



Fuzzy Ontology-Based System for Driver Behavior Classification




Abstract
1. Introduction
- Construction of a driver behavior model based on data from a realistic simulator and creation of an ontology for knowledge representation according to that model. This ontology has been integrated with a traffic ontology. The whole knowledge base allows us to model different general traffic scenarios, with driver-behavior-related knowledge.
- A fuzzy logic architecture based on the Mamdani approach that allows us to classify drivers into five profiles (very passive, passive, normal, aggressive, and dangerous), taking into account driver-related parameters such as age, gender, speed, and accelerator and brake usage. The proposed system has the following particularities regarding the knowledge base and the inference engine:
- 1.
- The knowledge base is made up of the driver behavior ontology connected to a traffic ontology, a database from a driving simulator, and a rule base learned through a genetic algorithm.
- 2.
- The proposed inference engine allows us to deal with the absence of data by substituting the membership degrees of the absent variables during the inference process, taking advantage of the properties of the conjunction operator.
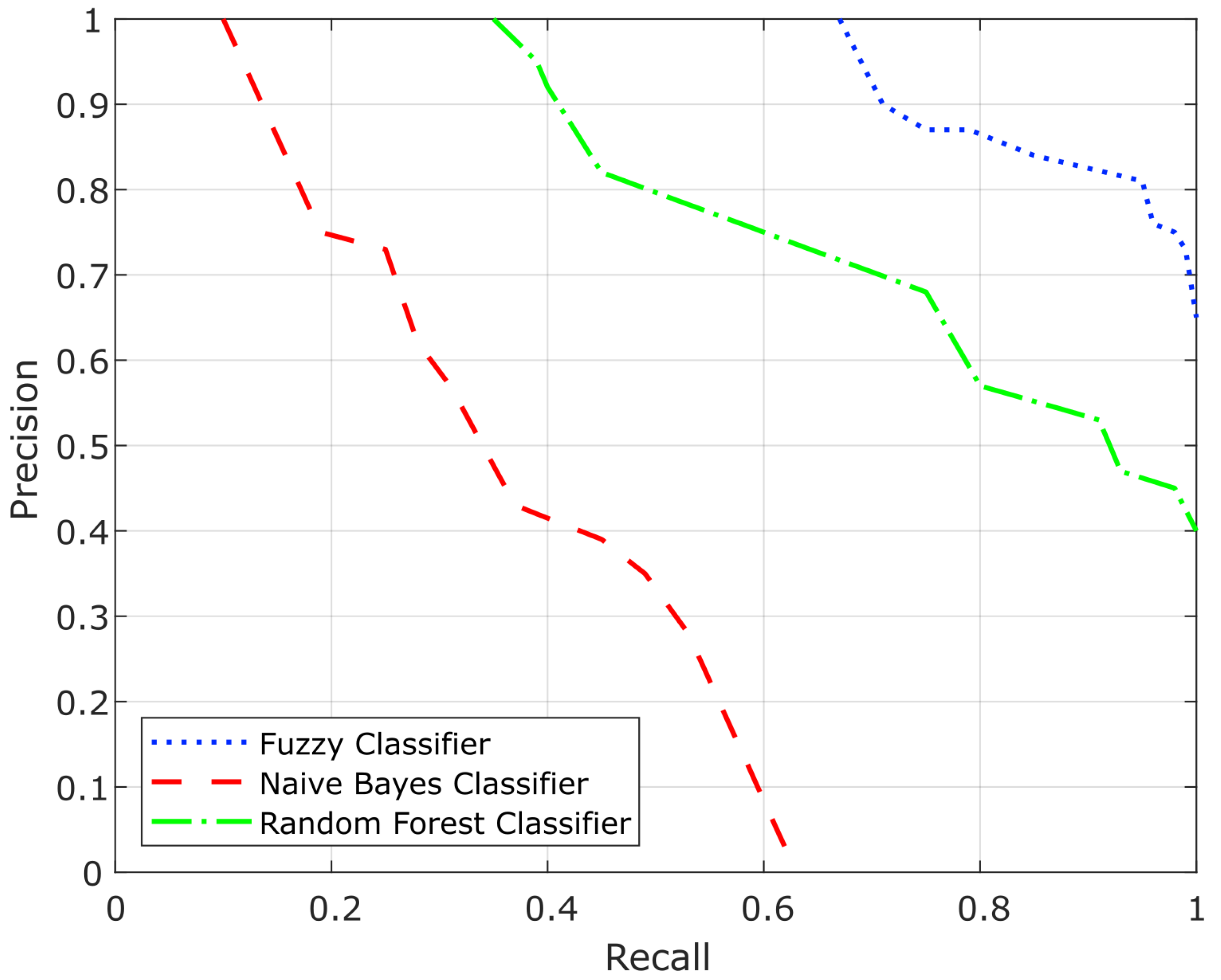
- An experimental evaluation to validate the effectiveness of the classification system, the expressiveness of the ontology, and the utility of the classification system in an ITS scenario. To compare the results of the proposed system with other approaches, two alternative classification algorithms have been implemented: a Naive Bayes classifier and a Random Forest classifier. The fuzzy classifier clearly outperforms the other approaches, mainly due to its more appropriate handling of uncertainty. In addition, experiments show that the proposed knowledge model is expressive enough for the evaluated scenarios, achieving good results in terms of the quality of the information retrieved. To validate the utility of the classification system, we have defined a traffic scenario where a driving assistance system sends recommendations to drivers, such as adjusting speed or choosing alternative routes, allowing them to optimize traffic and to improve their driving experience. Most drivers who were recommended a speed adjustment or an alternative route experienced a gain in time.
2. State-of-the-Art on Driver Behavior Feature Identification
3. Factors Affecting Driver Behavior
- Age and gender: There are some studies about the relationship between the gender and the driver age group with the road crashes. Some studies, such as [32], state that the percentage of men involved in traffic accidents is greater than women, independently of age. Regarding age groups, the same study shows that most traffic accidents involve people under 25 years, while a low percentage of accidents occurs in people over the age of 70, taking into account that the percentage of drivers over 70 years is much lower than in other age groups.
