




HRST: An Improved HRNet for Detecting Joint Points of Pigs

Abstract
:1. Introduction
2. Materials and Methods
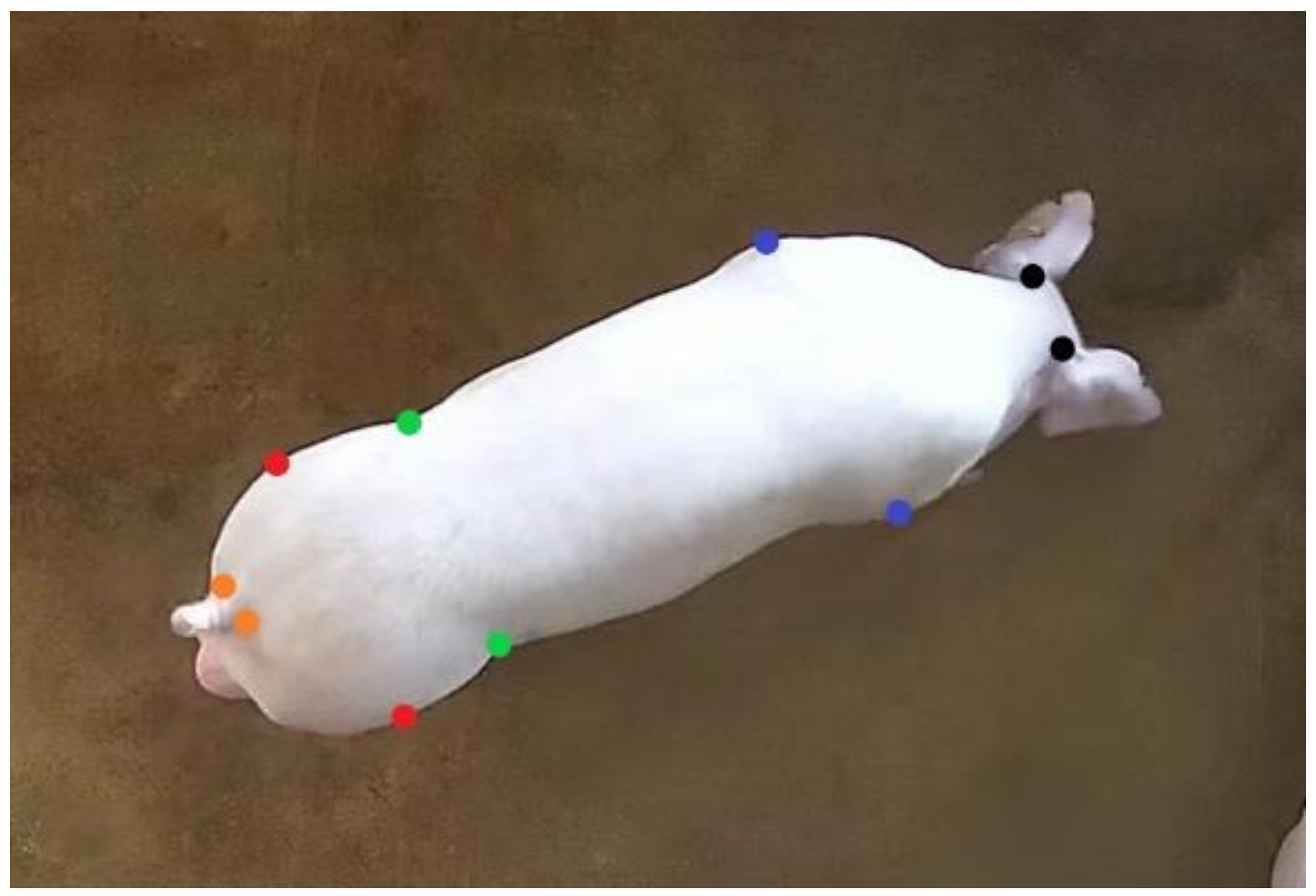
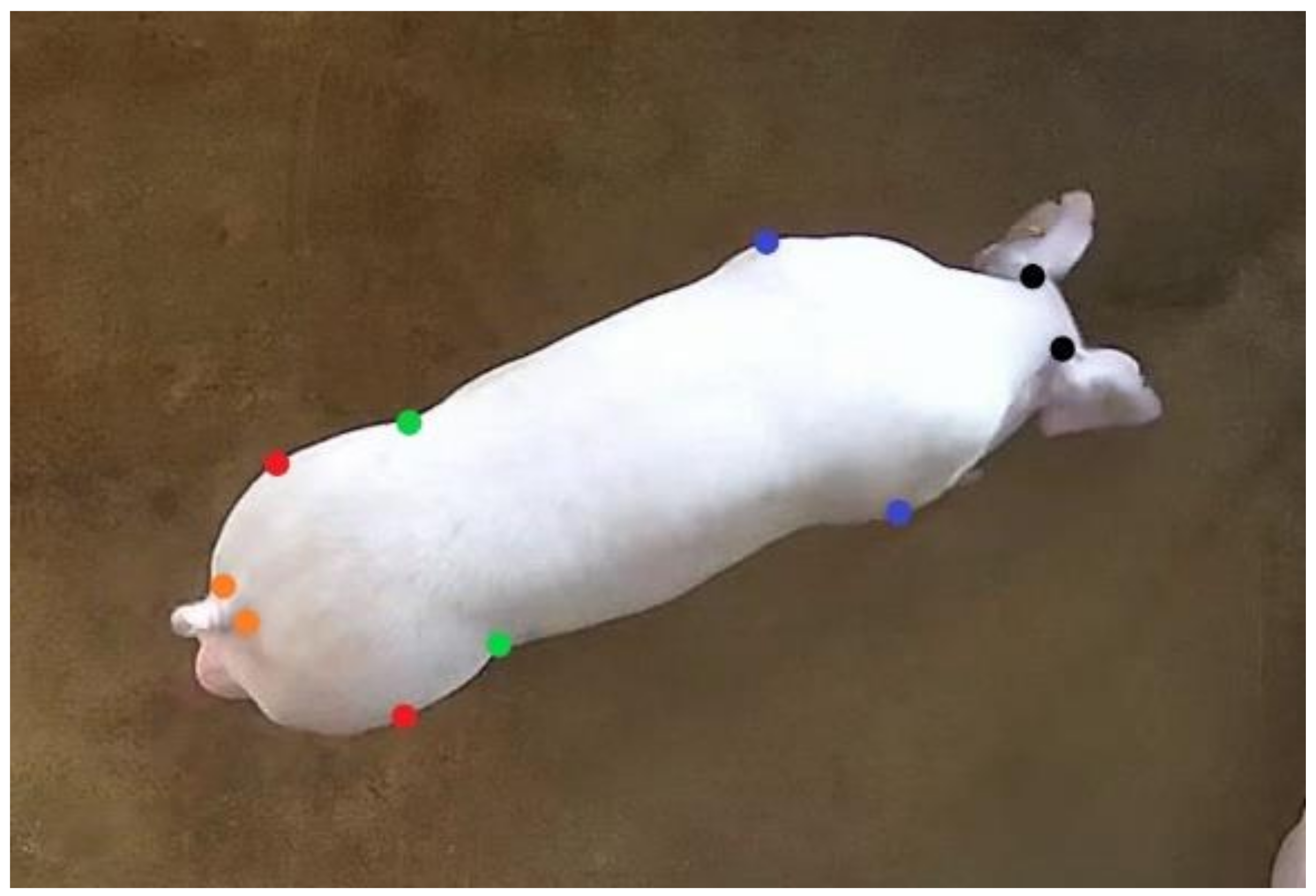
2.1. Datasets Collection and Dataset Annotation
2.2. Pig Posture Detection Based on Object Detection Algorithm
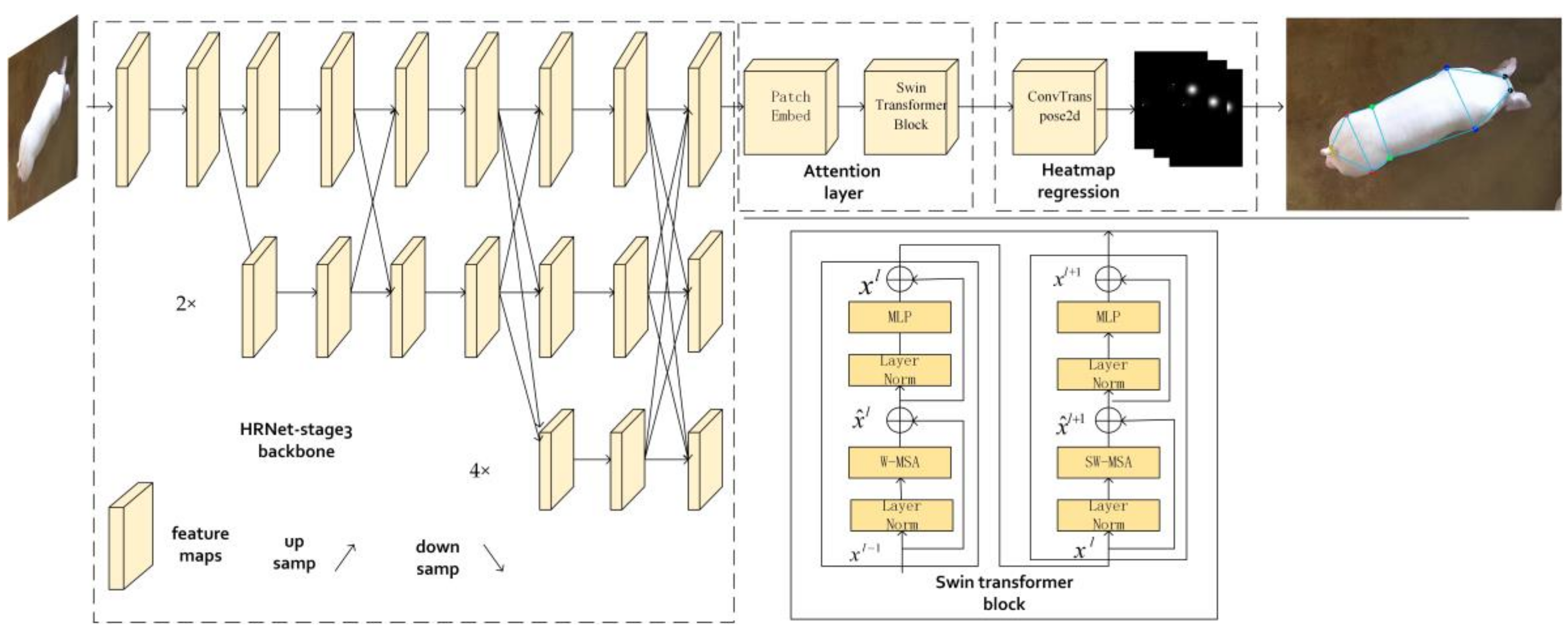
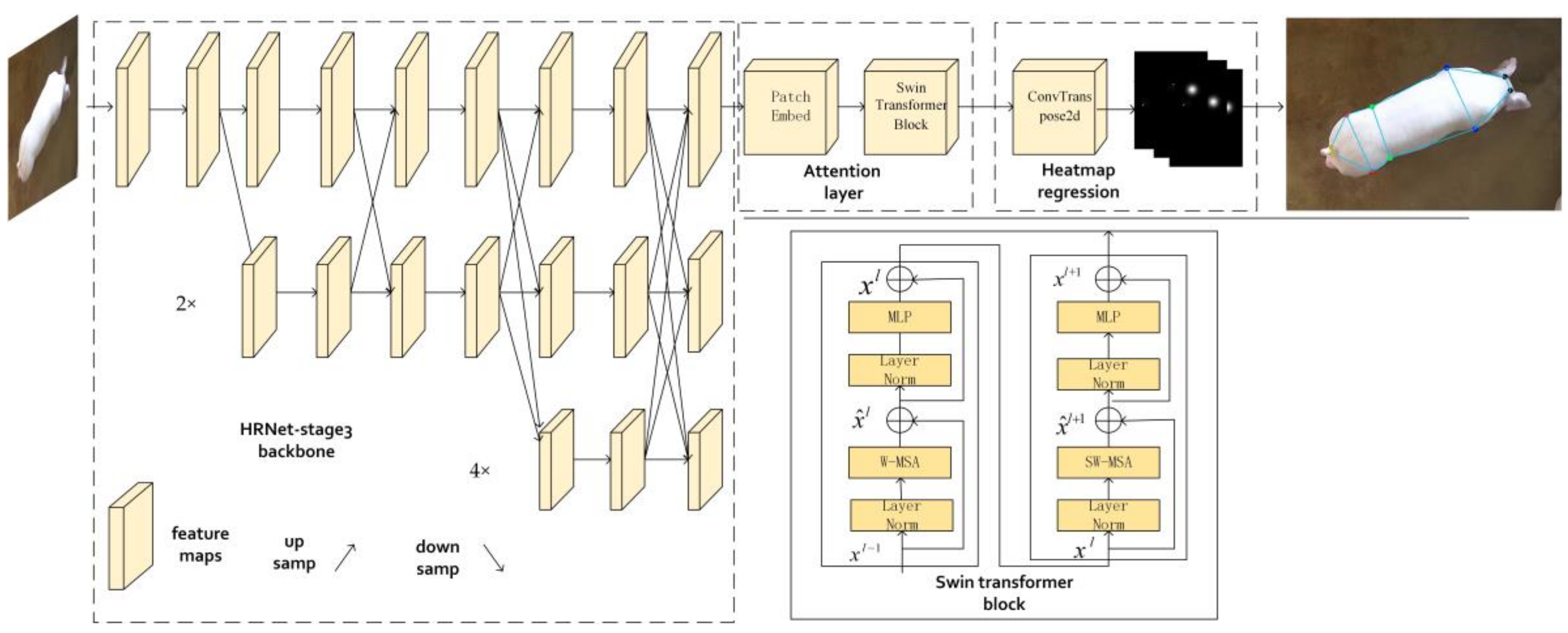
2.3. HRST (HRNet with Swin Transformer Block)
2.3.1. HRNet-Stage3
2.3.2. Attention Layer
2.3.3. Heatmap Regression
2.4. Joint Point Detection of Pig
3. Result and Discussion
3.1. Posture Detection
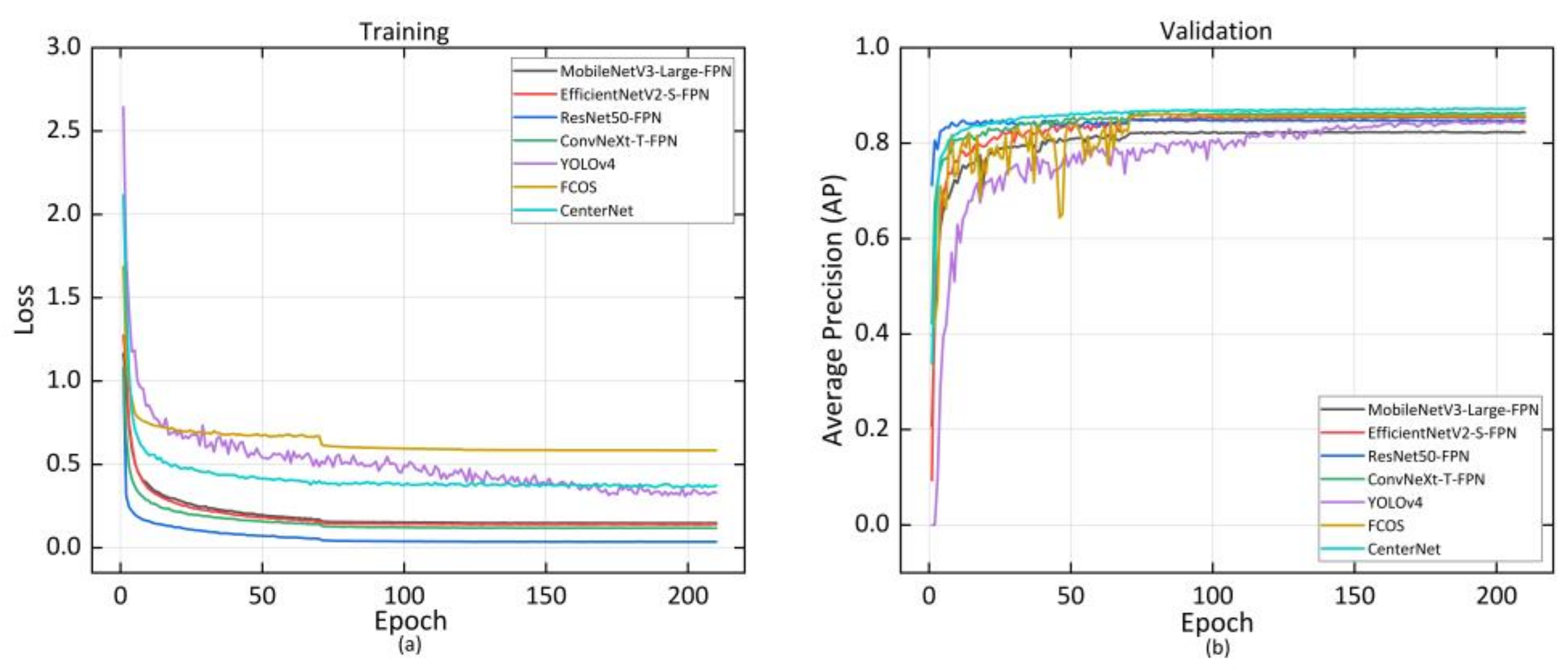
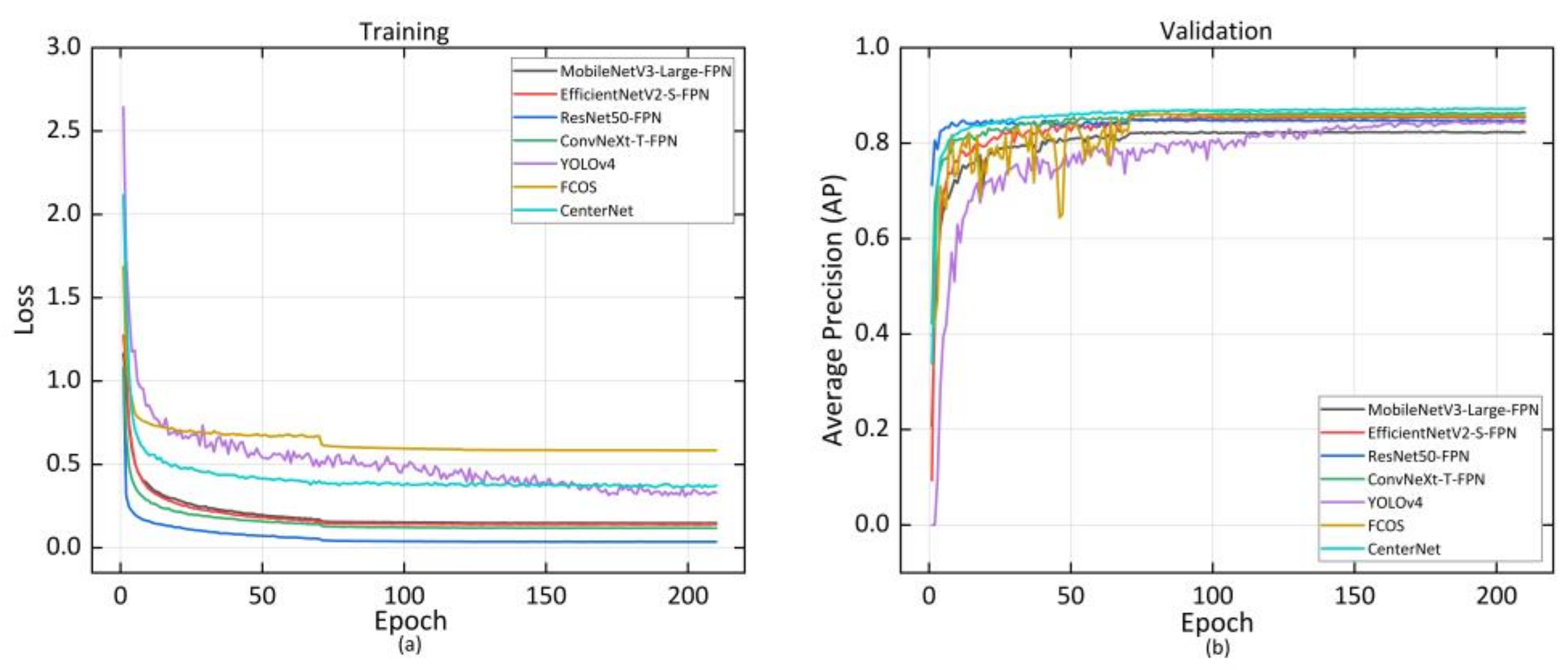
3.1.1. Implementation Details
3.1.2. Posture Detection Results
3.2. Joint Points Detection
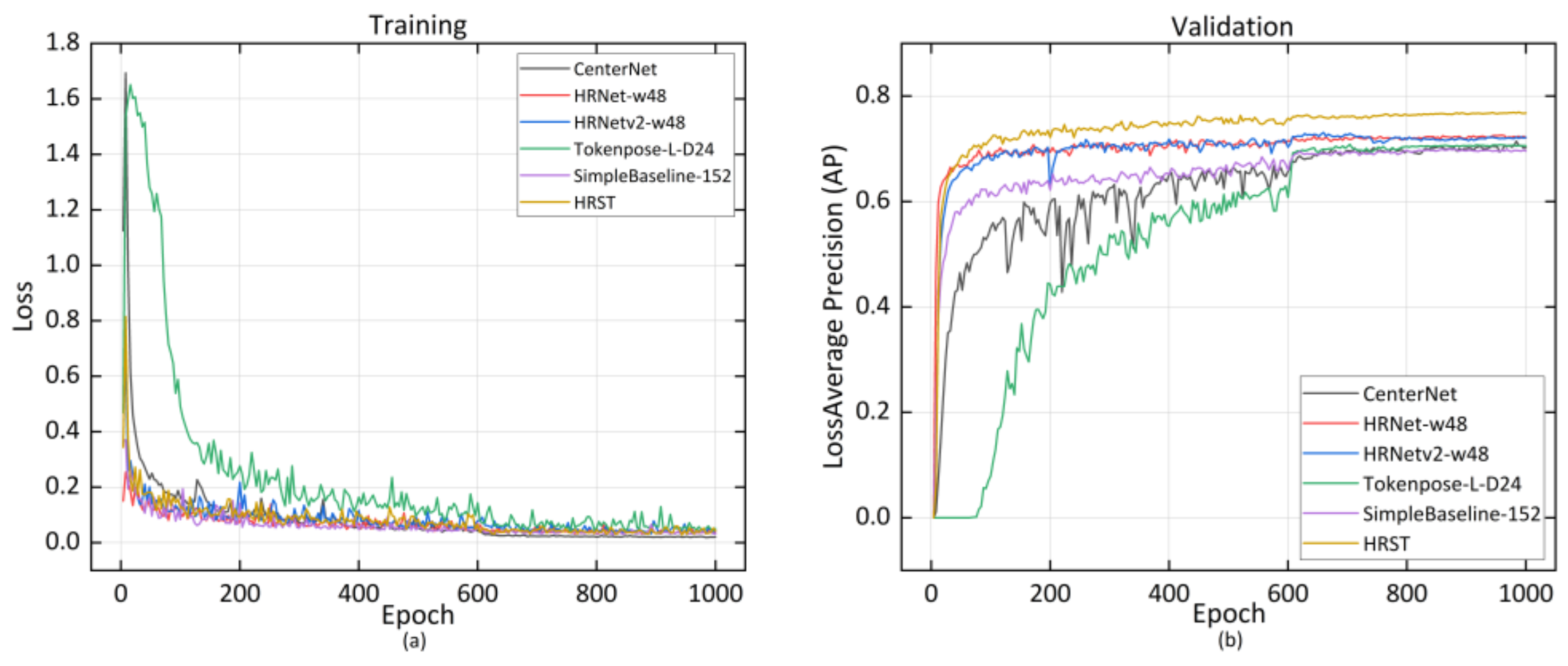
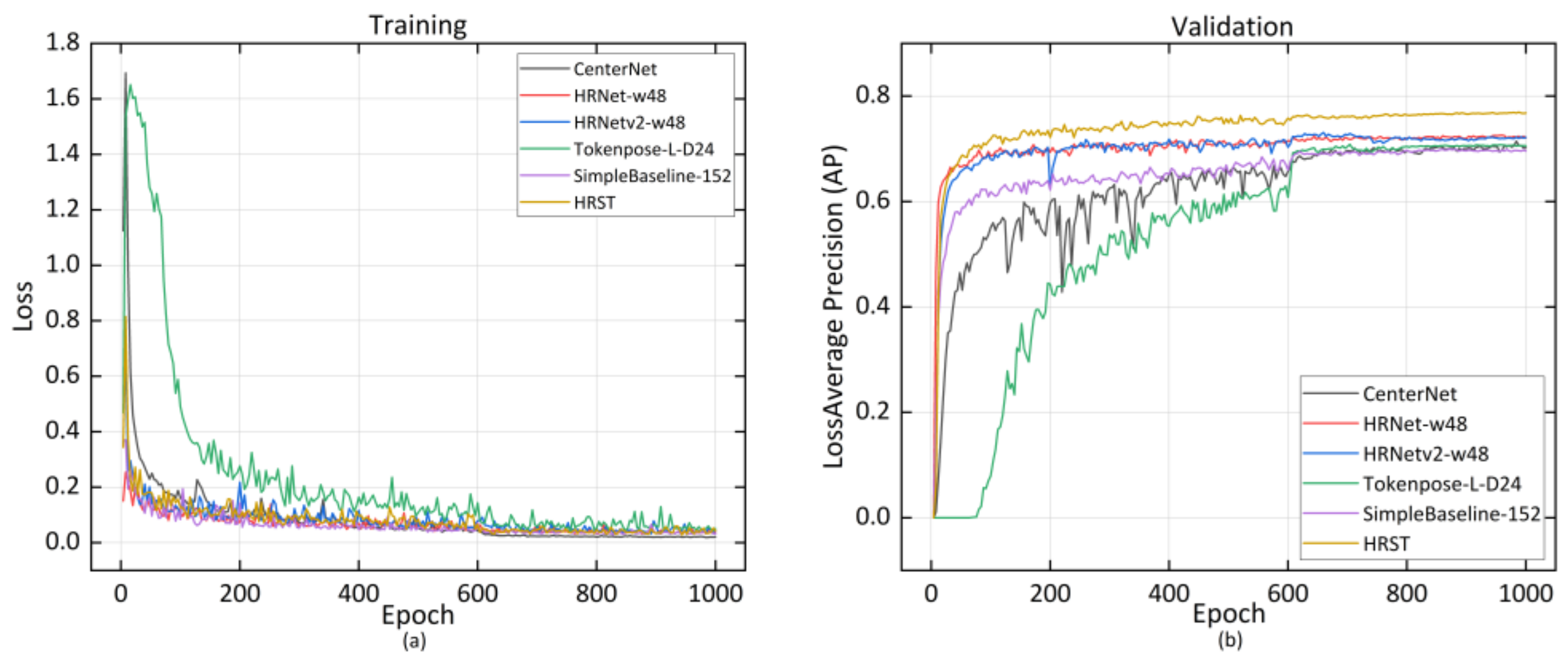
3.2.1. Implementation Details
3.2.2. Joint Points Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, C.; Zhang, J.; Teng, G. Mobile measuring system based on LabVIEW for pig body components estimation in a large-scale farm. Comput. Electron. Agric. 2019, 156, 399–405. [Google Scholar] [CrossRef]
