1. Introduction
In an in-line holographic microscope setup, the coherent light illuminates a dilute sample. Thus a large part of the light travels freely through the medium, which therefore acts as a reference beam, while the other part is diffracted by the objects within the sample. A camera sensor records the interference pattern of the reference and the diffracted waves, which results in the (raw) hologram image. This captured in-line hologram—unlike a conventional image—records all the volumetric information about the sample. Note that a CCD sensor can only record the intensity of the light; thus, the phase information is missing. Therefore, the numerically reconstructed image of this hologram at a special distance—called the reconstructed hologram—is biased by these missing, overlapping terms (e.g. twin image). Although there are phase recovery algorithms, these are iterative, computationally expensive procedures.
Several deep learning methods have been introduced recently in the fields of coherent imaging and digital holographic microscopy (DHM), showing superior performance to their conventional algorithmic counterparts. To name a few, it was applied to phase recovery and hologram reconstruction [
1,
2,
3,
4,
5], to phase-unwrapping [
6,
7], to label-free sensing [
8,
9,
10], to super-resolution [
11], to object focusing [
12], and even to make the transformation between coherent and incoherent imaging domains [
13]. In our last work [
14] we showed that the transformation between the domains is possible even without a paired dataset. Object classification is a common problem in DHM, as a holographic microscope is peculiarly suitable to inspect and measure large volumes rapidly, and classify/count micro-sized objects in a sample at a high speed. In [
15], the authors employ a lens-free digital in-line holographic microscope to classify cells labeled with molecular-specific microbeads using deep learning techniques and show that the classification is feasible using the measured raw holograms only, although with lower performance compared to the case when reconstructed holograms are used. Zhu et al. in [
16,
17] developed a deep learning-based holographic classification method that operates directly on raw holographic data to obtain quantitative information about microplastic pollutants. MacNeil et al. in [
18] utilized an in-line holographic microscope and deep learning solutions to classify planktons using reconstructed holograms.
3D convolutional neural networks are mainly applied in the field of medical imaging [
19,
20] and autonomous driving [
21]; to our best knowledge, they have not been employed for DHM classification tasks yet. The nearest field where 3D CNN was applied is near-field acoustical holography [
22,
23].
The design of the convolutional neural network (CNN) was strongly influenced by the human visual system and functions very well on natural images (with incoherent illumination). We argue that as our eyes are not accustomed to coherent lighting conditions and hologram images, likewise the CNN is not optimal for hologram processing. We hypothesize that a convolutional neural network cannot effectively take advantage of the globally encoded volumetric information present in a hologram as a CNN works on local features inherently by its design; thus, it is preferable to apply preprocessing steps that extract the depth information. This can be done by numerically propagating the single input hologram to multiple distances and then concatenating them along a new depth dimension resulting in a volume. Next, this volumetric data—extracted from the single hologram—can be processed with a 3D CNN. The information content of the volumetric input is not increased but it is more explicit and decompressed, and more suitable for a CNN architecture, we claim. To validate our hypothesis, we construct a database for a hologram object classification task. After this, we implement a 3D CNN method—which has a volumetric input—and the corresponding 2D CNN—which has a single hologram input—to compare their performance. The automatic hologram focusing algorithm is not always accurate, therefore, the robustness of the classifier to slightly defocused inputs is a crucial factor that is also investigated in this work. The main contributions of this study are as follows:
We debate that a CNN is optimal for utilizing all information present in a hologram and support this presumption with the results.
We show that extracting the depth information by reconstructing a volume and feeding it to a 3D-CNN-based architecture improves the classification accuracy compared to the 2D-CNN baseline which operates on a single reconstructed hologram.
We show that our 3D-model is inherently more robust to slightly defocused samples.
Finally, we propose a novel hologram augmentation technique—called hologram defocus augmentation—that improves the defocus tolerance of both methods.
