1. Introduction
With the rapid development of display technology, new video formats such as Ultra-High Definition (UHD), High Dynamic Range (HDR), and 360 videos have provided improved visual experiences. However, their considerable data volume is a challenge for video storage and real-time transmission. To compress different emerging video formats more efficiently, the Joint Video Experts Team (JVET) formulated a new generation of video compression standards in July 2020, namely, Versatile Video Coding (VVC) [
1].
Compared with High-Efficiency Video Coding (HEVC) [
2], VVC reduces the coding rate by more than 30% while maintaining the same subjective video quality [
3]. This is because many advanced coding techniques are introduced in VVC. To further remove the spatial coding redundancy, VVC proposes new technologies, such as extending the 35 intra prediction modes in HEVC to 67 [
4], multiple reference line (MRL) prediction [
5], and intra sub-partitioning (ISP) [
6]. Advanced techniques such as affine motion compensation prediction, adaptive motion vector resolution, and bidirectional optical flow have been proposed to further remove the temporal coding redundancy of VVC [
7]. In addition, to adapt to the different textures and motion characteristics of coding regions, VVC adopts a new coding structure, the quad-tree plus multi-type tree (QTMT) partition structure [
8], which can flexibly divide the coding unit (CU) into square and rectangular regions of different sizes. Although these new coding techniques can effectively improve the compression efficiency of intra and inter frames, they also drastically increase the coding complexity of VVC intra and inter frames, which has become a major obstacle to the deployment of VVC real-time applications. In particular, the flexible QTMT partition structure process accounts for considerable coding complexity [
9]. Therefore, it is necessary to ensure that fast decisions can be made in the QTMT partition process to greatly reduce the coding complexity of VVC.
The QTMT partition structure is an extension of the quad-tree (QT) partition structure in HEVC. In HEVC, the QT partition also occupies a considerable amount of coding complexity. To effectively reduce the coding complexity of HEVC, researchers have proposed many fast QT partition methods [
10,
11,
12,
13,
14,
15,
16]. These methods can be mainly classified into two categories: correlation-based methods and learning-based methods. For example, in [
12], a fast QT partition method is proposed by using the spatial and temporal correlation between the current coding CU and the coded CUs. In [
15], to accelerate the QT partition decision, the prediction model is trained by the deep learning method to predict the optimal QT partition in advance. However, these fast QT partition methods for HEVC cannot be directly used in the QTMT partition of VVC, because the multi-type tree (MT) partition is added to the QTMT partition structure, which makes the CU partition more flexible. In addition, many new coding techniques are applied to the QTMT partition structure, which results in the optimal CU partition in VVC and HEVC being different in the same coding regions.
To reduce the coding complexity of the intra VVC encoder, many fast CU decision methods [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29] have proposed the acceleration of intra QTMT partition. For example, in [
19], the authors propose a directional gradient-based early termination CU partition method in which four directional gradients (horizontal, vertical, 45, and 135) of CUs are extracted separately to represent the relationship between the optimal CU partition and the texture characteristics of the CU. In [
23], a fast decision method for QTMT partition with a cascaded decision structure composed of decision trees is proposed. In addition, the authors in [
25,
26,
27,
28,
29] adopted a deep-learning-based approach for fast QTMT partition decisions. However, these fast CU decision methods for intra QTMT partition cannot be directly used for inter QTMT partition, because the optimal intra CU partition of a CTU is mainly related to the texture characteristics of the CU under the intra coding. However, the optimal inter CU partition of a CTU is not only related to the CU’s texture characteristics but also related to the motion properties of the CU. Therefore, it is necessary to propose a fast inter QTMT partition decision method to reduce the inter coding complexity of VVC.
Researchers have proposed many fast CU partition decision methods for reducing the inter coding complexity of VVC [
30,
31,
32,
33]. In [
30], the difference between three frames is extracted to indicate that the CU is a motion block or a static block. If the CU is a static block, the CU is terminated for further partition early to reduce the complexity of inter coding. In [
31], three binary classifiers are established by using the random forest to accelerate the inter CU partition decision. In addition, the tunable risk interval is defined to obtain different coding complexity reductions. In [
32], combining the luminance, residual, and bidirectional motion information of the CU as the input information of a convolutional neural network (CNN), a multi-information fusion convolutional neural network (MF-CNN)-based early inter CU partition termination method is proposed. In addition, the Merge mode of the CU is terminated early using the residual information of the CU to further reduce the coding complexity of the inter CU. In [
33], a multi-level tree convolutional neural network (MLT-CNN) is proposed for a fast CU partition decision. First, the order of the decision process of CU is split into four levels: no partition–partition, QT partition–MT partition, binary tree (BT) partition–ternary tree (TT) partition, and vertical partition–horizontal partition. The MLT-CNN is then used to predict how the CU is split in each level. However, the temporal correlation of CU partition is not fully explored in VVC inter coding. Although many methods have proposed utilizing temporal correlation for fast QT-based CU partition decisions in HEVC, they cannot be directly used in the new QTMT-based CU partition. Therefore, it is possible to explore fast QTMT partition decisions based on temporal correlations. In this paper, we propose a temporal prediction model-based approach to predict CU partition to reduce the inter coding complexity of VVC. The main contributions are summarized as follows.
