


Exploration of Semantic Label Decomposition and Dataset Size in Semantic Indoor Scenes Synthesis via Optimized Residual Generative Adversarial Networks


Abstract
:1. Introduction
- We propose three different UNet-like architectures for the generator network and three different discriminator architectures to fit with each generator architecture. We compare them and highlight the advantages and disadvantages of each architecture.
- In the architecture of the generator, we compare two merging techniques (concatenation and addition) of the same feature size blocks in the encoder and the decoder. We show that merging using addition gives the same, if not better, results than merging features using concatenation, while the addition operation is less complex than concatenation.
- We propose relatively lightweight encoder-decoder GAN models with residual connections, less computational complexity, and higher quality of the generated images than the original U-Net, which is the core of the image-to-image translation approach using GAN (Pix2Pix).
- We explore the effect of the number of class labels (including the same label decomposition) and the number of training samples on the quality of the generated artificial images on the NYU depthV2 dataset and ADE20K Indoor subset.
2. Related Work
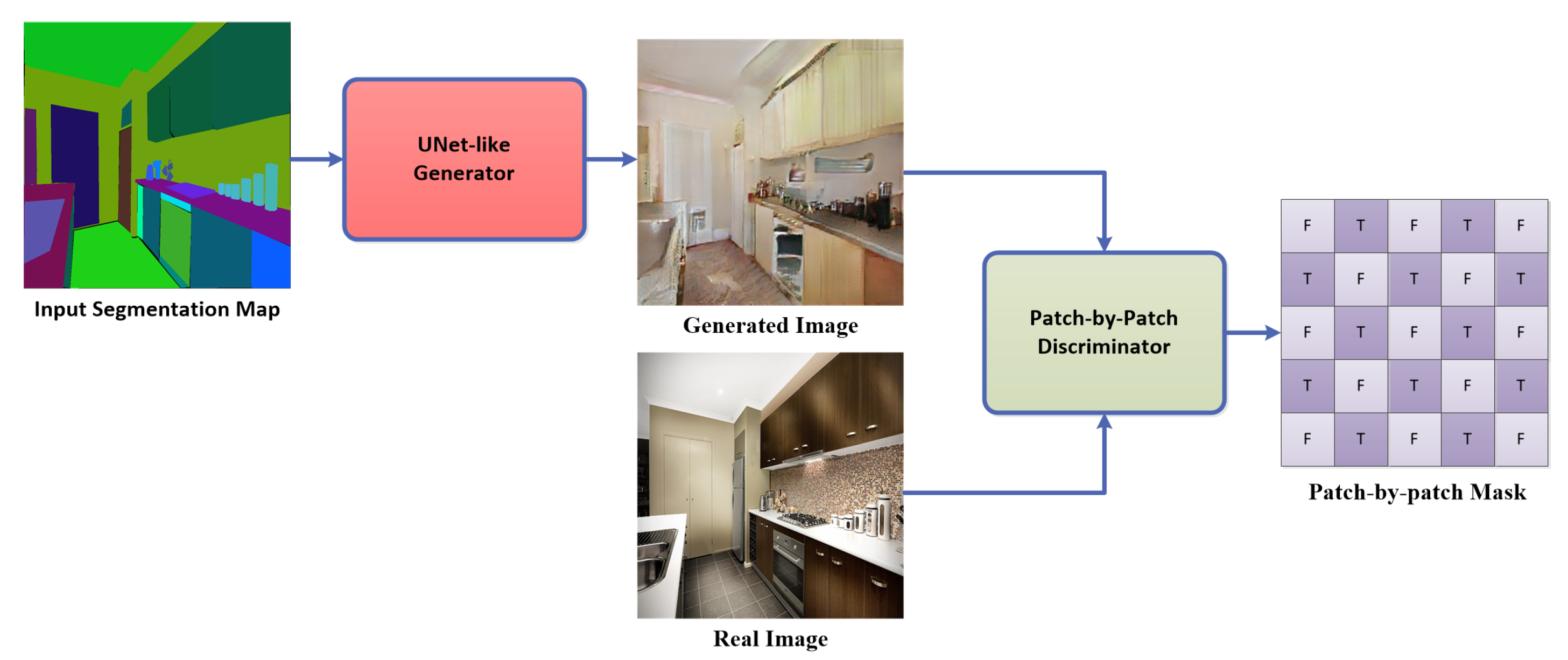
3. Proposed Method
3.1. Proposed Architectures
3.2. Loss Function
4. Benchmarks and Experiment Preparation
4.1. NYU Depth-V2
4.2. ADE20K Indoor Subset
4.3. Training and Test Configurations
4.4. Evaluation Metrcis
5. Experimental Results
5.1. Effect of the Feature Merging Technique on the Quality of the Generated Image
