
Focal DETR: Target-Aware Token Design for Transformer-Based Object Detection


Abstract
:1. Introduction
1.1. Two-Stage Object Detection
1.2. One-Stage Object Detection
1.3. Transformer-Based Object Detection
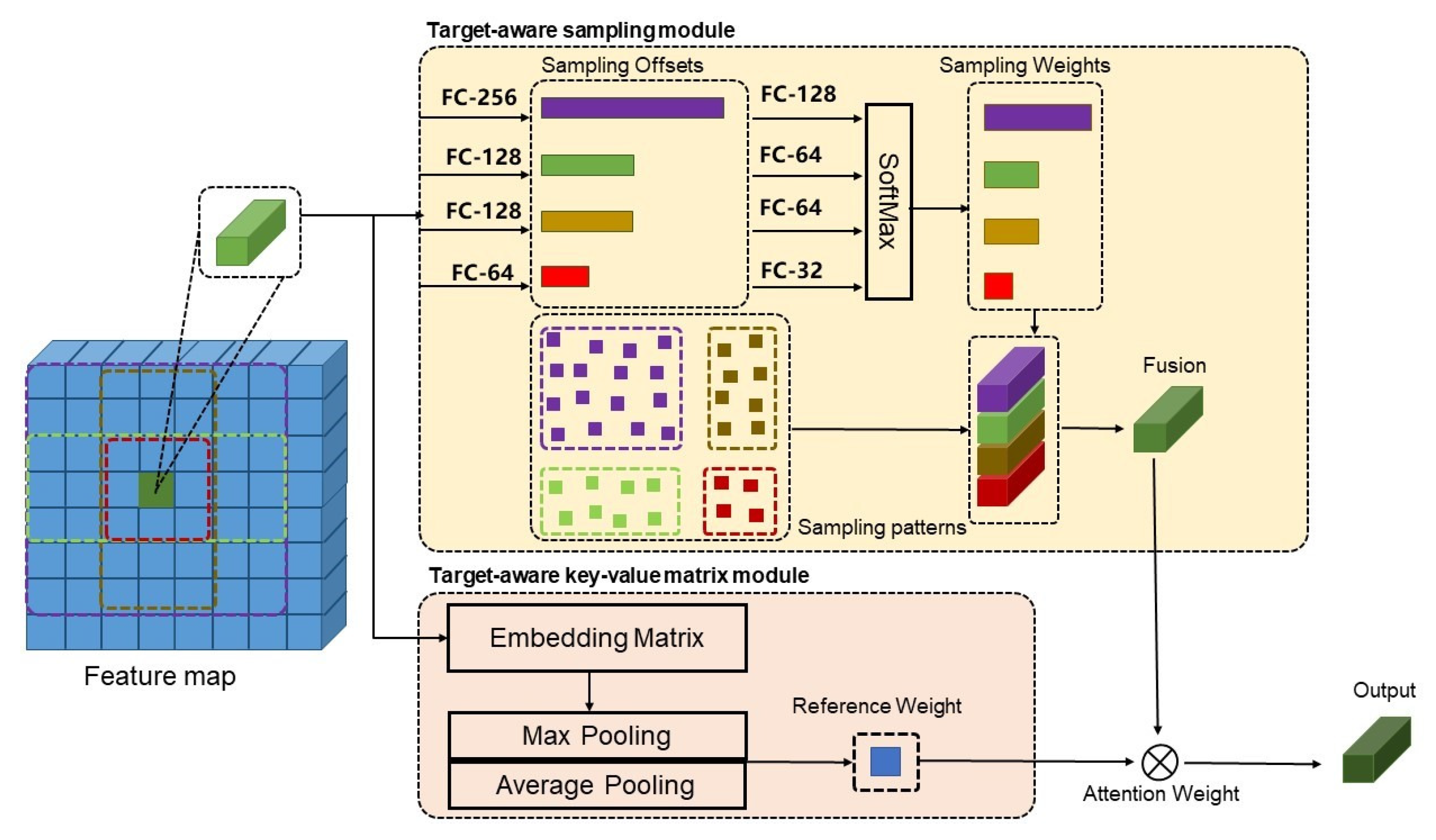
- A target-aware sampling method is proposed to encourage the sampling patterns to converge inside the target region and obtain its representative encoded features. It consists of a set of multi-pattern parallel sampling strategies. More specifically, the small sampling pattern extracts the detailed features, the large sampling pattern obtains the larger receptive field features, and the vertical–horizontal sampling pattern approximates the target boundary. These are further fused together to strengthen the connection between the same targets and mitigate target attribute diffusion.
