
StaticPigDet: Accuracy Improvement of Static Camera-Based Pig Monitoring Using Background and Facility Information

 ,
,  ,
, 
Abstract
1. Introduction
2. Related Works
3. Proposed Method
3.1. Perspective Transformation
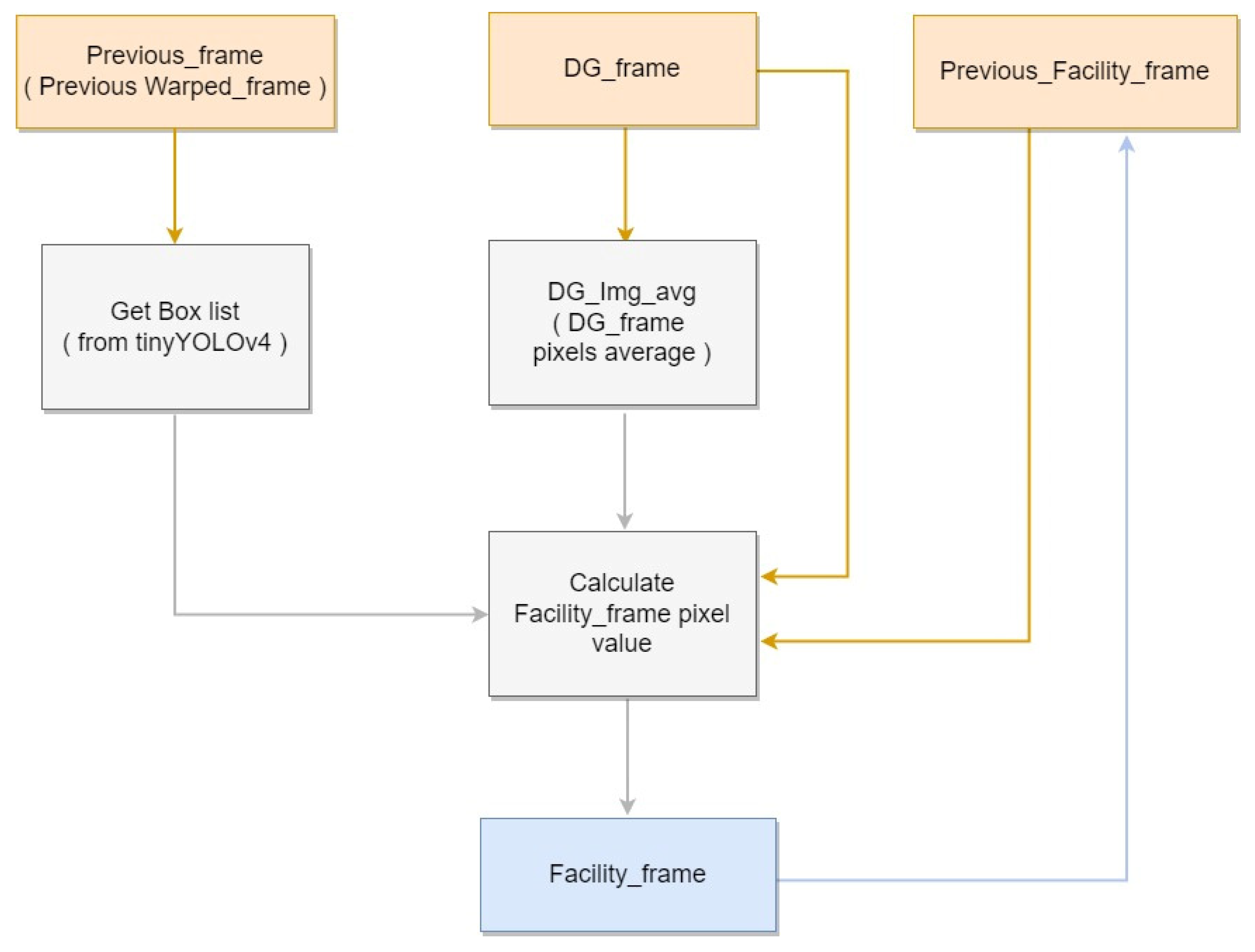
3.2. Background and Facility Generation
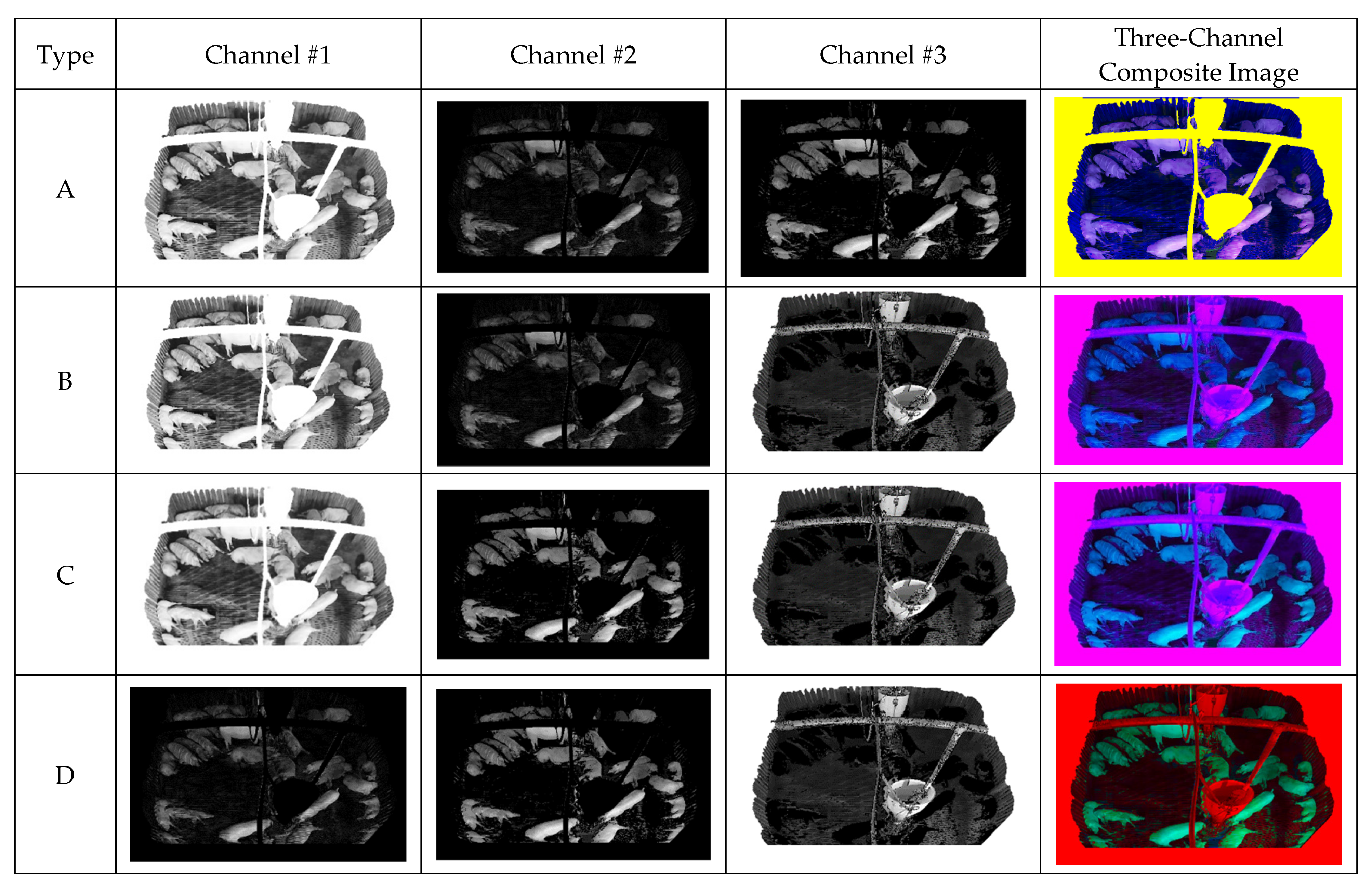
3.3. NPPS and Composite Image Generation
4. Experimental Results
5. Prospects for Further Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- OECD. Meat Consumption (Indicator). 2021. Available online: https://www.oecd-ilibrary.org/agriculture-and-food/meat-consumption/indicator/english_fa290fd0-en (accessed on 30 September 2022).
