
Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator

 , , , and
, , , and
Abstract
1. Introduction
1.1. Related Work
1.2. Contribution
- An RL agent capable of learning the desired policy for three types of intersections. Most approaches in the literature use RL to estimate the intentions of the adversarial vehicles, and the agent uses this information to cross an intersection. In our proposal, without any prior information about the scenario, our agent infers not only the intentions of the adversarial vehicles but also the type of intersection.
- A PPO algorithm with a preprocessing layer for the tactical level. We compare the training performance and the results obtained for both architectures with and without the features extractor. This module is introduced using a hybrid AD architecture, and the whole architecture is validated in a realistic simulator, which includes vehicle dynamics. This approach is an alternative to the trendy end-to-end approaches, showing good results in complex scenarios where end-to-end options do not converge.
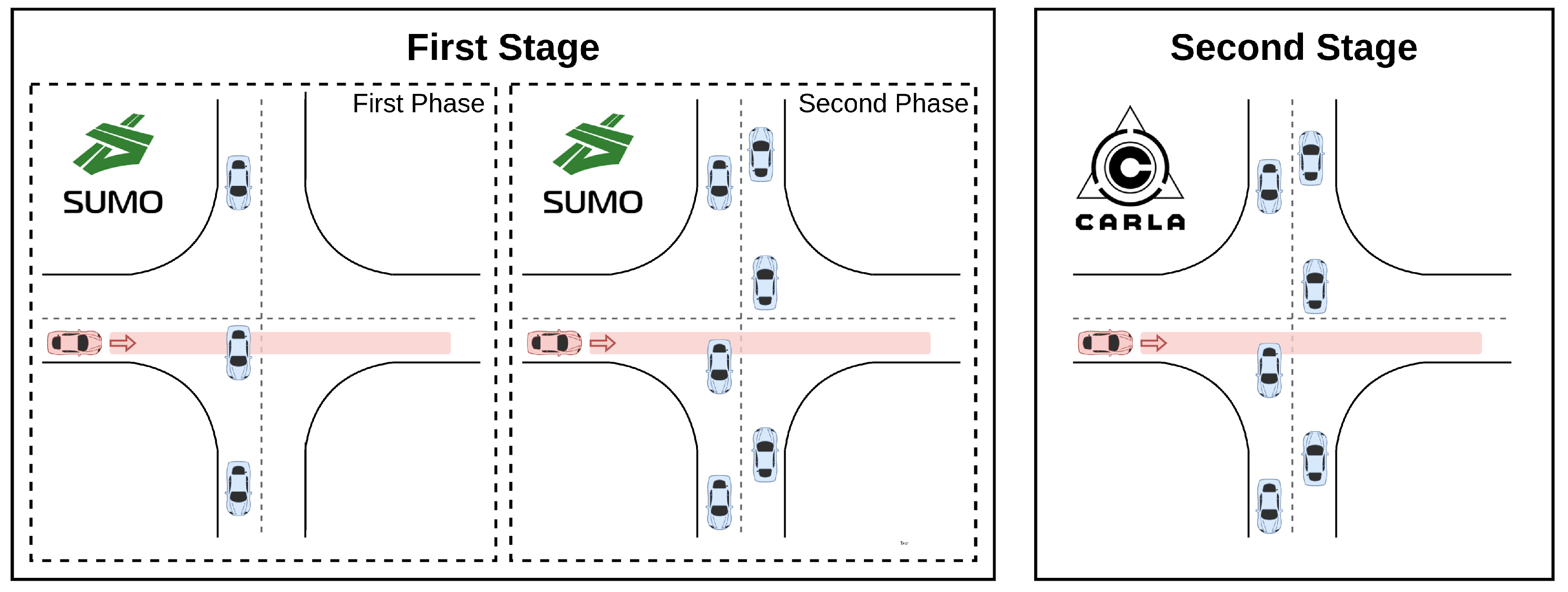
- A novel two-stage training method. We use a model trained in a light simulator as a prior model for training in a realistic simulator. This allows convergence in CARLA within a reasonable training time.
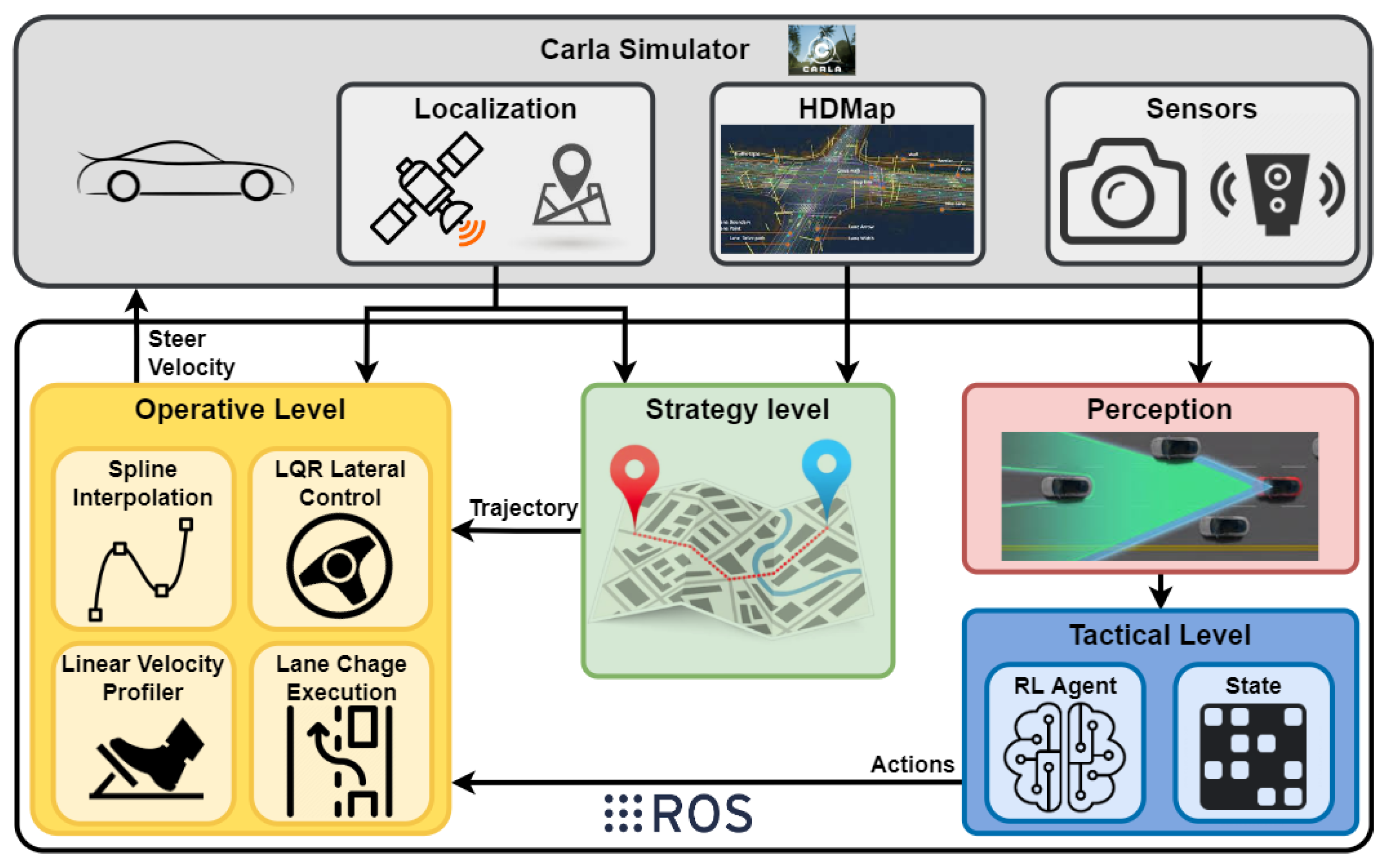
2. Hybrid Architecture
2.1. Strategy Level
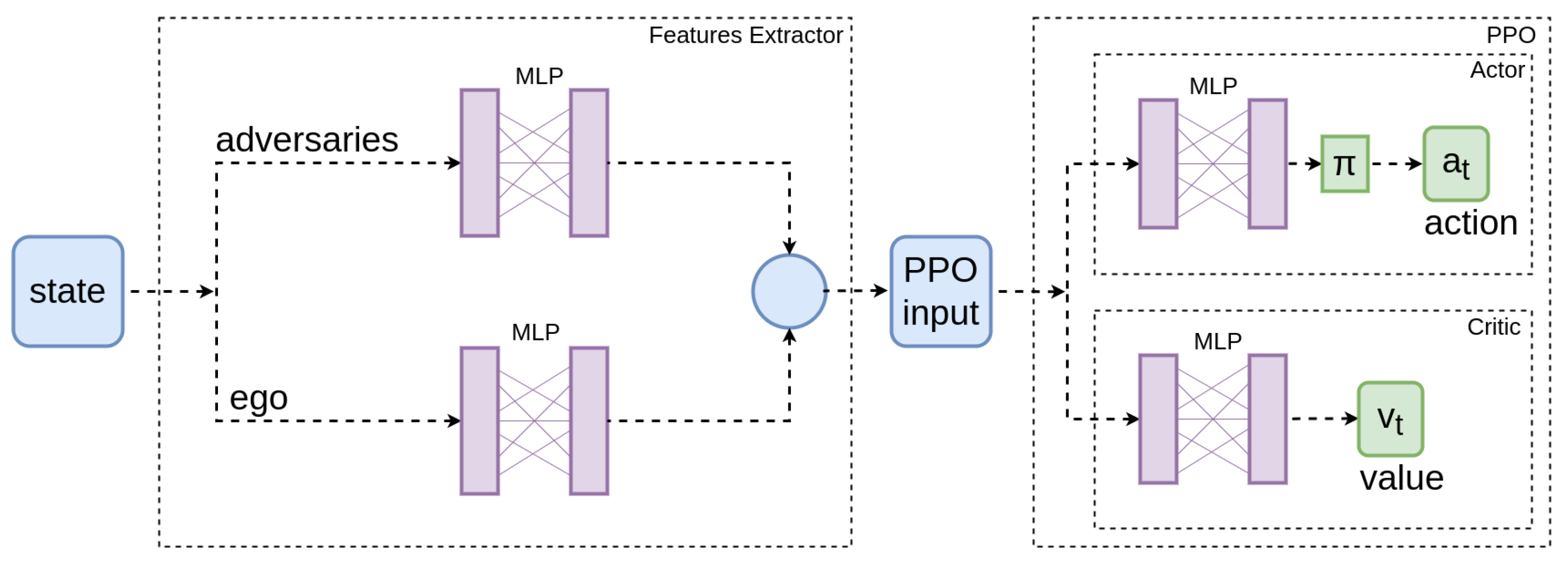
