The effectiveness of applying the fog computing layer within the existing IoT architectures depends on the objective of a specific IoT scenario. Each IoT service has its execution priorities and implementation restrictions that define the feasibility of applying fog computing principles within the specific scenario. However, the main goal in the design of the service architecture is to deliver its functionalities in the most efficient manner, and the efficiency of each specific service scenario is evaluated based on its primary goal. Within the IoT concept, fog computing primarily emerged as a response to the low latency requirements and the need to unburden the public network and cloud infrastructure of data traffic and processing load generated by IoT devices. Thus, the evaluation of the application of fog computing within IoT scenarios is primarily based on these premises and on all other consequential enhancements that can be achieved by shifting the processing load towards the network edge. One of those enhancements is the level of security in IoT architectures, which is often pointed out as the main obstacle towards further extensive growth of this concept. Employing local devices for raw data processing in local networks or applying security wrappers and cryptographic algorithms before forwarding data towards public networks could reduce the potential risk of service security breaches.
Achieving the full potential of fog computing within the specific IoT scenario requires that the primary goals, which determine its efficiency and could be affected by the utilization of fog computing, are first identified. The schedule of its service components along the fog-to-cloud environment is then tailored to improve the aimed efficiency based on the previously specified criteria.
Within this section, in
Section 3.1, we first analyzed the main relevant contexts that define the feasibility and deployment restrictions for the utilization of fog computing within the specific IoT scenario. Then, in
Section 3.2, we define relevant QoS parameters affected by the inclusion of fog computing in IoT environments. Finally, in
Section 3.3, we describe a procedure of IoT service categorization that affects the application of service scheduling along fog-to-cloud architectures.
3.1. Contexts of Service Scheduling across Fog-to-Cloud Environment
The feasibility and the efficiency of service scheduling across fog-to-cloud environments depends on three relevant contexts:
Available execution environment (device context);
Specific service scenario (service context);
Specific service user (user context).
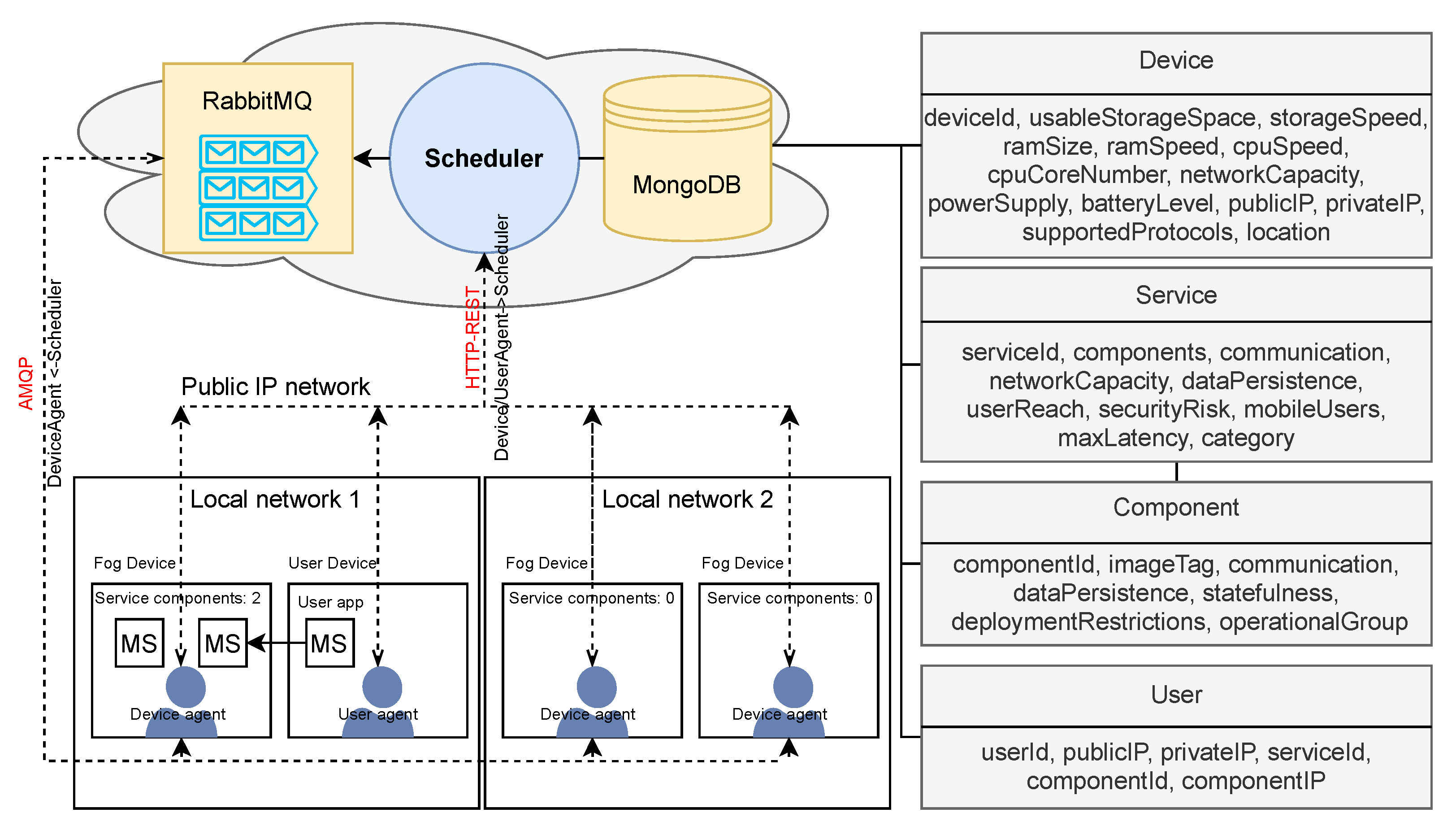
The device context describes each fog device that offers its resources for the execution of service components. It is a prerequisite for the execution of service scheduling since the inclusion of fog layer depends on the available devices in local environments. The service context and user context are then utilized to determine the efficient schedule of service components along the fog-to-cloud continuum.