5.2. Effect of the Number of Labels and Training Samples on the Quality of the Generated Image
5.3. Comparison between the Proposed GAN Models
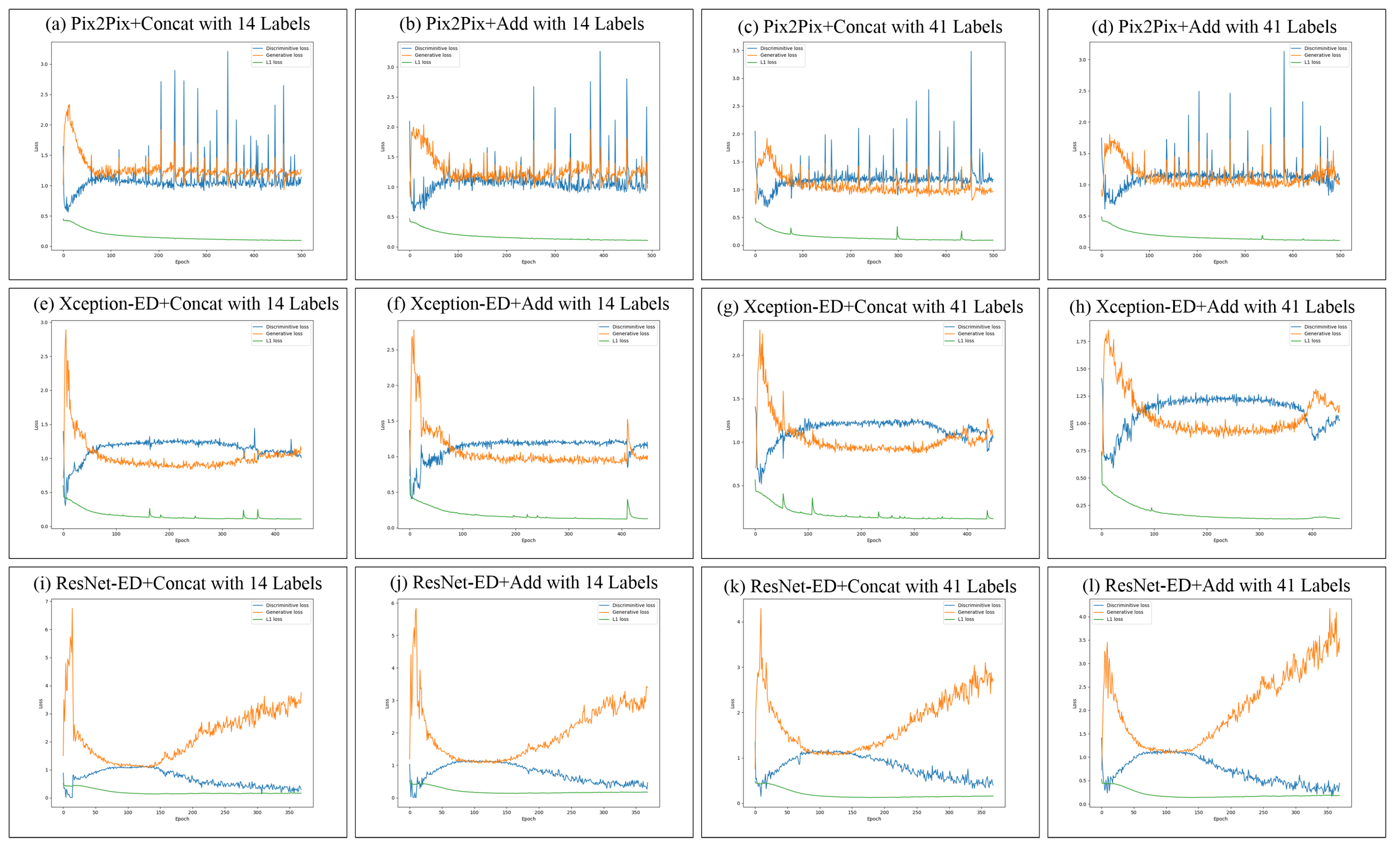
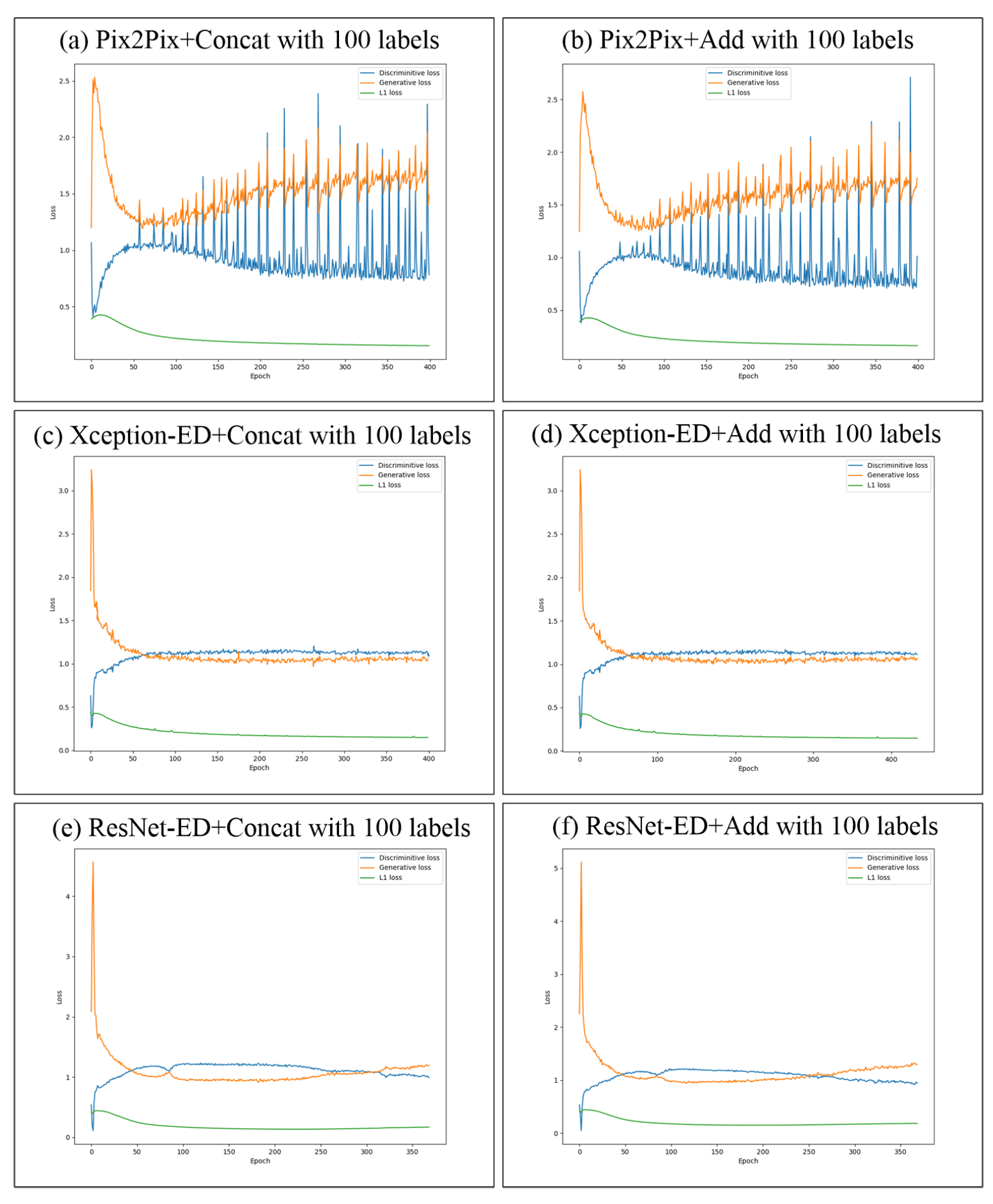
5.4. Training Stability and Loss Improvement of the Proposed GAN Models
5.5. Comparison between the Proposed Method and State-of-the-Art Methods
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Network |
| DCGAN | Deep Convolutional Generative Adversarial Network |
| CGAN | Conditional Generative Adversarial Network |
| Pix2Pix | image-to-image translation-based GenerativeAdversarial Network |
| CycleGAN | Cycle Consistency Generative Adversarial Network |
| StyleGAN | Style-Based Generator for Generative Adversarial Networks |
| SPADE | Spatially Adaptive Normalization |
| DAGAN | Dual Attention Generative Adversarial Network |
| SCGAN | Semantic Composition Generative Adversarial Network |
| INADE | INstance-Adaptive DEnormalization |
| OASIS | Only Adversarial Supervision for Semantic Image Synthesis |
| SDM | Semantic Diffusion Model |
| ED | Encoder-Decoder |
| Concat. | Concatenation-based architecure |
| Add. | Addition-based architecure |
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Jimenez Rezende, D.; Mohamed, S.; Wierstra, D. Stochastic Backpropagation and Approximate Inference in Deep Generative Models. In Proceedings of the International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer Assisted Intervention MICCAI; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2016, arXiv:1511.06434. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4396–4405. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Park, T.; Liu, M.-Y.; Wang, T.-C.; Zhu, J.-Y. Semantic Image Synthesis With Spatially-Adaptive Normalization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2332–2341. [Google Scholar]