2.2. Tactical Level
2.3. Operative Level
2.4. Perception
3. Background
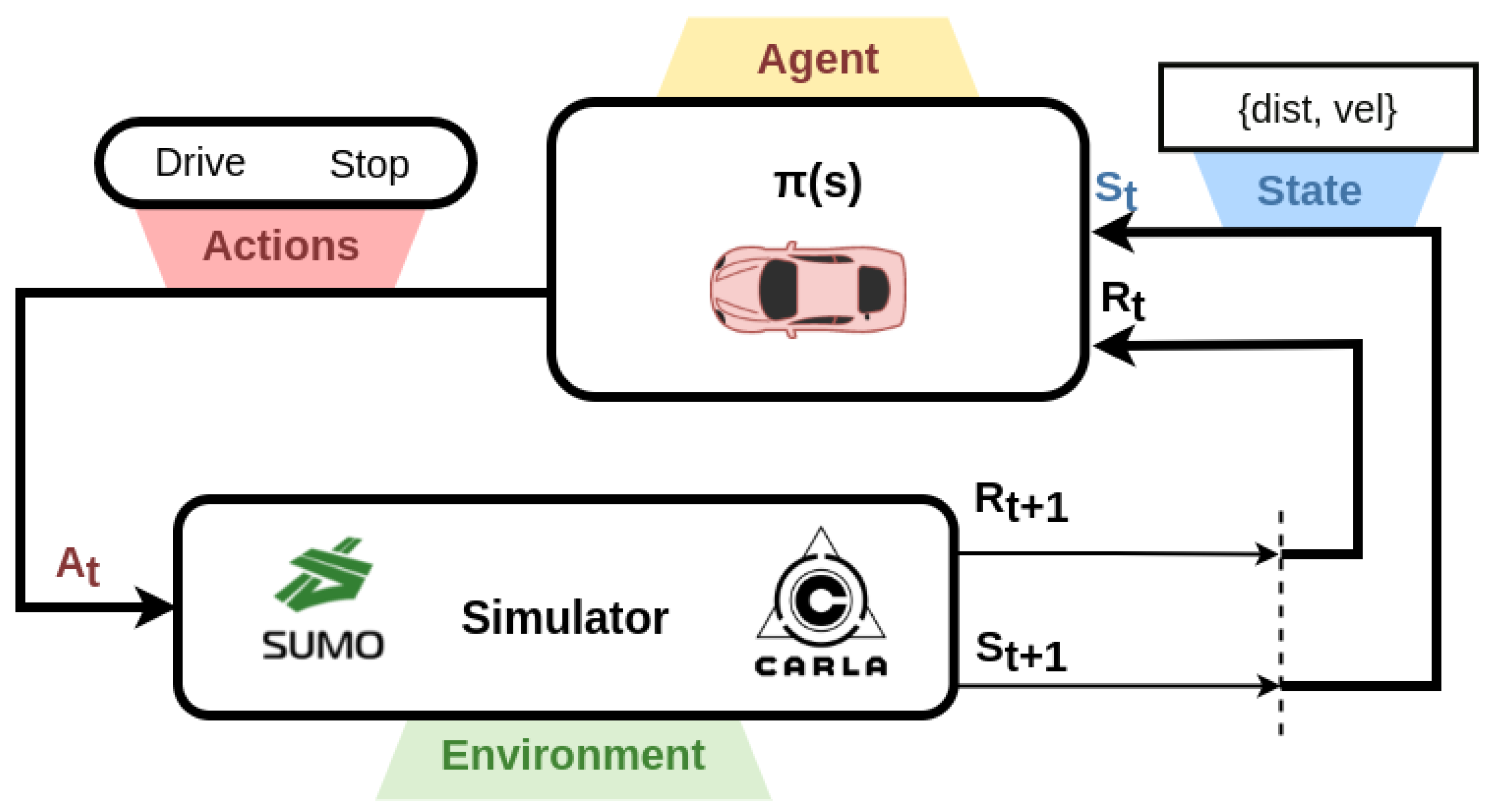
4. Reinforcement Learning at Intersections
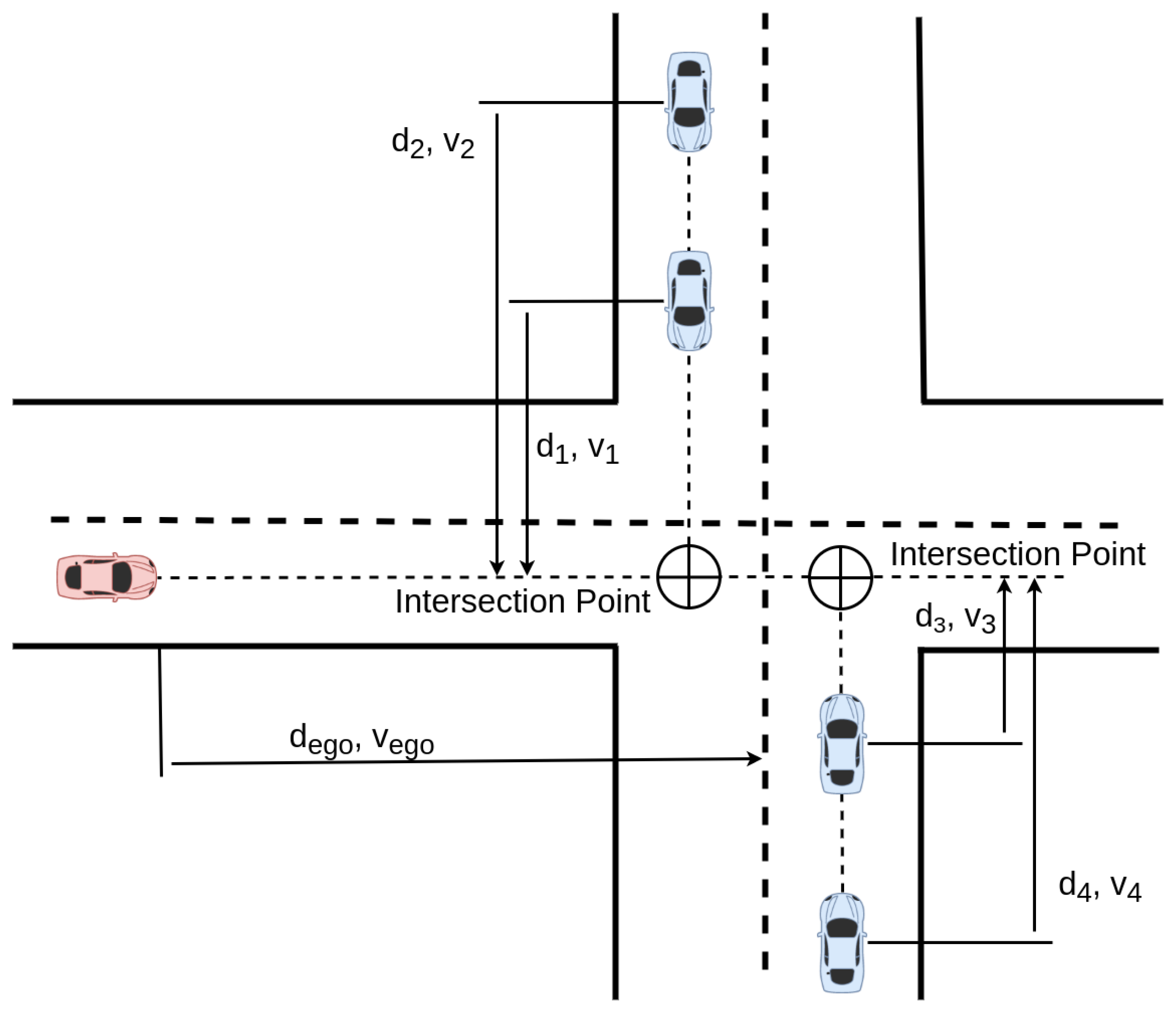
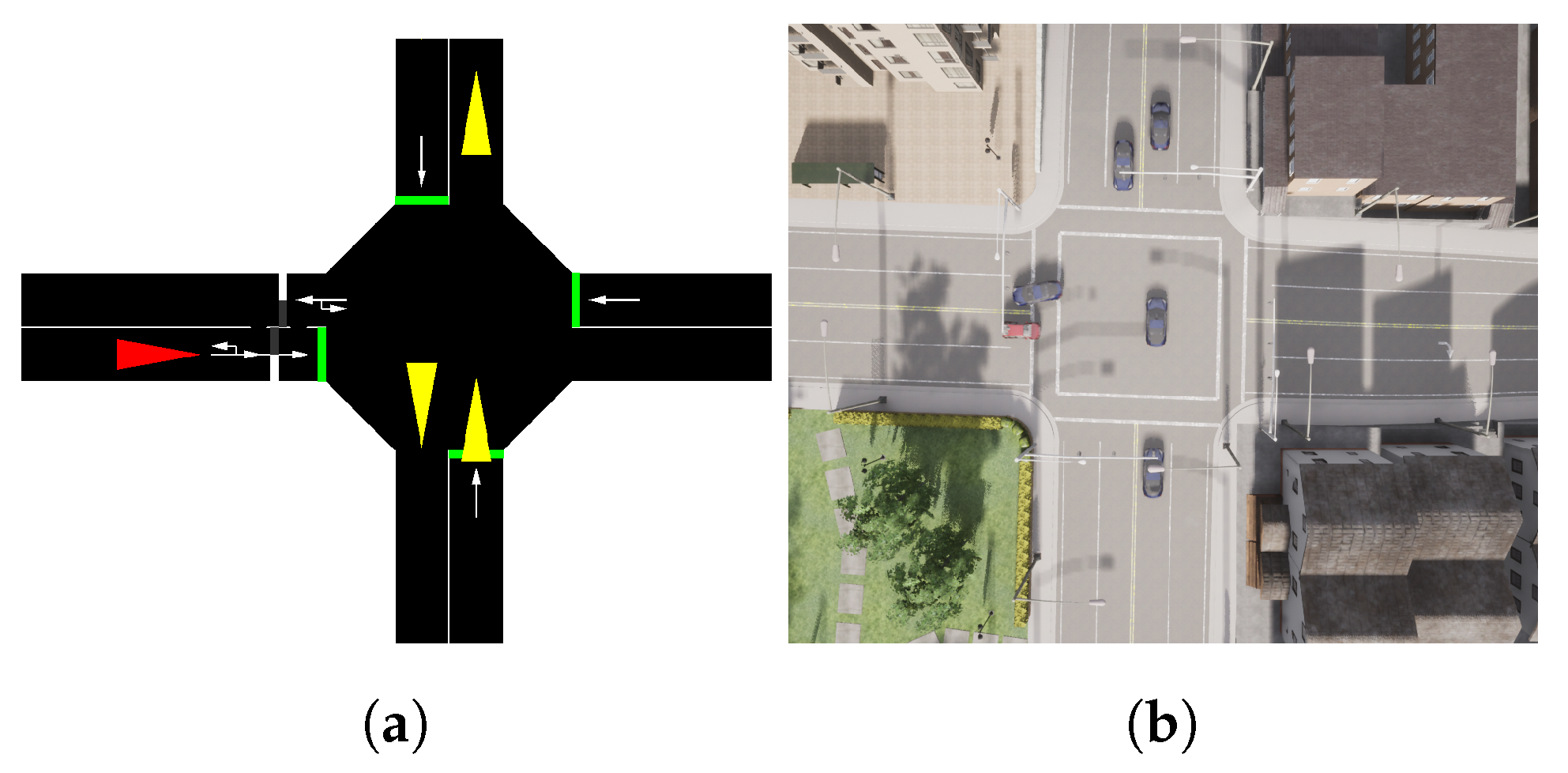
4.1. Modeling Intersections
4.1.1. State
4.1.2. Action
4.1.3. Reward
- Reward based on the velocity: ;
- Reward for crossing the intersection: ;
- Penalty for collisions: ;
- Penalty relative to the episode duration: .
