
Single Seed Identification in Three Medicago Species via Multispectral Imaging Combined with Stacking Ensemble Learning

 , ,
, ,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Multispectral Imaging System
2.3. Multispectral Image Analysis
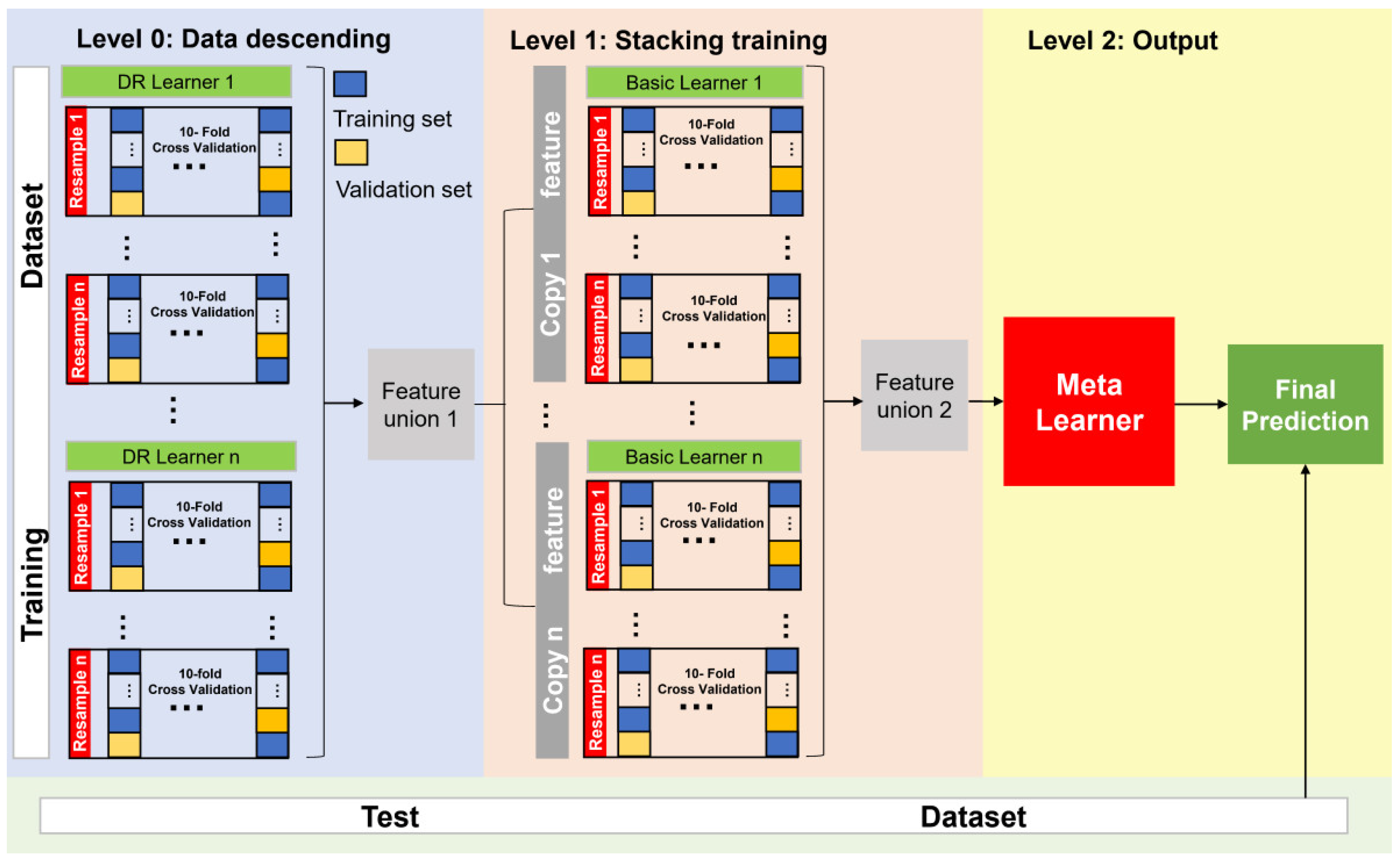
2.4. SEL Model
2.5. Selection of DRFE Models, Basic Models, and the Meta-Learner
2.6. Evaluation Metrics and Model Interpretation
2.7. Optimal Features Selection
3. Results
3.1. Morphological Features of Seeds in Three Medicago Species
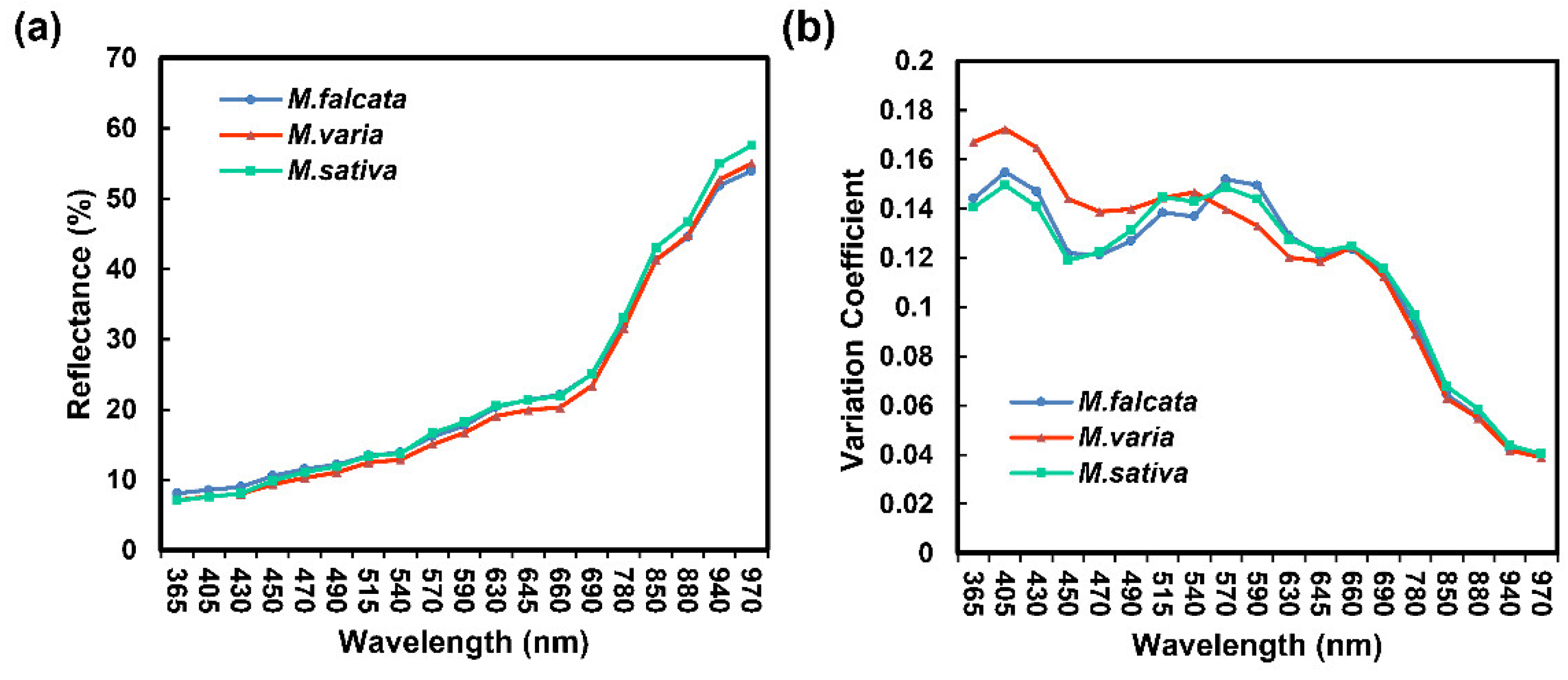
3.2. Spectroscopic Analysis of Seeds in Three Medicago Species
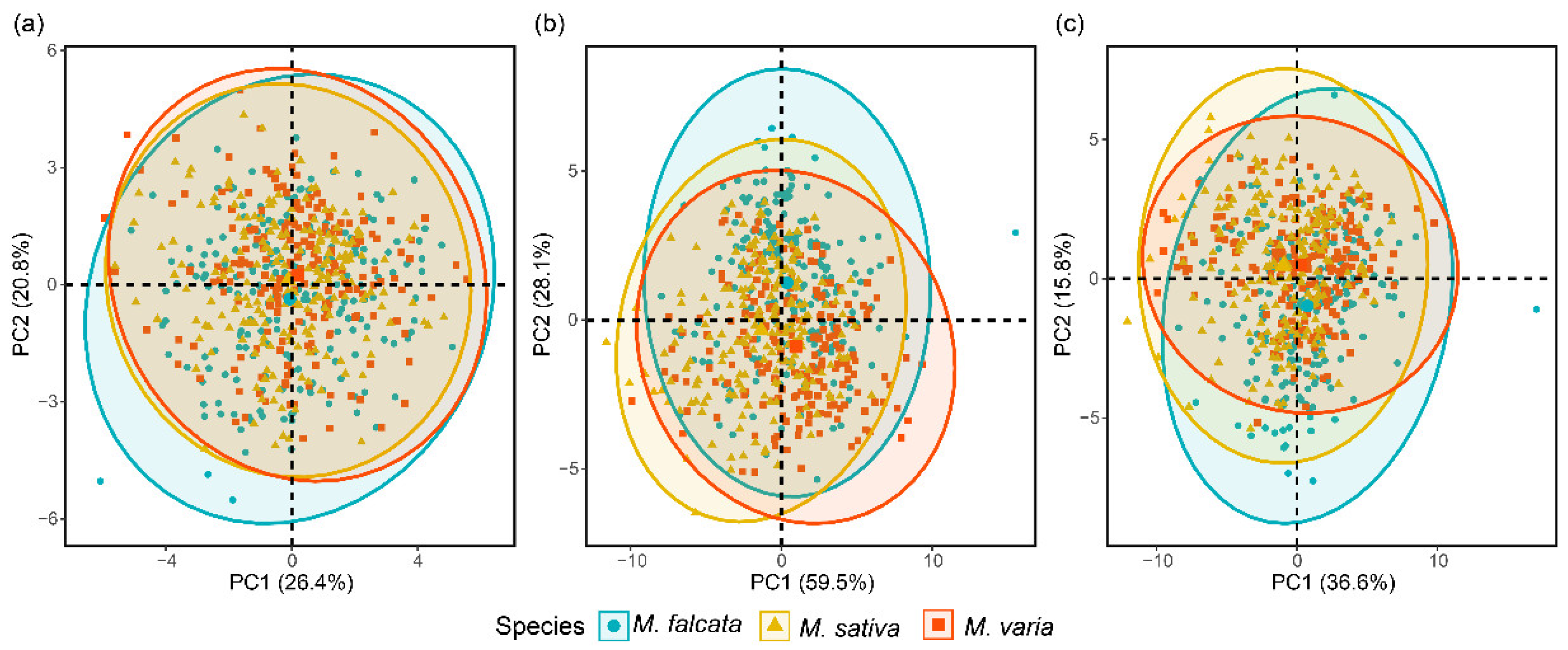
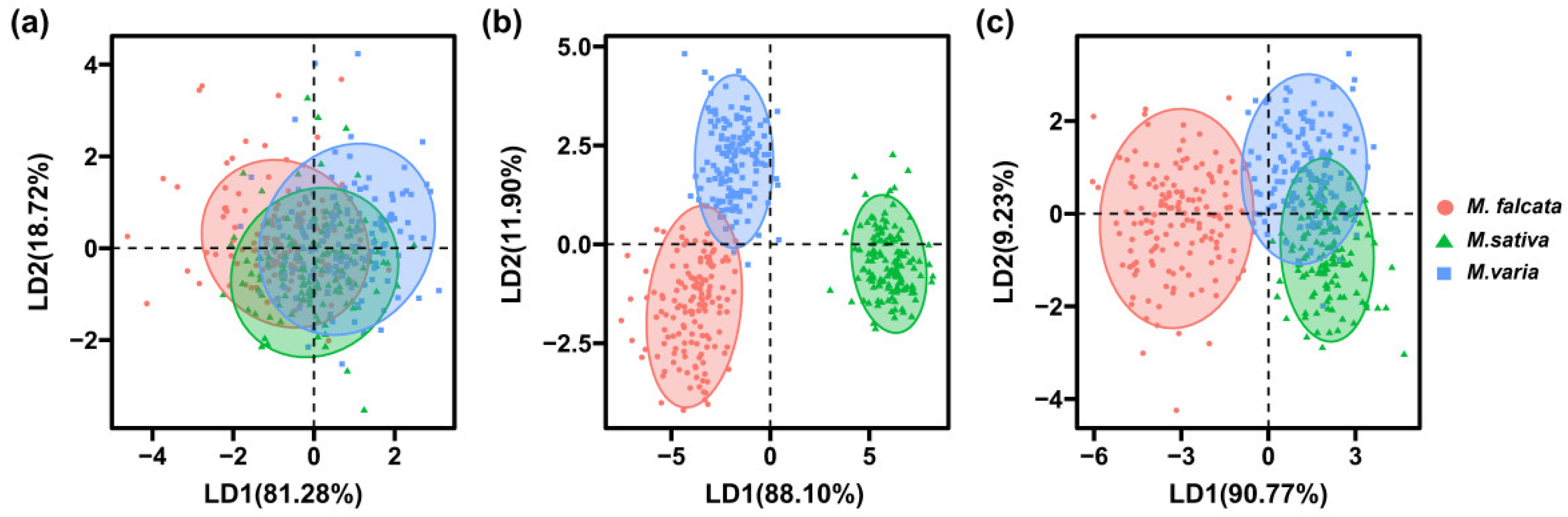
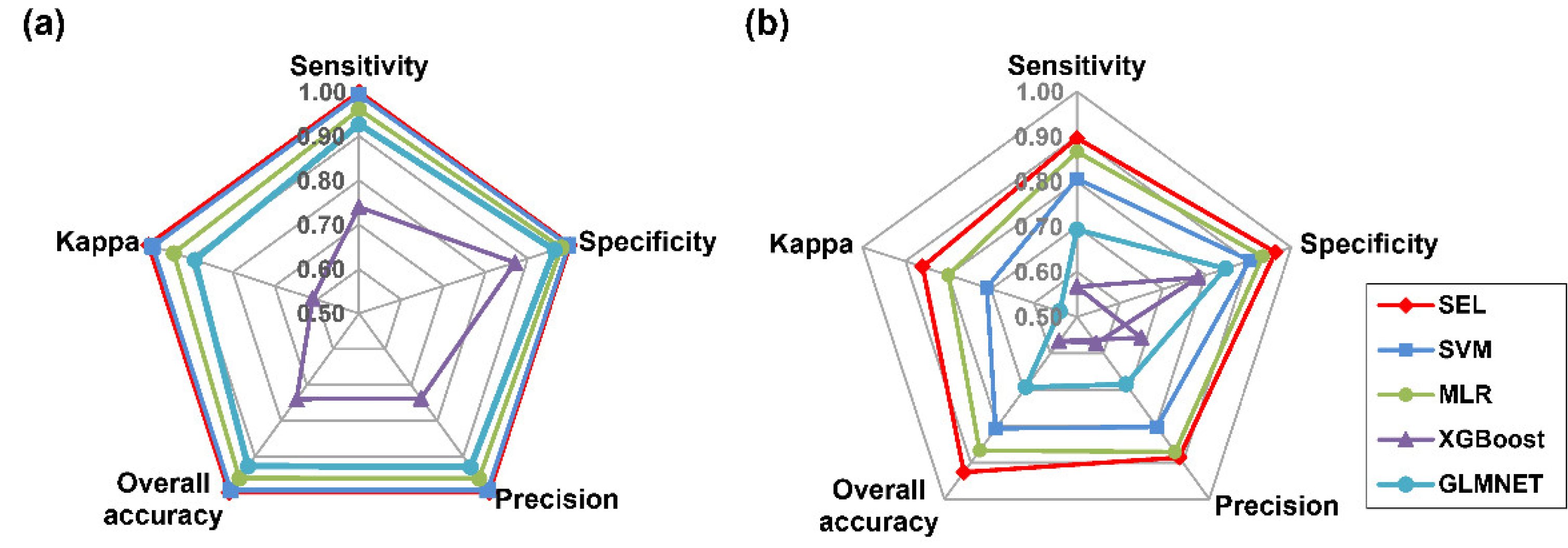
3.3. SEL Model for Seed Discrimination
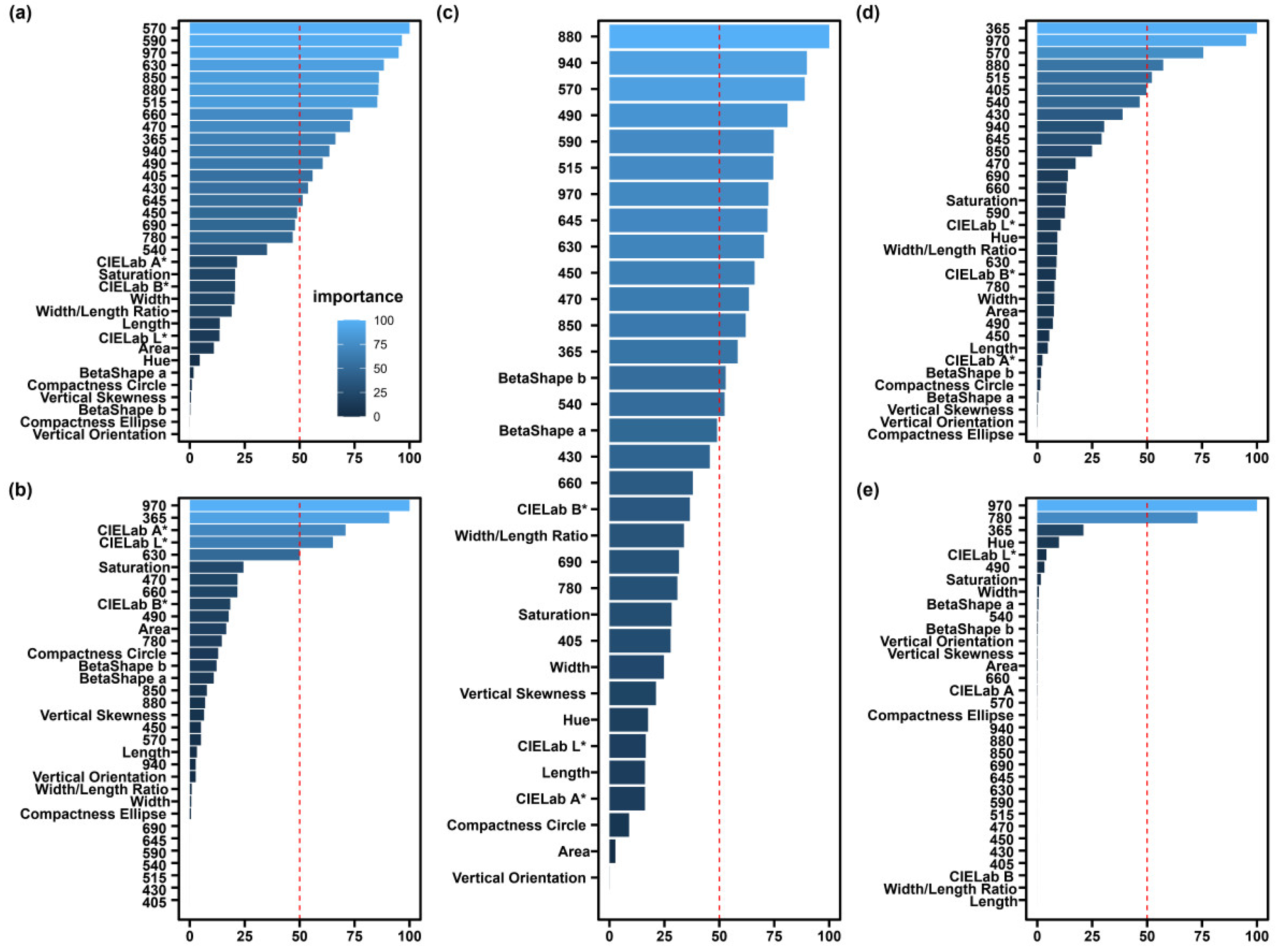
3.4. Optimal Feature Selection for Identifying Medicago Species Seeds
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dien, B.S.; Miller, D.J.; Hector, R.E.; Dixon, R.A.; Chen, F.; McCaslin, M.; Reisen, P.; Sarath, G.; Cotta, M.A. Enhancing alfalfa conversion efficiencies for sugar recovery and ethanol production by altering lignin composition. Bioresour. Technol. 2011, 102, 6479–6486. [Google Scholar] [CrossRef] [PubMed]
- Gaweł, E.; Grzelak, M.; Janyszek, M. Lucerne (Medicago sativa L.) in the human diet-Case reports and short reports. J. Herb. Med. 2017, 10, 8–16. [Google Scholar] [CrossRef]
- Giuberti, G.; Rocchetti, G.; Sigolo, S.; Fortunati, P.; Lucini, L.; Gallo, A. Exploitation of alfalfa seed (Medicago sativa L.) flour into gluten-free rice cookies: Nutritional, antioxidant and quality characteristics. Food Chem. 2018, 239, 679–687. [Google Scholar] [CrossRef] [PubMed]