- Road environment: The road environment can affect driver’s perception through some implicit information, such as the peripheral visual field, and explicit information, such as traffic signs. Road geometry is a factor that can affect the speed choice and speed perception. It is defined by the surface characteristics, the number of lanes, the width of each lane, the road curvature, the delineation, etc. Another factor is roadside development and objects near the road. Objects located very close to the road may force drivers to react, adapting their speed to the current situation. Other visible objects, even if they are far from the road, can also affect speed. For instance, the presence of trees, or buildings may cause drivers to slow down on those roads [33]. Objects can also cause driver distractions and overload.
- Temporary factors: Temporary factors may also affect driver behavior. The time of the day can affect speed, since usually less visual information is available at night than during the day. The presence of other road users may also affect driver speed, since drivers have to take into account the behavior of other cars, pedestrians, etc. There are other temporary factors such as parked cars, weather conditions [33], roadworks, or any special events that affect the traffic on specific roads [34].
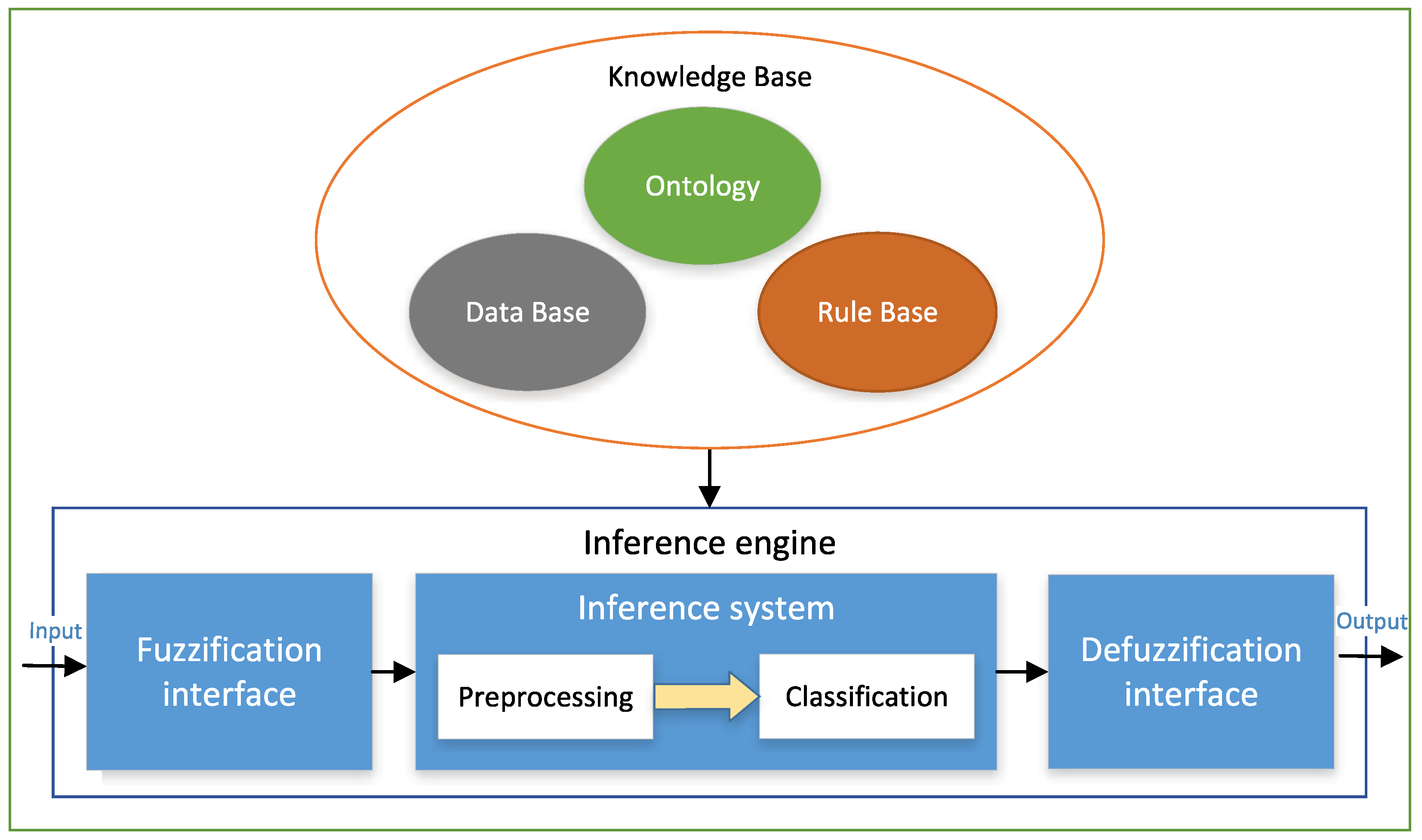
4. Architecture of the System for Driver Behavior Classification
4.1. The Inference Engine
- 1.
- The fuzzification interface allows the fuzzy rule-based system to translate crisp inputs to their corresponding values in the fuzzy sets with which the inference system operates. Fuzzification is the process of determining the membership degree of an input value to a specific fuzzy set. This process is performed via membership functions.
- 2.
- The inference system generates fuzzy outputs from fuzzy inputs obtained from the fuzzification interface, according to the rulebase. Each rule is evaluated using a conjunction operator and an implication operator. The classic conjunction and implication operators used in fuzzy logic are t-norm functions, due to their properties: monotonicity, associativity, commutativity, and having unity as the neutral element. Among the best known t-norms are the minimum and product functions. In this work, we have chosen the minimum as conjunction and implication operator, since it is the largest of the t-norms and therefore the most used in this type of system.The inference system is composed of two levels: the pre-processing level, which process the raw data to obtain the inputs for the classification, and the classification level, which obtains the final driver profile.
- 3.
