

Online Boosting-Based Target Identification among Similar Appearance for Person-Following Robots



Abstract
1. Introduction
2. Related Work
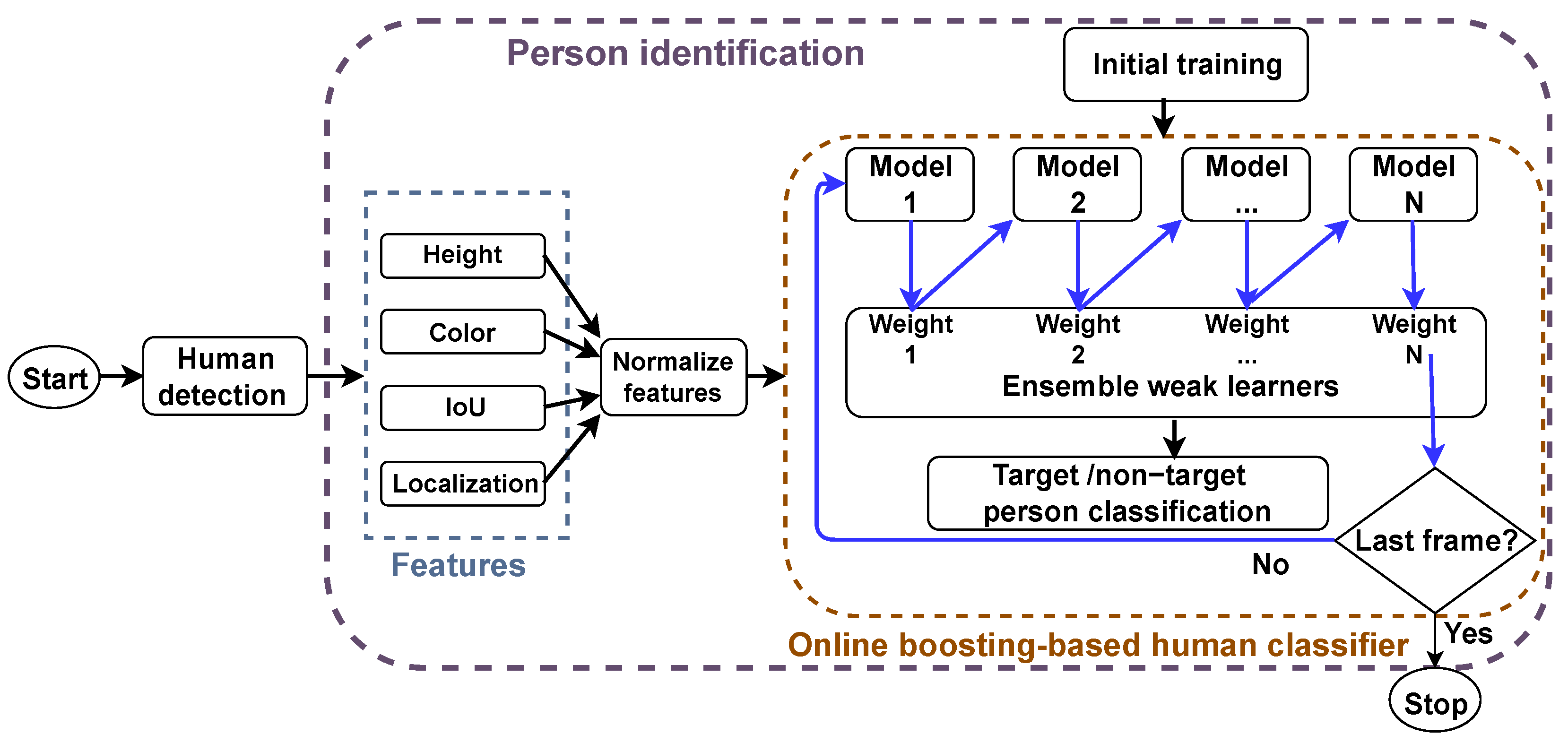
3. Human Identifier Methodology
3.1. Feature Definitions
3.1.1. Color Feature
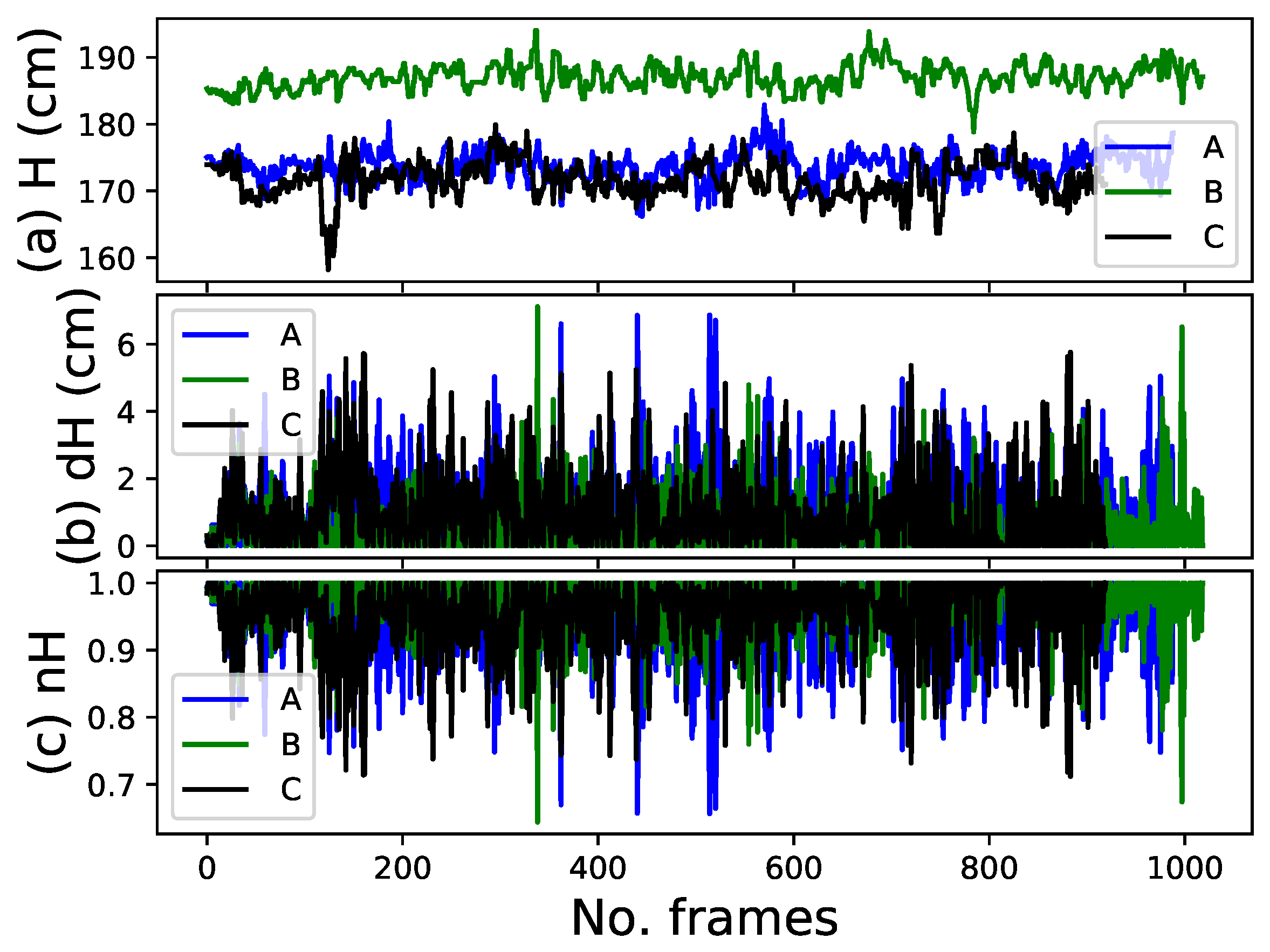
3.1.2. Height Feature
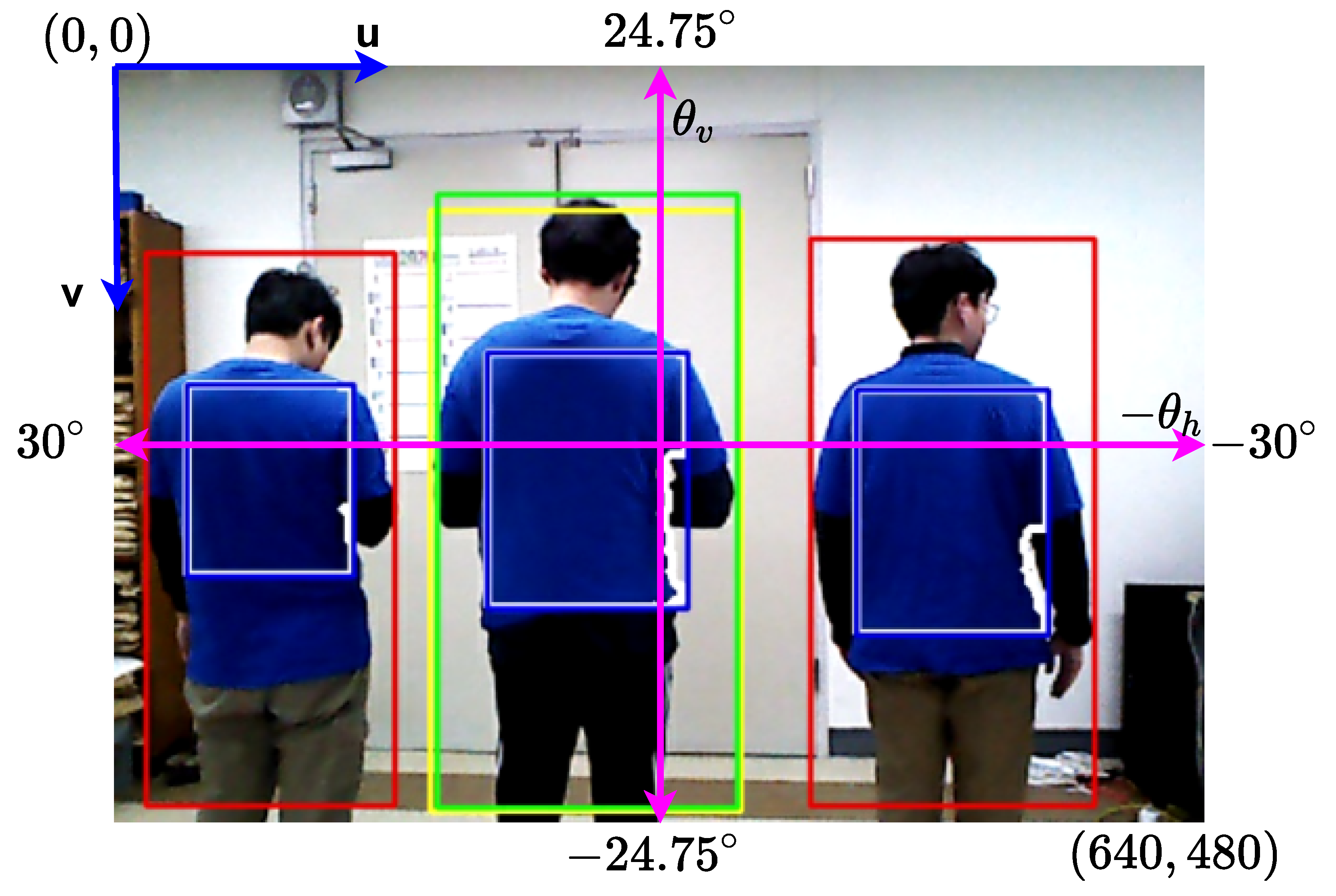
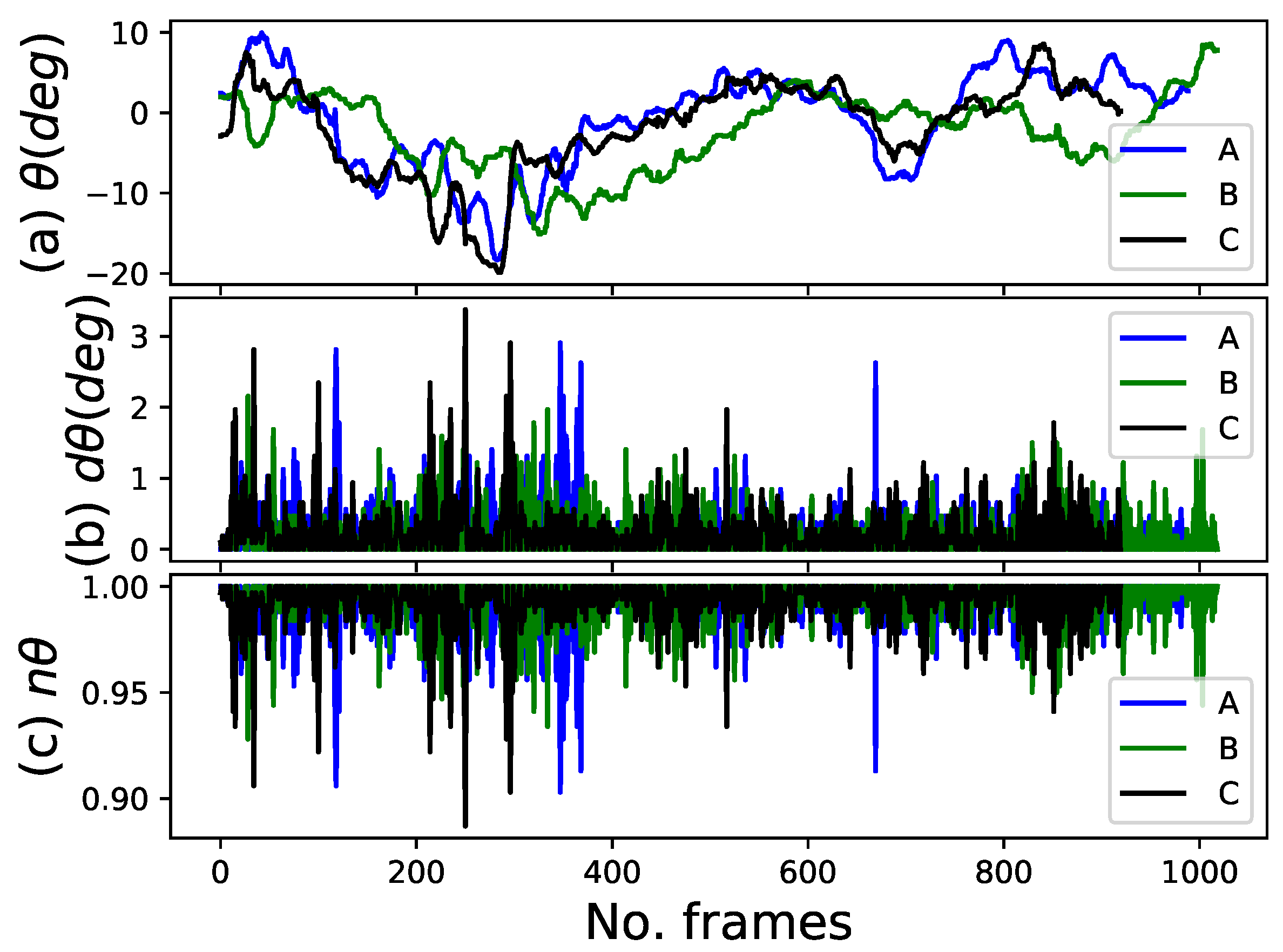
3.1.3. Localization Feature
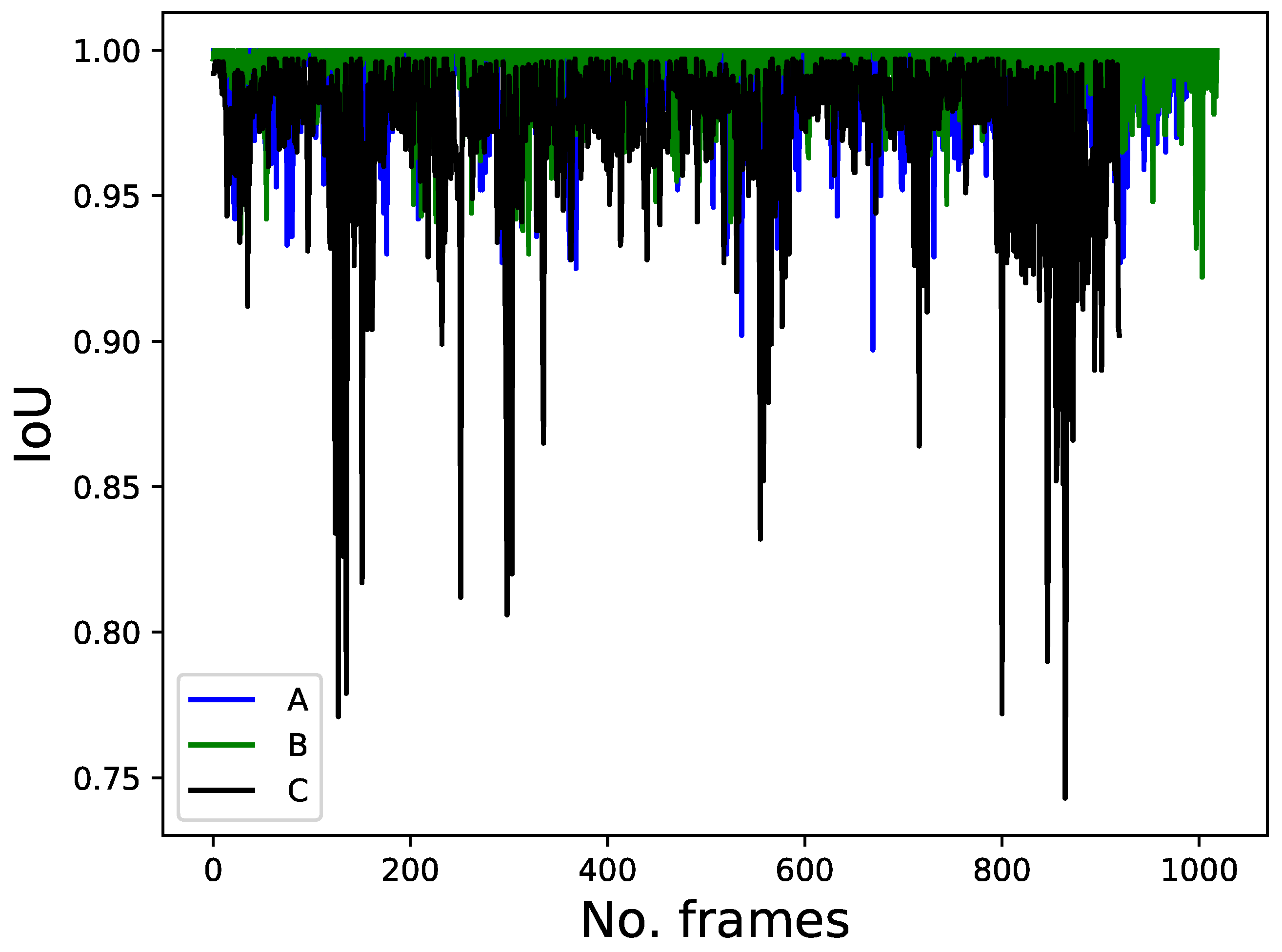
3.1.4. IoU Feature
3.2. Online Boosting-Based Person Classifier
4. Results and Discussion
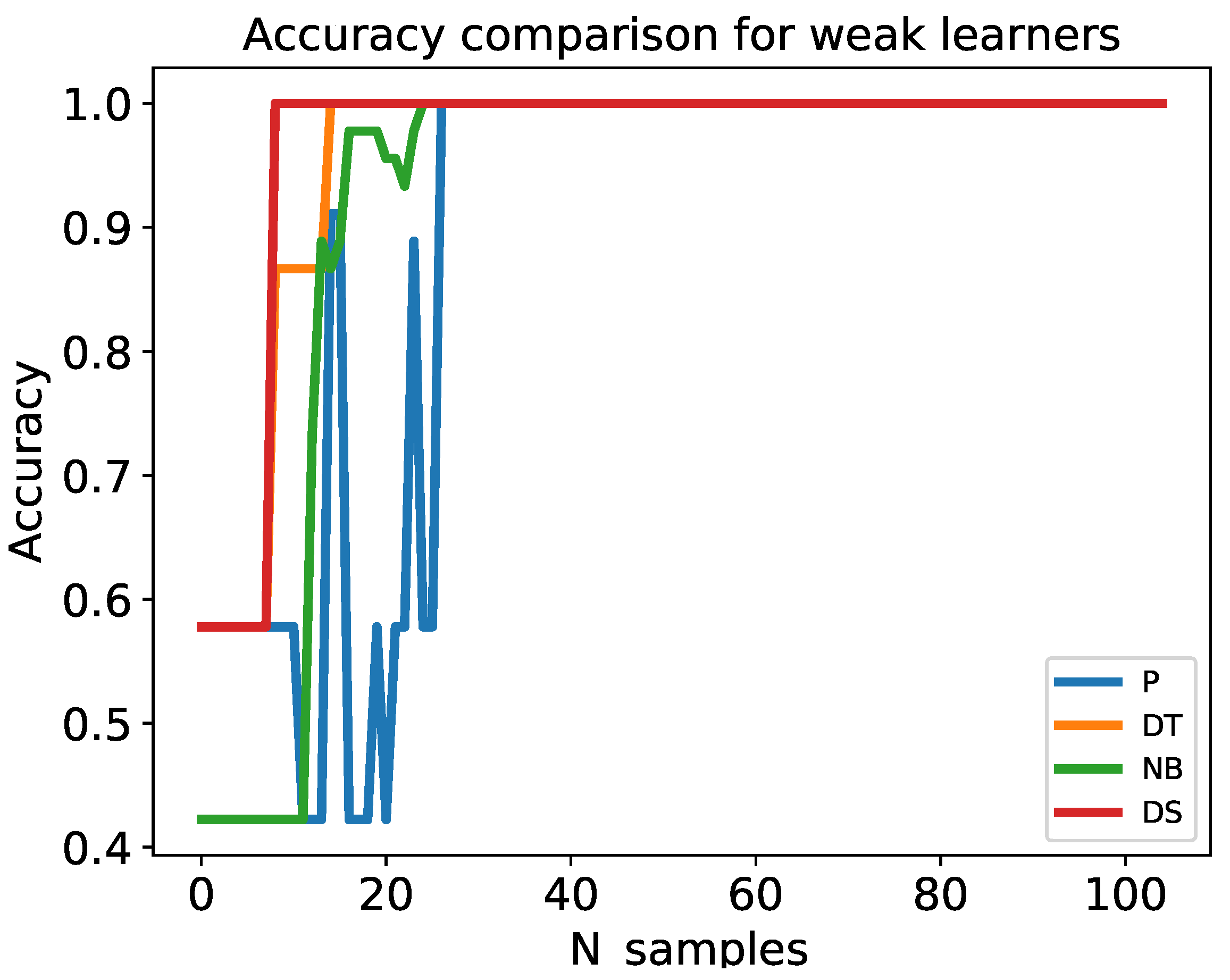
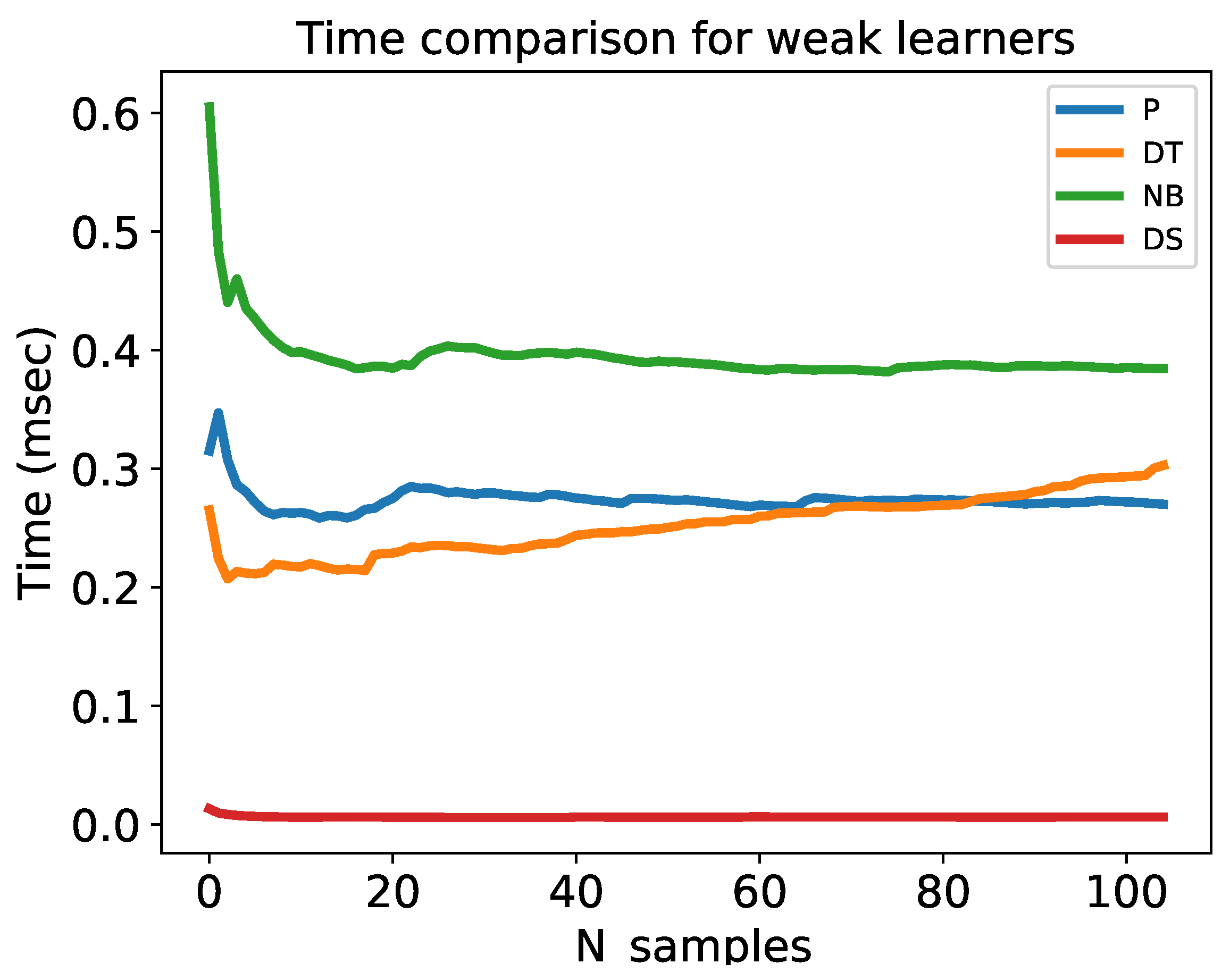
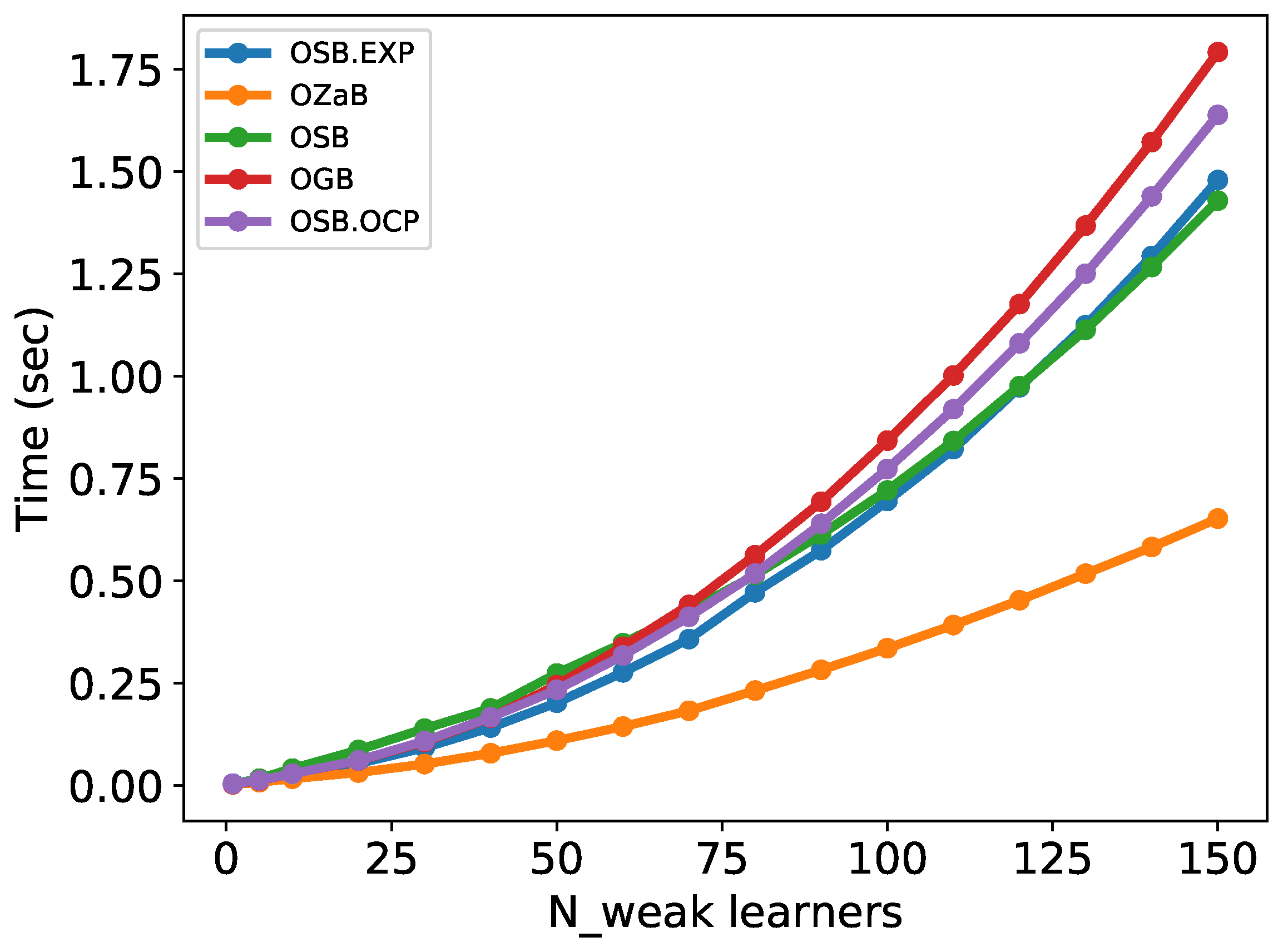
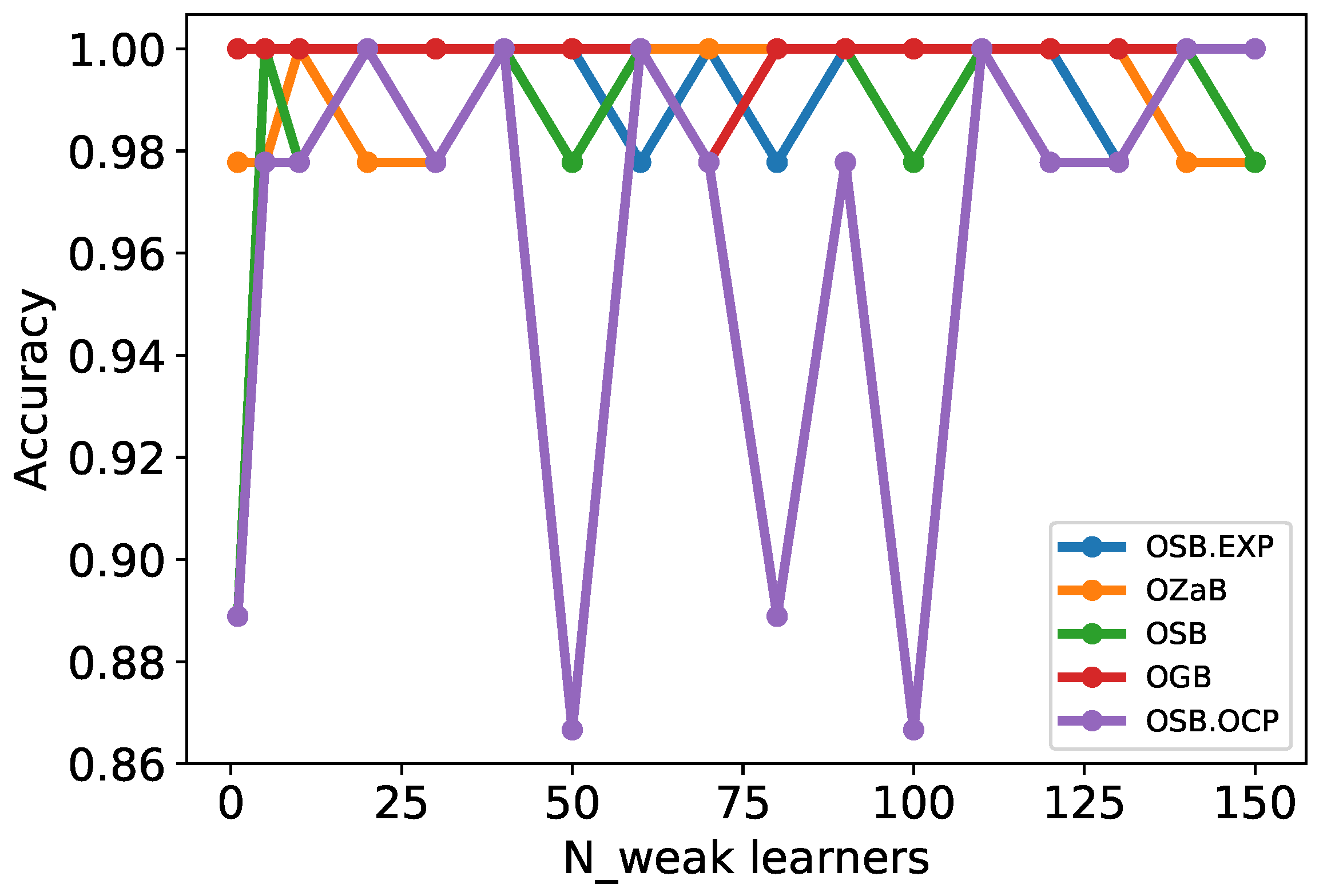
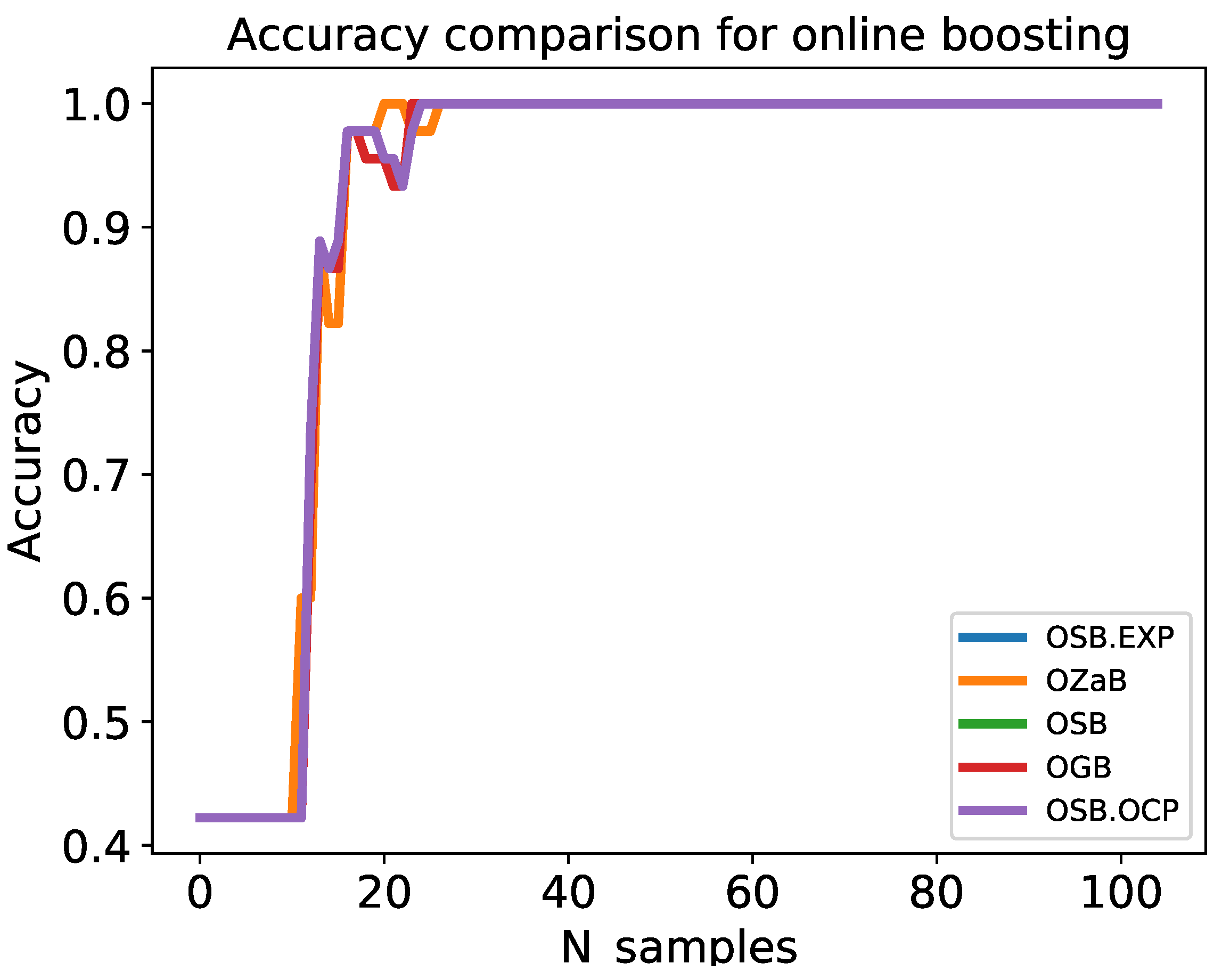
4.1. Online Boosting Algorithms Evaluation
4.1.1. Dataset Preprocessing
4.1.2. Performance Metrics
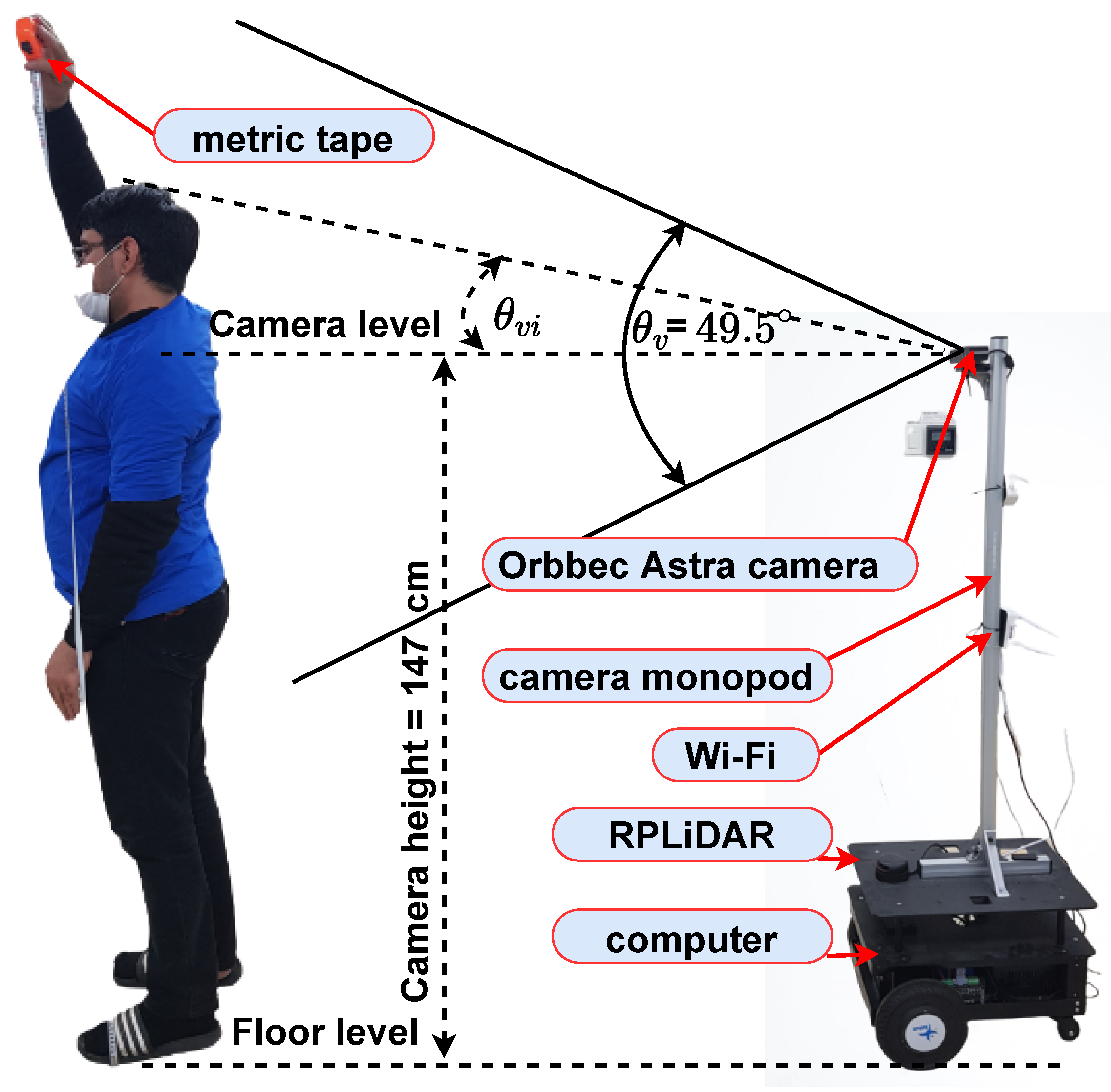
4.2. Infrastructure Setting
4.2.1. Platform
4.2.2. Environment
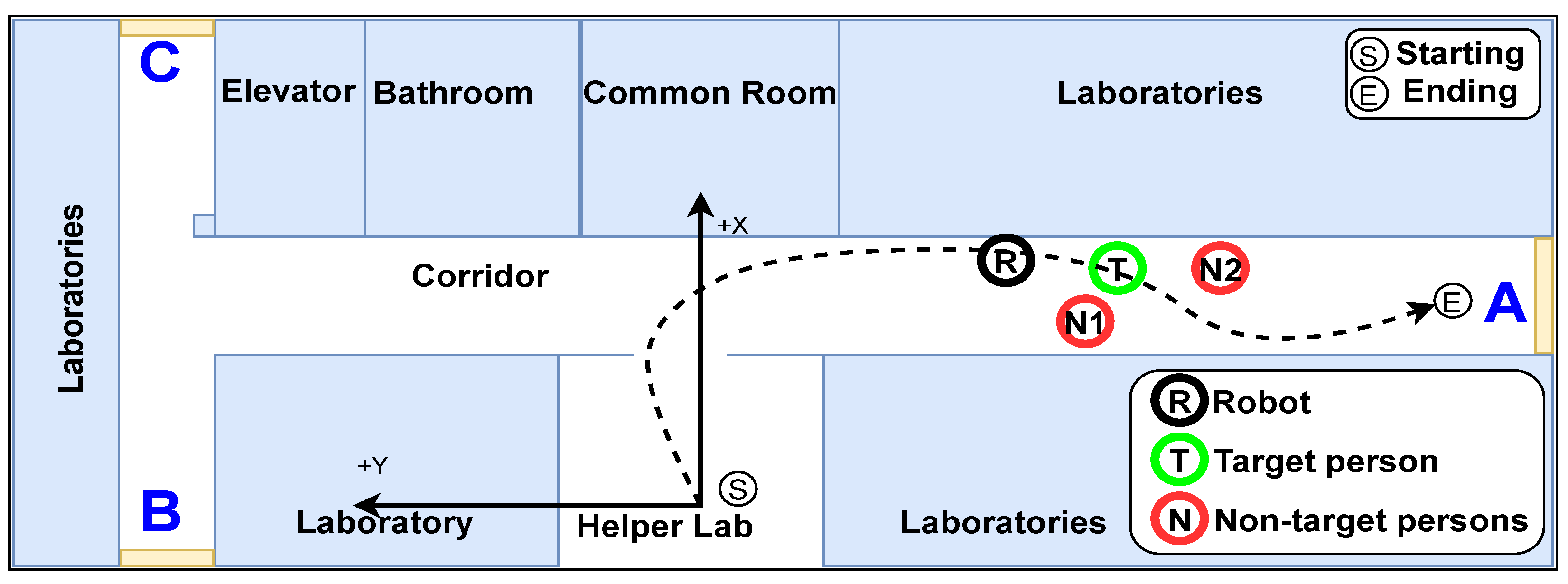
4.3. Human-Following Experiments
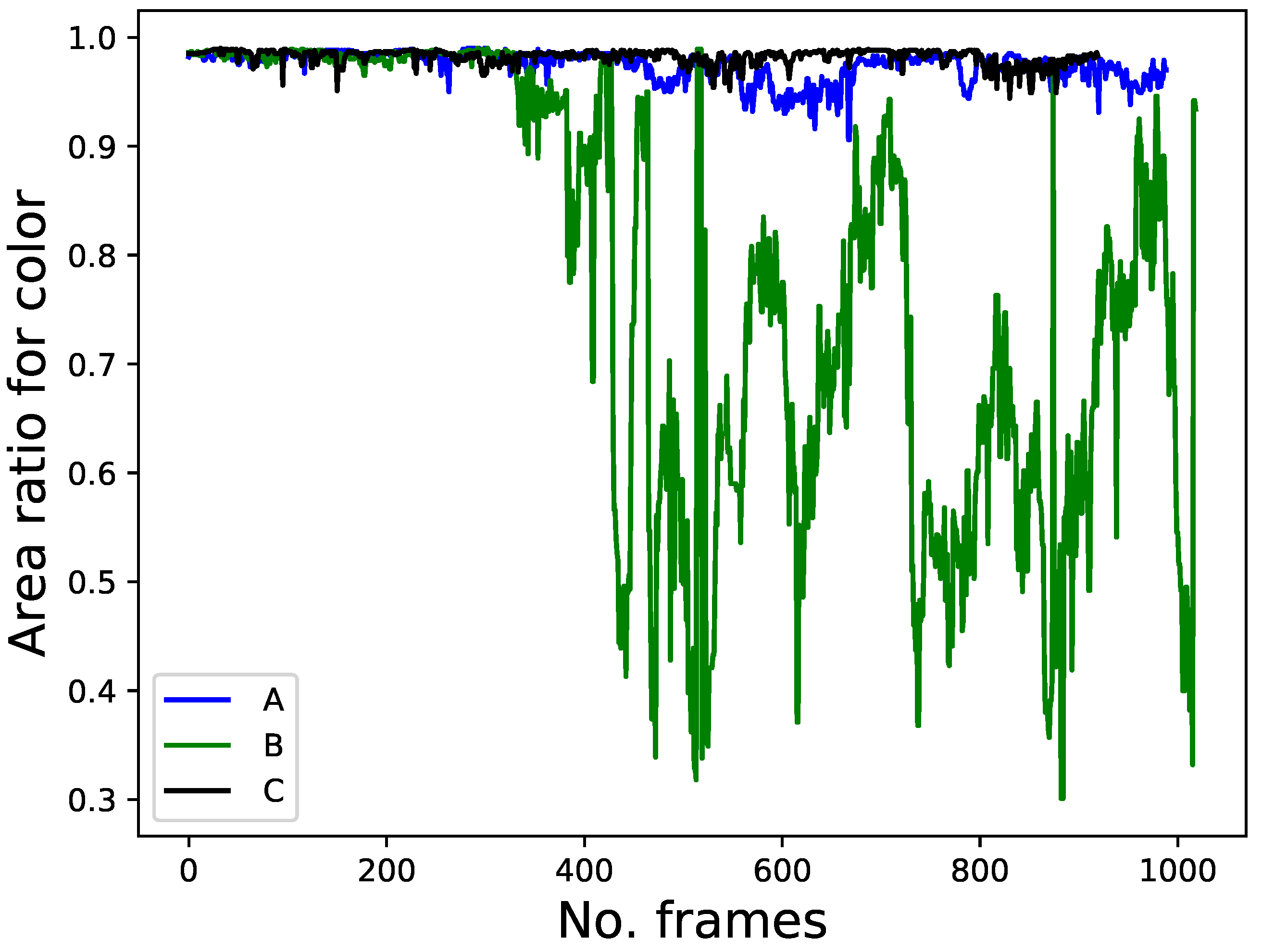
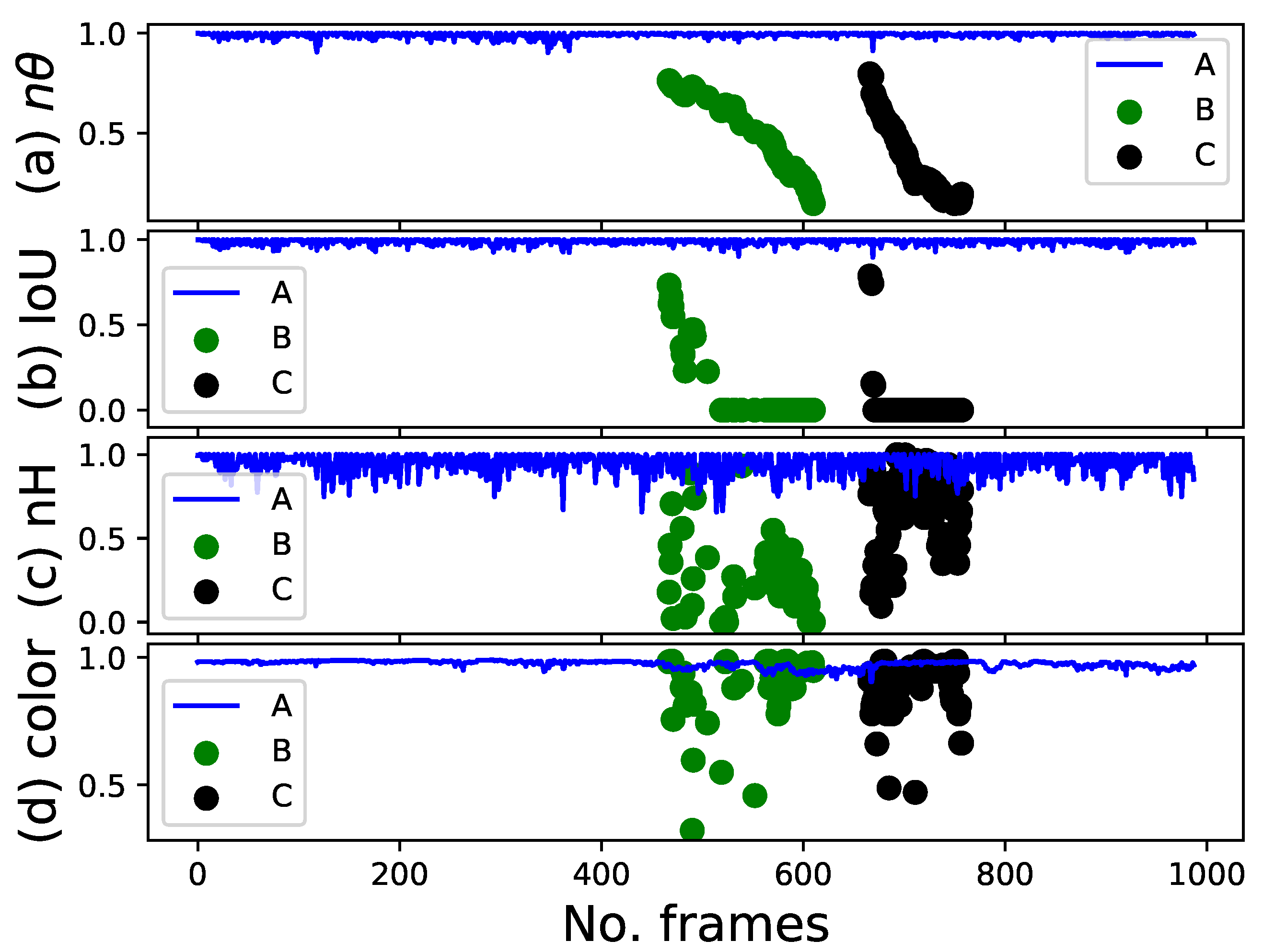
4.3.1. Human-Following Experiments Using Four Features
4.3.2. Comparison with Previous System: Using Two Features
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gross, H.M.; Scheidig, A.; Debes, K.; Einhorn, E.; Eisenbach, M.; Mueller, S.; Schmiedel, T.; Trinh, T.Q.; Weinrich, C.; Wengefeld, T.; et al. ROREAS: Robot coach for walking and orientation training in clinical post-stroke rehabilitation—Prototype implementation and evaluation in field trials. Auton. Robot. 2017, 41, 679–698. [Google Scholar] [CrossRef]
- Alghodhaifi, H.; Lakshmanan, S. Autonomous Vehicle Evaluation: A Comprehensive Survey on Modeling and Simulation Approaches. IEEE Access 2021, 9, 151531–151566. [Google Scholar] [CrossRef]
- Koide, K.; Miura, J.; Menegatti, E. Monocular person tracking and identification with on-line deep feature selection for person following robots. Robot. Auton. Syst. 2020, 124, 103348. [Google Scholar] [CrossRef]
- Kanchanasatian, K. A Robot Companion Algorithm for Side-by-Side Object Tracking and Following. In Proceedings of the 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Phuket, Thailand, 5–8 July 2022; pp. 1–7. [Google Scholar]
- Kästner, L.; Fatloun, B.; Shen, Z.; Gawrisch, D.; Lambrecht, J. Human-following and-guiding in crowded environments using semantic deep-reinforcement-learning for mobile service robots. In Proceedings of the International Conference on Robotics and Automation (ICRA), Pennsylvania, PA, USA, 23–27 May 2022; pp. 833–839. [Google Scholar]
- Zhang, J.X.; Yang, G.H. Low-complexity tracking control of strict-feedback systems with unknown control directions. IEEE Trans. Autom. Control 2019, 64, 5175–5182. [Google Scholar] [CrossRef]