- Saccomanno, B.; Wallace, M.; O’Sullivan, D.M.; Cockram, J. Use of genetic markers for the detection of off-types for DUS phenotypic traits in the inbreeding crop, barley. Mol. Breed. 2020, 40, 13. [Google Scholar] [CrossRef]
- Rahman, A.; Cho, B.K. Assessment of seed quality using non-destructive measurement techniques: A review. Seed Sci. Res. 2016, 26, 285–305. [Google Scholar] [CrossRef]
- Feng, L.; Zhu, S.S.; Liu, F.; He, Y.; Bao, Y.D.; Zhang, C. Hyperspectral imaging for seed quality and safety inspection: A review. Plant Methods 2019, 15, 91. [Google Scholar] [CrossRef]
- Shrestha, S.; Deleuran, L.C.; Olesen, M.H.; Gislum, R. Use of multispectral imaging in varietal identification of tomato. Sensors 2015, 15, 4496–4512. [Google Scholar] [CrossRef]
- ElMasry, G.; Mandour, N.; Al-Rejaie, S.; Belin, E.; Rousseau, D. Recent applications of multispectral imaging in seed phenotyping and quality monitoring-an overview. Sensors 2019, 19, 1090. [Google Scholar] [CrossRef]
- Franca-Silva, F.; Rego, C.H.Q.; Gomes-Junior, F.G.; Moraes, M.H.D.; Medeiros, A.D.; Silva, C.B.D. Detection of drechslera avenae (Eidam) sharif [Helminthosporium avenae (Eidam)] in black oat seeds (Avena strigosa Schreb) using multispectral imaging. Sensors 2020, 20, 3343. [Google Scholar] [CrossRef]
- Hu, X.W.; Yang, L.J.; Zhang, Z.X.; Wang, Y.R. Differentiation of alfalfa and sweet clover seeds via multispectral imaging. Seed Sci. Technol. 2020, 48, 83–99. [Google Scholar] [CrossRef]
- Liu, C.H.; Liu, W.; Lu, X.Z.; Chen, W.; Yang, J.B.; Zheng, L. Nondestructive determination of transgenic Bacillus thuringiensis rice seeds (Oryza sativa L.) using multispectral imaging and chemometric methods. Food Chem. 2014, 153, 87–93. [Google Scholar] [CrossRef] [PubMed]