- The defuzzification interface aggregates the information from the fuzzy sets and converts it into a crisp value (inference). Defuzzification can be performed in different modes, considering the order of aggregation and inference operations. In this work, we choose the mode FATI (First Aggregate, Then Infer) for defuzzification. Aggregation incorporates the individual fuzzy sets to a global one, using an aggregation operator. The aggregation operator is usually a t-conorm. This is due to the properties of this type of function: monotonicity, associativity, commutativity, and 0 as the neutral element. Examples of t-conorms are the maximum and sum functions. Maximum is the function for union in classical sets, so it is also the typical aggregation operator in fuzzy systems. In this work, we used the maximum t-conorm as aggregation operator for defuzzification.The second step consists of transforming the fuzzy set into a crisp value, using a defuzzification method. There is a great variety of defuzzification methods [37]. The most widely used are the centroid- and the maximum-based defuzzification techniques. In the case of the centroid technique, the crisp output value is computed as the center of the area of the membership function for the fuzzy value. In the maximum-based methods, the crisp output value is chosen from the values at which the membership degree is maximum. Depending on how this value is obtained from the maximum membership value set, there are some variations, such as the mean of maxima, the smallest maxima, and the largest maxima.For the selection of the defuzzification method, we tested the system with six of the most common defuzzification algorithms based on both the centroid and maximum approaches. These methods were: center of area (COA), fuzzy mean (FM), weighted fuzzy mean (WFM), first of maxima (FOM), last of maxima (LOM), and mean of maxima (MOM) [37]. In the case of centroid-based methods, the results are more disperse. This means that more membership functions are needed for more accurate classification. In contrast, in the maximum-based methods, as only the values with maximum membership are considered, the resulting sets of values are more delimited and therefore a more accurate result is obtained using fewer membership functions.From these results, we concluded that the more suitable approach for our system was the maximum-based one. Thus, we choose the last of maxima (LOM) as the defuzzification algorithm. In this method, the crisp output value selected is the largest of the values belonging to the set of values with the highest membership degree.
4.2. The Ontology
4.3. The Database
4.4. System Parameters
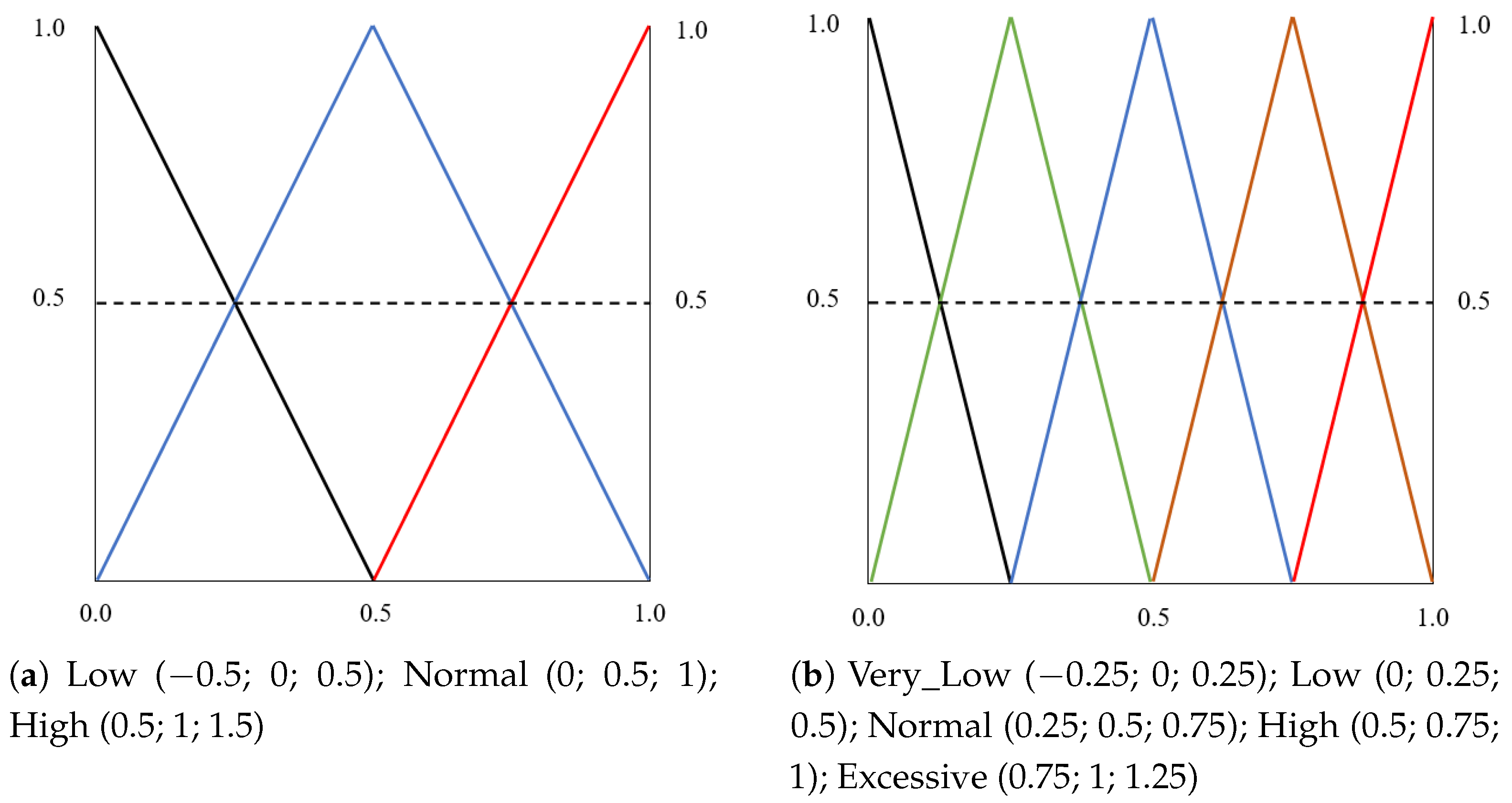
- Speed: Input variable, which describes the speed indicator. This parameter is computed as a fuzzy combination of three input values: (a) Low_Speed: percentage of times driving under the minimum speed limit; (b) High_Speed: percentage of times driving over the maximum speed limit; and (c) Normal_Speed: percentage of times driving within the correct speed limits. The fuzzy sets were designed using triangular-shaped membership functions representing the variables involved in the speed indicator computation (preprocessing level). Figure 4a shows the three fuzzy sets and membership functions that represent the input values for the speed indicator calculation. For the speed indicator output, we have defined five triangular membership functions (Figure 4b).
