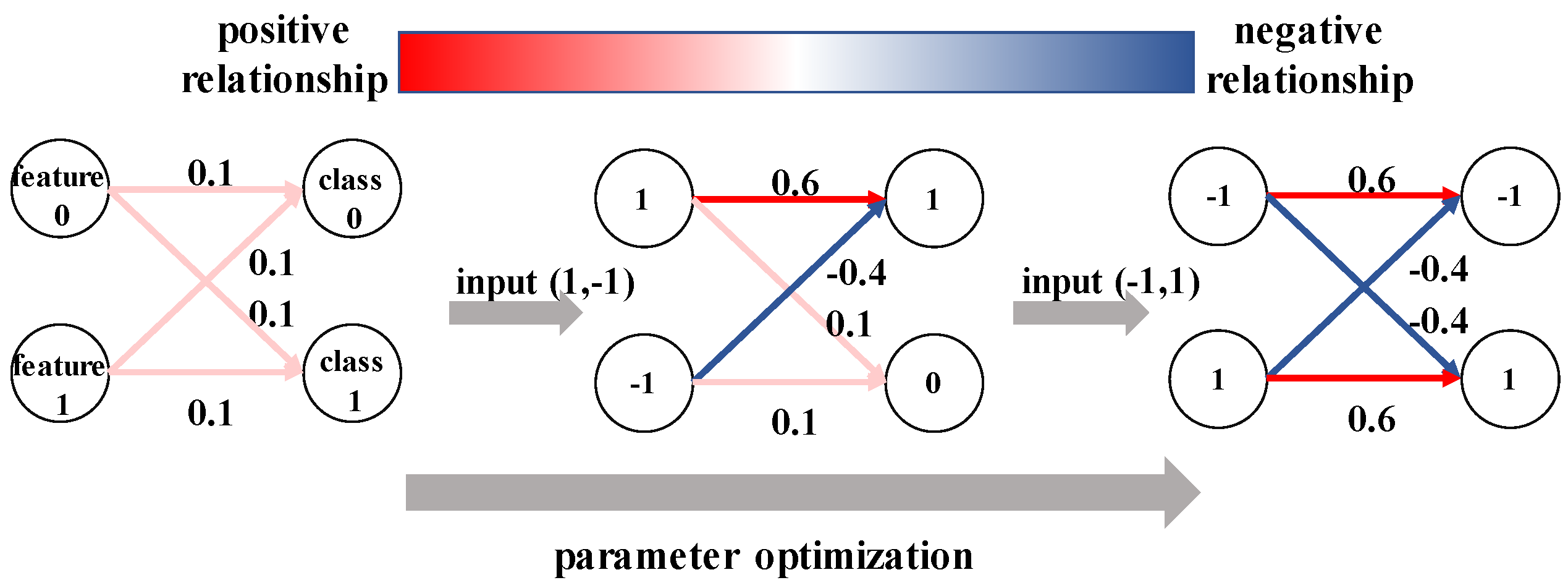
3.2. Multivariate Interactions of Benign and Backdoor Models
3.3. A Simple Approach for Backdoor Model Detection
- Transferable. Most existing backdoor-detection methods have some assumptions about potential attack methods (e.g., Neural Cleanse [12] requires the trigger to be smaller than the natural features). Attackers can change the form of triggers guided by these assumptions, which makes existing detection methods non-transferable to new attacks. IBD does not require defenders to have prior knowledge about the potential attacks. Therefore, it is transferable to detect different types of backdoor attacks, including some state-of-the-art attack methods that can bypass most existing defense methods [15]. Meanwhile, it is difficult for attackers to manipulate the multivariate interactions of features in the target model; thus, our methods are still robust against defense-known attacks;
- Cost-Friendly. Existing backdoor-detection methods often require defenders to collect a set of reliable test examples or to perform thousands of forward–backward steps on the target model, which leads to both high preparation costs and time costs. Compared with existing methods, our method is cost-friendly, since it only requires several forward processes of the classification model and does not require the test examples to be trustful (without triggers).