- A target-aware key-value matrix is proposed to be directly weighted on the feature map to reduce the interference of non-target regions. For that, we propose a learnable embedding matrix of the relationship between the target and the non-target to replace the original key-value matrix in DETR to calculate the self-attention weights.
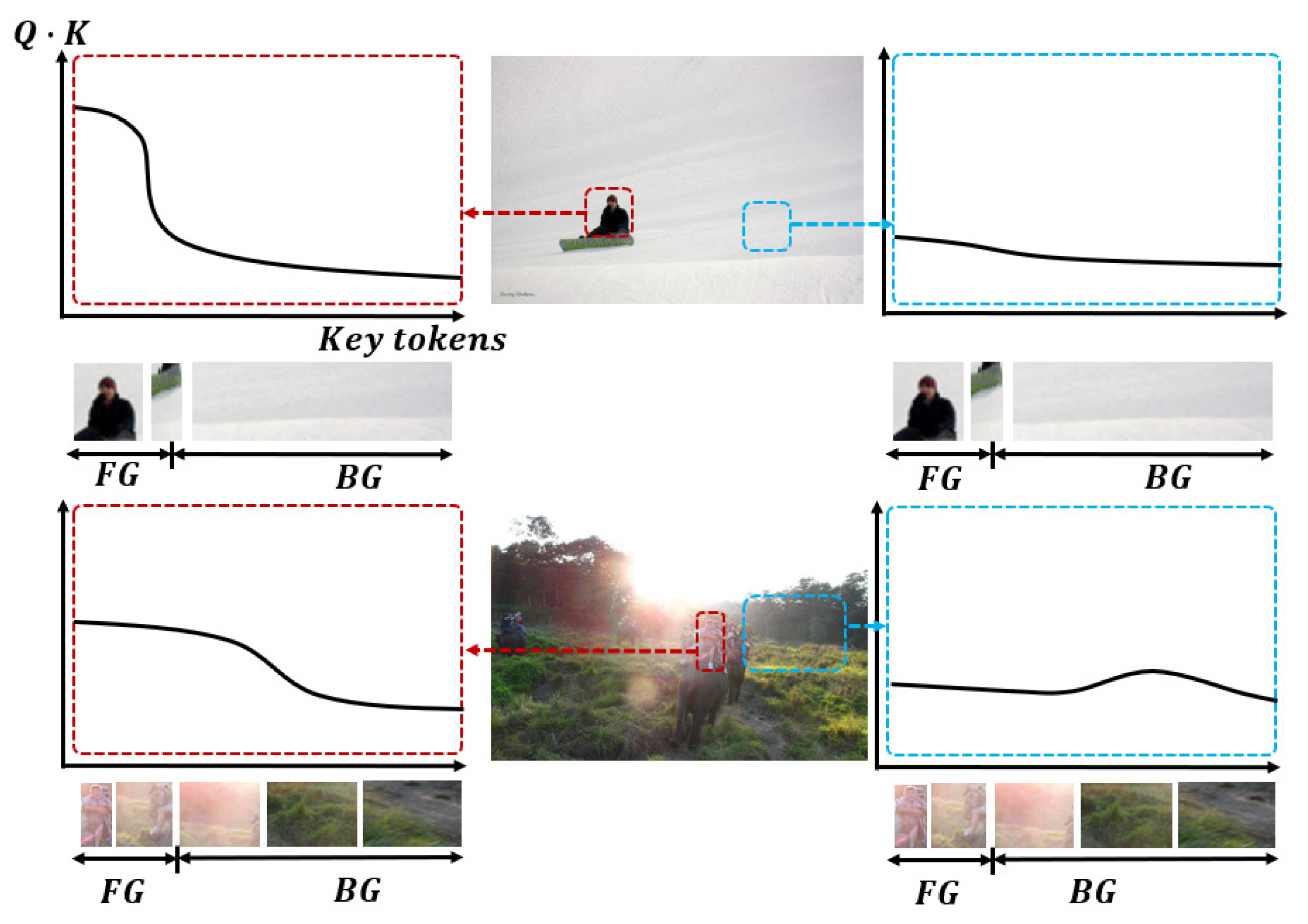
2. Motivation
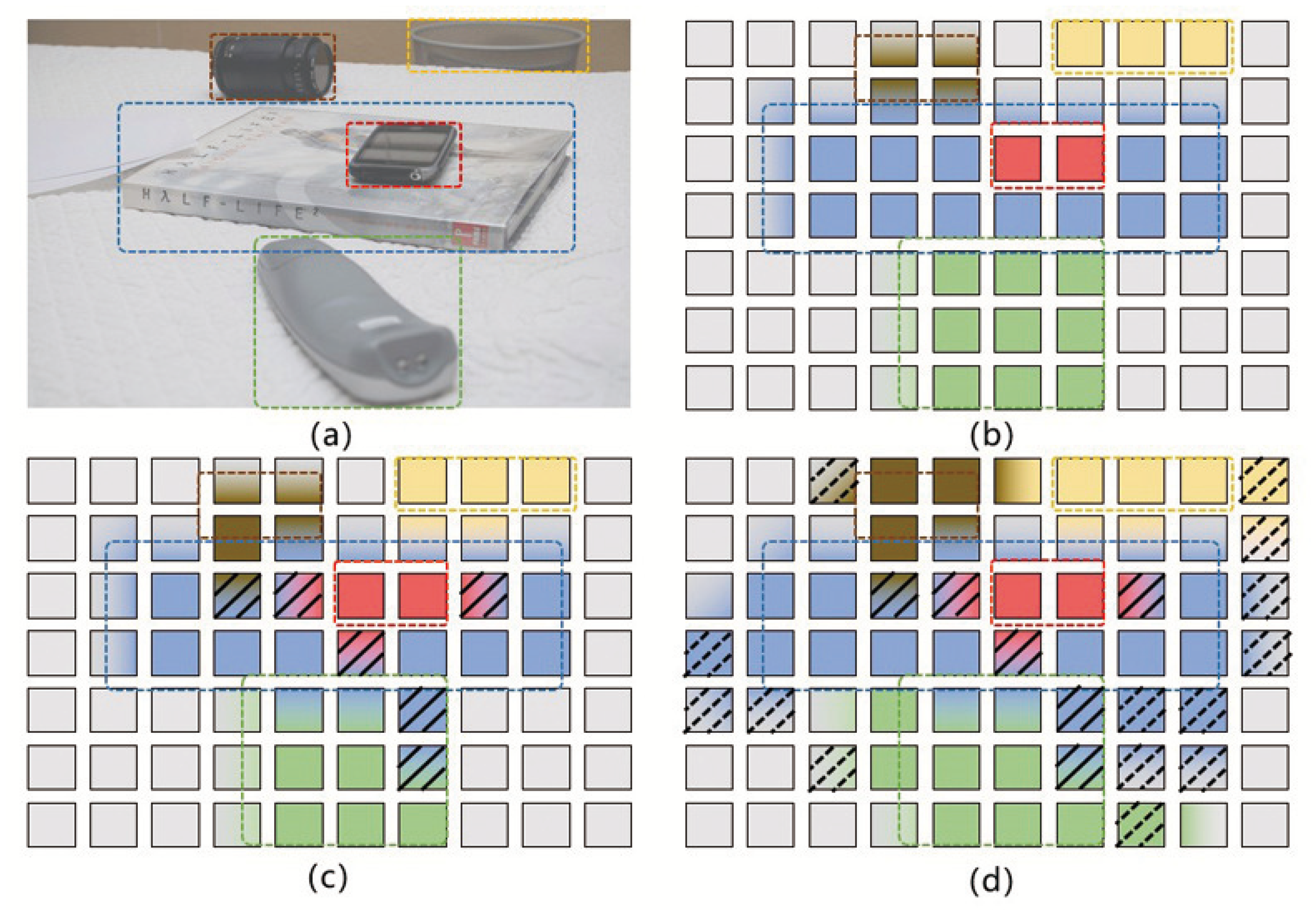
- Firstly, before attention encoding, each point on the feature map is the feature extracted by the convolution kernel in a specific region of the original image, regardless of points outside the region. Each dotted box represents a specific object, all feature blocks are not related, and there is no target attribute diffusion phenomenon or background interference.
- Secondly, the feature map should have clear object information, as shown in Figure 1b; the feature block containing the target area should only be associated with other areas of the same object (each target has a different color, red means mobile phone, brown means camera lens). When decoding the object query, the position and bounding box of the object can be obtained according to the associated feature block. The feature blocks of the background area are not associated with the target area, carry no object information, and will not cause the diffusion of target attributes or background interference.