- Chai, M.; Chen, D.; Liao, J.; Chu, Q.; Liu, B.; Yu, N. Diverse Semantic Image Synthesis via Probability Distribution Modeling. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7958–7967. [Google Scholar]
- Sushko, V.; Schönfeld, E.; Zhang, D.; Gall, J.; Schiele, B.; Khoreva, A. You Only Need Adversarial Supervision for Semantic Image Synthesis. In Proceedings of the 2021 International Conference on Learning Representations (ICLR), Virtual, 30 April–3 May 2018. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Wang, W.; Bao, J.; Zhou, W.; Chen, D.; Chen, D.; Yuan, L.; Li, H. Semantic Image Synthesis via Diffusion Models. arXiv 2022, arXiv:2207.00050. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the the international conference on Learning Representation (ICLR), Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.A.; Hinton, G.E. mageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Martin, H.; Hubert, R.; Thomas, U.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. Adv. Neural Inf. Process. Syst. (Neurips) 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/file/8a1d694707eb0fefe65871369074926d-Paper.pdf (accessed on 23 August 2022).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Wang, Y.; Qi, L.; Chen, Y.-C.; Zhang, X.; Jia, J. Image synthesis via semantic composition. Proceedings of International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13749–13758. [Google Scholar]
- Tang, H.; Bai, S.; Sebe, N. Dual Attention GANs for Semantic Image Synthesis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1994–2002. [Google Scholar]