- Li, X.W.; Fan, X.F.; Zhao, L.L.; Huang, S.; He, Y.; Suo, X.S. Discrimination of pepper seed varieties by multispectral imaging combined with machine learning. Appl. Eng. Agric. 2020, 36, 743–749. [Google Scholar] [CrossRef]
- Weng, H.Y.; Tian, Y.; Wu, N.; Li, X.L.; Yang, B.Y.; Huang, Y.P.; Ye, D.P.; Wu, R.Y. Development of a low-cost narrow band multispectral imaging system coupled with chemometric analysis for rapid detection of rice false smut in rice seed. Sensors 2020, 20, 1209. [Google Scholar] [CrossRef]
- Ang, K.L.M.; Seng, J.K.P. Big data and machine learning with hyperspectral information in agriculture. IEEE Access 2021, 9, 36699–36718. [Google Scholar] [CrossRef]
- Ma, C.; Zhang, H.H.; Wang, X.F. Machine learning for big data analytics in plants. Trends Plant Sci. 2014, 19, 798–808. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Balakrishnama, S.; Ganapathiraju, A. Linear discriminant analysis-a brief tutorial. Inst. Signal Inf. Process. 1998, 18, 1–8. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA; 2014; pp. 655–665. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Andiojaya, A.; Demirhan, H. A bagging algorithm for the imputation of missing values in time series. Expert Syst. Appl. 2019, 129, 10–26. [Google Scholar] [CrossRef]
- Wang, B.Y.; Pineau, J. Online bagging and boosting for imbalanced data streams. IEEE Trans. Knowl. Data Eng. 2016, 28, 3353–3366. [Google Scholar] [CrossRef]
- Hui, Y.; Mei, X.S.; Jiang, G.D.; Tao, T.; Pei, C.Y.; Ma, Z.W. Milling tool wear state recognition by vibration signal using a stacked generalization ensemble model. Shock. Vib. 2019, 2019, 7386523. [Google Scholar] [CrossRef]