- Jiangong, L.; Green-Miller, A.; Hu, X.; Lucic, A.; Mahesh, M.; Dilger, R.; Condotta, I.; Aldridge, B.; Hart, J.; Ahuja, N. Barriers to computer vision applications in pig production facilities. Comput. Electron. Agric. 2022, 200, 107227. [Google Scholar]
- Kashiha, M.; Bahr, C.; Ott, S.; Moons, C.; Niewold, T.; Ödberg, F.; Berckmans, D. Automatic identification of marked pigs in a pen using image pattern recognition. Comput. Electron. Agric. 2013, 93, 111–120. [Google Scholar] [CrossRef]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jørgensen, E. Foreground detection using loopy belief propagation. Biosyst. Eng. 2013, 116, 88–96. [Google Scholar] [CrossRef]
- Kashiha, M.; Bahr, C.; Ott, S.; Moons, C. Automatic monitoring of pig activity using image analysis. Livest. Sci. 2013, 159, 555–563. [Google Scholar]
- Ott, S.; Moons, C.; Kashiha, M.; Bahr, C.; Tuyttens, F.; Berckmans, D.; Niewold, T. Automated video analysis of pig activity at pen level highly correlates to human observations of behavioural activities. Livest. Sci. 2014, 160, 132–137. [Google Scholar] [CrossRef]
- Chung, Y.; Kim, H.; Lee, H.; Park, D.; Jeon, T.; Chang, H. A cost-effective pigsty monitoring system based on a video sensor. KSII Trans. Internet Inf. 2014, 8, 1481–1498. [Google Scholar]
- Kashiha, M.; Bahr, C.; Ott, S.; Moons, C.; Niewold, T.; Tuyttens, F.; Berckmans, D. Automatic monitoring of pig locomotion using image analysis. Livest. Sci. 2014, 159, 141–148. [Google Scholar] [CrossRef]
- Tu, G.; Karstoft, H.; Pedersen, L.; Jørgensen, E. Illumination and reflectance estimation with its application in foreground. Sensors 2015, 15, 12407–12426. [Google Scholar] [CrossRef]
- Guo, Y.; Zhu, W.; Jiao, P.; Ma, C.; Yang, J. Multi-object extraction from topview group-housed pig images based on adaptive partitioning and multilevel thresholding segmentation. Biosyst. Eng. 2015, 135, 54–60. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Hensel, O.; Edwards, S.; Sturm, B. Automation detection of mounting behaviours among pigs using image analysis. Comput. Electron. Agric. 2016, 124, 295–302. [Google Scholar] [CrossRef]
- Lee, J.; Jin, L.; Park, D.; Chung, Y. Automatic recognition of aggressive behavior in pigs using a kinect depth sensor. Sensors 2016, 16, 631. [Google Scholar] [CrossRef] [PubMed]
- Gronskyte, R.; Clemmensen, L.; Hviid, M.; Kulahci, M. Monitoring pig movement at the slaughterhouse using optical flow and modified angular histogram. Biosyst. Eng. 2016, 141, 19–30. [Google Scholar] [CrossRef]
- Buayai, P.; Kantanukul, T.; Leung, C.; Saikaew, K. Boundary detection of pigs in pens based on adaptive thresholding using an integral image and adaptive partitioning. CMU J. Nat. Sci. 2017, 16, 145–155. [Google Scholar] [CrossRef]
- Kim, J.; Chung, Y.; Choi, Y.; Sa, J.; Kim, H.; Chung, Y.; Park, D.; Kim, H. Depth-based detection of standing-pigs in moving noise environments. Sensors 2017, 17, 2757. [Google Scholar] [CrossRef]
- Zhang, L.; Gray, H.; Ye, X.; Collins, L.; Allinson, N. Automatic individual pig detection and tracking in surveillance videos. arXiv 2018, arXiv:1812.04901. [Google Scholar]
- Brünger, J.; Traulsen, I.; Koch, R. Model-based detection of pigs in images under sub-optimal conditions. Comput. Electron. Agric. 2018, 152, 59–63. [Google Scholar] [CrossRef]
- Tian, M.; Guo, H.; Chen, H.; Wang, Q.; Long, C.; Ma, Y. Automated pig counting using deep learning. Comput. Electron. Agric. 2019, 163, 104840. [Google Scholar] [CrossRef]
- Li, B.; Liu, L.; Shen, M.; Sun, Y.; Lu, M. Group-housed pig detection in video surveillance of overhead views using multi-feature template matching. Biosyst. Eng. 2019, 181, 28–39. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Sturm, B.; Edwards, S.; Jeppsson, K.; Olsson, A.; Müller, S.; Hensel, O. Deep learning and machine vision approaches for posture detection of individual pigs. Sensors 2019, 19, 3738. [Google Scholar] [CrossRef]
