
Efficient Informative Path Planning via Normalized Utility in Unknown Environments Exploration


Abstract
1. Introduction
- An Efficient information richness judgment from posterior map entropy decline value is proposed, which formulates the potential unknown detection volume for navigating robots to visit unknown space efficiently.
- An informative path utility calculation method that normalizes information measurements by path distance is proposed; the normalized utility leads to fewer local optimums.
- The proposed method has been extensively validated in two realistic simulation environments.
2. Releated Work
3. Problem Statement
4. Method
4.1. System Overview
4.2. Mapping
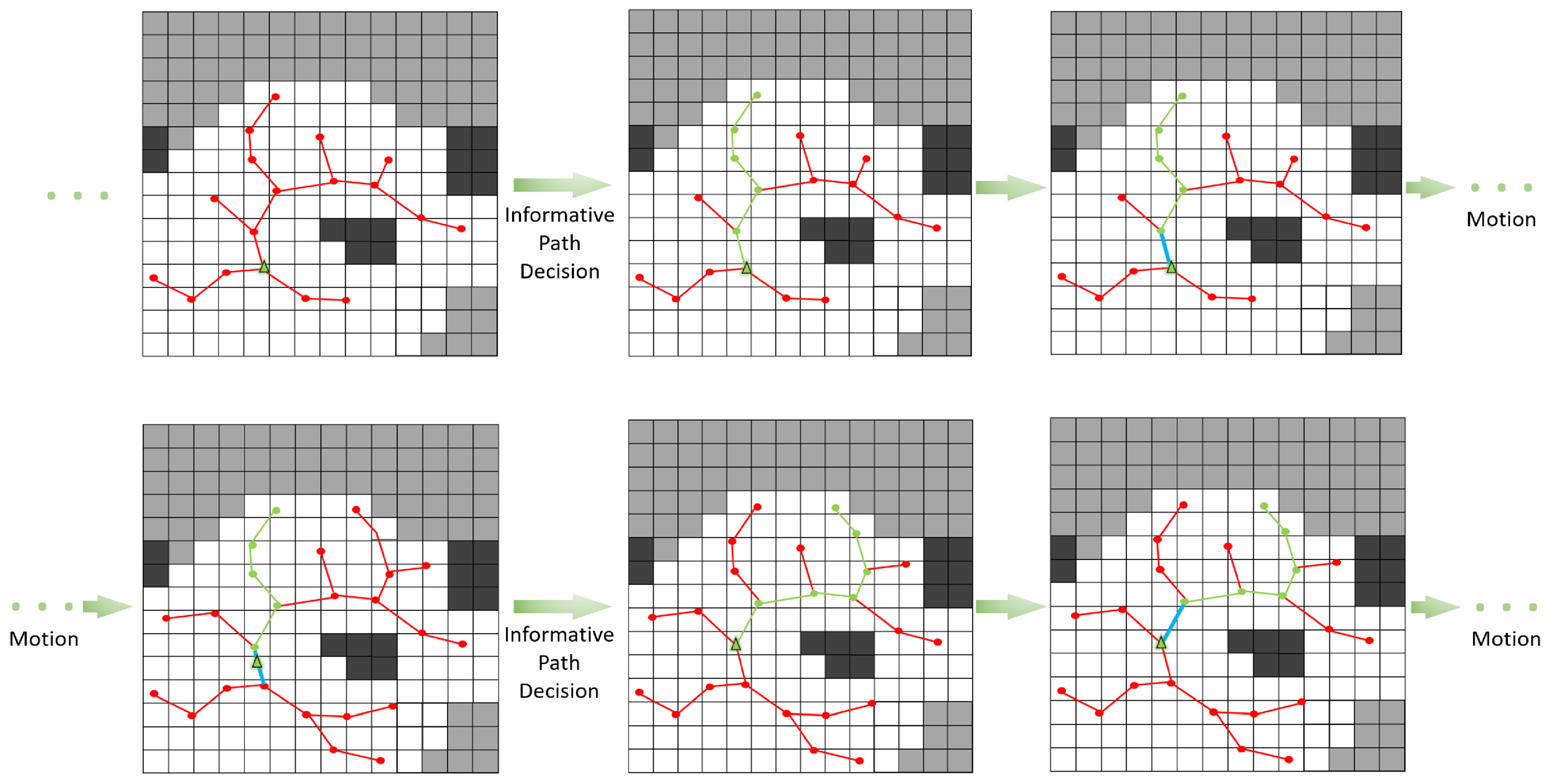
4.3. Topological Road Map
| Algorithm 1 Road Map Extension |
|
4.4. Informative Path Decision
4.5. Continuous Trajectory
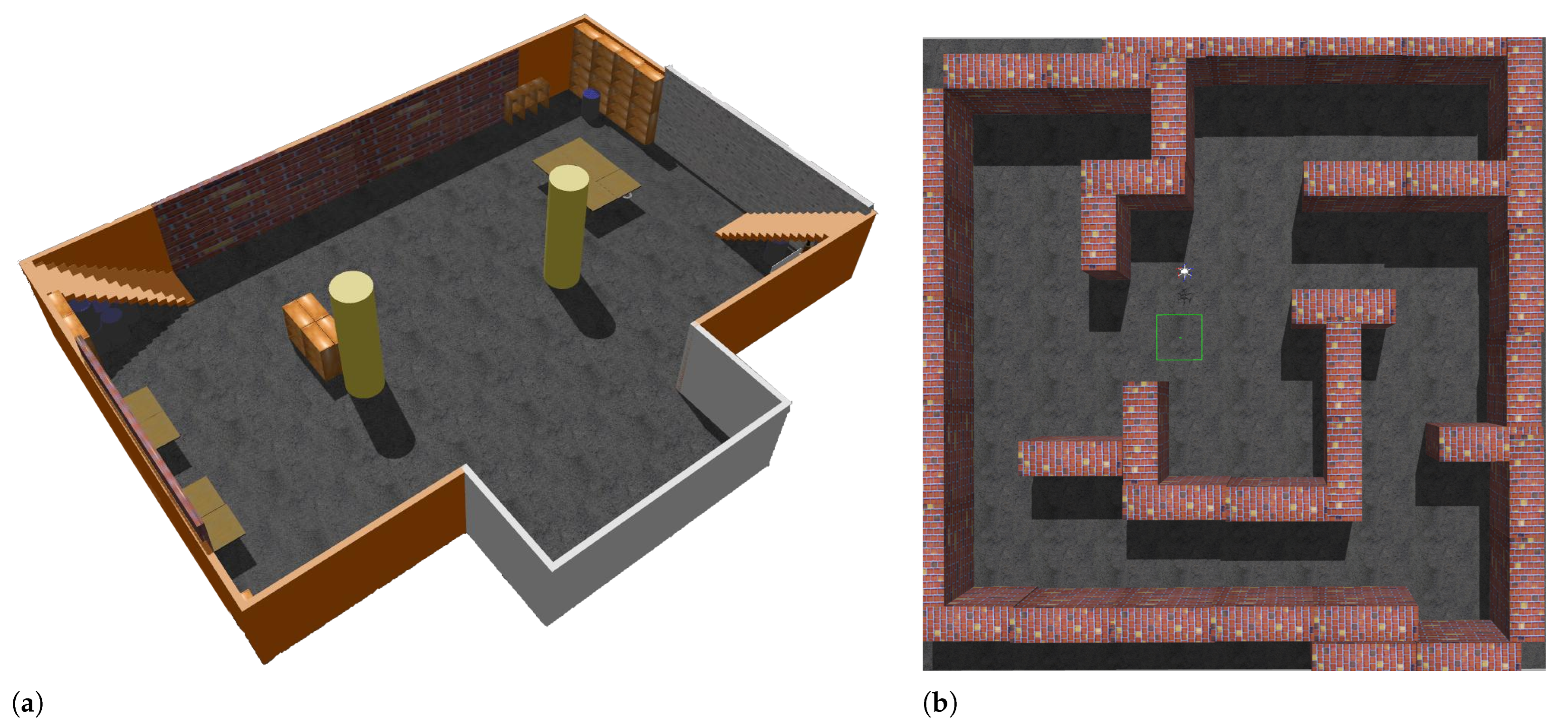
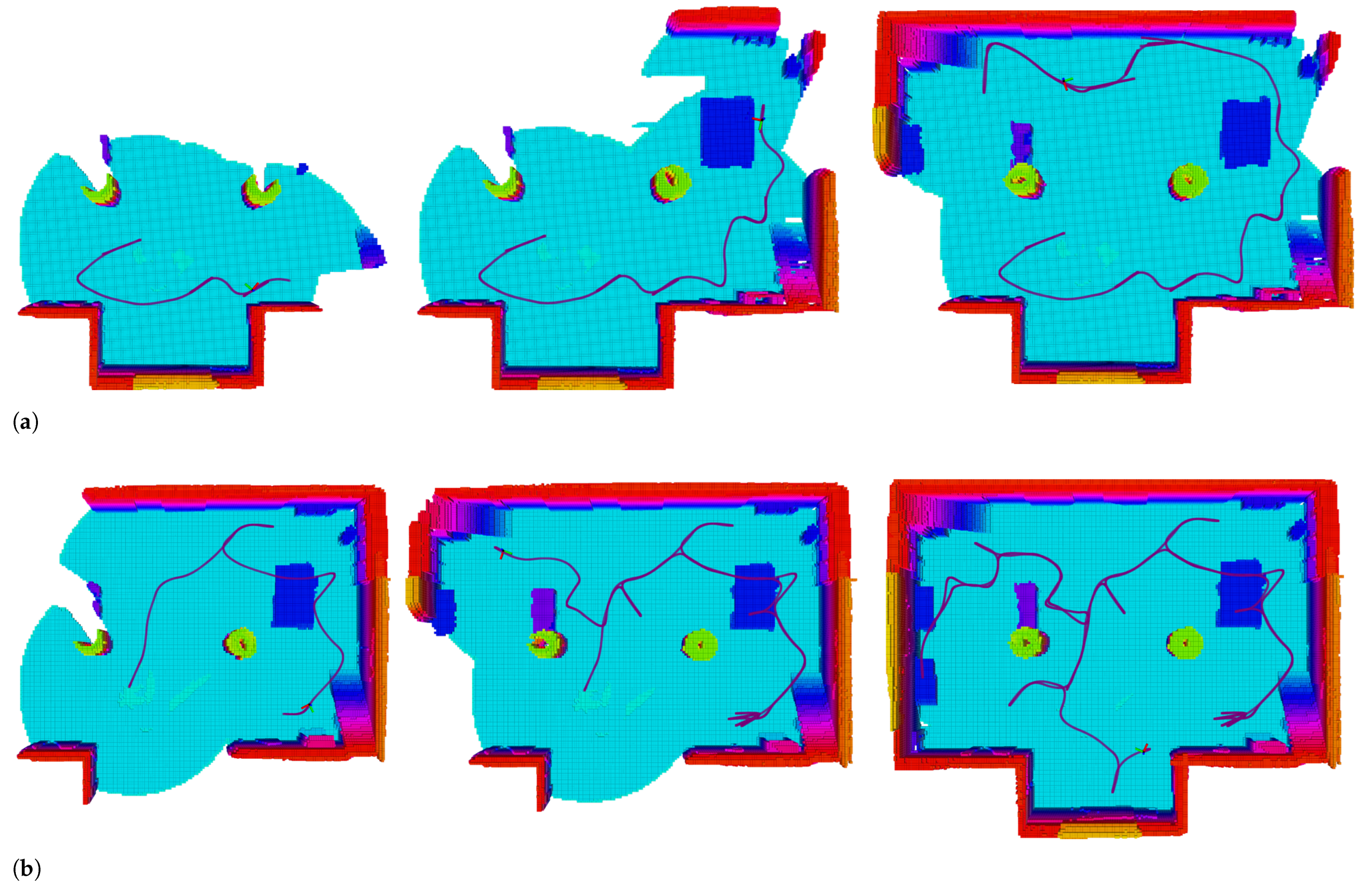
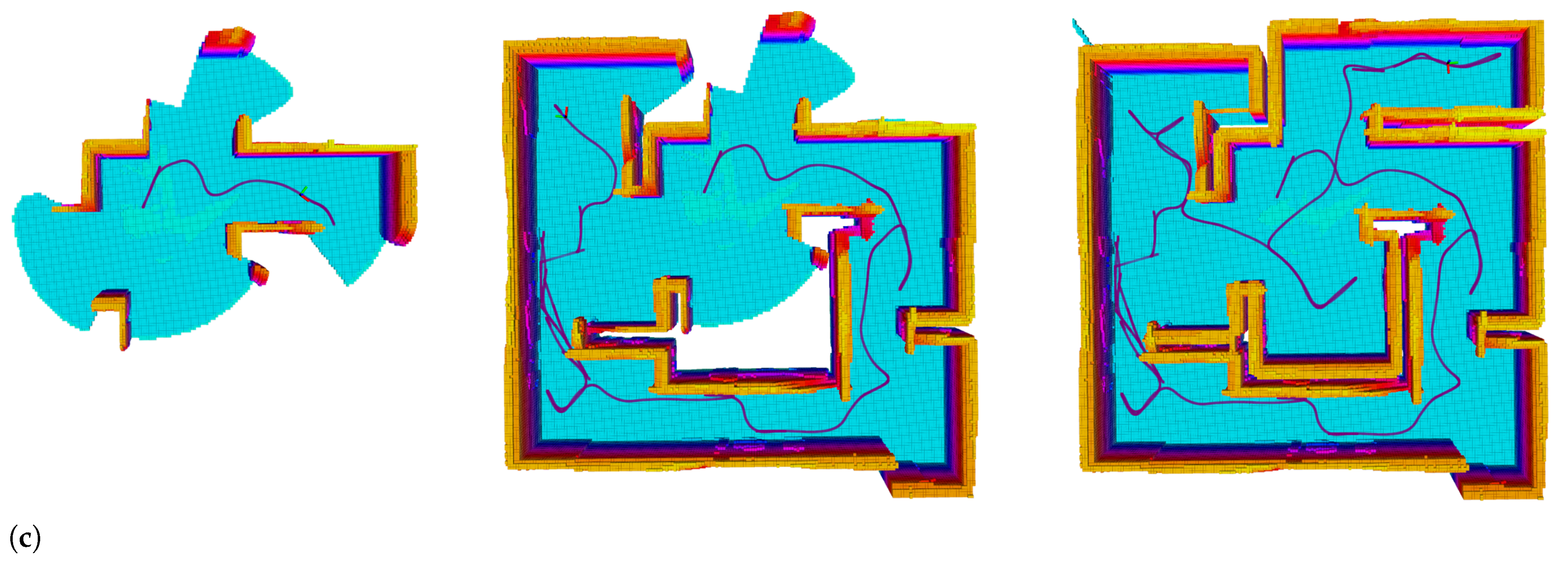
5. Experiments
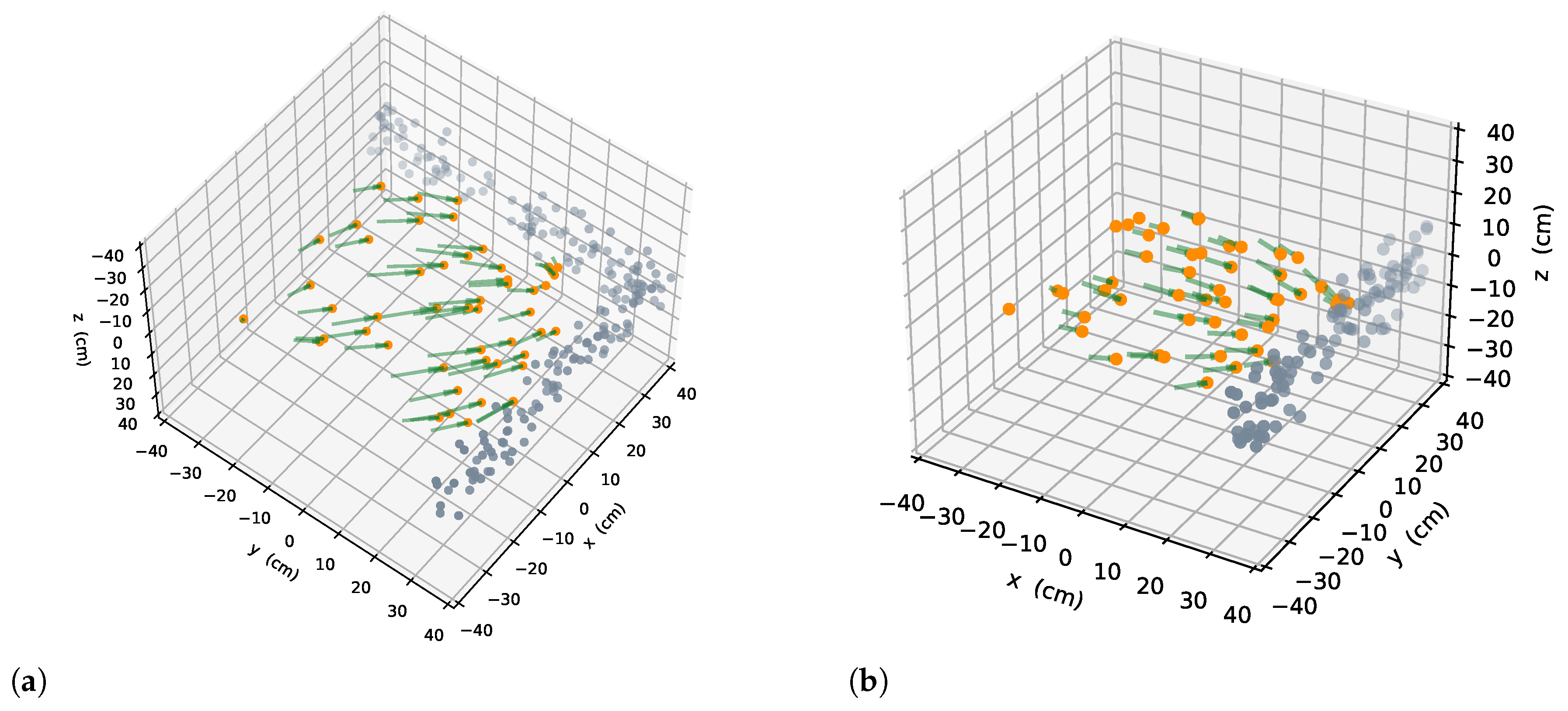
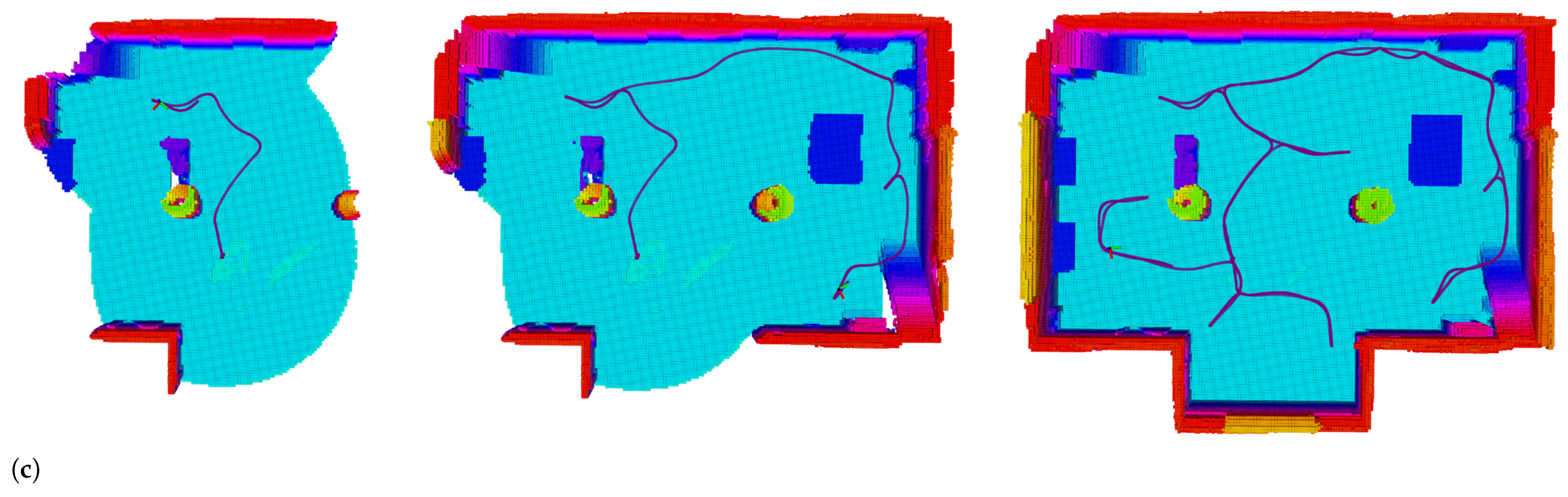
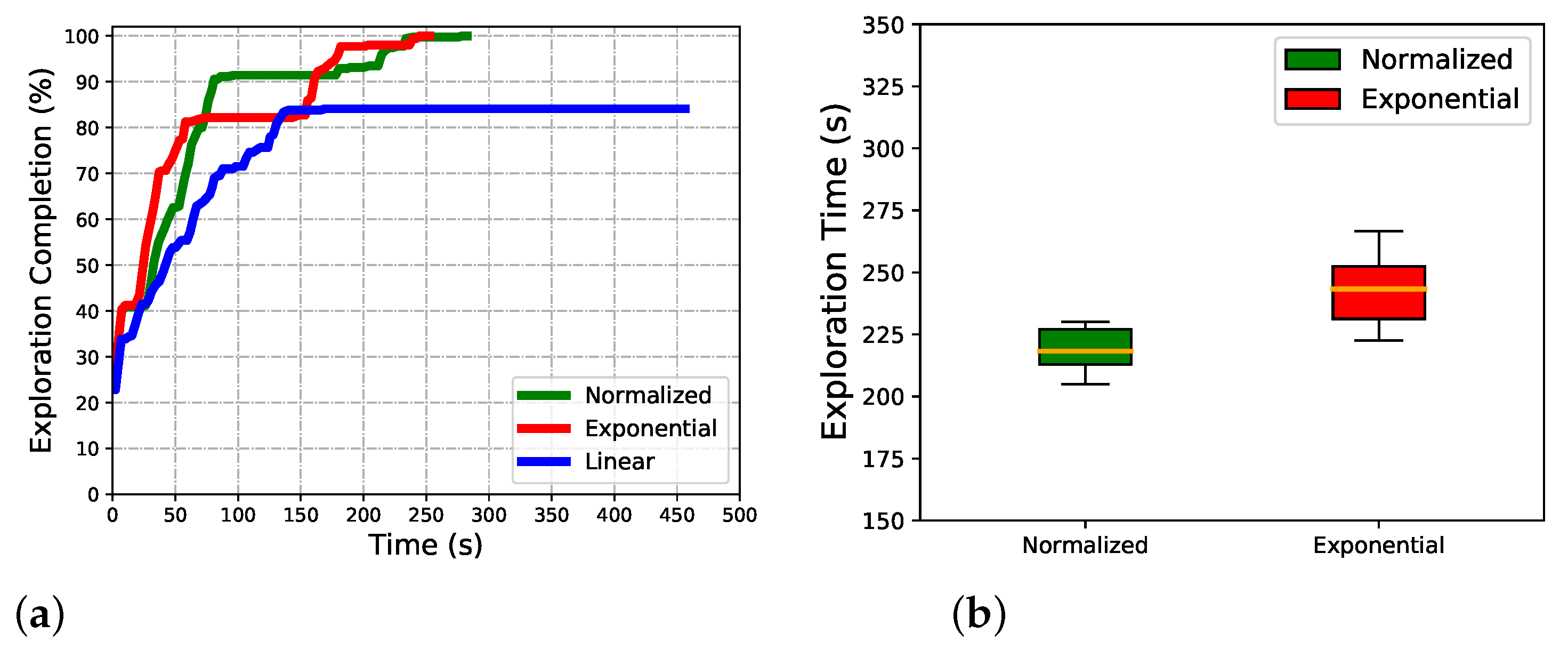
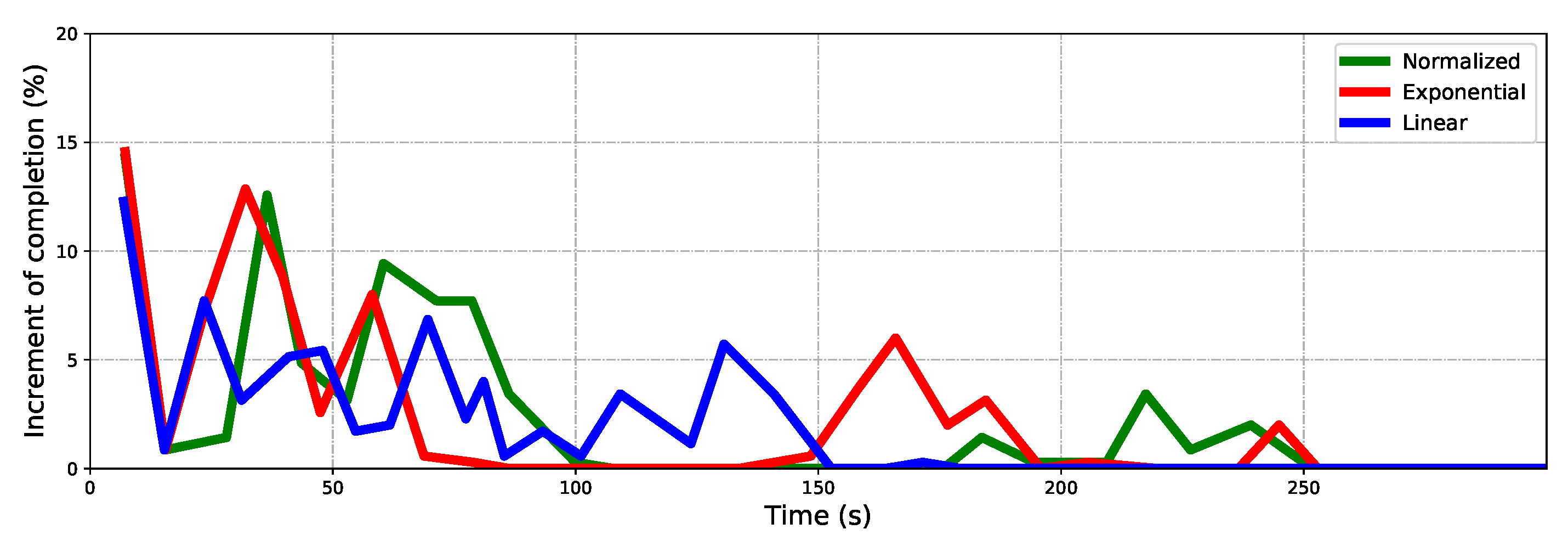
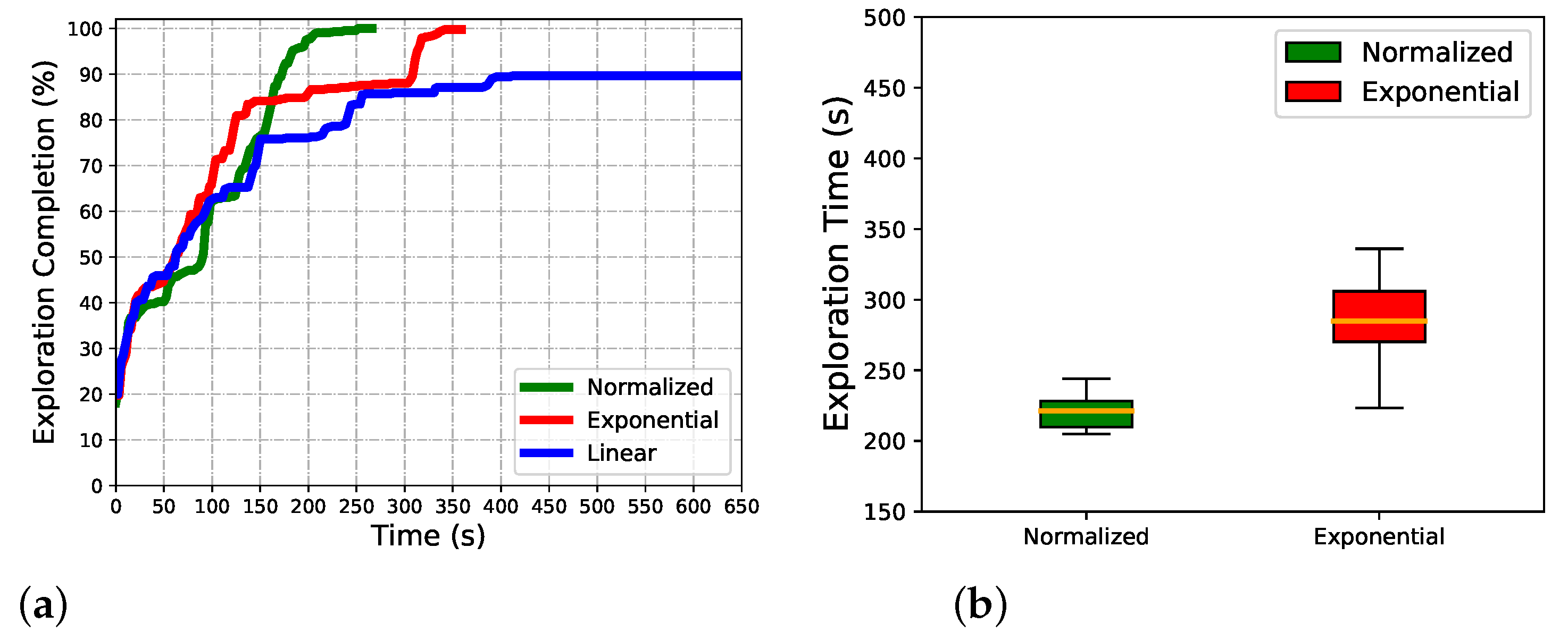
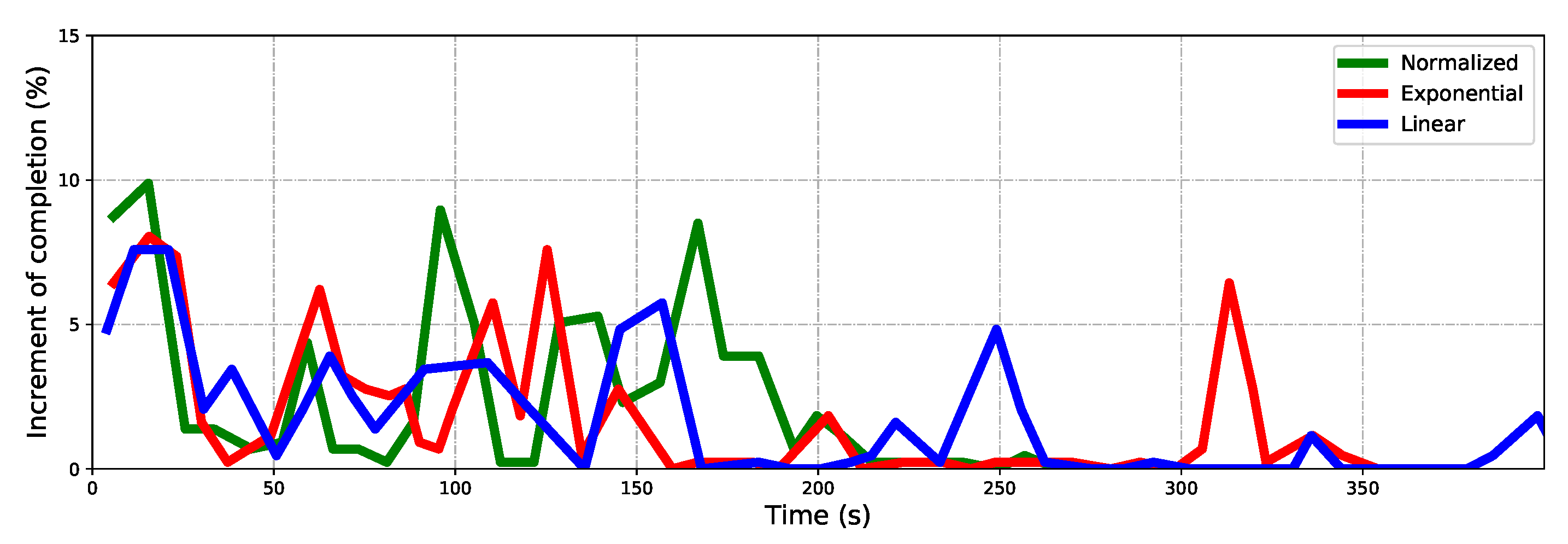
5.1. Effect of Normalized Utility
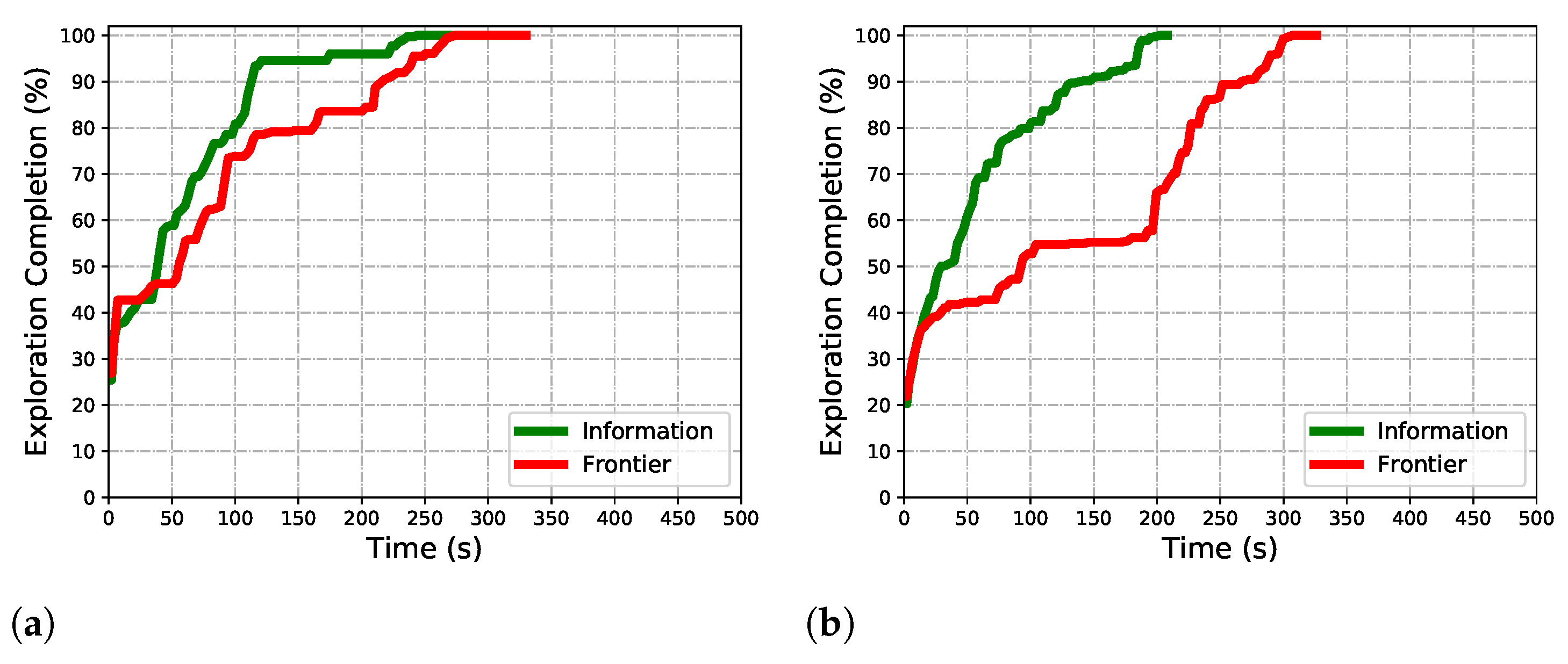
5.2. Viewpoint Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bai, X.; Cao, M.; Yan, W.; Ge, S.S. Efficient routing for precedence-constrained package delivery for heterogeneous vehicles. IEEE Trans. Autom. Sci. Eng. 2019, 17, 248–260. [Google Scholar] [CrossRef]
