1. Introduction
The extensive use of geolocation devices allows for the collection of a large volume of data from the trajectories of moving objects. Many machine learning tasks can benefit from this kind of data, such as real-time mobility events’ monitoring (e.g., detecting typical traffic flows, predicting traffic jams, or predicting the next location in road networks).
The challenge of determining the next important location of a moving object based on previous trajectories is known as location prediction (or trajectory prediction). Location prediction has drawn the researchers’ interest in recent years due to its various practical applications, including traffic management, police patrol, and tourism recommendation. This paper tackles the problem of learning how trajectories are represented for location prediction in the context of external, fixed, and sparse on-road sensors (e.g., traffic surveillance cameras) to capture vehicles’ trajectories.
Representation learning is an essential concept in machine learning, transforming input data into a useful format using a learning algorithm. Representation learning for trajectory modeling is concerned with building statistical or machine learning models of the observed trajectories of vehicles or people. Such models may have different uses: computing the probability of observing a given trajectory for anomaly detection [
1]; estimating the importance of different characteristics that drivers may consider relevant when following a trajectory; recovering sparse or incomplete trajectories, such as those observed from external sensors [
2]; aiding drivers in choosing an optimal route from an origin to a destination; the online prediction of the next location of a vehicle given its current location, [
3] which is the application studied in this paper.
We evaluate representation learning methods to generate the feature space and predict the next vehicle movement, which will allow for the displacement of a vehicle among the video surveillance cameras to be predicted. In contrast with most early research, we forecast the next movement of objects as external sensors on the road network record their positions. It is possible to determine the trajectories of the moving objects as a sequence of sensor positions, assuming that each sensor record contains sufficient information to uniquely identify the associated moving object, such as identifying vehicles by their license plates.
In Natural Language Processing (NLP), many works [
4,
5,
6,
7,
8] have proposed representation learning models based on neural networks to extract the features of words, or sentences, from their sequential order of words, while maintaining their semantic meaning. We take inspiration from NLP word representation methods that model the semantics of a word and its similarity with other words, by observing the many contexts of the word’s use in the language. Geometric distances between word vectors reflect semantic similarities and difference vectors encode semantic and syntactic relations [
9].
Thus, we aim to investigate the following research questions:
RQ1: Could NLP embedding models, more specifically, language models and word embeddings, be used to represent the vector space of trajectories in location prediction tasks using recurrent architectures?
RQ2: Are the representations of sensors/locations from representation models in NLP able to capture their context, i.e., the closest sensors/locations, both in terms of road distance and connectivity?
RQ3: Could trajectory representations from NLP embedding models adequately capture trajectories’ similarities?
State-of-the-art papers include the adoption of neural embeddings for model locations, points of interest (PoIs) [
10,
11,
12] or to learn the temporal interactions between users and items [
13]. The papers [
14,
15,
16] also focus on the next location prediction task from trajectories obtained by external sensors and assume that a road network constrains object movements. Their trajectories report predefined positions (i.e., sensors’ location) on the road network, which makes trajectories much more sparse than the usual GPS raw trajectories. Thus, the location prediction is different from (i) the papers that consider GPS trajectories, which occur in continuous locations [
3,
17], and (ii) the next stop location prediction, which is usually applied to points of interest or event places as [
18,
19,
20,
21], since the prediction involves movement rather than stops. In addition, none of the previous works investigated whether the embedding encoders leverage the location prediction models or how the embedding space represents the spatial relationships between the sensors and the trajectory’s similarities.
The rest of this article is structured as follows.
Section 2 explains the main concepts needed to understand this paper.
Section 3 introduces the related work.
Section 4 discusses the data, the NLP methods for obtaining embedding vectors, and the next location prediction architecture we used to achieve our goals.
Section 5 presents and discusses the experimental evaluation.
Section 6 concludes this work and suggests future developments.
2. Preliminaries
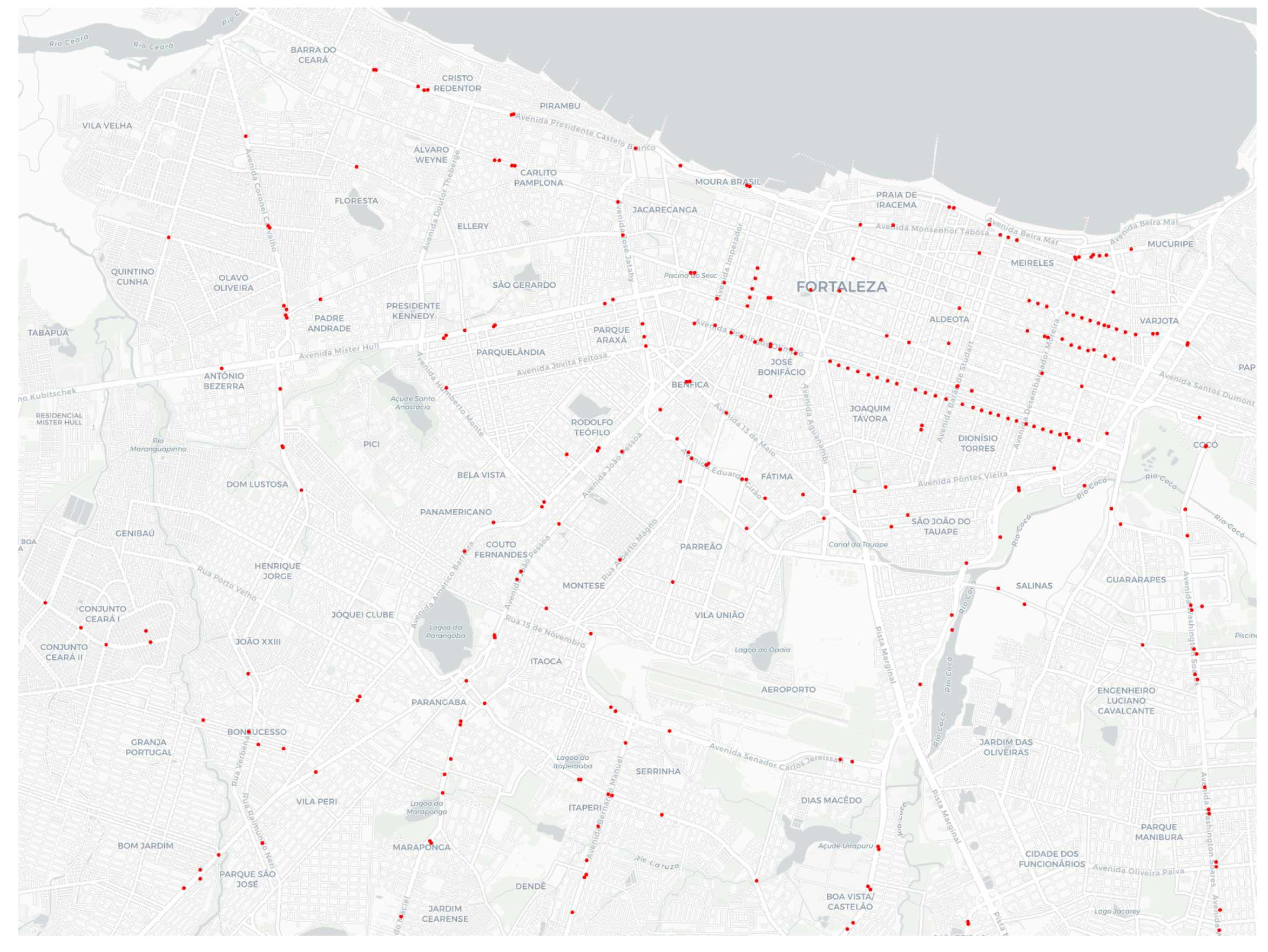
The Public Security Secretariat and Social Defense (SSPDS, acronym in Brazilian Portuguese ) of the state of Ceará, in Brazil, has developed the Approach Police System (SPIA, acronym in Brazilian Portuguese) to deal with the mobility of criminals. SPIA uses the video surveillance system and teams of police actions, especially motorcycle patrol. SPIA processes the data obtained by cameras equipped with a license plate recognition (LPR) system in real-time. SPIA checks whether each captured vehicle plate is related to a declared theft. If so, it informs the Integrated Police Operation Center (CIOPS, acronym in Brazilian Portuguese), where a vehicular approach police action is executed. Next, CIOPS operators plann how to approach the stolen vehicle through a visual examination of the video-monitoring cameras scattered around the city. Implemented in 2017, SPIA has led to a 48% reduction in vehicle theft actions in the state of Ceará.