- Algburi, R.N.A.; Gao, H.; Al-Huda, Z. Improvement of an Industrial Robotic Flaw Detection System. IEEE Trans. Autom. Sci. Eng. 2022, 19, 3953–3967. [Google Scholar] [CrossRef]
- Zhang, X.; Dai, L. Image Enhancement Based on Rough Set and Fractional Order Differentiator. Fractal Fract. 2022, 6, 214. [Google Scholar] [CrossRef]
- Algabri, R.; Choi, M.T. Target Recovery for Robust Deep Learning-Based Person Following in Mobile Robots: Online Trajectory Prediction. Appl. Sci. 2021, 11, 4165. [Google Scholar] [CrossRef]
- Schlegel, C.; Illmann, J.; Jaberg, H.; Schuster, M.; Wörz, R. Vision based person tracking with a mobile robot. In Proceedings of the BMVC, Southampton, UK, 14–17 September 1998; pp. 1–10. [Google Scholar]
- Chen, B.X.; Sahdev, R.; Tsotsos, J.K. Person following robot using selected online ada-boosting with stereo camera. In Proceedings of the 14th Conference on Computer and Robot Vision (CRV), Edmonton, AB, Canada, 17–19 May 2017; pp. 48–55. [Google Scholar]
- Yuan, J.; Zhang, S.; Sun, Q.; Liu, G.; Cai, J. Laser-based intersection-aware human following with a mobile robot in indoor environments. IEEE Trans. Syst. Man Cybern. Syst. 2018, 51, 354–369. [Google Scholar] [CrossRef]
- Algabri, R.; Choi, M.T. Deep-Learning-Based Indoor Human Following of Mobile Robot Using Color Feature. Sensors 2020, 20, 2699. [Google Scholar] [CrossRef]
- Chi, W.; Wang, J.; Meng, M.Q.H. A gait recognition method for human following in service robots. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1429–1440. [Google Scholar] [CrossRef]
- Islam, M.J.; Hong, J.; Sattar, J. Person-following by autonomous robots: A categorical overview. Int. J. Robot. Res. 2019, 38, 1581–1618. [Google Scholar] [CrossRef]
- Yuan, J.; Cai, J.; Zhang, X.; Sun, Q.; Sun, F.; Zhu, W. Fusing Skeleton Recognition With Face-TLD for Human Following of Mobile Service Robots. IEEE Trans. Syst. Man Cybern. Syst. 2019, 51, 2963–2979. [Google Scholar] [CrossRef]
- Wu, C.; Tao, B.; Wu, H.; Gong, Z.; Yin, Z. A UHF RFID-Based Dynamic Object Following Method for a Mobile Robot Using Phase Difference Information. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Linxi, G.; Yunfei, C. Human Following for Outdoor Mobile Robots Based on Point-Cloud’s Appearance Model. Chin. J. Electron. 2021, 30, 1087–1095. [Google Scholar] [CrossRef]
- Cha, D.; Chung, W. Human-Leg Detection in 3D Feature Space for a Person-Following Mobile Robot Using 2D LiDARs. Int. J. Precis. Eng. Manuf. 2020, 21, 1299–1307. [Google Scholar] [CrossRef]
- Stein, P.; Spalanzani, A.; Santos, V.; Laugier, C. Leader following: A study on classification and selection. Robot. Auton. Syst. 2016, 75, 79–95. [Google Scholar] [CrossRef]