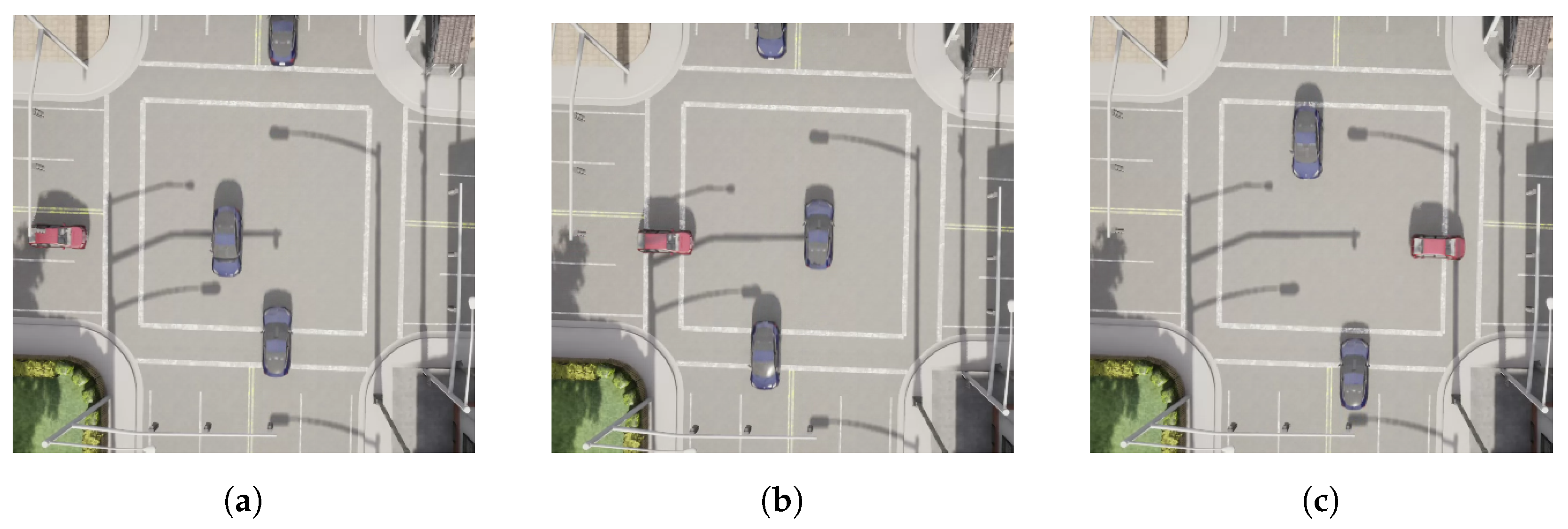
4.2. Intersection Scenarios
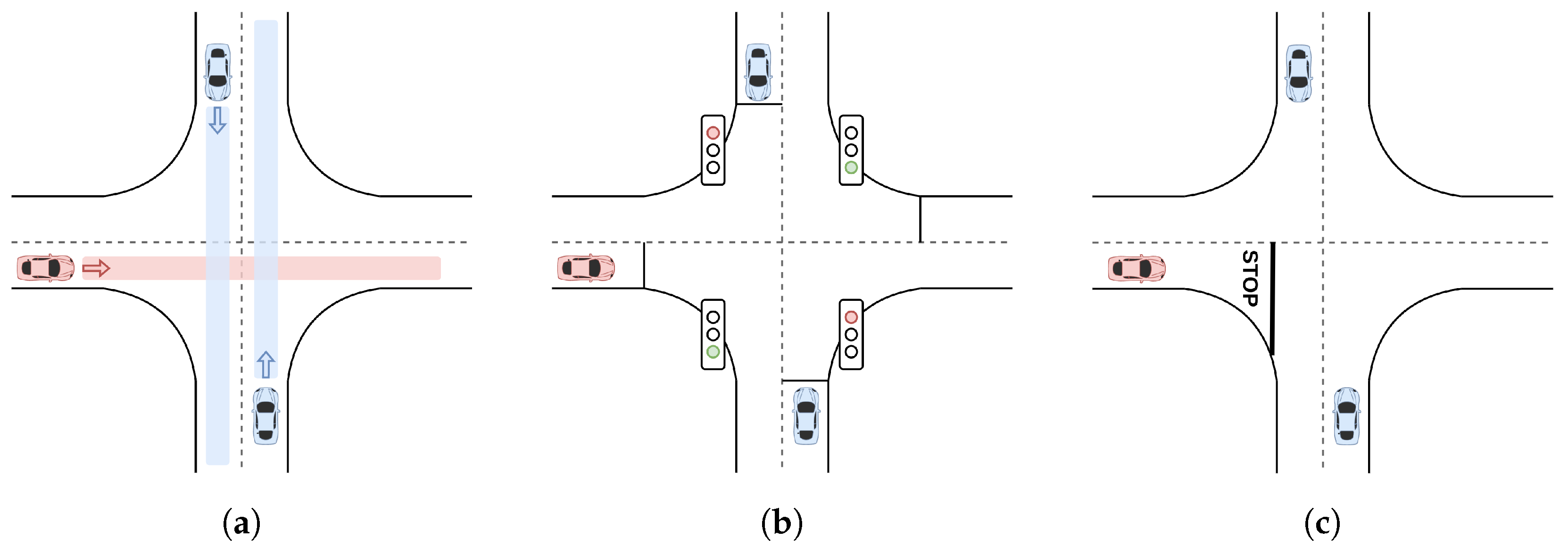
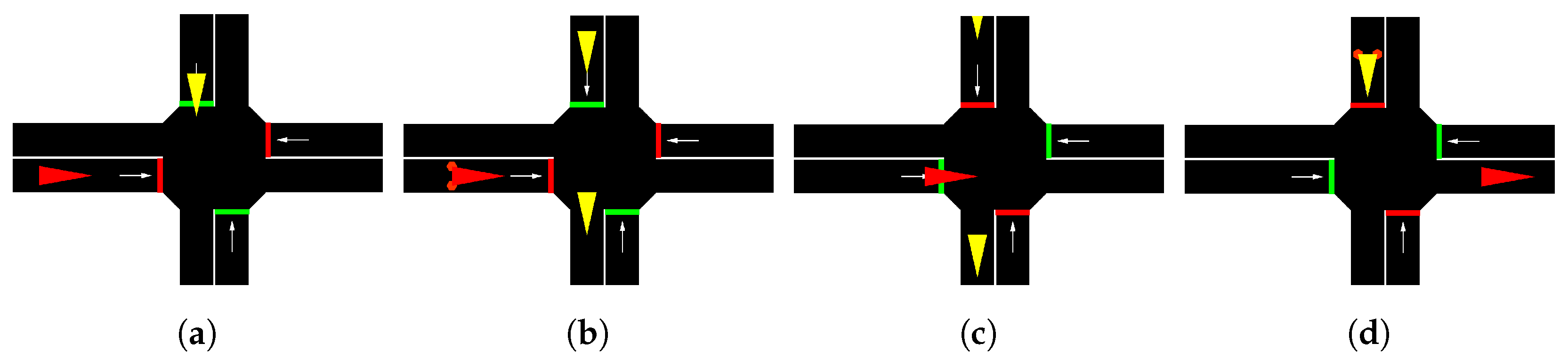
4.2.1. Uncontrolled Intersection
4.2.2. Traffic Light Intersection
4.2.3. Stop Sign Intersection
4.3. Neural Network Architecture
5. Experiments
5.1. Training the Algorithm
5.1.1. SUMO Simulator
5.1.2. CARLA Simulator
5.2. Evaluation Metrics
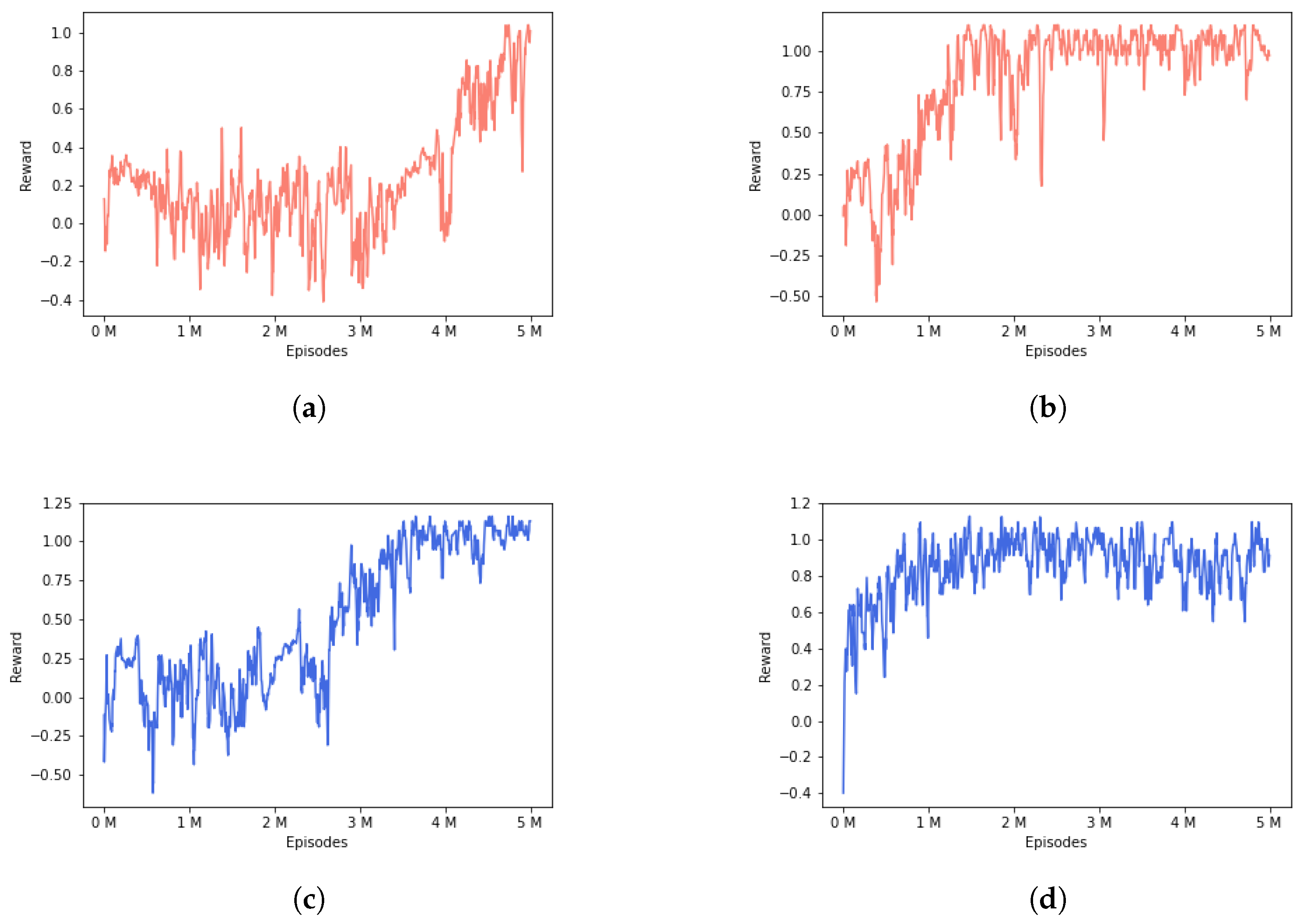
5.3. Results
5.4. Discussion
6. Conclusions and Future Works
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Werneke, J.; Vollrath, M. How do environmental characteristics at intersections change in their relevance for drivers before entering an intersection: Analysis of drivers’ gaze and driving behavior in a driving simulator study. Cogn. Technol. 2014, 16, 157–169. [Google Scholar] [CrossRef]
- NHTSA. Traffic Safety Facts 2019; National Highway Traffic Safety Administration: Washington, DC, USA, 2019.
