


Deep Learning for LiDAR Point Cloud Classification in Remote Sensing



Abstract
1. Introduction
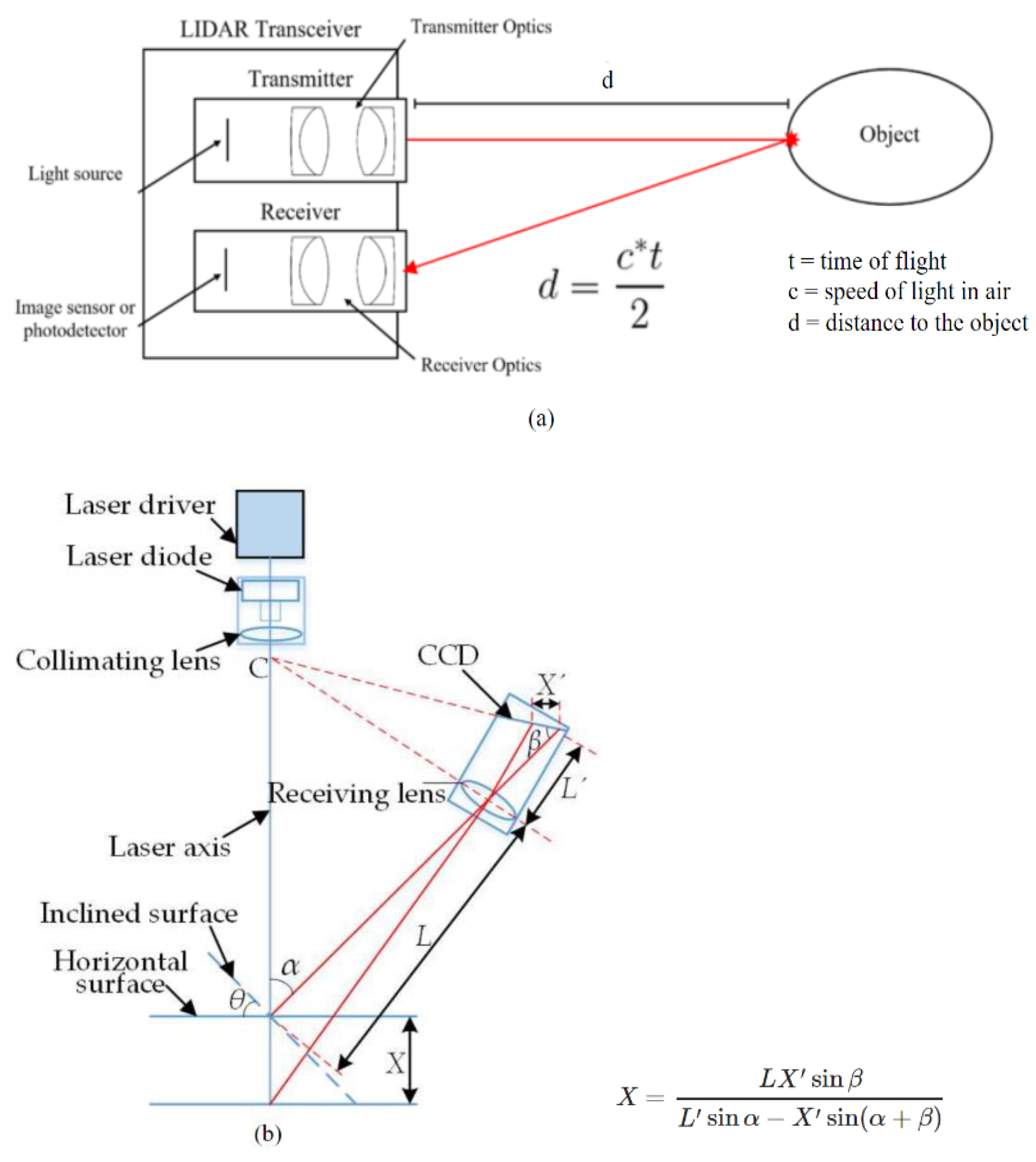
2. LiDAR Point Clouds
3. Point Cloud Computing
4. Deep Learning Models
4.1. Projection-Based Methods
- 2D Convolutional Neural Networks
- Multiview representation
- Volumetric grid representation
4.2. Point-Based Methods
- PointNets
- (Graph) Convolutional Point Networks
5. Benchmark Datasets
6. Performance Metrics
7. Comparative Analysis
8. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carter, J.; Schmid, K.; Waters, K.; Betzhold, L.; Hadley, B.; Mataosky, R.; Halleran, J. Lidar 101: An Introduction to Lidar Technology, Data, and Applications. (NOAA) Coastal Services Center. Available online: https://coast.noaa.gov/data/digitalcoast/pdf/lidar-101.pdf (accessed on 13 April 2022).
