
A Machine Learning and Blockchain Based Efficient Fraud Detection Mechanism



 , ,
, , 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Data-balancing technique and processioning are performed in the proposed system. In pre-processing, the data are divided into a training dataset and a test dataset.
- Machine learning techniques, XGboost and random forest (RF), are used for data classification. They classify the data as fraudulent or non-fraudulent. Both classifiers predict the type of data. These machine learning models are directly connected to the blockchain.
- The machine learning model is linked to the blockchain. A blockchain-based smart contract is written in which the machine learning model is deployed and used to predict the nature of new incoming transactions.
- The blockchain model is used to initiate the transactions, and then machine learning models are used to classify these transactions as malicious or legitimate.
- Two attacker models are also implemented to protect the proposed model from blockchain attacks.
2. Related Work
2.1. Adversarial Machine Learning Methods
3. Problem Statement and System Model
3.1. Problem Statement
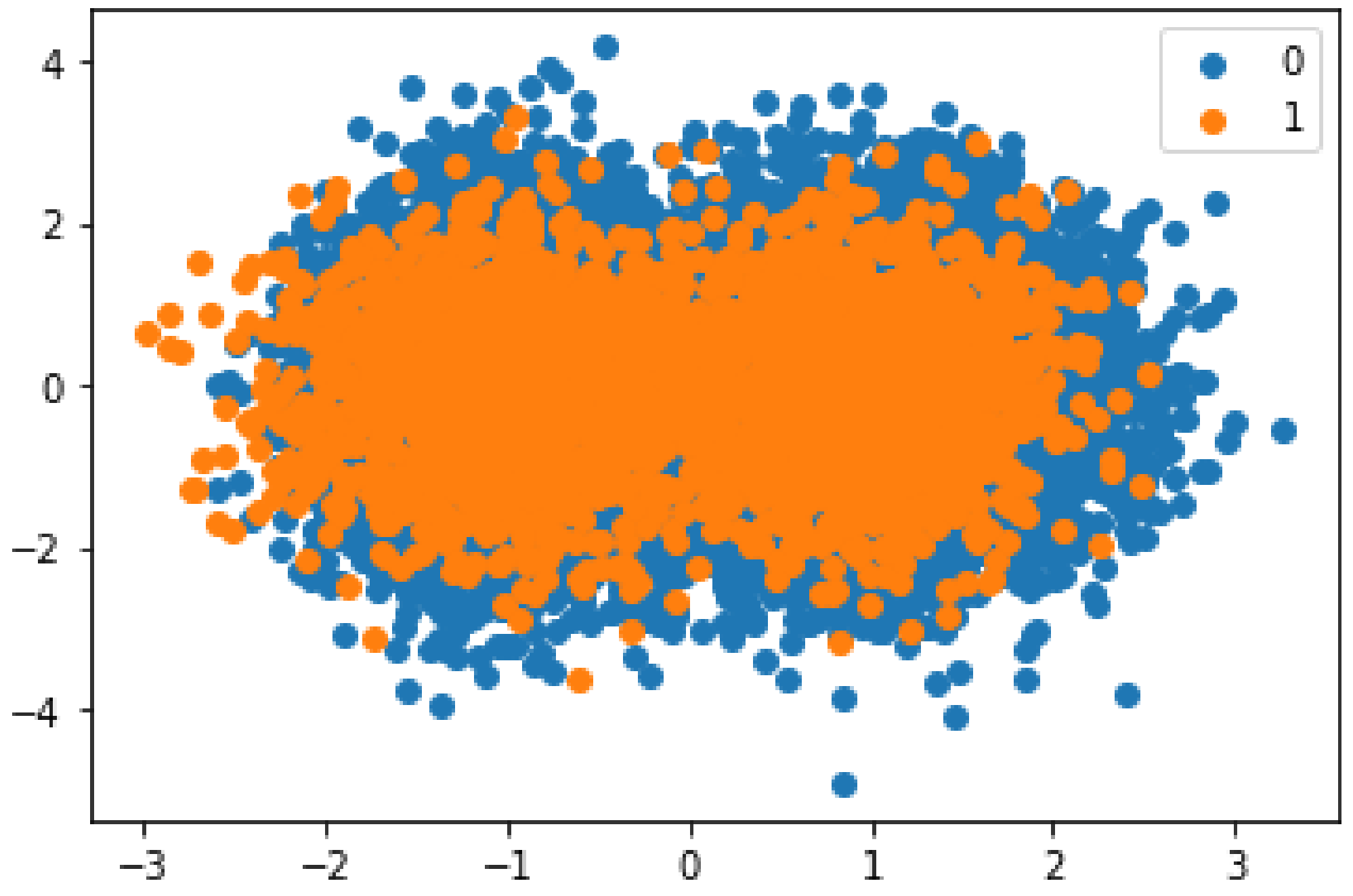
3.2. Dataset Explanation
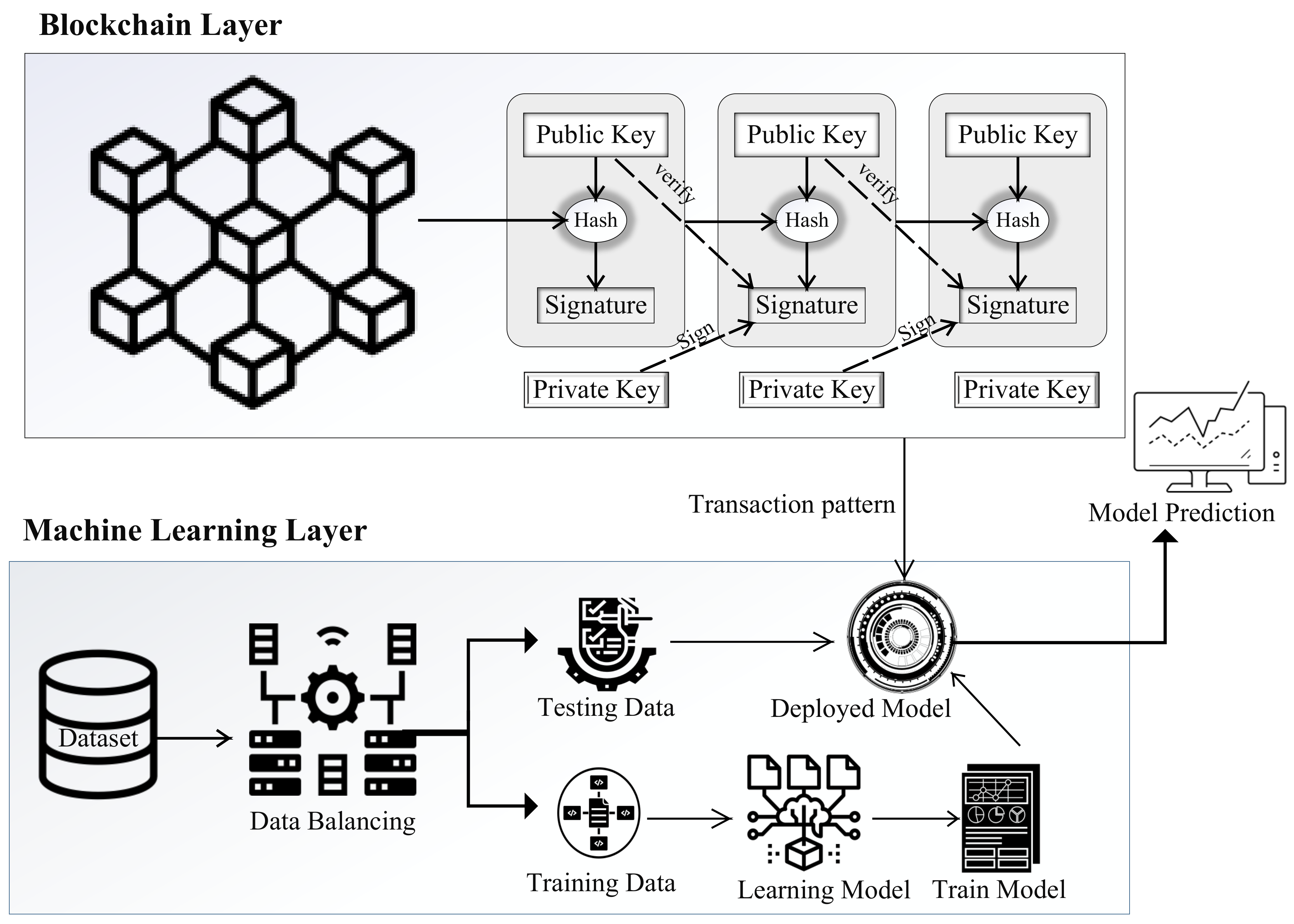
3.3. Proposed System Model
3.3.1. Data Balancing Using SMOTE
| Algorithm 1: Data balancing through SMOTE |
|
3.3.2. Detection of Fraudulent Transactions
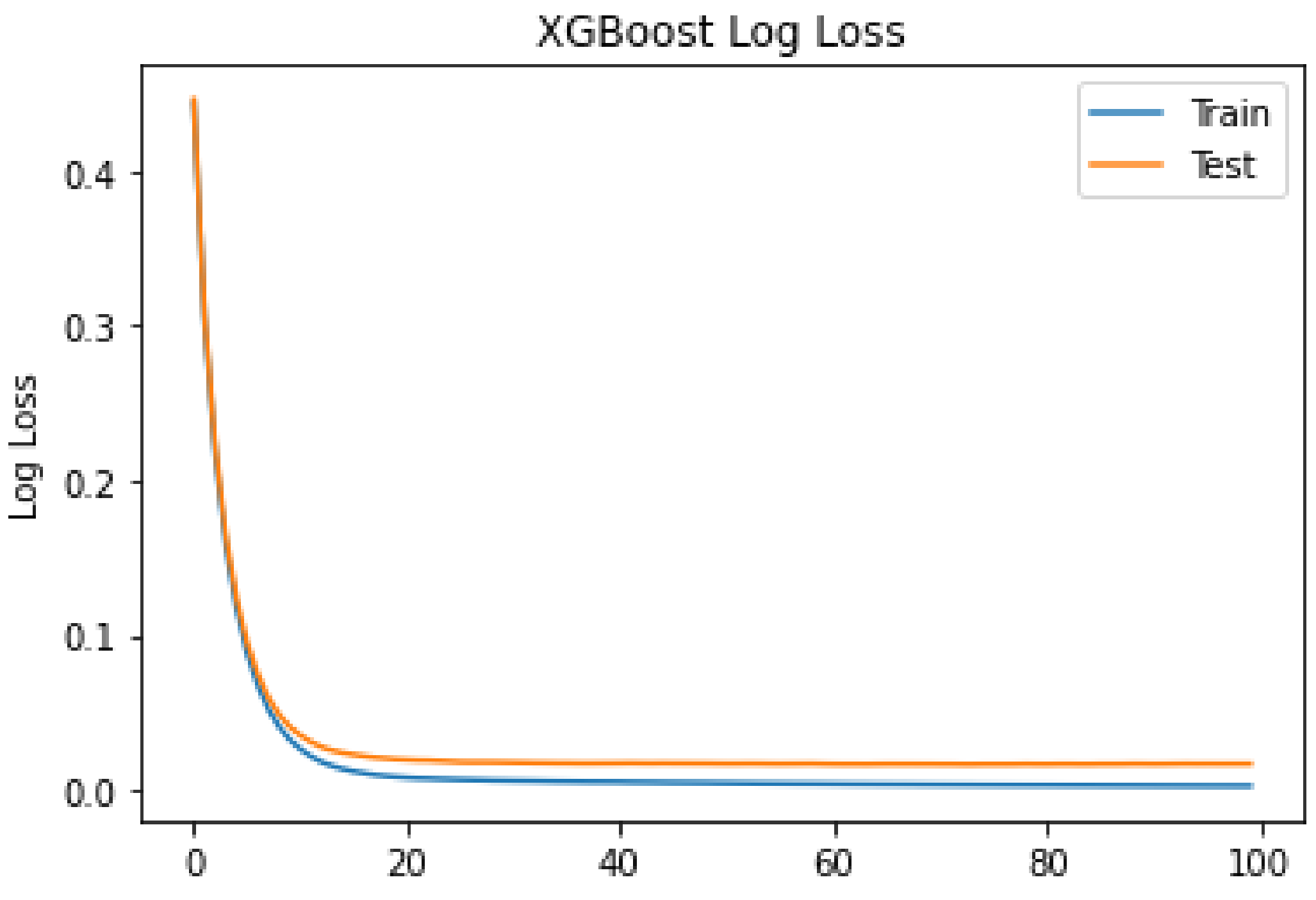
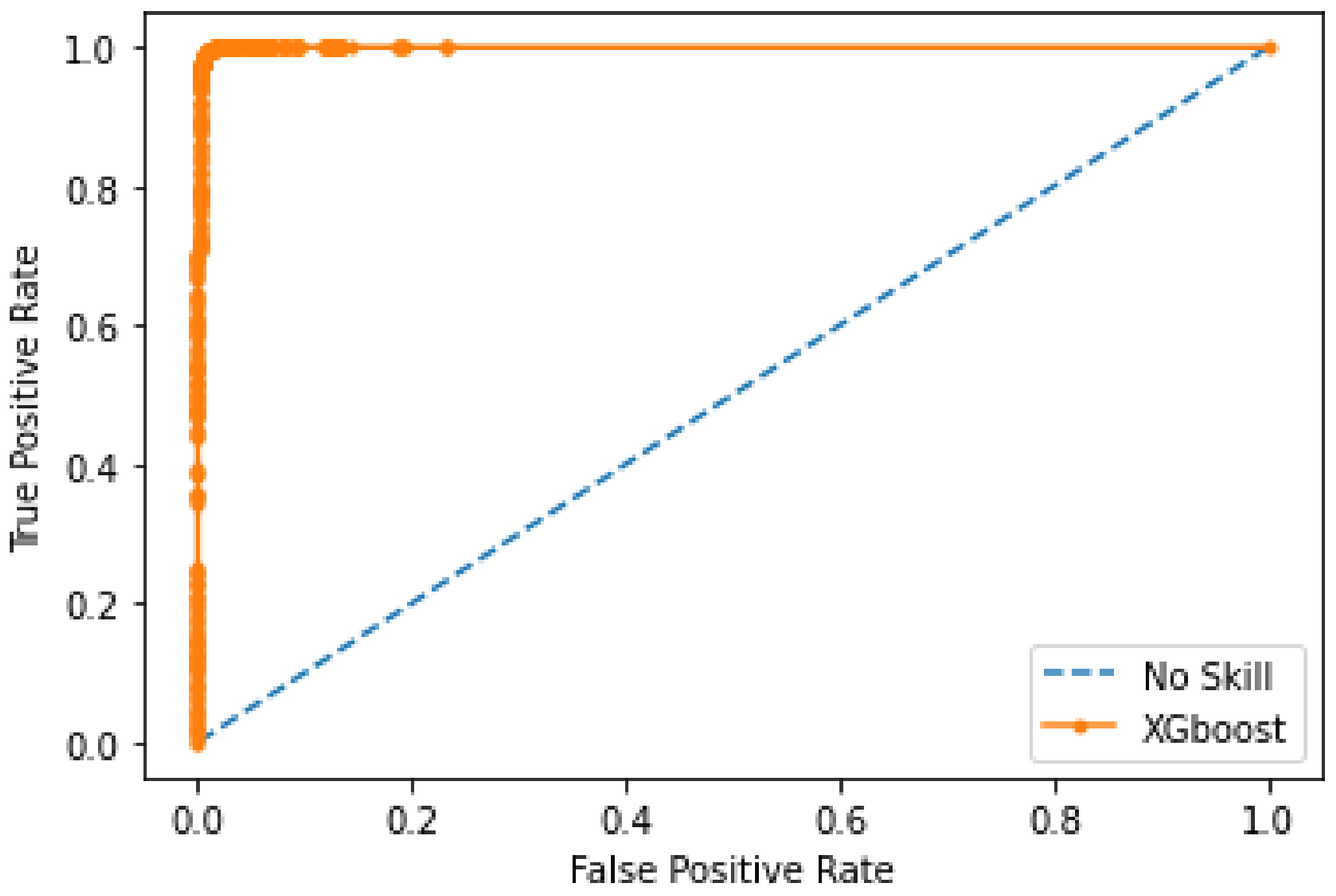
3.3.3. XGBoost
| Algorithm 2: Fraud detection through XGboost |
|
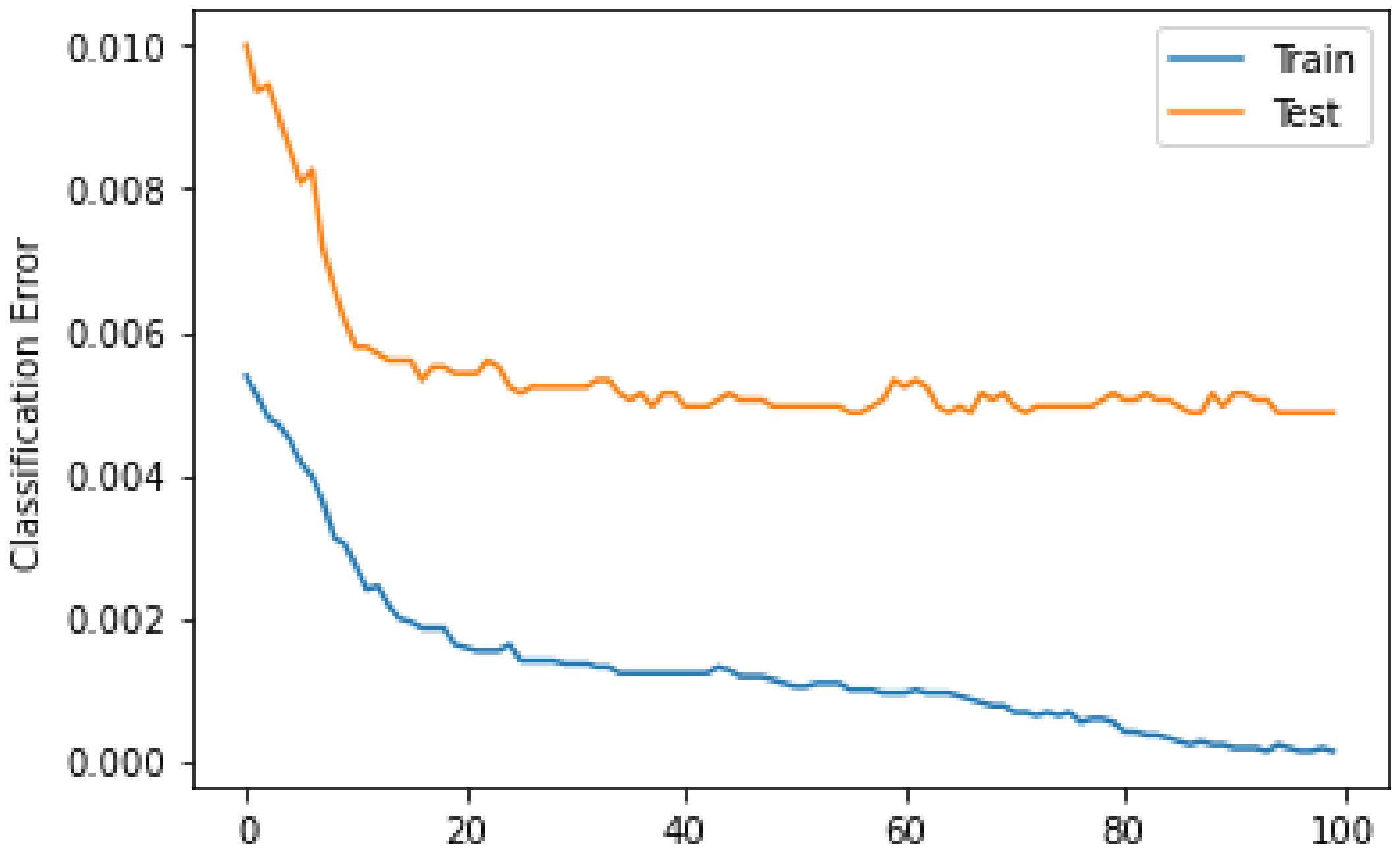
