


Pose Mask: A Model-Based Augmentation Method for 2D Pose Estimation in Classroom Scenes Using Surveillance Images

Abstract
1. Introduction
- To address the difficulty of pose estimation in classroom scenarios and to validate the effectiveness of our model-based data augmentation, we proposed a new dataset named Class Pose.
- Inspired by the masked autoencoders in image reconstruction, we proposed a model-based data augmentation method named Pose Mask, which served to fine-tune the pose estimation model using the reconstructed images as the new training set that was generated by the MAE trained with Pose Mask.
2. Materials and Methods
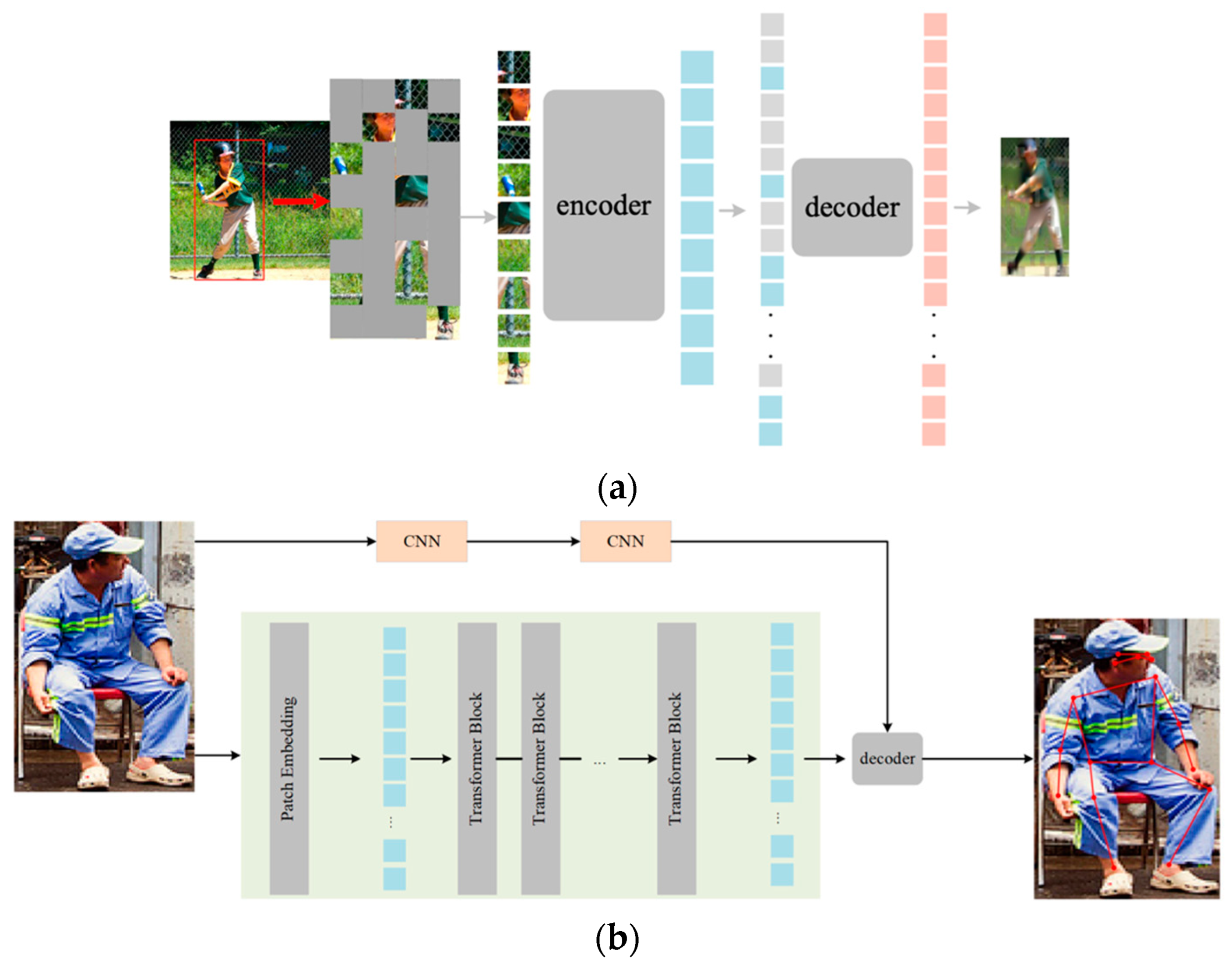
2.1. Overall Architecture
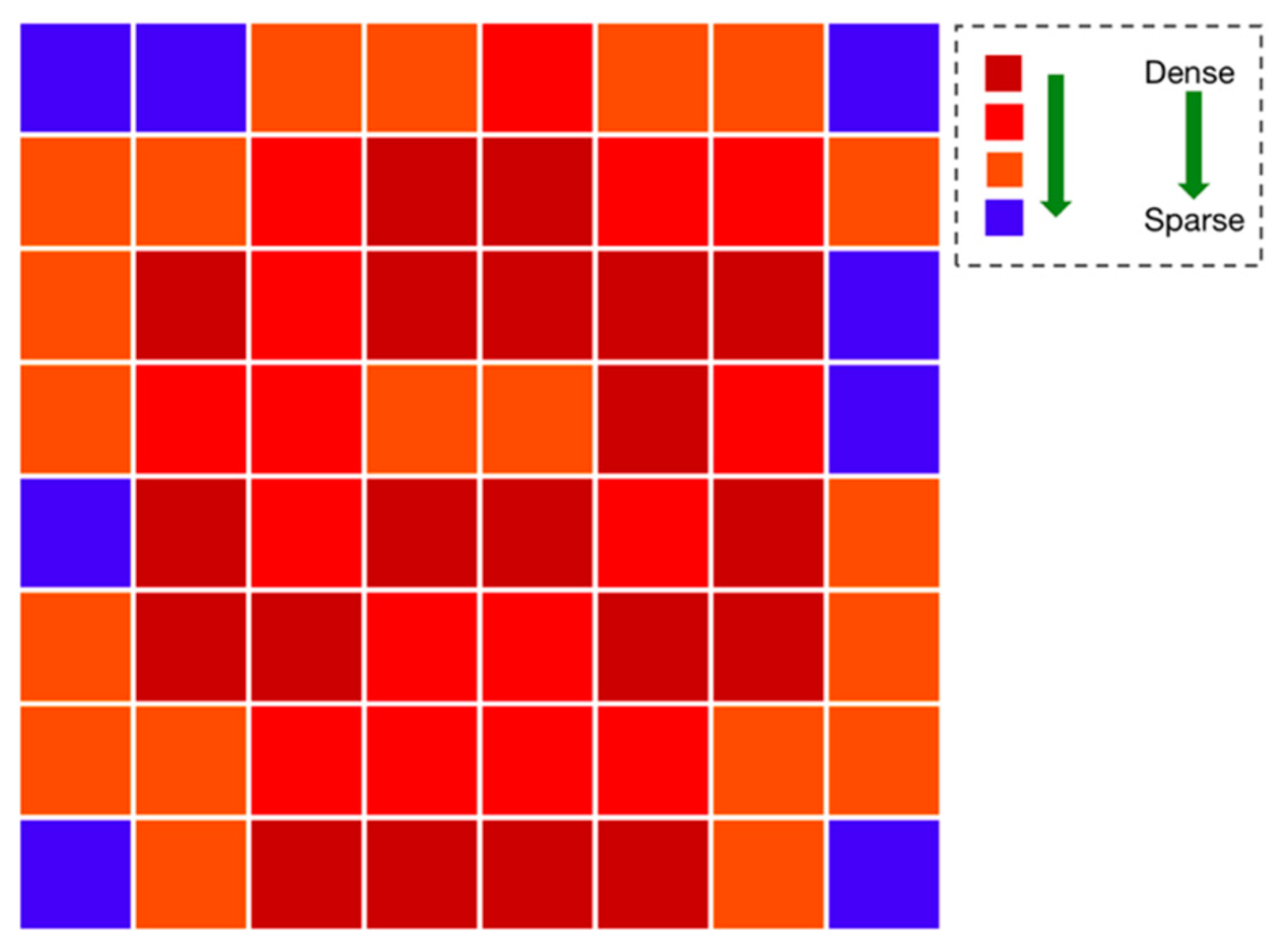
2.2. Pose Mask
2.3. The Design of Pose Estimator
2.4. Class Pose Dataset
2.4.1. Dataset Collection
2.4.2. Properties of Class Pose
3. Results
3.1. Implementation Details
3.2. Datasets and Evaluation Criteria
3.3. Ablation Study
3.3.1. Effect of Pre-Training the MAE via Pose Mask
3.3.2. Effect of SideCar
3.3.3. Comparisons with Mainstream Pose Estimators
3.3.4. Comparisons with Potential Image Augmentation Methods
3.4. Visualization
4. Discussion
4.1. Issues with Pre-Trained Data
4.2. Consistency of the Proposed Method
4.3. Contribution to Downstream Tasks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, M.Y.; Yuan, J.S. Recognizing human actions as the evolution of pose estimation maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Philippe, W.; Rogez, G. Mimetics: Towards understanding human actions out of context. IJCV 2021, 129, 1675–1690. [Google Scholar]
- Song, L.; Yu, G.; Yuan, J. Human pose estimation and its application to action recognition: A survey. JVCIR 2021, 76, 103055. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Bulat, A.; Kossaifi, J.; Tzimiropoulos, G.; Pantic, M. Toward fast and accurate human pose estimation via soft-gated skip connections. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Buenos Aires, Argentina, 16–20 November 2020. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014. [Google Scholar]
- Lin, F.C.; Ngo, H.H.; Dow, C.R. Student behavior recognition system for the classroom environment based on skeleton pose estimation and person detection. Sensors 2021, 21, 5314. [Google Scholar] [CrossRef] [PubMed]
- GitHub. Available online: https://github.com/CMU-Perceptual-Computing-Lab/openpose (accessed on 22 September 2022).