Figure 1 depicts a map of Fortaleza and its metropole region, with the surveillance cameras (red points) used by SPIA in 2019 plotted on that map. Despite the efficiency of SPIA, one of the most complex activities is predicting the trajectory of vehicle movement. At present, this is carried out manually, with several police agents simultaneously checking the video monitoring cameras. The modus operandi also requires the availability of several police vehicles scattered throughout the city, which must be dedicated to the service in question. Consequently, this current mode of operation is costly and subject to errors.
This paper considers the context in which trajectories are obtained from external sensors placed at fixed positions on roadsides, such as the ones collected by the SPIA. The moving objects have a unique identifier, for example, a vehicle’s license plate. The external sensors on the road network register the passage of moving objects.
Sensors may fail to capture the license plate and then produce incomplete trajectories with missing observations [
14,
15]. Furthermore, sensors are spatially sparse and not equally distributed, producing sparse trajectories.
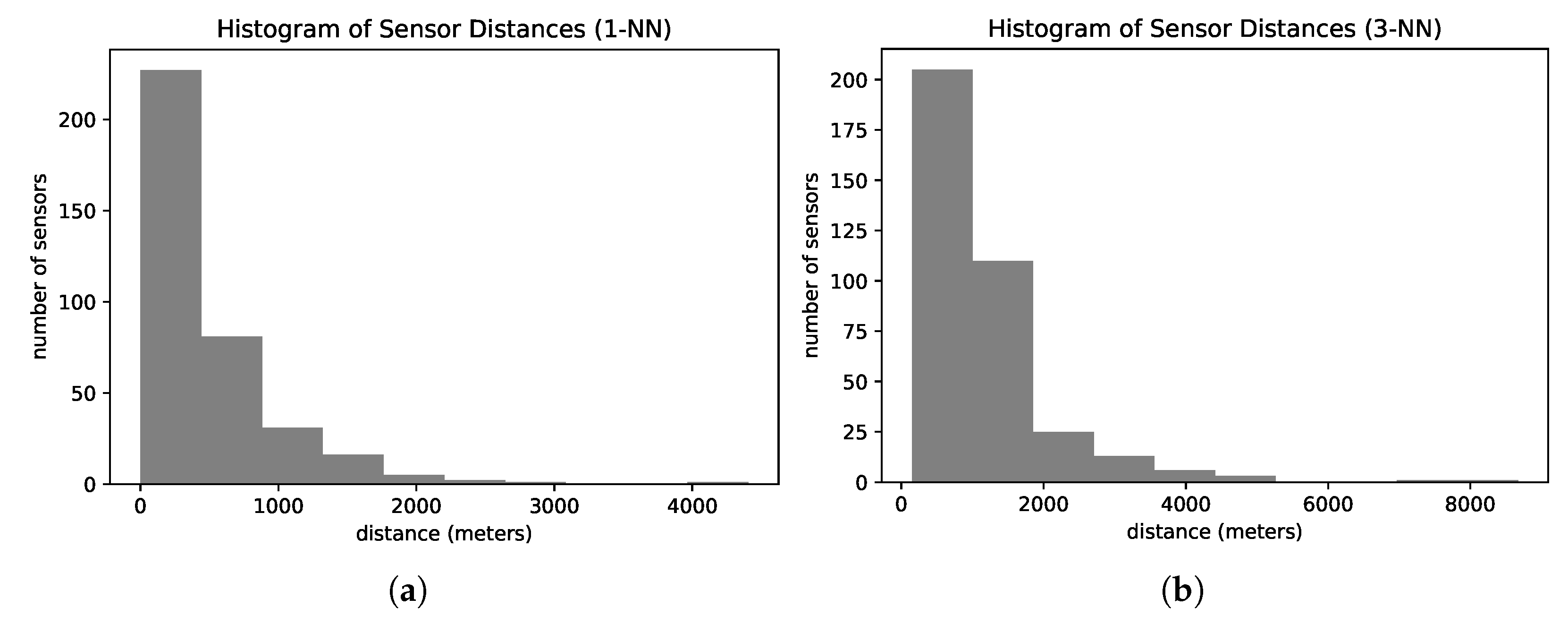
Figure 2 presents the histogram of road distances from one sensor to the nearest sensor (
Figure 2a) and the third nearest sensor (
Figure 2b) of our dataset. On average, the sensors are 440 m apart from their nearest neighbor. The nearest sensor is at least 600 m away from more than 25% of the sensors. Analyzing the distances between the third closest sensors, more than 40% of all sensors have their top three closest sensors located more than one kilometer away.
We present some definitions to support our problem statement in the same way as in our previous work [
14,
16].
Definition 1 (Trajectory). A trajectory is a function , that returns the location of a moving entity at a given time t. In other words, it is a finite set of chronologically sequenced points . , where is the spatial information, latitude and longitude, where the object was at time t.
Definition 2 (External Sensor Observation). When the sensor registers a vehicle’s passage, it produces the tuple where m is the identifier of the moving object, s is the sensor identifier, and t is a timestamp.
Definition 3 (External Sensor Trajectory). Let O be the set of observations generated by a set of sensors S. Let be the set of observations related to the moving object m. We define an External Sensor Trajectory (EST) of a moving object as the sequence of observations , such that and .
Now, we can define the problem that this paper tackles.
Definition 4 (EST Prediction). Let G be the street network, S be the set of external sensors implanted on G, O be the set of historical observations produced by S, and be the set of historical trajectories derived from O. Given the latest n observations of a driver m, , the problem consists of predicting the next sensor, , that is to be visited by m.
