

Research on Emotion Recognition Method Based on Adaptive Window and Fine-Grained Features in MOOC Learning
Abstract
:1. Introduction
2. Related Work
2.1. Research on Emotion Recognition in MOOC Scenarios
2.2. Research Based on Adaptive Window
3. Materials and Methods
3.1. Dataset Collection
3.2. Feature Extraction from Eye Movement, Audio and Video Images
3.3. Process of Methods
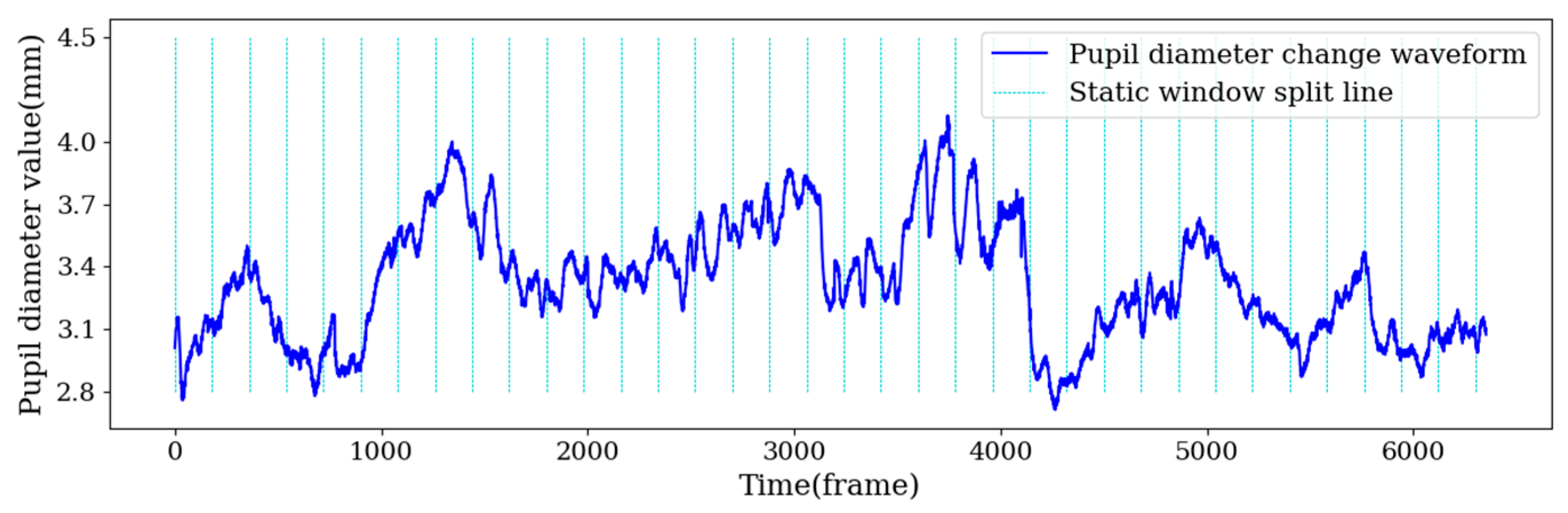
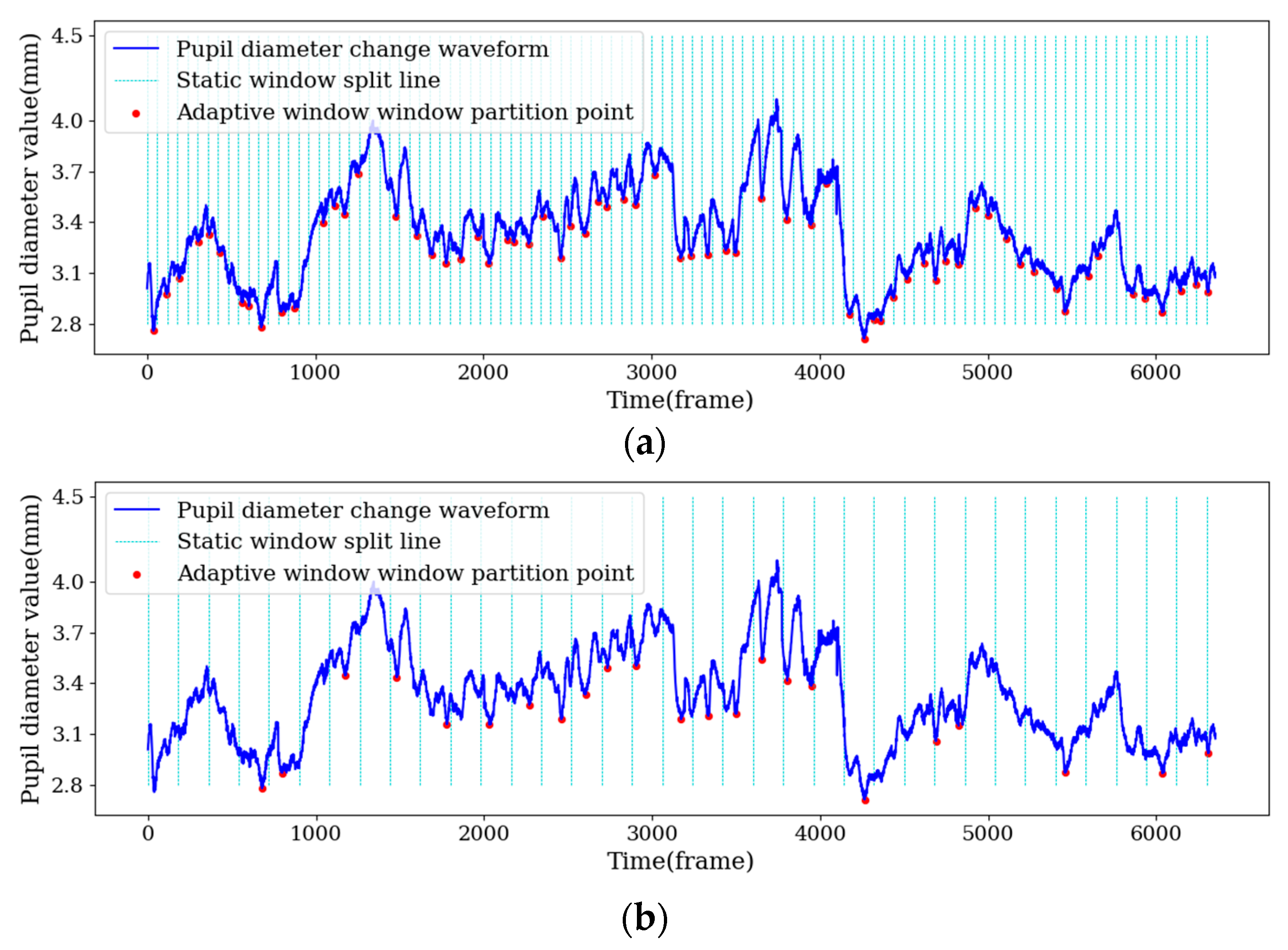
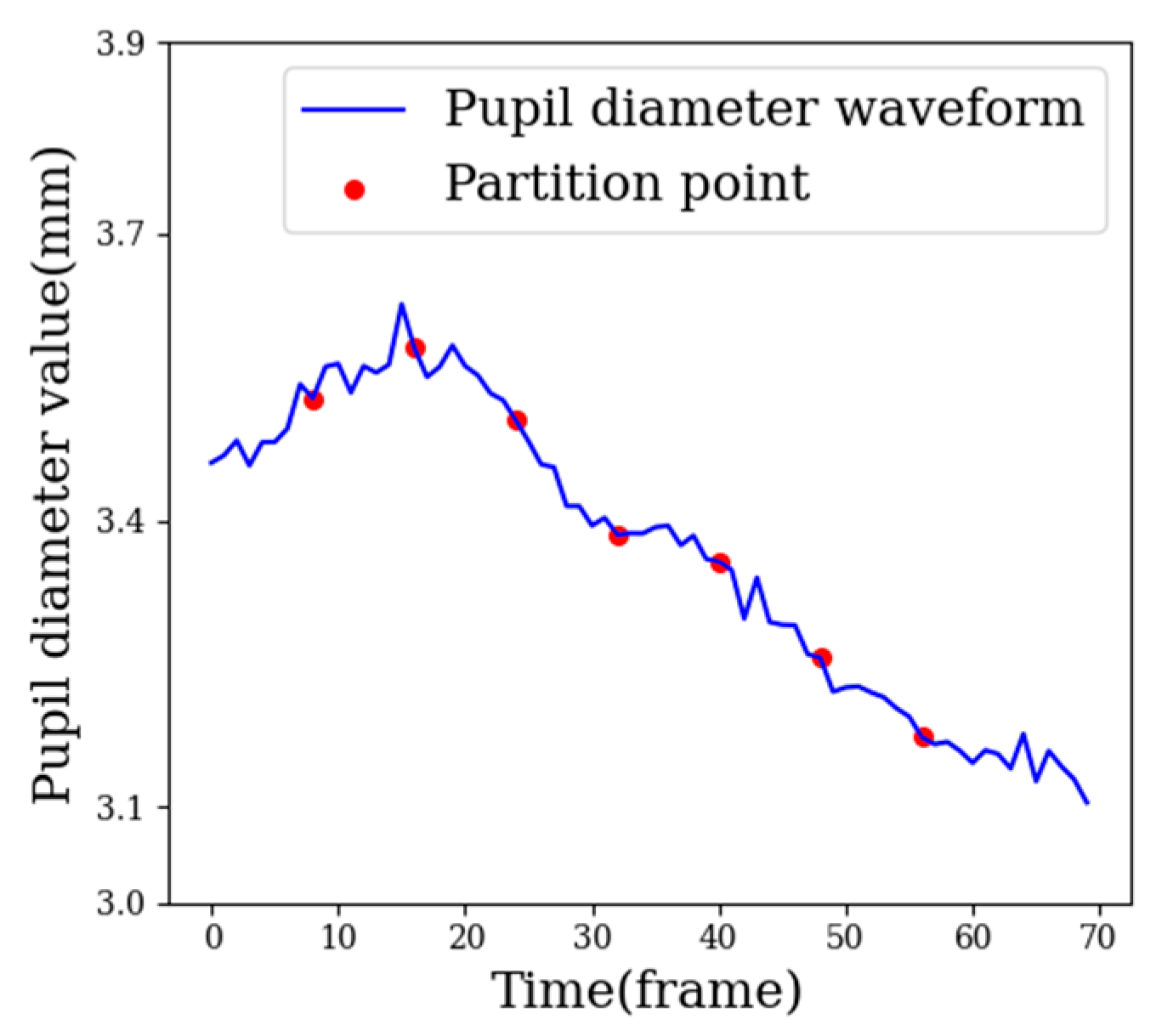
3.3.1. Sample Segmentation Based on Adaptive Window
| Algorithm 1 Calculating the partition points of the adaptive window |
| Input: List of pupil diameter during viewing video: Pd |
| Output: Split point list: Sp |
| Initialize: Sp=None |
| for i = n to the length of Pd do |
| i is the index of Pd |
| if Pd[i] < the Minimum of Pd[i-n:i] and Pd[i] < the Minimum of Pd[i+1:i+n] then |
| i is the local minimum from i-n to i+n |
| Deposit i into Sp |
| i =i+n |
| else |
| i=i+1 |
| end if |
| end for |
3.3.2. Fine-Grained Feature Extraction
4. Experiment
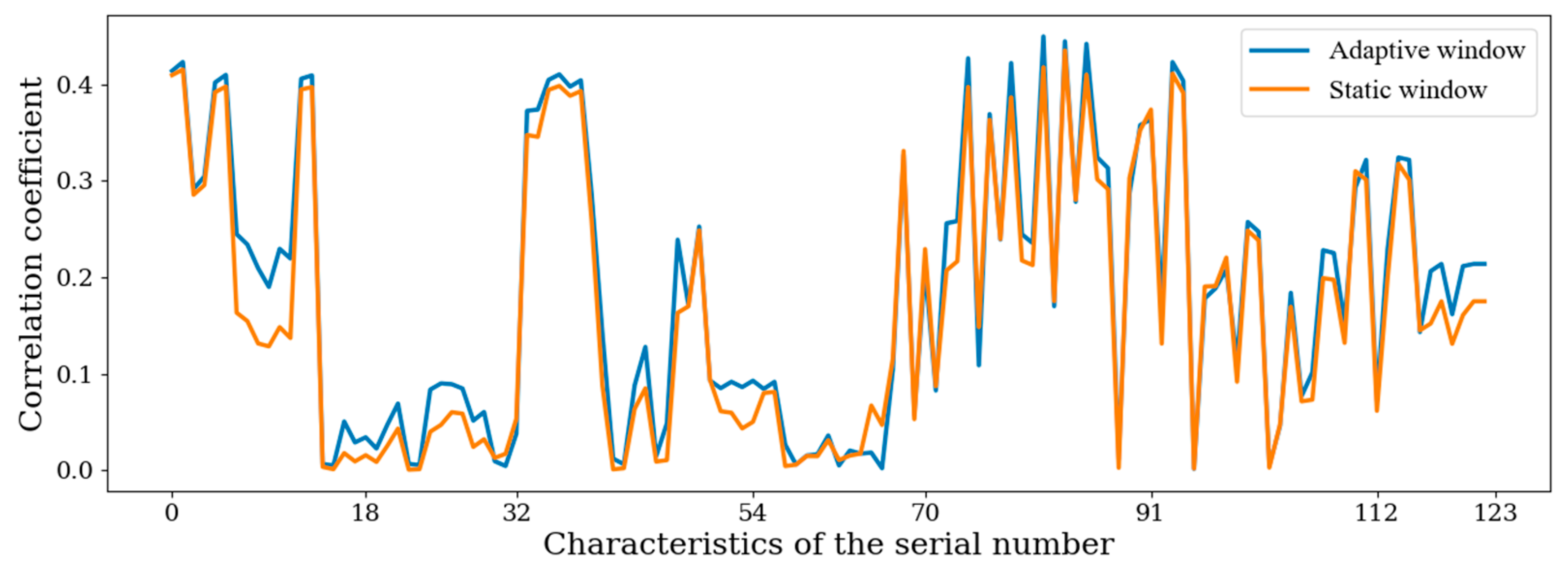
4.1. Comparison of AWS with SWS
4.2. Comparison of Fine-Grained Feature Methods
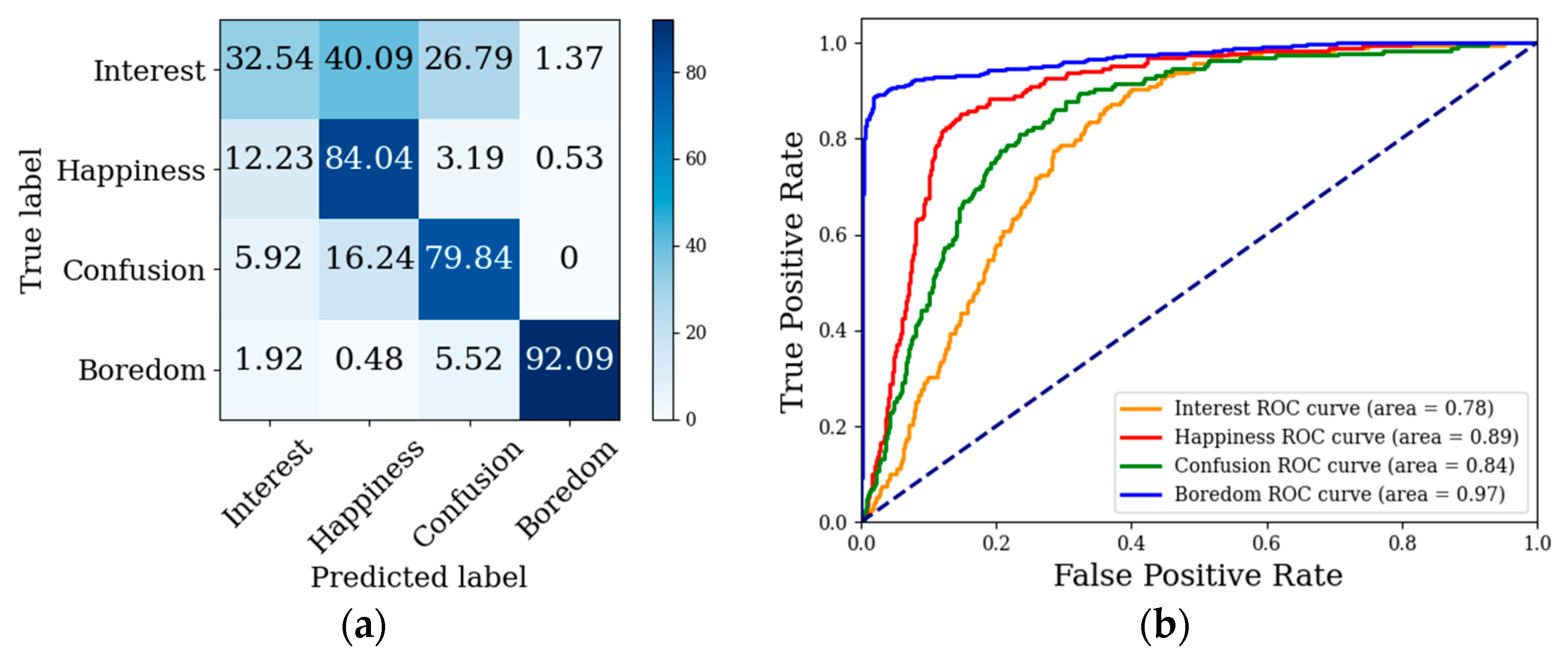
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Riel, J.; Lawless, K.A. Developments in MOOC Technologies and Participation Since 2012: Changes Since “The Year of the MOOC”. In Encyclopedia of Information Science and Technology, 4th ed.; IGI Global: Harrisburg, PA, USA, 2017. [Google Scholar]
