
Confronting Deep-Learning and Biodiversity Challenges for Automatic Video-Monitoring of Marine Ecosystems


{kind=link}
Abstract
:1. Introduction
2. Deep Learning for Biodiversity Monitoring
3. Biodiversity Rules and Deep Learning Limits
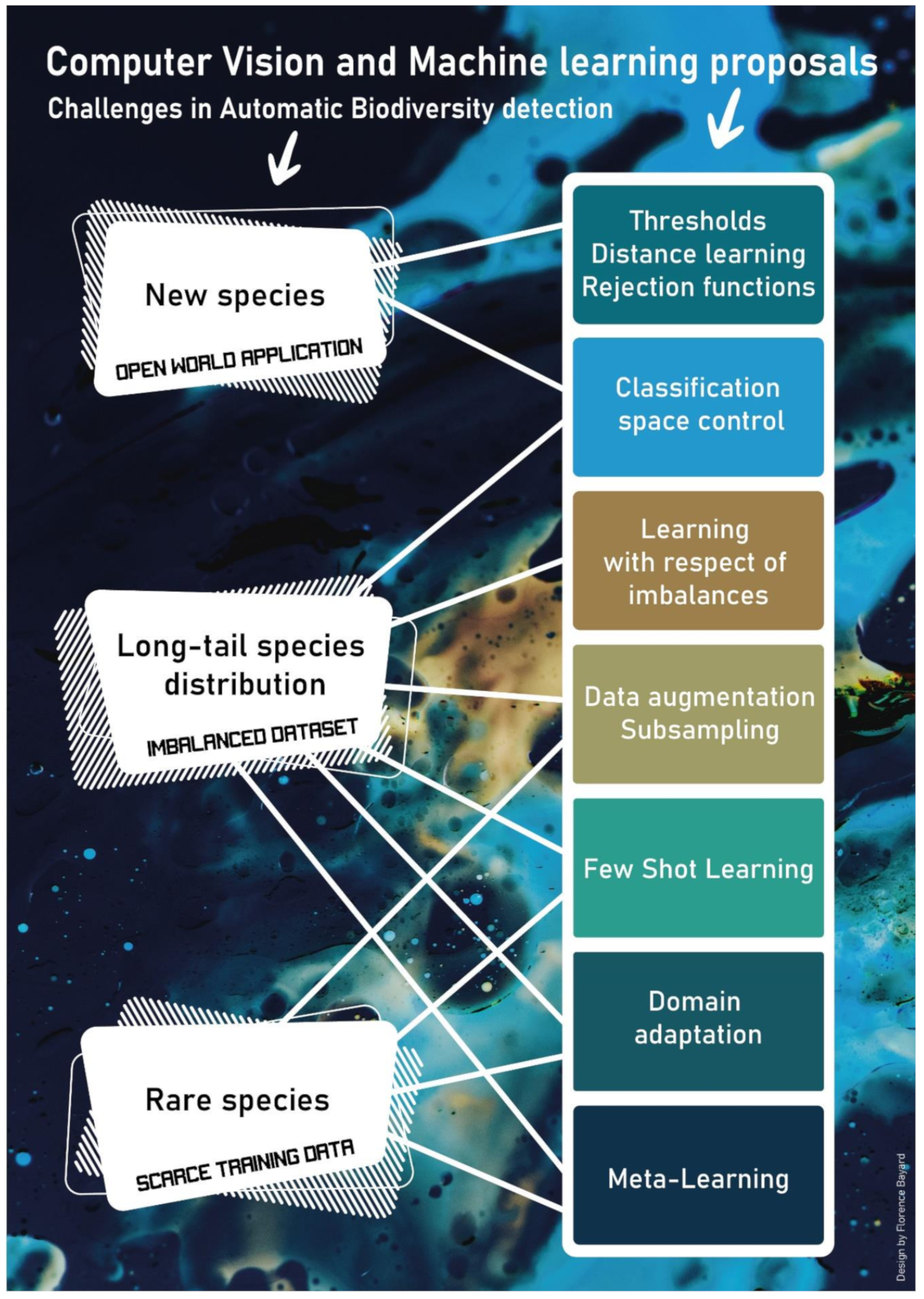
4. Long-Tail Datasets
5. Scarce Data
6. Open World Application
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dirzo, R.; Young, H.S.; Galetti, M.; Ceballos, G.; Isaac, N.J.B.; Collen, B. Defaunation in the Anthropocene. Science 2014, 345, 401–406. [Google Scholar] [CrossRef] [PubMed]
- Young, H.S.; McCauley, D.J.; Galetti, M.; Dirzo, R. Patterns, Causes, and Consequences of Anthropocene Defaunation. Annu. Rev. Ecol. Evol. Syst. 2016, 47, 333–358. [Google Scholar] [CrossRef] [Green Version]
- Lürig, M.D.; Donoughe, S.; Svensson, E.I.; Porto, A.; Tsuboi, M. Computer Vision, Machine Learning, and the Promise of Phenomics in Ecology and Evolutionary Biology. Front. Ecol. Evol. 2021, 9. [Google Scholar] [CrossRef]
- Juhel, J.B.; Vigliola, L.; Wantiez, L.; Letessier, T.B.; Meeuwig, J.J.; Mouillot, D. Isolation and no-entry marine reserves mitigate anthropogenic impacts on grey reef shark behavior. Sci. Rep. 2019, 91, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cappo, M.; De’ath, G.; Speare, P. Inter-reef vertebrate communities of the Great Barrier Reef Marine Park determined by baited remote underwater video stations. Mar. Ecol. Prog. Ser. 2007, 350, 209–221. [Google Scholar] [CrossRef]
