
Sea-Surface Target Visual Tracking with a Multi-Camera Cooperation Approach

 , ,
, ,  and
and
Abstract
:1. Introduction
1.1. Related Works
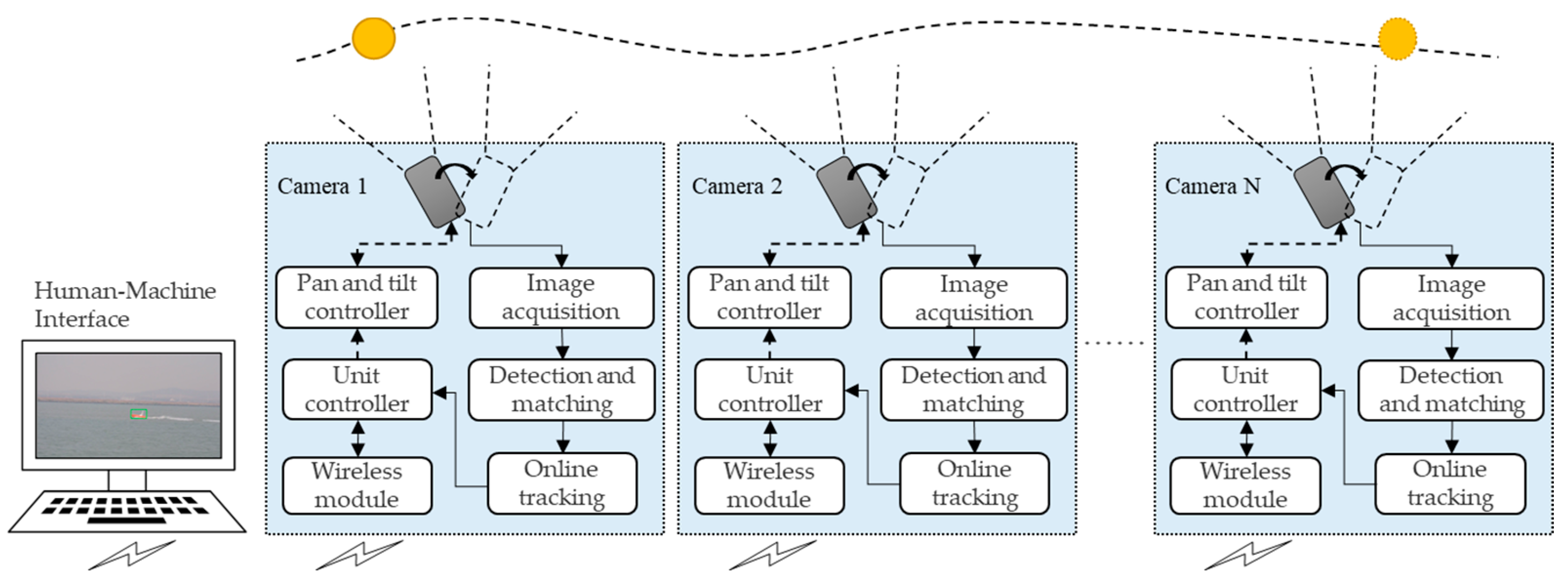
1.2. Multi-Camera Cooperative Moving-Target Visual Tracking System
2. Technologies of Moving-Target Visual Detection, Tracking, and Matching
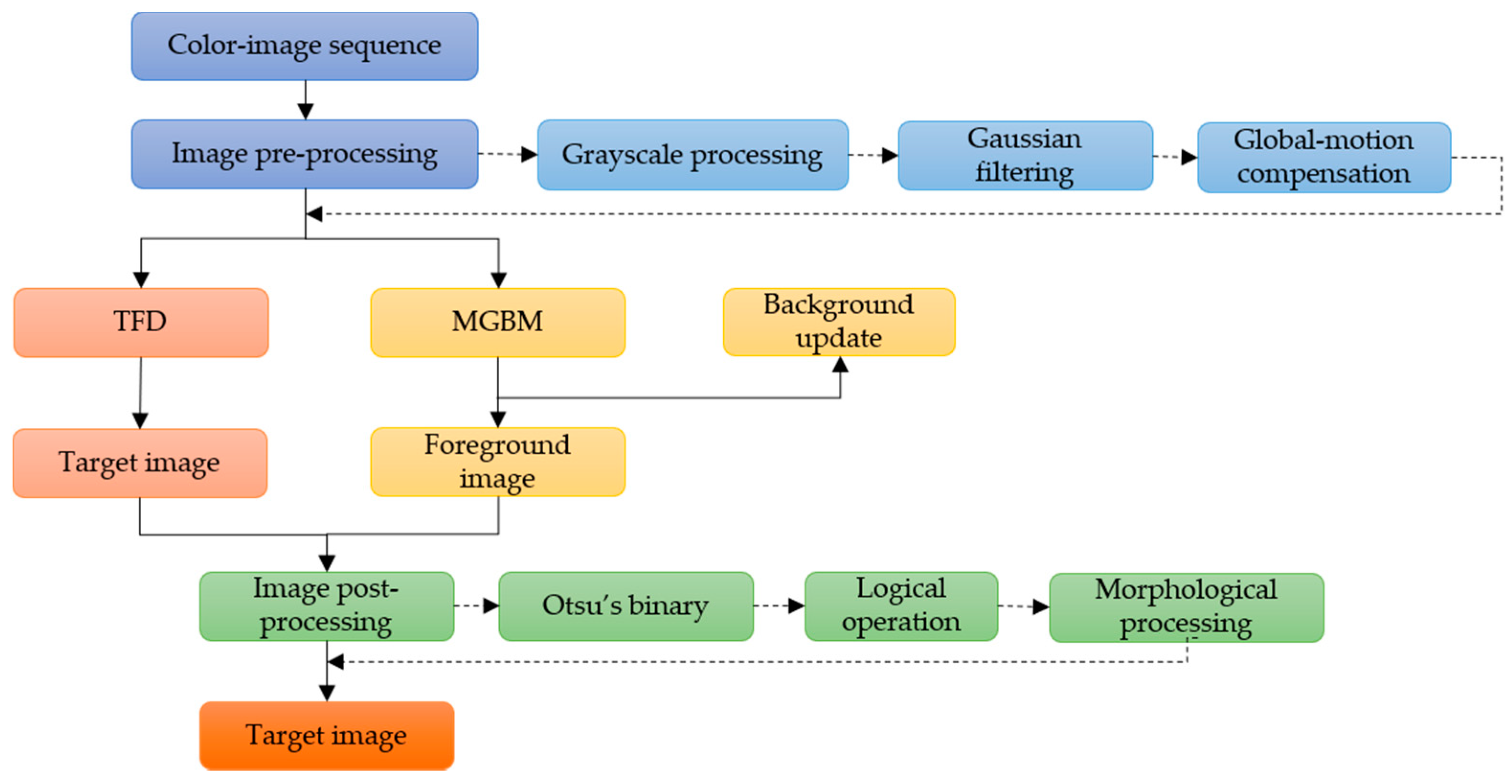
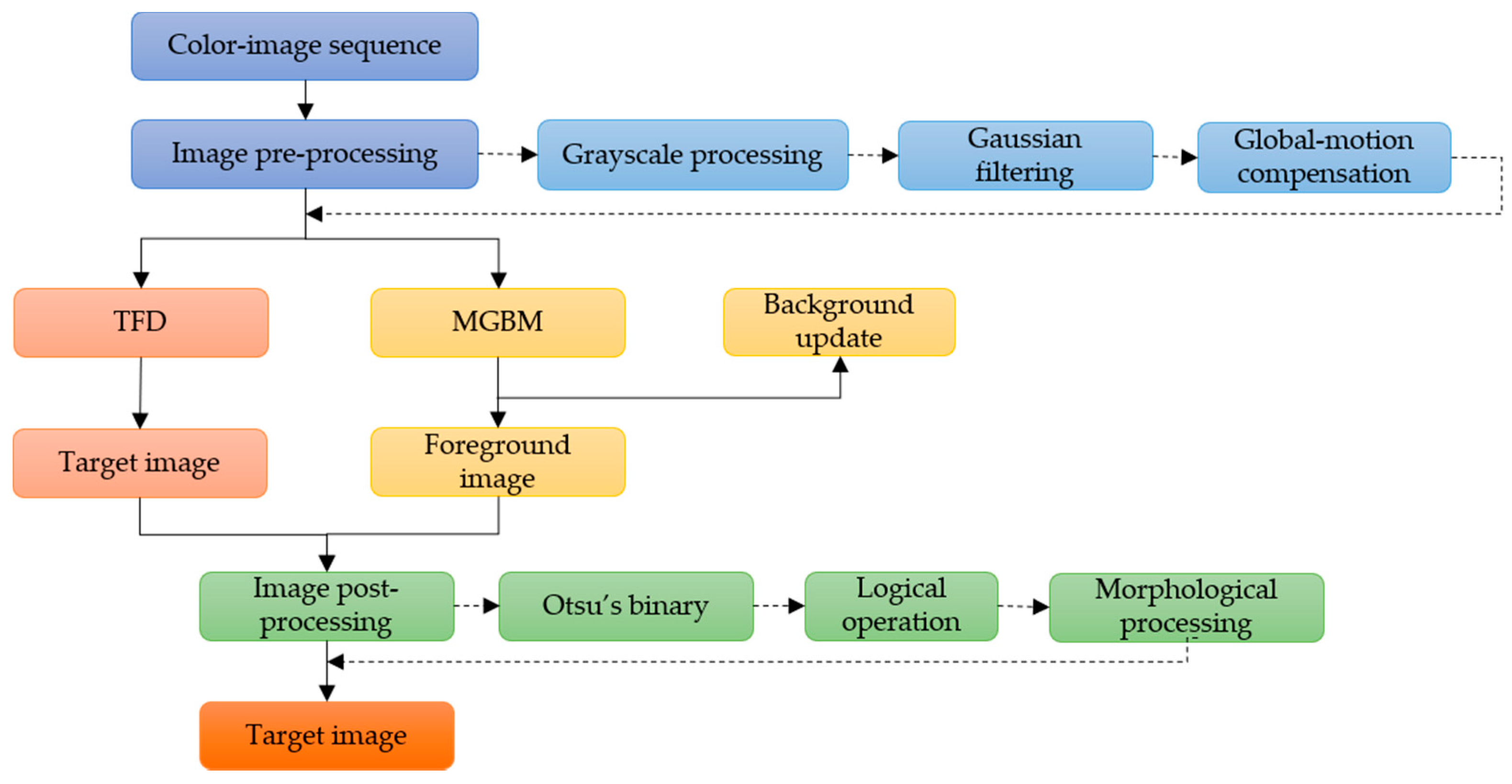
2.1. Moving-Target-Detection Algorithm Based on Mixed Gaussian Background Modeling and Three-Frame Difference Method
- (1).