- Li, G.; Liu, X.; Ma, Y.; Wang, B.; Zheng, L.; Wang, M. Body size measurement and live body weight estimation for pigs based on back surface point clouds. Biosyst. Eng. 2022, 218, 10–22. [Google Scholar] [CrossRef]
- Zhang, J.; Zhuang, Y.; Ji, H.; Teng, G. Pig weight and body size estimation using a multiple output regression convolutional neural network: A fast and fully automatic method. Sensors 2021, 21, 3218. [Google Scholar] [CrossRef] [PubMed]
- Pezzuolo, A.; Guarino, M.; Sartori, L.; González, L.A.; Marinello, F. On-barn pig weight estimation based on body measurements by a Kinect v1 depth camera. Comput. Electron. Agric. 2018, 148, 29–36. [Google Scholar] [CrossRef]
- Zhang, A.L.; Wu, B.P.; Wuyun, C.T.; Jiang, D.X.; Xuan, E.C.; Ma, F.Y. Algorithm of sheep body dimension measurement and its applications based on image analysis. Comput. Electron. Agric. 2018, 153, 33–45. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, Y.; He, J.; Chen, Z.; Li, D.; Ma, C.; Ba, Y.; Baima, Q.; Li, X.; Song, R. Research on Yak Body Ruler and Weight Measurement Method Based on Deep Learning and Binocular Vision. Math. Comput. Sci. 2022. [Google Scholar] [CrossRef]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 102897. [Google Scholar] [CrossRef]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020; pp. 5386–5395. [Google Scholar]
- Du, L.; Zhang, R.; Wang, X. Overview of two-stage object detection algorithms. J. Phys. Conf. Ser. 2020, 1544, 012033. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference On Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20 June 2019; pp. 2849–2858. [Google Scholar]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-free oriented proposal generator for object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20 June 2019; pp. 5693–5703. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.-T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11313–11322. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2403–2412. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Ruggero Ronchi, M.; Perona, P. Benchmarking and error diagnosis in multi-instance pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 369–378. [Google Scholar]