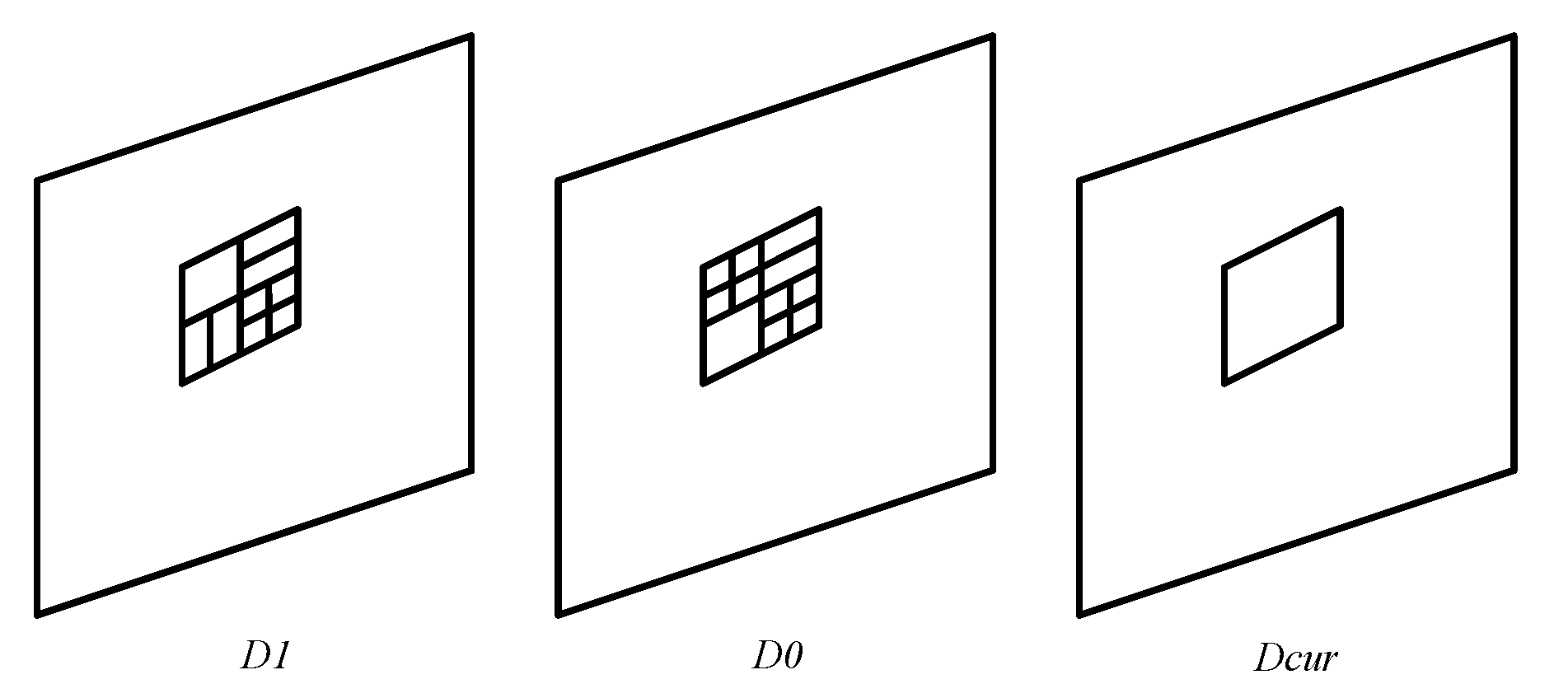
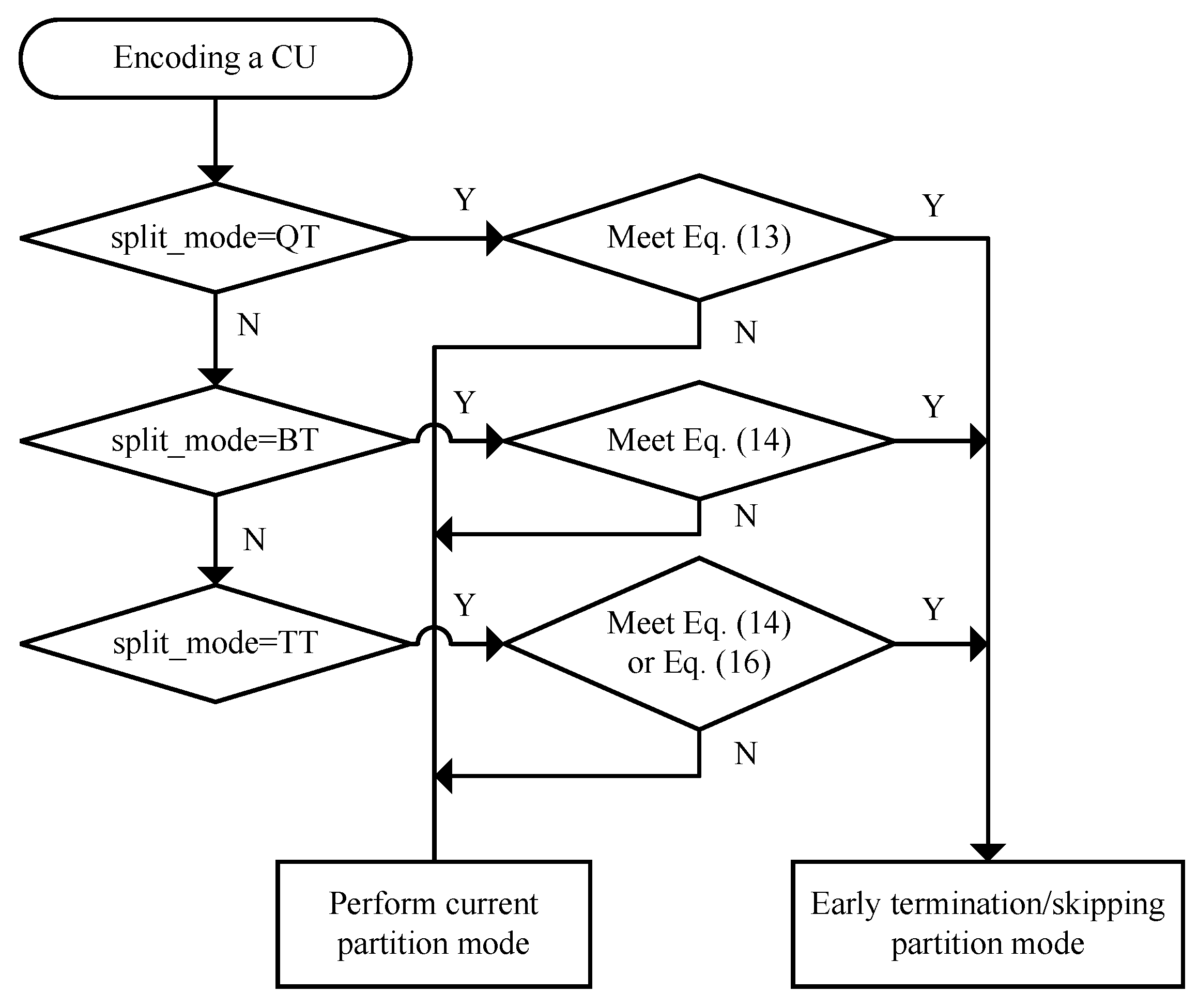
According to the partition of the encoded CU at the corresponding position of the current CU, we established a temporal prediction model to predict the optimal CU partition.
To reduce prediction errors, we further extract the motion vector information of the CU to determine whether the CU partition can be terminated early.
Compared with deep learning methods, our proposed method does not require the establishment of additional large datasets for training and does not require additional complex training to obtain decision parameters.
We organize the remainder of this paper as follows.
Section 2 presents the motivation and statistical analyses.
Section 3 presents the proposed fast inter CU partition method of VVC based on the temporal prediction model.
Section 4 presents the experimental results. The conclusion is in
Section 5.
2. Motivation and Statistical Analyses
A new QTMT-based CU partition structure is introduced in VVC to further improve the compression efficiency, and its flexible and changeable partition method is more suitable for video content with different textures and motion characteristics. In the VVC coding standard, a coding image is firstly split into multiple Coding Tree Units (CTUs), the default size of which is 128 × 128. Afterwards, the CTU is used as the root node for further hierarchical partition. The blocks obtained by the partition process are called Coding Units (CUs). A CTU can contain one CU or be recursively split into smaller square CUs or rectangular CUs, where a square CU can be obtained by QT partition, while a rectangular CU is obtained by MT partition. MT includes horizontal BT, vertical BT, horizontal TT, and vertical TT.