- Thirdly, due to the mechanism of attention weighting calculation, some sampling points of a certain target will fall in the region that does not belong to this target, this part of the sampling weight in (4) is expressed as . As shown in Figure 1c, the red region representing a mobile phone’s attribute diffuse to the blue region representing a book; the book’s attribute also diffuse to the lens region (brown) and the razor region (green). This is the phenomenon of target attribute diffusion (tokens highlighted with slashes in the figure). If the encoded feature token contains more attributes that do not belong to the same target, the target-aware ability will be reduced. It is difficult for object queries to establish effective associations with such weakly target-aware tokens, ultimately leading to false or missed detections.
- Fourthly, the background region also contains target information; this part of attention weight is expressed as . As shown in Figure 1d, the gray blocks are the background tokens, but some of them present different colors due to the doping target information (tokens highlighted with dotted lines in the figure). In the decoding process, object query will also confuse such tokens with target tokens, which affects the accuracy of detected object boundaries. This is the phenomenon of background interference.
3. Method
3.1. Proposed Target-Aware Sampling
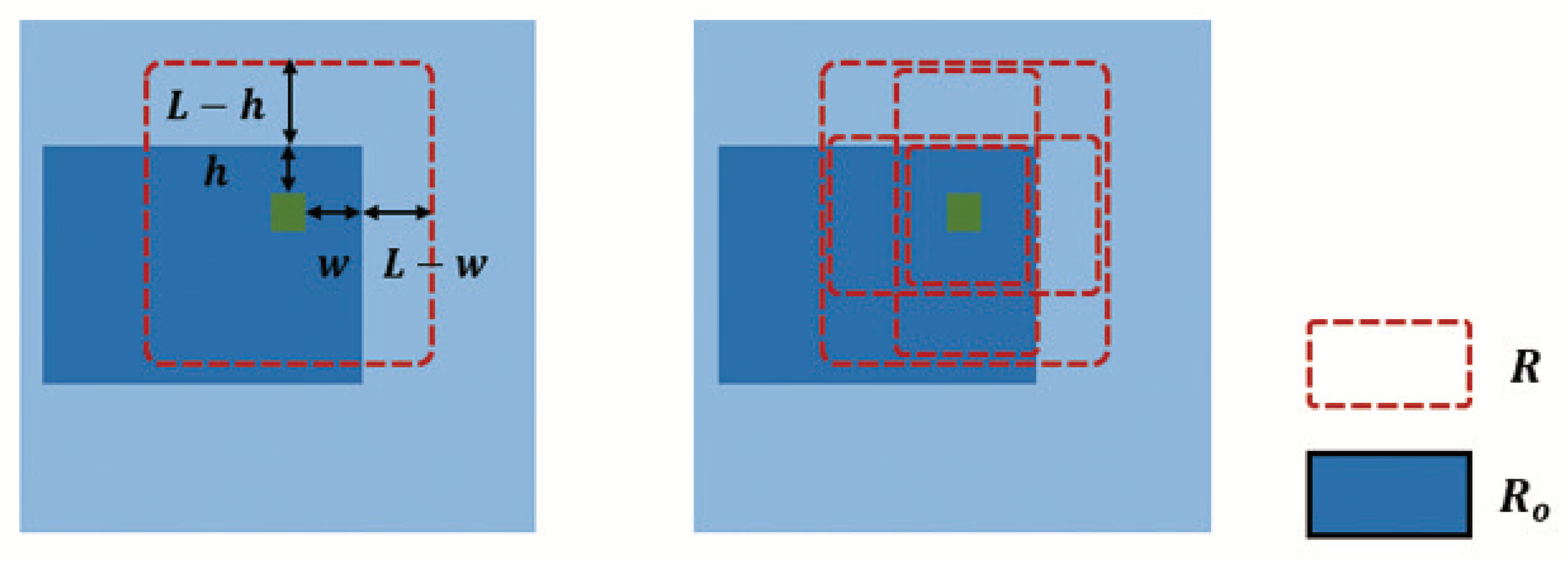
- Large sampling pattern. The sampling side length is , which is consistent with the initial sampling layer. This is used to obtain larger receptive-field features and maintain the network’s grasp and perception of the integrity of the target.
- Small sampling pattern. The sampling side length is . Compared with the large pattern with as the sampling side length, using a smaller sampling side length means less misallocated attention. Focusing on features near the reference point makes it easier to converge inside the object, suppressing the attention weights imposed outside the target.
- Vertical and horizontal sampling patterns. This consists of two sampling layers, the length of the sampling frame is and , respectively, the region is and , which can adapt the contour of objects to arbitrary shapes. Our sampling strategy takes the scales and directions into account; for a person, the vertical mode is more relevant and for a vehicle frame, the horizontal mode is dominant.