- Sidhu, P.K.; Kapoor, A.; Solanki, Y.; Singh, P.; Sehgal, D. Deep Learning Based Emotion Detection in an Online Class. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), New Delhi, India, 11–13 February 2022; pp. 1–6. [Google Scholar]
- Moeller, J.; Brackett, M.A.; Ivcevic, Z.; White, A.E. High school students’ feelings: Discoveries from a large national survey and an experience sampling study. Learn. Instr. 2020, 66, 101301. [Google Scholar] [CrossRef]
- Li, S.; Zheng, J.; Lajoie, S.P.; Wiseman, J. Examining the relationship between emotion variability, self-regulated learning, and task performance in an intelligent tutoring system. Educ. Tech Res. Dev. 2021, 69, 673–692. [Google Scholar] [CrossRef]
- Tormanen, T.; Jarvenoja, H.; Saqr, M.; Malmberg, J.; Jarvela, S. Affective states and regulation of learning during socio-emotional interactions in secondary school collaborative groups. Br. J. Educ. Psychol. 2022, 14, e12525. [Google Scholar]
- Zhao, S.; Huang, X.; Lu, X. A study on the Prediction of emotional Index to the Achievement of MOOC students. China Univ. Teach. 2019, 5, 66–71. [Google Scholar]
- Ye, J.M.; Liao, Z.X. Research on Learner Emotion Recognition Method in Online Learning Community. J. Chin. Mini-Micro Comput. Syst. 2021, 42, 912–918. [Google Scholar]