- Zintzen, M.J.; Anderson, C.D.; Roberts, E.S.; Harvey, E.S.; Stewart, A.L. Effects of latitude and depth on the beta diversity of New Zealand fish communities. Sci. Rep. 2017, 7, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Letessier, T.B.; Mouillot, D.; Bouchet, P.J.; Vigliola, L.; Fernandes, M.C.; Thompson, C.; Boussarie, G.; Turner, J.; Juhel, J.B.; Maire, E. Remote reefs and seamounts are the last refuges for marine predators across the Indo- Pacific. PLoS Biol. 2019, 17, 1–20. [Google Scholar] [CrossRef]
- MacNeil, M.A.; Chapman, D.D.; Heupel, M.; Simpfendorfer, C.A.; Heithaus, H.; Meekan, M.; Harvey, E.; Goetze, J.; Kiszka, J.; Bond, M.E. Global status and conservation potential of reef sharks. Nature 2020, 583, 801–806. [Google Scholar] [CrossRef]
- Christin, S.; Hervet, E.; Lecomte, N. Applications for deep learning in ecology. Methods Ecol. Evol. 2019, 1632–1644. [Google Scholar] [CrossRef]
- Weinstein, B.G. A computer vision for animal ecology. J. Anim. Ecol. 2017, 87, 533–545. [Google Scholar] [CrossRef]
- Miao, Z.; Gaynor, K.M.; Wang, J.; Liu, Z.; Muellerklein, O.; Norouzzadeh, M.S.; Getz, W.M. Insights and approaches using deep learning to classify wildlife. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef]
- Ditria, E.M.; Lopez-marcano, S.; Sievers, M.; Jinks, E.L.; Brown, C.J.; Connolly, R.M. Automating the Analysis of Fish Abundance Using Object Detection: Optimizing Animal Ecology With Deep Learning. Front. Mar. Sci. 2020, 7, 1–9. [Google Scholar] [CrossRef]
- Bjerge, K.; Nielsen, J.B.; Sepstrup, M.V.; Helsing-Nielsen, F.; Høye, T.T. An automated light trap to monitor moths (Lepidoptera) using computer vision-based tracking and deep learning. Sensors (Switzerland) 2021, 21, 343. [Google Scholar] [CrossRef]
- Hieu, N.V.; Hien, N.L.H. Automatic plant image identification of Vietnamese species using deep learning models. arXiv 2020, arXiv:2005.02832. Available online: https://arxiv.org/abs/2005.02832 (accessed on 10 December 2021).