Figure 1 shows an example of optimal CU partition of a CTU, and the six partition methods supported by the CU. In order to obtain the optimal CTU partition, a 128 × 128 CTU will first perform a top-to-bottom multi-level hierarchical partition process until the minimum CU size is 4 × 4, and each CU needs to calculate the rate-distortion cost (RD cost). CU pruning is then performed in a bottom-up manner, and the CUs with the smallest RD cost are combined to obtain the optimal CTU partition. This method of obtaining the optimal CU partition through the brute-force search process will lead to a considerable increase in the coding complexity of VVC. Although a CTU needs to traverse CUs of different sizes, only a few CUs of different sizes are selected in the optimal CTU partition. If the optimal CU partition in the CTU can be predicted early, and the RD cost calculation of the remaining CUs can be skipped, the coding complexity of VVC can be effectively reduced.
2.1. The Distribution of Different CU Sizes
In VVC inter coding, a larger CU size is usually selected as the optimal CU partition for background or slow-moving regions, while a smaller CU size is usually selected as the optimal CU for regions with complex motion regions. To represent the distribution of optimal CU sizes in VVC inter coding, four video sequences with different motion characteristics are tested, including “MarketPlace” (1920 × 1080), “FourPeople” (1280 × 720), “BasketballDrill” (832 × 480), and “BasketballPass” (416 × 240). Test conditions are shown in
Table 1. To simplify the statistical distribution of different CU sizes, we divide all optimal CU sizes into five non-overlapping categories, L64, L32, L16, L8, and L4, which correspond to the width and height of the CUs that are all greater than or equal to 64, 32, 16, 8, and 4, respectively. For example, an optimal CU with a width of 64 and a height of 32 will be classified as L32. The optimal CU size distributions for video sequences under different QPs are given in
Table 2. From
Table 2 we can observe the following points:
(1) For all video sequences, the average proportions of L64, L32, L16, L8, and L4 are 58.33%, 18.26%, 13.35%, 7.45%, and 2.61%, which indicates that the larger-size CUs are selected as optimal CUs for most regions. Under the same QP, as the CU size decreases, its proportion becomes smaller.
(2) With the increase of QP, the proportion of CUs in the L64 becomes larger, and the proportion of CUs in the L8 and L4 becomes smaller. When QP = 37, the maximum proportion of CU under the L64 is 89.62%, and the minimum proportion is 53.72%. The largest proportions of CUs in the L8 and L4 are only 4.89% and 1.81%. When QP = 22, the maximum proportions of CUs under L8 and L4 are 16.84% and 8.26%. This indicates that different QPs have a significant impact on the optimal CU selection for the same coding regions.
(3) For the sequence “FourPeople” containing large background regions, the proportion of CUs in the L64 exceeds 70.72%, and the proportion of CUs in the L4 is less than 2.15%. For the sequence “BasketballDrill” with complex motion regions, and the sequences “MarketPlace” and “BasketballPass” containing dynamic backgrounds and camera movements, the sum of L64 and L32 is larger. This shows that, for sequences with different motion characteristics, the distribution of the optimal CU size is different, and a larger CU size is usually selected as the optimal CU for background or slow-moving regions.
From the above observations, it can be concluded that, for different video sequences, if the CU partition can be accurately predicted in advance, it will greatly reduce the coding complexity of VVC.
2.2. Temporal Correlation of CUs
Since the content between adjacent frames is very similar, there is a high probability that the corresponding regions between adjacent frames have the same optimal CU partition. To explore the correlation of optimal CU partition between adjacent frames in the same regions,
Figure 2 presents the optimal CU partition for sequences “FourPeople” and “MarketPlace” under RA configuration. In VVC, the largest CU size of 128 × 128 corresponds to a CU depth of 0. As the CU is split into smaller sub-CUs, its corresponding depth is increased by 1.
Figure 2c,f show the absolute difference of CU depth between the 5th and 6th frames. In
Figure 2c,f, the four colors white, blue, green, and red represent the absolute difference of zero, one, two, and three, respectively, and black represents the depth difference greater than or equal to four. We can further observe that most background regions are marked with white or blue, which indicates that the CU depth correlation between adjacent frames is very high.
To analyze the CU depth difference (
) between adjacent frames,
is defined as follows:
where
and
represent the CU depth of the i-th frame and the
i + 1-th frame at the same position. The test sequences include “FourPeople” and “MarketPlace”, and the test conditions are shown in
Table 1.
Table 3,
Table 4 and
Table 5 represent the QTMT depth difference, the QT depth difference, and the MT depth difference of adjacent frames, respectively. It can be seen in
Table 3,
Table 4 and
Table 5 that the average percentages of depth differences of QTMT, QT, and MT that are less than or equal to 1 are 77.5%, 95.1%, and 85.8%, which indicates that the CU depth difference between adjacent frames is very small. Therefore, the CU depth of adjacent coded frames can be used to predict the optimal CU depth of the current coding frame.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}