- The acquired image sequences are preprocessed frame by frame, including graying, filtering, and global-motion compensation. The purpose of this step is to weaken noise, enhance image details, and improve efficiency of effective information extraction.
- (2).
- MGBM and TFD are used for target detection, respectively.
- (3).
- The processed image is binarized, and the mass center of the moving target processed by MGBM is used as the center, and then the logical “and” operation is carried out with the foreground region extracted by TFD. Then, image shape is processed and the final moving-target image is obtained.
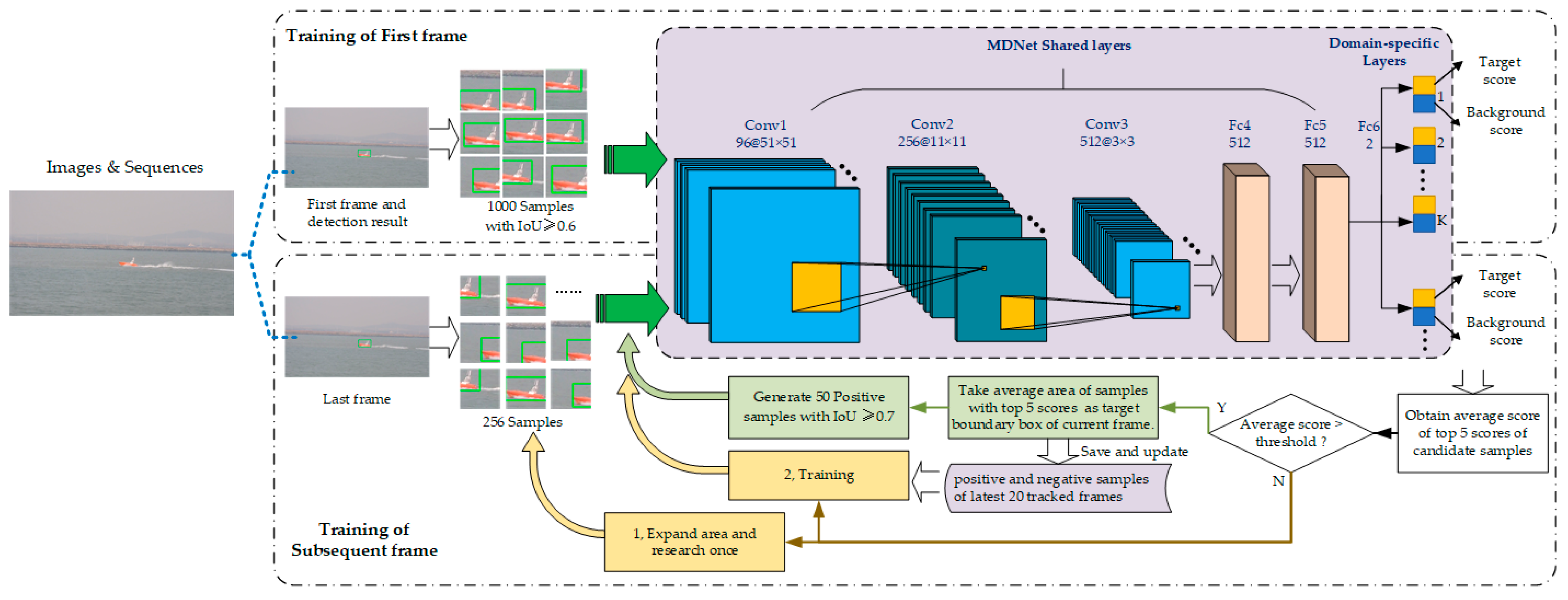
2.2. Moving-Target-Tracking Method Based on MDNet
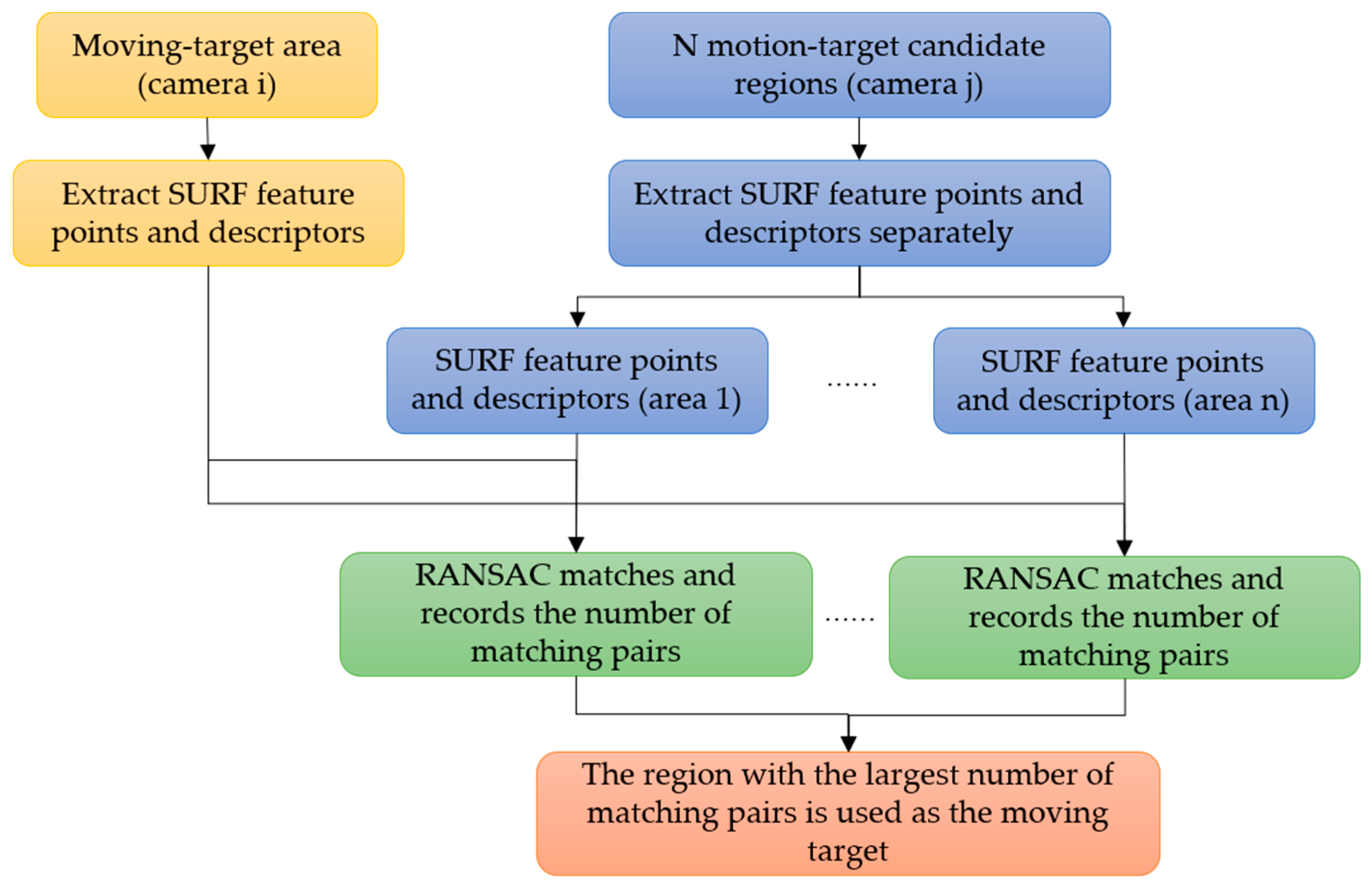
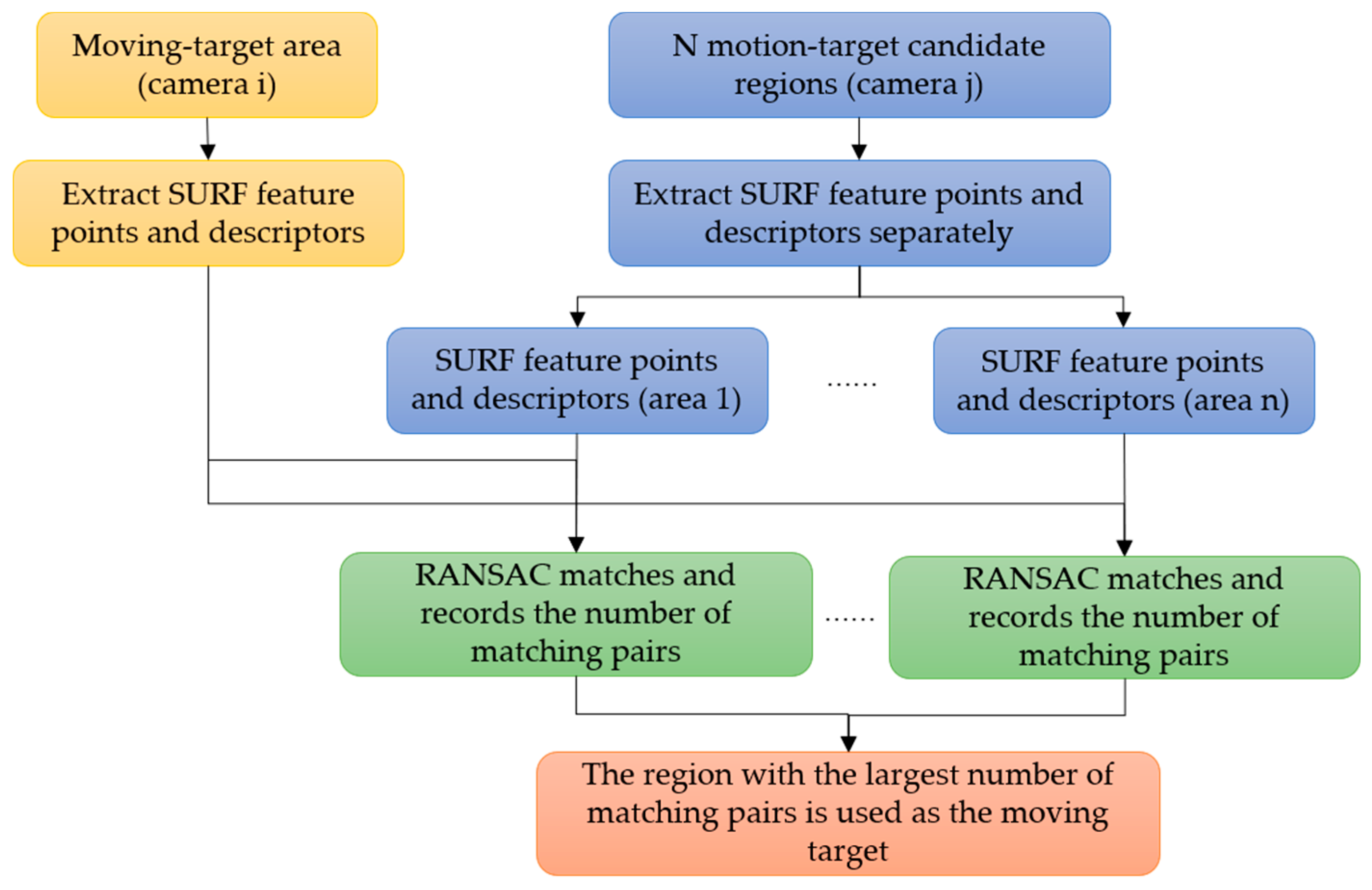
2.3. Moving-Target-Matching Method for a Multi-Camera System
3. Coordination Strategies
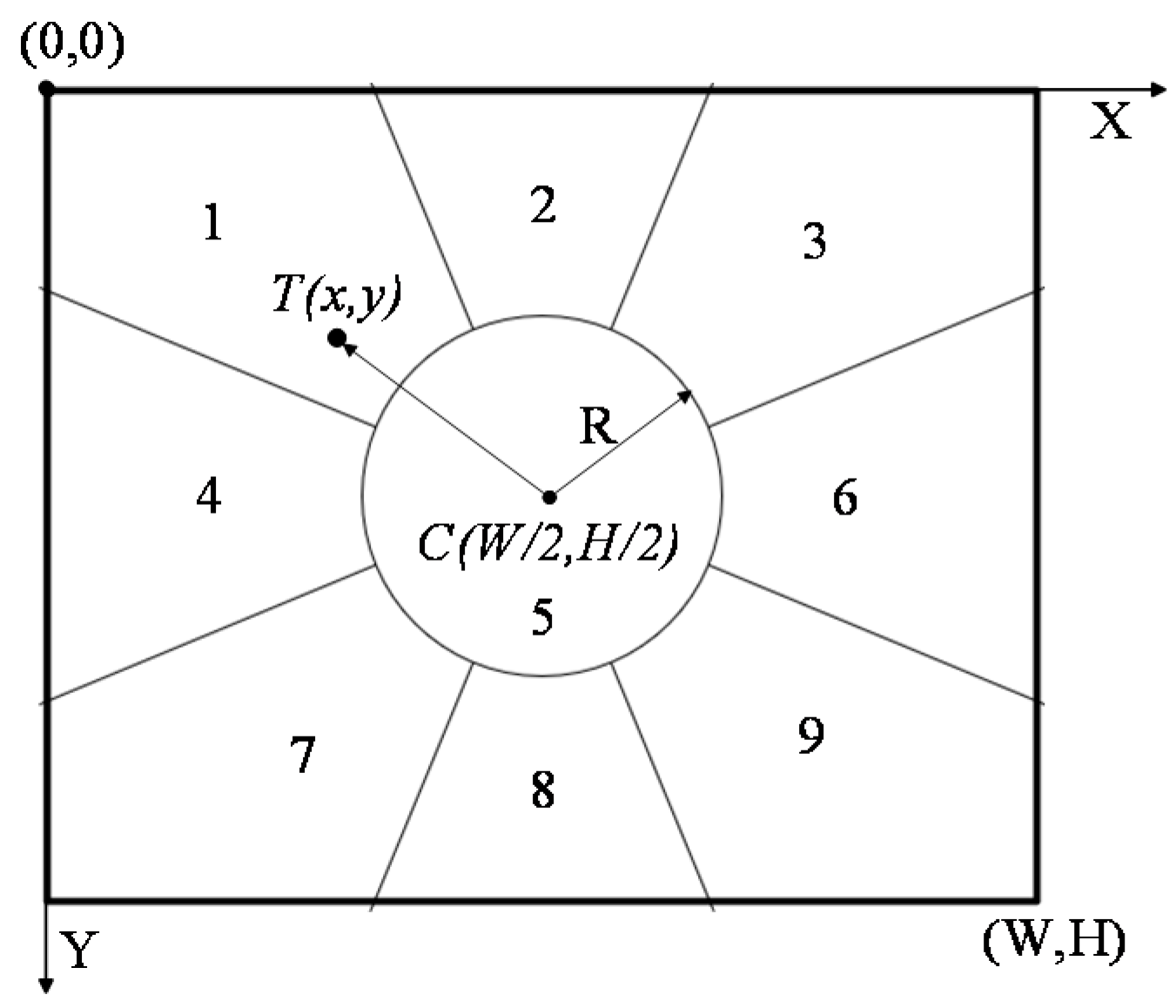
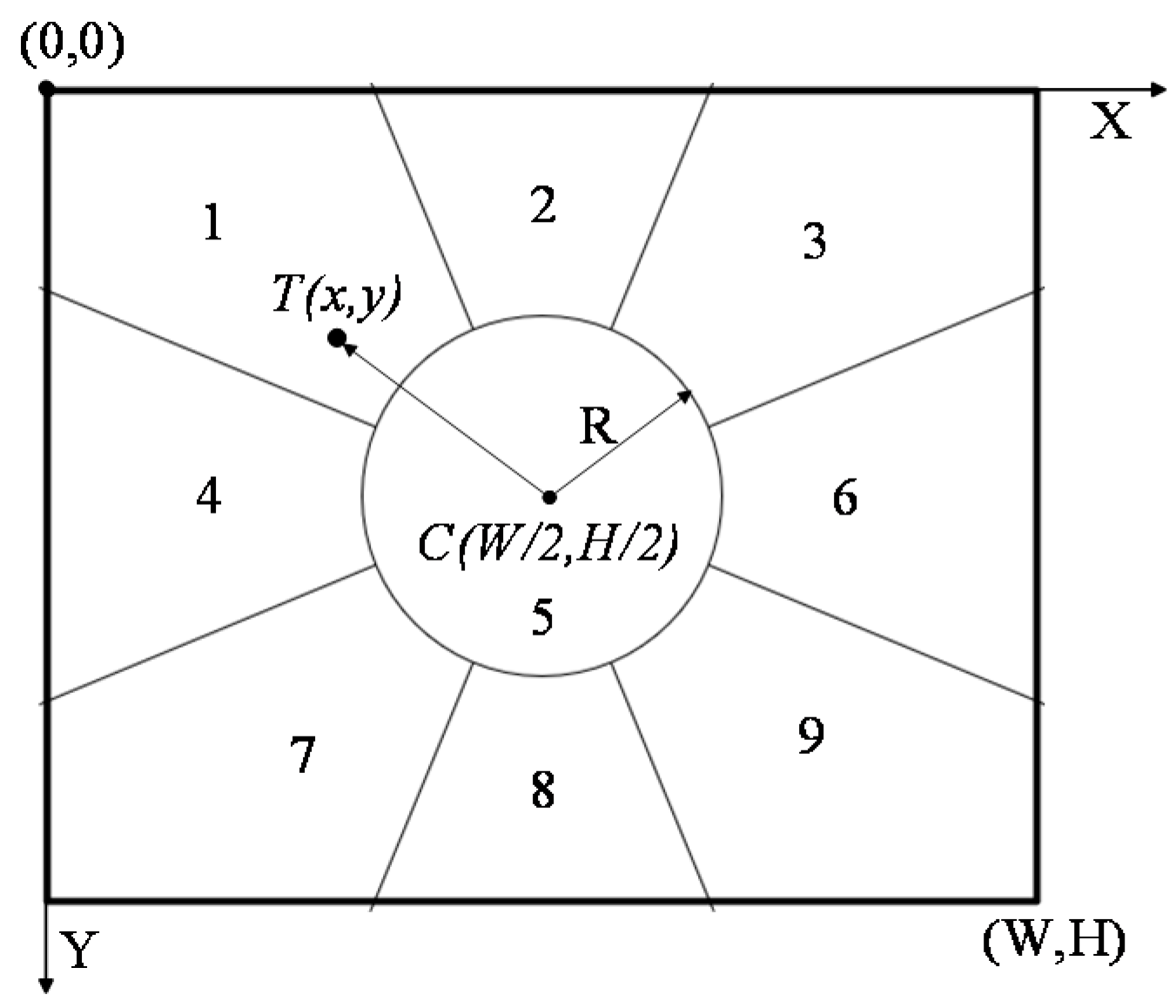
3.1. Pan-and-Tilt Control
- (1).
- Initialize partition of camera view field and set PT rotation speed to 1.
- (2).
- Adaptively adjust control parameters of PT. If the target is not in the central partition of the camera, rotate camera PT according to Table 1. Meanwhile, the position offset of target in two adjacent frames is calculated. According to the obtained offset, the rotation speed of PT is adjusted to keep the motion of the camera and target as consistent as possible, and to keep the target always placed in the center of the field of view.
- (3).
- Correct PT rotation parameters dynamically according to the position offset of the target in two adjacent frames. Calculate r frame by frame. If |r| > R, maintain rotation of PT, and adjust rotation speed in real time according to the rotation result of the next frame until the moving target can be tracked smoothly.
3.2. The MTU Selection
- (1).
- The tracking unit that captures the moving target first is selected as the MTU.
- (2).
- If two or more cameras detect the moving target at the same time, the camera whose current target image is more centered in the window, and target size in the picture is larger than the threshold is chosen, as the MTU.