- Bai, X.; Yan, W.; Ge, S.S.; Cao, M. An integrated multi-population genetic algorithm for multi-vehicle task assignment in a drift field. Inf. Sci. 2018, 453, 227–238. [Google Scholar] [CrossRef]
- Chen, Z.; Alonso-Mora, J.; Bai, X.; Harabor, D.D.; Stuckey, P.J. Integrated task assignment and path planning for capacitated multi-agent pickup and delivery. IEEE Robot. Autom. Lett. 2021, 6, 5816–5823. [Google Scholar] [CrossRef]
- Zhang, B.; Li, G.; Zheng, Q.; Bai, X.; Ding, Y.; Khan, A. Path planning for wheeled mobile robot in partially known uneven terrain. Sensors 2022, 22, 5217. [Google Scholar] [CrossRef]
- Petráček, P.; Krátkỳ, V.; Petrlík, M.; Báča, T.; Kratochvíl, R.; Saska, M. Large-scale exploration of cave environments by unmanned aerial vehicles. IEEE Robot. Autom. Lett. 2021, 6, 7596–7603. [Google Scholar] [CrossRef]
- Tabib, W.; Goel, K.; Yao, J.; Boirum, C.; Michael, N. Autonomous cave surveying with an aerial robot. IEEE Trans. Robot. 2021, 38, 1016–1032. [Google Scholar] [CrossRef]
- Kompis, Y.; Bartolomei, L.; Mascaro, R.; Teixeira, L.; Chli, M. Informed sampling exploration path planner for 3d reconstruction of large scenes. IEEE Robot. Autom. Lett. 2021, 6, 7893–7900. [Google Scholar] [CrossRef]
- Cieslewski, T.; Kaufmann, E.; Scaramuzza, D. Rapid exploration with multi-rotors: A frontier selection method for high speed flight. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2135–2142. [Google Scholar]
- Lee, E.M.; Choi, J.; Lim, H.; Myung, H. REAL: Rapid Exploration with Active Loop-Closing toward Large-Scale 3D Mapping using UAVs. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4194–4198. [Google Scholar]