- Psota, E.; Mittek, M.; Pérez, L.; Schmidt, T.; Mote, B. Multi-Pig Part Detection and Association with a Fully-Convolutional Network. Sensors 2019, 19, 852. [Google Scholar] [CrossRef]
- Hong, M.; Ahn, H.; Atif, O.; Lee, J.; Park, D.; Chung, Y. Field-applicable pig anomaly detection system using vocalization for embedded board implementations. Appl. Sci. 2020, 10, 6991. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Oczak, M.; Maschat, K.; Baumgartner, J.; Larsen, M.; Norton, T. A computer vision approach for recognition of the engagement of pigs with different enrichment objects. Comput. Electron. Agric. 2020, 175, 105580. [Google Scholar] [CrossRef]
- Alameer, A.; Kyriazakis, I.; Bacardit, J. Automated recognition of postures and drinking behaviour for the detection of compromised health in pigs. Sci. Rep. 2020, 10, 13665. [Google Scholar] [CrossRef]
- Riekert, M.; Klein, A.; Adrion, F.; Hoffmann, C.; Gallmann, E. Automatically detecting pig position and posture by 2D camera imaging and deep learning. Comput. Electron. Agric. 2020, 174, 105391. [Google Scholar] [CrossRef]
- Brünger, J.; Gentz, M.; Traulsen, I.; Koch, R. Panoptic segmentation of individual pigs for posture recognition. Sensors 2020, 20, 3710. [Google Scholar] [CrossRef] [PubMed]
- Ahn, H.; Son, S.; Kim, H.; Lee, S.; Chung, Y.; Park, D. EnsemblePigDet: Ensemble deep learning for accurate pig detection. Appl. Sci. 2021, 11, 5577. [Google Scholar] [CrossRef]
- Huang, E.; Mao, A.; Gan, H.; Ceballos, M.; Parsons, T.; Xue, Y.; Liu, K. Center clustering network improves piglet counting under occlusion. Comput. Electron. Agric. 2021, 189, 106417. [Google Scholar] [CrossRef]
- Riekert, M.; Opderbeck, S.; Wild, A.; Gallmann, E. Model selection for 24/7 pig position and posture detection by 2D camera imaging and deep learning. Comput. Electron. Agric. 2021, 187, 106213. [Google Scholar] [CrossRef]
- Hu, Z.; Yang, H.; Lou, T. Dual attention-guided feature pyramid network for instance segmentation of group pigs. Comput. Electron. Agric. 2021, 186, 106140. [Google Scholar] [CrossRef]
- Hegde, S.; Gangisetty, S. Pig-net: Inception based deep learning architecture for 3d point cloud segmentation. Comput. Graphics. 2021, 95, 13–22. [Google Scholar] [CrossRef]
- Shao, H.; Pu, J.; Mu, J. Pig-posture recognition based on computer vision: Dataset and exploration. Animals 2021, 11, 1295. [Google Scholar] [CrossRef] [PubMed]
- Ocepek, M.; Žnidar, A.; Lavrič, M.; Škorjanc, D. DigiPig: First developments of an automated monitoring system for body, head, and tail detection in intensive pig farming. Agriculture 2022, 12, 2. [Google Scholar] [CrossRef]
- Kim, J.; Suh, Y.; Lee, J.; Chae, H.; Ahn, H.; Chung, Y.; Park, D. EmbeddedPigCount: Pig counting with video object detection and tracking on an embedded board. Sensors 2022, 22, 2689. [Google Scholar] [CrossRef] [PubMed]
- Bo, Z.; Atif, O.; Lee, J.; Park, D.; Chung, Y. GAN-Based video denoising with attention mechanism for field-applicable pig detection system. Sensors 2022, 22, 3917. [Google Scholar] [CrossRef]
- Ji, H.; Yu, J.; Lao, F.; Zhuang, Y.; Wen, Y.; Teng, G. Automatic position detection and posture recognition of grouped pigs based on deep learning. Agriculture 2022, 12, 1314. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Access 2018, 99, 3212–3232. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Open Source Computer Vision: ‘OpenCV’. Available online: http://opencv.org (accessed on 20 September 2022).
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization; Academic Press Inc.: Cambridge, MA, USA, 1994. [Google Scholar]
- Hanwha Surveillance Camera. Available online: https://www.hanwhasecurity.com/product/qno-6012r/ (accessed on 30 September 2022).