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Zhong, M.; Sui, L.; Wang, Z.; Hu, D. Pavement Crack Detection from Mobile Laser Scanning Point Clouds Using a Time Grid. Sensors 2020, 20, 4198. [Google Scholar] [CrossRef]
- Xiu, H.; Shinohara, T.; Matsuoka, M.; Inoguchi, M.; Kawabe, K.; Horie, K. Collapsed Building Detection Using 3D Point Clouds and Deep Learning. Remote Sens. 2020, 12, 4057. [Google Scholar] [CrossRef]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 147, 178–192. [Google Scholar] [CrossRef]
- Pierdicca, R.; Paolanti, M.; Matrone, F.; Martini, M.; Morbidoni, C.; Malinverni, E.S.; Frontoni, E.; Lingua, A.M. Point Cloud Semantic Segmentation Using a Deep Learning Framework for Cultural Heritage. Remote Sens. 2020, 12, 1005. [Google Scholar] [CrossRef]
- Dong, P.; Chen, Q. LiDAR Remote Sensing and Applications; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 2018. [Google Scholar]
- Evans, J.S.; Hudak, A.T.; Faux, R.; Smith, A.M.S. Discrete Return Lidar in Natural Resources: Recommendations for Project Planning, Data Processing, and Deliverables. Remote Sens. 2009, 1, 776–794. [Google Scholar] [CrossRef]
- Michałowska, M.; Rapiński, J. A Review of Tree Species Classification Based on Airborne LiDAR Data and Applied Classifiers. Remote Sens. 2021, 13, 353. [Google Scholar] [CrossRef]
- Pirotti, F. Analysis of full-waveform LiDAR data for forestry applications: A review of investigations and methods. iForest-Biogeosci. For. 2011, 4, 100–106. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Lisin, D.A.; Mattar, M.A.; Blaschko, M.B.; Benfield, M.C.; Learned-Mille, E.G. Combining Local and Global Image Features for Object Class Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Liu, W.; Sun, J.; Li, W.; Hu, T.; Wang, P. Deep Learning on Point Clouds and Its Application: A Survey. Sensors 2019, 19, 4188. [Google Scholar] [CrossRef] [PubMed]
- Wasser, L.A. The Basics of LiDAR—Light Detection and Ranging—Remote Sensing. NSF NEON|Open Data to Understand our Ecosystems, 22 October 2020. Available online: https://www.neonscience.org/resources/learning-hub/tutorials/lidar-basics (accessed on 1 September 2022).
- Varshney, V. LiDAR: The Eyes of an Autonomous Vehicle. Available online: https://medium.com/swlh/lidar-the-eyes-of-an-autonomous-vehicle-82c6252d1101 (accessed on 15 August 2022).