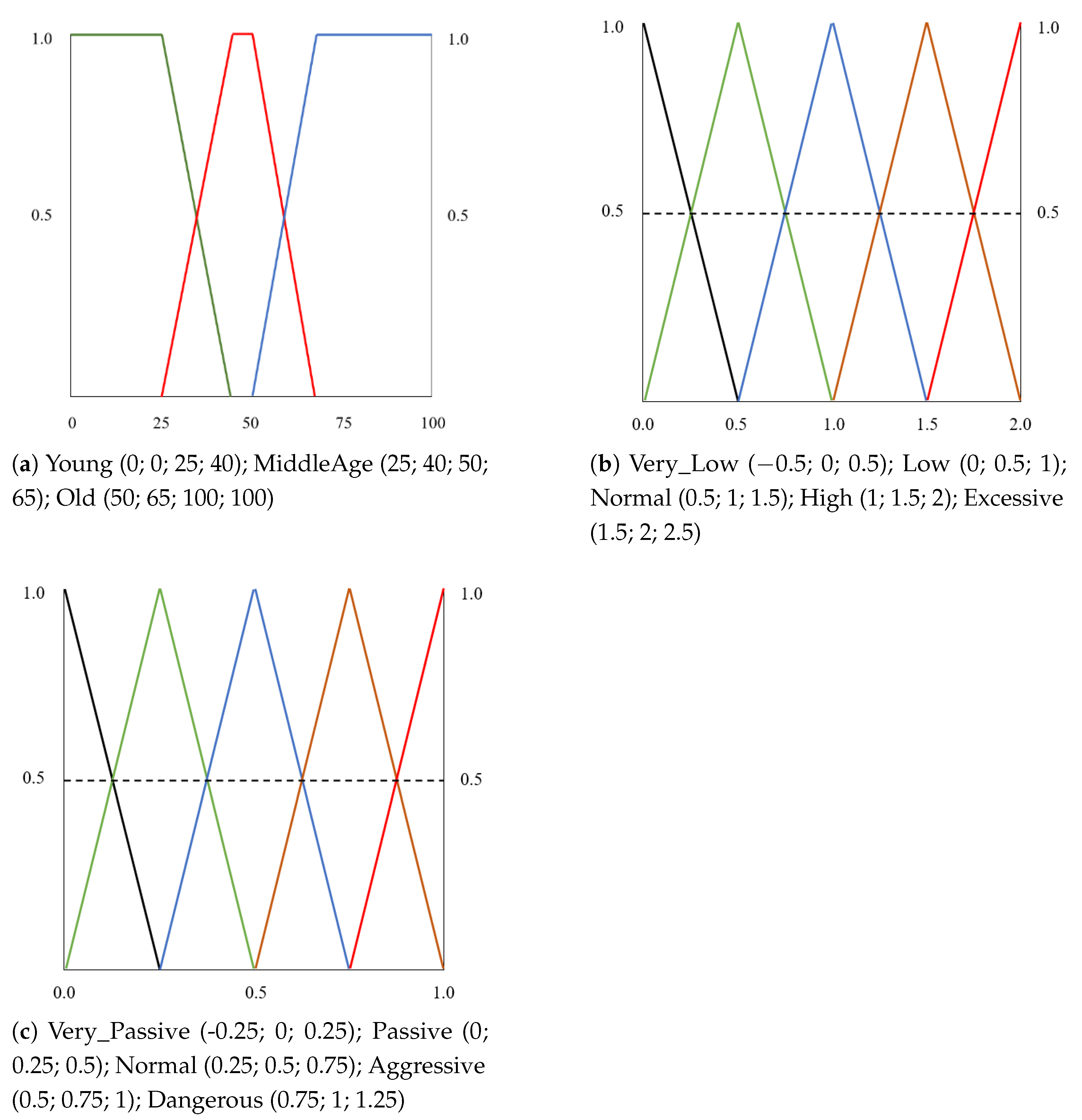
- Age: Describes the age of the driver, which is a well-known and widely used parameter, usually modeled using trapezoidal membership functions according to the age groups of the problem under study. Figure 5a shows the membership functions and fuzzy sets defined to describe the age in our setting.
- Acceleration and braking: Acceleration describes the way the accelerator pedal is used by the driver throughout the route. This parameter is computed as a fuzzy combination of three input values: (a) Low_Accel: percentage of times in which the driver should accelerate and does not accelerate; (b) High_Accel: percentage of times in which the driver should not accelerate and accelerates; and (c) Normal_Accel: percentage of times in which the driver makes correct use of the accelerator. Braking represents the way the brake is used by the driver throughout the route. This parameter is computed as a fuzzy combination of three input values: (a) Low_Brake: percentage of times in which the driver should brake and does not brake; (b) High_Brake: percentage of times in which the driver should not brake and brakes; (c) Normal_Brake: percentage of times in which the driver makes correct use of the brake. In both cases, the input variables of the preprocessing level were designed using triangular-shaped membership functions as presented in Figure 4a. For the acceleration and speed output, five fuzzy sets with triangular-shaped membership functions were defined. Figure 5b presents the membership functions and fuzzy sets defined to describe the acceleration and braking parameters.
- Driver profile: the output variable of the fuzzy system. It represents the driver profile. For this variable, 5 equally spaced, triangular-shaped membership functions were defined. Figure 5c presents the membership functions and fuzzy sets defined for the driver profile. The driver profile is classified into five categories: Very Passive, Passive, Normal, Aggressive, and Dangerous.