- Zhu, Z.; Xu, Z.; You, A.; Bai, X. Semantically Multi-Modal Image Synthesis. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5466–5475. [Google Scholar]
- Liu, X.; Yin, G.; Shao, J.; Wang, X.; Li, H. Learning to predict layout-to-image conditional convolutions for semantic image synthesis. In Proceedings of the 33rd International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; No.: 52. pp. 570–580. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat GANs on Image Synthesis. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Khaldi, Y.; Benzaoui, A.; Ouahabi, A.; Jacques, S.; Taleb-Ahmed, A. Ear Recognition Based on Deep Unsupervised Active Learning. IEEE Sens. J. 2021, 21, 20704–20713. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GAN Model | ED Merging Technique | G params. | D params. | LPIPS | FID |
|---|---|---|---|---|---|
| Pix2Pix | Concatenatation | 54,423,811 | 2,768,385 | 0.505 | 237.440 |
| Pix2Pix | Addition | 39,085,315 | 2,768,385 | 0.514 | 228.568 |
| Xception-ED | Concatenation | 33,452,515 | 41,825 | 0.471 | 203.329 |
| Xception-ED | Addition | 25,600,483 | 41,825 | 0.495 | 198.594 |
| ResNet-ED | Concatenation | 62,620,675 | 828,865 | 0.490 | 135.447 |
| ResNet-ED | Addition | 51,274,755 | 828,865 | 0.509 | 122.732 |
| GAN Model | ED Merging Technique | LPIPS | FID |
|---|---|---|---|
| Pix2Pix | Concatenation | 0.520 | 230.413 |
| Pix2Pix | Addition | 0.522 | 218.635 |
| Xception-ED | Concatenation | 0.472 | 193.458 |
| Xception-ED | Addition | 0.465 | 189.727 |
| ResNet-ED | Concatenation | 0.473 | 130.681 |
| ResNet-ED | Addition | 0.497 | 115.235 |
| Method | ED Merging Technique | LPIPS | FID |
|---|---|---|---|
| Pix2Pix | Concatenation | 0.515 | 140.241 |