2. Materials and Methods
In this study, we use an in-line holographic microscope system. Our setup measures background-subtracted holograms of samples in a flow-through cell. After the raw hologram is captured, the objects present in the volume are localized, separately focused, and then cropped. As the applied automatic focusing algorithm is not always accurate it is manually corrected in the process of creating the training database.
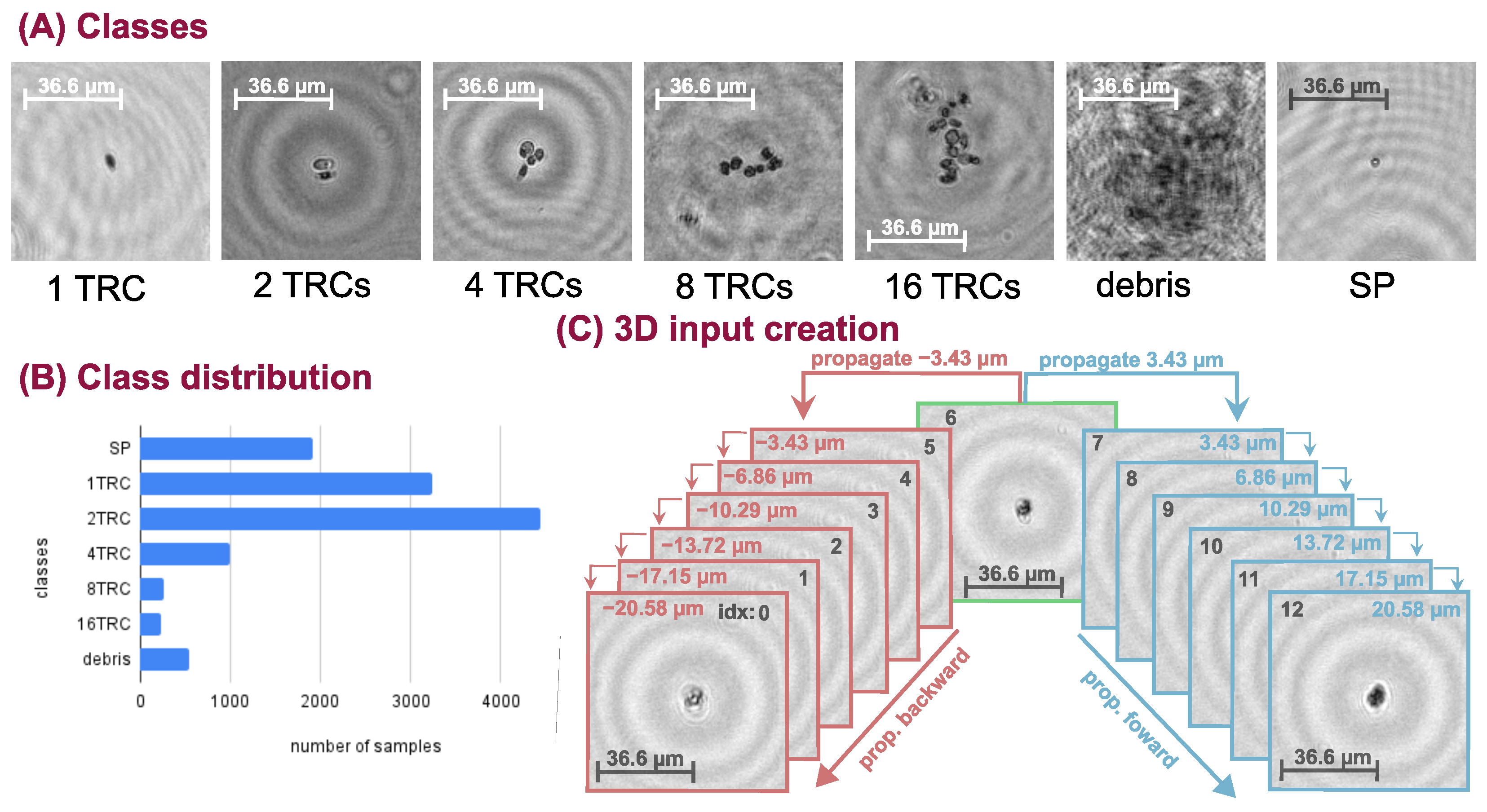
We inspected the performance of the deep neural networks (DNN) on a challenging real-life problem: the classification of conglomerated objects into number-of-objects categories (i.e. quantifying the objects). The chosen specimen is an alga, namely Phaeodactylum tricornutum (TRC), which tends to cluster together mainly in the power of two groups. Thus, we recorded samples with our holographic microscope system and constructed a training database containing 1, 2, 4, 8, and 16 TRC classes. Additionally, we extended the database with two more categories: (1) small particles (SP) that are not TRCs but consistently smaller objects, and (2) poor-quality images or unidentifiable objects (debris). The captured hologram objects were manually focused. An example from each class is shown in
Figure 1A. Usually, the larger the conglomerate the less numerous its occurrence is, therefore the database is imbalanced. The sample distribution can be seen in
Figure 1B. Class weighting is applied in the loss function to balance the learning and the uneven database during neural network training.