- El-Rashidy, N.; El-Sappagh, S.; Abuhmed, T.; Abdelrazek, S.; El-Bakry, H.M. Intensive care unit mortality prediction: An improved patient-specific stacking ensemble model. IEEE Access 2020, 8, 133541–133564. [Google Scholar] [CrossRef]
- Haddad, B.M.; Yang, S.; Karam, L.J.; Ye, J.P.; Patel, N.S.; Braun, M.W. Multifeature, sparse-based approach for defects detection and classification in semiconductor units. IEEE Trans. Autom. Sci. Eng. 2018, 15, 145–159. [Google Scholar] [CrossRef]
- Wu, T.A.; Zhang, W.; Jiao, X.Y.; Guo, W.H.; Hamoud, Y.A. Evaluation of stacking and blending ensemble learning methods for estimating daily reference evapotranspiration. Comput. Electron. Agric. 2021, 184, 106039. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Kwak, C.; Clayton-Matthews, A. Multinomial logistic regression. Nurs Res 2002, 51, 404–410. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. B 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Chen, T.Q.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, D.H.; Qian, L.Y.; Mao, B.J.; Huang, C.; Huang, B.; Si, Y.L. A data-driven design for fault detection of wind turbines using random forests and XGBoost. IEEE Access 2018, 6, 21020–21031. [Google Scholar] [CrossRef]
- Lang, M.; Binder, M.; Richter, J.; Schratz, P.; Pfisterer, F.; Coors, S.; Au, Q.; Casalicchio, G.; Kotthoff, L.; Bischl, B. mlr3: A modern object-oriented machine learning framework in R. J. Open Source Softw. 2019, 4, 1903. [Google Scholar] [CrossRef]
- Fisher, A.; Rudin, C.; Dominici, F. All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. [Google Scholar]