- (3).
- If the detected targets are all near the center of image of multiple cameras, the camera with a larger size of the target image is chosen as the MTU.
- (4).
- When the center of gravity of the target is out of the view field of the MTU, or half of the target image is outside the MTU view window, or the MTU loses the target, selection of the MTU from the others cameras occurs according to (1)–(3).
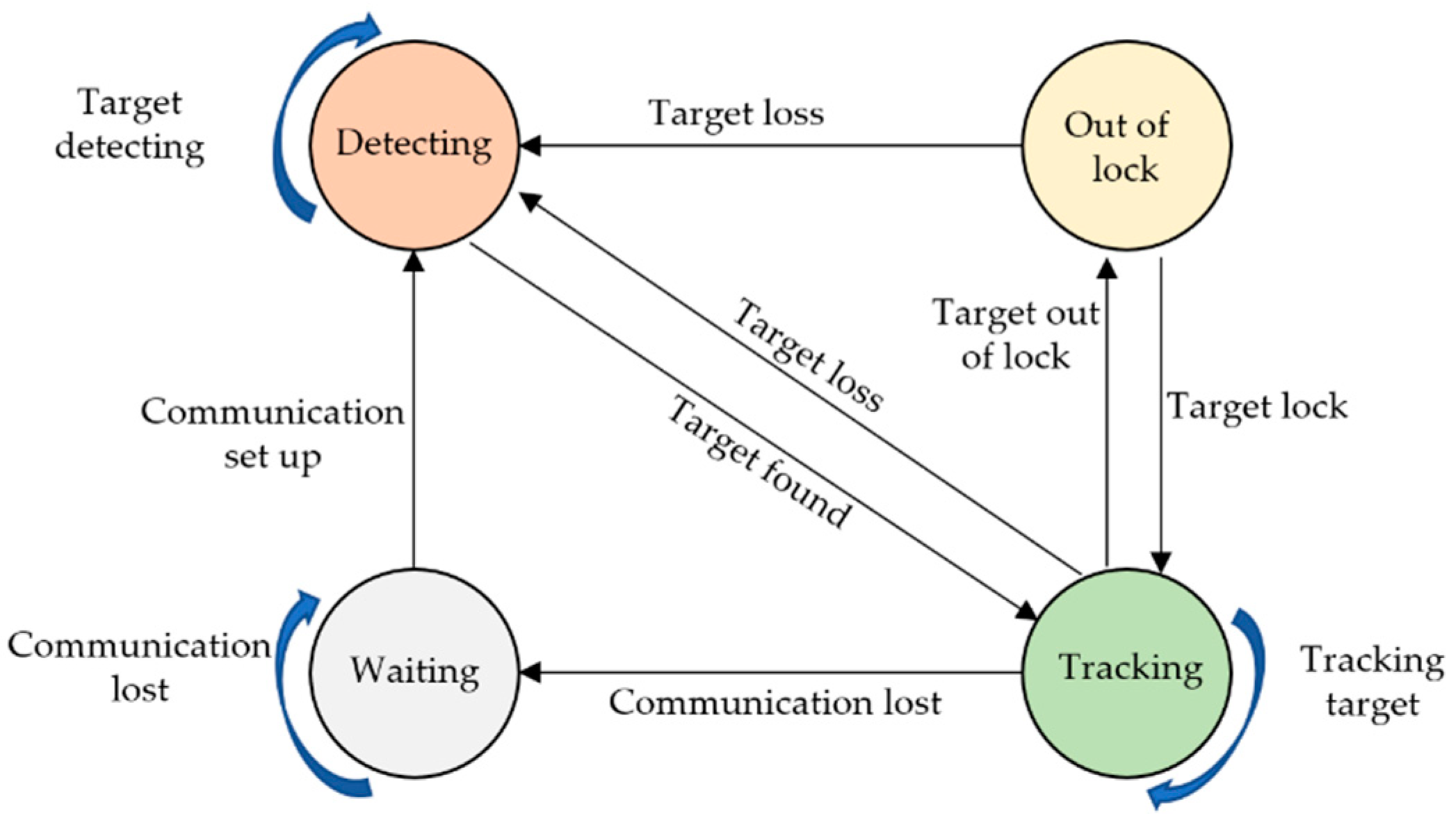
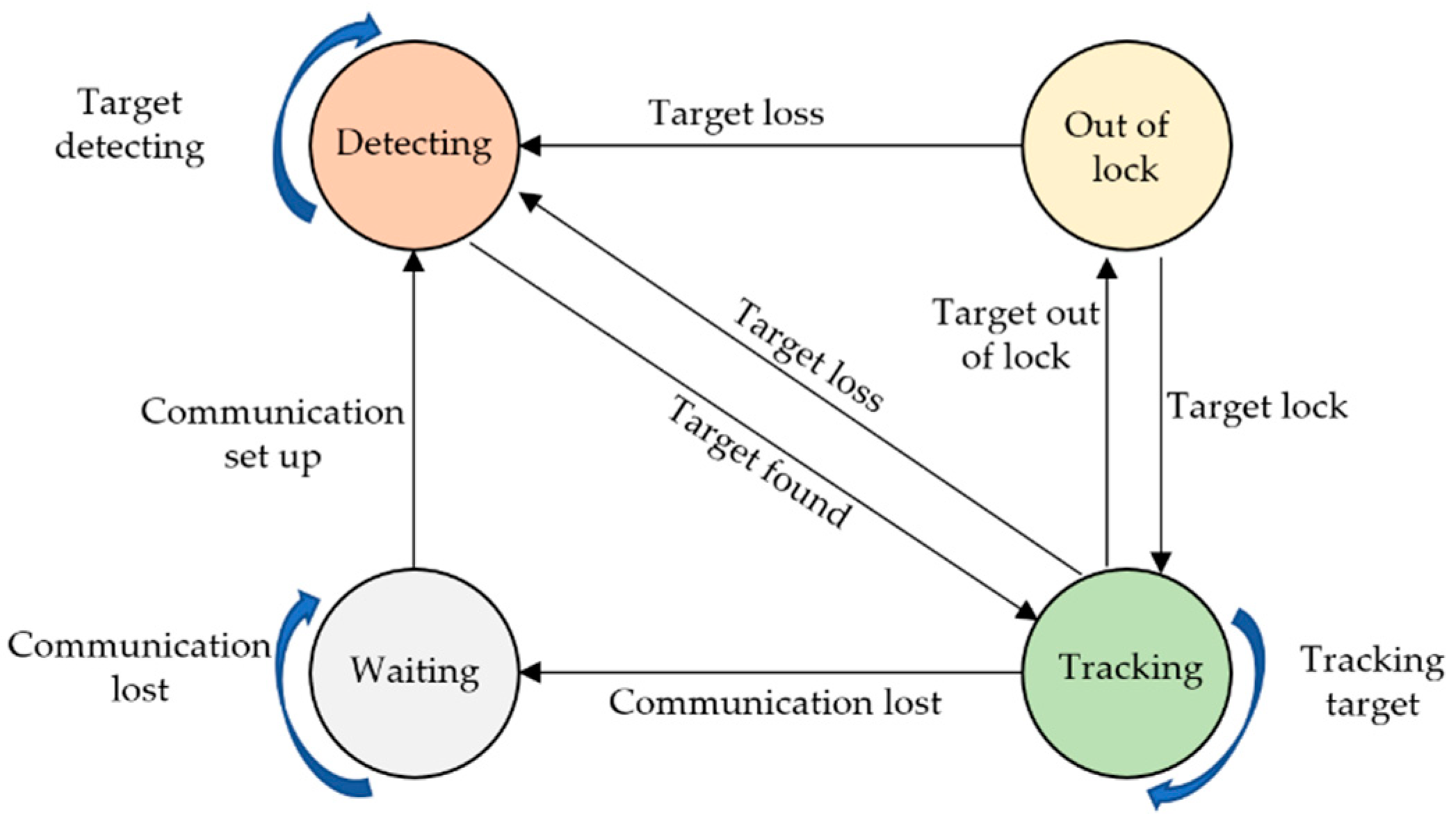
3.3. Unit Behavior-State Model
- (1).
- Waiting state. When a tracking unit loses communication with the host controller or computer, the unit will be in this state. Once communication is set up, the unit will change to detecting state.
- (2).
- Detecting state. In this state, the target is out of the range of view of the unit, so the target will be detected by using shared information from other units, meanwhile adjusting the PT of the camera under control of the host. Once the target is detected and matched, the unit will change to tracking state.
- (3).
- Tracking status. In this state, the moving target will be tracked continuously by adjusting the PT of the camera using the control strategy in Section 3.1. If the target is out of lock temporarily, while the target is still in the field of view of camera, the unit will change to the state of out of lock. If the target is out of viewing field, the unit will switch to detecting state.
- (4).
- Out-of-lock state. In this state, the target is out of lock, the camera will stop rotating and begin to search for a moving target in the field of view. If the target is relocked, the unit will revert to tracking state, otherwise switching to detecting state.
3.4. Cooperative Tracking Strategy
- (1).
- Pose relation of tracking beginning. As shown in Figure 7a, the system begins to detect the target, and the target is tracked by no more than one unit. The first unit finding the target acts as the MTU. Other units in detecting state control and rotate PT to detect and match the target from the view field of the MTU to save detecting time.
- (2).
- Pose relation of partial cooperation. As shown in Figure 7b, there are at least two units tracking the target, and they are in partial-cooperation pose relation, and the axes of view of cameras have at least one intersection point near the target. By calculating and sharing the position information of these intersection points, the units in detecting state or in out-of-lock state will be guided to find the target more quickly.
- (3).
- Pose relation of full cooperation. All units cooperate to track the target and their view field is superimposed. In this pose relation, the position of the target could be estimated by calculating the average value of the intersection points of view axes of cameras, as green points and circles show in Figure 7c.