- Li, G.; Li, S.; Li, S.; Qin, Y.; Cao, D.; Qu, X.; Cheng, B. Deep Reinforcement Learning Enabled Decision-Making for Autonomous Driving at Intersections. Automot. Innov. 2020, 3, 374–385. [Google Scholar] [CrossRef]
- Qiao, Z.; Muelling, K.; Dolan, J.M.; Palanisamy, P.; Mudalige, P. Automatically Generated Curriculum based Reinforcement Learning for Autonomous Vehicles in Urban Environment. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1233–1238. [Google Scholar] [CrossRef]
- Aoki, S.; Rajkumar, R. V2V-based Synchronous Intersection Protocols for Mixed Traffic of Human-Driven and Self-Driving Vehicles. In Proceedings of the 2019 IEEE 25th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Hangzhou, China, 18–21 August 2019; pp. 1–11. [Google Scholar] [CrossRef]
- Duan, X.; Jiang, H.; Tian, D.; Zou, T.; Zhou, J.; Cao, Y. V2I based environment perception for autonomous vehicles at intersections. China Commun. 2021, 18, 1–12. [Google Scholar] [CrossRef]
- Isele, D.; Rahimi, R.; Cosgun, A.; Subramanian, K.; Fujimura, K. Navigating Occluded Intersections with Autonomous Vehicles Using Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2034–2039. [Google Scholar] [CrossRef]
- Cosgun, A.; Ma, L.; Chiu, J.; Huang, J.; Demir, M.; Anon, A.; Lian, T.; Tafish, H.; Al-Stouhi, S. Towards full automated drive in urban environments: A demonstration in GoMentum Station, California. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV 2017), Los Angeles, CA, USA, 11–14 June 2017; Zhang, W.B., de La Fortelle, A., Acarman, T., Yang, M., Eds.; IEEE, Institute of Electrical and Electronics Engineers: Manhattan, NY, USA, 2017; pp. 1811–1818. [Google Scholar] [CrossRef]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end Learning of Driving Models from Large-scale Video Datasets. arXiv 2016, arXiv:1612.01079. [Google Scholar]
- Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.; Lam, V.; Bewley, A.; Shah, A. Learning to Drive in a Day. arXiv 2018, arXiv:1807.00412. [Google Scholar]
- Anzalone, L.; Barra, S.; Nappi, M. Reinforced Curriculum Learning For Autonomous Driving In Carla. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3318–3322. [Google Scholar] [CrossRef]
- Behrisch, M.; Bieker, L.; Erdmann, J.; Krajzewicz, D. SUMO—Simulation of Urban MObility: An overview. In Proceedings of the SIMUL 2011, Third International Conference on Advances in System Simulation, Barcelona, Spain, 23–28 October 2011; pp. 63–68. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; Volume 78, pp. 1–16. [Google Scholar]
- Wang, P.; Li, H.; Chan, C. Continuous Control for Automated Lane Change Behavior Based on Deep Deterministic Policy Gradient Algorithm. arXiv 2019, arXiv:1906.02275. [Google Scholar]
- Paden, B.; Cáp, M.; Yong, S.Z.; Yershov, D.S.; Frazzoli, E. A Survey of Motion Planning and Control Techniques for Self-driving Urban Vehicles. arXiv 2016, arXiv:1604.07446. [Google Scholar] [CrossRef]
- González, D.; Pérez, J.; Milanés, V.; Nashashibi, F. A Review of Motion Planning Techniques for Automated Vehicles. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1135–1145. [Google Scholar] [CrossRef]
- Mirchevska, B.; Pek, C.; Werling, M.; Althoff, M.; Boedecker, J. High-level Decision Making for Safe and Reasonable Autonomous Lane Changing using Reinforcement Learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2156–2162. [Google Scholar] [CrossRef]
- Ye, F.; Zhang, S.; Wang, P.; Chan, C. A Survey of Deep Reinforcement Learning Algorithms for Motion Planning and Control of Autonomous Vehicles. arXiv 2021, arXiv:2105.14218. [Google Scholar]
- Bojarski, M.; Testa, D.D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Moghadam, M.; Alizadeh, A.; Tekin, E.; Elkaim, G.H. An End-to-end Deep Reinforcement Learning Approach for the Long-term Short-term Planning on the Frenet Space. arXiv 2020, arXiv:2011.13098. [Google Scholar]
- Chopra, R.; Roy, S. End-to-End Reinforcement Learning for Self-driving Car. In Advanced Computing and Intelligent Engineering; Springer: Singapore, 2020; pp. 53–61. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Tram, T.; Jansson, A.; Grönberg, R.; Ali, M.; Sjöberg, J. Learning Negotiating Behavior Between Cars in Intersections using Deep Q-Learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3169–3174. [Google Scholar] [CrossRef]
- Tram, T.; Batkovic, I.; Ali, M.; Sjöberg, J. Learning When to Drive in Intersections by Combining Reinforcement Learning and Model Predictive Control. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3263–3268. [Google Scholar] [CrossRef]
- Kamran, D.; Lopez, C.F.; Lauer, M.; Stiller, C. Risk-Aware High-level Decisions for Automated Driving at Occluded Intersections with Reinforcement Learning. arXiv 2020, arXiv:2004.04450. [Google Scholar]
- Bouton, M.; Nakhaei, A.; Fujimura, K.; Kochenderfer, M.J. Safe Reinforcement Learning with Scene Decomposition for Navigating Complex Urban Environments. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1469–1476. [Google Scholar] [CrossRef]