The device context is the description of the available fog processing nodes. The existing literature does not provide a clear and unified definition of a fog node, but numerous specifications similarly describe its functionality. The authors in [
25] present their assumptions about the functionalities that fog devices should provide. These include computing, processing, and storing data in addition to routing and forwarding of data packets, sharing the network, computational, and storage load among themselves, and providing optimal support for the mobility of end-devices. However, more specific examples of device descriptions within fog environments are displayed in papers where practical experiments were conducted. Thus, the authors of [
26] define fog devices with the following properties: storage capacity, processing capacity, memory capacity, number of processing units, and the service rate of one processing unit. These parameters define the storage and processing capabilities of a fog node that are significant for service scheduling. Hence, the scheduler can determine the most suitable fog node to run a specific service component based on this information. Therefore, we also consider the storage and processing capabilities of the fog node, along with other properties that in our approach affect the decision about the most appropriate location for the service deployment. We define the device context with the following properties:
CPU (frequency, number of processing units);
RAM (frequency, capacity);
Storage memory (frequency, capacity);
Location (network address - private and public IP, GPS location);
Power supply (available battery capacity, AC power supply);
Communication (capacity of IP connection, other supported protocols).
The service context defines the information about the specific service scenario. Although there are numerous different descriptions and classifications of IoT services [
20,
27,
28], a unified definition does not exist. Still, the common baseline of existing definitions is that IoT services enable interaction with the physical world through sensor or actuator devices placed across targeted local environments. The goal of applying fog computing within IoT is to enhance service performance by migrating, at least partially, its processing components from the cloud towards these targeted local environments. However, each service scenario has different deployment limitations and operational goals that have to be considered to efficiently schedule its components across the fog-to-cloud continuum. Thus, we define the following properties that describe the service context within our approach:
Data persistence (persistent/non-persistent);
User reach (general/specific);
Communication (IP connection capacity, other necessary communication protocols);
Latency (maximum allowed latency);
Security (low/high risk);
Statefulness (stateful/stateless).