- Bao, Y.D.; Mi, C.X.; Wu, N.; Liu, F.; He, Y. Rapid classification of wheat grain varieties using hyperspectral imaging and chemometrics. Appl. Sci. 2019, 9, 4119. [Google Scholar] [CrossRef]
- Hu, X.W.; Yang, L.Z.; Zhang, Z.X. Non-destructive identification of single hard seed via multispectral imaging analysis in six legume species. Plant Methods 2020, 16, 116. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.Z.; Zhang, Z.X.; Hu, X.W. Cultivar discrimination of single alfalfa (Medicago sativa L.) seed via multispectral imaging combined with multivariate analysis. Sensors 2020, 20, 6575. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.L.; Liu, F.; He, Y.; Li, X.L. Application of hyperspectral imaging and chemometric calibrations for variety discrimination of maize seeds. Sensors 2012, 12, 17234–17246. [Google Scholar] [CrossRef] [PubMed]
- Galletti, P.A.; Carvalho, M.E.A.; Hirai, W.Y.; Brancaglioni, V.A.; Arthur, V.; Barboza da Silva, C. Integrating optical imaging tools for rapid and non-invasive characterization of seed quality: Tomato (Solanum lycopersicum L.) and carrot (Daucus carota L.) as study cases. Front. Plant Sci. 2020, 11, 577851. [Google Scholar] [CrossRef]
- Yu, Z.Y.; Fang, H.; Zhangjin, Q.N.; Mi, C.X.; Feng, X.P.; He, Y. Hyperspectral imaging technology combined with deep learning for hybrid okra seed identification. Biosyst. Eng. 2021, 212, 46–61. [Google Scholar] [CrossRef]
- Pang, L.; Wang, J.H.; Men, S.; Yan, L.; Xiao, J. Hyperspectral imaging coupled with multivariate methods for seed vitality estimation and forecast for quercus variabilis. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 245, 118888. [Google Scholar] [CrossRef]