- Satake, J.; Chiba, M.; Miura, J. Visual person identification using a distance-dependent appearance model for a person following robot. Int. J. Autom. Comput. 2013, 10, 438–446. [Google Scholar] [CrossRef]
- Algabri, R.; Choi, M.T. Robust Person Following Under Severe Indoor Illumination Changes for Mobile Robots: Online Color-Based Identification Update. In Proceedings of the 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 12–15 October 2021; pp. 1000–1005. [Google Scholar]
- Gupta, M.; Kumar, S.; Behera, L.; Subramanian, V.K. A novel vision-based tracking algorithm for a human-following mobile robot. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1415–1427. [Google Scholar] [CrossRef]
- Coşar, S.; Bellotto, N. Human Re-Identification with a Robot Thermal Camera Using Entropy-Based Sampling. J. Intell. Robot. Syst. 2020, 98, 85–102. [Google Scholar] [CrossRef]
- Koide, K.; Miura, J. Identification of a specific person using color, height, and gait features for a person following robot. Robot. Auton. Syst. 2016, 84, 76–87. [Google Scholar] [CrossRef]
- Lee, B.J.; Choi, J.; Baek, C.; Zhang, B.T. Robust Human Following by Deep Bayesian Trajectory Prediction for Home Service Robots. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7189–7195. [Google Scholar]
- Pang, L.; Zhang, Y.; Coleman, S.; Cao, H. Efficient hybrid-supervised deep reinforcement learning for person following robot. J. Intell. Robot. Syst. 2020, 97, 299–312. [Google Scholar] [CrossRef]
- Chen, B.X.; Sahdev, R.; Tsotsos, J.K. Integrating stereo vision with a CNN tracker for a person-following robot. In Proceedings of the International Conference on Computer Vision Systems, Shenzhen, China, 10–13 July 2017; pp. 300–313. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ju, Y.; Sun, G.; Chen, Q.; Zhang, M.; Zhu, H.; Rehman, M.U. A model combining convolutional neural network and LightGBM algorithm for ultra-short-term wind power forecasting. IEEE Access 2019, 7, 28309–28318. [Google Scholar] [CrossRef]
- Peng, B.; Al-Huda, Z.; Xie, Z.; Wu, X. Multi-scale region composition of hierarchical image segmentation. Multimed. Tools Appl. 2020, 79, 32833–32855. [Google Scholar] [CrossRef]
- De Angelis, D.; Sala, R.; Cantatore, A.; Poppa, P.; Dufour, M.; Grandi, M.; Cattaneo, C. New method for height estimation of subjects represented in photograms taken from video surveillance systems. Int. J. Leg. Med. 2007, 121, 489–492. [Google Scholar] [CrossRef]
- Hoogeboom, B.; Alberink, I.; Goos, M. Body height measurements in images. J. Forensic Sci. 2009, 54, 1365–1375. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Zhou, D.; Fang, J.; Song, X.; Guan, C.; Yin, J.; Dai, Y.; Yang, R. Iou loss for 2d/3d object detection. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 85–94. [Google Scholar]