| Pix2Pix | Addition | 0.525 | 137.905 |
| Xception-ED | Concatenation | 0.508 | 135.501 |
| Xception-ED | Addition | 0.522 | 131.256 |
| ResNet-ED | Concatenation | 0.491 | 95.402 |
| ResNet-ED | Addition | 0.505 | 81.067 |
| Method | LPIPS | FID |
|---|---|---|
| Pix2PixHD [9] | 0.125 | 135.271 |
| DAGAN [25] | 0.344 | 90.105 |
| SPADE [10] | 0.221 | 106.401 |
| SCGAN [24] | 0.341 | 87.141 |
| GroupDNet [26] | 0.232 | 117.511 |
| CC-FPSE [27] | 0.311 | 97.452 |
| INADE [11] | 0.491 | 109.340 |
| OASIS [12] | 0.364 | 85.322 |
| SDM [14] | 0.552 | 83.244 |
| ResNet-ED+Add (Ours) | 0.505 | 81.067 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrahem, H.; Salem, A.; Kang, H.-S. Exploration of Semantic Label Decomposition and Dataset Size in Semantic Indoor Scenes Synthesis via Optimized Residual Generative Adversarial Networks. Sensors 2022, 22, 8306. https://doi.org/10.3390/s22218306
Ibrahem H, Salem A, Kang H-S. Exploration of Semantic Label Decomposition and Dataset Size in Semantic Indoor Scenes Synthesis via Optimized Residual Generative Adversarial Networks. Sensors. 2022; 22(21):8306. https://doi.org/10.3390/s22218306
Chicago/Turabian StyleIbrahem, Hatem, Ahmed Salem, and Hyun-Soo Kang. 2022. "Exploration of Semantic Label Decomposition and Dataset Size in Semantic Indoor Scenes Synthesis via Optimized Residual Generative Adversarial Networks" Sensors 22, no. 21: 8306. https://doi.org/10.3390/s22218306
APA StyleIbrahem, H., Salem, A., & Kang, H.-S. (2022). Exploration of Semantic Label Decomposition and Dataset Size in Semantic Indoor Scenes Synthesis via Optimized Residual Generative Adversarial Networks. Sensors, 22(21), 8306. https://doi.org/10.3390/s22218306