- Dong, Z.; Sun, X.; Chen, C.; Sun, M. A Fast and On-Machine Measuring System Using the Laser Displacement Sensor for the Contour Parameters of the Drill Pipe Thread. Sensors 2018, 18, 1192. [Google Scholar] [CrossRef]
- Ioannidou, A.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. Deep learning advances in computer vision with 3D data: A survey. ACM Comput. Surv. 2017, 50, 1–38. [Google Scholar] [CrossRef]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollar, P. Panoptic Segmentation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Zhang, R.; Li, G.; Li, M.; Wang, L. Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 143, 85–96. [Google Scholar] [CrossRef]
- Du, J.; Jiang, Z.; Huang, S.; Wang, Z.; Su, J.; Su, S.; Wu, Y.; Cai, G. Point Cloud Semantic Segmentation Network Based on Multi-Scale Feature Fusion. Sensors 2021, 21, 1625. [Google Scholar] [CrossRef] [PubMed]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-view Spatial Feature Fusion for 3D Object Detection. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 720–736. [Google Scholar]
- Zhang, Z.; Chen, G.; Wang, X.; Shu, M. DDRNet: Fast point cloud registration network for large-scale scenes. ISPRS J. Photogramm. Remote Sens. 2021, 175, 184–198. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Holschneider, M.; Kronland-Martinet, R.; Morlet, J.; Tchamitchian, P. A Real-Time Algorithm for Signal Analysis with the Help of the Wavelet Transform; Wavelets: Berlin/Heidelberg, Germany, 1990. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. Computer Vision and Pattern Recognition. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Computer Vision and Pattern Recognition (CVPR). arXiv Preprint 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. PointASNL: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5589–5598. [Google Scholar]
- Li, J.; Chen, B.M.; Lee, G.H. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Boulch, A. ConvPoint: Continuous convolutions for point cloud processing. Comput. Graph. 2020, 88, 24–34. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Cao, D.; Li, J. TGNet: Geometric Graph CNN on 3-D Point Cloud Segmentation. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3588–3600. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A Deep Representation for Volumetric Shapes. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Kölle, M.; Laupheimer, D.; Schmohl, S.; Haala, N.; Rottensteiner, F.; Wegner, J.D.; Ledoux, H. The Hessigheim 3D (H3D) benchmark on semantic segmentation of high-resolution 3D point clouds and textured meshes from UAV LiDAR and Multi-View-Stereo. ISPRS Open J. Photogramm. Remote Sens. 2021, 1, 100001. [Google Scholar] [CrossRef]
- Lian, Y.; Feng, T.; Zhou, J.; Jia, M.; Li, A.; Wu, Z.; Jiao, L.; Brown, M.; Hager, G.; Yokoya, N.; et al. Large-Scale Semantic 3-D Reconstruction: Outcome of the 2019 IEEE GRSS Data Fusion Contest-Part B. IEEE Journal of Selected Topics in Applied Observations and Remote Sensing 2021, 14, 1158–1170. [Google Scholar] [CrossRef]
- Current Height File Netherlands 3 (AHN3). Available online: http://data.europa.eu/88u/dataset/41daef8b-155e-4608-b49c-c87ea45d931c (accessed on 8 April 2022).
- Wichmann, A.; Agoub, A.; Kada, M. RoofN3D: Deep Learning Training Data for 3D Building Reconstruction. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-2, 1191–1198. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9297–9307. [Google Scholar]
- Thomas, H.; Goulette, F.; Deschaud, J.-E.; Marcotegui, B.; LeGall, Y. Semantic Classification of 3D Point Clouds with Multiscale Spherical Neighborhoods. In Proceedings of the International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 390–398. [Google Scholar]