- Chen, S.T.; Lin, H.T.; Lu, C.J. An online boosting algorithm with theoretical justifications. arXiv 2012, arXiv:1206.6422. [Google Scholar]
- Al-Huda, Z.; Peng, B.; Yang, Y.; Algburi, R.N.A.; Ahmad, M.; Khurshid, F.; Moghalles, K. Weakly supervised semantic segmentation by iteratively refining optimal segmentation with deep cues guidance. Neural Comput. Appl. 2021, 33, 1–26. [Google Scholar] [CrossRef]
- Moghalles, K.; Li, H.C.; Alazeb, A. Weakly Supervised Building Semantic Segmentation Based on Spot-Seeds and Refinement Process. Entropy 2022, 24, 741. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Oza, N.C.; Russell, S.J. Online bagging and boosting. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 3–6 January 2001; pp. 229–236. [Google Scholar]
- Tanha, J.; Abdi, Y.; Samadi, N.; Razzaghi, N.; Asadpour, M. Boosting methods for multi-class imbalanced data classification: An experimental review. J. Big Data 2020, 7, 1–47. [Google Scholar] [CrossRef]
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Leistner, C.; Saffari, A.; Roth, P.M.; Bischof, H. On robustness of on-line boosting-a competitive study. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1362–1369. [Google Scholar]
- Pham, Q.B.; Pal, S.C.; Chakrabortty, R.; Norouzi, A.; Golshan, M.; Ogunrinde, A.T.; Janizadeh, S.; Khedher, K.M.; Anh, D.T. Evaluation of various boosting ensemble algorithms for predicting flood hazard susceptibility areas. Geomat. Nat. Hazards Risk 2021, 12, 2607–2628. [Google Scholar] [CrossRef]
- Wu, T.; Xie, K.; Xinpin, D.; Song, G. A online boosting approach for traffic flow forecasting under abnormal conditions. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery, Sichuan, China, 29–31 May 2012; pp. 2555–2559. [Google Scholar]
- Grabner, H.; Bischof, H. On-line boosting and vision. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 260–267. [Google Scholar]
- Abdu, A.; Zhai, Z.; Algabri, R.; Abdo, H.A.; Hamad, K.; Al-antari, M.A. Deep Learning-Based Software Defect Prediction via Semantic Key Features of Source Code—Systematic Survey. Mathematics 2022, 10, 3120. [Google Scholar] [CrossRef]
- Brandmeier, M.; Zamora, I.G.C.; Nykänen, V.; Middleton, M. Boosting for mineral prospectivity modeling: A new GIS toolbox. Nat. Resour. Res. 2020, 29, 71–88. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Features | Four | Two | ||
|---|---|---|---|---|
| Feature name | Color, height, localization and IoU | Color and height | ||
| T-shirt color | Blue | White | Black | Black |
| Successful experiments | 13/13 | 12/13 | 11/13 | 8/13 |
| Parameters | Exp. 1 | Exp. 2 | Exp. 3 | Exp. 4 | Exp. 5 | Exp. 6 | Exp. 7 | Exp. 8 | Exp. 9 | Exp. 10 | Exp. 11 | Exp. 12 | Exp. 13 | Total | Average | Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Experiment status | O | O | O | O | O | O | O | O | O | O | O | O | O | 13 /13 | - | - |