We should mention that grouping into powers of two is an approximation and there are occurrences in-between categories (e.g., 3, 5, 11 conglomerates) which are placed into the closest neighboring classes. The labeling of the data is challenging and might be imprecise because it is often not clear to which class the given hologram belongs.
The objects in the hologram are digitally focused/reconstructed with the angular spectrum method [
24] and then cropped with a 128 × 128 window around their centers. The reconstruction results in a complex image (
), for which absolute value (
) and angle (
) is calculated and stored as amplitude and phase images. Our database consists of such hologram amplitude and phase image pairs arranged in (C = 2, H = 128, W = 128) sized arrays, where C denotes the channel number, H denotes the height, and W denotes the width.
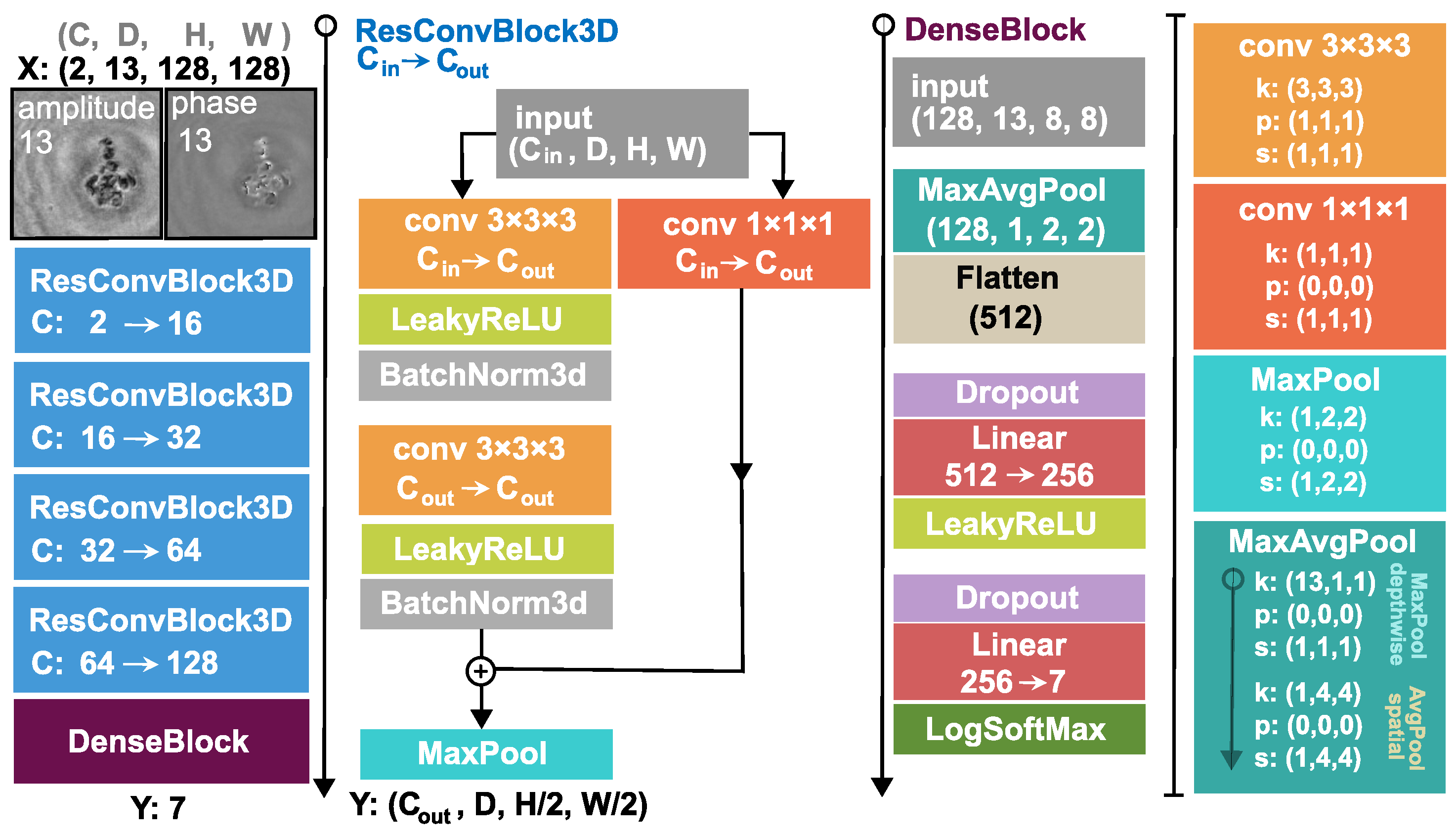
Our proposed 3D architecture is explained in
Figure 2. and the construction of its input is illustrated in
Figure 1C. We take a sample from the dataset and propagate it 6 steps forward and 6 steps backward and concatenate them along a new dimension resulting in a tensor of shape (C = 2, D = 13, H = 128, W = 128), where D stands for the depth and one step is 3.43
m. The backward and forward propagation terms are used to denote the direction of the propagation. For example, as shown in
Figure 1C, if we propagate with 3.43
m that is a forward step and if we propagate with −3.43
m that is a backward step. This volumetric input is fed into the 3D DNN, which comprises four 3D residual convolution blocks (ResConvBlock) and a fully connected head (DenseBlock), which computes the class probabilities. The ResConvBlock consists of two 3D convolutions with LeakyReLU activations and batch norms. There is a skip connection after the