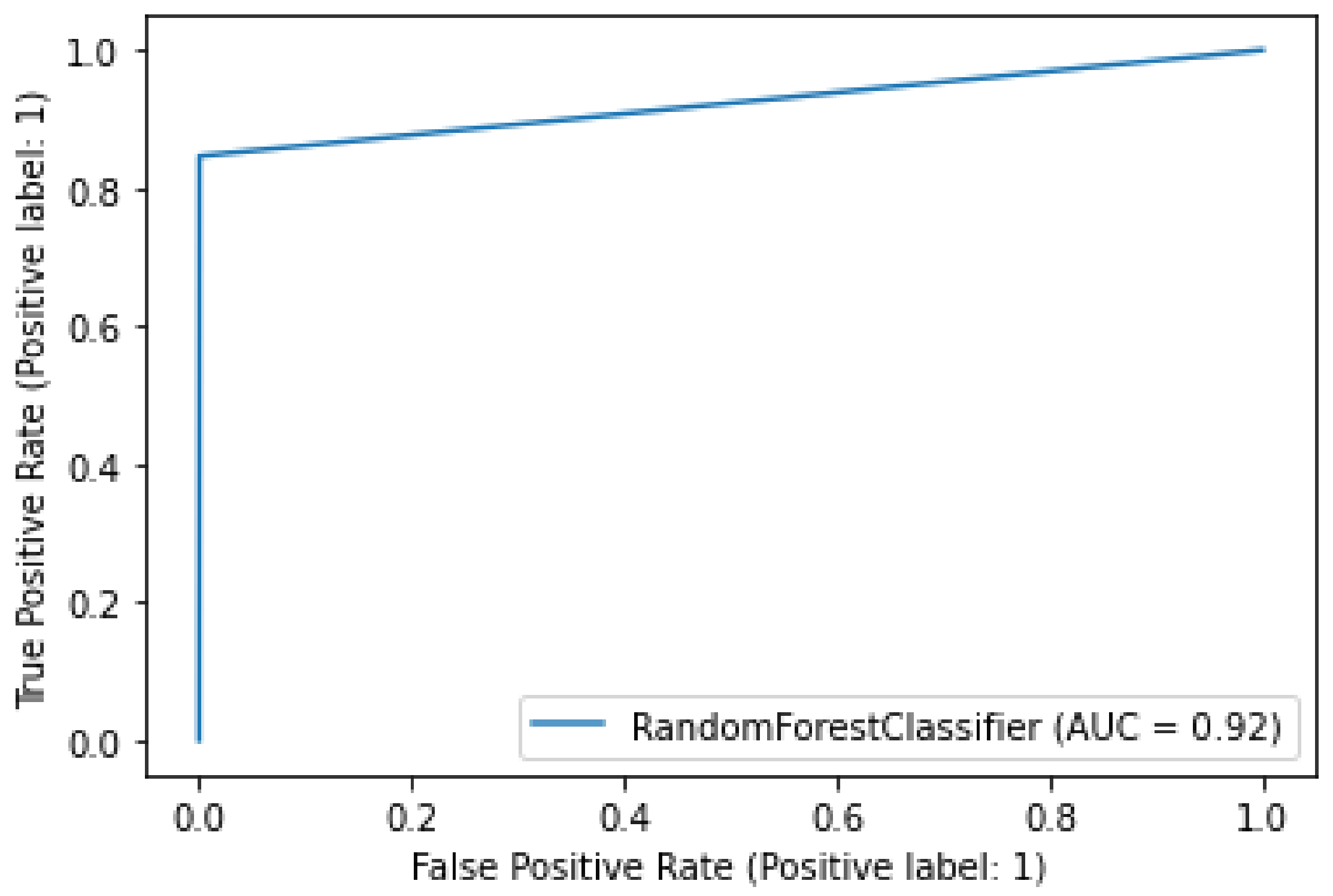
3.3.4. Random Forest
3.4. Linkage of Blockchain with Machine Learning in the Proposed Model
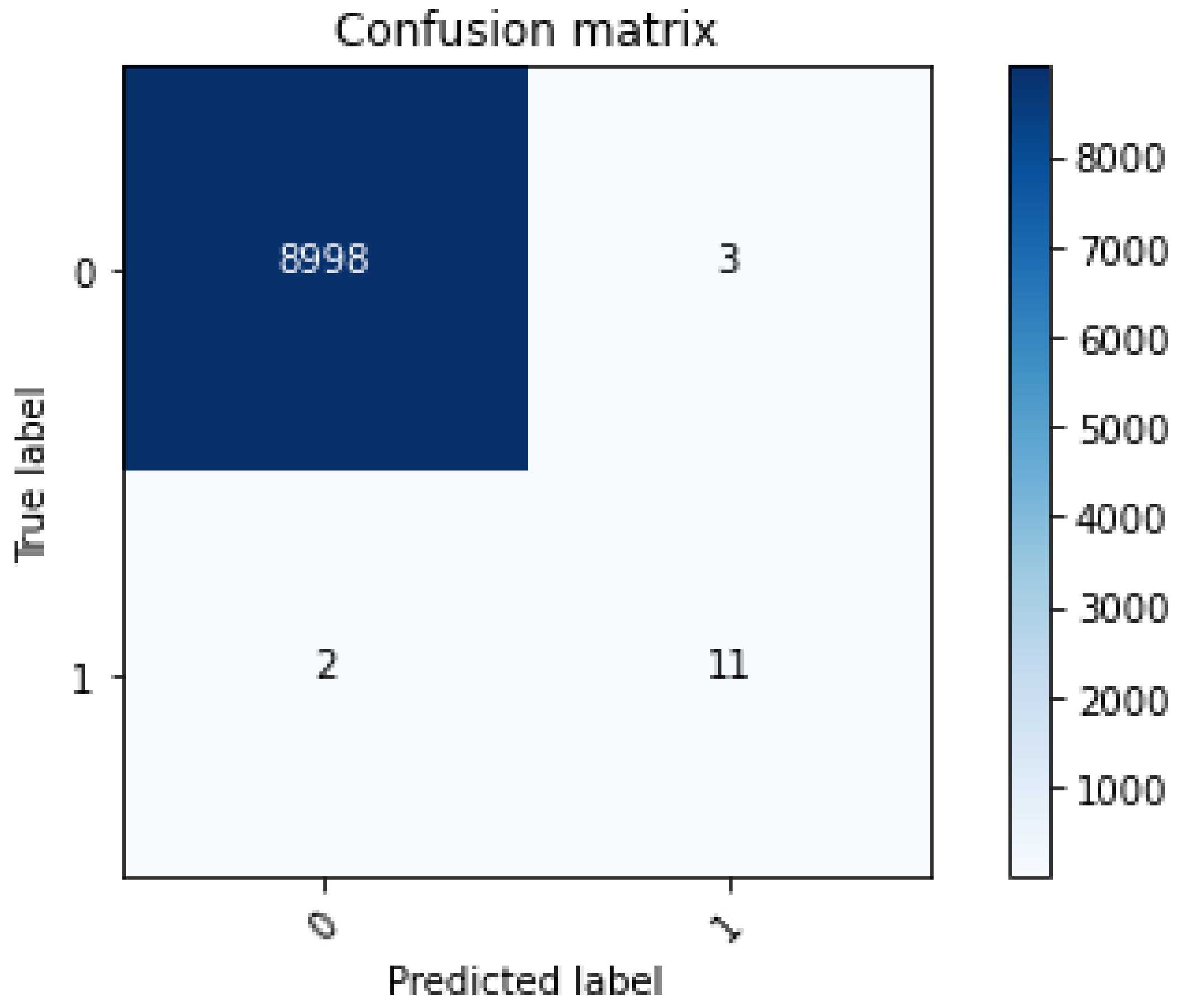
4. Results and Discussion
4.1. Validation of Proposed Model Based on Modern Cyber Attacks
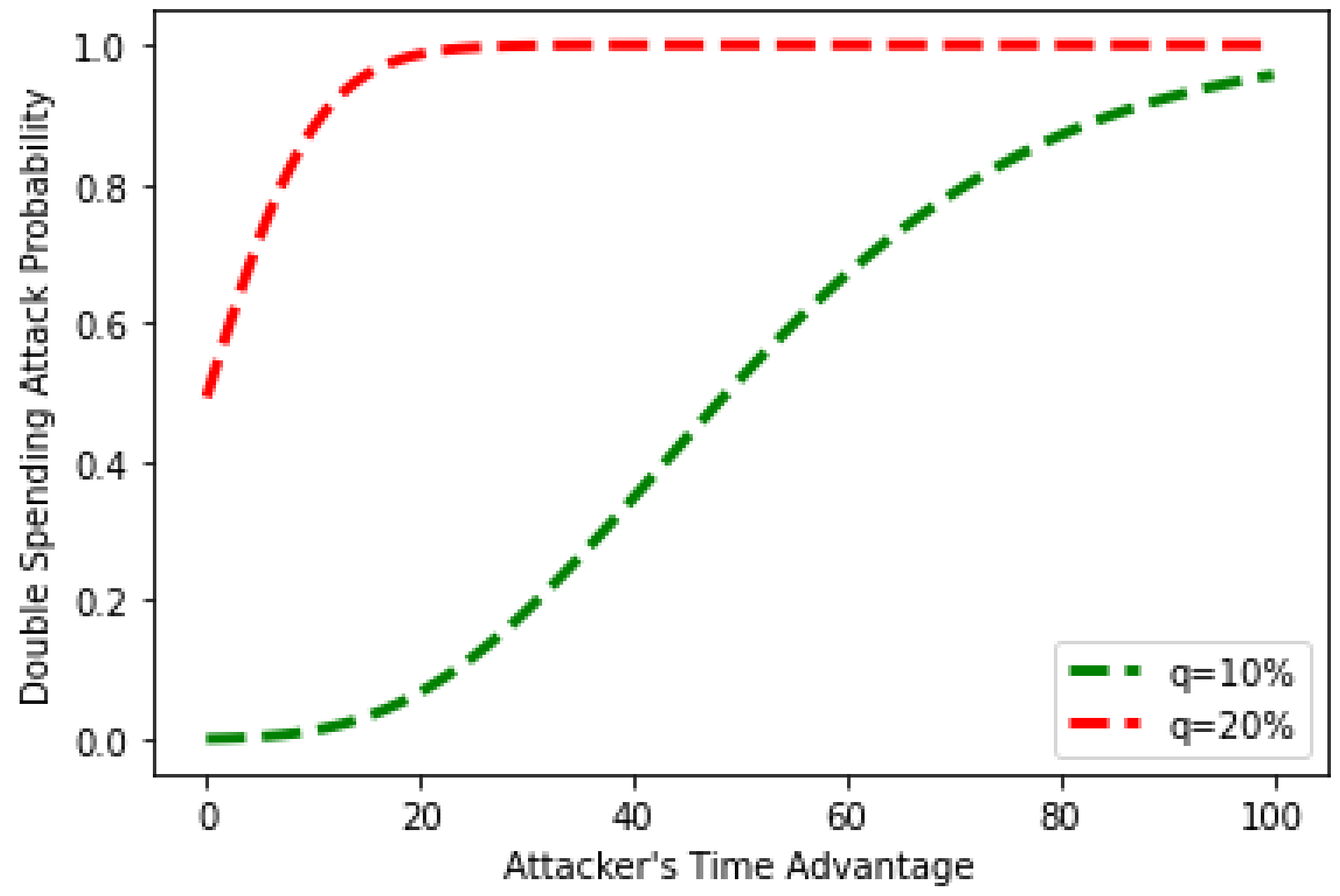
4.1.1. Double-Spending Attack
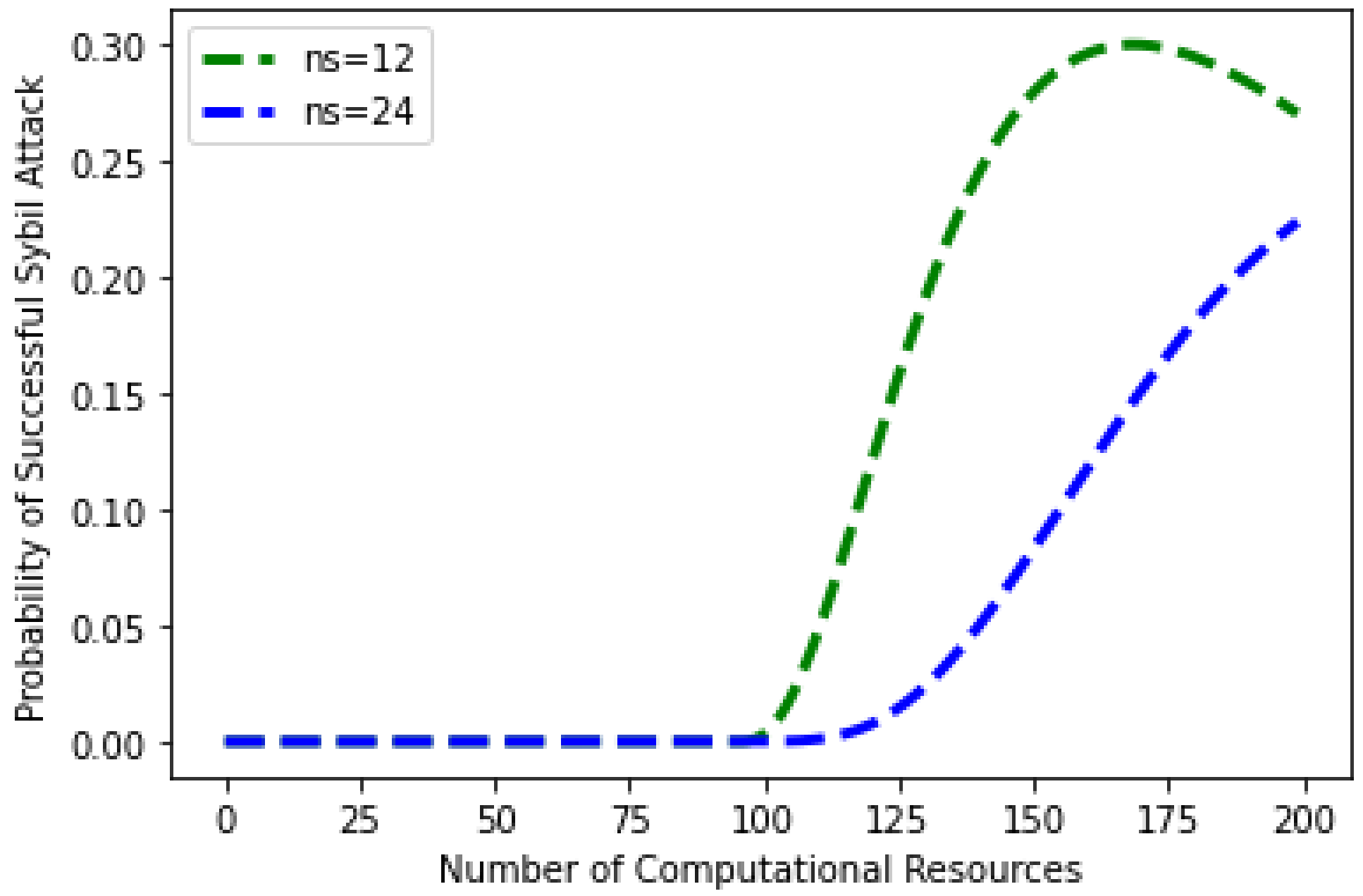
4.1.2. Sybil Attack
- Q: number of population
- g: number of items in the population that are classified as success
- h: number of items in the sample that are classified as successes
- c: number of computational power of sample
- N*: number of items in the sample
5. Security Analysis
- Re-entrancy vulnerability;
- Timestamp dependency;
- Callstack depth vulnerability;
- Transaction ordering dependency;
- Parity multisig bug;
- Integer overflow;
- Integer underflow.
Security Features
- Integrity: is an important feature which is used to ensure that there is no occurrence of data modification. The immutability of blockchain ensures data integrity and exchange messages between all participants and generates logs and events.
- Availability: it makes sure that the deployed smart contract in the blockchain is always available for all participants. Availability also ensures that all services are always available. It also protects the system against denial of service (DoS) attacks because all transactions are stored in a distributed ledger of Ethereum. Therefore, there is no fear of hacking, failure and compromise. The ledger of Ethereum is highly robust against the DoS attack because thousands of trusted mining nodes protect this ledger.