In general terms, the problem is predicting the next sensor from a given partial trajectory. The research questions presented in the last section that guides this work focus on investigating the natural language models to represent the trajectory sensors and exploring whether the prediction model improves.
We can observe a substantial similarity between natural language and EST. First, natural language and EST can be approximated by context. Given the context, we can predict the next word in the natural language.
Likewise, a road network constraints the movement of drivers, so their observation only occurs at fixed (predefined) positions (i.e., sensors’ location) on the road network. Thus, given a sequence of external sensors crossed by a driver, we can predict the next sensor on the driver’s trajectory.
Both domains can be viewed as time-dependent series. Regardless of the language, the dictionary can provide multiple choices that could succeed a word in a sentence. Likewise, there are various choices of paths in the driver’s trajectory; therefore, there are multiple possibilities for external sensors’ observation.
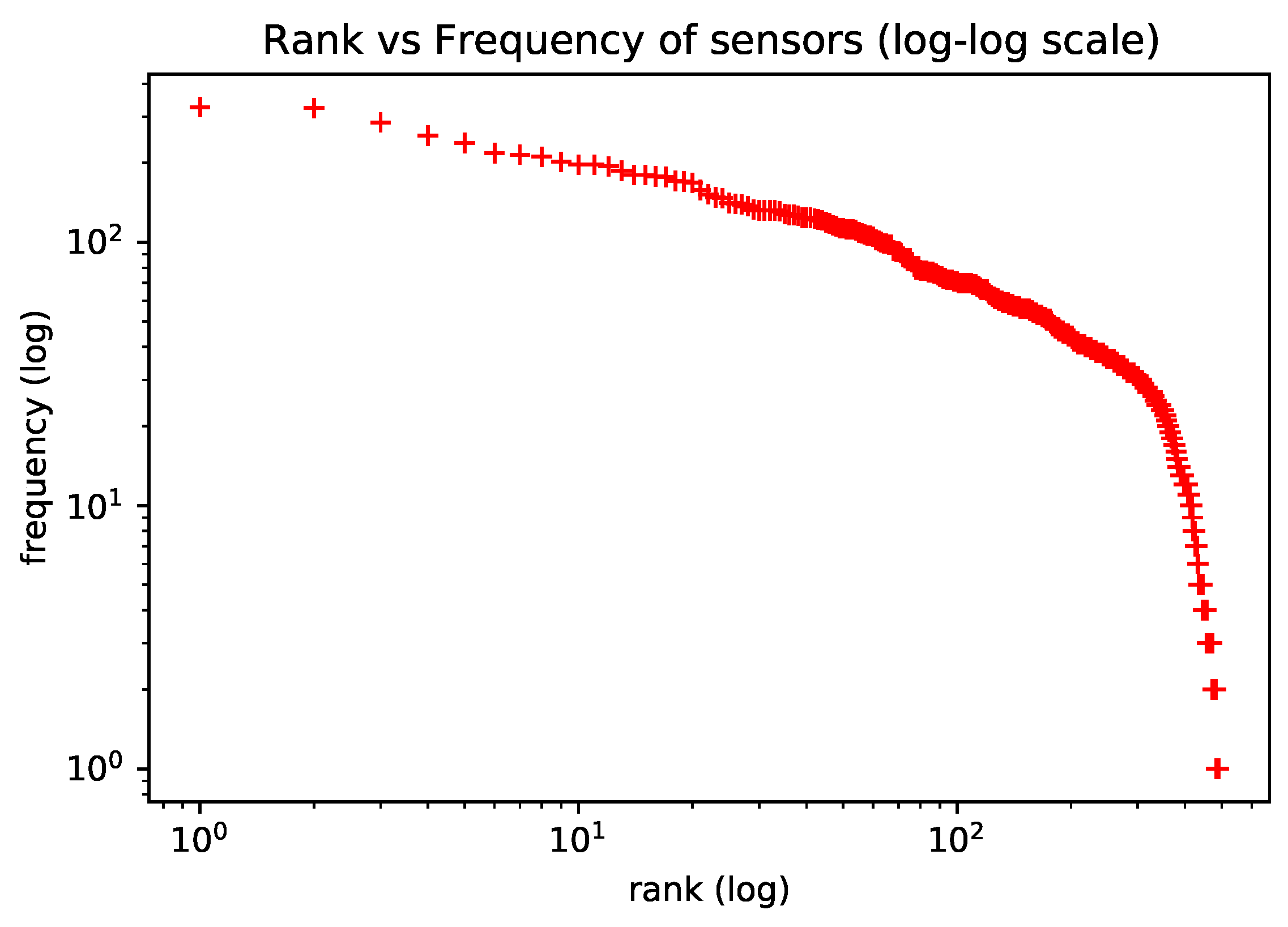
To motivate the use of natural language models in the representation learning of trajectory sensors, we verify that the frequency of trajectory sensors approximately follows a Zipf Law. The Zipf Law controls the word frequency distribution in natural language [
22]. In [
10], the authors observed the same Zipf’s Law behavior on human mobility habits and used this analogy to apply natural language models to learning representation for living habits.
Figure 3 (observed in the dataset utilized in our experiments) shows the distribution of sensor observations, which roughly follow Zipf’s Law, as expected. In the plot, axis
y is the frequency with which each sensor appears in trajectories; axis
x is the frequency rank, where rank
k is the kth most frequent sensor.
4. Data and Methods
This section explains the methodology used in this work to investigate the use of representation learning architectures for NLP on external sensors’ trajectories.
Firstly, we represented the trajectories as sequences of sensor labels. Since we want to evaluate these methods’ potential to capture the spatial representation, we discarded the temporal feature. We labelled each sensor using a geocode hash function applied to its geolocation.
Then, we trained a text representation learning model to learn a representation of the labels’ sensors. Mapping these to the text representation, we considered one sensor label as one word, a trajectory as a text, and the set of trajectories as the corpus of documents. The output of this step is a set of embedding vectors, with each one representing a sensor label.
We hypothesized that the vector embedding captured a relationship between sensors, such as spatial proximity or frequent use together. We experimented with the embedding vectors using different embedding models from NLP, such as Word2Vec [
4] and BERT [
28].
4.1. Data Preparation
We used the same dataset and pre-processing steps as in our previous work [
16]. The trajectory data came from a real traffic monitoring application, which had 489 sensors monitoring vehicles at Fortaleza city in Ceará, Brazil. The dataset contained 2990 stolen vehicles and 22,530 sensor observations collected from January 2019 to June 2019. Each record included the vehicle license plate, timestamp, latitude, longitude, and speed. We used the sensor’s location to infer its identification.
We segmented the trajectories in order to identify trips. Firstly, the trajectories were segmented by day, where the points from the same vehicle on the same day comprised one trajectory. Using the results of this segmentation, we computed the average time and standard deviation of the time that elapsed between successive observations. Then, when the displacement time between two consecutive sensors was longer than the average time plus two standard deviations, we applied another segmentation in the daily trajectories. Finally, we only maintained trajectories bigger than two records in the dataset.