- Bircher, A.; Kamel, M.; Alexis, K.; Oleynikova, H.; Siegwart, R. Receding horizon path planning for 3D exploration and surface inspection. Auton. Robot. 2018, 42, 291–306. [Google Scholar] [CrossRef]
- Respall, V.M.; Devitt, D.; Fedorenko, R.; Klimchik, A. Fast sampling-based next-best-view exploration algorithm for a MAV. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May 2021–5 June 2021; pp. 89–95. [Google Scholar]
- Papachristos, C.; Mascarich, F.; Khattak, S.; Dang, T.; Alexis, K. Localization uncertainty-aware autonomous exploration and mapping with aerial robots using receding horizon path-planning. Auton. Robot. 2019, 43, 2131–2161. [Google Scholar] [CrossRef]
- Schmid, L.; Reijgwart, V.; Ott, L.; Nieto, J.; Siegwart, R.; Cadena, C. A Unified Approach for Autonomous Volumetric Exploration of Large Scale Environments Under Severe Odometry Drift. IEEE Robot. Autom. Lett. 2021, 6, 4504–4511. [Google Scholar] [CrossRef]
- Brunel, A.; Bourki, A.; Demonceaux, C.; Strauss, O. Splatplanner: Efficient autonomous exploration via permutohedral frontier filtering. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May 2021–5 June 2021; pp. 608–615. [Google Scholar]
- Wang, C.; Ma, H.; Chen, W.; Liu, L.; Meng, M.Q.H. Efficient autonomous exploration with incrementally built topological map in 3-D environments. IEEE Trans. Instrum. Meas. 2020, 69, 9853–9865. [Google Scholar] [CrossRef]
- Gao, W.; Booker, M.; Adiwahono, A.; Yuan, M.; Wang, J.; Yun, Y.W. An improved frontier-based approach for autonomous exploration. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 292–297. [Google Scholar]