4. Experiment Results
4.1. Target-Detection Experiments
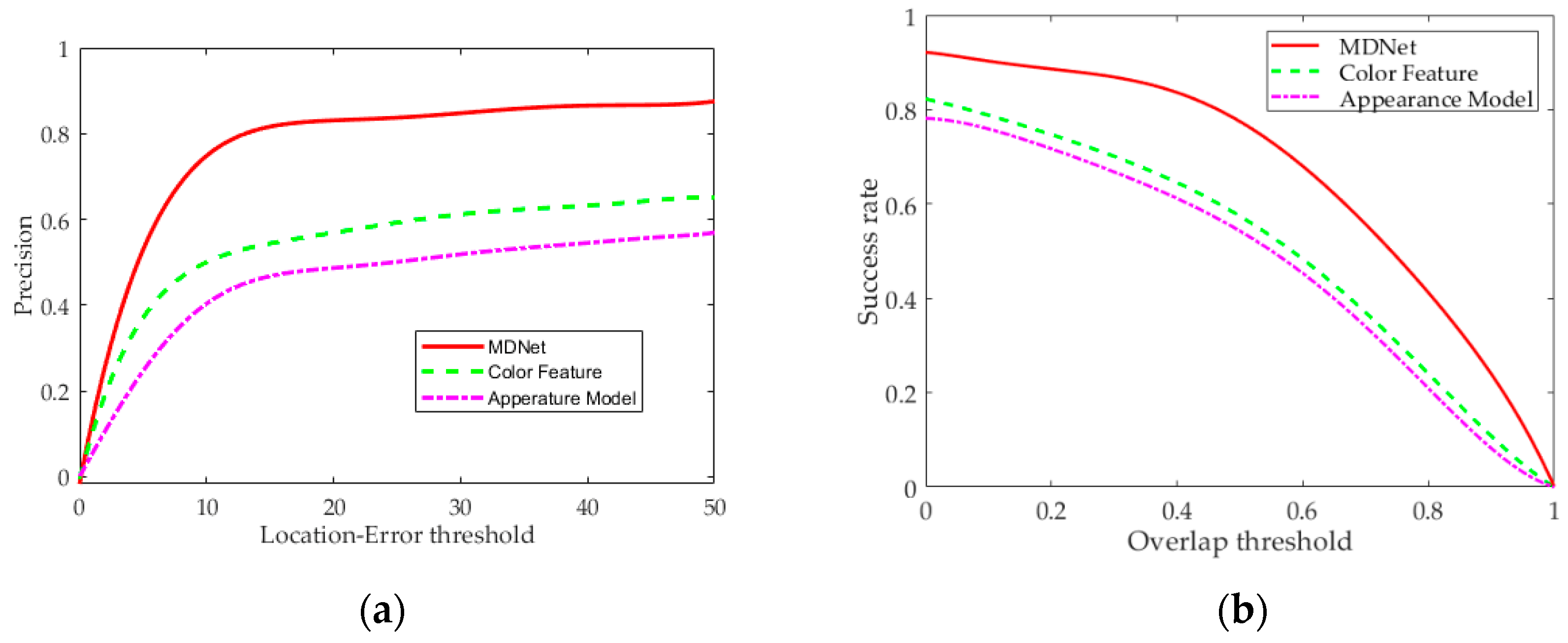
4.2. Target-Tracking Experiments
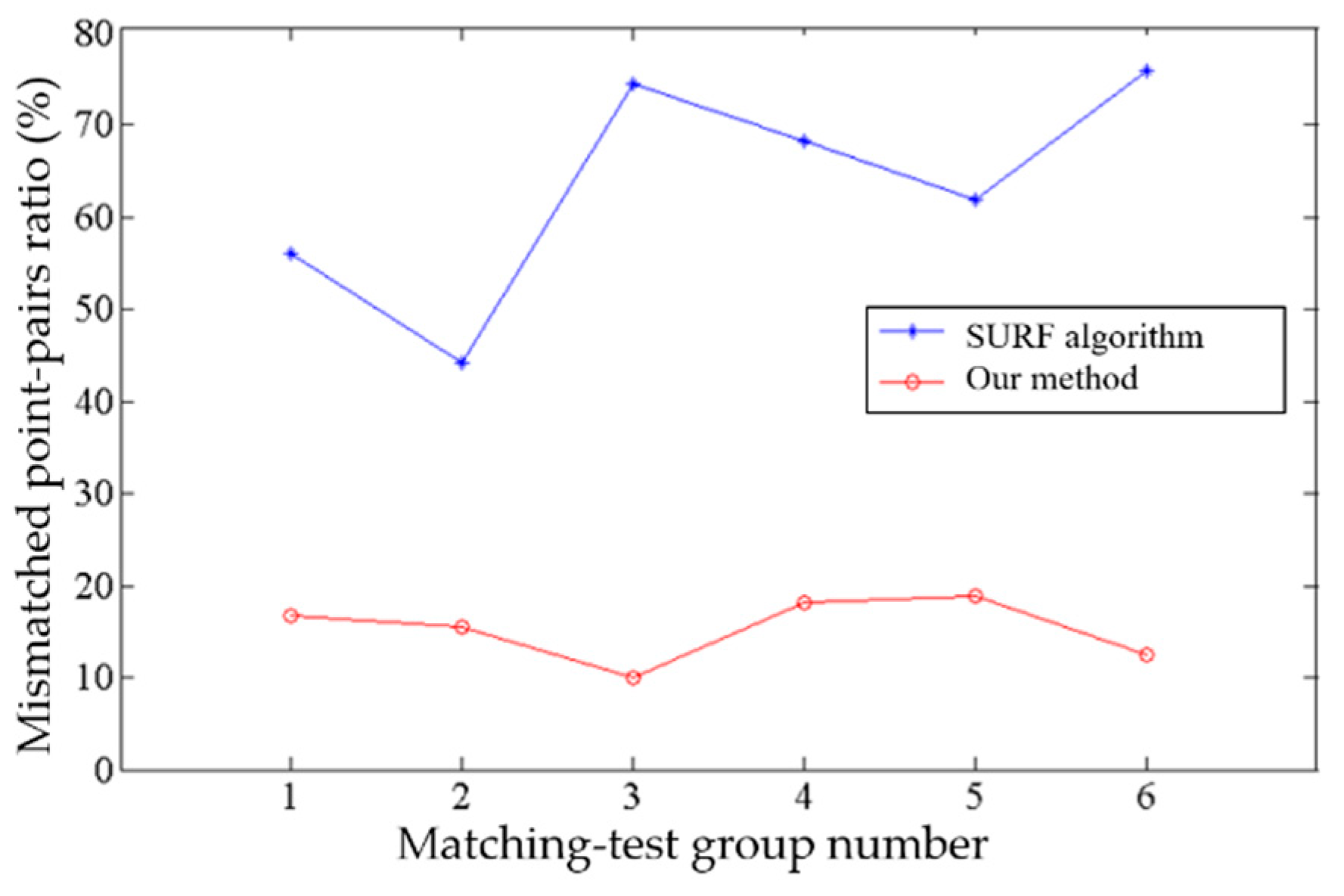
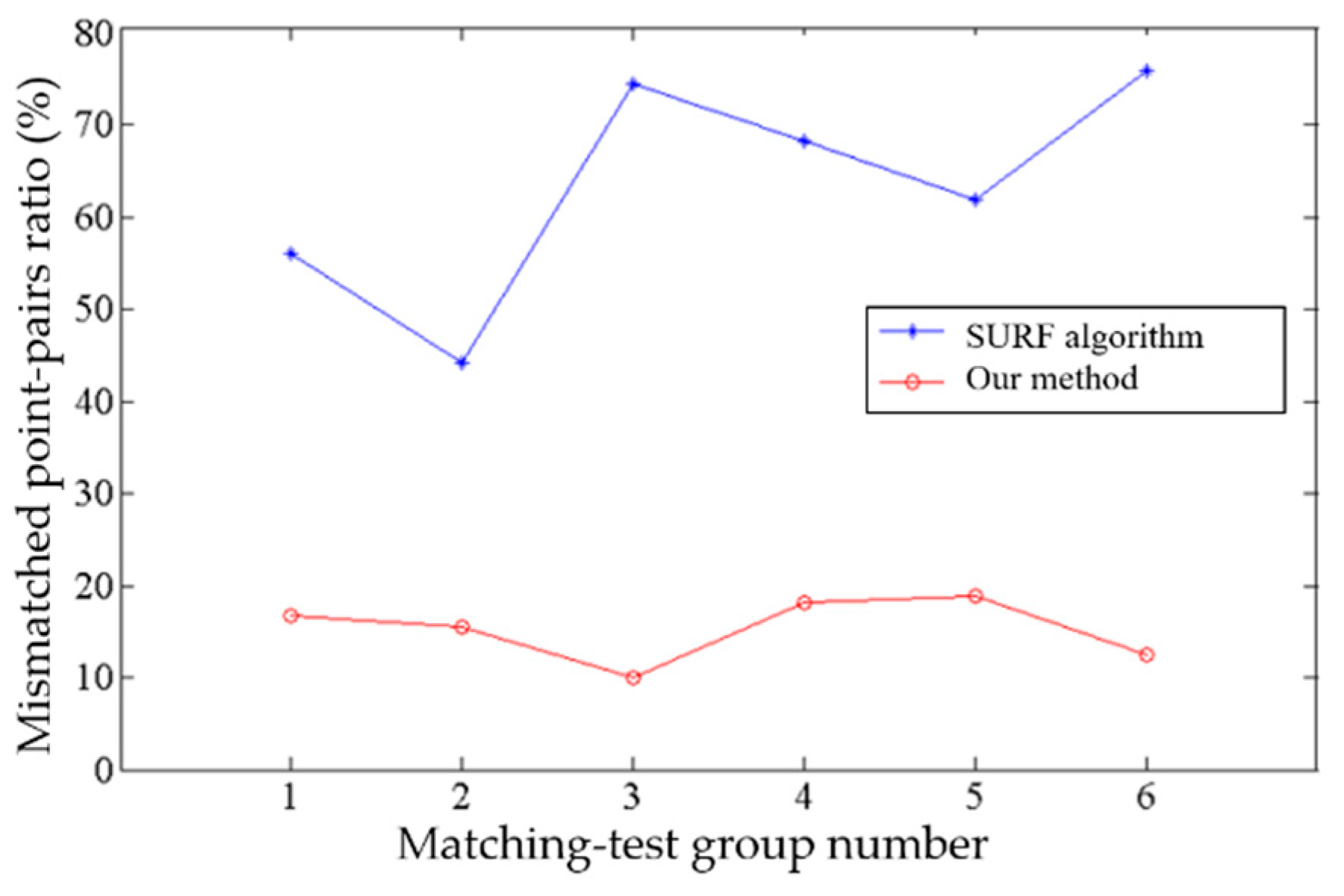
4.3. Target-Matching Experiments
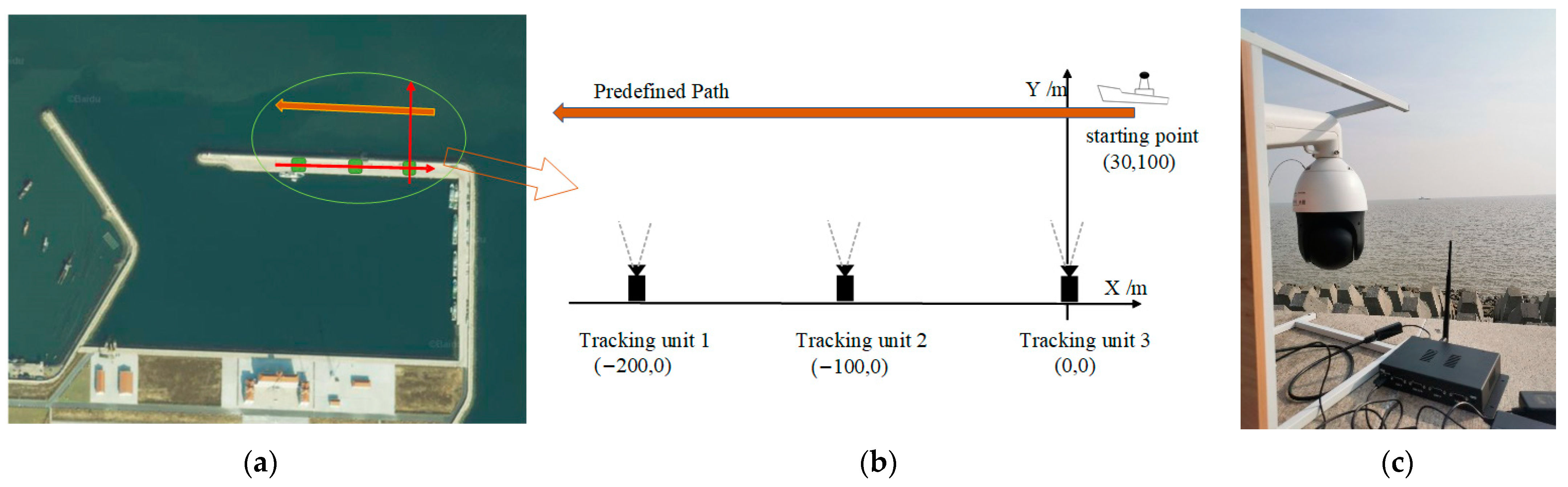
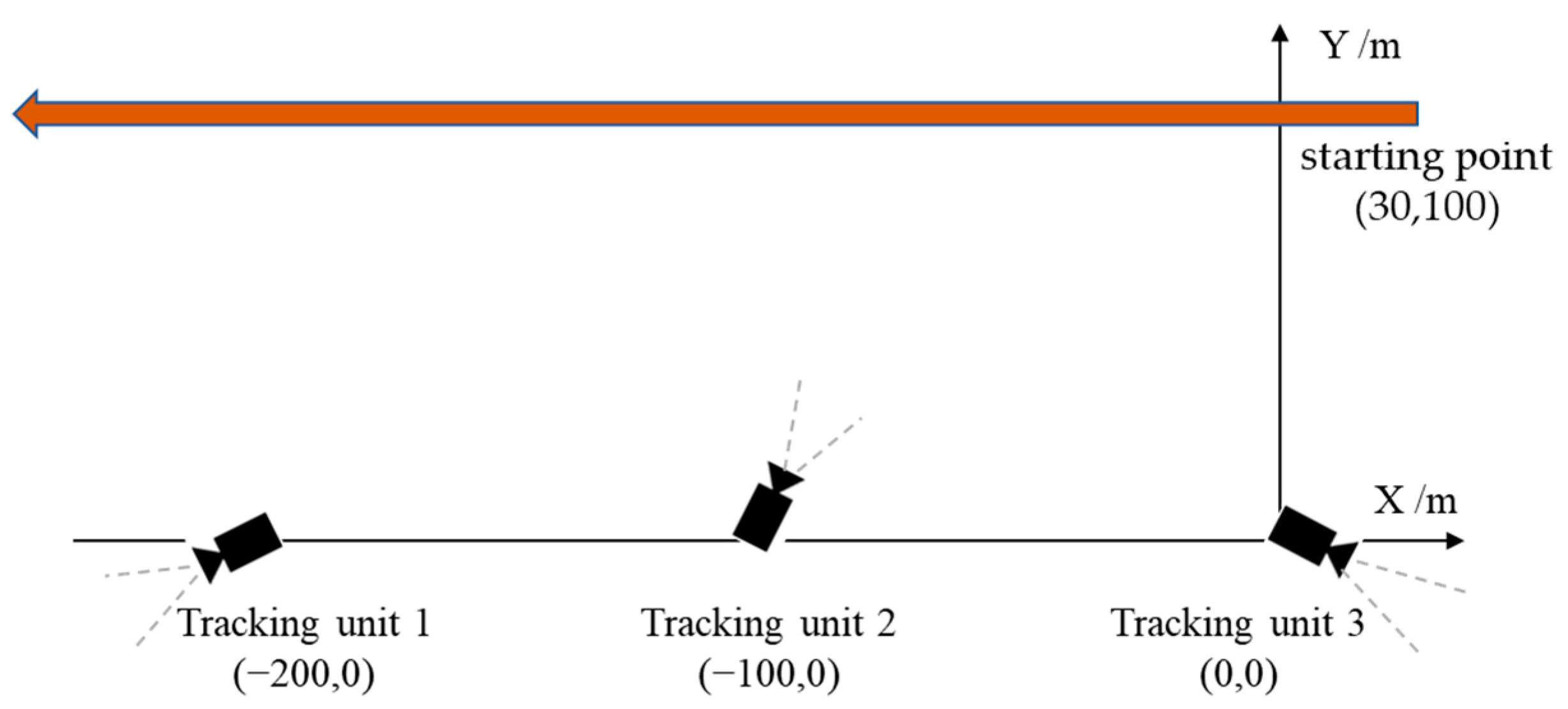
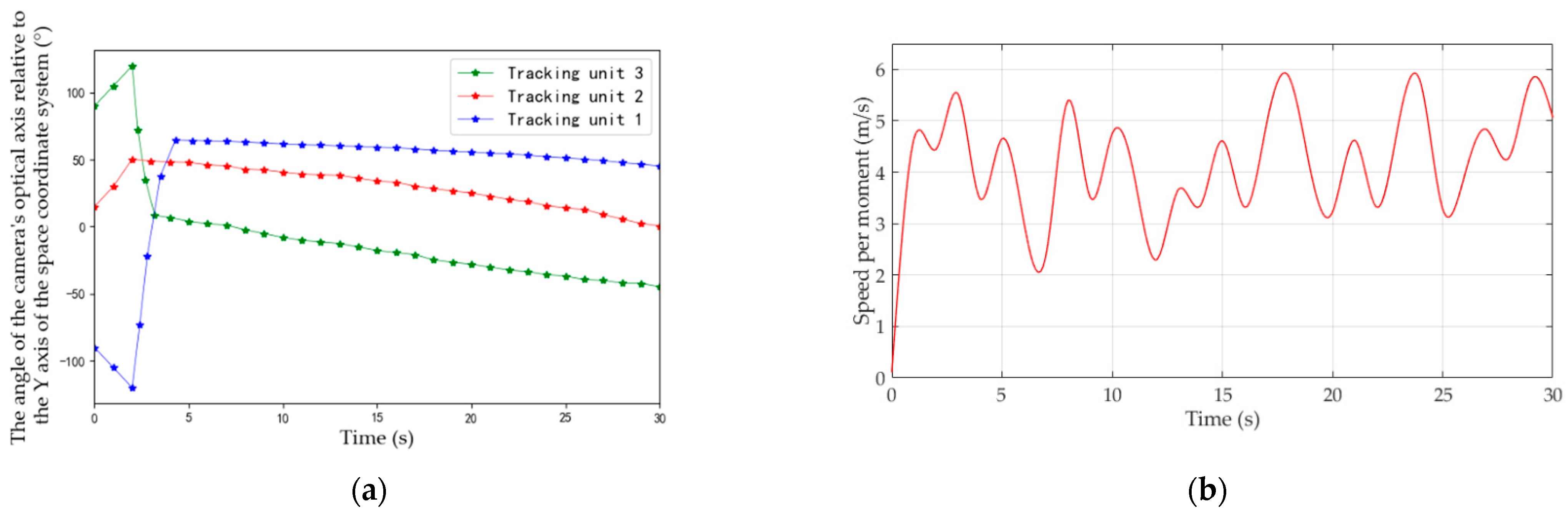
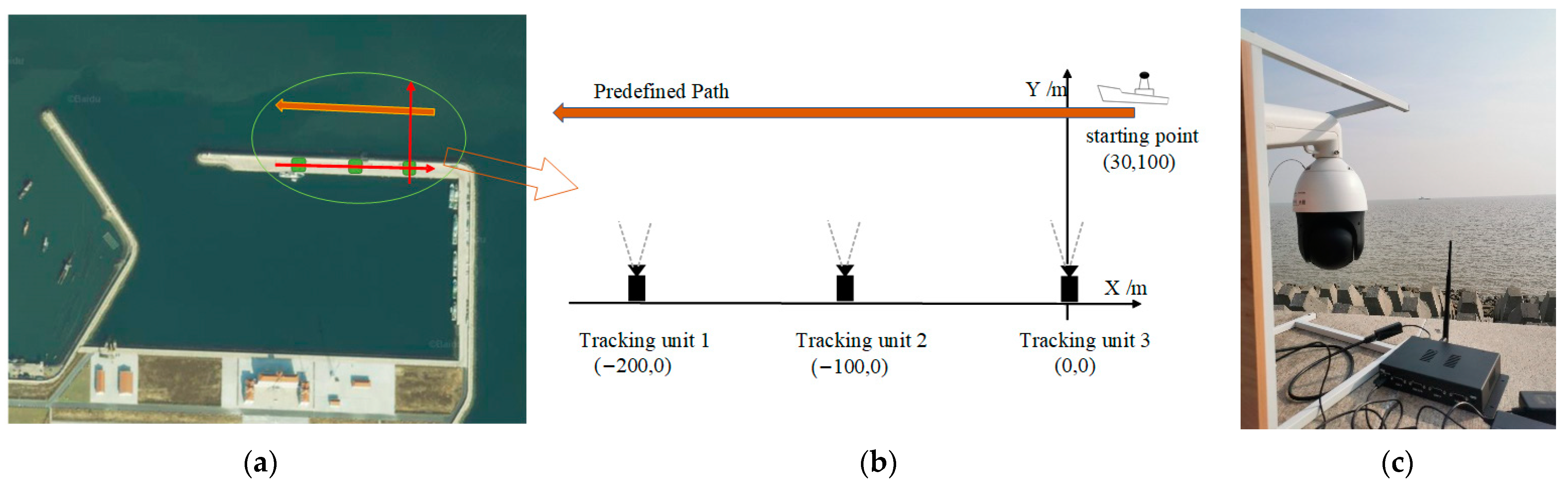
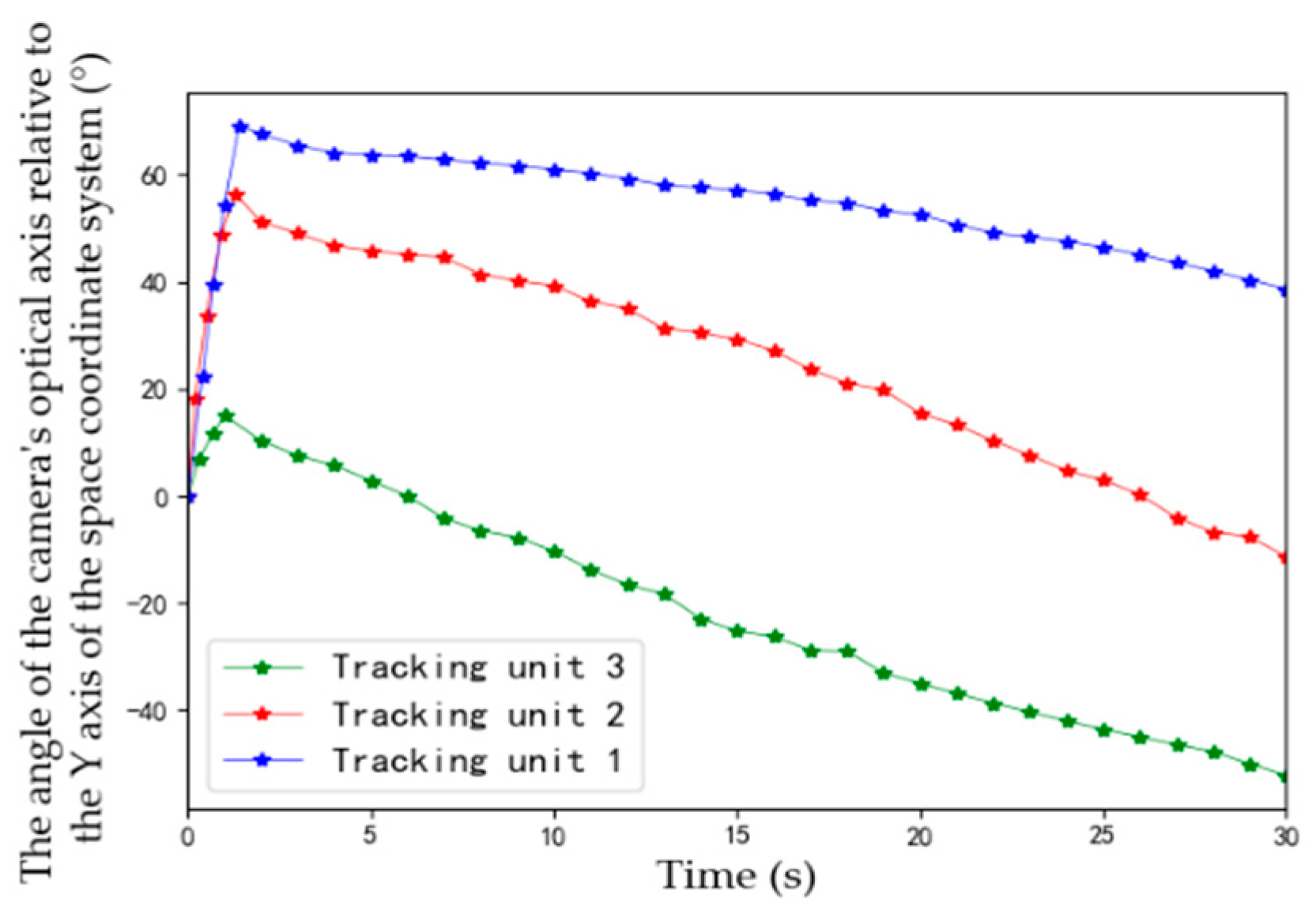
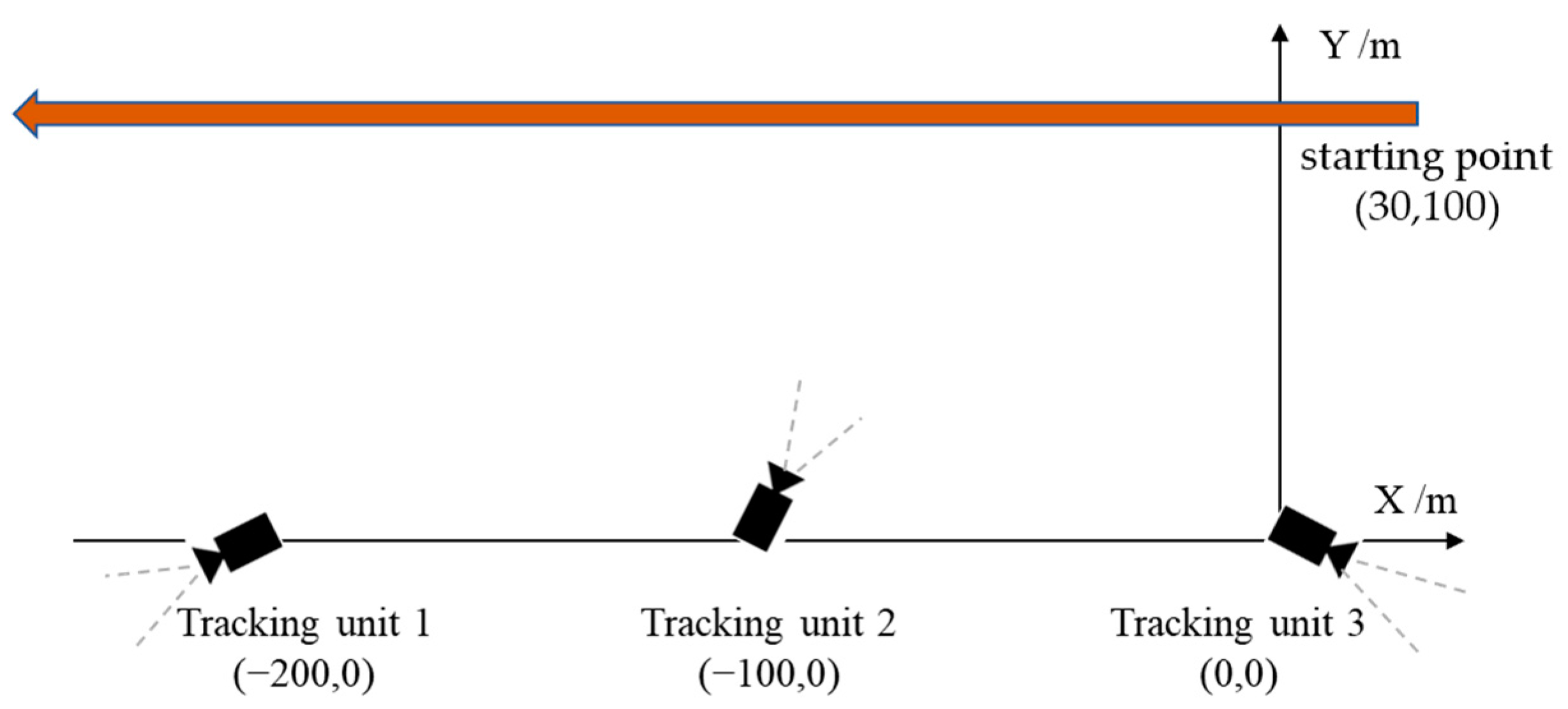
4.4. Field Experiments
5. Conclusions and Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yin, H.P.; Chen, B.; Chai, Y.; Liu, Z. Overview of vision based target detection and tracking. Acta Autom. Sin. 2016, 42, 1466–1489. [Google Scholar]
- Xiao, S.; Liu, S.; Song, M.M.; Nie, A.; Zhang, H.L. Coupling rub-impact dynamics of double translational joints with subsidence for time-varying load in a planar mechanical system. Multibody Syst. Dyn. 2020, 48, 451–486. [Google Scholar] [CrossRef]
- Yan, R.J.; Pang, S.; Sun, H.B.; Pang, Y.J. Development and missions of unmanned surface vehicle. J. Mar. Sci. Appl. 2010, 9, 451–457. [Google Scholar] [CrossRef]
- Jorge, N.C.; Frías-Velázquez, A.; Bo, N.B.; Slembrouck, M.; Guan, J.; Debard, G.; Vanrumste, B.; Tuytelaars, T.; Philips, W. Scalable semi-automatic annotation for multi-camera person tracking. IEEE Trans. Image Process. 2016, 25, 2259–2274. [Google Scholar]
- He, L.; Liu, G.L.; Tian, G.H.; Zhang, J.H.; Ji, Z. Efficient multi-view multi-target tracking using a distributed camera network. IEEE Sens. J. 2019, 20, 2056–2063. [Google Scholar] [CrossRef]
- Bozorgtabar, B.; Roland, G. Msmct: Multi-state multi-camera tracker. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3361–3376. [Google Scholar] [CrossRef]
- Yan, M.; Zhao, Y.J.; Liu, M.; Kong, L.Q.; Dong, L.Q. High-speed moving target tracking of multi-camera system with overlapped field of view. Signal Image Video Process. 2021, 15, 1369–1377. [Google Scholar] [CrossRef]
- Khan, S.M.; Mubarak, S. Tracking multiple occluding people by localizing on multiple scene planes. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 505–519. [Google Scholar] [CrossRef]
- Yan, W.J.; Wang, J.G.; Liu, Y. Application of Multiple Model Particle Filter in Maneuvering Target Tracking. Electron. Opt. Control 2012, 19, 18–21. [Google Scholar]
- Ighrayene, M.; Gao, Q.; Tarek, B. Making bayesian tracking and matching by the brisk interest points detector/descriptor cooperate for robust object tracking. In Proceedings of the 2016 IEEE International Conference on Signal and Image Processing (ICSIP), Beijing, China, 13–15 August 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Zheng, Y.; Xu, T.; Xu, D.; Yang, T.T.; Li, X. Coordinating Multiple Cameras to Assist Tracking Moving Objects Based on Network Topological Structure. Geomat. Inf. Sci. Wuhan Univ. 2017, 42, 1117–1122. [Google Scholar]