- Atapattu, T.; Falkner, K.; Thilakaratne, M.; Sivaneasharajah, L.; Jayashanka, R. What Do Linguistic Expressions Tell Us about Learners’ Confusion? A Domain-Independent Analysis in MOOCs. IEEE Trans. Learn. Technol. 2020, 13, 878–888. [Google Scholar] [CrossRef]
- Nandi, A.; Xhafa, F.; Subirats, L.; Fort, S. Real-Time Emotion Classification Using EEG Data Stream in E-Learning Contexts. Sensors 2021, 21, 1589. [Google Scholar] [CrossRef]
- Hung, J.C.; Lin, K.-C.L.; Lai, N.-X. Recognizing learning emotion based on convolutional neural networks and transfer learning. Appl. Soft Comput. 2019, 84, 2454–2466. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, C.; Zhang, Y.D. Multimodal emotion recognition based on manifold learning and convolution neural network. Multimed. Tools Appl. 2022, 12, 1002–1018. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Ren, Z.; Schuller, B. EmoBed: Strengthening Monomodal Emotion Recognition via Training with Crossmodal Emotion Embeddings. IEEE Trans. Affect. Comput. 2021, 12, 553–564. [Google Scholar] [CrossRef]
- Zhou, H.; Du, J.; Zhang, Y.; Wang, Q.; Liu, Q.-F.; Lee, C.-H. Information Fusion in Attention Networks Using Adaptive and Multi-Level Factorized Bilinear Pooling for Audio-Visual Emotion Recognition. IEEE/ACM Trans. Audio Speech Lang. Processing 2021, 29, 2617–2629. [Google Scholar] [CrossRef]
- Yamamoto, K.; Toyoda, K.; Ohtsuki, T. MUSIC-based Non-contact Heart Rate Estimation with Adaptive Window Size Setting. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 6073–6076. [Google Scholar]