- Confidentiality: the requirement of confidentiality is achieved using a permissioned or private blockchain, e.g., Hyperledger or private Ethereum networks. The proposed system is based on a permissioned blockchain network in the proposed scenario.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| List of abbreviations: | |
| Abbreviation | Full Form |
| AI | Artificial Intelligent |
| ANN | Artificial Neural Network |
| CPS | Cyber–Physical System |
| DBF | Deep Blockchain Framework |
| DTR | Decision Tree Regression |
| ePoW | enhanced Proof of Work |
| GMM | Gaussian Mixture Model |
| IoT | Internet of Things |
| LSTM | Long Short-Term Memory |
| MLO | Mixture Localization-based Outliers |
| MLP | Multi Layer Perceptron |
| PCA | Principle Component Analysis |
| RFE | Recursive Feature Elimination |
| SDA | Stacked De-noising Autoencoders |
| SMOTE | Synthetic Minority Oversampling Technique |
| SVD | Singular Value Decomposition |
| SVM | Support Vector Machine |
| XGboost | eXtreme Gradient Boosting |
| List of acronyms: | |
| Abbreviation | Full Form |
| Catch-up function | |
| K | Number of confirmation to declare a block |
| m | Honest nodes mine the block |
| n | Attackers mine the block |
| Potential progress function | |
| q | Probability of attack |
| T | Time needed for mining |
| t | Time advantage for the attackers |
| Average time for the mining of block | |
| x | Available computational power in network |
| z | Initial disadvantage of attacker |
References
- Staudemeyer, R.C.; Voyiatzis, A.G.; Moldovan, G.; Suppan, S.R.; Lioumpas, A.; Calvo, D. Smart cities under attack. In Human-Computer Interaction and Cybersecurity Handbook; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Podgorelec, B.; Turkanović, M.; Karakatič, S. A machine learning-based method for automated blockchain transaction signing including personalized anomaly detection. Sensors 2020, 20, 147. [Google Scholar] [CrossRef] [PubMed]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 21 March 2020).
- Farrugia, S.; Ellul, J.; Azzopardi, G. Detection of illicit accounts over the Ethereum blockchain. Expert Syst. Appl. 2020, 150, 113318. [Google Scholar] [CrossRef]
- Ostapowicz, M.; Żbikowski, K. Detecting fraudulent accounts on blockchain: A supervised approach. In Proceedings of the International Conference on Web Information Systems Engineering, Hong Kong, China, 19–22 January 2020; Springer: Cham, Switzerland, 2020; pp. 18–31. [Google Scholar]
- Aziz, A.S.A.; Hassanien, A.E.; Azar, A.T.; Hanafy, S.E. Genetic Algorithm with Different Feature Selection Techniques for Anomaly Detectors Generation. In Proceedings of the 2013 Federated Conference on Computer Science and Information Systems (FedCSIS), Kraków, Poland, 8–11 September 2013. [Google Scholar]
- Hassanien, A.E.; Tolba, M.; Azar, A.T. Advanced Machine Learning Technologies and Applications: Second International Conference, AMLTA 2014, Cairo, Egypt, 28–30 November 2014. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2014; Volume 488, ISBN 978-3-319-13460-4. [Google Scholar]
- Khan, H.; Asghar, M.U.; Asghar, M.Z.; Srivastava, G.; Maddikunta, P.K.R.; Gadekallu, T.R. Fake review classification using supervised machine learning. In Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; Springer: Cham, Switzerland, 2021; pp. 269–288. [Google Scholar]
- Shahbazi, Z.; Hazra, D.P.; Park, S.; Byun, Y.C. Toward Improving the Prediction Accuracy of Product Recommendation System Using Extreme Gradient Boosting and Encoding Approaches. Symmetry 2020, 12, 1566. [Google Scholar] [CrossRef]
- Pesantez-Narvaez, J.; Guillen, M.; Alcañiz, M. Predicting motor insurance claims using telematics data—XGBoost versus logistic regression. Risks 2019, 7, 70. [Google Scholar] [CrossRef]
- Li, J.; Gu, C.; Wei, F.; Chen, X. A Survey on Blockchain Anomaly Detection Using Data Mining Techniques. In Proceedings of the International Conference on Blockchain and Trustworthy Systems, Guangzhou, China, 7–8 December 2019; Springer: Singapore, 2019. [Google Scholar]
- Reid, F.; Harrigan, M. An analysis of anonymity in the bitcoin system. In Security and Privacy in Social Networks; Springer: New York, NY, USA, 2013; pp. 197–223. [Google Scholar]
- Ngai, E.W.T.; Hu, Y.; Wong, Y.H.; Chen, Y.; Sun, X. The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decis. Support Syst. 2011, 50, 559–569. [Google Scholar] [CrossRef]
- Saia, R.; Carta, S. Evaluating Credit Card Transactions in the Frequency Domain for a Proactive Fraud Detection Approach. In Proceedings of the 14th International Conference on Security and Cryptography (SECRYPT 2017), Madrid, Spain, 26–28 July 2017; pp. 335–342. [Google Scholar]
- Sánchez, D.; Vila, M.A.; Cerda, L.; Serrano, J.M. Association rules applied to credit card fraud detection. Expert Syst. Appl. 2009, 36, 3630–3640. [Google Scholar] [CrossRef]
- Gyamfi, N.K.; Abdulai, J.D. Bank fraud detection using support vector machine. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 1–3 November 2018; pp. 37–41. [Google Scholar]
- Panigrahi, S.; Kundu, A.; Sural, S.; Majumdar, A.K. Credit card fraud detection: A fusion approach using Dempster–Shafer theory and Bayesian learning. Inf. Fusion 2009, 10, 354–363. [Google Scholar] [CrossRef]
- Shi, F.B.; Sun, X.Q.; Gao, J.H.; Xu, L.; Shen, H.W.; Cheng, X.Q. Anomaly detection in Bitcoin market via price return analysis. PLoS ONE 2019, 14, e0218341. [Google Scholar] [CrossRef]