We assumed that drivers generally prefer the shortest path between two locations [
15]. Therefore, we completed the transitions between two consecutive sensors according to the shortest path. In other words, if sensor
appears after sensor
in a trajectory, we assumed that all sensors on the shortest path from
to
were missing sensors; thus, we completed the trajectory considering these sensors.
Like in [
11,
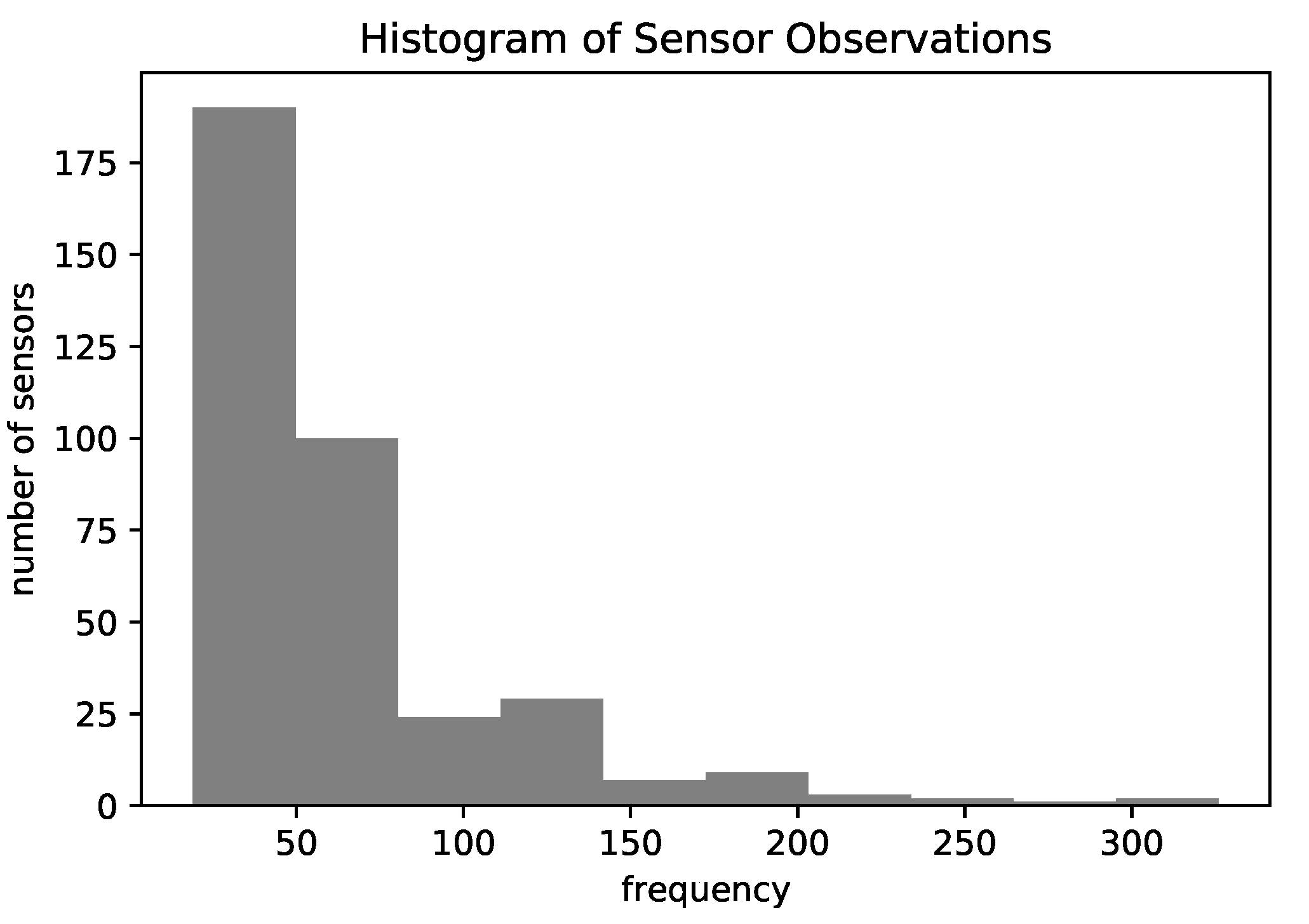
16], we kept only the representative locations and discarded the sensors that occurred at less than the 25th percentile of frequency (18 observations) which may not be significant for global patterns. After applying this filter, the total number of sensors was 369.
Figure 4 shows a histogram of the number of observations for each sensor in the final data, which depicts the unbalance between sensors’ frequencies. Finally, we evaluated the models using the holdout 80–20 approach, where we randomly chose 80% of trajectories for training and 20% for the test.
4.2. Embedding Models
Here, we briefly explain the NLP methods that were applied to generate the embeddings. In this work, the pre-trained embeddings are used to represent sensors in the location prediction task.
Word2Vec is a representation learning framework for words based on feedforward neural networks. Word2Vec presents two main architectures: the Continuous Bag-of-Words (CBOW) Model and the Continuous Skip-gram Model. In both architectures, word vectors are trained based on a slide window of n-grams on the corpus, such as . The CBOW predicts the current word based on the window context . The Skip-gram predicts surrounding words given the current word . The main drawback of Word2Vec is that it is trained on a separate local context window instead of a global context.
The transformers architecture [
35] introduced the self-attention mechanism, a sequence model that is able to create an embedding space of words that provides token representations based on the representation of the more relevant tokens in the sequence. BERT [
28] is a multi-layer transformer encoder. that was proposed to mitigate the unidirectionality constraint of its previous language models. Unidirectionality implies that the model can only access the previous tokens in the self-attention Transformer layers. Contrary to unidirectionality, BERT creates an embedding space of words, considering both the left and right contexts.
The pre-trained word representations of BERT can be obtained using two different tasks, a masked language model (MLM), or a next sentence prediction. The MLM model randomly masks a percentage of the input tokens in the sequence. During training, the goal is to predict the masked tokens on the sequence based on their left and right contexts. This step results in the pre-trained representations for the tokens in a specific vocabulary. Word2Vec and BERT MLM are the solutions that were investigated in our experiments to learning sensor representations.
4.3. EST Prediction Model
Recurrent Neural Networks (RNN) [
36] compose a class of neural networks that work on sequences of arbitrary lengths. Sequential data, such as trajectories, has a particular characteristic, where the order in which the instances appear in the sequence matters. Unlike Multilayer Perceptron (MLP), neural networks. which process each data input independently of the previous piece, RNNs can remember previous information in the sequence and update the network weights considering this past information. A Long Short-Term Memory Network (LSTM) [
37] is an RNN tat is designed to overcome the vanishing and exploding gradient problem in vanilla RNN. An LSTM comprises several memory cells, with each one defining a hidden layer. A memory cell has a recurrent edge with a value associated with it, called a cell state.