- Bouton, M.; Cosgun, A.; Kochenderfer, M.J. Belief state planning for autonomously navigating urban intersections. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 825–830. [Google Scholar] [CrossRef]
- Bouton, M.; Nakhaei, A.; Fujimura, K.; Kochenderfer, M.J. Cooperation-Aware Reinforcement Learning for Merging in Dense Traffic. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3441–3447. [Google Scholar] [CrossRef]
- Shu, K.; Yu, H.; Chen, X.; Chen, L.; Wang, Q.; Li, L.; Cao, D. Autonomous Driving at Intersections: A Critical-Turning-Point Approach for Left Turns. arXiv 2020, arXiv:2003.02409. [Google Scholar]
- Kurzer, K.; Schörner, P.; Albers, A.; Thomsen, H.; Daaboul, K.; Zöllner, J.M. Generalizing Decision Making for Automated Driving with an Invariant Environment Representation using Deep Reinforcement Learning. arXiv 2021, arXiv:2102.06765. [Google Scholar]
- Soviany, P.; Ionescu, R.T.; Rota, P.; Sebe, N. Curriculum Learning: A Survey. arXiv 2021, arXiv:2101.10382. [Google Scholar] [CrossRef]
- Wang, X.; Chen, Y.; Zhu, W. A Survey on Curriculum Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4555–4576. [Google Scholar] [CrossRef]
- Diaz-Diaz, A.; Ocaña, M.; Llamazares, A.; Gómez-Huélamo, C.; Revenga, P.; Bergasa, L.M. HD maps: Exploiting OpenDRIVE potential for Path Planning and Map Monitoring. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 2022. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; p. 5. [Google Scholar]
- Gutiérrez, R.; López-Guillén, E.; Bergasa, L.M.; Barea, R.; Pérez, Ó.; Gómez Huélamo, C.; Arango, J.F.; del Egido, J.; López, J. A Waypoint Tracking Controller for Autonomous Road Vehicles Using ROS Framework. Sensors 2020, 20, 4062. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- van Hasselt, H.; Guez, A.; Hessel, M.; Mnih, V.; Silver, D. Learning values across many orders of magnitude. arXiv 2016. [Google Scholar] [CrossRef]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested traffic states in empirical observations and microscopic simulations. Phys. Rev. E 2000, 62, 1805–1824. [Google Scholar] [CrossRef] [PubMed]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Wegener, A.; Piórkowski, M.; Raya, M.; Hellbrück, H.; Fischer, S.; Hubaux, J.P. TraCI: An Interface for Coupling Road Traffic and Network Simulators. In Proceedings of the 11th Communications and Networking Simulation Symposium, Ottawa, ON, Canada, 14–17 April 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 155–163. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. arXiv 2018, arXiv:1812.05784. [Google Scholar]
- Arango, J.F.; Bergasa, L.M.; Revenga, P.; Barea, R.; López-Guillén, E.; Gómez-Huélamo, C.; Araluce, J.; Gutiérrez, R. Drive-By-Wire Development Process Based on ROS for an Autonomous Electric Vehicle. Sensors 2020, 20, 6121. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phase | Duration (s) | State |
|---|---|---|
| 1 | 20 | GrGr |
| 2 | 2 | yryr |
| 3 | 20 | rGrG |
| 4 | 2 | ryry |
| Traffic Light | Stop Signal | Uncontrolled | Combination | |||||
|---|---|---|---|---|---|---|---|---|
| (%) | (s) | (%) | (s) | (%) | (s) | (%) | (s) | |
| 1-PPO | 53 | 112 | 37 | 93 | 23 | 109 | 30 | 105 |
| 2-PPO | 95 | 67 | 78 | 78 | 87 | 63 | 88 | 71 |
| 1-FEPPO | 61 | 104 | 48 | 82 | 30 | 111 | 37 | 102 |
| 2-FEPPO | 100 | 43 | 90 | 94 | 95 | 55 | 95 | 85 |
| Traffic Light | Stop Signal | Uncontrolled | Combination | |||||
|---|---|---|---|---|---|---|---|---|
| (%) | (s) | (%) | (s) | (%) | (s) | (%) | (s) | |
| SUMO | 78 | 17 | 35 | 19 | 47 | 19 | 50 | 19 |
| CARLA | 83 | 17 | 70 | 19 | 75 | 16 | 78 | 17 |
| Architecture | Success Rate (%) |
|---|---|
| 2-FEPPO | 95 |
| MPC Agent [24] | 95.2 |
| Level-k Agent [28] | 93.8 |
| Sc04 Left Turn [30] | 90.3 |
| Traffic Light | Stop Signal | Uncontrolled | Combination | |||||
|---|---|---|---|---|---|---|---|---|
| (%) | (s) | (%) | (s) | (%) | (s) | (%) | (s) | |
| Ground Truth | 100 | 43 | 90 | 94 | 95 | 55 | 95 | 85 |
| Sensor Data | 96 | 42 | 88 | 92 | 94 | 51 | 91 | 80 |
| Simulator | No. of Episodes | Time (h) |
|---|---|---|
| SUMO | 30 k | 5 |
| CARLA (estimated) | 30 k | 1650 |
| SUMO + CARLA | 30 k + 1 k | 10.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutiérrez-Moreno, R.; Barea, R.; López-Guillén, E.; Araluce, J.; Bergasa, L.M. Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator. Sensors 2022, 22, 8373. https://doi.org/10.3390/s22218373
Gutiérrez-Moreno R, Barea R, López-Guillén E, Araluce J, Bergasa LM. Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator. Sensors. 2022; 22(21):8373. https://doi.org/10.3390/s22218373
Chicago/Turabian StyleGutiérrez-Moreno, Rodrigo, Rafael Barea, Elena López-Guillén, Javier Araluce, and Luis M. Bergasa. 2022. "Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator" Sensors 22, no. 21: 8373. https://doi.org/10.3390/s22218373
APA StyleGutiérrez-Moreno, R., Barea, R., López-Guillén, E., Araluce, J., & Bergasa, L. M. (2022). Reinforcement Learning-Based Autonomous Driving at Intersections in CARLA Simulator. Sensors, 22(21), 8373. https://doi.org/10.3390/s22218373