- Li, S.; Li, J.; Tang, H.; Qian, R.; Lin, W. ATRW: A benchmark for Amur tiger re-identification in the wild. arXiv 2019, arXiv:1906.05586, preprint. [Google Scholar]
- Tang, Z.-R.; Hu, R.; Chen, Y.; Sun, Z.-H.; Li, M. Multi-expert learning for fusion of pedestrian detection bounding box. Knowl.-Based Syst. 2022, 241, 108254. [Google Scholar] [CrossRef]
- Hu, R.; Tang, Z.-R.; Wu, E.Q.; Mo, Q.; Yang, R.; Li, J. RDC-SAL: Refine distance compensating with quantum scale-aware learning for crowd counting and localization. Appl. Intell. 2022, 1–13. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, M.; Wang, Z. Construction of the animal skeletons keypoint detection model based on transformer and scale fusion. Trans. Chin. Soc. Agric. Eng. 2021, 37, 179–185. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, Pasadena, CA, USA, 13–15 December 2021; pp. 10096–10106. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 11976–11986. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Taipei, Taiwan, 2–4 December 2019; pp. 6105–6114. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yang, H.; Guo, L.; Wu, X.; Zhang, Y. Scale-aware attention-based multi-resolution representation for multi-person pose estimation. Multimed. Syst. 2022, 28, 57–67. [Google Scholar] [CrossRef]
- Li, Z.; Li, Y.; Yang, Y.; Guo, R.; Yang, J.; Yue, J.; Wang, Y. A high-precision detection method of hydroponic lettuce seedlings status based on improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-scale context aggregation for semantic segmentation of remote sensing images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef]
- Liu, Y.; Li, J.; Ren, L.c.; Zhang, J.l.; Xu, Z.y. Human pose estimation based on parallel high-resolution net. Comput. Eng. Des. 2022, 43, 237–244. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30, 6000–6010. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Cha, J.-Y.; Yoon, H.-I.; Yeo, I.-S.; Huh, K.-H.; Han, J.-S. Peri-implant bone loss measurement using a region-based convolutional neural network on dental periapical radiographs. J. Clin. Med. 2021, 10, 1009. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Posture Classes | Number of Individual Postures | |||