4. Experimental Results
4.1. Defense Setting
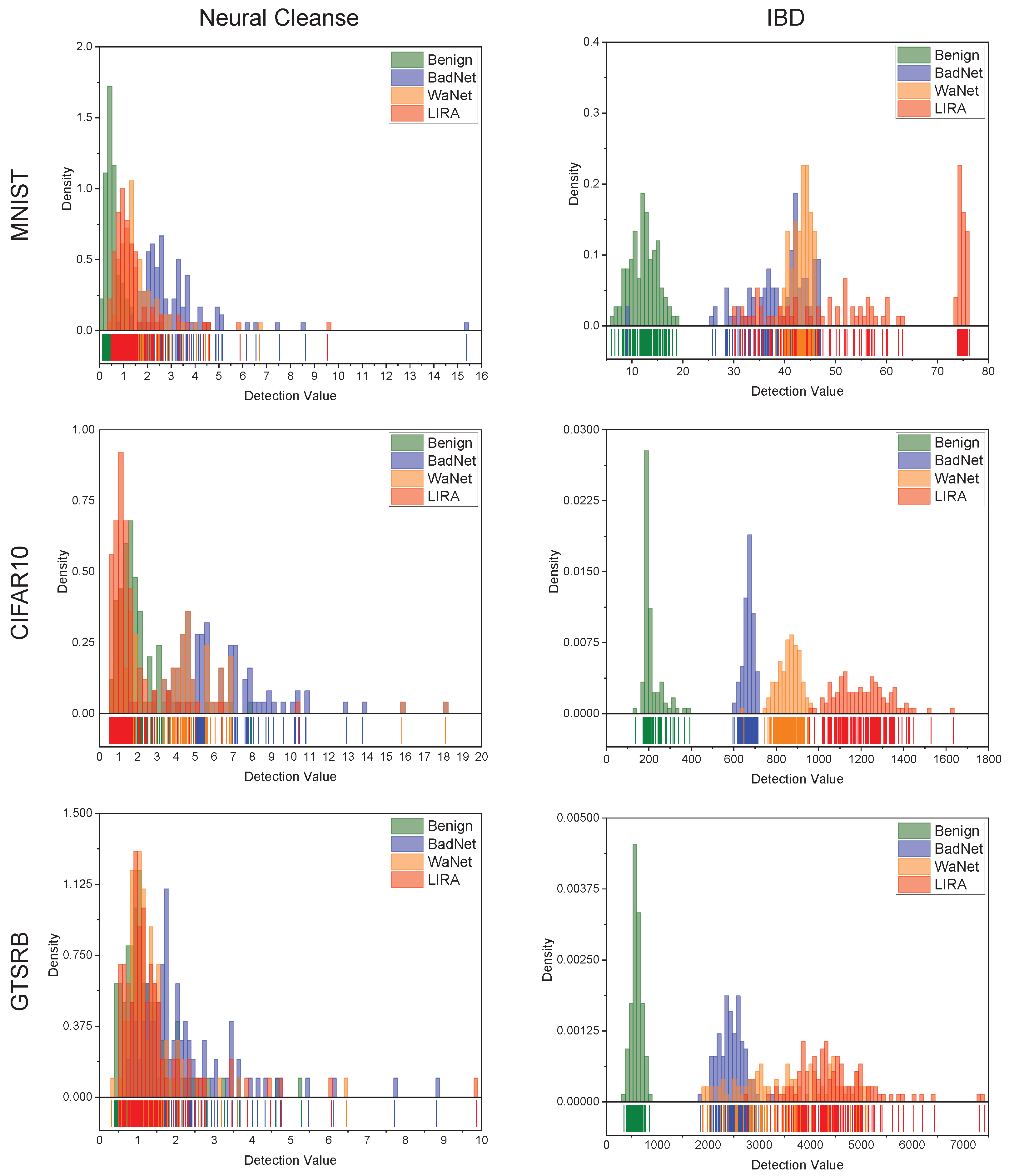
4.2. Evaluate Interpretable Method
4.3. Performance Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| IBD | Interpretable Backdoor-Detection Method |
| LIRA | Learnable, Imperceptible, and Robust Backdoor Attacks |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
References
- Kang, Y.; Yamaguchi, K.; Naito, T.; Ninomiya, Y. Multiband image segmentation and object recognition for understanding road scenes. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1423–1433. [Google Scholar] [CrossRef]
- Al-Qizwini, M.; Barjasteh, I.; Al-Qassab, H.; Radha, H. Deep learning algorithm for autonomous driving using googlenet. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 89–96. [Google Scholar]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Vazquez-Fernandez, E.; Gonzalez-Jimenez, D. Face recognition for authentication on mobile devices. Image Vis. Comput. 2016, 55, 31–33. [Google Scholar] [CrossRef]
- Zulfiqar, M.; Syed, F.; Khan, M.J.; Khurshid, K. Deep face recognition for biometric authentication. In Proceedings of the IEEE 2019 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Swat, Pakistan, 24–25 July 2019; pp. 1–6. [Google Scholar]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. BadNets: Evaluating Backdooring Attacks on Deep Neural Networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Tang, R.; Du, M.; Liu, N.; Yang, F.; Hu, X. An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; ACM: New York, NY, USA, 2020; pp. 218–228. [Google Scholar]
- Latif, S.; e Huma, Z.; Jamal, S.S.; Ahmed, F.; Ahmad, J.; Zahid, A.; Dashtipour, K.; Aftab, M.U.; Ahmad, M.; Abbasi, Q.H. Intrusion detection framework for the internet of things using a dense random neural network. IEEE Trans. Ind. Inform. 2021, 6435–6444. [Google Scholar] [CrossRef]
- Oluwasanmi, A.; Aftab, M.U.; Baagyere, E.; Qin, Z.; Ahmad, M.; Mazzara, M. Attention Autoencoder for Generative Latent Representational Learning in Anomaly Detection. Sensors 2021, 22, 123. [Google Scholar] [CrossRef] [PubMed]
- Assefa, A.A.; Tian, W.; Acheampong, K.N.; Aftab, M.U.; Ahmad, M. Small-scale and occluded pedestrian detection using multi mapping feature extraction function and Modified Soft-NMS. Comput. Intell. Neurosci. 2022, 2022, 9325803. [Google Scholar] [CrossRef] [PubMed]