- Villon, S.; Mouillot, D.; Chaumont, M.; Darling, E.C.; Subsol, G.; Claverie, T.; Villéger, S. A Deep learning method for accurate and fast identification of coral reef fishes in underwater images. Ecol. Inform. 2018, 48, 238–244. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Gleason, H.A. The Significance of Raunkiaer’s Law of Frequency. Ecology 1929, 10, 406–408. [Google Scholar] [CrossRef]
- Fisher, R.A.; Corbet, A.S.; Williams, C.B. The Relation Between the Number of Species and the Number of Individuals in a Random Sample of an Animal Population. J. Anim. Ecol. 1943, 12, 42. [Google Scholar] [CrossRef]
- Preston, F.W. The Commonness, And Rarity, of Species. Ecol. Soc. Am. 1948, 29, 254–283. [Google Scholar] [CrossRef]
- Hercos, A.P.; Sobansky, M.; Queiroz, H.L. Magurran AE. Local and regional rarity in a diverse tropical fish assemblage. Proc. R. Soc. B Biol. Sci. 2013, 280. [Google Scholar] [CrossRef] [Green Version]
- Jones, G.P.; Munday, P.L.; Caley, M.J. Rarity in Coral Reef Fish Communities. In Coral Reef Fishes; Sale, P.F., Ed.; Academic Press: Cambridge, MA, USA, 2002; pp. 81–101. [Google Scholar]
- Brown, J.H. On the Relationship between Abundance and Distribution of Species. Am. Nat. 1984, 124, 255–279. [Google Scholar] [CrossRef]
- Whittaker, R.H. Dominance and Diversity in Land Plant Communities. Am. Assoc. Adv. Sci. Stable 1965, 147, 250–260. [Google Scholar] [CrossRef]
- Whittaker, R.H. Vegetation of the Great Smoky Mountains. Ecol. Monogr. 1956, 26, 1–80. [Google Scholar] [CrossRef]
- Loreau, M.; Holt, R.D. Spatial flows and the regulation of ecosystems. Am. Nat. 2004, 163, 606–615. [Google Scholar] [CrossRef] [Green Version]
- Holt, R.D.; Loreau, M. Biodiversity and Ecosystem Functioning: The Role of Trophic Interactions and the Importance of System Openness. In The Functional Consequences of Biodiversity; Princeton University Press: Princeton, NJ, USA, 2013; pp. 246–262. [Google Scholar]
- Carr, M.H.; Neigel, J.E.; Estes, J.A.; Andelman, S.; Warner, R.R.; Largier, J.L. Comparing Marine and Terrestrial Ecosystems: Implications for the Design of Coastal Marine Reserves. Ecol. Appl. 2003, 13, 90–107. [Google Scholar] [CrossRef] [Green Version]
- Scheirer, W.J.; de Rezende Rocha, A.; Sapkota, A.; Boult, T.E. Toward Open Set Recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Vluymans, S. Learning from Imbalanced Data In IEEE Transactions on Knowledge and Data Engineering; IEEE: New York, NY, USA, 2009; pp. 1263–1284. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, U.; Popescu, A.; Hudelot, C. Active learning for imbalanced datasets. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1428–1437. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Japkowicz, N. The Class Imbalance Problem: Significance and Strategies. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.35.1693&rep=rep1&type=pdf (accessed on 10 December 2021).
- Yates, K.L.; Bouchet, P.J.; Caley, M.J.; Mengersen, K.; Randin, C.F.; Parnell, S.; Fielding, A.H.; Bamford, A.J.; Ban, S.; Márcia, A.M. Outstanding Challenges in the Transferability of Ecological Models. Trends Ecol. Evol. 2018, 33, 790–802. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Dyk, D.A.; Meng, X.L. The Art of Data Augmentation. J. Comput. Graph. Stat. 2012, 8600, 1–50. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6. [Google Scholar] [CrossRef]
- Wong, S.C.; Mcdonnell, M.D.; Adam, G.; Victor, S. Understanding data augmentation for classification: When to warp ? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Mariani, G.; Scheidegger, F.; Istrate, R.; Bekas. C.; Malossi, C. BAGAN: Data Augmentation with Balancing GAN. arXiv 2018, arXiv:1803.09655. Available online: https://arxiv.org/abs/1803.09655 (accessed on 10 December 2021).
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Dickie, D.A.; Hernández, M.V.; Wardlaw, J.; Rueckert, D. GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks. arXiv 2018, arXiv:1810.10863. Available online: https://arxiv.org/abs/1810.10863 (accessed on 10 December 2021).
- Frid-adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging, Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar]
- Doersch, C. Tutorial on Variational Autoencoders. arXiv 2016, arXiv:1606.05908. Available online: http://arxiv.org/abs/1606.05908 (accessed on 10 December 2021).
- Beery, S.; Liu, Y.; Morris, D.; Piavis, J.; Kapoor, A.; Joshi, N.; Meister, M.; Perona, P. Synthetic examples improve generalization for rare classes. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, WACV 2020, Snowmass, CO, USA, 2–5 March 2020; pp. 852–862. [Google Scholar] [CrossRef]
- Allken, V.; Handegard, N.O.; Rosen, S.; Schreyeck, T.; Mahiout, T.; Malde, K. Fish species identification using a convolutional neural network trained on synthetic data. ICES J. Mar. Sci. 2019, 76, 342–349. [Google Scholar] [CrossRef]
- Ekbatani, H.K.; Pujol, O.; Segui, S. Synthetic data generation for deep learning in counting pedestrians. In Proceedings of the ICPRAM 2017–6th International Conference on Pattern Recognition Applications and Methods, Porto, Portugal, 24–26 January 2017; pp. 318–323. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:1712.04621. Available online: https://arxiv.org/abs/1712.04621 (accessed on 10 December 2021).