|---|---|---|---|---|
| Train Dataset | Validation Dataset | Test Dataset | Total | |
| Standing | 5499 | 735 | 644 | 6234 |
| Lying | 9058 | 1084 | 1171 | 10,412 |
| Total sample | 14557 | 1819 | 1815 | 18,191 |
| Joint Point | Joint Point | ||
|---|---|---|---|
| left neck | 0.005322321731521584 | right abdomen | 0.005311422910349784 |
| right neck | 0.00546914966592658 | left hip | 0.010024322728349425 |
| left shoulder | 0.009892777323066001 | right hip | 0.008588638693752731 |
| right shoulder | 0.00871434068851134 | left tail | 0.004319627728346724 |
| left abdomen | 0.004523805890671292 | right tail | 0.00422832022133345 |
| Class | Feature Extractor | GFLOPs | Params | AP | AP50 | AP75 | AR | FPS |
|---|---|---|---|---|---|---|---|---|
| Faster-RCNN | ResNet50-FPN | 177.11 | 41.4M | 84.7 | 99.0 | 98.6 | 88.9 | 18 |
| Faster-RCNN | MobileNetV3-Large-FPN | 6.62 | 6.2M | 82.3 | 99.5 | 97.8 | 86.6 | 29 |
| Faster-RCNN | EfficientNetV2-S-FPN | 59.73 | 24.3M | 84.8 | 99.0 | 98.9 | 88.9 | 21 |