- Oyama, T.; Okura, S.; Yoshida, K.; Fujino, T. Backdoor Attack on Deep Neural Networks Triggered by Fault Injection Attack on Image Sensor Interface. In Proceedings of the 5th Workshop on Attacks and Solutions in Hardware Security, Virtual Event, 19 November 2021; ACM: New York, NY, USA, 2021; pp. 63–72. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar]
- Gao, Y.; Xu, C.; Wang, D.; Chen, S.; Ranasinghe, D.C.; Nepal, S. STRIP: A defence against trojan attacks on deep neural networks. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; ACM: New York, NY, USA, 2019; pp. 113–125. [Google Scholar]
- Kolouri, S.; Saha, A.; Pirsiavash, H.; Hoffmann, H. Universal litmus patterns: Revealing backdoor attacks in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 301–310. [Google Scholar]
- Nguyen, T.A.; Tran, A.T. WaNet-Imperceptible Warping-based Backdoor Attack. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Doan, K.; Lao, Y.; Zhao, W.; Li, P. LIRA: Learnable, Imperceptible and Robust Backdoor Attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11946–11956. [Google Scholar]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Rakin, A.S.; He, Z.; Fan, D. TBT: Targeted Neural Network Attack With Bit Trojan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 13195–13204. [Google Scholar]
- Kim, Y.; Daly, R.; Kim, J.S.; Fallin, C.; Lee, J.; Lee, D.; Wilkerson, C.; Lai, K.; Mutlu, O. Flipping bits in memory without accessing them: An experimental study of DRAM disturbance errors. In Proceedings of the International Symposium on Computer Architecture, Minneapolis, MN, USA, 14–18 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 361–372. [Google Scholar]
- Li, Y.; Jiang, Y.; Li, Z.; Xia, S.T. Backdoor learning: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Erion, G.G.; Lee, S. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Sundararajan, M.; Dhamdhere, K.; Agarwal, A. The Shapley Taylor Interaction Index. Proc. Mach. Learn. Res. 2020, 119, 9259–9268. [Google Scholar]
- Zhang, H.; Xie, Y.; Zheng, L.; Zhang, D.; Zhang, Q. Interpreting Multivariate Shapley Interactions in DNNs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2021; AAAI Press: Menlo Park, CA, USA, 2021; pp. 10877–10886. [Google Scholar]
- Kuhn, H.W.; Tucker, A.W. Contributions to the Theory of Games; Princeton University Press: Princeton, NJ, USA, 1953; Volume 2. [Google Scholar]
- Roth, A.E. The Shapley Value: Essays in Honor of Lloyd S. Shapley; Cambridge University Press: Princeton, NJ, USA, 1988. [Google Scholar]
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Tront, Toronto, ON, Canada, 2009. [Google Scholar]