The EST prediction model investigated, which was also based on the previous papers [
14,
15,
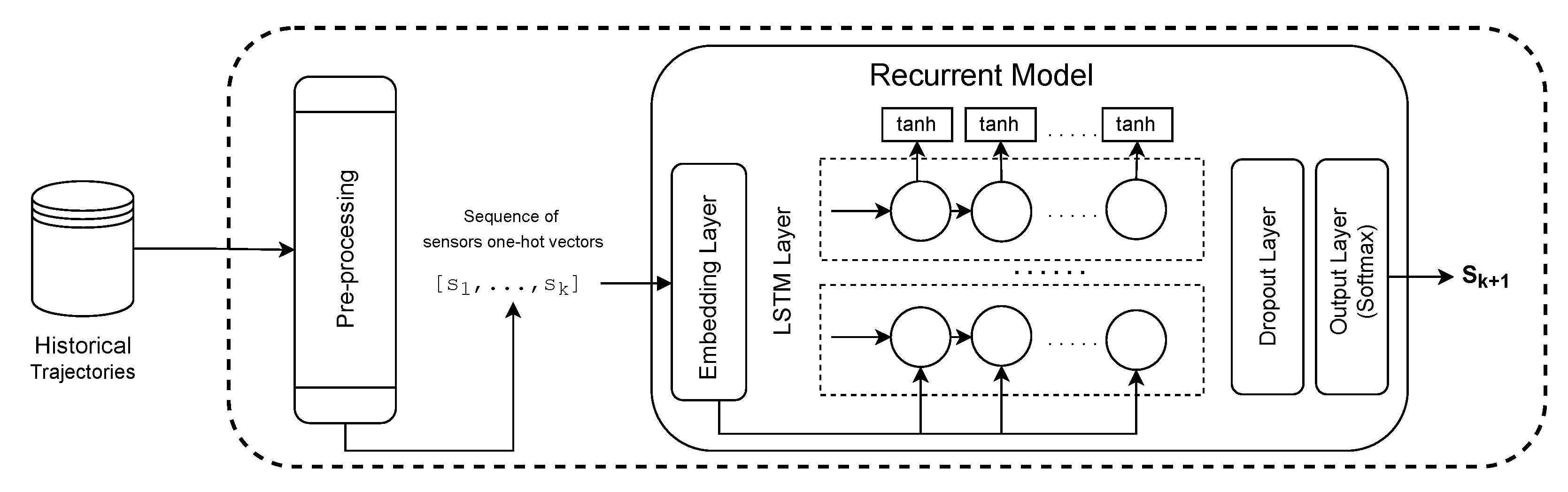
16] is a recurrent based model. The first layer (1) is an Embedding Layer, which applies a linear transformation on the high-dimensional input vectors to reduce their dimensionality while trying to preserve the similarity between instances from the original space of features in the new feature space. The original representation of the input in our problem is the one-hot encoding representation, in which the dimensionality of the vectors is the number of existent sensors. A one-hot encoding represents categorical values as binary vectors, where all values are zero except the index of the categorical input, which is marked as one. The parameters of the embedding layer can be trained (or tuned) while training the other parameters in the neural network for the following location prediction or can be pre-trained using a representation learning model. The output of the embedding layer is sent to (2) a LSTM Layer, which is able to learn the moving patterns from the sensor sequence. In sequence, we have (3) a Dropout Layer, to help to prevent overfitting problems by randomly hiding some input units at each iteration of the training phase. Moreover, (4) an Output Layer is a fully connected layer. The activation function of the output layer is the Softmax. The Softmax function converts the output into a vector that indicates the probability of each sensor being the target.
Figure 5 shows the EST prediction architecture that was utilized in our experiments.
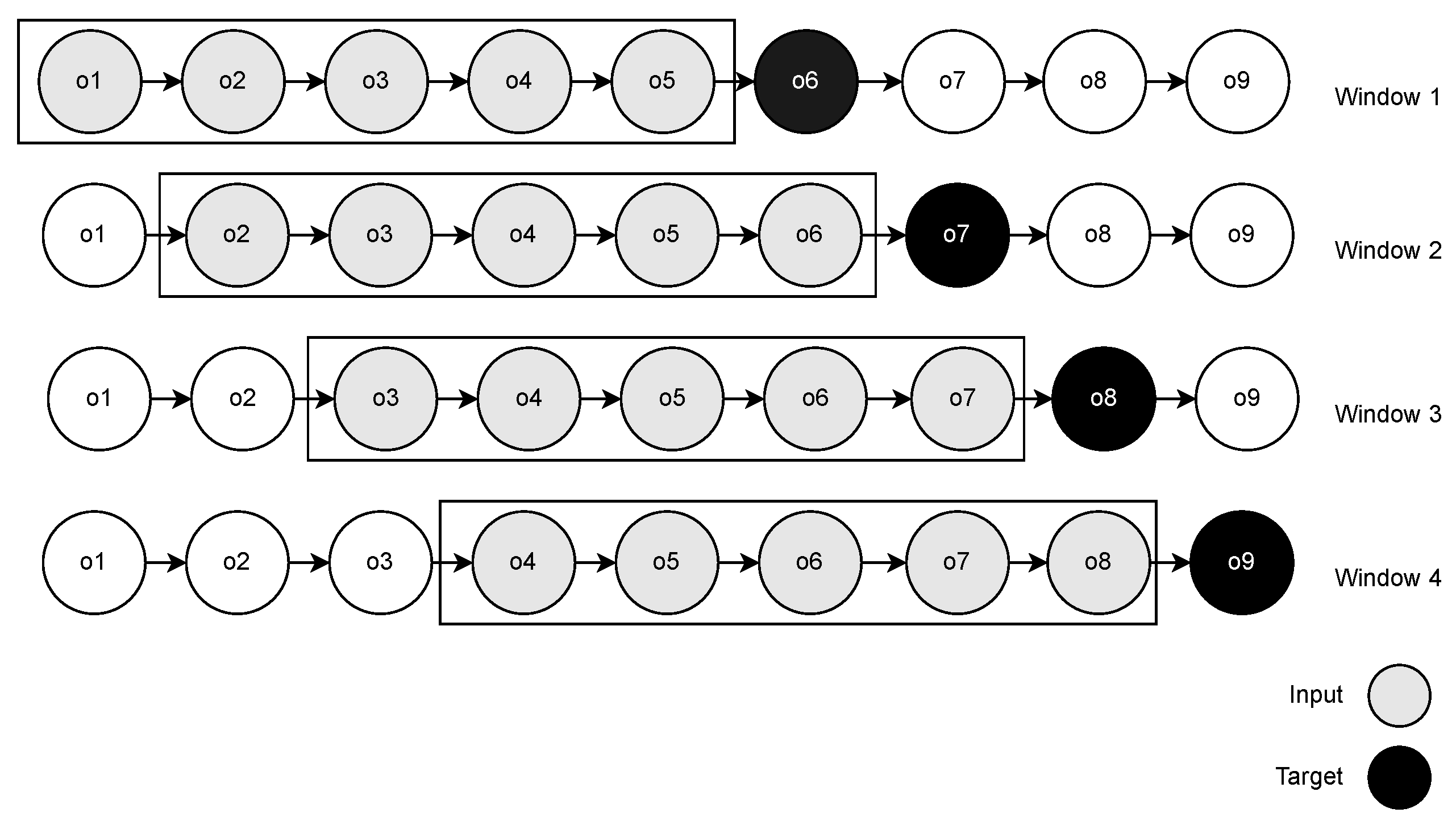
Our EST prediction model received fixed-length sub-trajectories corresponding to the last
w sensors that were observed. Thus, we used the sliding window strategy in the training step to convert the trajectories into fixed-length sensor sequences. In the sliding window (
Figure 6), we scanned the entire trajectory by moving a window one position forward at each iteration. We began the window with the first sensor observation and retrieved the
sensors in the window as features (
) and the first sensor outside the window,
, as the target. Iteratively, we moved the window and repeated the process until we found the last position in the trajectory.