- NVIDIA. NVIDIA Jetson TX2. Available online: http://www.nvidia.com/object/embedded-systems-dev-kitsmodules.html (accessed on 30 September 2022).
- Intel. Intel RealSense D435. Available online: https://www.intelrealsense.com/depth-camera-d435 (accessed on 30 September 2022).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkareit, J.; Jones, L.; Gomez, A.; Kaiser, G.; Polosukhin, I. Attention is all you need. In Proceedings of the NeurIPS, Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Background and Facility Information Utilization | Year | Detection Technique | Accuracy Reported | Reference |
|---|---|---|---|---|
| No | 2013 | Image Processing | 88.70% ※ | [3] |
| Image Processing | 93.30% ※ | [4] | ||
| Image Processing | 89.80% ※ | [5] | ||
| 2014 | Image Processing | - | [6] | |
| Image Processing | 99.00% ※ | [7] | ||
| Image Processing | 89.90% ※ | [8] | ||
| 2015 | Image Processing | 95.48% ※ | [9] | |
| Image Processing | - | [10] | ||
| 2016 | Image Processing | 88.60%~94.50% ※ | [11] | |
| Image Processing | 90.20%~95.70% ※ | [12] | ||
| Image Processing | - | [13] | ||
| 2017 | Image Processing | - | [14] | |
| Image Processing | 94.47% ※ | [15] | ||
| 2018 | Deep Learning | 89.58% ※ | [16] | |
| Deep Learning | - | [17] | ||
| 2019 | Deep Learning | - | [18] | |
| Image Processing + Deep Learning | 86.80% ※ | [19] | ||
| Image Processing + Deep Learning | 92.00%~95.00% ※ | [20] | ||
| Image Processing + Deep Learning | 77.10%~98.10% ※ | [21] | ||
| 2020 | Deep Learning | 94.70% ※ | [22] | |
| Deep Learning | 96.50%~97.60% ※ | [23] | ||
| Deep Learning | 98.00%~99.80% ※ | [24] | ||
| Deep Learning | 67.70%~87.40% ※ | [25] | ||
| Image Processing + Deep Learning | 95.00%※ | [26] | ||
| 2021 | Deep Learning | 94.33%※ | [27] | |
| Deep Learning | - | [28] | ||
| Deep Learning | 58.00%~84.00% ※ | [29] | ||
| Deep Learning | 93.1%※ | [30] | ||
| Image Processing + Deep Learning | - | [31] | ||
| Image Processing + Deep Learning | 92.45% ※ | [32] | ||
| Image Processing + Deep Learning | - | [33] | ||
| 2022 | Deep Learning | 99.44% ※ | [34] | |
| Deep Learning | - | [35] | ||
| Image Processing + Deep Learning | 82.80%~99.50% ※ | [36] | ||
| Yes | 2022 | Image Processing + Deep Learning | 94.45% * | Proposed |
| Type | Train Dataset (Hadong) | Test Dataset (Hadong) | TP | FP | FN | Precision | Recall | Accuracy (AP0.5) |
|---|---|---|---|---|---|---|---|---|
| Baseline | Color Image | Color Image | 3729 | 517 | 864 | 0.88 | 0.81 | 84.39 |
| Proposed StaticPigDet | Composite Image A + B + C + D | Composite Image A | 3885 | 385 | 385 | 0.91 | 0.91 | 94.02 |
| Composite Image B | 3916 | 398 | 354 | 0.91 | 0.92 | 94.19 | ||
| Composite Image C | 3882 | 272 | 388 | 0.93 | 0.91 | 94.44 | ||
| Composite Image D | 3868 | 332 | 402 | 0.92 | 0.91 | 94.45 |
| Type | Train Dataset (Hadong) | Test Dataset (Hadong) | TP | FP | FN | Precision | Recall | Accuracy (AP0.5) |
|---|---|---|---|---|---|---|---|---|
| Baseline | Color Image | Color Image | 3967 | 2135 | 626 | 0.65 | 0.86 | 86.70 |
| Proposed StaticPigDet | Composite Image A + B + C + D | Composite Image A | 3709 | 500 | 561 | 0.88 | 0.87 | 91.83 |
| Composite Image B | 3725 | 491 | 545 | 0.88 | 0.87 | 92.24 | ||