| Target’s travel distance (m) | 30.40 | 31.30 | 31.16 | 31.39 | 31.46 | 31.55 | 31.40 | 31.43 | 31.53 | 31.44 | 31.76 | 31.31 | 30.61 | 406.75 | 31.29 | 0.38 |
| Robot’s travel distance (m) | 29.44 | 29.52 | 29.03 | 29.34 | 29.37 | 29.64 | 29.59 | 29.26 | 29.13 | 29.47 | 29.64 | 29.14 | 26.95 | 379.51 | 29.19 | 0.70 |
| Robot’s travel time (s) | 39.93 | 40.19 | 40.11 | 39.18 | 39.77 | 39.94 | 41.41 | 40.14 | 38.67 | 39.21 | 39.16 | 38.07 | 38.28 | 514.05 | 39.54 | 0.91 |
| Robot’s average velocity (m/s) | 0.74 | 0.73 | 0.72 | 0.75 | 0.74 | 0.74 | 0.71 | 0.73 | 0.75 | 0.75 | 0.76 | 0.77 | 0.70 | - | 0.74 | 0.02 |
| No. of frames (N) | 1004 | 1012 | 1008 | 990 | 995 | 1003 | 997 | 1010 | 910 | 969 | 983 | 957 | 959 | 12,797 | 984.38 | 29.12 |
| No. of frames for model () | 1000 | 1012 | 1001 | 990 | 980 | 1000 | 993 | 1006 | 910 | 969 | 973 | 957 | 932 | 12,723 | 978.69 | 30.40 |
| Successfully tracked (frames) (n) | 998 | 1012 | 1001 | 990 | 979 | 1000 | 993 | 1006 | 909 | 969 | 973 | 953 | 859 | 12,642 | 972.46 | 43.76 |
| No. of lost frames by model | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 4 | 73 | 81 | 6.23 | 20.10 |
| Lost frames due to noise | 4 | 0 | 7 | 0 | 15 | 3 | 4 | 4 | 0 | 0 | 10 | 0 | 27 | 74 | 5.69 | 7.85 |
| Lost track of the target (frames) | 6 | 0 | 7 | 0 | 16 | 3 | 4 | 4 | 1 | 0 | 10 | 4 | 100 | 155 | 11.92 | 26.85 |
| Successfully tracked (s) | 39.69 | 40.19 | 39.83 | 39.18 | 39.13 | 39.82 | 41.24 | 39.98 | 38.62 | 39.21 | 38.76 | 37.91 | 34.29 | 507.86 | 39.07 | 1.66 |
| Lost track of the target (s) | 0.24 | 0.00 | 0.28 | 0.00 | 0.64 | 0.12 | 0.17 | 0.16 | 0.04 | 0.00 | 0.40 | 0.16 | 3.99 | 6.19 | 0.48 | 1.07 |
| successful tracking rate (%) | 0.99 | 1.00 | 0.99 | 1.00 | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 1.00 | 0.90 | - | 0.99 | 0.03 |
| Lost tracking rate (%) | 0.01 | 0.00 | 0.01 | 0.00 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.10 | - | 0.01 | 0.03 |
| Successful tracking rate for model (%) | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.92 | - | 0.99 | 0.02 |
| Lost tracking rate for model (%) | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.08 | - | 0.01 | 0.02 |
| fps | 25.14 | 25.18 | 25.13 | 25.27 | 25.02 | 25.11 | 24.08 | 25.16 | 23.53 | 24.71 | 25.10 | 25.14 | 25.05 | - | 24.89 | 0.51 |
| Parameters | Exp. 1 | Exp. 2 | Exp. 3 | Exp. 4 | Exp. 5 | Exp. 6 | Exp. 7 | Exp. 8 | Exp. 9 | Exp. 10 | Exp. 11 | Exp. 12 | Exp. 13 | Total | Average | Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Experiment status | O | O | O | X | O | O | O | O | O | O | O | O | O | 12 /13 | - | - |
| Target’s travel distance (m) | 29.54 | 29.63 | 29.57 | 28.26 | 29.60 | 29.89 | 30.16 | 30.04 | 30.06 | 30.12 | 29.41 | 29.80 | 29.35 | 385.43 | 29.65 | 0.54 |