5. Experimental Evaluation
From here, we conducted our research by splitting it into three sets of experiments: (i) Analysis of Location Prediction—investigate whether NLP models have the potential to model the vectorial space of features for location prediction; (ii) Analysis of Sensor Embeddings—investigate whether sensor embeddings obtained from NLP models can capture the relationship between sensor locations; (iii) Analysis of Trajectory Embeddings—investigate whether the trajectory embeddings obtained from NLP models can capture the behavior of the whole trajectory.
5.1. Analysis of Location Prediction
In this section, we conducted experiments to examine the research question RQ1: Could NLP embedding models, more specifically, language models and word embeddings, be used to represent the vector space of trajectories in location prediction tasks using recurrent architectures?
To extract the embedding representation of sensors, we evaluated both BERT MLM and Word2Vec. The embedding of words from NLP models was used as the embedding layer on top of the LSTM-based model (as shown in
Figure 5) to predict the next location. The LSTM-based model was evaluated with and without fine-tuning on the embedding layer. The fine-tuning adjusts the weights of the embedding layer on the training step for one specific task (location prediction in our case). We also evaluated the pure LSTM model as a baseline, i.e., LSTM with an embedding layer that was trained from zero.
In BERT MLM, part of the trajectory sensors is masked, and the model is trained to predict the masked sensors considering the unmasked ones.
We propose applying a simple data augmentation strategy that works with a masked model. We replicated the training dataset a number of
times. As in [
28], we randomly chose the masked 15% of sensors on each replicated sample. In the case of Word2Vec, we applied CBOW architecture. The variation in hyper-parameters of BERT MLM and Word2Vec are shown in
Table 1.
For the Word2Vec model, we varied the parameters (
Table 1) and trained one EST prediction model using the embeddings obtained by each parameter configuration of Word2Vec. We reported the result for the configuration that acheived the best accuracy in the EST prediction model. For BERT MLM, we masked the last sensor in the validation data and collected the accuracy for each BERT MLM configuration. We trained an LSTM using the configuration that reported the best BERT MLM accuracy.
Using the pre-trained embeddings, we trained LSTM models to predict the next sensor given the previous m (we varied m according to the set [5, 7, 15, 31]; when m = 5, the model outperforms others) observed sensors on the same trajectory. The models were evaluated using ACC@N and closeness_error metrics. The ACC@N measures the percentage of instances where the correct prediction was among the N most probable outputs according to the estimation given by the model, using the softmax activation. The closeness_error is the road network distance between the predicted sensor and the expected one.
Models. Concerning the models in our work, we considered the following configurations: (i) LSTM, where the embedding layer was trained from scratch on the prediction task; (ii) LBERT, where the LSTM usined the pre-trained embeddings of BERT MLM as an embedding layer; (iii) LBERT-FT, where the pre-trained BERT embedding layer was fine-tuned under the next sensor prediction task; (iv) LW2V, where the LSTM used the pre-trained embeddings of Word2Vec as an embedding layer; (v) LW2V-FT, where the pre-trained Word2Vec embedding layer was fine-tuned under the next sensor prediction task. Furthermore, we only report the results of the better parameter configurations.
Table 2 presents the results for the best model configuration for each strategy. The best accuracy for each different window size was reported in
Appendix A. The LSTM predictor with the fine-tuned BERT embedding layer achieves the best result. The fine-tuning of the BERT-embedding layer improved the accuracy ACC@1 by up to 7%; the same behavior was found for ACC@2 and ACC@3. We believe that BERT better represents the feature space of sensors for trajectories because it learns representations by adjusting the weight of the context. In addition, the positional encoder of BERT captures sequential connexions from the road network. The masked language model of BERT also simulates and learns under the situation of missing data, where the sensor does not capture the passage of a moving object. The LSTM predictor using Word2Vec embedding reached the lowest accuracy, 52.14%, followed by its fine-tuned version. The fine-tuning of the Word2Vec embedding layer did not significantly improve the predictor. One possible reason is that Word2Vec models do not learn sequential patterns, but only the surrounding context. The baseline LSTM achieves 66% of accuracy, these results are consistent with the ones obtained by [
16].
Table 3 reports the mean and percentiles of the closeness error obtained by the models. The median and lower percentiles were omitted since, for all models, their values were zero. The mean closeness error of LBERT-FT was the best one, with a value of 0.79 km, followed by LBERT with 0.97 km and LSTM with 1 km. LW2V and LW2V-FT found the worst results, in this order. LBERT-FT obtained 80% of all predictions with errors under 1.3 km. LBERT reached a 70% lower of closeness error than 0.5 km and an 80% lower closeness than 1.6 km. We can conclude that BERT representation not only helped to increase the accuracy, but also increased the proximity between predicted and expected sensors when the predictor failed. However, with fine-tuning for location prediction tasks, BERT representations could achieve better results.
5.2. Analysis of Sensor Embeddings
These experiments are guided by the research question RQ2: Are the representations of sensors/locations from representation models in NLP that can capture their context, i.e., the closest sensors/locations, in terms of both road distance and connectivity?
Our goal is to evaluate if the spatial relationship impacts the degree of similarity of the sensor embeddings. We evaluate the relationship between spatial and embedding distances and investigate how similar embeddings reflect the spatial proximity or connectivity in the road network. To achieve this goal, we used BERT MLM, which leverages the best next-location predictor from the experiments, as explained in the previous section (
Section 5.1). BERT MLM was used to generate the embedding space of the sensors.