4.5. The Rulebase
5. Experiments
5.1. Validating the Classification Module and the Expressiveness of the Knowledge Base
- Number of segments in which the user drives over the maximum speed limit;
- Number of segments in which the user drives under the minimum speed limit;
- Number of segments in which the user drives within the allowed speed limits;
- Number of segments in which the driver should accelerate and does not accelerate;
- Number of segments in which the driver should not accelerate and accelerates;
- Number of segments in which the driver makes correct use of the accelerator;
- Number of segments in which the driver should brake and does not brake;
- Number of segments in which the driver should not brake and brakes;
- Number of segments in which the driver makes correct use of the brake.
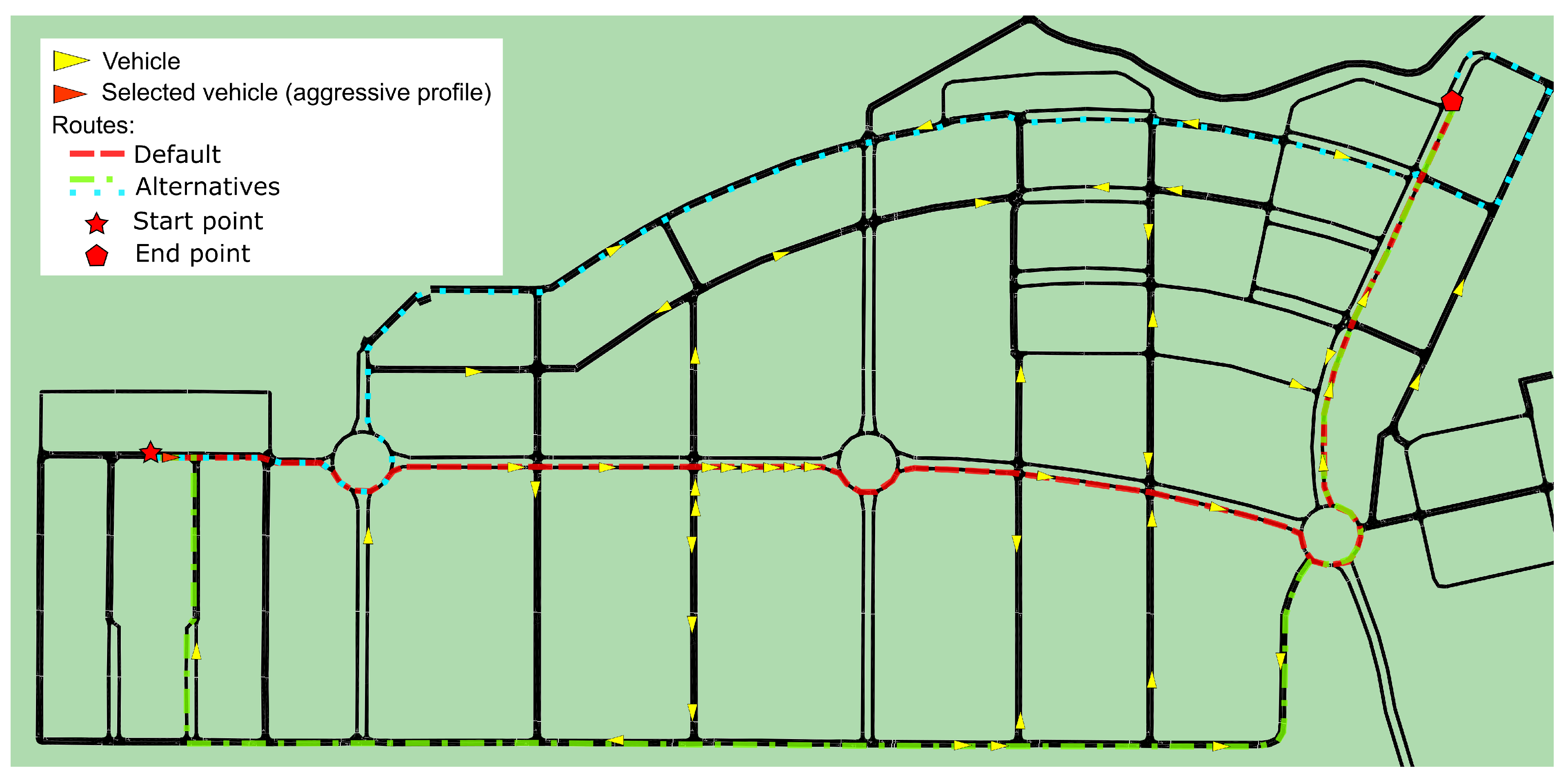
5.2. Traffic Flow Optimization Validation
- Vehicles: represents the number of vehicles used in the experiment;
- Alternative routes suggested: shows the percentage of cases in which alternative routes were suggested, considering the driver profile;
- Time gain: the percentage of cases where vehicles gained time after taking an alternative route;
- Time loss: the percentage of cases where the vehicles suffered a time loss after taking an alternative route;
- No change of time: the percentage of cases in which no gain or loss of time was experienced after taking an alternative route;
- Speed reduction suggested: the percentage of cases in which speed reduction was suggested;
- Speed increasing suggested: the percentage of cases in which speed increasing was suggested.