convolutions and before the MaxPool operation. To accomplish this, we can not simply add the input to the output features because they have different channel numbers. Therefore, the input is projected with a 1 × 1 × 1 kernel 3D convolution into an output-sized tensor so they can be added (During neural network training, the gradient can backpropagate through the skip branch more freely because of the much simpler operations). The MaxPool operation in this block halves the spatial dimension and leaves the depth unaffected. In the DenseBlock, the whole depth is max pooled and the spatial dimension is average pooled to a size of (H = 2, W = 2), then, this tensor is flattened into a vector. A dropout with a drop probability of 0.5 is used before the linear layers. A LeakyReLU activation function is applied after the first linear layer and a LogSoftMax after the second and final one. Thus, the network was trained with a negative log-likelihood loss (NLLLoss) function:
where
N is the number of classes,
denotes the weights for class balancing,
is the binary label (takes on 1 for the correct class otherwise 0),
is the output of the network. As mentioned before, the last layer applies a LogSoftMax operation:
where
is the network output before the last normalization layer, which is described in the equation above. Note that this is equivalent to using cross-entropy loss when softmax is applied in the output layer.
To be able to evaluate the surmised advantage of the 3D network we also built its 2D alternative for baseline. For this 2D DNN, the input is simply the single reconstructed hologram amplitude and phase, 2D convolutions are employed instead of 3D ones and, obviously, the depthwise max pool operation in the DenseBlock is omitted. All the same channel and feature numbers are applied for a fair comparison.