- Charrow, B.; Kahn, G.; Patil, S.; Liu, S.; Goldberg, K.; Abbeel, P.; Michael, N.; Kumar, V. Information-Theoretic Planning with Trajectory Optimization for Dense 3D Mapping. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015; Volume 11, pp. 3–12. [Google Scholar]
- Richter, C.; Bry, A.; Roy, N. Polynomial trajectory planning for aggressive quadrotor flight in dense indoor environments. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2016; pp. 649–666. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Zhou, B.; Zhang, Y.; Chen, X.; Shen, S. FUEL: Fast UAV Exploration Using Incremental Frontier Structure and Hierarchical Planning. IEEE Robot. Autom. Lett. 2021, 6, 779–786. [Google Scholar] [CrossRef]
- Lu, L.; Redondo, C.; Campoy, P. Optimal frontier-based autonomous exploration in unconstructed environment using RGB-D sensor. Sensors 2020, 20, 6507. [Google Scholar] [CrossRef] [PubMed]
- Dai, A.; Papatheodorou, S.; Funk, N.; Tzoumanikas, D.; Leutenegger, S. Fast frontier-based information-driven autonomous exploration with an mav. In Proceedings of the 2020 IEEE international conference on robotics and automation (ICRA), Paris, France, 31 May 2020–31 August 2020; pp. 9570–9576. [Google Scholar]
- Williams, J.; Jiang, S.; O’Brien, M.; Wagner, G.; Hernandez, E.; Cox, M.; Pitt, A.; Arkin, R.; Hudson, N. Online 3D frontier-based UGV and UAV exploration using direct point cloud visibility. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Karlsruhe, Germany, 14–16 September 2020; pp. 263–270. [Google Scholar]