- Wang, T.; Zeng, J.D.; Bhuiyan, M.Z.; Chen, Y.H.; Cai, Y.Q.; Tian, H.; Xie, M. Energy-efficient relay tracking with multiple mobile camera sensors. Comput. Netw. 2018, 133, 130–140. [Google Scholar] [CrossRef]
- Zhang, G.F.; Tian, Z.R.; Liao, Y.L.; Wang, S.; Chen, W.T. Application of Multi-Camera Tracking and Positioning Technology in Substation. In Proceedings of the 2019 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Macao, China, 1–4 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- You, S.S.; Yao, H.T.; Xu, C.S. Multi-Target Multi-Camera Tracking with Optical-based Pose Association. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3105–3117. [Google Scholar] [CrossRef]
- Neehar, P.; Pirazh, K.; Rambhatla, S.S.; Vineet, S.; Saumya, R.; Chen, J.C.; Rama, C. Towards real-time systems for vehicle re-identification, multi-camera tracking, and anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Srigrarom, S.; Sie, N.J.L.; Cheng, H.; Chew, K.H.; Lee, M.; Ratsamee, P. Multi-camera Multi-drone Detection, Tracking and Localization with Trajectory-based Re-identification. In Proceedings of the 2021 Second International Symposium on Instrumentation, Control, Artificial Intelligence, and Robotics (ICA-SYMP), Bangkok, Thailand, 20–22 January 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Gao, F.; Lu, Y.G. Moving Target Detection Using Inter-Frame Difference Methods Combined with Texture Features and Lab Color Space. In Proceedings of the 2019 International Conference on Artificial Intelligence and Advanced Manufacturing (AIAM), Dublin, Ireland, 16–18 October 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Zhang, H.Y.; Wu, K. A vehicle detection algorithm based on three-frame differencing and background subtraction. In Proceedings of the 2012 Fifth International Symposium on Computational Intelligence and Design, Hangzhou, China, 28–29 October 2012; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; IEEE: Piscataway, NJ, USA, 1999. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Learning patterns of activity using real-time tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 747–757. [Google Scholar] [CrossRef] [Green Version]
- Sharma, R.D.; Agrwal, S.L.; Gupta, S.K.; Prajapati, A. Optimized dynamic background subtraction technique for moving object detection and tracking. In Proceedings of the 2017 2nd International Conference on Telecommunication and Networks (TEL-NET), Noida, India, 10–11 August 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Li, J.; Pan, Z.M.; Zhang, Z.H.; Zhang, H. Dynamic ARMA-Based Background Subtraction for Moving Objects Detection. IEEE Access 2019, 7, 128659–128668. [Google Scholar] [CrossRef]