- Roynard, X.; Deschaud, J.-E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Li, J. Toronto-3D: A large-scale mobile lidar dataset for semantic segmentation of urban roadways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 202–203. [Google Scholar]
- Matrone, F.; Lingua, A.; Pierdicca, R.; Malinverni, E.S.; Paolanti, M.; Grilli, E.; Remondino, F.; Murtiyoso, A.; Landes, T. A Benchmark For Large-Scale Heritage Point Cloud Semantic Segmentation. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2-2, 1419–1426. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Schindler and M. Pollefeys. Semantic3d. net: A new large-scale point cloud classification benchmark. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, IV-1-W1, 91–98. [Google Scholar] [CrossRef]
- Trochta, J.; Krůček, M.; Vrška, T.; Král, K. 3D Forest: An application for descriptions of three-dimensional forest structures using terrestrial LiDAR. PLoS ONE 2017, 12, e0176871. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Boulch, A.; Puy, G.; Marlet, R. FKAConv: Feature-kernel alignment for point cloud convolution. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Geng, X.; Ji, S.; Lu, M.; Zhao, L. Multi-Scale Attentive Aggregation for LiDAR Point Cloud Segmentation. Remote Sens. 2021, 13, 691. [Google Scholar] [CrossRef]
- Han, X.; Dong, Z.; Yang, B. A point-based deep learning network for semantic segmentation of MLS point clouds. ISPRS J. Photogramm. Remote Sens. 2021, 175, 199–214. [Google Scholar] [CrossRef]
- Özdemir, E.; Remondino, F.; Golkar, A. Aerial Point Cloud Classification with Deep Learning and Machine Learning Algorithms. ISPRS-Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019, XLII-4/W18, 843–849. [Google Scholar] [CrossRef]
- Shajahan, D.A.; Nayel, V.; Muthuganapathy, R. Roof Classification From 3-D LiDAR Point Clouds Using Multiview CNN With Self-Attention. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1465–1469. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, L.; Zhong, R.; Chen, D.; Zhang, L.; Li, X.; Wang, Q.; Chen, S. Hierarchical Aggregated Deep Features for ALS Point Cloud Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1686–1699. [Google Scholar] [CrossRef]
- Lei, X.; Wang, H.; Wang, C.; Zhao, Z.; Miao, J.; Tian, P. ALS Point Cloud Classification by Integrating an Improved Fully Convolutional Network into Transfer Learning with Multi-Scale and Multi-View Deep Features. Sensors 2020, 20, 6969. [Google Scholar] [CrossRef] [PubMed]
- Huang, R.; Xu, Y.; Hong, D.; Yao, W.; Ghamisi, P.; Stilla, U. Deep point embedding for urban classification using ALS point clouds: A new perspective from local to global. ISPRS J. Photogramm. Remote Sens. 2020, 163, 62–81. [Google Scholar] [CrossRef]
- Krisanski, S.; Taskhiri, M.; Aracil, S.G.; Herries, D.; Turner, P. Sensor Agnostic Semantic Segmentation of Structurally Diverse and Complex Forest Point Clouds Using Deep Learning. Remote Sens. 2021, 13, 1413. [Google Scholar] [CrossRef]
- Shinohara, T.; Xiu, H.; Matsuoka, M. FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning. Sensors 2020, 20, 3568. [Google Scholar] [CrossRef]
- Wen, C.; Yang, L.; Li, X.; Peng, L.; Chi, T. Directionally constrained fully convolutional neural network for airborne LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 162, 50–62. [Google Scholar] [CrossRef]
- Turgeon-Pelchat, M.; Foucher, S.; Bouroubi, Y. Deep Learning-Based Classification of Large-Scale Airborne LiDAR Point Cloud. Can. J. Remote Sens. 2021, 47, 381–395. [Google Scholar] [CrossRef]
- Zhang, L. Deep Learning-Based Classification and Reconstruction of Residential Scenes from Large-Scale Point Clouds. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1887–1897. [Google Scholar] [CrossRef]