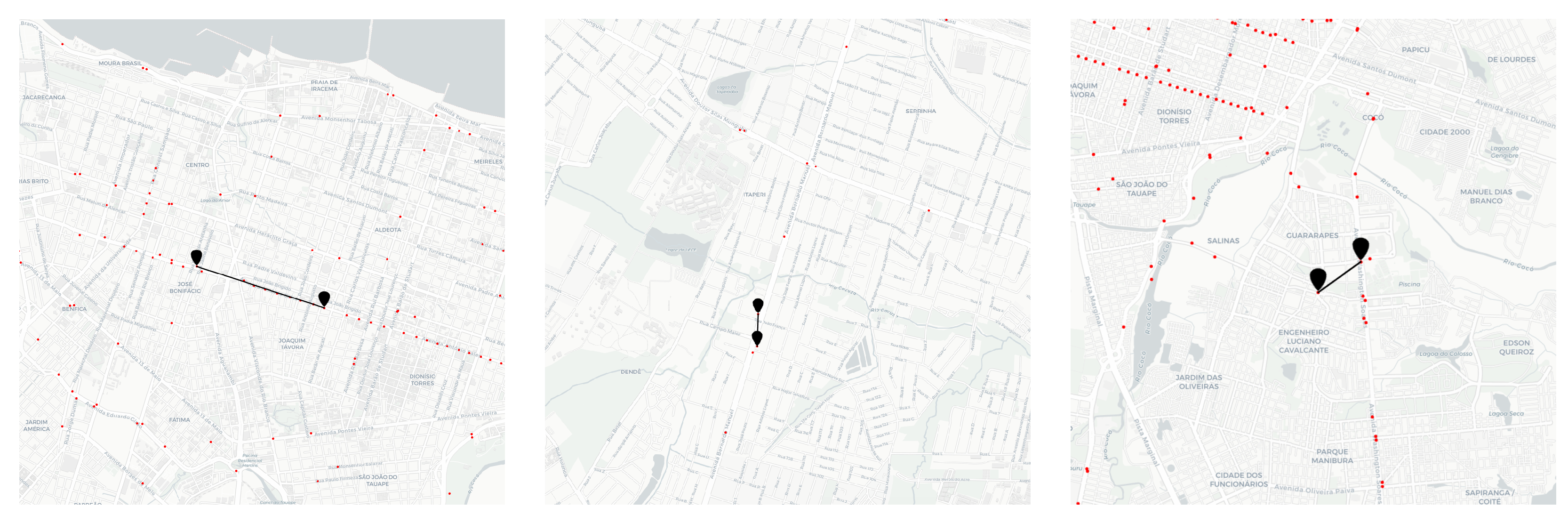
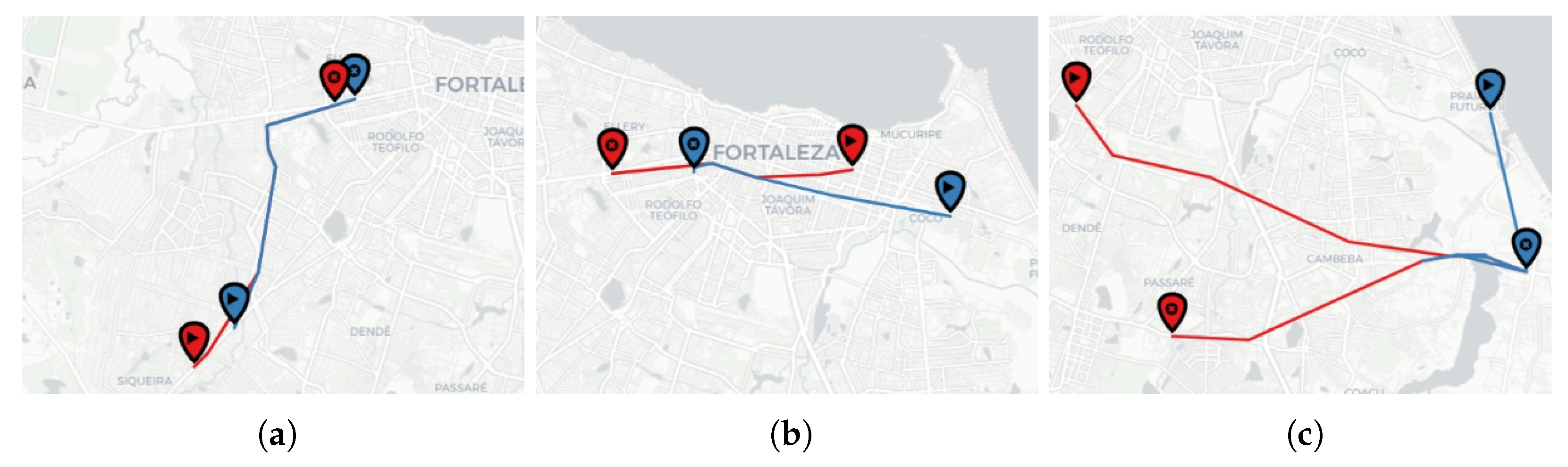
Figure 7 exemplifies the embedding vectors of sensors in a space. The points (in red) are sensors, and the markers (in black) connected by a line represent a pair of nearest sensors according to the cosine distance between their embedding vectors.
Although the nearest embedding sensors vectors from BERT MLM are not directly the closest in space, we can see, in
Figure 7, that they are seen on the roads with some connectivity and also in their spatial neighborhood. This suggests that BERT MLM could capture some spatial relationship between sensors.
To better understand the impact of spatial proximity on embedding similarity, we analyze the Mean Reciprocal Rank (MRR) of sensors concerning these metrics. In Information Retrieval, the Reciprocal Rank (RR) calculates the rank at which the first relevant document was retrieved. If the relevant document was retrieved at rank
r, then RR is
[
38]. We adapt the definition of RR measure for our particular goal (Definitions 5 and 6).
Definition 5 (Reciprocal Rank). Given a reference distance , a query distance , a query object o and a set of objects O, the reciprocal rank of o with respect to the reference distance and the query distance for the set O is , if the closest object to o, according by is at rank r according by .
In these experiments, the reference distance was set to be a spatial distance (Euclidean and road distances), while the query distance was the cosine distance between embedding vectors.
Definition 6 (Mean Reciprocal Rank). The Mean Reciprocal Rank (MRR) is the average RR across a set of query objects.
First, we collected the MRR using the Euclidean distance as , and Cosine distance as . In that case, the MRR was , which means the nearest sensor according to Euclidean distance is around the most similar on the embedding space, on average. Using the Road Network distance as and cosine distance as , MRR was , so the nearest sensor in the road network is, on average, around the most similar on the embedding space. We believe that, on average, being in the top five or six is acceptable, as we are learning a new space (embeddings) that can represent the sensors, which is not a trivial task.