The Pytorch deep learning framework is used to construct and train the neural networks. We split our data into training and test sets (85:15). Furthermore, we split the training set into 5-folds and conduct 5-fold validation training, using 4 folds for training and leaving out 1 fold for validation. Thus, we will have 5 models (with distinct parametrization) trained on altered datasets so we can have statistics on the performance of the methods when evaluating the multiple corresponding models on the test set. Adam optimizer is used for model parameter tuning with 2 learning rate and 0.01 weight decay. An early stop is utilized to stop the training when the validation is not improved in the last 10 epochs; thus, the learnings took place for approximately 80 epochs in our data. Standard augmentations were employed (rotate, horizontal flip, and vertical flip) to avoid overfitting and to achieve better generalization.
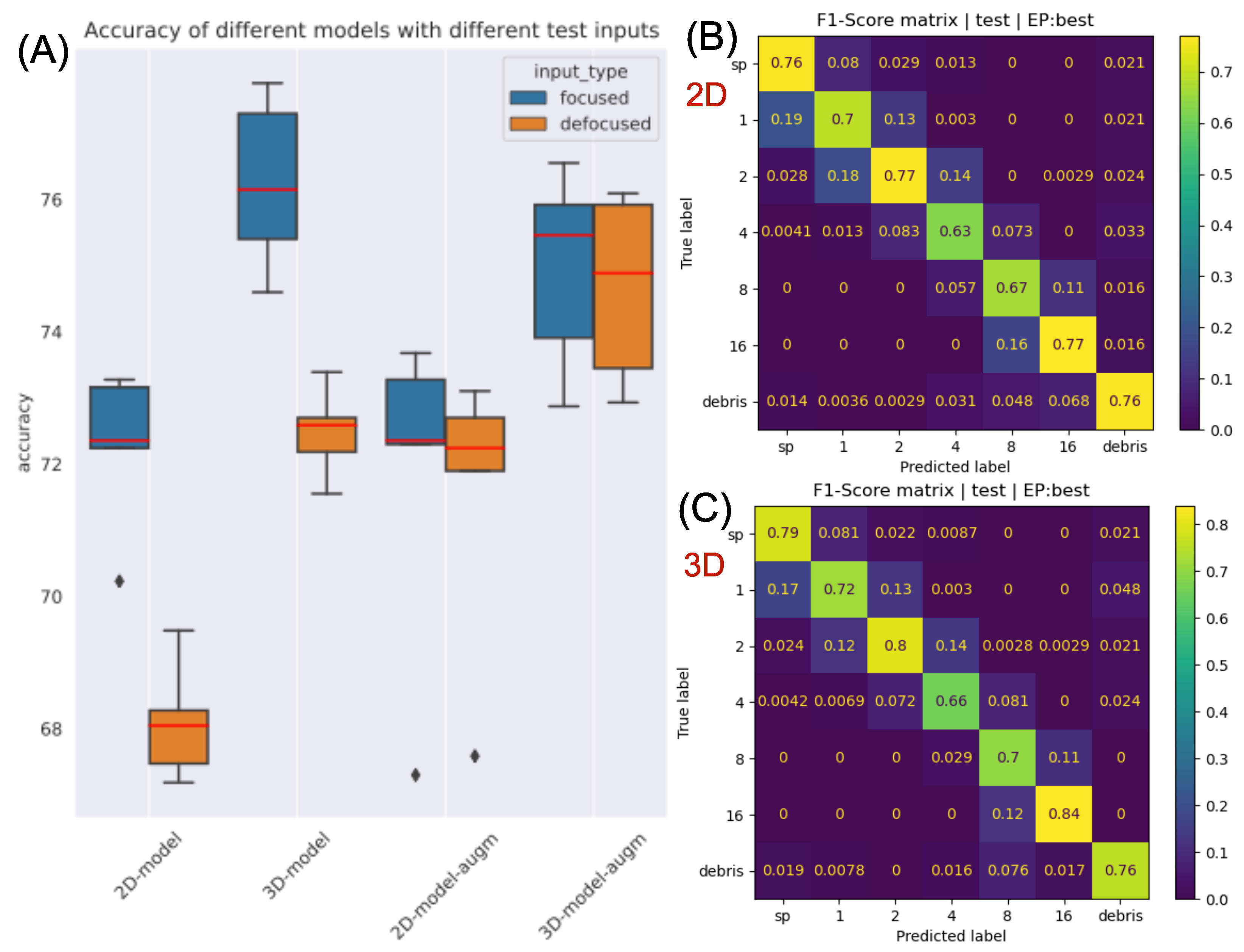
To evaluate and compare the performance of the methods, we calculate the average accuracy and NLLLoss for every 5 models—which are trained with different fold configurations—on the test set and then compute their mean and standard deviation. Additionally, the F1-score matrix—i.e. the harmonic mean of the row-wise and column-wise normed confusion matrix—is constructed which provides insights into class-level performance.