6. Conclusions and Upcoming Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| COA | Center of Area |
| FATI | First Aggregate, Then Infer |
| FM | Fuzzy Mean |
| FOM | First of Maxima |
| ITS | Intelligent Transportation Systems |
| JADE | JAVA Agent DEvelopment Framework |
| LOM | Last of Maxima |
| MOM | Mean of Maxima |
| MSE | Mean Square Error |
| WFM | Weighted Fuzzy Mean |
References
- Fernandez, S.; Ito, T. Semantic Integration of Sensor Data with SSN Ontology in a Multi-Agent Architecture for Intelligent Transportation Systems. IEICE Trans. Inf. Syst. 2017, 100, 2915–2922. [Google Scholar] [CrossRef]
- Hendricks, D.L.; Fell, J.C.; Freedman, M. The Relative Frequency of Unsafe Driving Acts in Serious Traffic Crashes; Technical report; National Highway Traffic Safety Administration: Washington, DC, USA, 2001. [Google Scholar]
- Marina Martinez, C.; Heucke, M.; Wang, F.Y.; Gao, B.; Cao, D. Driving Style Recognition for Intelligent Vehicle Control and Advanced Driver Assistance: A Survey. IEEE Trans. Intell. Transp. Syst. 2018, 19, 666–676. [Google Scholar] [CrossRef]
- Johnson, D.A.; Trivedi, M.M. Driving style recognition using a smartphone as a sensor platform. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems (ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1609–1615. [Google Scholar] [CrossRef]
- Huang, X.; Tan, Y.; He, X. An Intelligent Multifeature Statistical Approach for the Discrimination of Driving Conditions of a Hybrid Electric Vehicle. IEEE Trans. Intell. Transp. Syst. 2011, 12, 453–465. [Google Scholar] [CrossRef]
- Lin, N.; Zong, C.; Tomizuka, M.; Song, P.; Zhang, Z.; Li, G. An Overview on Study of Identification of Driver Behavior Characteristics for Automotive Control. Math. Probl. Eng. 2014, 2014, 569109. [Google Scholar] [CrossRef]
- Quintero M, C.G.; López, J.O.; Cuervo Pinilla, A.C. Driver behavior classification model based on an intelligent driving diagnosis system. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 894–899. [Google Scholar] [CrossRef]
- Khodairy, M.A.; Abosamra, G. Driving Behavior Classification Based on Oversampled Signals of Smartphone Embedded Sensors Using an Optimized Stacked-LSTM Neural Networks. IEEE Access 2021, 9, 4957–4972. [Google Scholar] [CrossRef]
- Yao, Y.; Zhao, X.; Wu, Y.; Zhang, Y.; Rong, J. Clustering driver behavior using dynamic time warping and hidden Markov model. J. Intell. Transp. Syst. 2021, 25, 249–262. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, K.; Zhao, L.; Fan, P. A driving intention prediction method based on hidden Markov model for autonomous driving. Comput. Commun. 2020, 157, 143–149. [Google Scholar] [CrossRef]
- Qi, W. Fuzzy control strategy of pure electric vehicle based on driving intention recognition. J. Intell. Fuzzy Syst. 2020, 39, 5131–5139. [Google Scholar] [CrossRef]
- Moslem, S.; Gul, M.; Farooq, D.; Celik, E.; Ghorbanzadeh, O.; Blaschke, T. An Integrated Approach of Best-Worst Method (BWM) and Triangular Fuzzy Sets for Evaluating Driver Behavior Factors Related to Road Safety. Mathematics 2020, 8, 414. [Google Scholar] [CrossRef]
- Hong, Z.; Chen, Y.; Wu, Y. A driver behavior assessment and recommendation system for connected vehicles to produce safer driving environments through a “follow the leader” approach. Accid. Anal. Prev. 2020, 139, 105460. [Google Scholar] [CrossRef]
- Feng, X.; Cen, Z.; Hu, J.; Zhang, Y. Vehicle Trajectory Prediction Using Intention-based Conditional Variational Autoencoder. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3514–3519. [Google Scholar] [CrossRef]
- Adamidis, F.K.; Mantouka, E.G.; Vlahogianni, E.I. Effects of controlling aggressive driving behavior on network-wide traffic flow and emissions. Int. J. Transp. Sci. Technol. 2020, 9, 263–276. [Google Scholar] [CrossRef]
- Mohammadnazar, A.; Arvin, R.; Khattak, A.J. Classifying travelers’ driving style using basic safety messages generated by connected vehicles: Application of unsupervised machine learning. Transp. Res. Part Emerg. Technol. 2021, 122, 102917. [Google Scholar] [CrossRef]
- Würtz, S.; Göhner, U. Driving Style Analysis Using Recurrent Neural Networks with LSTM Cells. J. Adv. Inf. Technol. 2020, 11, 1–9. [Google Scholar] [CrossRef]
- Shahverdy, M.; Fathy, M.; Berangi, R.; Sabokrou, M. Driver behavior detection and classification using deep convolutional neural networks. Expert Syst. Appl. 2020, 149, 113240. [Google Scholar] [CrossRef]