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.; Tech, C. Class-Balanced Loss Based on Effective Number of Samples. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cao, K.; Wei, C.; Gaidon, A.; Arechiga, N.; Ma, T. Learning imbalanced datasets with label-distribution-aware margin loss. Adv. Neural Inf. Process. Syst. 2019, 32, 1–18. [Google Scholar]
- Tan, J.R.; Wang, C.B.; Li, B.Y.; Li, Q.Q.; Ouyang, W.L.; Yin, C.Q.; Yan, J.J. Equalization loss for long-tailed object recognition. In Proceedings of the IEEE Comput Soc Conf Comput Vis Pattern Recognit, Seattle, WA, USA, 13–19 June 2020; pp. 11659–11668. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; pp. 1856–1868. [Google Scholar]
- Jamal, M.A.; Cloud, H. Task Agnostic Meta-Learning for Few-Shot Learning. In Proceedings of theIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sun, Q.; Chua, Y.L.T. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of theIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Li, H.; Eigen, D.; Dodge, S.; Zeiler, M.; Wang, X. Finding task-relevant features for few-shot learning by category traversal. arXiv 2019, arXiv:1905.11116. Available online: https://arxiv.org/abs/1905.11116 (accessed on 10 December 2021).
- Sung, F.; Yang, Y.; Zhang, L. Learning to Compare: Relation Network for Few-Shot Learning Queen Mary University of London. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Oreshkin, B.N.; Rodriguez, P.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. Adv. Neural Inf. Process. Syst. 2018, 721–731. [Google Scholar]
- Zhang, X.; Hospedales, T. RelationNet2: Deep Comparison Columns for Few-Shot Learning. arXiv Prepr. 2017, arXiv:181107100. Available online: https://arxiv.org/abs/1811.07100 (accessed on 10 December 2021).
- Wang, Y.; Yao, Q.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-shot. ACM Comput. Surv. 2020, 53. [Google Scholar] [CrossRef]
- Li, A.; Luo, T.; Lu, Z.; Xiang, T.; Wang, L. Large-Scale Few-Shot Learning: Knowledge Transfer With Class Hierarchy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7212–7220. [Google Scholar]
- Liu, L.; Zhou, T.; LONG, G.; Jiang, J.; Zhang, C. Many-Class Few-Shot Learning on Multi-Granularity Class Hierarchy. arXiv 2020, arXiv:2006.15479. Available online: https://arxiv.org/abs/2006.15479 (accessed on 10 December 2021). [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. arXiv 2019, arXiv:1904.05046. Available online: https://arxiv.org/abs/1904.05046 (accessed on 10 December 2021). [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, H.Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Villon, S.; Iovan, C.; Mangeas, M.; Claverie, T. Automatic underwater fish species classification with limited data using few-shot learning. Ecol. Inform. 2021, 63, 101320. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P. Object Detection with Deep Learning: A Review In IEEE Transactions on Neural Networks and Learning Systems; IEEE: New York, NY, USA, 2019; pp. 3212–3232. [Google Scholar]
- Scheirer, W.J. Probability Models for Open Set Recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2014. [Google Scholar] [CrossRef] [Green Version]
- Jain, L.P.; Scheirer, W.J.; Boult, T.E. Multi-class Open Set Recognition Using Probability of Inclusion. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 393–409. [Google Scholar]
- Zhang, H.; Member, S.; Patel, V.M.; Member, S. Sparse Representation-based Open Set Recognition. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2016; pp. 1–8. [Google Scholar]
- Lonij, V.P.A.; Rawat, A.; Nicolae, M. Open-World Visual Recognition Using Knowledge Graphs. arXiv 2017, arXiv:1708.08310. Available online: https://arxiv.org/abs/1708.08310 (accessed on 10 December 2021).