- Sun, B.; Wang, C.; Chen, X.; Zhang, Y.; Shao, H. PPG signal motion artifacts correction algorithm based on feature estimation. OPTIK 2019, 176, 337–349. [Google Scholar] [CrossRef]
- Yang, H.; Xu, Z.; Liu, L.; Tian, J.; Zhang, Y. Adaptive Slide Window-Based Feature Cognition for Deceptive Information Identification. IEEE Access 2020, 8, 134311–134323. [Google Scholar] [CrossRef]
- Li, P.; Hou, D.; Zhao, J.; Xiao, Z.; Qian, T. Research on Adaptive Energy Detection Technology Based on Correlation Window. In Proceedings of the 2021 IEEE 5th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Xi’an, China, 15–17 October 2021; pp. 836–840. [Google Scholar]
- Gao, J.; Zhu, H.; Murphey, Y.L. Adaptive Window Size Based Deep Neural Network for Driving Maneuver Prediction. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 87–92. [Google Scholar]
- Zhang, C.; Chi, J.; Zhang, Z.; Wang, Z. The Research on Eye Tracking for Gaze Tracking System. Acta Autom. Sin. 2010, 8, 1051–1061. [Google Scholar] [CrossRef]
- LI Ai, L.I.; Liu, T.-G.; Ling, X.; Lu, Z.-H. Correlation between emotional status and pupils size in normal people. Rec. Adv. Ophthalmol. 2013, 33, 1075–1077. [Google Scholar]
- Moharana, L.; Das, N. Analysis of Pupil Dilation on Different Emotional States by Using Computer Vision Algorithms. In Proceedings of the 2021 1st Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology(ODICON), Bhubaneswar, India, 8–9 January 2021; pp. 1–6. [Google Scholar]