- Kumar, P.; Gupta, G.P.; Tripathi, R. TP2SF: A Trustworthy Privacy-Preserving Secured Framework for sustainable smart cities by leveraging blockchain and machine learning. J. Syst. Archit. 2021, 115, 101954. [Google Scholar] [CrossRef]
- Zhao, Y.; Tarus, S.K.; Yang, L.T.; Sun, J.; Ge, Y.; Wang, J. Privacy-preserving clustering for big data in cyber-physical-social systems: Survey and perspectives. Inf. Sci. 2020, 515, 132–155. [Google Scholar] [CrossRef]
- Alkadi, O.; Moustafa, N.; Turnbull, B.; Choo, K.K.R. A deep blockchain framework-enabled collaborative intrusion detection for protecting IoT and cloud networks. IEEE Internet Things J. 2020, 8, 9463–9472. [Google Scholar] [CrossRef]
- AlKadi, O.; Moustafa, N.; Turnbull, B.; Choo, K.K.R. Mixture localization-based outliers models for securing data migration in cloud centers. IEEE Access 2019, 7, 114607–114618. [Google Scholar] [CrossRef]
- Keshk, M.; Sitnikova, E.; Moustafa, N.; Hu, J.; Khalil, I. An integrated framework for privacy-preserving based anomaly detection for cyber-physical systems. IEEE Trans. Sustain. Comput. 2019, 6, 66–79. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Xuan, S.; Liu, G.; Li, Z.; Zheng, L.; Wang, S.; Jiang, C. Random forest for credit card fraud detection. In Proceedings of the 2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), Zhuhai, China, 27–29 March 2018; pp. 1–6. [Google Scholar]
- Liu, C.; Chan, Y.; Alam Kazmi, S.H.; Fu, H. Financial fraud detection model: Based on random forest. Int. J. Econ. Financ. 2015, 7, 178–188. [Google Scholar] [CrossRef]
- Apruzzese, G.; Andreolini, M.; Colajanni, M.; Marchetti, M. Hardening random forest cyber detectors against adversarial attacks. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 427–439. [Google Scholar] [CrossRef]
- Primartha, R.; Tama, B.A. Anomaly detection using random forest: A performance revisited. In Proceedings of the 2017 International Conference on Data and Software Engineering (ICoDSE), Palembang, Indonesia, 1–2 November 2017; pp. 1–6. [Google Scholar]
- Laskov, P. Practical evasion of a learning-based classifier: A case study. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 197–211. [Google Scholar]
- Pham, T.; Lee, S. Anomaly detection in bitcoin network using unsupervised learning methods. arXiv 2016, arXiv:1611.03941. [Google Scholar]
- Martin, K.; Rahouti, M.; Ayyash, M.; Alsmadi, I. Anomaly detection in blockchain using network representation and machine learning. Secur. Priv. 2022, 5, e192. [Google Scholar] [CrossRef]
- Pinzón, C.; Rocha, C. Double-spend attack models with time advantange for bitcoin. Electron. Notes Theor. Comput. Sci. 2016, 329, 79–103. [Google Scholar] [CrossRef]
- Bitcoin Network Transactional Metadata. Available online: https://www.kaggle.com/datasets/omershafiq/bitcoin-network-transactional-metadata (accessed on 12 September 2022).
- Shafiq, O. Anomaly Detection in Blockchain. Master’s Thesis, Tampere University, Tampere, Finland, 2019. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Sadaf, K.; Sultana, J. Intrusion detection based on autoencoder and isolation Forest in fog computing. IEEE Access 2020, 8, 167059–167068. [Google Scholar] [CrossRef]
- Eyal, I.; Sirer, E.G. Majority is not enough: Bitcoin Mining is vulnerable. In Proceedings of the International Conference on Financial Cryptography and Data Security, Christ Church, Barbados, 3–7 March 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 436–454. [Google Scholar]
- Landa, R.; Griffin, D.; Clegg, R.G.; Mykoniati, E.; Rio, M. A Sybilproof indirect reciprocity mechanism for peer-to-peer networks. In Proceedings of the IEEE INFOCOM 2009, Rio De Janeiro, Brazil, 24 April 2009; pp. 343–351. [Google Scholar]
- Luu, L.; Chu, D.-H.; Olickel, H.; Saxena, P.; Hobor, A. Making smart contracts smarter. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Nizamuddin, N.; Hasan, H.; Salah, K.; Iqbal, R. Blockchain-based framework for protecting author royalty of digital assets. Arab. J. Sci. Eng. 2019, 44, 3849–3866. [Google Scholar] [CrossRef]
- Halo Block, Medium. How To Use Oyente, a Smart Contract Security Analyzer—Solidity Tutorial. 2020. Available online: https://medium.com/haloblock/how-to-use-oyente-a-smart-contract-security-analyzer-solidity-tutorial-86671be93c4b (accessed on 13 April 2020).






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashfaq, T.; Khalid, R.; Yahaya, A.S.; Aslam, S.; Azar, A.T.; Alsafari, S.; Hameed, I.A. A Machine Learning and Blockchain Based Efficient Fraud Detection Mechanism. Sensors 2022, 22, 7162. https://doi.org/10.3390/s22197162
Ashfaq T, Khalid R, Yahaya AS, Aslam S, Azar AT, Alsafari S, Hameed IA. A Machine Learning and Blockchain Based Efficient Fraud Detection Mechanism. Sensors. 2022; 22(19):7162. https://doi.org/10.3390/s22197162
Chicago/Turabian StyleAshfaq, Tehreem, Rabiya Khalid, Adamu Sani Yahaya, Sheraz Aslam, Ahmad Taher Azar, Safa Alsafari, and Ibrahim A. Hameed. 2022. "A Machine Learning and Blockchain Based Efficient Fraud Detection Mechanism" Sensors 22, no. 19: 7162. https://doi.org/10.3390/s22197162
APA StyleAshfaq, T., Khalid, R., Yahaya, A. S., Aslam, S., Azar, A. T., Alsafari, S., & Hameed, I. A. (2022). A Machine Learning and Blockchain Based Efficient Fraud Detection Mechanism. Sensors, 22(19), 7162. https://doi.org/10.3390/s22197162