- Chen, J.C.; Lee, C.Y.; Huang, P.Y.; Lin, C.R. Driver Behavior Analysis via Two-Stream Deep Convolutional Neural Network. Appl. Sci. 2020, 10, 1908. [Google Scholar] [CrossRef]
- Alvarez-Coello, D.; Klotz, B.; Wilms, D.; Fejji, S.; Gómez, J.M.; Troncy, R. Modeling dangerous driving events based on in-vehicle data using Random Forest and Recurrent Neural Network. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 165–170. [Google Scholar] [CrossRef]
- Maier, C.; Mattke, J.; Pflügner, K.; Weitzel, T. Smartphone use while driving: A fuzzy-set qualitative comparative analysis of personality profiles influencing frequent high-risk smartphone use while driving in Germany. Int. J. Inf. Manag. 2020, 55, 102207. [Google Scholar] [CrossRef]
- Eftekhari, H.R.; Ghatee, M. A similarity-based neuro-fuzzy modeling for driving behavior recognition applying fusion of smartphone sensors. J. Intell. Transp. Syst. 2019, 23, 72–83. [Google Scholar] [CrossRef]
- De Rango, F.; Tropea, M.; Serianni, A.; Cordeschi, N. Fuzzy inference system design for promoting an eco-friendly driving style in IoV domain. Veh. Commun. 2021, 34, 100415. [Google Scholar] [CrossRef]
- Fernandez, S.; Ito, T. Driver classification for intelligent transportation systems using fuzzy logic. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1212–1216. [Google Scholar] [CrossRef]
- Wang, W.; Xi, J.; Zhao, D. Driving Style Analysis Using Primitive Driving Patterns With Bayesian Nonparametric Approaches. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2986–2998. [Google Scholar] [CrossRef]
- Pramunanto, E.; Zaini, A.; Rizkiana, V. Prototype of Driving Behavior Monitoring System Using Naïve Bayes Classification Method. In Proceedings of the 2019 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 17–18 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Huang, C.; Wang, X.; Cao, J.; Wang, S.; Zhang, Y. HCF: A Hybrid CNN Framework for Behavior Detection of Distracted Drivers. IEEE Access 2020, 8, 109335–109349. [Google Scholar] [CrossRef]
- Chen, L.W.; Chen, H.M. Driver Behavior Monitoring and Warning With Dangerous Driving Detection Based on the Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7232–7241. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Di, W.; Wei, J. Deep Learning Essentials; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Ericsson, E. Variability in urban driving patterns. Transp. Res. Part Transp. Environ. 2000, 5, 337–354. [Google Scholar] [CrossRef]
- Padilla, J.L.; Castro, C.; Doncel, P.; Taubman-Ben-Ari, O. Adaptation of the multidimensional driving styles inventory for Spanish drivers: Convergent and predictive validity evidence for detecting safe and unsafe driving styles. Accid. Anal. Prev. 2020, 136, 105413. [Google Scholar] [CrossRef] [PubMed]
- Vivoli, R.; Bergomi, M.; Rovesti, S.; Bussetti, P.; Guaitoli, G. Biological and behavioral factors affecting driving safety. J. Prev. Med. Hyg. 2006, 47, 69–73. [Google Scholar] [PubMed]
- Kilpeläinen, M.; Summala, H. Effects of weather and weather forecasts on driver behaviour. Transp. Res. Part Traffic Psychol. Behav. 2007, 10, 288–299. [Google Scholar] [CrossRef]
- Elliott, M.A.; McColl, V.; Kennedy, J.V. Road Design Measures to Reduce Drivers’ Speed via ’Psychological’ Processes: A Literature Review; Transport Research Laboratory: Crowthorne, UK, 2003. [Google Scholar]
- Mamdani, E.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int. J.-Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Fernández, S.; Marsa-Maestre, I.; Velasco, J.R. Performing Ontology Alignment via a Fuzzy-Logic Multi-layer Architecture. In Communications in Computer and Information Science, Proceedings of the Knowledge Discovery, Knowledge Engineering and Knowledge Management, Barcelona, Spain, 4–7 October 2012; Fred, A., Dietz, J.L.G., Liu, K., Filipe, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 194–210. [Google Scholar]
- Fortemps, P.; Roubens, M. Ranking and defuzzification methods based on area compensation. Fuzzy Sets Syst. 1996, 82, 319–330. [Google Scholar] [CrossRef]
- Fernandez, S.; Ito, T. Driver Behavior Model Based on Ontology for Intelligent Transportation Systems. In Proceedings of the 2015 IEEE 8th International Conference on Service-Oriented Computing and Applications (SOCA), Washington, DC, USA, 19–21 October 2015; pp. 227–231. [Google Scholar] [CrossRef]