- Lindqvist, B.; Agha-Mohammadi, A.A.; Nikolakopoulos, G. Exploration-RRT: A multi-objective Path Planning and Exploration Framework for Unknown and Unstructured Environments. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September 2021–1 October 2021; pp. 3429–3435. [Google Scholar]
- Xu, J.; Park, K.S. A real-time path planning algorithm for cable-driven parallel robots in dynamic environment based on artificial potential guided RRT. Microsyst. Technol. 2020, 26, 3533–3546. [Google Scholar] [CrossRef]
- Oleynikova, H.; Taylor, Z.; Siegwart, R.; Nieto, J. Safe local exploration for replanning in cluttered unknown environments for microaerial vehicles. IEEE Robot. Autom. Lett. 2018, 3, 1474–1481. [Google Scholar] [CrossRef]
- Selin, M.; Tiger, M.; Duberg, D.; Heintz, F.; Jensfelt, P. Efficient autonomous exploration planning of large-scale 3-d environments. IEEE Robot. Autom. Lett. 2019, 4, 1699–1706. [Google Scholar] [CrossRef]
- Pérez-Higueras, N.; Jardón, A.; Rodríguez, Á.; Balaguer, C. 3D exploration and navigation with optimal-RRT planners for ground robots in indoor incidents. Sensors 2019, 20, 220. [Google Scholar] [CrossRef]
- Tian, Z.; Guo, C.; Liu, Y.; Chen, J. An improved RRT robot autonomous exploration and SLAM construction method. In Proceedings of the 2020 5th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 19–20 September 2020; pp. 612–619. [Google Scholar]
- Lau, B.P.L.; Ong, B.J.Y.; Loh, L.K.Y.; Liu, R.; Yuen, C.; Soh, G.S.; Tan, U.X. Multi-AGV’s Temporal Memory-Based RRT Exploration in Unknown Environment. IEEE Robot. Autom. Lett. 2022, 7, 9256–9263. [Google Scholar] [CrossRef]