3.2. Proposed Target-Aware Key-Value Matrix
3.3. Proposed Focal DETR Structure
4. Experimental Results
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Comparison with Other Object-Detection Methods
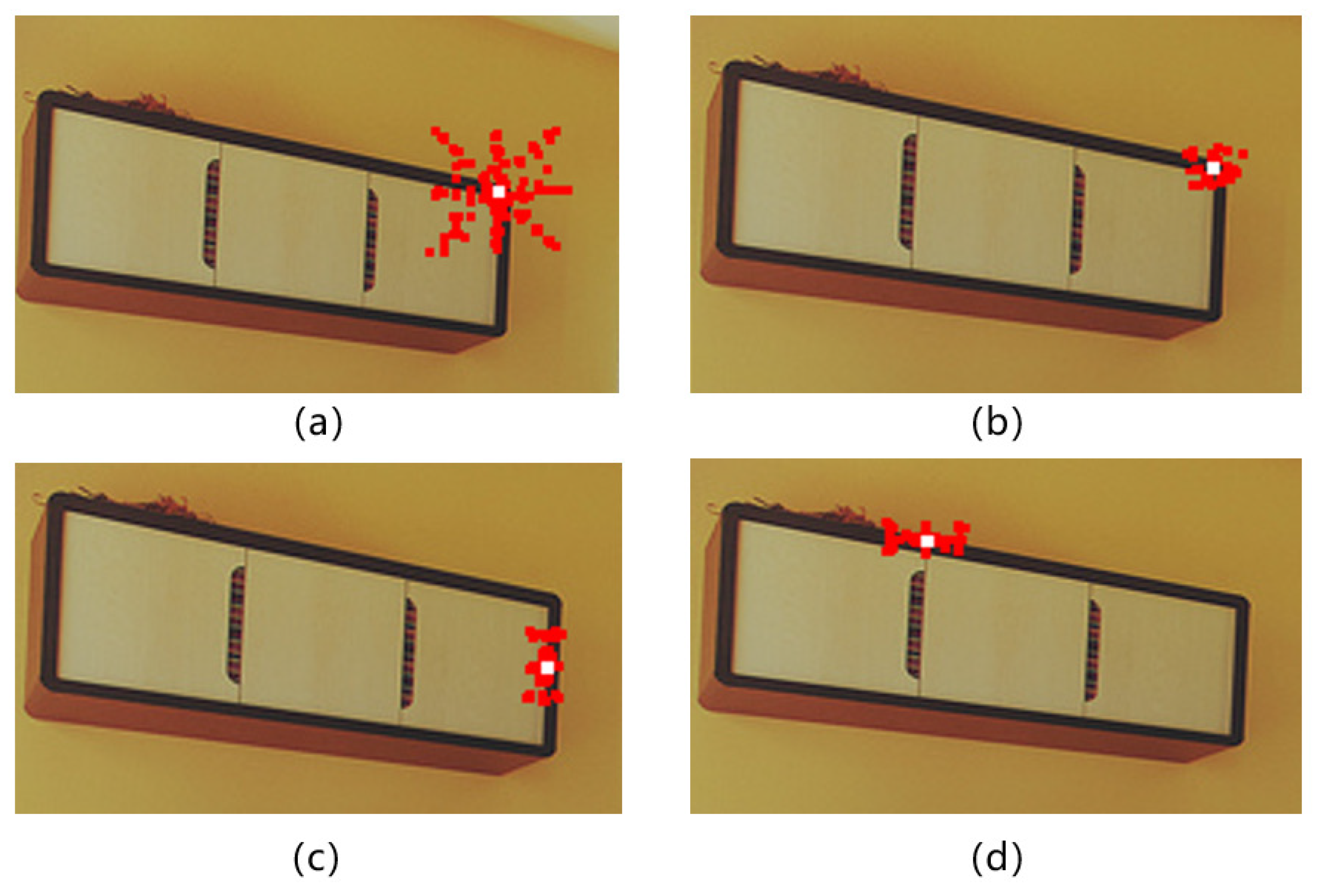
4.4. Evaluation of Various Sampling Patterns
4.5. Evaluation of Various Fusion Methods
4.6. Evaluation of Target-Aware Matrix
4.7. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for fast training convergence. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3651–3660. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor DETR: Query Design for Transformer-Based Object Detection. arXiv 2021, arXiv:2109.07107. [Google Scholar]
- Yao, Z.; Ai, J.; Li, B.; Zhang, C. Efficient DETR: Improving end-to-end object detector with dense prior. arXiv 2021, arXiv:2104.01318. [Google Scholar]
- Lin, J.; Mao, X.; Chen, Y.; Xu, L.; He, Y.; Xue, H. D2ETR: Decoder-Only DETR with Computationally Efficient Cross-Scale Attention. arXiv 2022, arXiv:2203.00860. [Google Scholar]
- Chen, Z.; Zhang, J.; Tao, D. Recurrent glimpse-based decoder for detection with transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5260–5269. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 14454–14463. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6399–6408. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K.M. Rethinking transformer-based set prediction for object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3611–3620. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. Up-DETR: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1601–1610. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ||||||
|---|---|---|---|---|---|---|
| Faster-RCNN [3] | 42.0 | 62.1 | 45.5 | 26.6 | 45.4 | 53.4 |
| RetinaNet [10] | 40.8 | 61.1 | 44.1 | 24.1 | 44.2 | 51.2 |
| FCOS [27] | 41.0 | 59.8 | 44.1 | 26.2 | 44.6 | 52.2 |
| TSP-FCOS [28] | 43.1 | 62.3 | 47.0 | 26.6 | 46.8 | 55.9 |
| TSP-RCNN [28] | 43.8 | 63.3 | 48.3 | 28.6 | 46.9 | 55.7 |