| Robot’s travel distance (m) | 27.80 | 27.95 | 27.94 | 26.83 | 27.83 | 27.77 | 27.98 | 27.70 | 27.61 | 27.77 | 27.43 | 27.98 | 27.88 | 360.46 | 27.73 | 0.33 |
| Robot’s travel time (s) | 51.12 | 46.26 | 45.37 | 43.64 | 41.50 | 47.04 | 41.88 | 39.63 | 37.33 | 39.21 | 39.95 | 39.14 | 47.36 | 559.42 | 43.03 | 4.12 |
| Robot’s average velocity (m/s) | 0.54 | 0.60 | 0.62 | 0.61 | 0.67 | 0.59 | 0.67 | 0.70 | 0.74 | 0.71 | 0.69 | 0.71 | 0.59 | - | 0.65 | 0.06 |
| No. of frames (N) | 1299 | 1161 | 1018 | 1069 | 1047 | 1178 | 1066 | 997 | 943 | 923 | 1009 | 981 | 1183 | 13,874 | 1067.23 | 110.50 |
| No. of frames for model () | 1247 | 1159 | 1012 | 1058 | 1044 | 1172 | 1059 | 990 | 934 | 920 | 994 | 975 | 1153 | 13,717 | 1055.15 | 102.06 |
| Successfully tracked (frames) (n) | 1212 | 1159 | 1010 | 1032 | 1044 | 1172 | 1059 | 987 | 934 | 918 | 982 | 975 | 1130 | 13,614 | 1047.23 | 97.14 |
| No. of lost frames by model | 35 | 0 | 2 | 26 | 0 | 0 | 0 | 3 | 0 | 2 | 12 | 0 | 23 | 103.00 | 7.92 | 12.17 |
| Lost frames due to noise | 52 | 2 | 6 | 11 | 3 | 6 | 7 | 7 | 9 | 3 | 15 | 6 | 30 | 157.00 | 12.08 | 14.11 |
| Lost track of the target (frames) | 87 | 2 | 8 | 37 | 3 | 6 | 7 | 10 | 9 | 5 | 27 | 6 | 53 | 260.00 | 20.00 | 25.22 |
| Successfully tracked (s) | 47.69 | 46.18 | 45.01 | 42.13 | 41.38 | 46.80 | 41.60 | 39.23 | 36.97 | 39.00 | 38.88 | 38.90 | 45.24 | 549.01 | 42.23 | 3.65 |
| Lost track of the target (s) | 3.42 | 0.08 | 0.36 | 1.51 | 0.12 | 0.24 | 0.27 | 0.40 | 0.36 | 0.21 | 1.07 | 0.24 | 2.12 | 10.40 | 0.80 | 0.99 |
| Successful tracking rate (%) | 0.93 | 1.00 | 0.99 | - | 1.00 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.97 | 0.99 | 0.96 | - | 0.98 | 0.02 |
| Lost tracking rate (%) | 0.07 | 0.00 | 0.01 | - | 0.00 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.03 | 0.01 | 0.04 | - | 0.02 | 0.02 |
| Successful tracking rate for model (%) | 0.97 | 1.00 | 1.00 | - | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 1.00 | 0.98 | - | 0.99 | 0.01 |
| Lost tracking rate for model (%) | 0.03 | 0.00 | 0.00 | - | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.02 | - | 0.01 | 0.01 |
| fps | 25.41 | 25.10 | 22.44 | 24.49 | 25.23 | 25.04 | 25.45 | 25.16 | 25.26 | 23.54 | 25.25 | 25.06 | 24.98 | - | 24.80 | 0.95 |
| Parameters | Exp. 1 | Exp. 2 | Exp. 3 | Exp. 4 | Exp. 5 | Exp. 6 | Exp. 7 | Exp. 8 | Exp. 9 | Exp. 10 | Exp. 11 | Exp. 12 | Exp. 13 | Total | Average | Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Experiment status | O | O | O | O | O | O | X | O | O | O | O | X | O | 11 /13 | - | - |
| Target’s travel distance (m) | 29.73 | 29.31 | 29.80 | 28.93 | 28.89 | 28.83 | 20.06 | 29.62 | 29.25 | 29.26 | 29.72 | 20.44 | 28.88 | 362.70 | 27.90 | 3.41 |
| Robot’s travel distance (m) | 27.78 | 27.37 | 26.18 | 27.51 | 27.55 | 27.38 | 19.22 | 27.27 | 27.06 | 27.17 | 27.79 | 19.64 | 27.49 | 339.40 | 26.11 | 2.99 |