- Wen, C.; Li, X.; Yao, X.; Peng, L.; Chi, T. Airborne LiDAR point cloud classification with global-local graph attention convolution neural network. ISPRS J. Photogramm. Remote Sens. 2021, 173, 181–194. [Google Scholar] [CrossRef]
- Widyaningrum, E.; Bai, Q.; Fajari, M.; Lindenbergh, R. Airborne Laser Scanning Point Cloud Classification Using the DGCNN Deep Learning Method. Remote Sens. 2021, 13, 859. [Google Scholar] [CrossRef]
- Ghasemieh, A.; Kashef, R. 3D object detection for autonomous driving: Methods, models, sensors, data, and challenges. Transportation Engineering 2022, 8, 100115. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Jebamikyous, H.H.; Kashef, R. Autonomous Vehicles Perception (AVP) Using Deep Learning: Modeling, Assessment, and Challenges. IEEE Access 2022, 10, 10523–10535. [Google Scholar] [CrossRef]
- Jebamikyous, H.H.; Kashef, R. (2021, December). Deep Learning-Based Semantic Segmentation in Autonomous Driving. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing & Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Haikou, Hainan, China, 20–22 December 2021. [Google Scholar]


{kind=link}
| Dataset | Data Type | Data Format | Points/Objects | No. of Classes | Density |
|---|---|---|---|---|---|
| ModelNet40 [40] | 3D CAD | OFF Files | 127,915 Models | 40 | N/A |
| ISPRS 3D Vaihingen [41] | ALS LiDAR | x, y, z, reflectance, return count | 780.9 K pts | 9 | 4–8 pts/m2 |
| Hessigheim 3D [42] | ALS LiDAR | x, y, z, intensity, return count | 59.4 M training pts, 14.5 M validation pts | 11 | 800 pts/m2 |
| 2019 IEEE GRSS Data fusion contest [43] | ALS LiDAR | x, y, z, intensity, return count | 83.7 M training pts, 83.7 M validation pts | 6 | Very dense |
| AHN(3) [44] | ALS LiDAR | x, y, z, intensity, return count, additional normalization, and location data | 190.3 M pts | 5 | 20 pts/m2 |
| RoofN3D [45] | ALS LiDAR | multipoints, multipolygons | 118.1 K roofs | 3 | 4.72 pts/m2 |
| semanticKITTI [46] | MLS LiDAR | x, y, z, reflectance, GPS data | 4.549 K pts | 25 (28) | Sparse |
| S3DIS [47] | Indoor Structured-light 3D scanner | x, y, z, r, g, b | 215.0 M pts | 12 | 35,800 pts/m2 |
| Paris-Lille-3D [48] | MLS LiDAR | x, y, z, reflectance, additional position data | 143.1 M pts | 10 coarse (50 total) | 1000–2000 pts/m2 |
| Toronto3D [49] | MLS LiDAR | x, y, z, r, g, b, intensity, additional position data | 78.3 M pts | 8 | 1000 pts/m2 |
| ArCH [50] | TLS LiDAR, TLS+ALS LiDAR | x, y, z, r, g, b, normalized coordinates | 102.1 M training pts, 34.0 M testing pts | 6–9 depending on the scene | subsampled differently depending on the scene |
| Semantic3D [51] | TLS LiDAR | x, y, z, intensity, r, g, b | 4.0 B pts | 8 | Very dense |
| 3D Forest [52] | TLS LiDAR | x, y, z, intensity | 467.2 K pts | 4 | 15–40 pts/m2 |
| Metric | Formula | |
|---|---|---|
| IoU | Where cij is ground truth class, i predicted as j | |
| mIoU | Where N is the number of classes | |
| OA | ||
| Precision | ||
| Recall | ||
| F1 score | ||
| Average precision (AP) | ||
| Kappa coefficient | ||
| ModelNet40 Object Classification | ||||||||||
| Method | OA | Class Average Accuracy | ||||||||
| PointNet [11] | 89.2 | 86.2 | ||||||||
| PointNet++ [13] | 91.9 | - | ||||||||
| ConvPoint [37] | 92.5 | 89.6 | ||||||||
| DGCNN [38] | 93.5 | 90.7 | ||||||||
| MVCNN [32] | 90.1 | 79.5 | ||||||||
| FKAConv [54] | 92.5 | 89.5 | ||||||||
| VoxNet [33] | 83.0 | - | ||||||||
| SO-Net [36] | 93.4 | 90.8 | ||||||||
| PointASNL [35] | 93.2 | - | ||||||||
| S3DIS Indoor Semantic segmentation | ||||||||||
| Method | OA | mIOU | ||||||||
| PointNet [11] | 78.62 | 47.71 | ||||||||
| ConvPoint/Fusion [37] | 85.2/88.8 | 62.6/68.2 | ||||||||
| DGCNN [38] | 84.1 | 56.1 | ||||||||
| PointASNL [35] | - | 68.7 | ||||||||