- Taylor, J.; Chiou, C.-P.; Bond, L.J. A methodology for sorting haploid and diploid corn seed using terahertz time domain spectroscopy and machine learning. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2019; p. 080001. [Google Scholar]
- Klukkert, M.; Wu, J.X.; Rantanen, J.; Carstensen, J.M.; Rades, T.; Leopold, C.S. Multispectral UV imaging for fast and non-destructive quality control of chemical and physical tablet attributes. Eur. J. Pharm. Sci. 2016, 90, 85–95. [Google Scholar] [CrossRef]
- Park, H.; Crozier, K.B. Multispectral imaging with vertical silicon nanowires. Sci. Rep. 2013, 3, 2460. [Google Scholar] [CrossRef]
- Sendin, K.; Manley, M.; Williams, P.J. Classification of white maize defects with multispectral imaging. Food Chem. 2018, 243, 311–318. [Google Scholar] [CrossRef]
- Liu, N.F.; Townsend, P.A.; Naber, M.R.; Bethke, P.C.; Hills, W.B.; Wang, Y. Hyperspectral imagery to monitor crop nutrient status within and across growing seasons. Remote Sens. Environ. 2021, 255, 112303. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | Cultivar | Origin | Moisture Content (%) | Harvest Year | Storage Temperature (°C) |
|---|---|---|---|---|---|
| M. falcata | Tenggeli | China | 6.26 | 2020 | 25 |
| M. varia | Caoyuan No.3 | China | 5.40 | 2020 | 25 |
| M. sativa | Zhongmu No.1 | China | 5.12 | 2019 | 25 |
| Level | Models | Optimization Range of Partial Hyperparameters | Tuned Hyperparameters |
|---|---|---|---|
| Basic models | SVM | kernel = [‘polynomial’, ‘linear’, ‘sigmoid’, ‘radial’]; cost = [0:5] | kernel = ‘polynomial’; cost = 2.746 |
| GLMNET | α = [0:1] | α = 0.346 | |
| XGBoost | booster = [‘gbtree’, ‘gbliner’, ‘dart’]; η = [0:0.5]; nrounds = [1:20, tags = ‘budget’] | booster = ‘gblinear’; η = 0.408; nrounds = 11 | |