- Sun, P.Y.; Lv, L.R.; Qin, J.; Lin, L.H. Moving Target Detection based on Multi-feature Adaptive Background Model. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Guan, Y.S.; Wang, Y. Joint Detection and Tracking Scheme for Target Tracking in Moving Platform. In Proceedings of the 2020 IEEE Radar Conference (RadarConf20), Florence, Italy, 21–25 September 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Gui, Q.A.; Xia, Y.J. Kalman Filter Algorithm for Sports Video Moving Target Tracking. In Proceedings of the 2020 International Conference on Advance in Ambient Computing and Intelligence (ICAACI), Ottawa, ON, Canada, 12–13 September 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- He, A.F.; Luo, C.; Tian, X.M.; Zeng, W.J. A twofold siamese network for real-time object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ondruska, P.; Posner, I. Deep tracking: Seeing beyond seeing using recurrent neural networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, N.Y.; Li, S.Y.; Gupta, A.; Yeung, D.Y. Transferring rich feature hierarchies for robust visual tracking. arXiv 2015, arXiv:1501.04587. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Danelljan, M.; Bhat, G.; Shahbaz, K.F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yuan, Y.; Emmanuel, S.; Lin, W.; Fang, Y. Visual object tracking based on appearance model selection. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), San Jose, CA, USA, 15–19 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–4. [Google Scholar]
- Tang, Z.; Hwang, J.N. Moana: An online learned adaptive appearance model for robust multiple object tracking in 3d. IEEE Access 2019, 7, 31934–31945. [Google Scholar] [CrossRef]
- Jiang, Q.; Liu, M.; Fu, X.; Shang, Y.; Ding, H. Pedestrian Tracking Based on HSV Color Features and Reconstruction by Contributions. In Proceedings of the 2018 5th International Conference on Information, Cybernetics, and Computational Social Systems (ICCSS), Hangzhou, China, 16–19 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7–12. [Google Scholar]
- Qi, Y.; Wang, Y.; Liu, Y. Object tracking based on deep CNN feature and color feature. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 469–473. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, B.; Yan, J.J.; Wu, W.; Zhu, Z.; Hu, X.L. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bhat, G.; Danelljan, M.; Van, L.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Ruan, J.X.; Xie, L.Y.; Ruan, Y.Y.; Liu, L.D.; Chen, Q.; Zhang, Q. Image stitching algorithm based on SURF and wavelet transform. In Proceedings of the 2018 7th International Conference on Digital Home (ICDH), Guilin, China, 30 November–1 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Zhao, W.L.; Ngo, C.W. Flip-invariant SIFT for copy and object detection. IEEE Trans. Image Process. 2012, 22, 980–991. [Google Scholar] [CrossRef]