- Wu, C.Y.; Lin, H.Y. Autonomous mobile robot exploration in unknown indoor environments based on rapidly-exploring random tree. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, VIC, Australia, 13–15 February 2019; pp. 1345–1350. [Google Scholar]
- Xu, Z.; Deng, D.; Shimada, K. Autonomous UAV Exploration of Dynamic Environments Via Incremental Sampling and Probabilistic Roadmap. IEEE Robot. Autom. Lett. 2021, 6, 2729–2736. [Google Scholar] [CrossRef]
- Wang, C.; Chi, W.; Sun, Y.; Meng, M.Q.H. Autonomous Robotic Exploration by Incremental Road Map Construction. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1720–1731. [Google Scholar] [CrossRef]
- Hardouin, G.; Morbidi, F.; Moras, J.; Marzat, J.; Mouaddib, E.M. Surface-driven Next-Best-View planning for exploration of large-scale 3D environments. IFAC-PapersOnLine 2020, 53, 15501–15507. [Google Scholar] [CrossRef]
- Yoder, L.; Scherer, S. Autonomous exploration for infrastructure modeling with a micro aerial vehicle. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 427–440. [Google Scholar]
- Corah, M.; O’Meadhra, C.; Goel, K.; Michael, N. Communication-efficient planning and mapping for multi-robot exploration in large environments. IEEE Robot. Autom. Lett. 2019, 4, 1715–1721. [Google Scholar] [CrossRef]
- Schmid, L.; Pantic, M.; Khanna, R.; Ott, L.; Siegwart, R.; Nieto, J. An efficient sampling-based method for online informative path planning in unknown environments. IEEE Robot. Autom. Lett. 2020, 5, 1500–1507. [Google Scholar] [CrossRef]