- Henderson, R.R.; Bradley, M.M.; Lang, P.J. Emotional imagery and pupil diameter. Psychophysiology 2018, 55, e13050. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Moeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef]
- Tarnowski, P.; Kołodziej, M.; Majkowski, A.; Rak, R.J. Eye-Tracking Analysis for Emotion Recognition. Comput. Intell. Neurosci. 2020, 2020, 2909267. [Google Scholar] [CrossRef]
- Li, M.; Cao, L.; Zhai, Q.; Li, P.; Liu, S.; Li, R.; Feng, L.; Wang, G.; Hu, B.; Lu, S. Method of Depression Classification Based on Behavioral and Physiological Signals of Eye Movement. Complexity 2020, 2020, 4174857. [Google Scholar] [CrossRef]
- Liu, W.; Qiu, J.-L.; Zheng, W.-L.; Lu, B.-L. Comparing Recognition Performance and Robustness of Multimodal Deep Learning Models for Multimodal Emotion Recognition. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 715–729. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Specific Features | |
|---|---|---|
| Eye movement signal | Time domain feature | Maximum, minimum, average, median, range, standard deviation, variance, energy, average amplitude, saccade time, fixation time and coordinate difference of eye movement, root mean square |
| Wave feature | Crest factor, waveform factor, skewness factor, impulse factor, clearance factor, kurtosis factor | |