- Fu, W.P.; Qin, C.; Liu, J.; Yang, S.Q.; Wang, W. Matching and location of image object based on SIFT algorithm. Chin. J. Sci. Instrum. 2011, 32, 163–169. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Namiki, A. Target tracking of moving and rotating object by high-speed monocular active vision. IEEE Sens. J. 2020, 20, 6727–6744. [Google Scholar] [CrossRef]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kumari, P.; Nandyala, N.; Teja, A.K.S.; Goel, N.; Saini, M. Dynamic Scheduling of an Autonomous PTZ Camera for Effective Surveillance. In Proceedings of the 2020 IEEE 17th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Delhi, India, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Jing, L.; Xu, J.; Zhong, F.W.; Kong, X.Y.; Qiao, Y.; Wang, Y.Z. Pose-assisted multi-camera collaboration for active object tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 759–766. [Google Scholar]
- Ding, Z.L.; Huang, T.J.; Lu, Z.Q. Learning individually inferred communication for multi-agent cooperation. arXiv 2020, arXiv:2006.06455. [Google Scholar]
- Zheng, J.; Lu, C.; Hao, C.; Chen, D.M.; Guo, D.H. Improving the Generalization Ability of Deep Neural Networks for Cross-Domain Visual Recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 13, 607–620. [Google Scholar] [CrossRef]
- Hao, C.; Chen, D.M. Software/Hardware Co-design for Multi-modal Multi-task Learning in Autonomous Systems. In Proceedings of the IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Area | Range of Target Location | Pan-and-Tilt Direction |
|---|---|---|
| 1 | |r| ≥ R, | Upper left |
| 2 | |r| ≥ R, | Upper |
| 3 | |r| ≥ R, | Upper right |
| 4 | |r| ≥ R, | Left |
| 5 | |r| < R | Stop |
| 6 | |r| ≥ R,/8] | Right |
| 7 | |r| ≥ R, | Lower left |
| 8 | |r| ≥ R, | Lower |
| 9 | |r| ≥ R, | Lower right |
| Algorithms | Average IoU (%) | Average Recognition Rate (%) | Average False-Detection Rate (%) |
|---|---|---|---|
| TFD | 32.68 | 54.17 | 23.49 |
| MGBM | 47.19 | 62.35 | 15.29 |
| Our algorithm | 67.52 | 78.61 | 7.32 |
| Unit 1 | Unit 2 | Unit 3 | |
|---|---|---|---|
| The number of frames correctly tracked | 94 | 100 | 11 |
| The number of frames in which the target appears | 100 | 100 | 19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rao, J.; Xu, K.; Chen, J.; Lei, J.; Zhang, Z.; Zhang, Q.; Giernacki, W.; Liu, M. Sea-Surface Target Visual Tracking with a Multi-Camera Cooperation Approach. Sensors 2022, 22, 693. https://doi.org/10.3390/s22020693
Rao J, Xu K, Chen J, Lei J, Zhang Z, Zhang Q, Giernacki W, Liu M. Sea-Surface Target Visual Tracking with a Multi-Camera Cooperation Approach. Sensors. 2022; 22(2):693. https://doi.org/10.3390/s22020693
Chicago/Turabian StyleRao, Jinjun, Kai Xu, Jinbo Chen, Jingtao Lei, Zhen Zhang, Qiuyu Zhang, Wojciech Giernacki, and Mei Liu. 2022. "Sea-Surface Target Visual Tracking with a Multi-Camera Cooperation Approach" Sensors 22, no. 2: 693. https://doi.org/10.3390/s22020693
APA StyleRao, J., Xu, K., Chen, J., Lei, J., Zhang, Z., Zhang, Q., Giernacki, W., & Liu, M. (2022). Sea-Surface Target Visual Tracking with a Multi-Camera Cooperation Approach. Sensors, 22(2), 693. https://doi.org/10.3390/s22020693