The user context provides the description of a specific service user. Most of the existing attempts to define the user context across the literature focus on the creation of accurate user profiles based on the relevant information about specific users [
29,
30]. Since our goal is to enhance the QoS in service delivery, we consider user inputs that affect the targeted QoS level as their relevant profiles. Additionally, as the authors in [
31] point out, the main drawback of central cloud processing is the lack of location awareness in service delivery for mobile users. Thus, we consider the user’s network location as an important property that tackles this drawback within our service scheduling approach. Therefore, we define the following properties of user context:
3.3. Deployment Restrictions and the Categorization of IoT Services
This section describes our categorization of IoT services that determines the priority of identified QoS parameters and the deployment restrictions of a particular IoT scenario. Although there are numerous different IoT use-cases, each service scenario includes similar operational components from the following functional groups:
These groups often imply separate microservices that together carry out the complete service functionality. However, the functional group of each microservice affects its deployment location across the distributed fog-to-cloud environment. Thus, to design an efficient scheduling algorithm, we first categorized IoT services and defined the deployment restrictions for specific use-cases.
The primary goal of our categorization is to determine the importance priority among previously identified QoS parameters for different categories of IoT services. Thus, the first step was to define service categories that briefly describe the essential purpose of a specific service scenario. Optimizations enabled by the application of fog computing are then mainly defined by these categories that primarily determine the goal of the specific service.
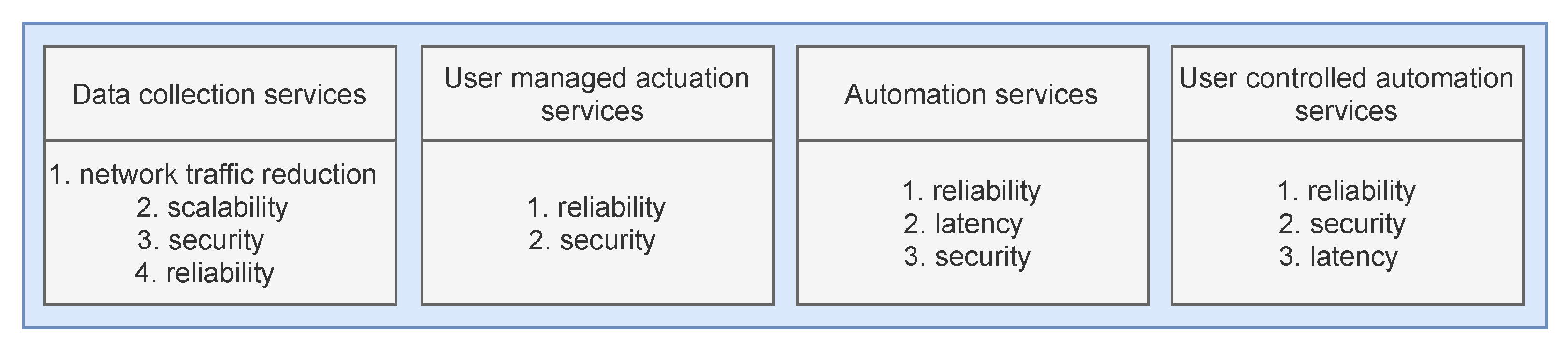
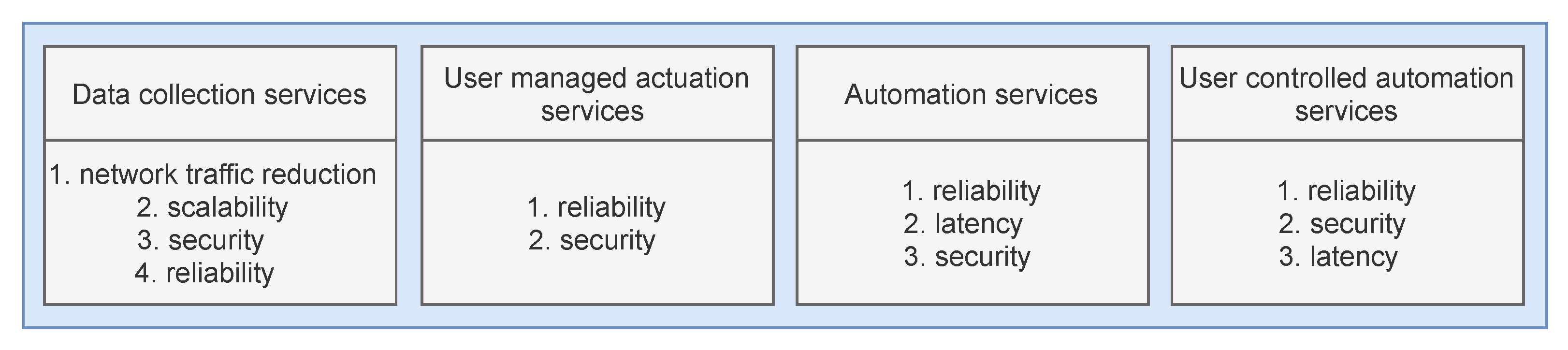
We define four different IoT service categories, as depicted in
Figure 1, along with the associated QoS parameters ordered by their priority ranking within each category. These categories encompass most of the existing IoT scenarios described across the existing literature as the IoT scenarios with the highest application potential.