- Houben, S.; Stallkamp, J.; Salmen, J.; Schlipsing, M.; Igel, C. Detection of Traffic Signs in Real-World Images: The German Traffic Sign Detection Benchmark. In Proceedings of the International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013. Number 1288. [Google Scholar]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-pruning: Defending against backdooring attacks on deep neural networks. In Proceedings of the International Symposium on Research in Attacks, Intrusions, and Defenses, Crete, Greece, 10–12 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 273–294. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Attack | Mean Relationship Value | |
|---|---|---|---|
| Target Class | Benign Classes | ||
| MNIST | Benign | - | 32.7 |
| BadNet | 85.7 | 33.2 | |
| WaNet | 114.8 | 32.9 | |
| LIRA | 122.5 | 33.5 | |
| CIFAR-10 | Benign | - | 48.6 |
| BadNet | 108.3 | 46.5 | |
| WaNet | 182.4 | 50.2 | |
| LIRA | 212.9 | 49.5 | |
| GTSRB | Benign | - | 43.7 |
| BadNet | 93.8 | 45.8 | |
| WaNet | 149.2 | 44.7 | |
| LIRA | 196.5 | 46.0 | |
| Dataset | Clean Accuracy | BadNet | WaNet | LIRA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Attack Success Rate | Neural Cleanse | IBD | Attack Success Rate | Neural Cleanse | IBD | Attack Success Rate | Neural Cleanse | IBD | ||
| MNIST | 0.99 | 0.99 | 0.33 | 0.98 | 0.99 | 0.24 | 1 | 0.99 | 0.21 | 1 |
| CIFAR10 | 0.84 | 0.98 | 0.25 | 1 | 0.98 | 0.17 | 1 | 0.98 | 0.16 | 1 |
| GTSRB | 0.99 | 0.98 | 0.27 | 1 | 0.99 | 0.18 | 1 | 0.99 | 0.15 | 1 |
| Dataset | Model | Time Cost (s) | |
|---|---|---|---|
| Neural Cleanse | IBD | ||
| MNIST | VGG-like | 180 | 0.1 |
| CIFAR10 | ResNet18 | 240 | 0.15 |
| GTSRB | ResNet18 | 1800 | 0.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Liu, X.; Ding, K.; Xin, B. IBD: An Interpretable Backdoor-Detection Method via Multivariate Interactions. Sensors 2022, 22, 8697. https://doi.org/10.3390/s22228697
Xu Y, Liu X, Ding K, Xin B. IBD: An Interpretable Backdoor-Detection Method via Multivariate Interactions. Sensors. 2022; 22(22):8697. https://doi.org/10.3390/s22228697
Chicago/Turabian StyleXu, Yixiao, Xiaolei Liu, Kangyi Ding, and Bangzhou Xin. 2022. "IBD: An Interpretable Backdoor-Detection Method via Multivariate Interactions" Sensors 22, no. 22: 8697. https://doi.org/10.3390/s22228697
APA StyleXu, Y., Liu, X., Ding, K., & Xin, B. (2022). IBD: An Interpretable Backdoor-Detection Method via Multivariate Interactions. Sensors, 22(22), 8697. https://doi.org/10.3390/s22228697