| Faster-RCNN | ConvNeXt-T-FPN | 97.98 | 34.3M | 86.1 | 99.5 | 99.0 | 90.0 | 18 |
| YOLOv4 | CSPDarknet53 | 119.50 | 63.9M | 84.1 | 98.5 | 97.8 | 88.1 | 52 |
| FCOS | ResNet50-FPN | 177.47 | 31.84M | 85.7 | 99.0 | 98.1 | 90.2 | 21 |
| CenterNet (for posture detection) | DLA-34 | 96.29 | 20.2M | 86.5 | 99.0 | 98.9 | 89.5 | 26 |
| Class | GFLOPs | Params | AP | AP50 | AP75 | AR | FPS |
|---|---|---|---|---|---|---|---|
| CenterNet (for joint point detection) | 13.95 | 20.6M | 67.2 | 94.4 | 83.2 | 73.8 | 56 |
| HRNet-w48 | 35.43 † | 63.6M † | 70.6 † | 94.9 | 86.4 | 78.0 | 26 |
| HRNetv2-w48 | 39.53 | 65.9M | 72.1 | 96.6 | 91.7 | 78.6 | 24 |
| Simple Baseline-152 | 28.67 | 68.6M | 69.6 | 96.0 | 86.6 | 76.0 | 48 |
| Tokenpose-L-D24 | 23.98 | 29.9M | 70.2 | 95.6 | 85.1 | 77.6 | 26 |
| HRST | 20.65 † (↓41.7%) | 17.3 M † ( ↓72.8%) | 77.4 † ( ↑6.8%) | 95.9 | 90.4 | 82.8 | 40 |
| Class | GFLOPs | Params | AP | AP50 | AP75 | AR | FPS |
|---|---|---|---|---|---|---|---|
| CenterNet (for joint point detection) | 13.95 | 20.6M | 75.2 | 95.2 | 77.0 | 86.5 | 56 |