Data collection services and user-managed actuation services include basic scenarios, enabling simple IoT functionalities without intermediate data processing. Data collection services consider scenarios where the sensor data are gathered from sensor devices and stored within the cloud. Data are then offered directly to users or third-party companies for further processing (e.g., smart metering services). The high data volume generated in these scenarios is often pointed out as their most significant flaw, along with the security of transmitted data. Thus, fog computing optimizations within this category focus on reducing the data volume in public networks and strengthening the security of data transmission.
User-managed actuation services include basic scenarios where actuator control is enabled directly to users (e.g., door locks, heat control, etc.). Such services usually do not have a critical response time, but security and reliability are their essential properties since actuating devices perform actions that affect the physical world. Thus, applying fog computing in these scenarios should be pointed towards these QoS parameters.
The second two categories include more complex services that include all previously stated operational components. Automation services include completely autonomous scenarios, where actuation is executed autonomously based on the sensor data collected from the targeted environment (e.g., autonomous driving, automated parking ramps, etc.). Primary QoS parameters within such scenarios are reliability and latency, since actions must be completed almost instantly as a response to real-world situations. User-controlled automation services are a similar category where the actuation is to a certain extent controlled by the user (e.g., smart intercom, camera drones, etc.). Hence, latency in such scenarios is a less critical QoS parameter than reliability and security, since the threat of unauthorized actuation control exists within this category.
Another factor that affects the execution of our service scheduling are particular IoT services that require a specific deployment location across the distributed fog-to-cloud environment for their components. Service context parameters determine such deployment restrictions, and thus, they have to be considered before executing component scheduling. Our scheduling algorithm prioritizes local fog execution for each service component by default, so our goal was to detect use-cases that demand a different approach. Thus, if the service implies communication over constrained communication protocols, has high-security risk, or the specific user reach, its components should be explicitly deployed in a local environment, especially those intended to establish the interaction with the end devices. Additionally, the migration of stateful service components or those that include persistent data storage should be restricted since the effectiveness in such cases is lost because of the complexity and duration of their transfer. Therefore, service parameters: communication, security, user reach, data persistence, and statefulness, are considered first while executing our scheduling algorithm on the specific service component to recognize and address the described exceptional cases, if necessary.
3.4. Objective Function
In this subsection, we define the objective function of our scheduling algorithm that summarizes all previously described factors affecting the application of fog computing architecture. Applying fog computing benefits the IoT architecture in terms of the stated QoS parameters, as described previously in
Section 3.2. Thus, our first goal is to prioritize the local execution of service components, as the local interaction between the user (
U) and the service improves the level of each stated QoS parameter:
The IoT service (
S) is a set of
n service components (
sc):
and the set of
m available fog devices (
F) includes all nodes running in the cloud (
), user’s local network (
), and nodes in other private networks that are publicly exposed (
):
while the ones considered in this step are the ones running in the user’s local environment:
However, it is necessary to consider the possibility that each service component may have a deployment restriction that requires a specific execution environment as described in
Section 3.3. Thus, we define the following two deployment restrictions:
If the defined objective function cannot schedule all service components to the user’s local environment (except the ones with deployment restrictions) as there may not be available local fog devices, we propose considering the latency as the second decision parameter since it also approximates locality. Thus, the second objective function aims to determine the available fog node that has the minimal latency in communication with the user requesting the service:
but it only considers a subset of
s publicly available fog nodes and the ones running in the cloud:
The proposed approach favors service execution in fog environments to reach the improvements in terms of the stated QoS parameters, while the adjusted scheduling performance can be imposed by utilizing available deployment restrictions. In the following sections, we describe the algorithm based on the proposed objective function along with its implementation and performance evaluation.