| Audio signal | Maximum, minimum, average, median, range, standard deviation, variance | |
| Video image | Maximum, minimum, average, median, range, standard deviation, variance | |
| Modalities | Pupil Diameter | Audio Signal | Video Image | All the Features | ||||
|---|---|---|---|---|---|---|---|---|
| Time-domain features | Waveform features | Time-domain features | Time-domain features | |||||
| First-order difference | First-order difference | First-order difference | ||||||
| Adaptive window | 0.25 | 0.05 | 0.2 | 0.05 | 0.27 | 0.2 | 0.21 | 0.1824 |
| Static window | 0.22 | 0.03 | 0.18 | 0.04 | 0.26 | 0.19 | 0.19 | 0.1656 |
| Modalities | Eye Movement | Audio | Video Image | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Evaluation | Acc (%) | m-F1 | AUC | Acc (%) | m-F1 | AUC | Acc (%) | m-F1 | AUC | |
| Research | ||||||||||
| [14] | 51.3 | 0.46 | 0.7 | 65.2 | 0.6 | 0.76 | 61.8 | 0.56 | 0.77 | |
| [15] | 50.2 | 0.46 | 0.69 | 64.9 | 0.59 | 0.75 | 58.1 | 0.53 | 0.75 | |
| Our method | 53.7 | 0.48 | 0.71 | 68.4 | 0.63 | 0.82 | 62.4 | 0.58 | 0.77 | |
| Sample Type | Classification Model | Modalities | |||
|---|---|---|---|---|---|
| Eye Movement (%) | Audio (%) | Video Image (%) | Feature Layer Fusion (%) | ||
| Adaptive sample | KNN | 43 | 40 | 24 | 48 |
| RF | 41 | 42 | 20 | 29 | |
| 1D-Resnet18 | 53.7 | 68.4 | 62.4 | 68.7 | |
| Adaptive fine-grained sample | LSTM | 59.6 | 69.3 | 64.9 | 69.2 |
| TCN | 62.9 | 71.1 | 68 | 71.2 | |