- Tabib, W.; Goel, K.; Yao, J.; Dabhi, M.; Boirum, C.; Michael, N. Real-Time Information-Theoretic Exploration with Gaussian Mixture Model Maps. In Proceedings of the Robotics: Science and Systems, Breisgau, Germany, 22–26 June 2019; pp. 1–9. [Google Scholar]
- Saulnier, K.; Atanasov, N.; Pappas, G.J.; Kumar, V. Information theoretic active exploration in signed distance fields. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May 2020–31 August 2020; pp. 4080–4085. [Google Scholar]
- Song, S.; Jo, S. Surface-based exploration for autonomous 3d modeling. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4319–4326. [Google Scholar]
- Budd, M.; Lacerda, B.; Duckworth, P.; West, A.; Lennox, B.; Hawes, N. Markov decision processes with unknown state feature values for safe exploration using gaussian processes. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 7344–7350. [Google Scholar]
- Papachristos, C.; Kamel, M.; Popović, M.; Khattak, S.; Bircher, A.; Oleynikova, H.; Dang, T.; Mascarich, F.; Alexis, K.; Siegwart, R. Autonomous exploration and inspection path planning for aerial robots using the robot operating system. In Robot Operating System (ROS); Springer: Berlin/Heidelberg, Germany, 2019; pp. 67–111. [Google Scholar]
- Mellinger, D.; Kumar, V. Minimum snap trajectory generation and control for quadrotors. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2520–2525. [Google Scholar]