| Robot’s travel time (s) | 37.20 | 39.55 | 38.90 | 39.06 | 40.63 | 43.12 | 38.18 | 42.21 | 39.14 | 38.47 | 41.23 | 33.10 | 40.41 | 511.21 | 39.32 | 2.50 |
| Robot’s average velocity (m/s) | 0.75 | 0.69 | 0.67 | 0.70 | 0.68 | 0.64 | 0.50 | 0.65 | 0.69 | 0.71 | 0.67 | 0.59 | 0.68 | - | 0.66 | 0.06 |
| No. of frames (N) | 900 | 967 | 951 | 947 | 1013 | 1064 | 937 | 977 | 904 | 938 | 977 | 799 | 973 | 12,347 | 950 | 62.57 |
| No. of frames for model () | 890 | 898 | 896 | 898 | 965 | 994 | 859 | 909 | 867 | 901 | 923 | 763 | 942 | 11,705 | 900 | 55.60 |
| Successfully tracked (frames) (n) | 873 | 881 | 861 | 875 | 953 | 954 | 839 | 877 | 857 | 886 | 921 | 745 | 938 | 11,460 | 882 | 55.33 |
| No. of lost frames by model | 17 | 17 | 35 | 23 | 12 | 40 | 20 | 32 | 10 | 15 | 2 | 18 | 4 | 245 | 19 | 11.37 |
| Lost frames due to noise | 10 | 69 | 55 | 49 | 48 | 70 | 78 | 68 | 37 | 37 | 54 | 36 | 31 | 642 | 49 | 19.16 |
| Lost track of the target (frames) | 27 | 86 | 90 | 72 | 60 | 110 | 98 | 100 | 47 | 52 | 56 | 54 | 35 | 887 | 68 | 26.43 |
| Successfully tracked (s) | 36.08 | 36.04 | 35.22 | 36.09 | 38.22 | 38.66 | 34.19 | 37.89 | 37.10 | 36.34 | 38.87 | 30.86 | 38.96 | 474.53 | 36.50 | 2.25 |
| Lost track of the target (s) | 1.12 | 3.52 | 3.68 | 2.97 | 2.41 | 4.46 | 3.99 | 4.32 | 2.03 | 2.13 | 2.36 | 2.24 | 1.45 | 36.69 | 2.82 | 1.09 |
| Successful tracking rate (%) | 0.97 | 0.91 | 0.91 | 0.92 | 0.94 | 0.90 | - | 0.90 | 0.95 | 0.94 | 0.94 | - | 0.96 | - | 0.93 | 0.03 |
| Lost tracking rate (%) | 0.03 | 0.09 | 0.09 | 0.08 | 0.06 | 0.10 | - | 0.10 | 0.05 | 0.06 | 0.06 | - | 0.04 | - | 0.07 | 0.03 |
| Successful tracking rate for model (%) | 0.98 | 0.98 | 0.96 | 0.97 | 0.99 | 0.96 | - | 0.96 | 0.99 | 0.98 | 1.00 | - | 1.00 | - | 0.98 | 0.01 |
| Lost tracking rate for model (%) | 0.02 | 0.02 | 0.04 | 0.03 | 0.01 | 0.04 | - | 0.04 | 0.01 | 0.02 | 0.00 | - | 0.00 | - | 0.02 | 0.01 |
| fps | 24.20 | 24.45 | 24.44 | 24.24 | 24.93 | 24.67 | 24.54 | 23.15 | 23.10 | 24.38 | 23.70 | 24.14 | 24.08 | - | 24.16 | 0.55 |
| Parameters | Exp. 1 | Exp. 2 | Exp. 3 | Exp. 4 | Exp. 5 | Exp. 6 | Exp. 7 | Exp. 8 | Exp. 9 | Exp. 10 | Exp. 11 | Exp. 12 | Exp. 13 | Total | Average | Std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Experiment status | O | X | O | O | X | O | O | O | X | X | X | O | O | 8 /13 | - | - |
| Target’s travel distance (m) | 29.81 | 20.15 | 29.38 | 29.30 | 19.85 | 28.99 | 29.49 | 30.07 | 24.17 | 24.59 | 20.25 | 28.83 | 28.67 | 343.54 | 26.43 | 4.06 |
| Robot’s travel distance (m) | 27.77 | 19.20 | 27.39 | 27.54 | 19.03 | 27.26 | 27.74 | 28.00 | 23.41 | 23.69 | 19.25 | 27.95 | 27.82 | 326.03 | 25.08 | 3.70 |
| Robot’s travel time (s) | 41.06 | 46.16 | 38.77 | 41.12 | 62.76 | 38.14 | 38.17 | 39.44 | 38.26 | 34.74 | 49.97 | 45.45 | 49.79 | 563.83 | 43.37 | 7.50 |