{kind=link}
{kind=link}
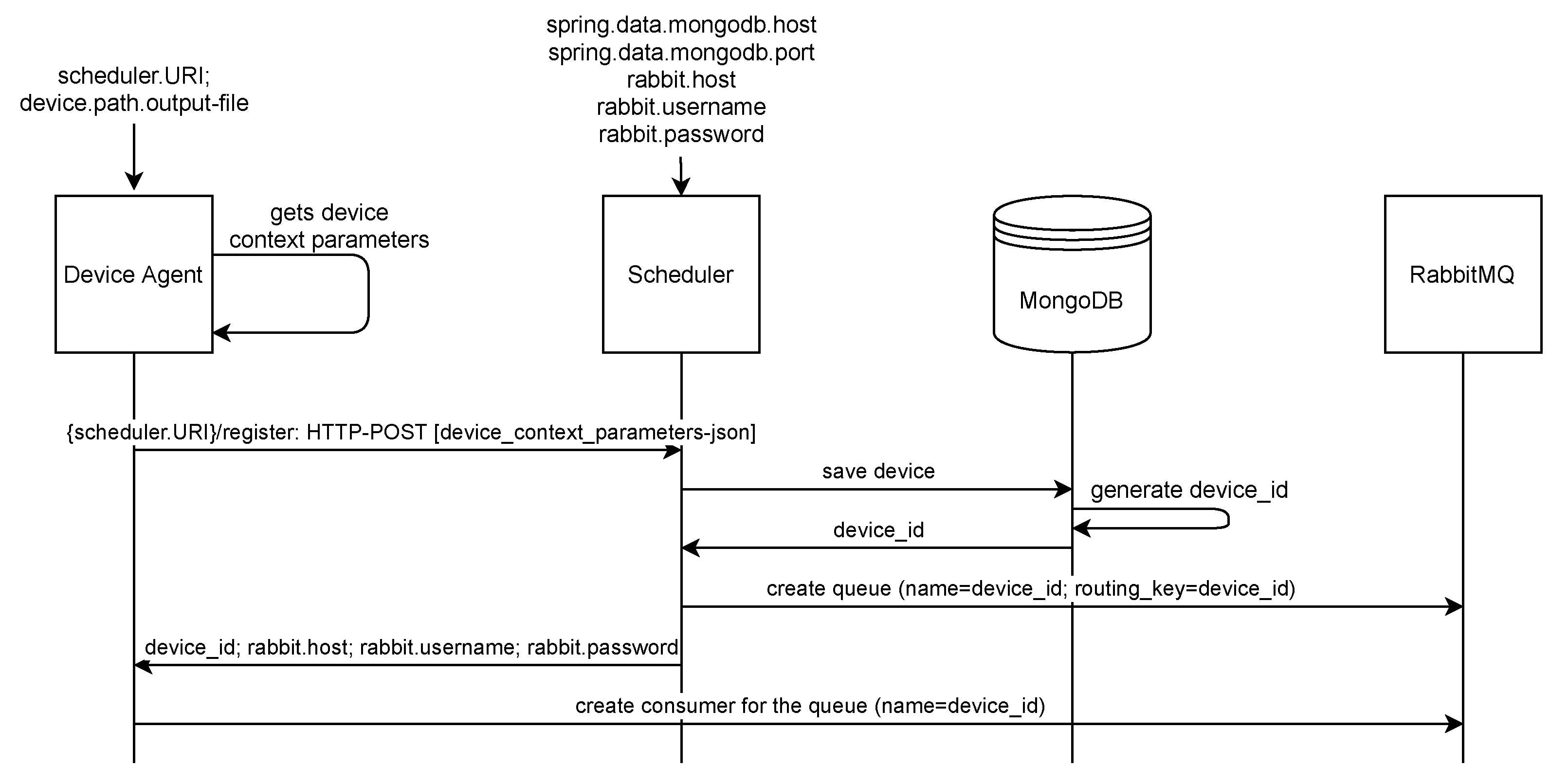{kind=link}