| LSTM + CNN | 62.3 | 71.9 | 65.7 | 72.2 | |
| TCN + CNN | 65.1 | 75.6 | 70.4 | 76.2 | |
| Sample Type | Classification Model | Eye Movement | Audio | Video Image |
|---|---|---|---|---|
| SWS | KNN | 23 | 60 | 34 |
| RF | 25 | 65 | 34 | |
| 1D-Resnet18 | 27.5 | 65.3 | 35.8 | |
| AWS | KNN | 26 | 64 | 49 |
| RF | 26 | 65 | 47 | |
| 1D-Resnet18 | 29.5 | 66.9 | 47.7 | |
| Adaptive fine-grained sample | LSTM | 40.2 | 65.9 | 47.1 |
| TCN | 41.8 | 66 | 50.2 | |
| LSTM + CNN | 40.5 | 66.2 | 45.5 | |
| TCN + CNN | 42.5 | 67.1 | 52.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, X.; Bao, J.; Tao, X.; Li, Z. Research on Emotion Recognition Method Based on Adaptive Window and Fine-Grained Features in MOOC Learning. Sensors 2022, 22, 7321. https://doi.org/10.3390/s22197321
Shen X, Bao J, Tao X, Li Z. Research on Emotion Recognition Method Based on Adaptive Window and Fine-Grained Features in MOOC Learning. Sensors. 2022; 22(19):7321. https://doi.org/10.3390/s22197321
Chicago/Turabian StyleShen, Xianhao, Jindi Bao, Xiaomei Tao, and Ze Li. 2022. "Research on Emotion Recognition Method Based on Adaptive Window and Fine-Grained Features in MOOC Learning" Sensors 22, no. 19: 7321. https://doi.org/10.3390/s22197321
APA StyleShen, X., Bao, J., Tao, X., & Li, Z. (2022). Research on Emotion Recognition Method Based on Adaptive Window and Fine-Grained Features in MOOC Learning. Sensors, 22(19), 7321. https://doi.org/10.3390/s22197321