| TGNet [39] | 88.5 | 57.8 | ||||||||
| FKAConv [54] | - | 68.4 | ||||||||
| Toronto3D Urban MLS Semantic segmentation | ||||||||||
| Method | OA | mIoU | Road | Road mrk. | Natural | Bldg | Util. line | Pole | Car | Fence |
| PointNet++ [13] | 84.88 | 41.81 | 89.27 | 0.00 | 69.00 | 54.10 | 43.70 | 23.30 | 52.00 | 3.00 |
| DGCNN [38] | 94.24 | 61.79 | 93.88 | 0.00 | 91.25 | 80.39 | 62.40 | 62.32 | 88.26 | 15.81 |
| TGNet [39] | 94.08 | 61.34 | 93.54 | 0.00 | 90.83 | 81.57 | 65.26 | 62.98 | 88.73 | 7.85 |
| MSAAN [55] | 95.90 | 75.00 | 96.10 | 59.90 | 94.40 | 85.40 | 85.80 | 77.00 | 83.70 | 17.70 |
| ConvPoint * [37] | 96.07 | 74.82 | 97.07 | 54.83 | 93.55 | 90.60 | 82.9 | 76.19 | 92.93 | 12.42 |
| [56] | 93.6 | 70.8 | 92.2 | 53.8 | 92.8 | 86.0 | 72.2 | 72.5 | 75.7 | 21.2 |
| Paper | Category | Architecture(s) Based on/Proposed | Test Dataset | Performance 1 | Application |
|---|---|---|---|---|---|
| [5] | 2D Projection | CNN, cGAN | TUM MLS 2016 | 85.04 * | Road marking extraction, classification, and completion |
| [57] | 2D Projection | 1D CNN, 2D CNN, LSTM DNN | ISPRS 3D Vaihingen | 79.4 * | ALS Point cloud classification |
| [56] | 2D projection Point CNN | 3D Convolution U-Net | Toronto3D | 70.8 ^ | MLS Point cloud semantic segmentation |
| [58] | Multi-view Projection | MVCNN | RoofN3D | 99 * Saddleback 96 * Two-sided Hip 83 * Pyramid | Roof Classification |
| [59] | Voxelization | Clustering, Voxelization, 3D CNN | ISPRS 3D Vaihingen | 79.60 * | ALS Point cloud classification |
| [60] | Voxelization, 2D projection | DenseNet201 | ISPRS 3D Vaihingen | 83.62 * | ALS Point cloud classification |
| [61] | PointNet/MLP/FCL | PointNet++, Joint Manifold Learning, Global Graph-based | ISPRS 3D Vaihingen AHN3 | 66.2 * 83.7 * | ALS Point cloud classification |
| [62] | PointNet/MLP/FCL | PointNet++ | Proprietary | 95.4 ~ | TLS Forest Point cloud Semantic Segmentation |
| [21] | PointNet/MLP/FCL | MSSCN, MLP, Spatial Aggregation Network | S3DIS ScanNet | 89.8 ~ 86.3 ~ | Point Cloud Semantic Segmentation |
| [55] | PointNet/MLP/FCL | MSAAN, RandLA-Net | CSPC (scene-2, scene-5) Toronto3D | 64.5 ^, 61.8 ^, 75.0 ^ | Point Cloud Semantic Segmentation |
| [63] | PointNet/MLP/FCL | PointNet T-Nets, FWNet, 1D CNN | ZORZI et al. 2019 | 76 * | Full-Waveform LiDAR Semantic Segmentation |
| [64] | Point CNN | Dconv, CNN, U-Net | ISPRS 3D Vaihingen | 70.7 * | ALS Point cloud classification |
| [65] | Point CNN | ConvPoint, CNN | Saint-Jean NB (provincial website) Montreal QC (CMM) | 96.6 ^ 69.9 ^ | ALS Point cloud classification |
| [66] | Voxelization 3D CNN | 3D CNN, DQN | ISPRS 3D Vaihingen | 98.0 ~ | Point cloud classification and reconstruction |
| [67] | Graph/Point CNN | Graph attention CNN | ISPRS 3D Vaihingen | 71.5 * | ALS Point cloud classification |
| [68] | Graph/Point CNN | DGCNN | AHN3 | 89.7 * | ALS Point cloud classification |
| [6] | Graph/Point CNN | DGCNN | ArCH | 81.4 * | Cultural Heritage point cloud segmentation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diab, A.; Kashef, R.; Shaker, A. Deep Learning for LiDAR Point Cloud Classification in Remote Sensing. Sensors 2022, 22, 7868. https://doi.org/10.3390/s22207868
Diab A, Kashef R, Shaker A. Deep Learning for LiDAR Point Cloud Classification in Remote Sensing. Sensors. 2022; 22(20):7868. https://doi.org/10.3390/s22207868
Chicago/Turabian StyleDiab, Ahmed, Rasha Kashef, and Ahmed Shaker. 2022. "Deep Learning for LiDAR Point Cloud Classification in Remote Sensing" Sensors 22, no. 20: 7868. https://doi.org/10.3390/s22207868
APA StyleDiab, A., Kashef, R., & Shaker, A. (2022). Deep Learning for LiDAR Point Cloud Classification in Remote Sensing. Sensors, 22(20), 7868. https://doi.org/10.3390/s22207868