- Geng, C.; Huang, S.; Chen, S. Recent Advances in Open Set Recognition: A Survey. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2020. [Google Scholar] [CrossRef] [Green Version]
- Hassen, M.; Chan, P.K. Learning a Neural-network-based Representation for Open Set Recognition. In Proceedings of the 2020 SIAM International Conference on Data Mining, Cincinnati, OH, USA, 5–8 May 2020. [Google Scholar]
- Parmar, J.; Chouhan, S.S.; Rathore, S.S. Open-world Machine Learning: Applications, Challenges, and Opportunities. arXiv 2021, arXiv:2105.13448. Available online: https://arxiv.org/abs/2105.13448 (accessed on 10 December 2021).
- Song, L.; Sehwag, V.; Bhagoji, A.N.; Mittal, P. A Critical Evaluation of Open-World Machine Learning. arXiv 2020, arXiv:2007.04391. Available online: https://arxiv.org/abs/2007.04391 (accessed on 10 December 2021).
- Leng, Q.; Ye, M.; Tian, Q. A Survey of Open-World Person Re-identification. In IEEE Transactions on Circuits and Systems for Video Technology; IEEE: New York, NY, USA, 2019; pp. 1092–1108. [Google Scholar] [CrossRef]
- Mendes, P.R.; Roberto, J.; Rafael, M.D.S.; Werneck, R.D.O.; Stein, B.V.; Pazinato, D.V.; de Almeida, W.R.; Penatti, O.A.B.; Torres, R.D.S.; Rocha, A. Nearest neighbors distance ratio open-set classifier. Mach. Learn. 2017, 106, 359–386. [Google Scholar] [CrossRef] [Green Version]
- Bendale, A.; Boult, T.E. Towards open set deep networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar] [CrossRef] [Green Version]
- Dhamija, A.R.; Günther, M.; Boult, T.E. Reducing network agnostophobia. arXiv 2018, arXiv:1811.04110. Available online: https://arxiv.org/abs/1811.04110 (accessed on 10 December 2021).
- Ge, Z.; Chen, Z. Generative OpenMax for Multi-Class Open Set Classification. arXiv 2017, arXiv:1707.07418. Available online: https://arxiv.org/abs/1707.07418 (accessed on 10 December 2021).
- Rosa, R.D.; Mensink, T.; Caputo, B. Online Open World Recognition. arXiv 2016, arXiv:1604.02275. Available online: https://arxiv.org/abs/1604.02275 (accessed on 10 December 2021).
- Shu, L.; Xu, H.; Liu, B. Unseen Class Discovery in Open-World Classification. arXiv 2018, arXiv:1801.05609. Available online: https://arxiv.org/abs/1801.05609 (accessed on 10 December 2021).
- Oza, P.; Patel, V.M. Deep CNN-based Multi-task Learning for Open-Set Recognition. arXiv 2019, arXiv:1903.03161. Available online: https://arxiv.org/abs/1903.03161 (accessed on 10 December 2021).
- Guo, X.; Chen, X.; Zeng, K. Multi-stage Deep Classifier Cascades for Open World Recognition. In Proceedings of the 28th ACM International Conference on Information and Knowledge Managemen, Beijing, China, 3–7 November 2019; pp. 179–188. [Google Scholar]
- Miller, D.; Niko, S.; Milford, M.; Dayoub, F. Class Anchor Clustering: A Loss for Distance-based Open Set Recognition. arXiv 2021, arXiv:2004.02434. Available online: https://arxiv.org/abs/2004.02434 (accessed on 10 December 2021).
- Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Large-scale long-tailed recognition in an open world. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2532–2541. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villon, S.; Iovan, C.; Mangeas, M.; Vigliola, L. Confronting Deep-Learning and Biodiversity Challenges for Automatic Video-Monitoring of Marine Ecosystems. Sensors 2022, 22, 497. https://doi.org/10.3390/s22020497
Villon S, Iovan C, Mangeas M, Vigliola L. Confronting Deep-Learning and Biodiversity Challenges for Automatic Video-Monitoring of Marine Ecosystems. Sensors. 2022; 22(2):497. https://doi.org/10.3390/s22020497
Chicago/Turabian StyleVillon, Sébastien, Corina Iovan, Morgan Mangeas, and Laurent Vigliola. 2022. "Confronting Deep-Learning and Biodiversity Challenges for Automatic Video-Monitoring of Marine Ecosystems" Sensors 22, no. 2: 497. https://doi.org/10.3390/s22020497
APA StyleVillon, S., Iovan, C., Mangeas, M., & Vigliola, L. (2022). Confronting Deep-Learning and Biodiversity Challenges for Automatic Video-Monitoring of Marine Ecosystems. Sensors, 22(2), 497. https://doi.org/10.3390/s22020497