| HRNet-w48 | 35.43 † | 63.6M † | 88.8 † | 97.2 | 90.6 | 91.9 | 26 |
| HRNetv2-w48 | 39.53 | 65.9M | 89.0 | 97.3 | 90.4 | 92.2 | 24 |
| Simple Baseline-152 | 28.67 | 68.6M | 86.4 | 96.4 | 90.3 | 90.1 | 48 |
| Tokenpose-L-D24 | 23.98 | 29.9M | 87.1 | 97.2 | 89.3 | 90.6 | 26 |
| HRST | 20.65 † (↓41.7%) | 17.3M † ( ↓72.8%) | 89.6 † ( ↑0.8%) | 98.4 | 91.5 | 92.4 | 40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, W.; Lu, J.; Wang, H. HRST: An Improved HRNet for Detecting Joint Points of Pigs. Sensors 2022, 22, 7215. https://doi.org/10.3390/s22197215
Wang X, Wang W, Lu J, Wang H. HRST: An Improved HRNet for Detecting Joint Points of Pigs. Sensors. 2022; 22(19):7215. https://doi.org/10.3390/s22197215
Chicago/Turabian StyleWang, Xiaopin, Wei Wang, Jisheng Lu, and Haiyan Wang. 2022. "HRST: An Improved HRNet for Detecting Joint Points of Pigs" Sensors 22, no. 19: 7215. https://doi.org/10.3390/s22197215
APA StyleWang, X., Wang, W., Lu, J., & Wang, H. (2022). HRST: An Improved HRNet for Detecting Joint Points of Pigs. Sensors, 22(19), 7215. https://doi.org/10.3390/s22197215