| DETR [11] | 42.0 | 62.4 | 44.2 | 20.5 | 45.8 | 61.1 |
| UP-DETR [29] | 42.8 | 63.0 | 45.3 | 20.8 | 47.1 | 61.7 |
| Anchor-DETR [15] | 42.1 | 63.1 | 44.9 | 22.3 | 46.2 | 60.0 |
| Conditional-DETR [14] | 43.0 | 64.0 | 45.7 | 22.7 | 46.7 | 61.5 |
| Deformable-DETR [12] | 43.8 | 62.6 | 47.7 | 26.4 | 47.1 | 58.0 |
| Ours | 44.7 | 63.9 | 48.5 | 27.0 | 47.5 | 59.1 |
| Pattern | ||||||
|---|---|---|---|---|---|---|
| Small | 42.9 | 62.4 | 46.9 | 25.7 | 46.5 | 55.8 |
| Rectangle-L | 43.6 | 63.1 | 47.7 | 26.2 | 46.7 | 57.4 |
| Rectangle-W | 43.4 | 63.1 | 47.2 | 26.0 | 46.8 | 57.3 |
| Large | 43.8 | 63.3 | 47.5 | 26.3 | 47.1 | 57.7 |
| Fusion Method | ||||||
|---|---|---|---|---|---|---|
| Adding | 44.7 | 63.9 | 48.5 | 27.0 | 47.5 | 59.1 |
| Splicing | 42.2 | 62.0 | 46.0 | 25.8 | 45.7 | 55.5 |
| Pooling | 43.2 | 62.7 | 47.1 | 25.8 | 46.2 | 57.3 |
| Target-Aware Sampling | Target-Aware Key-Value Matrix | ||||||
|---|---|---|---|---|---|---|---|
| - | - | 43.4 | 62.6 | 47.5 | 26.3 | 46.9 | 57.9 |
| √ | - | 43.7 | 63.2 | 47.3 | 25.8 | 46.6 | 58.3 |
| - | √ | 43.8 | 63.3 | 47.5 | 26.3 | 47.1 | 57.7 |
| √ | √ | 44.7 | 63.9 | 48.5 | 27.0 | 47.5 | 59.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, T.; Zhang, Z.; Tian, J.; Ma, L. Focal DETR: Target-Aware Token Design for Transformer-Based Object Detection. Sensors 2022, 22, 8686. https://doi.org/10.3390/s22228686
Xie T, Zhang Z, Tian J, Ma L. Focal DETR: Target-Aware Token Design for Transformer-Based Object Detection. Sensors. 2022; 22(22):8686. https://doi.org/10.3390/s22228686
Chicago/Turabian StyleXie, Tianming, Zhonghao Zhang, Jing Tian, and Lihong Ma. 2022. "Focal DETR: Target-Aware Token Design for Transformer-Based Object Detection" Sensors 22, no. 22: 8686. https://doi.org/10.3390/s22228686
APA StyleXie, T., Zhang, Z., Tian, J., & Ma, L. (2022). Focal DETR: Target-Aware Token Design for Transformer-Based Object Detection. Sensors, 22(22), 8686. https://doi.org/10.3390/s22228686