| Meta-learner | XGBoost | Booster = [‘gbtree’, ‘gbliner’, ‘dart’]; η = [0:0.5]; nrounds = [1:20, tags = ‘budget’] | Booster = ‘gblinear’; η = 0.424; nrounds = 5 |
| Prediction | Reference | Total | |||
|---|---|---|---|---|---|
| M. falcata | M. sativa | M. varia | |||
| Training | M. falcata | 140 | 0 | 0 | - |
| (n = 140) | M. sativa | 0 | 140 | 0 | - |
| M. varia | 0 | 0 | 140 | - | |
| Accuracy | 1.00 | 1.00 | 1.00 | 1.00 | |
| Sensitivity | 1.00 | 1.00 | 1.00 | 1.00 | |
| Specificity | 1.00 | 1.00 | 1.00 | 1.00 | |
| Precision | 1.00 | 1.00 | 1.00 | 1.00 | |
| Testing | M. falcata | 59 | 0 | 0 | 59 |
| (n = 60) | M. sativa | 0 | 60 | 0 | 0 |
| M. varia | 1 | 0 | 60 | 1 | |
| Accuracy | 0.99 | 1.00 | 1.00 | 1.00 | |
| Sensitivity | 0.98 | 1.00 | 1.00 | 0.99 | |
| Specificity | 1.00 | 1.00 | 0.99 | 1.00 | |
| Precision | 1.00 | 1.00 | 0.98 | 0.99 | |
| CV | Accuracy | 0.99 ± 0.01 | 1.00 ± 0.00 | 0.98 ± 0.02 | 0.98 ± 0.02 |
| (n = 140) | Sensitivity | 0.98 ± 0.02 | 1.00 ± 0.00 | 1.00 ± 0.00 | 0.98 ± 0.02 |
| Specificity | 1.00 ± 0.00 | 1.00 ± 0.00 | 0.98 ± 0.02 | 0.99 ± 0.01 | |
| Precision | 1.00 ± 0.00 | 1.00 ± 0.00 | 0.98 ± 0.02 | 0.98 ± 0.02 | |
| Prediction | Reference | Total | |||
|---|---|---|---|---|---|
| M. falcata | M. sativa | M. varia | |||
| Training | M. falcata | 140 | 0 | 0 | - |
| (n = 140) | M. sativa | 0 | 137 | 2 | - |
| M. varia | 0 | 3 | 138 | - | |
| Accuracy | 1.00 | 0.99 | 0.99 | 0.99 | |
| Sensitivity | 1.00 | 0.98 | 0.99 | 0.99 | |
| Specificity | 1.00 | 0.99 | 0.99 | 0.99 | |
| Precision | 1.00 | 0.99 | 0.98 | 0.99 | |
| Testing | M. falcata | 59 | 0 | 1 | - |
| (n = 60) | M. sativa | 1 | 55 | 8 | - |