{kind=link}
{kind=link}
{kind=link}
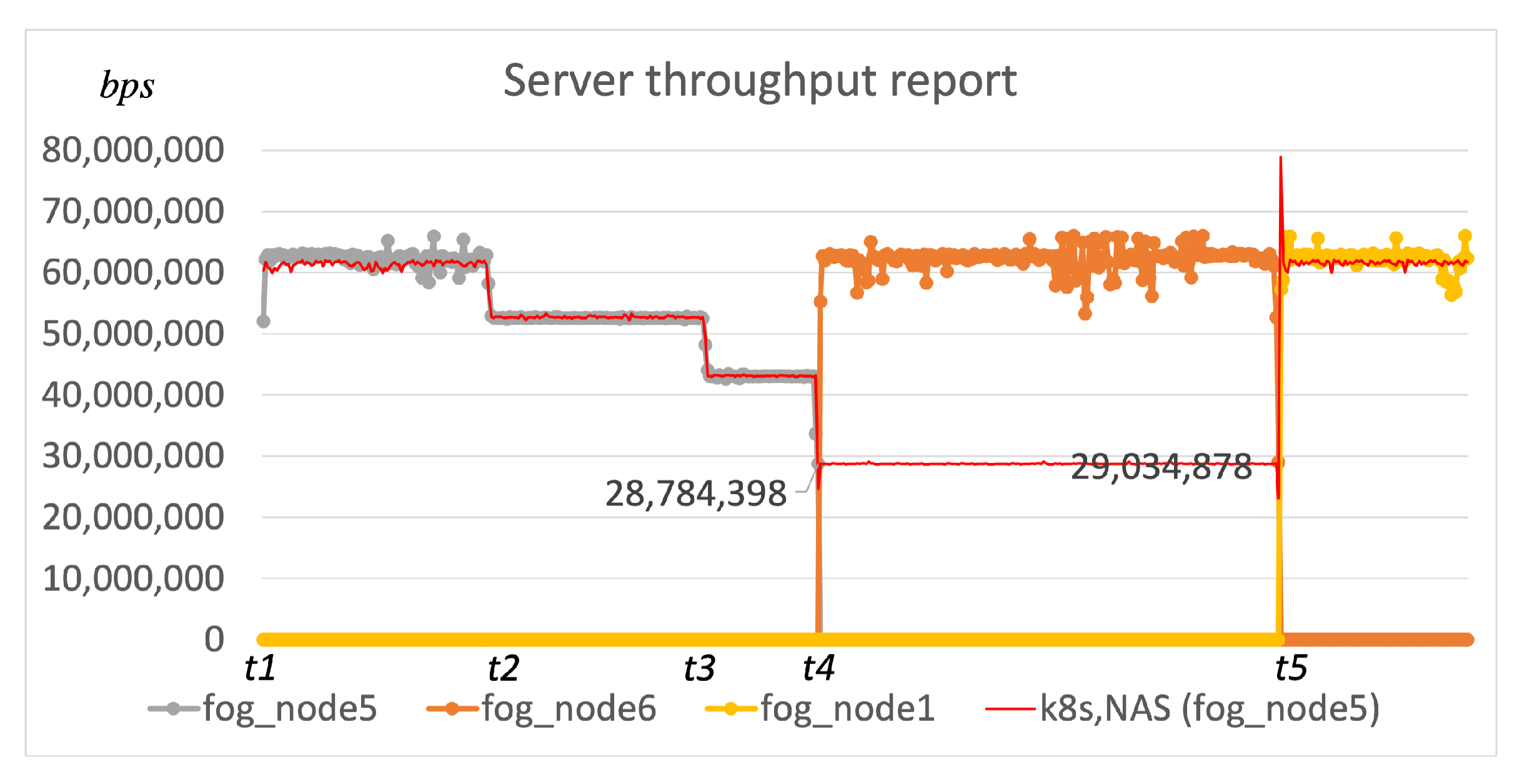