- Furrer, F.; Burri, M.; Achtelik, M.W.; Siegwart, R. Chapter RotorS—A Modular Gazebo MAV Simulator Framework. In Robot Operating System (ROS): The Complete Reference (Volume 1); Springer International Publishing: Cham, Switzerland, 2016; pp. 595–625. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
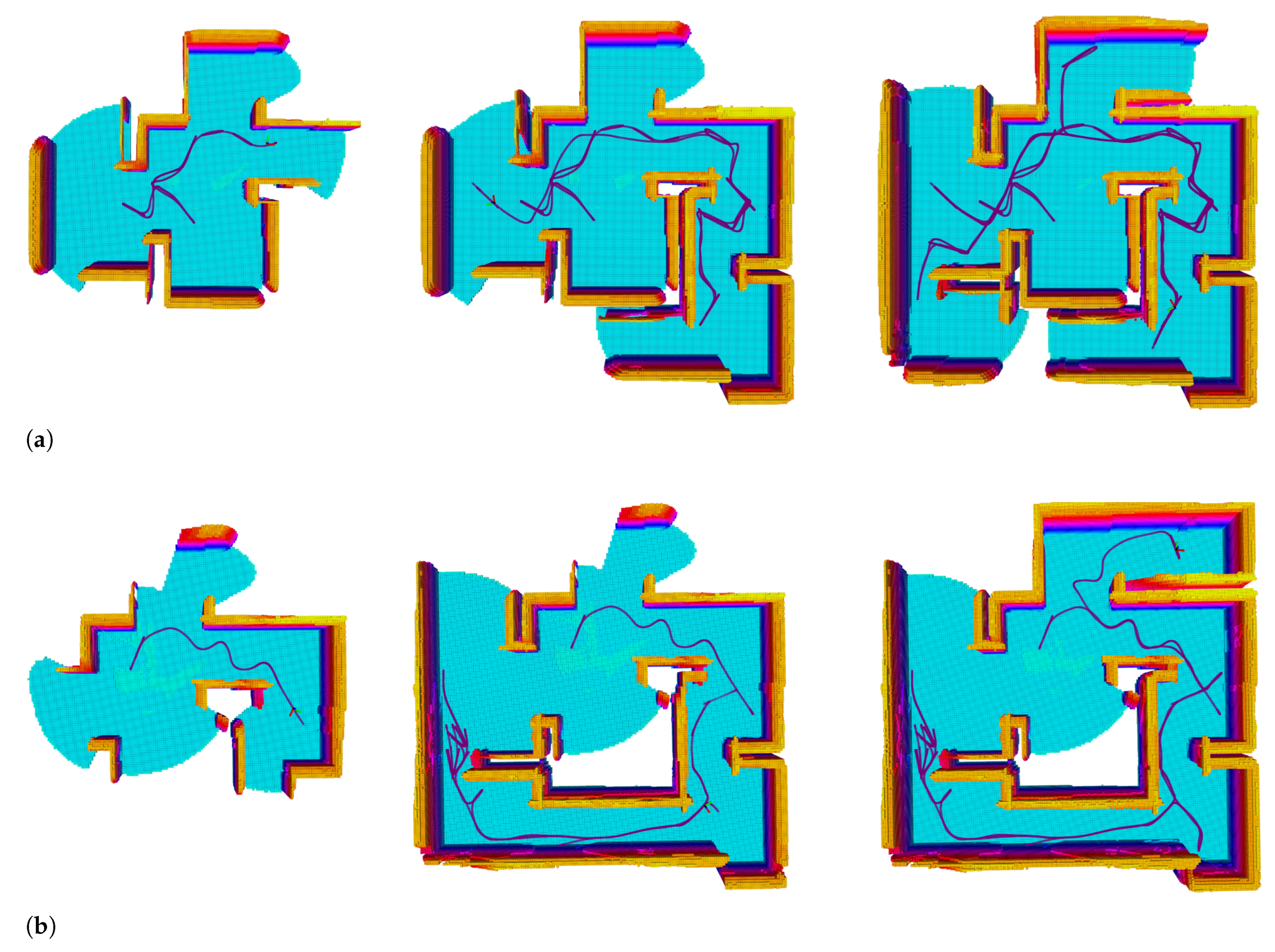{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum segment length | ||
| Sensor range | ||
| Field of View | ||
| Maximum velocity | ||
| Maximum acceleration | ||
| Maximum yaw velocity | ||
| Exponential parameter | ||
| Linear parameter |
| Indoor | Maze | |||||
|---|---|---|---|---|---|---|
| Method | Evaluation (ms) | Total (s) | Trajectory (m) | Evaluation (ms) | Total (s) | Trajectory (m) |
| Frontiers [13] | ||||||
| Information | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, T.; Deng, B.; Gui, J.; Zhu, X.; Yao, W. Efficient Informative Path Planning via Normalized Utility in Unknown Environments Exploration. Sensors 2022, 22, 8429. https://doi.org/10.3390/s22218429
Yu T, Deng B, Gui J, Zhu X, Yao W. Efficient Informative Path Planning via Normalized Utility in Unknown Environments Exploration. Sensors. 2022; 22(21):8429. https://doi.org/10.3390/s22218429
Chicago/Turabian StyleYu, Tianyou, Baosong Deng, Jianjun Gui, Xiaozhou Zhu, and Wen Yao. 2022. "Efficient Informative Path Planning via Normalized Utility in Unknown Environments Exploration" Sensors 22, no. 21: 8429. https://doi.org/10.3390/s22218429
APA StyleYu, T., Deng, B., Gui, J., Zhu, X., & Yao, W. (2022). Efficient Informative Path Planning via Normalized Utility in Unknown Environments Exploration. Sensors, 22(21), 8429. https://doi.org/10.3390/s22218429