| M. varia | 0 | 5 | 51 | - | |
| Accuracy | 0.99 | 0.92 | 0.90 | 0.94 | |
| Sensitivity | 0.98 | 0.92 | 0.85 | 0.92 | |
| Specificity | 0.99 | 0.93 | 0.96 | 0.96 | |
| Precision | 0.98 | 0.92 | 0.91 | 0.92 | |
| CV | Accuracy | 0.99 ± 0.01 | 0.93 ± 0.05 | 0.92 ± 0.05 | 0.91 ± 0.05 |
| (n = 140) | Sensitivity | 0.99 ± 0.02 | 0.9 ± 0.11 | 0.90 ± 0.10 | 0.91 ± 0.05 |
| Specificity | 0.99 ± 0.01 | 0.96 ± 0.04 | 0.95 ± 0.04 | 0.96 ± 0.02 | |
| Precision | 0.97 ± 0.02 | 0.93 ± 0.07 | 0.90 ± 0.07 | 0.92 ± 0.05 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, Z.; Sun, M.; Ou, C.; Sun, S.; Mao, C.; Hong, L.; Wang, J.; Li, M.; Jia, S.; Mao, P. Single Seed Identification in Three Medicago Species via Multispectral Imaging Combined with Stacking Ensemble Learning. Sensors 2022, 22, 7521. https://doi.org/10.3390/s22197521
Jia Z, Sun M, Ou C, Sun S, Mao C, Hong L, Wang J, Li M, Jia S, Mao P. Single Seed Identification in Three Medicago Species via Multispectral Imaging Combined with Stacking Ensemble Learning. Sensors. 2022; 22(19):7521. https://doi.org/10.3390/s22197521
Chicago/Turabian StyleJia, Zhicheng, Ming Sun, Chengming Ou, Shoujiang Sun, Chunli Mao, Liu Hong, Juan Wang, Manli Li, Shangang Jia, and Peisheng Mao. 2022. "Single Seed Identification in Three Medicago Species via Multispectral Imaging Combined with Stacking Ensemble Learning" Sensors 22, no. 19: 7521. https://doi.org/10.3390/s22197521
APA StyleJia, Z., Sun, M., Ou, C., Sun, S., Mao, C., Hong, L., Wang, J., Li, M., Jia, S., & Mao, P. (2022). Single Seed Identification in Three Medicago Species via Multispectral Imaging Combined with Stacking Ensemble Learning. Sensors, 22(19), 7521. https://doi.org/10.3390/s22197521