{kind=link}
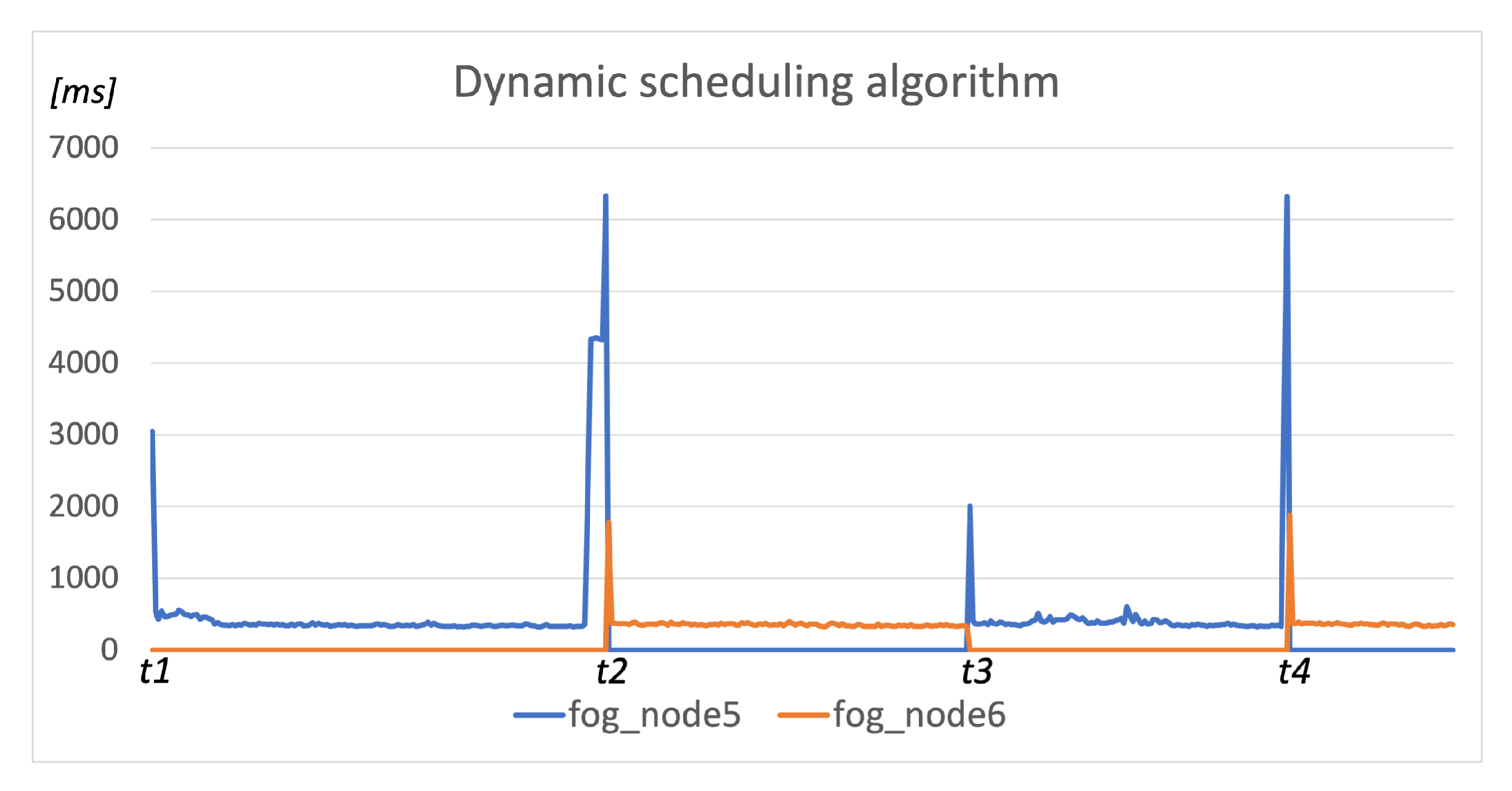{kind=link}
{kind=link}