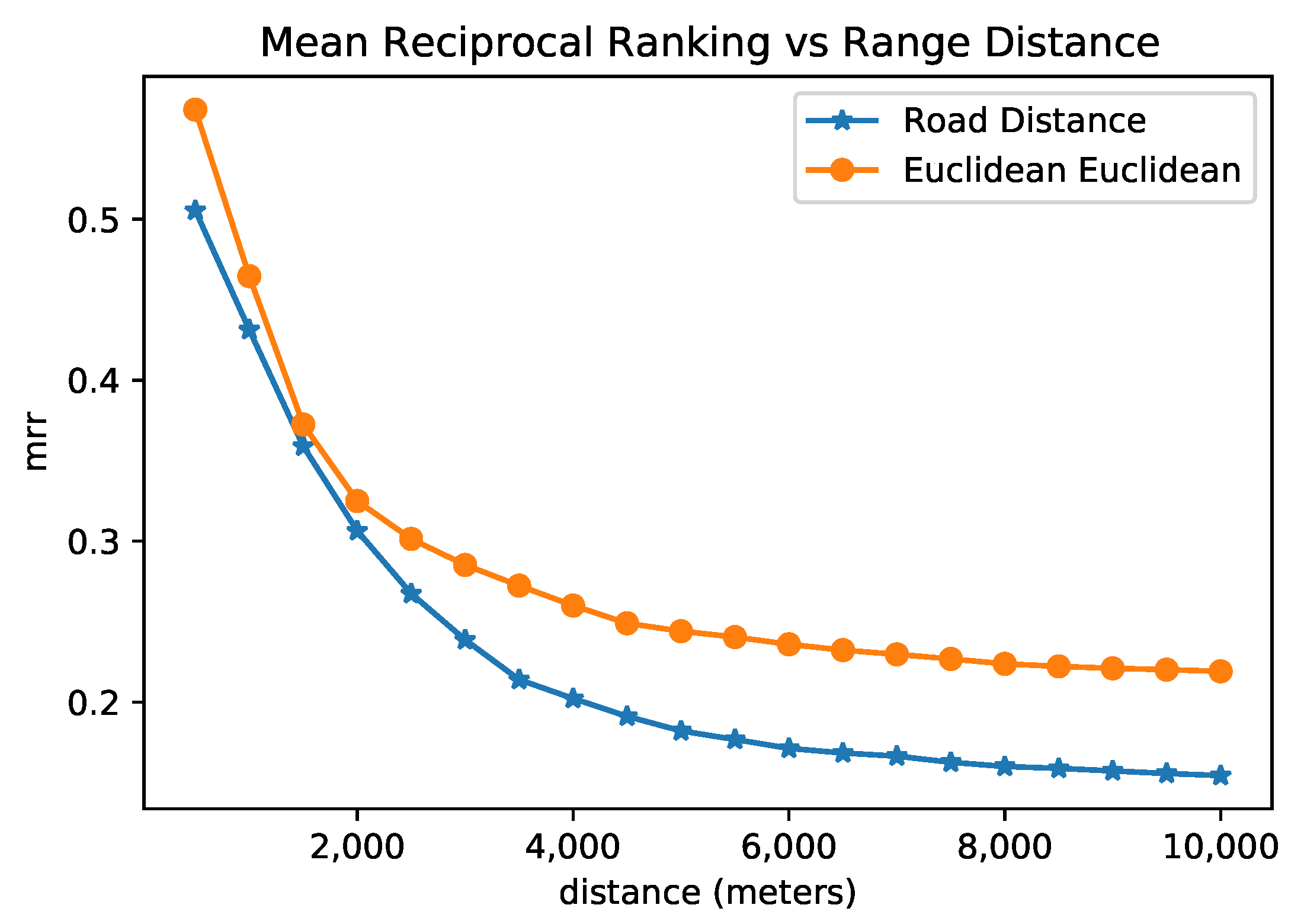
We also evaluated the variation in MRR for sensors inside a neighborhood using the following methodology. We calculate the RR for each sensor considering a spatial distance (both the Euclidean and the Road Network distances) as the reference distance and the cosine distance between the embedding vectors as the query distance. The set of sensors to be ranked (O) were filtered, leaving only the ones that were spatially close to the sensor considered as the query object, i.e., the ones that fell inside the distance range. We varied the range distance and collected the MRR according to the filtered sensors.
Figure 8 presents the result of this analysis for both Euclidean and road network distances. One can observe that, among pairs of sensors with a distance of around 1.5 km, the MRR is about 0.35, which means that the closest sensor in space was found at rank 2 or 3; when the filter of maximal distance increases, the MRR decreases. Even when the maximal distance is around 4 km for Euclidean space, the MRR is more significant than 0.25, and for the road distance of approximately 4 km, the MRR is 0.20. In other words, the rank given by the embeddings of the closest sensor is around 4 and 5 for euclidean and road distances, respectively. The embedding representation reached a rank that was slightly similar to the spatial rank for the set of sensors that are not as spatially distant. We argue that an efficient model of sensor representation does not necessarily reflect only the spatial proximity, but may also reflect the connectivity in terms of road connectivity and frequent paths. Overall, we note from the previous research question that BERT sensor embeddings achieved better results for the next location prediction task. Furthermore, the BERT embeddings tend to reflect more spatial similarity when considering the sensor’s neighborhood as limited to a distance.
5.3. Analysis of Trajectory Embeddings
In this section, we investigated the research question RQ3: Could trajectory representations from NLP embedding models adequately capture trajectories’ similarity? This was conducted by evaluating the similarity between trajectory embeddings regarding the similarity between raw trajectories.
We defined trajectory embedding as the average vector of the embedding of the sensors comprising the trajectory. As in
Section 5.2, we used BERT MLM to generate the embedding representation of sensors.
Figure 9 exemplifies different pairs of the most similar trajectories in the test set according to the cosine distance of their embedding vectors. Consider the trajectory source, the marker with a triangle, and the target, the other marker. We divided the figure into three cases: when trajectories present high, medium, and low spatial similarity.
We aim to show that the trajectory embeddings can capture the spatial likeness for some cases but not for others. A further direction to improve the embedding quality is training with more data or investigating other language models.
We evaluated the Reciprocal Rank and the Mean Reciprocal Rank (Definitions 5 and 6) between raw EST trajectories and their embeddings using the Dynamic Time Warping (DTW) and the Edit (ED) distances between raw trajectories, and also the cosine distance between embedding vectors. DTW is one of the most popular trajectory distance measures. It searches for all possible alignment points between two trajectories to find the one with minimal distance. To measure the distance between sensors, we used the Euclidean distance. ED quantifies the dissimilarities between two sequences of strings by counting the number of operations that are needed to transform one string into another. For more details about trajectory similarity functions, we refer to the survey [
39].
The experiment considers the cosine distance between trajectory embeddings as the query distance. We perform two experiments: compute the MRR using DTW as a reference distance and another one using ED as a reference distance. By using DTW as the reference distance, MRR obtained the best results, with a value of 0.44. In other words, the embedding rank for the most similar trajectory according to DTW is between 1 and 3, on average. The MRR using ED as the reference distance was 0.27. We believe that being on the top from one to three, on average, is a good result, as we are learning a new embedding space to represent trajectories, which is a complex task due to the nature of these trajectory data.
Another experiment we performed was filtering out the set of trajectories objects
O to contain only those with the reference distance under a maximal value. Similar to the analysis of sensor embeddings, we evaluated how the MRR performs on a subset of trajectories when the neighborhood increases.
Figure 10 shows the results. For the most similar trajectories pairs (DTW distance of approximately 5), the MRR was close to 5. For trajectories on the neighborhood filtered by DTW equal to 85, the MRR reached the minimum value (0.44) and remained almost constant when the neighborhood increases. This result implies that BERT MLM embeddings could capture spatial similarity and connectivity when the sensors of similar trajectories did not exactly match. The highest value of MRR using ED was 0.33, at the point at which ED was at a maximum of 10. This result implies that BERT embedding can represent the sequence of discrete location labels in a trajectory (measured by edit distance). With these experiments, we achieved our goal of using an NLP model and evaluating its quality to represent the trajectories and capture their spatial similarity.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