- Xu, X.; Xin, T. Classroom attention analysis based on multiple euler angles constraint and head pose estimation. In Proceedings of the International Conference on Multimedia Modeling, Daejeon Metropolitan City, Korea, 5–8 January 2020. [Google Scholar]
- Yu, Z.; Li, Y.; Liu, Y. Synpose: A Large-Scale and Densely Annotated Synthetic Dataset for Human Pose Estimation in Classroom. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Marina Bay Sands Expo & Convention Center, Singapore, 22–27 May 2022. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Nie, X.; Feng, J.; Zhang, J.; Yan, S. Single-stage multi-person pose machines. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 16–24 September 2022. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Xu, H.; Ding, S.; Zhang, X.; Xiong, H.; Tian, Q. Masked Autoencoders are Robust Data Augmentors. arXiv 2022, arXiv:2206.04846. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. ViTPose: Simple vision transformer baselines for human pose estimation. arXiv 2022, arXiv:2204.12484. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L. Hrformer: High-resolution vision transformer for dense predict. In Proceedings of the 2021 Conference on Neural Information Processing Systems, Vertual, 6–14 December 2021; pp. 7281–7293. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. arXiv 2021, arXiv:2106.04803. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, M.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. arXiv 2021, arXiv:2106.14881. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 16–24 September 2022. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 16–24 September 2022. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K. Res2net: A new multi-scale backbone architecture. T-PAMI 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 12–14 April 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pre-Training Strategy | Backbone Choice [22] | AP on Class Pose (%) |
|---|---|---|
| MAE-Original * | ViT-B | 59.3 |
| MAE-Pose Mask * | ViT-B | 60.2 |
| MAE-Original * | ViT-L | 60.5 |
| MAE-Pose Mask * | ViT-L | 61.8 |
| MAE IN-1K 1 | ViT-B | 59.1 |
| MAE IN-1K | ViT-L | 59.9 |
| NO MAE 2 | ViT-B | 57.3 |
| NO MAE | ViT-L | 58.8 |
| Model | Stages | AP on Class Pose (%) |
|---|---|---|
| ResNet-50 | 1 | 61.6 |
| ResNet-50 | 2 | 62.0 |
| ResNet-50 | 3 | 62.1 |
| ResNet-50 | 4 | 61.9 |
| ResNet-152 | 2 | 62.7 |
| ResNeSt-50 [30] | 2 | 62.5 |
| Res2Net-50 [31] | 2 | 62.4 |
| Model | Input Size | AP on Class Pose (%) |
|---|---|---|
| Simple Baselines (ResNet-152) | 256 × 192 | 52.3 |
| Simple Baselines (ResNet-152) | 384 × 288 | 54.6 |
| HRNet-W48 [16] | 256 × 192 | 54.4 |
| HRNet-W48 | 384 × 288 | 55.8 |
| HRNet W48 + DarkPose [32] | 384 × 288 | 57.8 |
| UDP-Pose-PSA [33] | 256 × 192 | 58.7 |
| UDP-Pose-PSA | 384 × 288 | 59.4 |
| ViTPose | 256 × 192 | 60.1 |
| ViTPose | 384 × 288 | 60.5 |
| ViTPose + PM 1 | 384 × 288 | 61.8 |
| ViTPose + SideCar 2 | 384 × 288 | 60.9 |
| ViTPose + SideCar + PM | 384 × 288 | 62.1 |
| Augmentation | Type | AP on Class Pose (%) |
|---|---|---|
| N/A | N/A | 59.1 |
| MAE with reconstructed images 1 | Model-based | 61.3 |
| MAE with reconstructed images (PM) 2 | Model-based | 62.1 |
| CycleGAN | Model-based | 59.3 |
| Horizontal flip | Traditional | 59.7 |
| Vertical flip | Traditional | 57.9 |
| Random rotate | Traditional | 58.4 |
| Random crop | Traditional | 59.2 |
| Color jitter | Traditional | 59.3 |
| Channel shuffle | Traditional | 58.8 |
| Gaussian blur | Traditional | 58.5 |
| Cutout | Traditional | 59.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Ma, M.; Li, H.; Ning, H.; Wang, M. Pose Mask: A Model-Based Augmentation Method for 2D Pose Estimation in Classroom Scenes Using Surveillance Images. Sensors 2022, 22, 8331. https://doi.org/10.3390/s22218331
Liu S, Ma M, Li H, Ning H, Wang M. Pose Mask: A Model-Based Augmentation Method for 2D Pose Estimation in Classroom Scenes Using Surveillance Images. Sensors. 2022; 22(21):8331. https://doi.org/10.3390/s22218331
Chicago/Turabian StyleLiu, Shichang, Miao Ma, Haiyang Li, Hanyang Ning, and Min Wang. 2022. "Pose Mask: A Model-Based Augmentation Method for 2D Pose Estimation in Classroom Scenes Using Surveillance Images" Sensors 22, no. 21: 8331. https://doi.org/10.3390/s22218331
APA StyleLiu, S., Ma, M., Li, H., Ning, H., & Wang, M. (2022). Pose Mask: A Model-Based Augmentation Method for 2D Pose Estimation in Classroom Scenes Using Surveillance Images. Sensors, 22(21), 8331. https://doi.org/10.3390/s22218331