- Fernandez, S.; Ito, T.; Hadfi, R. Architecture for Intelligent Transportation System Based in a General Traffic Ontology. In Studies in Computational Intelligence, Proceedings of the Computer and Information Science 2015, Las Vegas, NV, USA, 29 June–1 July 2015; Lee, R., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 43–55. [Google Scholar]
- Hattori, H.; Nakajima, Y.; Ishida, T. Learning From Humans: Agent Modeling With Individual Human Behaviors. IEEE Trans. Syst. Man, Cybern.-Part Syst. Humans 2011, 41, 1–9. [Google Scholar] [CrossRef]
- Thrift, P.R. Fuzzy Logic Synthesis with Genetic Algorithms. In Proceedings of the ICGA, San Diego, CA, USA, 15 July 1991; pp. 509–513. [Google Scholar]
- Davis, L. Handbook of Genetic Algorithms; Van Nostrand Reinhold Company: Washington, DC, USA, 1991. [Google Scholar]
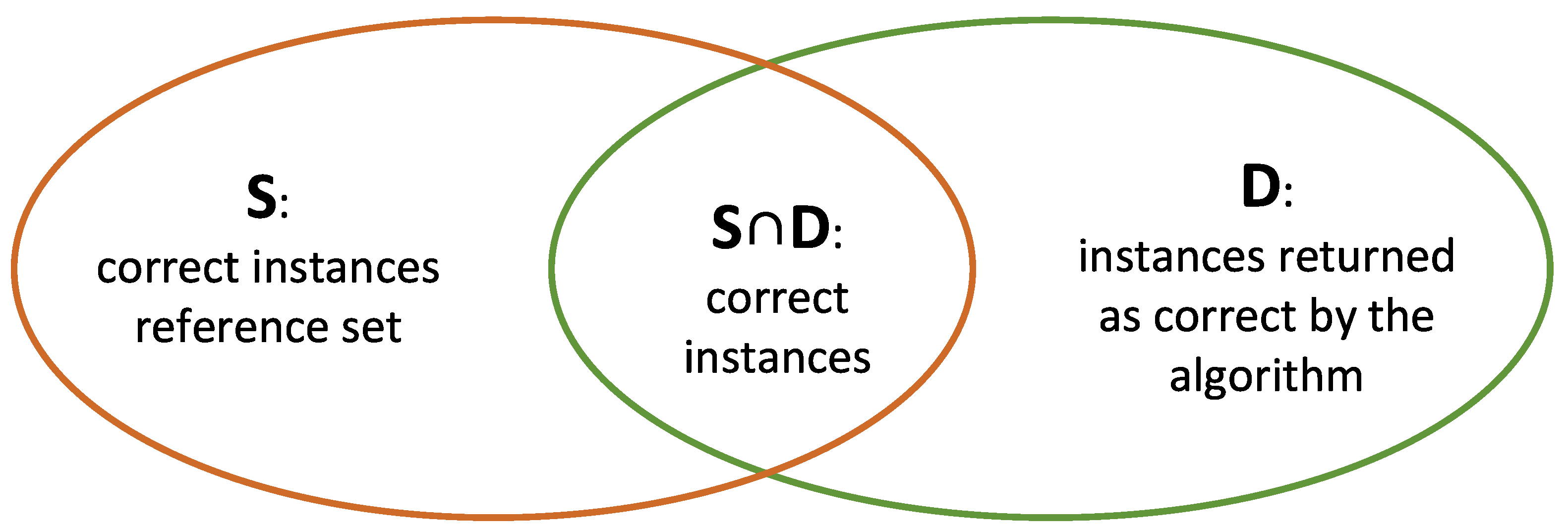
- van Rijsbergen, C. Information Retrieval, 2nd ed.; Butterworths: London, UK, 1979. [Google Scholar]
- Sirin, E.; Parsia, B.; Grau, B.C.; Kalyanpur, A.; Katz, Y. Pellet: A practical OWL-DL reasoner. J. Web Semant. 2007, 5, 51–53. [Google Scholar] [CrossRef]
- Pérez, J.; Arenas, M.; Gutierrez, C. Semantics and Complexity of SPARQL. ACM Trans. Database Syst. 2009, 34, 1–45. [Google Scholar] [CrossRef]
- Jade Site|Java Agent DEvelopment Framework. Available online: https://jade.tilab.com/ (accessed on 4 January 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rule | Antecedent | Consequent |
|---|---|---|
| 1 | Car(x) ∧ Curve(y) ∧ On(x, y) | Release_Accelerator |
| 2 | Car(x) ∧ Straight(y) ∧ On(y, x) | Accelerate |
| 3 | Car(x) ∧ HillUp(y) ∧ On(y, x) | Accelerate |
| 4 | Car(x) ∧ HillDown(y) ∧ On(y, x) | Release_Accelerator |
| 5 | Car(x) ∧ Curve(y) ∧ InSight(y, x) | Release_Accelerator |
| 6 | Car(x) ∧ Straight(y) ∧ InSight(y, x) | Accelerate |
| 7 | Car(x) ∧ HillUp(y) ∧ InSight(y, x) | Accelerate |
| 8 | Car(x) ∧ HillDown(y) ∧ InSight(y, x) | Release_Accelerator |
| 9 | Car(x) ∧ OverSpeed(x) | Release_Accelerator |
| 10 | Car(x) ∧ UnderSpeed(x) | Accelerate |
| Rule | Antecedent | Consequent (Profile) |
|---|---|---|
| 1 | Age (“old”) ∧ Accelerator (“very_low”) ∧ Brake (“very_high”) ∧ Speed (“very_low”) | Very passive |
| 2 | Age (“old”) ∧ Accelerator (“low”) ∧ Brake (“high”) ∧ Speed (“low”) | Passive |
| 3 | Age (“Middle”) ∧ Accelerator (“normal”) ∧ Brake (“normal”) ∧ Speed (“normal”) | Normal |
| 4 | Age (“young”) ∧ Accelerator (“high”) ∧ Brake (“low”) ∧ Speed (“high”) | Aggressive |
| 5 | Age (“young”) ∧ Accelerator (“excessive”) ∧ Brake (“very_low”) ∧ Speed (“excessive”) | Dangerous |
| Classification Method | MSE | Precision | Recall | F1 |
|---|---|---|---|---|
| Fuzzy classifier | 0.17 | 0.82 | 0.87 | 0.84 |
| Random Forest classifier | 0.23 | 0.68 | 0.70 | 0.69 |
| Naive Bayes classifier | 0.36 | 0.51 | 0.36 | 0.42 |
| Test | Precision | Recall | F1 |
|---|---|---|---|
| Q1 (Driver behavior model) | 0.78 | 0.99 | 0.87 |
| Q1.1 (Perception) | 0.80 | 0.96 | 0.87 |
| Q1.2 (Physical state) | 0.75 | 1 | 0.86 |
| Q1.3 (Cognitive state) | 0.77 | 0.98 | 0.86 |
| Q1.4 (Actions) | 0.78 | 1 | 0.88 |
| Q2 (Traffic ontology) | 0.84 | 0.95 | 0.89 |
| Q2.1 (Vehicles) | 0.85 | 0.93 | 0.89 |
| Q2.2 (Infrastructure) | 0.92 | 0.95 | 0.93 |
| Q2.3 (Traffic) | 0.76 | 0.97 | 0.85 |
| Vehicles | Alternative Routes Suggested | Time Gain | Time Loss | No Change of Time | Speed Reduction Suggested | Speed Increasing Suggested |
|---|---|---|---|---|---|---|
| 50–150 | 14.5% | 82.7% | 7% | 10.3% | 5.2% | 2.1% |
| 150–300 | 10.8% | 60.4% | 12.5% | 27.1% | 3.7% | 1.3% |
| 300–500 | 7.3% | 56.1% | 13.7% | 30.2% | 3.3% | 2.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernandez, S.; Ito, T.; Cruz-Piris, L.; Marsa-Maestre, I. Fuzzy Ontology-Based System for Driver Behavior Classification. Sensors 2022, 22, 7954. https://doi.org/10.3390/s22207954
Fernandez S, Ito T, Cruz-Piris L, Marsa-Maestre I. Fuzzy Ontology-Based System for Driver Behavior Classification. Sensors. 2022; 22(20):7954. https://doi.org/10.3390/s22207954
Chicago/Turabian StyleFernandez, Susel, Takayuki Ito, Luis Cruz-Piris, and Ivan Marsa-Maestre. 2022. "Fuzzy Ontology-Based System for Driver Behavior Classification" Sensors 22, no. 20: 7954. https://doi.org/10.3390/s22207954
APA StyleFernandez, S., Ito, T., Cruz-Piris, L., & Marsa-Maestre, I. (2022). Fuzzy Ontology-Based System for Driver Behavior Classification. Sensors, 22(20), 7954. https://doi.org/10.3390/s22207954