| Composite Image C | 3672 | 373 | 598 | 0.91 | 0.86 | 91.78 | ||
| Composite Image D | 3585 | 392 | 685 | 0.90 | 0.84 | 91.04 |
| Train Dataset (Hadong) | Test Dataset (Hadong) | TP | FP | FN | Precision | Recall | Accuracy (AP0.5) |
|---|---|---|---|---|---|---|---|
| Composite Image A | Composite Image A | 3632 | 479 | 638 | 0.88 | 0.85 | 89.88 |
| Composite Image B | Composite Image B | 3657 | 819 | 613 | 0.82 | 0.86 | 86.77 |
| Composite Image C | Composite Image C | 3686 | 810 | 584 | 0.82 | 0.86 | 87.78 |
| Composite Image D | Composite Image D | 3463 | 656 | 807 | 0.84 | 0.81 | 83.77 |
| Train Dataset (Hadong) | Test Dataset (Hadong) | TP | FP | FN | Precision | Recall | Accuracy (AP0.5) |
|---|---|---|---|---|---|---|---|
| Composite Image A | Composite Image A | 3620 | 1034 | 650 | 0.78 | 0.85 | 86.46 |
| Composite Image B | Composite Image B | 3703 | 1544 | 567 | 0.71 | 0.87 | 87.45 |
| Composite Image C | Composite Image C | 3668 | 812 | 602 | 0.82 | 0.86 | 88.30 |
| Composite Image D | Composite Image D | 3621 | 815 | 649 | 0.82 | 0.85 | 86.60 |
| Type | Train Dataset (Hadong) | Test Dataset (Chungbuk) | TP | FP | FN | Precision | Recall | Accuracy (AP0.5) |
|---|---|---|---|---|---|---|---|---|
| Baseline | Color Image | Color Image | 764 | 42 | 958 | 0.95 | 0.44 | 75.86 |
| Proposed StaticPigDet | Composite Image A + B + C + D | Composite Image A | 1543 | 1276 | 179 | 0.55 | 0.90 | 81.30 |
| Composite Image B | 1526 | 919 | 196 | 0.62 | 0.89 | 77.41 | ||
| Composite Image C | 1509 | 235 | 213 | 0.87 | 0.88 | 88.71 | ||
| Composite Image D | 1472 | 112 | 250 | 0.93 | 0.85 | 90.25 |
| Type | Train Dataset (Hadong) | Test Dataset (Chungbuk) | TP | FP | FN | Precision | Recall | Accuracy (AP0.5) |
|---|---|---|---|---|---|---|---|---|
| Baseline | Color Image | Color Image | 1270 | 2168 | 452 | 0.37 | 0.74 | 63.15 |
| Proposed StaticPigDet | Composite Image A + B + C + D | Composite Image A | 1280 | 1612 | 442 | 0.44 | 0.74 | 65.41 |
| Composite Image B | 1282 | 1220 | 440 | 0.51 | 0.74 | 68.77 | ||
| Composite Image C | 1248 | 979 | 474 | 0.56 | 0.72 | 65.71 | ||
| Composite Image D | 1371 | 709 | 351 | 0.66 | 0.80 | 77.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, S.; Ahn, H.; Baek, H.; Yu, S.; Suh, Y.; Lee, S.; Chung, Y.; Park, D. StaticPigDet: Accuracy Improvement of Static Camera-Based Pig Monitoring Using Background and Facility Information. Sensors 2022, 22, 8315. https://doi.org/10.3390/s22218315
Son S, Ahn H, Baek H, Yu S, Suh Y, Lee S, Chung Y, Park D. StaticPigDet: Accuracy Improvement of Static Camera-Based Pig Monitoring Using Background and Facility Information. Sensors. 2022; 22(21):8315. https://doi.org/10.3390/s22218315
Chicago/Turabian StyleSon, Seungwook, Hanse Ahn, Hwapyeong Baek, Seunghyun Yu, Yooil Suh, Sungju Lee, Yongwha Chung, and Daihee Park. 2022. "StaticPigDet: Accuracy Improvement of Static Camera-Based Pig Monitoring Using Background and Facility Information" Sensors 22, no. 21: 8315. https://doi.org/10.3390/s22218315
APA StyleSon, S., Ahn, H., Baek, H., Yu, S., Suh, Y., Lee, S., Chung, Y., & Park, D. (2022). StaticPigDet: Accuracy Improvement of Static Camera-Based Pig Monitoring Using Background and Facility Information. Sensors, 22(21), 8315. https://doi.org/10.3390/s22218315