| Robot’s average velocity (m/s) | 0.68 | 0.42 | 0.71 | 0.67 | 0.30 | 0.71 | 0.73 | 0.71 | 0.61 | 0.68 | 0.39 | 0.61 | 0.56 | - | 0.60 | 0.14 |
| No. of frames (N) | 983 | 1173 | 976 | 1040 | 1502 | 936 | 961 | 978 | 892 | 843 | 1262 | 1126 | 1253 | 13,925 | 1071.15 | 184.73 |
| No. of frames for model () | 941 | 818 | 913 | 997 | 1181 | 906 | 935 | 944 | 863 | 838 | 1044 | 1049 | 1144 | 12,573 | 967.15 | 111.51 |
| Successfully tracked (frames) (n) | 888 | 656 | 908 | 921 | 639 | 905 | 883 | 888 | 765 | 782 | 756 | 991 | 1059 | 11,041 | 849.31 | 123.09 |
| No. of lost frames by model | 53 | 162 | 5 | 76 | 542 | 1 | 52 | 56 | 98 | 56 | 288 | 58 | 85 | 1532 | 117.85 | 147.25 |
| Lost frames due to noise | 42 | 355 | 63 | 43 | 321 | 30 | 26 | 34 | 29 | 5 | 218 | 77 | 109 | 1352 | 104.00 | 117.25 |
| Lost track of the target (frames) | 95 | 517 | 68 | 119 | 863 | 31 | 78 | 90 | 127 | 61 | 506 | 135 | 194 | 2884 | 221.85 | 249.49 |
| Successfully tracked (s) | 37.09 | 25.81 | 36.07 | 36.41 | 26.70 | 36.87 | 35.07 | 35.81 | 32.81 | 32.23 | 29.93 | 40.00 | 42.08 | 446.90 | 34.38 | 4.77 |
| Lost track of the target (s) | 3.97 | 20.35 | 2.70 | 4.70 | 36.06 | 1.26 | 3.10 | 3.63 | 5.45 | 2.51 | 20.04 | 5.45 | 7.71 | 116.92 | 8.99 | 10.24 |
| Successful tracking rate (%) | 0.90 | - | 0.93 | 0.89 | - | 0.97 | 0.92 | 0.91 | - | - | - | 0.88 | 0.85 | - | 0.90 | 0.04 |
| Lost tracking rate (%) | 0.10 | - | 0.07 | 0.11 | - | 0.03 | 0.08 | 0.09 | - | - | - | 0.12 | 0.15 | - | 0.10 | 0.04 |
| Successful tracking rate for model (%) | 0.94 | - | 0.99 | 0.92 | - | 1.00 | 0.94 | 0.94 | - | - | - | 0.94 | 0.93 | - | 0.95 | 0.03 |
| Lost tracking rate for model (%) | 0.06 | - | 0.01 | 0.08 | - | 0.00 | 0.06 | 0.06 | - | - | - | 0.06 | 0.07 | - | 0.05 | 0.03 |
| fps | 23.94 | 25.41 | 25.17 | 25.29 | 23.93 | 24.54 | 25.17 | 24.80 | 23.32 | 24.27 | 25.26 | 24.77 | 25.16 | - | 24.70 | 0.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Algabri, R.; Choi, M.-T. Online Boosting-Based Target Identification among Similar Appearance for Person-Following Robots. Sensors 2022, 22, 8422. https://doi.org/10.3390/s22218422
Algabri R, Choi M-T. Online Boosting-Based Target Identification among Similar Appearance for Person-Following Robots. Sensors. 2022; 22(21):8422. https://doi.org/10.3390/s22218422
Chicago/Turabian StyleAlgabri, Redhwan, and Mun-Taek Choi. 2022. "Online Boosting-Based Target Identification among Similar Appearance for Person-Following Robots" Sensors 22, no. 21: 8422. https://doi.org/10.3390/s22218422
APA StyleAlgabri, R., & Choi, M.-T. (2022). Online Boosting-Based Target Identification among Similar Appearance for Person-Following Robots. Sensors, 22(21), 8422. https://doi.org/10.3390/s22218422