Besides that, we also inspected the robustness of the methods to slightly defocused inputs. For this, we randomly propagate the original in-focus test holograms in the range from −13.72 m to 13.72 m which will contain slightly defocused and in-focus sample images too. We presume that the 3D method provides superior performance in the case of defocused inputs because it maps a whole volume from a single hologram—that will contain the in-focus section too if the mapped depth is sufficiently large and the resolution is adequately fine.
Additionally, we introduce a kind of data augmentation technique specific to holograms, called hologram defocus augmentation: we randomly propagate the input holograms in a specified range. In our experiment, this continuous range was [−13.72, 13.72]
m where the center (zero) represents the in-focus (not augmented) original input hologram, see examples in
Figure 3. With this augmentation, we can effectively expand and generalize our database, which will result in increased defocus tolerance. We trained both 2D and 3D-models with and without hologram defocus augmentation and tested each one with in-focus inputs and also with defocused inputs. In the case of the 3D-model, the defocus augmentation means that the initial sample—from which the 3D input is created—is altered, which may result in the in-focus section being shifted from the middle of the constructed volume.
4. Discussion
The results support our initial hypothesis that the 2D-model can not effectively utilize the global information present in the reconstructed hologram image: it has to be explicitly extracted by volumetric input construction and fed to the 3D-model. The proposed method has particular relevance in the case of large objects, which can be distinguished based on their whole 3D structure (for example some pollens). The classification of such objects can be solved by proper application of the presented approach.
The improvements are obvious, but even the accuracy of the 3D-model (∼75%) is considered to be very low considering the state-of-the-art CNN classification results. This relatively low score originates from the hard classification problem and from the inaccuracies of the database (for example, as mentioned in the methods section, there exist samples in-between categories). Furthermore, it is often not clear, even for a human, which class the reconstructed object belongs to, especially for larger conglomerates (e.g., 4, 8). Nevertheless, it is still suitable for comparing different methods.
The disadvantage of the 3D-method is that it is computationally very expensive. The training time of the 2D NN was approximately 10 minutes, while it was approximately 1 h and 30 min for the 3D NN on an Nvidia Tesla V100 GPU. Furthermore, the inference speed of the 2D method was an order of magnitude faster than the 3D method. In addition, the inference time does not involve the hologram preprocessing, i.e., the construction of the volumetric input, which is also time-consuming. Its memory requirement is also more than doubled. In the case of real-world applications, one should carefully consider whether the amount of performance improvement is worth the increased computation demand. But there are many ways to make the method more efficient; for example, both computation time and classification performance might be improved if the objects were copped after the 3D input construction.
In order to utilize the global information present on the hologram without increasing the required computations, one could apply Fourier Neural Networks (FNN)—which is the future direction of our research. A hologram can be represented as a complex image (containing the amplitude and phase information naturally) that can be processed in the Fourier space by element-wise multiplication with learnable filter matrices which have a global receptive field. Chen et al. in [
25] applied FNN for phase reconstruction tasks with promising results. This approach could be adopted for classification tasks too.







{kind=link}
{kind=link}
{kind=link}
{kind=link}